
Cours
Ingénierie des prompts avec l'API OpenAI
4 h
47.9K
GPT-5.2 est un modèle performant pour générer des workflows et des pipelines multi-étapes qui exigent fiabilité, structure et moins d’hallucinations. OpenAI met en avant des progrès sur les tâches à long contexte et une meilleure performance sur les tâches de type feuille de calcul.
Dans ce tutoriel, nous allons construire une application Streamlit qui se comporte comme un analyste junior :
L’essentiel ici est que GPT-5.2 ne “fait” pas directement les slides. Il génère un plan strict que votre code exécute de manière déterministe.
Lisez aussi nos guides sur les modèles récents d’OpenAI, GPT-5.5, GPT-5.4, GPT-5.3 Codex et GPT-5.3 Instant
GPT-5.2 est le nouveau modèle de la série GPT-5 d’OpenAI, avec des améliorations pour les tâches de bout en bout comme la création de feuilles de calcul, la réalisation de présentations, l’écriture et le débogage de code, la compréhension de longs contextes et l’utilisation d’outils.
Voici les propriétés de GPT-5.2 les plus pertinentes pour ce projet :
Dans cette section, nous allons créer un générateur d’artefacts structurés (Excel et PowerPoint) en utilisant le modèle GPT-5.2 encapsulé dans une application Streamlit. À haut niveau, l’application Streamlit finale réalise :
Lecture du CSV et création d’un classeur canonique
Appel de GPT-5.2 via OpenAI ou OpenRouter avec Structured Outputs (response_format: json_schema)
Validation du plan retourné par rapport à notre schéma
Rendu des graphiques dans Excel et application du style selon notre palette de marque
Génération finale d’un PowerPoint avec graphiques intégrés et citations
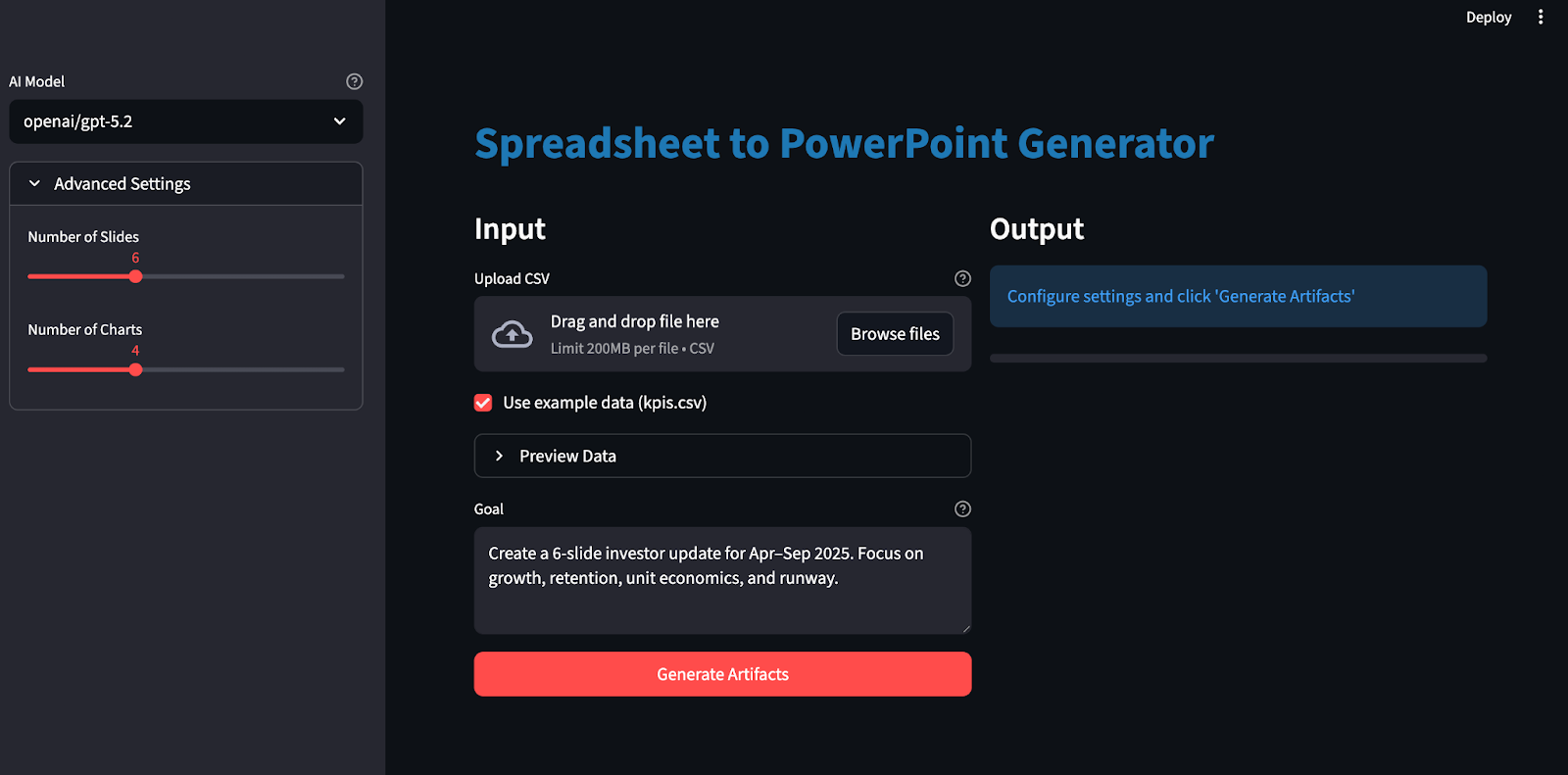
Construisons-le pas à pas.
Avant de générer des classeurs Excel et des decks PowerPoint avec GPT-5.2, nous devons configurer un environnement local. Nous allons commencer par installer les bibliothèques clés et définir les clés API comme variables d’environnement.
pip install streamlit pandas pydantic python-dotenv requests openpyxl python-pptxNous utiliserons Streamlit pour construire l’interface web interactive, Pandas pour charger et préparer le CSV, Pydantic pour valider le plan JSON verrouillé par schéma de GPT-5.2. Nous utilisons aussi python-dotenv pour charger en toute sécurité des clés comme OPENROUTER_API_KEY/OPENAI_API_KEY depuis un fichier .env. La bibliothèque requests appelle l’endpoint compatible OpenRouter/OpenAI, tandis que openpyxl génère le classeur et les graphiques Excel, et python-pptx crée le deck PowerPoint avec des graphiques natifs (éditables).
Ensuite, définissons nos clés API :
export OPENAI_API_KEY="your_key"
export OPENROUTER_API_KEY="your_key"Notez que GPT-5.2 est accessible via plusieurs services, notamment l’API officielle d’OpenAI ainsi que des services comme OpenRouter, et d’autres.
