Cursus
Fondements de GitHub
10 h
La maîtrise du contrôle de version repose sur la compréhension des outils nuancés que Git fournit pour gérer l'historique des projets. Parmi ces outils, git reset --soft se distingue comme l'une des commandes les plus élégantes et les plus puissantes pour la manipulation chirurgicale des commits. Après avoir collaboré avec des équipes dispersées dans plusieurs start-ups et environnements d'entreprise, j'ai constaté que la maîtrise de cette commande unique transforme fondamentalement la manière dont les développeurs abordent la gestion de l'historique des commits. gestion de l'historique des commits.
Permettez-moi de vous raconter une anecdote qui illustre parfaitement l'importance de cette question. Au cours de ma deuxième année en tant que développeur professionnel, j'ai travaillé sur une fonctionnalité essentielle qui nécessitait l'intégration de trois API différentes. À l'instar de nombreux développeurs, j'ai effectué des commits fréquents, parfois plusieurs fois par heure, afin de déboguer les cas limites et d'affiner l'implémentation. Une fois la fonctionnalité terminée, j'avais accumulé 23 commits avec des messages tels que « correction d'une faute de frappe », « correction effective du bug » et « suppression du code de débogage ».
Lors de la révision du code, mon responsable technique a examiné l'historique des commits et a déclaré : « Cela reflète votre processus de débogage, et non ce que vous avez développé. » Ce moment m'a permis de comprendre la différence entre les commits en tant que points de contrôle personnels et les commits en tant que communication professionnelle. git reset --soft est devenu mon outil pour transformer les premiers en seconds.
Ce guide vous présentera tout ce que j'ai appris sur l'utilisation efficace d'git reset --soft , y compris les flux de travail qui m'ont permis de gagner un nombre considérable d'heures et m'ont aidé à conserver des historiques clairs pour des centaines de fonctionnalités. Que vous souhaitiez nettoyer l'historique des commits avant une fusion ou restructurer votre travail pour améliorer la révision du code, il est essentiel pour tout développeur souhaitant maîtriser Git de comprendre le fonctionnement de la réinitialisation logicielle.
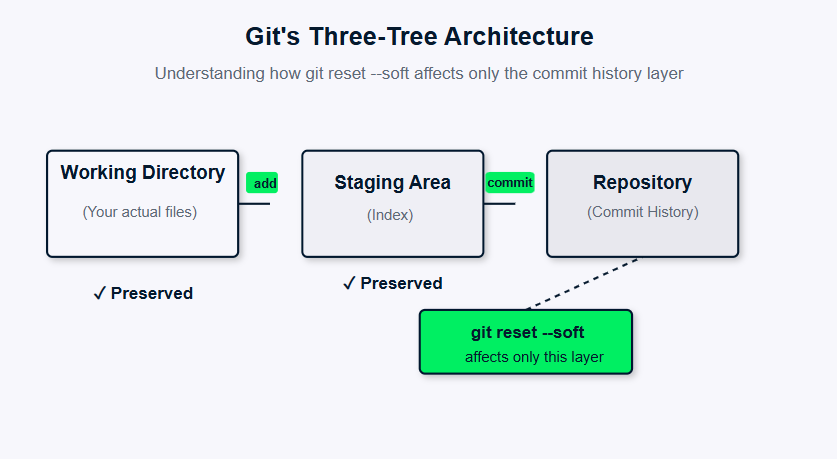
Visualiser comment git reset --soft n'affecte que l'historique des commits.
La commande Git reset vous permet de naviguer dans l'historique des commits, en offrant différents niveaux de « défaire » les modifications dans votre référentiel. La commande reset modifie fondamentalement l'emplacement vers lequel pointe votre pointeur de branche (HEAD) dans le graphique des commits, mais la particularité réside dans la manière dont elle gère les trois domaines critiques de l'architecture de Git : l'historique des commits, la zone de préparation et le répertoire de travail.
Les développeurs ont recours à git reset lorsqu'ils ont besoin de réorganiser leur travail, de corriger des erreurs ou de préparer des historiques de commit plus clairs pour la collaboration. Contrairement à git revert, qui crée de nouveaux commits pour annuler les modifications précédentes, reset déplace réellement votre pointeur de branche vers l'arrière dans l'historique. Cette fonctionnalité le rend extrêmement efficace pour les workflows de développement local, où vous avez un contrôle total sur le calendrier des validations.
La qualité des options de réinitialisation de Git réside dans leur flexibilité. Chaque mode (doux, mixte et dur) offre différents compromis entre sécurité et exhaustivité, vous permettant de choisir précisément la quantité de travail que vous souhaitez conserver ou supprimer.
Avant d'entrer dans les détails de la réinitialisation logicielle, il est essentiel de comprendre comment Git gère le code dans ses trois domaines principaux afin de pouvoir prendre des décisions éclairées quant au mode de réinitialisation à utiliser.
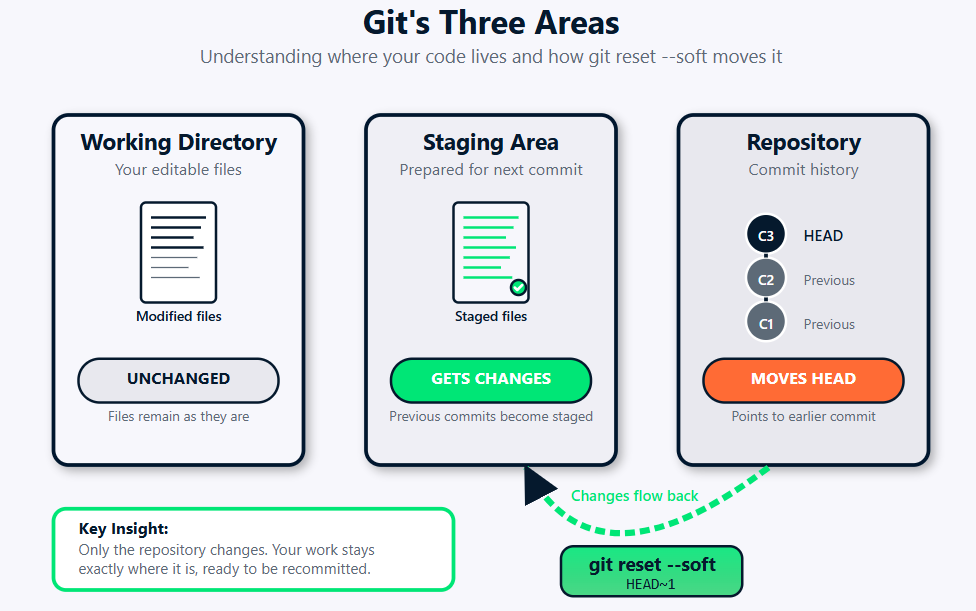
git reset --soft Diagramme du flux de travail illustrant comment la commande affecte les trois domaines principaux de Git : le répertoire de travail, la zone de préparation et le référentiel.