Il est recommandé d’utiliser un fichier .env pour stocker localement les clés API :
Dans le fichier .env, enregistrez les éléments suivants :
OPENROUTER_API_KEY="your_key"
OPENAI_API_KEY="your_key"Puis chargez ces clés API avec la bibliothèque load_dotenv :
from dotenv import load_dotenv
load_dotenv()À ce stade, notre environnement est prêt à s’authentifier auprès de l’API OpenAI.
Ensuite, nous définissons un plan d’artefact verrouillé par schéma, sous forme d’un blueprint JSON strict qui indique à GPT-5.2 exactement quels graphiques créer et comment structurer les diapositives, afin que la sortie du modèle puisse être décodée et validée avec Structured Outputs via response_format: { type: "json_schema", strict: true } plutôt que du texte libre.
import os
import io
import re
import json
import math
import tempfile
from dataclasses import dataclass
from pathlib import Path
from typing import Dict, List, Literal, Optional, Tuple
import requests
import pandas as pd
import numpy as np
import streamlit as st
import openpyxl
from dotenv import load_dotenv
from pydantic import BaseModel, Field, ValidationError
from openpyxl import Workbook, load_workbook
from openpyxl.styles import Font, Alignment, PatternFill
from openpyxl.utils import get_column_letter
from openpyxl.chart import LineChart, BarChart, Reference
from openpyxl.chart.series import SeriesLabel
from pptx import Presentation
from pptx.util import Inches, Pt
from pptx.chart.data import CategoryChartData
from pptx.enum.chart import XL_CHART_TYPE, XL_LEGEND_POSITION
ChartKind = Literal["line", "bar"]
def safe_float(x) -> float:
try:
if x is None:
return 0.0
if isinstance(x, (int, float)):
return float(x)
return float(str(x).replace(",", "").replace("$", ""))
except Exception:
return 0.0
def fmt_money(v: float) -> str:
sign = "-" if v < 0 else ""
v = abs(v)
if v >= 1_000_000:
return f"{sign}${v/1_000_000:.2f}M"
if v >= 1_000:
return f"{sign}${v/1_000:.1f}K"
return f"{sign}${v:.0f}"
def fmt_pct(v: float) -> str:
if v is None or (isinstance(v, float) and (math.isnan(v) or math.isinf(v))):
return "n/a"
return f"{v*100:.1f}%"
class ChartSeriesSpec(BaseModel):
name: str
metric: str
class ChartSpec(BaseModel):
id: str
kind: ChartKind
title: str
x_metric: str
series: List[ChartSeriesSpec]
anchor: str
class SlideBullet(BaseModel):
text: str
citations: List[str] = Field(min_length=1, max_length=4)
class SlideSpec(BaseModel):
title: str
chart_id: Optional[str] = None
bullets: List[SlideBullet] = Field(min_length=2, max_length=4)
class ArtifactPlan(BaseModel):
charts: List[ChartSpec] = Field(min_length=3, max_length=6)
slides: List[SlideSpec] = Field(min_length=4, max_length=10)Le code ci-dessus définit le plan avec des modèles Pydantic, qui assurent trois points essentiels :
Structure du plan : ChartKind = Literal["line", "bar"] restreint les types de graphiques à un petit enum, ChartSpec capture le contrat complet d’un graphique, et SlideSpec définit la mise en page d’une diapositive en la liant éventuellement à un graphique via chart_id.
Garantie de qualité automatique : des contraintes comme Field() assurent que nous avons toujours assez de graphiques/diapositives, que chaque diapositive comporte suffisamment de puces, et que chaque puce inclut des citations.
Planification et rendu : GPT-5.2 ne produit que le blueprint — graphiques, diapositives et citations — sous forme de JSON structuré, tandis que le reste du code gère l’exécution, le formatage Excel, le rendu des graphiques et la mise en page du deck.
Avec ce schéma en place, GPT-5.2 devient un planificateur qui produit un blueprint JSON validé.
Une fois le schéma du plan défini, la prochaine étape consiste à appeler GPT-5.2 en “mode schéma”, afin qu’il renvoie un blueprint JSON que vous pouvez valider et exécuter. Plutôt que d’espérer que le modèle “se comporte bien”, nous demandons à l’API de décoder directement selon votre JSON Schema en utilisant response_format: { type: "json_schema", ... strict: true }, ce à quoi servent précisément les Structured Outputs.
def chat_json_schema(
model: str,
messages: list,
json_schema: dict,
api_key: str,
temperature: float = 0.2,
max_tokens: int = 6000,
timeout_s: int = 120,
api_provider: Optional[str] = None,
) -> dict:
if api_provider is None:
if "/" in model:
api_provider = "openrouter"
elif os.getenv("OPENAI_API_KEY") and api_key == os.getenv("OPENAI_API_KEY"):
api_provider = "openai"
elif os.getenv("OPENROUTER_API_KEY") and api_key == os.getenv("OPENROUTER_API_KEY"):
api_provider = "openrouter"
else:
api_provider = "openrouter"
if api_provider == "openai":
url = "https://api.openai.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
if "/" in model:
model = model.split("/", 1)[1]
else:
url = "https://openrouter.ai/api/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
if os.getenv("OPENROUTER_SITE_URL"):
headers["HTTP-Referer"] = os.getenv("OPENROUTER_SITE_URL")
if os.getenv("OPENROUTER_APP_NAME"):
headers["X-Title"] = os.getenv("OPENROUTER_APP_NAME")
payload = {
"model": model,
"messages": messages,
"temperature": temperature,
"max_tokens": max_tokens,
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "artifact_plan",
"strict": True,
"schema": json_schema,
},
},
}
r = requests.post(url, headers=headers, data=json.dumps(payload), timeout=timeout_s)
r.raise_for_status()
data = r.json()
if "error" in data:
provider_name = "OpenAI" if api_provider == "openai" else "OpenRouter"
raise RuntimeError(f"{provider_name} error: {data['error']}")
finish_reason = data["choices"][0].get("finish_reason")
if finish_reason == "length":
raise RuntimeError("Model output truncated (max_tokens). Increase max_tokens or reduce schema size.")
content = data["choices"][0]["message"]["content"]
if isinstance(content, dict):
return content
try:
return json.loads(content)
except json.JSONDecodeError as e:
preview = (content or "")[:800]
raise RuntimeError(f"Failed to parse JSON. Preview:\n{preview}") from eLa fonction chat_json_schema() est l’unique passerelle qui transforme des invites en un plan validé :
Routage de fournisseur (OpenRouter vs OpenAI) : si le nom du modèle est “namespacé” (openai/gpt-5.2), vous utilisez par défaut OpenRouter car c’est le format utilisé pour le routage de modèles. Si vous définissez explicitement api_provider="openai", vous envoyez la même charge utile Chat Completions à l’endpoint d’OpenAI. Vous pouvez tout à fait ignorer OpenRouter.
Configuration des endpoints : pour OpenAI, vous appelez https://api.openai.com/v1/chat/completions avec une authentification Bearer standard. Pour OpenRouter, vous appelez https://openrouter.ai/api/v1/chat/completions et incluez éventuellement des en-têtes d’attribution tels que HTTP-Referer et X-Title, comme recommandé par la documentation d’OpenRouter.
Décodage selon le response_format : le bloc clé de la charge utile est response_format: { type: "json_schema", json_schema: { strict: true, schema: ... } }, qui force le modèle à produire une sortie restreinte à notre JSON Schema.
Ensuite, nous validerons le plan JSON du modèle avec Pydantic et, seulement s’il passe les contrôles, nous procéderons au rendu des graphiques Excel et à la génération du deck PowerPoint.
Avant tout rendu, nous avons besoin d’une fine couche qui rende tout CSV téléversé analysable et cohérent. Ces fonctions utilitaires réalisent quatre tâches : charger et nettoyer le CSV, créer une table modèle dérivée, calculer un ensemble compact de faits pour l’invite, et rendre la sortie Excel lisible grâce à l’ajustement automatique des colonnes.
GPT-5.2 ne peut pas planifier de façon fiable des graphiques et des slides si la table d’entrée est vide ou si des champs numériques sont stockés comme chaînes. Cette fonction standardise le jeu de données pour que les étapes suivantes n’aient pas à deviner.
def load_and_validate_csv(csv_path: str) -> pd.DataFrame:
df = pd.read_csv(csv_path)
if len(df) == 0:
raise ValueError("CSV is empty")
if len(df.columns) == 0:
raise ValueError("CSV has no columns")
date_cols = [c for c in df.columns if any(x in c.lower() for x in ['date', 'time', 'month', 'year', 'period', 'week'])]
if date_cols:
date_col = date_cols[0]
df[date_col] = df[date_col].astype(str)
for col in df.columns:
if col not in date_cols:
try:
df[col] = pd.to_numeric(df[col])
if df[col].dtype in ['float64', 'int64']:
df[col] = df[col].fillna(0)
except (ValueError, TypeError):
pass
return dfLa fonction ci-dessus :
pd.read_csv.pd.to_numeric, et remplit les valeurs manquantes avec zéro pour éviter les cascades de NaN par la suite. À la fin de cette étape, vous disposez d’un DataFrame non vide avec des colonnes numériques.
Les CSV bruts sont hétérogènes selon les domaines. La feuille modèle agit comme une couche de normalisation où nous ajoutons des métriques dérivées utiles pour les graphiques, sans demander à l’utilisateur de les calculer manuellement.
def compute_model_df(raw_df: pd.DataFrame) -> pd.DataFrame:
df = raw_df.copy()
numeric_cols = df.select_dtypes(include=[np.number]).columns.tolist()
if "new_mrr" in df.columns and "churned_mrr" in df.columns:
df["net_new_mrr"] = df["new_mrr"] - df["churned_mrr"]
revenue_cols = [c for c in df.columns if any(x in c.lower() for x in ['revenue', 'mrr', 'income', 'sales'])]
cost_cols = [c for c in df.columns if any(x in c.lower() for x in ['cost', 'cogs', 'expense'])]
if revenue_cols and cost_cols:
revenue = df[revenue_cols[0]]
cost = df[cost_cols[0]]
df["gross_margin"] = ((revenue - cost) / revenue.replace(0, pd.NA)).fillna(0)
for col in numeric_cols[:5]:
if col not in df.columns:
continue
df[f"{col}_change"] = df[col].pct_change().fillna(0)
return dfLa fonction compute_model_df() effectue deux opérations largement utiles :
Elle recherche une colonne de sortie principale et une colonne d’entrée secondaire puis calcule un ratio simple pour mesurer la part du signal primaire après prise en compte du signal secondaire.
Pour quelques colonnes numériques, elle calcule pct_change(), qui renvoie par défaut la variation fractionnelle par rapport à la ligne précédente, ce qui sert de base pour capter l’évolution d’une métrique temporelle.
Même avec des sorties structurées, nous souhaitons fournir à GPT-5.2 un résumé compact des évolutions sur la période. Ces faits servent aussi d’amorce que le modèle peut réutiliser dans les puces des slides.
def compute_facts(model_df: pd.DataFrame) -> Dict[str, str]:
def delta(a: float, b: float) -> float:
return 0.0 if a == 0 else (b - a) / a
if len(model_df) == 0:
return {"error": "No data"}
first = model_df.iloc[0]
last = model_df.iloc[-1]
date_cols = [c for c in model_df.columns if any(x in c.lower() for x in ['date', 'time', 'month', 'year', 'period', 'week'])]
period_col = date_cols[0] if date_cols else model_df.columns[0]
facts = {
"period": f"{first[period_col]} → {last[period_col]}",
"row_count": len(model_df),
"column_count": len(model_df.columns),
}
numeric_cols = model_df.select_dtypes(include=[np.number]).columns.tolist()
for i, col in enumerate(numeric_cols[:5]):
if col in first.index and col in last.index:
start_val = safe_float(first[col])
end_val = safe_float(last[col])
avg_val = safe_float(model_df[col].mean())
facts[f"{col}_start"] = fmt_money(start_val) if start_val >= 100 else f"{start_val:.2f}"
facts[f"{col}_end"] = fmt_money(end_val) if end_val >= 100 else f"{end_val:.2f}"
facts[f"{col}_change_pct"] = fmt_pct(delta(start_val, end_val))
facts[f"{col}_avg"] = fmt_money(avg_val) if avg_val >= 100 else f"{avg_val:.2f}"
return factsNous choisissons d’abord la première et la dernière ligne pour définir la fenêtre temporelle. Ensuite, nous sélectionnons une colonne (date, month, week, period) pour un reporting lisible.
Pour un petit ensemble de colonnes numériques, nous calculons un instantané de début, fin, moyenne et la variation en pourcentage sur la période. Cela produit un dictionnaire léger de signaux qui aide le modèle à rédiger les puces.
Les largeurs par défaut des colonnes Excel rendent les classeurs générés peu soignés. L’ajustement automatique est une simple retouche qui améliore immédiatement l’utilisabilité.
def autosize_columns(ws, max_width: int = 45):
for col in ws.columns:
max_len = 0
col_letter = get_column_letter(col[0].column)
for cell in col:
if cell.value is None:
continue
max_len = max(max_len, len(str(cell.value)))
ws.column_dimensions[col_letter].width = min(max_len + 2, max_width)La fonction autosize_columns() parcourt chaque colonne, trouve la longueur maximale de chaîne, et définit ws.column_dimensions[col_letter].width. La bibliothèque OpenPyXL expose column_dimensions et sa propriété width pour contrôler la largeur d’affichage dans Excel.