L'historique des commits représente l'enregistrement permanent de votre projet, une chaîne liée d'instantanés qui retrace l'évolution de votre base de code. HEAD sert de marqueur de position actuelle dans cette chronologie, indiquant généralement la dernière validation sur votre branche active.
Lorsque j'ai commencé à utiliser Git dans un contexte professionnel, j'ai conceptualisé HEAD comme un signet dans l'historique de mon projet, et ce modèle mental m'a été très utile pendant plus d'une décennie. Le fait de déplacer HEAD vers l'arrière à travers les opérations d'git reset s « réécrit » efficacement la chronologie de votre branche, faisant apparaître les commits comme s'ils n'avaient jamais existé du point de vue de votre branche. Cependant, ces commits ne sont pas immédiatement supprimés, le garbage collection les garde accessibles via le reflog à des fins de récupération.
Il est essentiel de bien comprendre le fonctionnement de HEAD, car cela a une incidence sur les historiques de fusion, les relations entre les branches et les workflows de collaboration. Chaque fois que vous déplacez HEAD vers l'arrière, vous indiquez essentiellement : « Je souhaite que ma branche ressemble à ce qu'elle était à ce moment précis dans le temps. » C'est un outil puissant, mais ce pouvoir s'accompagne de responsabilités, en particulier lorsque l'on travaille avec des référentiels partagés.
La zone de préparation, également appelée index, sert de zone de préparation pour la prochaine validation. Considérez cela comme un brouillon dans lequel vous organisez précisément les modifications que vous souhaitez inclure dans votre prochain instantané. Les fichiers dans la zone de préparation ont été marqués avec git add, mais n'ont pas encore été intégrés à votre historique permanent.
J'apprécie expliquer la zone de préparation à l'aide d'une analogie avec la photographie qui m'a marqué au début de ma carrière. Votre répertoire de travail est comparable à des accessoires dispersés dans un studio photo, certains que vous souhaitez inclure dans la prise de vue, d'autres non. La zone de préparation correspond au positionnement et à l'éclairage de vos sujets avant de prendre la photo (la validation). Vous pouvez ajuster la zone de préparation autant de fois que vous le souhaitez avant de valider cet instantané final.
Les différents modes de réinitialisation interagissent avec la zone de transit de manière distincte. Cette interaction détermine si les modifications que vous avez précédemment préparées restent prêtes à être validées ou si elles sont annulées et renvoyées dans le répertoire de travail. Comprendre cette relation permet d'éviter la confusion à laquelle sont confrontés de nombreux développeurs lorsque les modifications qu'ils ont soigneusement mises en place disparaissent soudainement ou persistent de manière inattendue après une opération de réinitialisation.
Votre répertoire de travail contient les fichiers que vous modifiez actuellement, la version active de votre code que vous voyez dans votre éditeur de texte ou votre IDE. Cette zone contient à la fois les fichiers suivis (fichiers connus de Git) et les fichiers non suivis (nouveaux fichiers que Git n'a pas été chargé de surveiller).
La relation entre le répertoire de travail et les opérations de réinitialisation varie considérablement d'un mode à l'autre, et c'est là que la plupart des développeurs rencontrent des difficultés. Certains modes de réinitialisation laissent vos fichiers de travail intacts, tandis que d'autres peuvent écraser de manière irréversible vos modifications actuelles. Cette distinction est essentielle lorsque vous êtes en plein développement et que vous devez ajuster l'historique des commits sans perdre le travail en cours.
Au début de ma carrière, j'ai appris cette leçon à mes dépens lorsque j'ai accidentellement utilisé git reset --hard au lieu de git reset --soft et perdu trois heures de travail non validé. Cette erreur m'a appris à toujours vérifier le mode de réinitialisation que j'utilise et à créer des branches de sauvegarde avant toute opération importante sur l'historique.
Git propose trois modes de réinitialisation principaux, chacun étant conçu pour différents scénarios et exigences de sécurité. Après avoir utilisé ces modes pendant plusieurs années dans divers contextes, allant de projets individuels à des collaborations au sein de grandes équipes.
Je peux vous assurer que la compréhension de ces modes permet d'éviter la perte de données et vous aide à choisir l'outil le mieux adapté à votre situation spécifique.

Tableau comparatif des --soft, --mixedet --hard git reset.
Les trois modes de réinitialisation ont des répercussions variées sur l'architecture de Git, et je les considère comme ayant différents niveaux de « tolérance » :
--soft: Déplace uniquement HEAD, en conservant à la fois la zone de préparation et le répertoire de travail.--mixed (par défaut) : Déplace HEAD et réinitialise la zone de préparation, en conservant le répertoire de travail.--hard: Déplace HEAD, réinitialise la zone de préparation et remplace le répertoire de travail.Chaque mode répond à des besoins spécifiques, et j'ai développé des préférences pour chacun d'entre eux au fil du temps. La réinitialisation logicielle est particulièrement utile lorsque vous souhaitez restructurer les commits sans perdre aucun travail. Elle est devenue mon outil de prédilection pour le nettoyage des commits. La réinitialisation mixte est utile lorsque vous devez réorganiser les modifications différemment, ce que je trouve pratique lorsque j'ai trop organisé et que je souhaite créer des commits plus ciblés. La réinitialisation matérielle permet de repartir de zéro, mais nécessite une extrême prudence en raison de sa nature destructive.