Ensuite, nous branchons la table modèle nettoyée et les faits dans l’invite de planification de GPT-5.2, validons le plan renvoyé, puis réalisons le rendu des graphiques et des slides.
À partir de la table modèle nettoyée et des faits synthétiques de l’étape précédente, nous générons maintenant un classeur Excel déterministe avec openpyxl.
def build_workbook_base(raw_df: pd.DataFrame, model_df: pd.DataFrame, out_xlsx: str) -> Tuple[str, int]:
wb = Workbook()
wb.remove(wb.active)
header_fill = PatternFill("solid", fgColor="F2F2F2")
header_font = Font(bold=True)
ws_raw = wb.create_sheet("Raw")
for j, col in enumerate(raw_df.columns, start=1):
c = ws_raw.cell(row=1, column=j, value=col)
c.font = header_font
c.fill = header_fill
c.alignment = Alignment(horizontal="center", vertical="center")
for i, row in enumerate(raw_df.itertuples(index=False), start=2):
for j, val in enumerate(row, start=1):
ws_raw.cell(row=i, column=j, value=val)
ws_raw.freeze_panes = "A2"
autosize_columns(ws_raw)
row_end = 1 + len(raw_df)
ws_model = wb.create_sheet("Model")
for j, col in enumerate(model_df.columns, start=1):
c = ws_model.cell(row=1, column=j, value=col)
c.font = header_font
c.fill = header_fill
c.alignment = Alignment(horizontal="center", vertical="center")
for i, row in enumerate(model_df.itertuples(index=False), start=2):
for j, val in enumerate(row, start=1):
ws_model.cell(row=i, column=j, value=val)
ws_model.freeze_panes = "A2"
autosize_columns(ws_model)
col_index = {name: idx + 1 for idx, name in enumerate(model_df.columns)}
money_keywords = ['mrr', 'revenue', 'income', 'sales', 'cost', 'expense', 'cash', 'balance', 'burn', 'price', 'amount', 'fee']
pct_keywords = ['margin', 'rate', 'ratio', 'pct', 'percent', 'change', 'growth']
for col_name, col_idx in col_index.items():
col_lower = col_name.lower()
is_money = any(kw in col_lower for kw in money_keywords)
is_pct = any(kw in col_lower for kw in pct_keywords) or 'margin' in col_lower
is_large_number = False
if col_name in model_df.columns:
sample_vals = model_df[col_name].dropna()
if len(sample_vals) > 0 and pd.api.types.is_numeric_dtype(sample_vals):
max_val = abs(sample_vals.max())
is_large_number = max_val > 1000
for r in range(2, row_end + 1):
if is_money or is_large_number:
ws_model.cell(row=r, column=col_idx).number_format = "$#,##0"
elif is_pct:
ws_model.cell(row=r, column=col_idx).number_format = "0.0%"
elif pd.api.types.is_numeric_dtype(model_df[col_name]):
ws_model.cell(row=r, column=col_idx).number_format = "0.0"
ws_charts = wb.create_sheet("Charts")
ws_charts["A1"] = "Charts"
ws_charts["A1"].font = Font(bold=True)
wb.save(out_xlsx)
return out_xlsx, row_endVoici ce que fait ce constructeur de classeur :
Créer l’ossature du classeur : Workbook() instancie un nouveau classeur, puis wb.remove(wb.active) supprime la feuille par défaut pour contrôler totalement l’ordre des feuilles. Les nouvelles feuilles sont ajoutées explicitement avec wb.create_sheet("Raw"), wb.create_sheet("Model") et wb.create_sheet("Charts").
Écrire la feuille Raw : nous écrivons une ligne d’en-tête avec Font, PatternFill et Alignment, puis ajoutons chaque ligne de raw_df. La fonction autosize_columns(ws_raw) améliore la lisibilité sans redimensionnement manuel.
Calculer les bornes : nous utilisons row_end = 1 + len(raw_df), ce qui donne une dernière ligne stable pour générer en toute sécurité des plages comme A2:A{row_end} pour les catégories de graphiques et les citations.
Appliquer des heuristiques de format numérique : nous définissons cell.number_format en fonction des mots-clés du nom de colonne et du dtype, pour qu’Excel affiche les valeurs en devise, pourcentage ou nombre simple.
Créer une feuille Charts : wb.create_sheet("Charts") nous fournit une zone d’ancrage stable pour les graphiques. Cela correspond au flux de travail openpyxl où l’on crée un LineChart ou BarChart, on lie les plages via Reference, on définit les catégories avec set_categories, puis on place le graphique avec ws.add_chart().
Après cette étape, vous avez un fichier Excel cohérent que l’étape suivante peut référencer précisément par plages de cellules.
Étape 6 : rendre les graphiques
Maintenant que la structure du classeur est fixée, nous pouvons rendre les graphiques dans la feuille Charts et appliquer une identité visuelle cohérente. J’ai appliqué la palette DataCamp :
def add_charts_to_workbook(xlsx_path: str, charts: List[ChartSpec], metric_to_range: Dict[str, str]):
wb = load_workbook(xlsx_path)
ws_model = wb["Model"]
ws_charts = wb["Charts"]
header_map = {ws_model.cell(1, c).value: c for c in range(1, ws_model.max_column + 1)}
def ref_from_metric(metric: str, row_start: int, row_end: int) -> Reference:
if metric not in header_map:
raise ValueError(f"Unknown metric in Model sheet: {metric}")
col = header_map[metric]
return Reference(ws_model, min_col=col, min_row=row_start, max_col=col, max_row=row_end)
for ch in charts:
chart = LineChart() if ch.kind == "line" else BarChart()
chart.title = ch.title
x_metric = ch.x_metric
if x_metric not in header_map:
date_keywords = ['date', 'time', 'month', 'year', 'period', 'week']
date_cols = [col for col in header_map.keys() if col and any(kw in str(col).lower() for kw in date_keywords)]
if date_cols:
x_metric = date_cols[0]
else:
x_metric = list(header_map.keys())[0] if header_map else "month"
x_ref = ref_from_metric(x_metric, 2, ws_model.max_row)
chart.set_categories(x_ref)
chart_colors = ["01EF63", "203147"]
for i, s in enumerate(ch.series):
y_ref = ref_from_metric(s.metric, 2, ws_model.max_row)
chart.add_data(y_ref, titles_from_data=False)
chart.series[-1].title = SeriesLabel(v=s.name)
series = chart.series[-1]
color_hex = chart_colors[i % len(chart_colors)]
try:
if ch.kind == "line":
series.graphicalProperties.line.solidFill = color_hex
series.graphicalProperties.line.width = 30000
else:
series.graphicalProperties.solidFill = color_hex
except AttributeError:
pass
anchor = ch.anchor.strip()
if "!" in anchor:
anchor = anchor.split("!")[-1]
if anchor and anchor.isalpha():
anchor = f"{anchor}2"
if not re.match(r'^[A-Z]+[0-9]+La fonction add_charts_to_workbook() est le moteur de rendu qui transforme notre plan en visuels Excel brandés.