Il existe également la commande spécifique au fichier « git reset », qui n'agit que sur la zone de préparation, désactivant la préparation de fichiers spécifiques sans affecter les validations ou autres modifications préparées. Ce contrôle précis m'a été d'une grande aide à de nombreuses reprises lorsque j'ai accidentellement mis en attente des fichiers qui n'auraient pas dû être inclus dans une validation particulière.
Le mode « --soft » (Tout sauf la structure des commits) préserve de manière unique tous les éléments à l'exception de la structure des commits, ce qui le rend particulièrement efficace pour l'optimisation du flux de travail. Lorsque vous effectuez une réinitialisation logicielle, votre répertoire de travail reste exactement tel qu'il était, et toutes les modifications issues des commits « annulés » sont automatiquement mises en attente, prêtes à être réengagées. Ce comportement rend la réinitialisation logicielle idéale pour l'édition des messages de validation. modifier les messages de validation, la restructuration de l'historique et l'optimisation du flux de travail.
Permettez-moi d'illustrer cela à l'aide d'un scénario réel tiré de mon expérience. Je travaillais sur une fonctionnalité qui impliquait la mise à jour des composants front-end et back-end. Au fur et à mesure du développement, j'ai effectué des commits distincts pour chaque modification mineure : un pour la mise à jour d'une classe CSS, un autre pour la modification d'un point de terminaison API, un autre encore pour la mise à jour des tests. À la fin, j'avais sept commits qui faisaient tous partie de la mise en œuvre d'une seule fonctionnalité cohérente.
Avant de soumettre le code pour révision, j'ai utilisé la commande « git reset --soft HEAD~7 » pour annuler les sept commits tout en conservant les modifications en attente, puis j'ai créé deux commits propres : un pour les modifications du backend et un pour celles du frontend. Cette transformation a rendu la révision du code beaucoup plus pertinente, car le réviseur a pu comprendre le regroupement logique des modifications plutôt que de suivre mon processus de développement sinueux.
La comparaison des modes révèle leurs philosophies différentes :
Dans mon flux de travail quotidien, j'utilise probablement la réinitialisation logicielle 80 % du temps, la réinitialisation mixte 15 % du temps et la réinitialisation matérielle 5 % du temps, et ces 5 % correspondent généralement à des situations où je supprime des branches expérimentales qui n'ont pas abouti.
Pour maîtriser l'application pratique de la réinitialisation logicielle, il est nécessaire de comprendre à la fois les mécanismes et les flux de travail dans lesquels elle apporte le plus de valeur. Permettez-moi de vous présenter les techniques essentielles qui sont devenues une seconde nature dans mon processus de développement.

Une procédure étape par étape pour utiliser la commande git reset --soft commande.
La syntaxe de base pour la réinitialisation logicielle est simple : git reset --soft . Le défi consiste à identifier la bonne cible et à comprendre les résultats. Permettez-moi de vous présenter mon processus de travail habituel :
git log --oneline -10
git reset --soft m0n1o2p
git statusJe commence par git log --oneline -10 pour consulter l'historique de mes commits récents dans un format compact. Une fois que j'ai identifié mon commit cible, j'exécute git reset --soft m0n1o2p. Cette commande déplace mon pointeur de branche vers l'arrière tout en conservant l'ensemble du travail effectué lors des commits ultérieurs. Enfin, git status confirme que toutes les modifications issues des commits de réinitialisation sont désormais préparées et prêtes à être réengagées.
Voici un conseil que m'a donné un mentor au début de ma carrière : utilisez toujours git log --oneline en premier lieu pour obtenir une représentation visuelle de votre historique de commits. J'utilise également fréquemment git log --graph --oneline --all lorsque je travaille avec plusieurs branches afin de comprendre la relation entre les différentes lignes de développement.
Vous pouvez également utiliser des références relatives telles que HEAD~2 pour revenir deux commits en arrière à partir de votre position actuelle. Je trouve cela particulièrement utile pour les opérations rapides : git reset --soft HEAD~1 est probablement la commande que je tape le plus souvent, car elle annule uniquement la dernière validation tout en conservant tout ce qui est prêt pour une nouvelle tentative.
L'une des applications les plus pratiques de la réinitialisation logicielle consiste à corriger les commits récents, que ce soit pour ajuster le message de commit, ajouter des modifications oubliées ou réorganiser la structure des commits. Ce processus m'a évité de nombreuses situations embarrassantes.
git log -1
git reset --soft HEAD~1
git add forgotten_file.py
git commit -m "Implement user authentication with proper validation
- Add login/logout endpoints
- Include password validation logic
- Add forgotten error handling module
- Update tests for new authentication flow"Je viens de valider, mais j'ai omis d'inclure un fichier important. J'utilise git log -1 pour examiner mon commit incomplet, puis git reset --soft HEAD~1. Cette commande annule la validation tout en conservant toutes les modifications préparées. Après avoir ajouté le fichier oublié avec la commande` git add forgotten_file.py`, je crée un nouveau commit qui inclut tous les éléments avec un message de commit approprié.
Ce processus est devenu une seconde nature pour moi. J'utilise probablement ce modèle plusieurs fois par semaine, en particulier lorsque je suis dans un état de fluidité et que je m'engage fréquemment. Il est très satisfaisant de pouvoir nettoyer son travail rétroactivement, c'est comme disposer d'un bouton « annuler » pour le contrôle des versions.
J'ai également trouvé cette technique extrêmement utile lorsque je travaille avec des conventions de messages de validation. De nombreuses équipes utilisent des formats tels que Commits conventionnels, et si je me rends compte que je n'ai pas suivi correctement le format, une réinitialisation rapide me permet de le corriger sans créer de commits supplémentaires.