Charger le classeur : nous ouvrons d’abord le fichier Excel généré avec load_workbook(xlsx_path). Ensuite, nous construisons une header_map depuis la première ligne, associant chaque nom de colonne à son index Excel.
Construire les références de plages : la fonction Reference() définit la plage exacte à tracer, et chart.set_categories(x_ref) alimente l’axe des abscisses. Le schéma standard consiste à créer des objets de référence, ajouter les données puis définir les catégories.
Instancier le type de graphique : pour chaque spec, nous créons un LineChart() ou un BarChart(), et définissons chart.title.
Appliquer la palette de marque : pour chaque série, nous lions la plage Y avec chart.add_data(), puis définissons le libellé d’affichage via SeriesLabel().
Enfin, la fonction ws_charts.add_chart() place chaque graphique à une cellule précise en haut à gauche.
C’est ici que le plan devient un vrai deck. Nous créons un PowerPoint, posons titres et puces, intégrons des graphiques construits à partir de la même table que pour Excel, et ajoutons un pied de page qui conserve les citations des plages de cellules du plan.
def build_pptx(out_pptx: str, model_df: pd.DataFrame, plan: ArtifactPlan):
prs = Presentation()
blank = prs.slide_layouts[6]
chart_by_id = {c.id: c for c in plan.charts}
def add_title(slide, title: str):
box = slide.shapes.add_textbox(Inches(0.5), Inches(0.2), Inches(9.0), Inches(0.6))
tf = box.text_frame
tf.clear()
p = tf.paragraphs[0]
p.text = title
p.font.size = Pt(32)
p.font.bold = True
def add_bullets(slide, bullets: List[SlideBullet], left, top, width, height):
box = slide.shapes.add_textbox(left, top, width, height)
tf = box.text_frame
tf.word_wrap = True
tf.clear()
for i, b in enumerate(bullets):
p = tf.paragraphs[0] if i == 0 else tf.add_paragraph()
p.text = b.text
p.font.size = Pt(18)
p.level = 0
p.space_before = Pt(4)
p.space_after = Pt(8)
def add_sources_footer(slide, bullets: List[SlideBullet]):
sources = []
seen = set()
for b in bullets:
for c in b.citations:
if c not in seen:
seen.add(c)
sources.append(c)
if not sources:
return
text = "Sources: " + "; ".join(sources)
box = slide.shapes.add_textbox(Inches(0.5), Inches(6.8), Inches(9.0), Inches(0.4))
tf = box.text_frame
tf.clear()
p = tf.paragraphs[0]
p.text = text
p.font.size = Pt(9)
p.font.italic = True
def add_chart(slide, chart_spec: ChartSpec, left, top, width, height):
date_cols = [c for c in model_df.columns if any(x in c.lower() for x in ['date', 'time', 'month', 'year', 'period', 'week'])]
x_col = date_cols[0] if date_cols else model_df.columns[0]
categories = model_df[x_col].astype(str).tolist()
chart_data = CategoryChartData()
chart_data.categories = categories
chart_colors = ["01EF63", "203147"]
for i, s in enumerate(chart_spec.series):
values = model_df[s.metric].apply(safe_float).tolist()
chart_data.add_series(s.name, values)
chart_type = XL_CHART_TYPE.LINE if chart_spec.kind == "line" else XL_CHART_TYPE.COLUMN_CLUSTERED
graphic_frame = slide.shapes.add_chart(chart_type, left, top, width, height, chart_data)
chart = graphic_frame.chart
chart.has_title = True
chart.chart_title.text_frame.text = chart_spec.title
chart.has_legend = True
chart.legend.position = XL_LEGEND_POSITION.BOTTOM
chart.legend.include_in_layout = False
from pptx.dml.color import RGBColor
for i, series in enumerate(chart.series):
color_hex = chart_colors[i % len(chart_colors)]
color_rgb = RGBColor(
int(color_hex[0:2], 16),
int(color_hex[2:4], 16),
int(color_hex[4:6], 16)
)
fill = series.format.fill
fill.solid()
fill.fore_color.rgb = color_rgb
if chart_spec.kind == "line":
line = series.format.line
line.color.rgb = color_rgb
line.width = Pt(3)
for s in plan.slides:
slide = prs.slides.add_slide(blank)
add_title(slide, s.title)
has_chart = bool(s.chart_id and s.chart_id in chart_by_id)
if has_chart:
add_bullets(
slide,
s.bullets,
left=Inches(0.5),
top=Inches(1.0),
width=Inches(4.5),
height=Inches(5.5),
)
add_chart(
slide,
chart_by_id[s.chart_id],
left=Inches(5.2),
top=Inches(1.0),
width=Inches(4.5),
height=Inches(5.5),
)
else:
add_bullets(
slide,
s.bullets,
left=Inches(0.5),
top=Inches(1.0),
width=Inches(9.0),
height=Inches(5.5),
)
add_sources_footer(slide, s.bullets)
prs.save(out_pptx)
def build_allowed_ranges(model_df: pd.DataFrame, row_end: int) -> Dict[str, str]:
ranges = {}
for i, col in enumerate(model_df.columns, start=1):
col_letter = get_column_letter(i)
ranges[col] = f"Model!{col_letter}2:{col_letter}{row_end}"
return ranges
def validate_plan(plan: ArtifactPlan, allowed_ranges: Dict[str, str]) -> None:
allowed_set = set(allowed_ranges.values())
chart_ids = {c.id for c in plan.charts}
if len(chart_ids) != len(plan.charts):
raise ValueError("Duplicate chart ids in plan.")
for s in plan.slides:
if s.chart_id and s.chart_id not in chart_ids:
raise ValueError(f"Slide references unknown chart_id: {s.chart_id}")
for s in plan.slides:
for b in s.bullets:
for c in b.citations:
if c not in allowed_set:
raise ValueError(f"Citation not in allowed set: {c}")
allowed_metrics = set(allowed_ranges.keys())
for c in plan.charts:
if c.x_metric not in allowed_metrics:
pass
for s in c.series:
if s.metric not in allowed_metrics:
raise ValueError(f"Unknown series metric: {s.metric}")Comprenons le code ci-dessus étape par étape :
Créer le deck et indexer les graphiques : prs = Presentation() démarre un nouveau PPTX, tandis que blank = prs.slide_layouts[6] offre un canevas vierge pour un placement précis.
Titres et puces : la fonction add_title() écrit dans une zone de texte text_frame, et add_bullets() ajoute un paragraphe par puce en contrôlant taille de police et espacements.
Pied de page des sources : add_sources_footer() déduplique les citations à travers les puces et rend une ligne Sources : compacte en bas, pour conserver la traçabilité sans surcharger la diapositive.
Intégrer des graphiques : add_chart() construit un CategoryChartData() avec une colonne de type temporel en X et les séries planifiées, puis insère le tout via slide.shapes.add_chart(), qui renvoie un GraphicFrame.
Style de marque : enfin, nous convertissons l’hex en RGBColor et l’appliquons par série.
Règles de mise en page et garde-fous : si une diapositive a un chart_id valide, nous utilisons une mise en page deux colonnes, sinon des puces pleine largeur. La fonction build_allowed_ranges() crée la liste autorisée des plages citables, et validate_plan() impose l’unicité des IDs, des références valides, des citations autorisées et des métriques permises pour éviter toute invention par le modèle.
À ce stade, nous disposons de données tabulaires propres, que nous allons transformer en un plan de construction (graphiques, diapositives, citations) exécutable par le moteur de rendu.
def generate_plan_with_llm(
api_key: str,
model: str,
goal: str,
allowed_ranges: Dict[str, str],
facts: Dict[str, str],
num_slides: int = 6,
num_charts: int = 4,
) -> ArtifactPlan:
plan_schema = {
"type": "object",
"properties": {
"charts": {
"type": "array",
"minItems": 3,
"maxItems": 6,
"items": {
"type": "object",
"properties": {
"id": {"type": "string"},
"kind": {"type": "string", "enum": ["line", "bar"]},
"title": {"type": "string"},
"x_metric": {"type": "string"},
"series": {
"type": "array",
"minItems": 1,
"maxItems": 3,
"items": {
"type": "object",
"properties": {
"name": {"type": "string"},
"metric": {"type": "string"},
},
"required": ["name", "metric"],
"additionalProperties": False,
},
},
"anchor": {"type": "string"},
},
"required": ["id", "kind", "title", "x_metric", "series", "anchor"],
"additionalProperties": False,
},
},
"slides": {
"type": "array",
"minItems": 4,
"maxItems": 10,
"items": {
"type": "object",
"properties": {
"title": {"type": "string"},
"chart_id": {"type": ["string", "null"]},
"bullets": {
"type": "array",
"minItems": 2,
"maxItems": 4,
"items": {
"type": "object",
"properties": {
"text": {"type": "string"},
"citations": {
"type": "array",
"minItems": 1,
"maxItems": 4,
"items": {"type": "string"},
},
},
"required": ["text", "citations"],
"additionalProperties": False,
},
},
},
"required": ["title", "chart_id", "bullets"],
"additionalProperties": False,
},
},
},
"required": ["charts", "slides"],
"additionalProperties": False,
}
system = (
"You produce investor-grade slides with traceability.\n"
"Output MUST match the JSON schema exactly.\n"
"Rules:\n"
"1) Use ONLY the allowed citation ranges (exact strings).\n"
"2) No generic filler. Every bullet must contain at least ONE number (e.g., $X, X%, X mo).\n"
"3) Keep bullets short: <= 12 words.\n"
"4) Prefer trends (start→end) or averages; avoid speculation.\n"
"5) Provide exactly the requested number of charts and slides.\n"
"6) Use chart_id to attach the correct chart to each slide.\n"
"7) Chart anchors: Use cell references ONLY (e.g., 'A2', 'A20', 'A38'). Do NOT include sheet name like 'CHARTS!A'.\n"
)
user = (
f"Goal: {goal}\n"
f"Requested: {num_charts} charts and {num_slides} slides.\n\n"
f"Facts (use these; do not invent):\n{json.dumps(facts, indent=2)}\n\n"
f"Allowed citation ranges (use exact values only):\n{json.dumps(list(allowed_ranges.values()), indent=2)}\n\n"
"Metric keys available for charts:\n"
f"{json.dumps(list(allowed_ranges.keys()), indent=2)}\n\n"
"Chart requirements:\n"
"- x_metric: Use a date/time column (e.g., 'month', 'date', 'period', 'week') for the X-axis.\n"
" If no date column exists, use the first column from the available metrics.\n"
"- Create meaningful charts based on available metrics in the data.\n"
"- Focus on trends, comparisons, and key business metrics.\n"
"- Chart colors: Use these specific shades for all chart series:\n"
" * Primary color: #01ef63 (bright green)\n"
" * Secondary color: #203147 (dark blue/navy)\n"
" * Alternate between these two colors for multiple series in the same chart.\n"
"Slide requirements:\n"
"- Create slides that tell a story with the available data.\n"
"- Suggested structure: Overview, Key Metrics, Trends, Analysis, Summary, Next Steps.\n"
"- Adapt slide titles and content to match the data domain (e.g., sales, marketing, operations, finance).\n"
)
messages = [{"role": "system", "content": system}, {"role": "user", "content": user}]
plan_json = chat_json_schema(
model=model,
messages=messages,
json_schema=plan_schema,
api_key=api_key,
temperature=0.2,
max_tokens=6000,
)
try:
plan = ArtifactPlan.model_validate(plan_json)
validate_plan(plan, allowed_ranges)
if len(plan.slides) != num_slides:
raise ValueError(f"Expected {num_slides} slides, got {len(plan.slides)}")
if len(plan.charts) != num_charts:
raise ValueError(f"Expected {num_charts} charts, got {len(plan.charts)}")
return plan
except (ValidationError, ValueError) as e:
repair = messages + [
{"role": "assistant", "content": json.dumps(plan_json)},
{"role": "user", "content": f"Fix JSON to satisfy schema + rules. Error:\n{str(e)}"},
]
plan_json = chat_json_schema(
model=model,
messages=repair,
json_schema=plan_schema,
api_key=api_key,
temperature=0.0,
max_tokens=6000,
)
plan = ArtifactPlan.model_validate(plan_json)
validate_plan(plan, allowed_ranges)
if len(plan.slides) != num_slides or len(plan.charts) != num_charts:
raise RuntimeError("Plan repaired but counts still wrong. Tighten prompt or increase max_tokens.")
return planLa fonction generate_plan_with_llm() est le cerveau de cette démo. Voici comment nous l’intégrons au pipeline :
JSON Schema explicite : plan_schema définit l’unique forme de réponse autorisée, charts[] et slides[], avec champs requis et enums.