Les commits volumineux enfreignent le principe des modifications atomiques et compliquent la révision du code. La réinitialisation logicielle offre une solution efficace pour diviser les commits trop volumineux en segments logiques et vérifiables. Il s'agit de l'une des techniques qui a le plus amélioré mes commentaires sur la révision de code au fil des ans.
git log --oneline -3
git reset --soft HEAD~1
git status
git reset
git add models/user.py
git commit -m "Add user model with validation rules"
git add controllers/user_controller.py
git commit -m "Implement user CRUD operations"
git add tests/test_user_model.py tests/test_user_controller.py
git commit -m "Add comprehensive user model and controller tests"
git add templates/user/ static/css/user.css
git commit -m "Add user interface templates and styling"Je commence par git log --oneline -3 pour identifier le commit surdimensionné, puis j'utilise git reset --soft HEAD~1. Cette commande annule la validation tout en conservant les modifications préparées. L'exécution de la commande « git reset » (sans options) désactive tout, me permettant ainsi de repartir de zéro. Je suis désormais en mesure de créer des commits ciblés : d'abord le modèle, puis le contrôleur, ensuite les tests, et enfin les composants de l'interface utilisateur. Cette approche permet de transformer un commit volumineux en éléments logiques et vérifiables.
Cette approche a considérablement modifié la manière dont les réviseurs de code répondent à mes demandes de modification. Au lieu de recevoir des commentaires tels que « Cette validation est trop volumineuse pour être examinée efficacement », je reçois désormais des commentaires spécifiques et exploitables sur chaque composant logique de mes modifications.
Une chose que j'ai apprise est de réfléchir à l'histoire que racontent mes commits. Chaque validation doit représenter une idée complète qui a du sens en soi. Si je ne parviens pas à expliquer clairement en une seule phrase ce que fait un commit, c'est probablement qu'il est trop volumineux et qu'il doit être divisé.
Lorsque vous avez effectué plusieurs petites validations au cours du développement (correction de fautes de frappe, prise en compte des commentaires de révision ou progrès incrémentiels),les regrouper en un seul commit soigné permet d'obtenir un historique plus clair. Cette technique est devenue indispensable dans mon flux de travail, en particulier lorsque je travaille sur des fonctionnalités pendant plusieurs jours.
git log --oneline -6
git reset --soft HEAD~5
git status
git commit -m "Implement comprehensive user registration system
- Add user registration endpoint with validation
- Include password strength requirements
- Add comprehensive test coverage
- Update documentation with usage examples"J'utilise git log --oneline -6 pour consulter mon historique de développement, puis git reset --soft HEAD~5. Cette commande combine cinq commits incrémentiels tout en préparant automatiquement l'ensemble du travail. En exécutant « git status », je constate que tout est prêt pour une nouvelle validation. Je crée ensuite un commit soigné avec un message professionnel qui décrit la fonctionnalité complète plutôt que le processus de débogage.
J'apprécie particulièrement cette technique avant de fusionner des branches de fonctionnalités. Cela me permet d'effectuer des commits granulaires pendant le développement (ce qui facilite le débogage et le suivi de la progression) tout en présentant un historique clair et professionnel à la branche principale.
L'une des méthodes de travail que j'ai développée consiste à utiliser une convention de nommage pour mes commits en cours. J'utiliserai des préfixes tels que « WIP : » ou « temp : » pour les commits que je prévois de fusionner ultérieurement. Cela permet d'identifier facilement les commits qui sont des « commits d'histoire » par opposition aux « commits de point de contrôle ».
Après avoir réécrit l'historique local avec une réinitialisation douce, il est nécessaire de procéder avec prudence lors de la poussée vers les dépôts distants. Étant donné que vous avez modifié la structure des commits, Git refusera une opération de push normale. C'est là qu'il est essentiel de bien comprendre comment pousser en toute sécurité.
git push origin feature-branch
git push --force-with-lease origin feature-branchAprès avoir réécrit l'historique, une commande git push origin feature-branch standard échouera avec une erreur « non-fast-forward ». Je préfère utiliser git push --force-with-lease origin feature-branch . Cette commande effectue une poussée forcée en toute sécurité tout en garantissant que personne d'autre n'a mis à jour la branche depuis ma dernière récupération.
L'option « --force-with-lease » a permis à mon équipe d'éviter plusieurs situations critiques. Il garantit la sécurité en s'assurant que personne d'autre n'a poussé de commits vers la branche depuis votre dernière récupération. Cela évite de remplacer accidentellement le travail des collaborateurs, une erreur qui peut nuire considérablement aux relations au sein de l'équipe et à la stabilité du projet.
J'ai appris à mes dépens ce qu'est l'--force-with-lease, après avoir accidentellement écrasé le travail d'un collègue avec une commande force push classique. La conversation qui a suivi était... gênante. Depuis lors, j'ai adopté --force-with-lease comme paramètre par défaut pour toute opération de force push, et je recommande la même chose à toute personne travaillant sur des référentiels partagés.
Les workflows Git réels présentent des scénarios dans lesquels la réinitialisation logicielle devient indispensable. Permettez-moi de partager quelques exemples tirés de ma propre expérience en matière de développement qui illustrent comment gérer des situations courantes que vous rencontrerez dans des environnements professionnels.
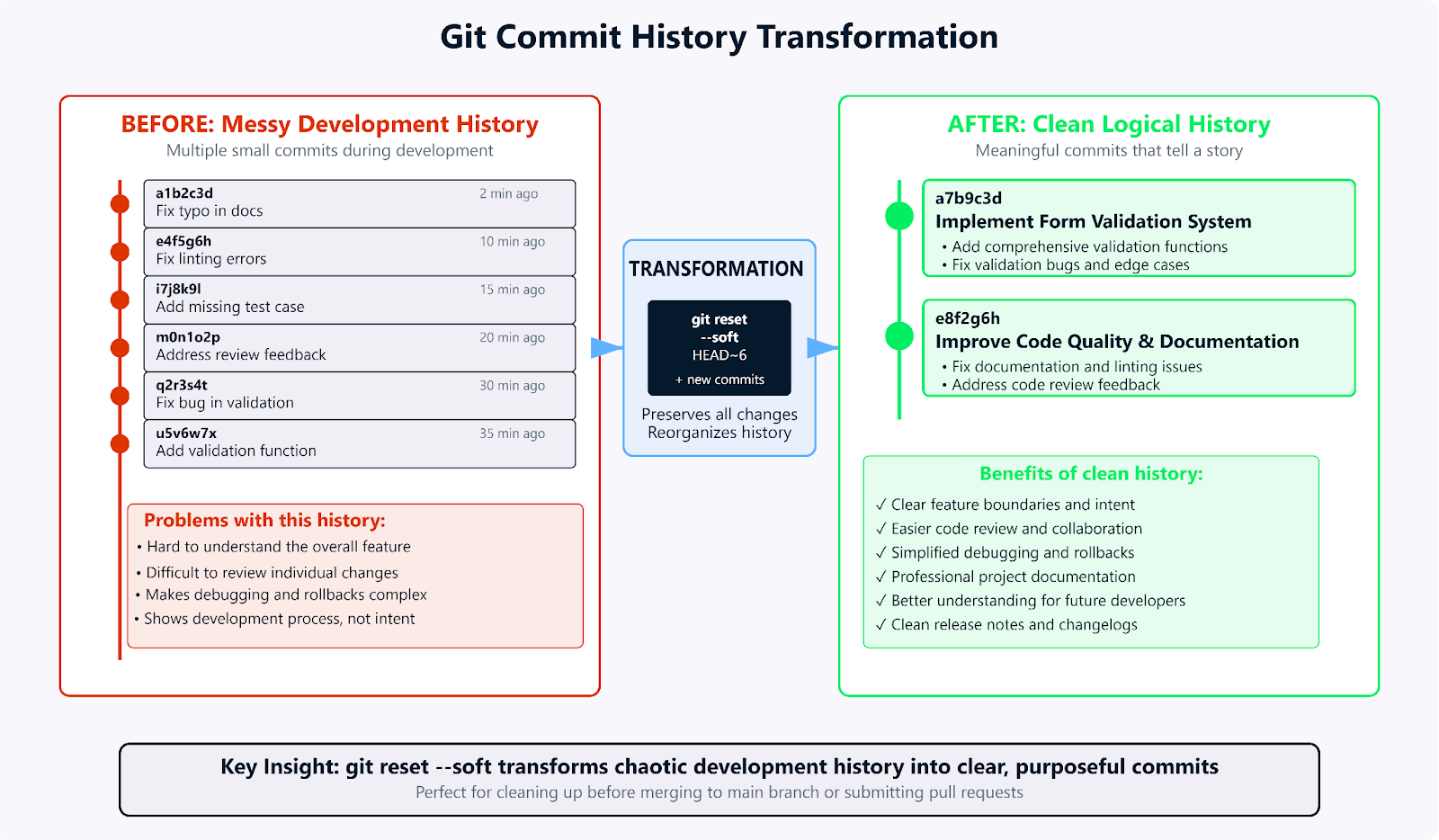
Transformer les commits désordonnés avec git reset --soft.
Il s'agit du cas d'utilisation le plus fréquent de la réinitialisation logicielle dans mon flux de travail quotidien, lorsque l'on effectue une validation trop tôt ou avec un message de validation inadéquat. Je procède probablement ainsi au moins une fois par jour.
git log -1
git reset --soft HEAD~1
git status
git commit -m "Fix authentication middleware edge case handling
- Resolve null pointer exception when user session expires
- Add proper error handling for malformed JWT tokens
- Include additional test coverage for session timeout scenarios
- Update error messages to be more user-friendly"Lorsque je constate un message de commit peu approprié tel que « fix stuff » après avoir exécuté git log -1, j'utilise git reset --soft HEAD~1. Cette commande annule la validation tout en conservant les modifications préparées. Ensuite, git status confirme que tout est prêt, et je peux à nouveau valider avec un message professionnel qui explique clairement ce que j'ai corrigé.
Ce flux de travail m'a évité d'avoir des messages de validation tels que « asdf », « temp » ou « fix » enregistrés de manière permanente dans l'historique du projet. Les messages de commit professionnels sont importants, car ils servent de documentation pour les futurs développeurs (y compris vous-même à l'avenir) qui cherchent à comprendre pourquoi des modifications ont été apportées.
J'ai établi une règle pour moi-même : si je ne parviens pas à rédiger un message de validation qui explique clairement la raison de mes modifications, la validation n'est probablement pas prête. La réinitialisation logicielle me permet de valider rapidement et fréquemment pendant le développement tout en conservant des normes professionnelles dans l'historique final.
Il est parfois nécessaire d'annuler plusieurs validations afin de réorganiser une série de modifications connexes ou d'intégrer des commentaires qui affectent plusieurs validations. Ce scénario se présente fréquemment lors des cycles de révision du code.
git log --oneline -8
git reset --soft HEAD~4
git status
git commit -m "Refactor user authentication system based on security review
This consolidates the previous authentication improvements into a single
cohesive implementation that addresses all security concerns raised
during code review."Lorsque les commentaires issus de la révision du code concernent plusieurs commits, j'utilise git log --oneline -8 pour identifier les commits qui nécessitent une restructuration, puis git reset --soft HEAD~4. Cette commande les annule tout en conservant les modifications en attente. Après avoir exécuté git status pour vérifier que tout est prêt, je crée un seul commit qui traite tous les commentaires dans une implémentation cohérente.
Je me souviens d'une révision de code particulièrement difficile au cours de laquelle l'équipe de sécurité a identifié des problèmes couvrant trois commits différents dans ma fonctionnalité d'authentification. Plutôt que de créer des commits « correctifs » supplémentaires, j'ai utilisé cette technique pour intégrer leurs commentaires et présenter l'implémentation corrigée sous la forme d'un commit unique et clair. Le réviseur a apprécié de ne pas avoir à suivre les corrections sur plusieurs commits.