Garde-fous dans le prompt système : nous imposons des non-négociables pour garantir un plan restituable et traçable. Nous limitons aussi le placement des graphiques à des cellules simples, afin que la mise en page reste déterministe et non improvisée. C’est exactement le type de contrôle multi-étapes que GPT-5.2 gère bien.
Message utilisateur : il fournit l’objectif, les volumes demandés, les faits calculés et les clés de métriques autorisées. Comme le modèle ne voit rien d’autre, il a beaucoup moins d’occasions d’inventer des colonnes, des plages ou des affirmations non supportées.
Décodage conforme au schéma : nous appelons chat_json_schema() avec response_format défini à json_schema et strict: true, ce qui impose le respect du schéma lors du décodage.
Validation en deux couches : d’abord ArtifactPlan.model_validate(plan_json) confirme la conformité aux modèles Pydantic. Ensuite, validate_plan() applique des contraintes métiers.
Enfin, nous chaînons le chargement du CSV, la génération Excel, la planification LLM, le rendu des graphiques et l’export PPTX final, puis renvoyons les chemins de sortie.
@dataclass
class RunOutputs:
xlsx_path: str
pptx_path: str
plan_path: str
logs: str
def run_pipeline(csv_path: str, goal: str, outdir: str, model: str, num_slides: int, num_charts: int) -> RunOutputs:
load_dotenv()
openai_key = os.getenv("OPENAI_API_KEY")
openrouter_key = os.getenv("OPENROUTER_API_KEY")
if "/" in model or openrouter_key:
api_key = openrouter_key
if not api_key:
raise RuntimeError("Missing OPENROUTER_API_KEY (required for OpenRouter models)")
elif openai_key:
api_key = openai_key
else:
raise RuntimeError("Missing API key. Set either OPENAI_API_KEY or OPENROUTER_API_KEY")
out = Path(outdir)
out.mkdir(parents=True, exist_ok=True)
xlsx_path = str(out / "investor_update.xlsx")
pptx_path = str(out / "investor_update.pptx")
plan_path = str(out / "plan.json")
raw_df = load_and_validate_csv(csv_path)
model_df = compute_model_df(raw_df)
xlsx_path, row_end = build_workbook_base(raw_df, model_df, xlsx_path)
allowed_ranges = build_allowed_ranges(model_df, row_end)
facts = compute_facts(model_df)
plan = generate_plan_with_llm(
api_key=api_key,
model=model,
goal=goal,
allowed_ranges=allowed_ranges,
facts=facts,
num_slides=num_slides,
num_charts=num_charts,
)
with open(plan_path, "w", encoding="utf-8") as f:
json.dump(plan.model_dump(), f, indent=2)
add_charts_to_workbook(xlsx_path, plan.charts, allowed_ranges)
build_pptx(pptx_path, model_df, plan)
logs = (
f"CSV rows: {len(raw_df)}\n"
f"Excel: {xlsx_path}\n"
f"PPTX: {pptx_path}\n"
f"Plan: {plan_path}\n"
f"Facts used: {facts}\n"
)
return RunOutputs(xlsx_path=xlsx_path, pptx_path=pptx_path, plan_path=plan_path, logs=logs)Assemblons pas à pas tous les composants de notre pipeline :
@dataclass crée un conteneur léger pour xlsx_path, pptx_path, plan_path et logs, pour que l’UI Streamlit traite le résultat comme une valeur structurée unique plutôt que de jongler avec des tuples ou des variables globales.load_dotenv() charge notre fichier .env dans les variables d’environnement afin que OPENAI_API_KEY et OPENROUTER_API_KEY soient lisibles via os.getenv(). Nous choisissons ensuite la clé du fournisseur via une règle simple : si OPENROUTER_API_KEY existe, utiliser OpenRouter ; sinon, basculer vers OpenAI si disponible.build_workbook_base(). La fonction generate_plan_with_llm() renvoie ensuite un ArtifactPlan qui est enregistré en JSON avec json.dump() pour faciliter l’inspection et le debug.build_pptx() construit le deck à partir du plan et de la table.Après cette étape, notre application Streamlit peut appeler run_pipeline(), afficher les logs et proposer trois sorties déterministes au téléchargement : le classeur Excel, le deck PPTX et le plan JSON.
Maintenant que le pipeline principal est prêt, l’ultime étape consiste à l’encapsuler dans une application Streamlit pour que chacun puisse téléverser un fichier, définir un objectif, choisir un modèle et télécharger les artefacts générés.
load_dotenv()
st.set_page_config(
page_title="GPT-5.2 PPT and Excel Generator",
page_icon="",
layout="wide",
initial_sidebar_state="expanded"
)
st.markdown("""
<style>
.main-header {
font-size: 2.5rem;
font-weight: 700;
color: #1f77b4;
margin-bottom: 1rem;
}
.sub-header {
font-size: 1.2rem;
color: #666;
margin-bottom: 2rem;
}
.success-box {
padding: 1rem;
background-color: #d4edda;
border-left: 4px solid #28a745;
margin: 1rem 0;
}
.error-box {
padding: 1rem;
background-color: #f8d7da;
border-left: 4px solid #dc3545;
margin: 1rem 0;
}
.info-box {
padding: 1rem;
background-color: #d1ecf1;
border-left: 4px solid #17a2b8;
margin: 1rem 0;
}
.slide-preview {
border: 2px solid #ddd;
border-radius: 8px;
padding: 10px;
margin: 10px 0;
background: white;
box-shadow: 0 2px 4px rgba(0,0,0,0.1);
}
</style>
""", unsafe_allow_html=True)
def main():
try:
if 'outputs' not in st.session_state:
st.session_state.outputs = None
if 'generated' not in st.session_state:
st.session_state.generated = False
st.markdown('<div class="main-header">Spreadsheet to PowerPoint Generator</div>', unsafe_allow_html=True)
with st.sidebar:
# API Provider selection
api_provider = st.selectbox(
"API Provider",
["OpenAI", "OpenRouter"],
help="Select which API to use. Make sure the corresponding API key is set in your .env file"
)
# Model selection based on provider
if api_provider == "OpenAI":
model = st.selectbox(
"AI Model",
[
"gpt-4o",
"gpt-4-turbo",
"gpt-4",
"gpt-3.5-turbo",
],
help="OpenAI models. Requires OPENAI_API_KEY in .env file"
)
else: # OpenRouter
model = st.selectbox(
"AI Model",
[
"openai/gpt-5.2",
"openai/gpt-4-turbo",
"openai/gpt-4o",
"anthropic/claude-3-opus",
"anthropic/claude-3-sonnet",
],
help="OpenRouter models. Requires OPENROUTER_API_KEY in .env file"
)
with st.expander("Advanced Settings"):
num_slides = st.slider("Number of Slides", 4, 10, 6)
num_charts = st.slider("Number of Charts", 3, 6, 4)
col1, col2 = st.columns([1, 1])
with col1:
st.markdown("### Input")
uploaded_file = st.file_uploader(
"Upload CSV",
type=['csv'],
help="Upload any CSV file. The app will automatically detect columns and create appropriate charts and slides."