Cette approche est particulièrement utile lorsque vous avez testé différentes implémentations et que vous souhaitez présenter la solution finale sans montrer tous les commits d'essais et d'erreurs qui y ont conduit.
Bien que cela ne concerne pas spécifiquement la réinitialisation logicielle, la compréhension des opérations de réinitialisation au niveau des fichiers complète vos workflows de réinitialisation logicielle et vous offre un contrôle précis sur votre zone de transit.
git add user_model.py user_controller.py debug_helper.py
git status
git reset debug_helper.py
git statusAprès avoir mis en scène plusieurs fichiers avec git add user_model.py user_controller.py debug_helper.py, je me rends compte que le fichier de débogage ne devrait pas être inclus. J'utilise git reset debug_helper.py. Cette commande désactive uniquement ce fichier, laissant les autres activés. L'exécution de la commande « git status » confirme que la désactivation sélective a fonctionné correctement.
Ce niveau de contrôle précis est devenu essentiel dans mon flux de travail. Je me retrouve souvent à mettre en attente plus de fichiers que prévu, et le fait de pouvoir retirer de manière sélective des fichiers de la mise en attente sans affecter mon historique de validation me permet de créer des validations précises.
J'ai également trouvé cela utile lorsque je travaille avec des fichiers générés automatiquement ou lorsque mon IDE inclut accidentellement des fichiers que je n'avais pas l'intention de valider. C'est beaucoup plus efficace que de tout désactiver puis de réactiver de manière sélective.
Ce scénario se produit lorsque vous souhaitez supprimer des commits de l'historique tout en conservant les modifications réelles du code en vue d'une réintégration potentielle. J'utilise cette technique lorsque je constate que ma structure de commit ne reflète pas correctement la réalité.
git log --oneline -4
git reset --soft HEAD~3
git reset
git add backend/
git commit -m "Implement backend API changes for user profile feature"
git add frontend/
git commit -m "Update frontend components for user profile display"Lorsque j'ai des commits frontend/backend mélangés qui devraient être organisés différemment, j'utilise git log --oneline -4 pour visualiser l'historique désordonné, puis git reset --soft HEAD~3. Cette commande supprime les validations tout en conservant les modifications préparées. L'exécution de la commande « git reset » (sans options) désactive tout, ce qui me permet de réorganiser en ajoutant d'abord les fichiers backend, puis les fichiers frontend sous forme de commits logiques distincts.
Ce flux de travail s'est révélé particulièrement utile lors du développement de fonctionnalités full-stack, où j'ai initialement validé les modifications front-end et back-end ensemble, mais où j'ai ensuite réalisé qu'il était préférable de les valider séparément afin de faciliter la révision et le retour en arrière éventuel.
La division des commits améliore la qualité de la révision du code et rend le débogage futur plus précis. Cette technique a considérablement amélioré les commentaires que je reçois sur les demandes d'extraction.
git show --name-only HEAD
git reset --soft HEAD~1
git reset
git add models/user_profile.py
git commit -m "Add user profile model with validation"
git add api/user_profile_endpoints.py
git commit -m "Implement user profile API endpoints"
git add tests/test_user_profile.py
git commit -m "Add comprehensive user profile tests"
git add frontend/components/UserProfile.js
git add frontend/styles/user-profile.css
git commit -m "Add user profile frontend components and styling"J'utilise git show --name-only HEAD pour identifier les fichiers modifiés dans le commit volumineux, puis git reset --soft HEAD~1. Cette commande annule la validation tout en conservant les modifications préparées. L'exécution de la commande « git reset » (sans options) désactive tout. Je suis désormais en mesure de créer des commits ciblés : d'abord le modèle, puis les points de terminaison API, ensuite les tests, et enfin les composants frontend. Cette approche permet de transformer un engagement important en éléments logiques et vérifiables.
La transformation qui en résulte est remarquable. Au lieu que les réviseurs aient à comprendre un commit volumineux qui touche à plusieurs aspects, ils peuvent examiner chaque élément logique séparément. Cela permet d'obtenir un meilleur retour d'information, des révisions plus rapides et une réduction du nombre de bogues qui parviennent jusqu'à la production.
J'ai remarqué que lorsque je prends le temps de diviser correctement les commits, les réviseurs sont plus susceptibles de détecter les problèmes subtils, car ils peuvent se concentrer sur un seul point à la fois plutôt que d'être submergés par un ensemble de modifications important.
Les workflows Git professionnels nécessitent des pratiques rigoureuses afin d'éviter toute perte de données et de maintenir la productivité de l'équipe. Ces directives reflètent les enseignements tirés de nombreuses années de gestion de projets complexes et, il faut le reconnaître, de quelques erreurs coûteuses commises en cours de route.
Avant d'effectuer toute opération de réinitialisation, je mets toujours en place des mesures de sécurité permettant de corriger les erreurs. Cette habitude s'est développée après un incident particulièrement pénible au début de ma carrière, au cours duquel j'ai perdu plusieurs heures de travail.
git branch backup-before-reset-$(date +%Y%m%d-%H%M%S)
git reset --soft HEAD~3
git reset --hard backup-before-reset-20250905-182003Je crée systématiquement une branche de sauvegarde avant d'effectuer des opérations risquées à l'aide de git branch backup-before-reset-$(date +%Y%m%d-%H%M%S). Cette commande crée un filet de sécurité horodaté. Si un problème survient après mes opérations de réinitialisation, je peux récupérer mes données à l'adresse git reset --hard backup-before-reset-20250905-182003.
git status
git log --oneline -10
git diff --stagedAprès les opérations de réinitialisation, je vérifie l'ensemble à l'aide de git status pour contrôler la mise en scène, git log --oneline -10 pour examiner l'historique des validations, et git diff --staged. Cette dernière commande indique précisément ce qui sera inclus dans mon prochain commit.