)
use_example = st.checkbox("Use example data (kpis.csv)", value=True if not uploaded_file else False)
if uploaded_file or use_example:
if use_example:
csv_path = "kpis.csv"
df = pd.read_csv(csv_path)
else:
df = pd.read_csv(uploaded_file)
with tempfile.NamedTemporaryFile(delete=False, suffix='.csv', mode='w') as f:
df.to_csv(f, index=False)
csv_path = f.name
with st.expander(" Preview Data", expanded=False):
try:
st.dataframe(df, width='stretch')
except Exception as e:
st.write("**Data Preview:**")
st.table(df.head(20))
if len(df) > 20:
st.caption(f"Showing first 20 of {len(df)} rows")
st.caption(f"Rows: {len(df)} | Columns: {len(df.columns)}")
else:
csv_path = None
st.info("Upload a CSV or use example data to continue")
goal = st.text_area(
"Goal",
value="Create a 6-slide investor update for Apr–Sep 2025. Focus on growth, retention, unit economics, and runway.",
height=100,
help="Describe what you want the AI to create"
)
generate_btn = st.button("Generate Artifacts", type="primary", use_container_width=True)
with col2:
st.markdown("### Output")
status_container = st.empty()
progress_bar = st.progress(0)
if not generate_btn:
status_container.info("Configure settings and click 'Generate Artifacts'")
if generate_btn:
if not csv_path:
st.error("Please upload a CSV or select 'Use example data'")
st.stop()
try:
status_container.info("Processing... This may take 30-60 seconds")
progress_bar.progress(10)
output_dir = Path("out")
output_dir.mkdir(exist_ok=True)
progress_bar.progress(20)
with st.spinner("Generating artifacts..."):
outputs: RunOutputs = run_pipeline(
csv_path=csv_path,
goal=goal,
outdir=str(output_dir),
model=model,
num_slides=num_slides,
num_charts=num_charts
)
st.session_state.outputs = outputs
st.session_state.generated = True
progress_bar.progress(100)
except Exception as e:
status_container.markdown(
f'<div class="error-box"> <b>Error:</b> {str(e)}</div>',
unsafe_allow_html=True
)
st.exception(e)
st.session_state.generated = False
if st.session_state.generated and st.session_state.outputs:
outputs = st.session_state.outputs
try:
if "Error" not in outputs.logs:
status_container.markdown(
'<div class="success-box"><b>Success!</b> Artifacts generated successfully</div>',
unsafe_allow_html=True
)
tab1, tab2, tab3, tab4 = st.tabs(["PowerPoint", "Excel", "JSON Plan", "Logs"])
with tab1:
st.markdown("### PowerPoint Slides")
pptx_path = Path(outputs.pptx_path)
if pptx_path.exists():
try:
prs = Presentation(str(pptx_path))
slide_count = len(prs.slides)
except:
slide_count = "unknown"
with open(pptx_path, "rb") as f:
st.download_button(
label="Download PowerPoint",
data=f.read(),
file_name="investor_update.pptx",
mime="application/vnd.openxmlformats-officedocument.presentationml.presentation",
width='stretch',
key="pptx_download"
)
st.markdown("---")
col_info1, col_info2 = st.columns(2)
with col_info1:
st.metric("Slides", slide_count)
with col_info2:
file_size = pptx_path.stat().st_size / 1024 # KB
st.metric("File Size", f"{file_size:.1f} KB")
else:
st.error("PowerPoint file not found")
with tab2:
st.markdown("### Excel Workbook")
xlsx_path = Path(outputs.xlsx_path)
if xlsx_path.exists():
with open(xlsx_path, "rb") as f:
st.download_button(
label="Download Excel",
data=f.read(),
file_name="investor_update.xlsx", mime="application/vnd.openxmlformats-officedocument.spreadsheetml.sheet",
width='stretch',
key="xlsx_download"
)
wb = openpyxl.load_workbook(xlsx_path)
st.markdown("#### Data Preview")
ws = wb["Model"]
data = []
headers = [cell.value for cell in ws[1]]
for row in ws.iter_rows(min_row=2, values_only=True):
data.append(row)
df_preview = pd.DataFrame(data, columns=headers)
try:
st.dataframe(df_preview.head(10), width='stretch')
except Exception:
st.table(df_preview.head(10))
if len(df_preview) > 10:
st.caption(f"Showing first 10 of {len[df_preview)} rows")
else:
st.error("Excel file not found")
with tab3:
st.markdown("### Schema-Locked JSON Plan")
plan_path = Path(outputs.plan_path)
if plan_path.exists():
with open(plan_path, "r") as f:
plan_data = json.load(f)
st.download_button(
label="Download JSON",
data=json.dumps(plan_data, indent=2),
file_name="plan.json",
mime="application/json",
key="json_download"
)
st.markdown("---")
st.json(plan_data)
col_a, col_b = st.columns(2)
with col_a:
st.metric("Charts Generated", len(plan_data.get("charts", [])))
with col_b:
st.metric("Slides Generated", len(plan_data.get("slides", [])))
else:
st.error("JSON plan not found")
with tab4:
st.markdown("### Generation Logs")
st.code(outputs.logs, language="text")
else:
status_container.markdown(
f'<div class="error-box"> <b>Error occurred</b><br>{outputs.logs}</div>',
unsafe_allow_html=True
)
except Exception as e:
st.error(f"Error displaying results: {str(e)}")
st.exception(e)
except Exception as e:
st.error(f"Fatal Error: {str(e)}")
st.exception(e)
st.info("Try installing dependencies: pip install -r requirements.txt")
if __name__ == "__main__":
try:
main()
except Exception as e:
import sys
print(f"Fatal error: {e}", file=sys.stderr)
import traceback
traceback.print_exc()Dans la couche Streamlit, nous définissons le cadre de l’app avec st.set_page_config(layout="wide"), puis nous scindons l’écran via st.columns() pour que la partie gauche collecte les entrées tandis que la droite affiche les contrôles d’exécution et les sorties. Le pipeline ne s’exécute qu’au clic sur st.button() : nous vérifions d’abord la présence d’un fichier, enveloppons st.spinner() pour éviter un gel visuel, puis nous renvoyons les artefacts à l’utilisateur via st.download_button() pour l’Excel, le PowerPoint et le fichier de plan.
Une fois cette étape achevée, enregistrez le tout sous app.py et lancez l’expérience complète avec :
streamlit run app.pyApprenez avec DataCamp
Cours
Cours
Cours