La règle la plus importante que je respecte : ne jamais effectuer d'opérations de réinitialisation sur des commits qui ont été partagés avec d'autres personnes, sauf si j'ai obtenu l'accord explicite de mon équipe. Cette règle a permis d'éviter de nombreux conflits et de maintenir la confiance au sein de l'équipe.
Une technique que j'ai développée consiste à utiliser des noms de branches descriptifs qui indiquent l'état d'avancement du travail. Par exemple, feature/user-auth-wip indique clairement aux membres de l'équipe que l'historique de cette branche est susceptible de changer.
La réinitialisation logicielle gère les fichiers suivis de manière efficace, mais certaines subtilités peuvent poser des difficultés aux développeurs. La compréhension de ces limites m'a permis d'éviter toute confusion et tout comportement inattendu.
git reset --soft HEAD~2
git status
git add .Lorsque j'utilise git reset --soft HEAD~2, l'exécution de git status indique que tout est prêt. Cette commande annule deux validations tout en conservant les modifications préparées. Je peux ensuite utiliser git add . pour mettre en attente toute modification supplémentaire avant de tout valider à nouveau.
La réécriture de l'historique par des opérations de réinitialisation peut semer la confusion chez les collaborateurs et perturber les flux de travail partagés. J'ai appris à établir des protocoles d'équipe concernant le moment et la manière d'utiliser la réinitialisation sur les branches partagées. Dans mon équipe actuelle, nous avons une règle : il est interdit de modifier l'historique de la branche principale ou de toute autre branche sur laquelle un autre développeur a basé son travail.
Une erreur que je constate chez certains développeurs consiste à utiliser la réinitialisation logicielle sur des commits qui ont été fusionnés dans d'autres branches. Cela crée des historiques divergents difficiles à concilier et peut entraîner l'apparition multiple des mêmes modifications dans l'historique du projet.
J'ai également appris à faire preuve de prudence lors de la réinitialisation des commits contenant des résolutions de conflits de fusion. Les informations relatives à la résolution de fusion sont perdues lors de la réinitialisation. Si vous devez procéder à une nouvelle fusion, vous devrez résoudre les mêmes conflits.
Communiquer les modifications apportées à l'historique permet d'éviter les conflits au sein de l'équipe et de maintenir la stabilité du projet. J'ai élaboré un protocole de communication qui a été très utile à mes équipes au fil des ans.
git checkout -b feature/user-auth-history-cleanup
git reset --soft HEAD~4
git commit -m "Implement user authentication system"
git push origin feature/user-auth-history-cleanupJe travaille sur des branches de fonctionnalités clairement nommées, telles que git checkout -b feature/user-auth-history-cleanup. Cette commande crée une branche qui signale les modifications apportées à l'historique. Après avoir effectué des opérations de réinitialisation telles que git reset --soft HEAD~4, je publie la version nettoyée et crée une demande d'extraction avec un historique organisé.
git push --force-with-lease origin feature-branchLorsque la force est nécessaire, j'utilise git push --force-with-lease. Cette commande effectue un push en toute sécurité tout en s'assurant que personne d'autre n'a mis à jour la branche.
Je m'efforce également de documenter tout changement historique majeur dans les descriptions des demandes d'extraction. Par exemple : Remarque : L'historique de cette branche a été nettoyé à l'aide de git reset --soft afin de regrouper 5 commits incrémentiels en 2 commits logiques pour faciliter la révision.
La communication est essentielle. Je m'assure toujours d'informer les membres de l'équipe avant de réécrire l'historique sur toute branche à laquelle ils pourraient avoir accès, et je fournis des hachages clairs avant/après la validation afin qu'ils puissent comprendre les modifications apportées.
Même les développeurs expérimentés rencontrent des situations où les opérations de réinitialisation ne se déroulent pas comme prévu. La compréhension des techniques de récupération renforce la confiance dans l'utilisation des fonctionnalités avancées de Git et apporte une tranquillité d'esprit lorsque l'on travaille avec des historiques complexes.
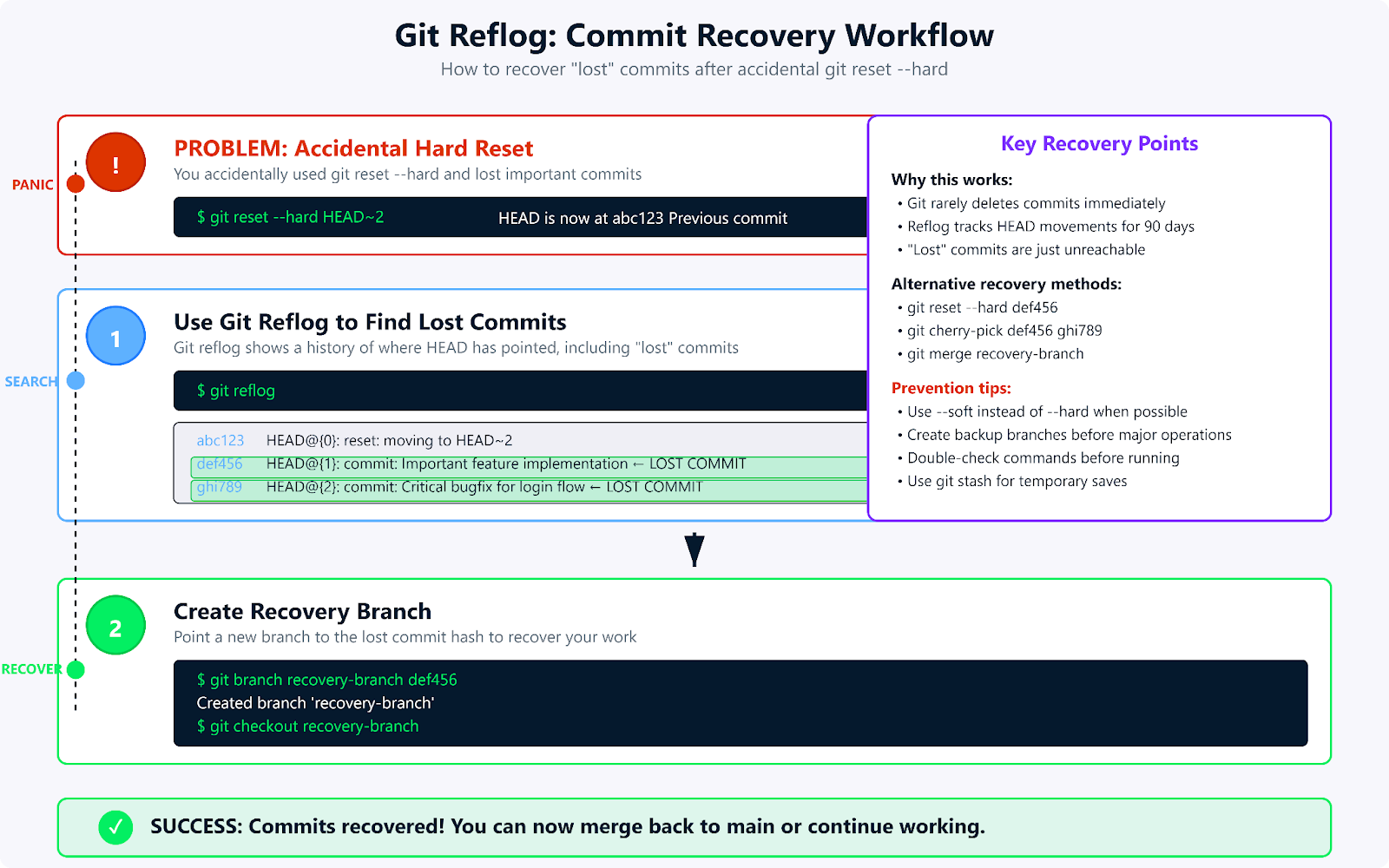
Un diagramme de flux de travail illustrant comment git reflog récupère les commits perdus après une réinitialisation complète.
Bien que cette section se concentre sur la récupération après une réinitialisation matérielle, la compréhension des principes s'applique à toutes les opérations de réinitialisation. Git et son reflog conserve un historique des emplacements vers lesquels HEAD a pointé, ce qui permet de récupérer des commits apparemment perdus.
git reflog
git reset --hard def5678
git branch recovery-branch def5678
git checkout recovery-branchLe reflog de Git suit les cursus de HEAD, ce qui permet la récupération des commits. J'exécute la commande « git reflog » pour consulter l'historique, identifier la validation que je souhaite récupérer, puis j'utilise soit « git reset --hard def5678 ». Cette commande effectue une restauration directe, ou je peux utiliser la commande plus sécurisée « git branch recovery-branch def5678 » suivie de «git checkout recovery-branch » pour examiner d'abord la récupération.
Le reflog m'a aidé à de nombreuses reprises. Je me souviens d'un incident particulièrement stressant où j'ai accidentellement utilisé git reset --hard au lieu de git reset --soft et où j'ai cru avoir perdu une journée entière de travail. Le reflog m'a permis de localiser précisément où mon travail avait été enregistré, et en quelques minutes, j'ai pu tout récupérer.
Le reflog offre une sécurité importante, mais il est essentiel de connaître sa durée de validité. Git conserve deux dates d'expiration distinctes pour ces enregistrements :
git reset --hard sont conservées pendant 30 jours par défaut.Dans un scénario de récupération tel que celui-ci, vous pouvez compter sur environ un mois pour récupérer votre travail. Cependant, cela ne fonctionne que pour les commits qui faisaient partie de l'historique de votre dépôt local. Si vous n'avez jamais effectué de modifications localement, même le reflog ne pourra pas vous aider.
Une technique que j'utilise lorsque je m'apprête à effectuer des opérations risquées consiste à effectuer d'abord un commit temporaire, même si le travail n'est pas prêt. Je peux toujours le réinitialiser ultérieurement, mais le fait de l'avoir dans le journal de référence offre une sécurité supplémentaire.
Lorsque les commits ont été poussés vers des dépôts distants, le processus de récupération devient plus complexe et nécessite une coordination de l'équipe. Cette situation nécessite une réflexion approfondie sur l'impact que cela pourrait avoir sur les autres membres de l'équipe.
git reset --soft HEAD~1
git commit -m "Corrected implementation with proper error handling"
git push --force-with-lease origin main
git revert abc1234
git push origin mainPour les commits qui n'ont pas encore été récupérés par d'autres, j'utilise git reset --soft HEAD~1. Cette commande annule la validation tout en conservant les modifications préparées. Je crée ensuite une validation corrigée et la transmets avec --force-with-lease. Pour les commits largement distribués, il est plus prudent d'utiliser l'option « git revert abc1234 » suivie d'un push normal, car cela ne perturbe pas le travail des autres développeurs.
J'ai compris l'importance de cette distinction lors d'un projet où j'ai forcé la réécriture de l'historique dans une branche partagée sur laquelle trois autres développeurs avaient déjà basé leur travail. Les conflits de fusion et la confusion qui en ont résulté ont nécessité une demi-journée pour être résolus et m'ont appris à être beaucoup plus prudent lorsque je réécris l'historique partagé.
La poussée forcée vers des branches partagées doit être envisagée en dernier recours et nécessite une communication explicite au sein de l'équipe. Dans la plupart des cas, git revert offre une alternative plus sûre en créant de nouveaux commits qui annulent les modifications précédentes plutôt que de réécrire l'historique.
La maîtrise de la commande ` git reset --soft ` vous permet de gérer les commits avec précision tout en conservant votre travail intact. Il est idéal pour nettoyer les commits, améliorer les messages de commit ou préparer un historique soigné pour la collaboration, le tout sans perdre les progrès réalisés.
Pour approfondir vos compétences, veuillez explorer le contrôle de version avec Git. le contrôle de version avec Git ou les concepts GitHub .
Meilleurs cours DataCamp
Cursus
Cursus
Cours
Tutoriel
Aditya Sharma
Tutoriel
Moez Ali
Tutoriel
Mark Pedigo
Tutoriel
Satyabrata Pal
Tutoriel
Allan Ouko
