
Cours
Boîte à outils Python
4 h
318.2K
Tableau est un outil de visualisation de données très populaire parmi les professionnels des données et un outil couramment demandé lors de l'embauche. Python est un langage de programmation polyvalent très utilisé en science des données. L'intégration de Python dans Tableau permet aux utilisateurs de construire des modèles sophistiqués, d'exécuter des calculs complexes et d'étendre les capacités natives de Tableau.
Ceci est particulièrement utile pour les analystes de données, les scientifiques de données et les professionnels de l'intelligence économique qui cherchent à exploiter la modélisation statistique, l'apprentissage automatique et les techniques de traitement des données directement dans leurs tableaux de bord.
Cet article fait office de tutoriel pratique pour l'intégration de Python dans Tableau. Vous apprendrez à configurer votre environnement, à exécuter des scripts Python, à explorer des cas d'utilisation analytiques avancés et à résoudre des problèmes courants. Si vous souhaitez vous familiariser avec Tableau, suivez ce cours d'introduction à Tableau.
L'intégration de Python avec Tableau est rendue possible grâce à un service externe, l'extension analytique appelée TabPy (Tableau Python Server). Cette extension permet aux utilisateurs de Tableau d'exécuter des scripts Python dans leur environnement Tableau.
Bien que vous puissiez avoir de l'expérience dans l'utilisation de Python pour créer des fichiers puis les visualiser dans Tableau comme ce tutoriel Visualiser des données avec Python et Tableau, cette connexion avec TabPy permet une intégration plus transparente entre les données dans Tableau et vos scripts Python.
TabPy sert de passerelle entre Tableau et Python. Il fonctionne sur un modèle client-serveur, où Tableau (client) envoie des scripts à TabPy (serveur), qui les exécute dans un environnement Python et renvoie les résultats.
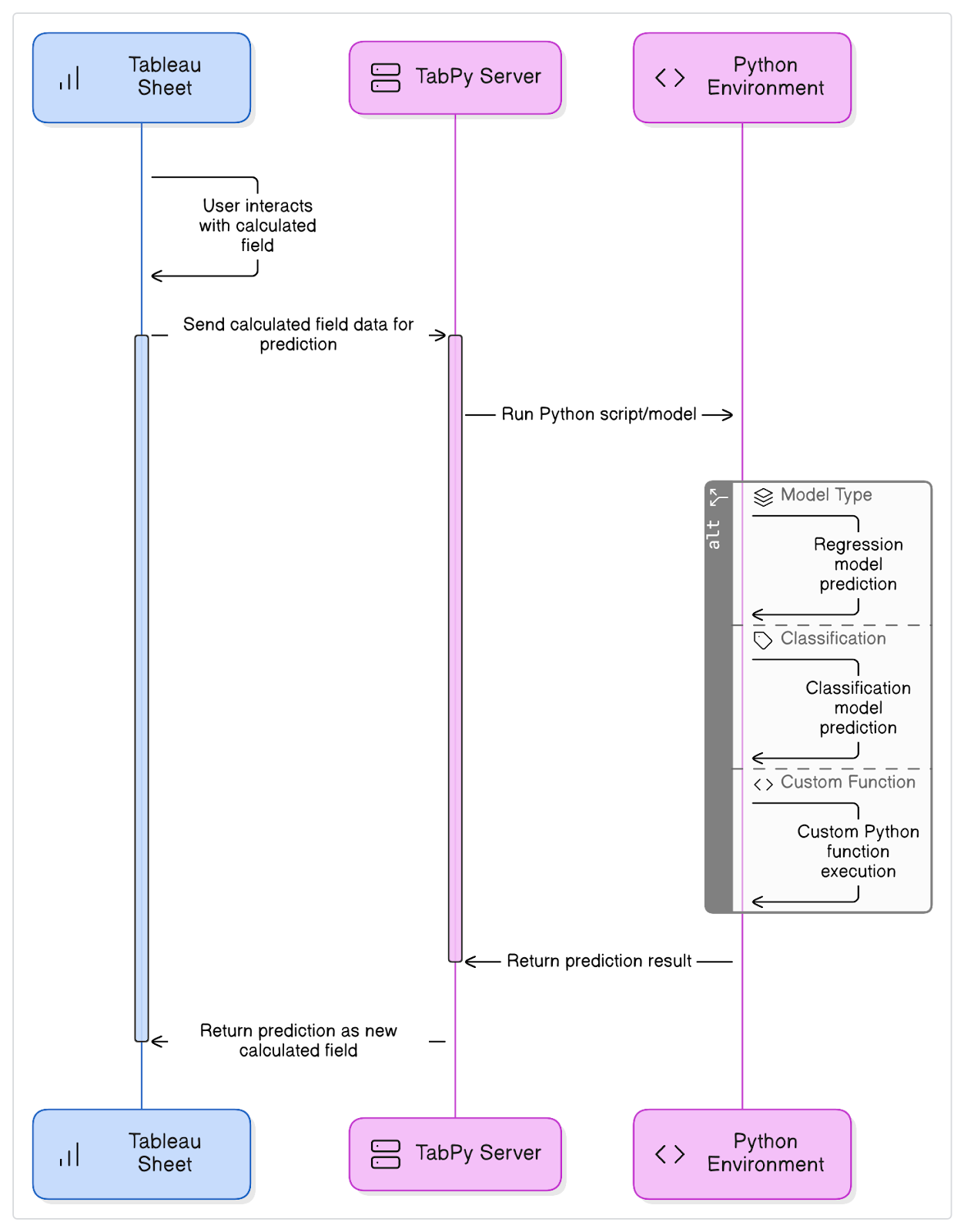
Diagramme montrant la connexion entre Tableau, TabPy et l'environnement Python généré à l'aide de eraser.io.
Bien que Tableau soit extraordinairement puissant, ses champs calculés peuvent parfois sembler encombrants ou inefficaces lorsqu'il s'agit de tâches analytiques complexes. L'intégration de Python offre plusieurs avantages par rapport aux capacités natives de Tableau et donne aux utilisateurs plus de liberté pour traiter leurs données.
Par exemple, vous pouvez inclure les cas d'utilisation suivants avec Python :
scikit-learn, statsmodels, et xgboost pour la régression, le regroupement et la classification.pandas ou numpy pour augmenter la puissance analytique de votre tableau de bord Tableau.Pour commencer à utiliser Python dans Tableau, vous devrez installer et configurer TabPy. Cette étape est assez simple ! Le processus principal consiste à s'assurer que Python et Tableau sont installés sur votre ordinateur.
1. Installez Python. Suivez les instructions de votre système d'exploitation pour installer Python.
2. Créez un environnement virtuel :
python3 -m venv tableau-env3. Installez TabPy (assurez-vous d'activer votre environnement). Vous pouvez également installer d'autres paquets tels que pandas, numpy, sklearn, et d'autres encore à ce moment-là.
pip install tabpy4. Lancez TabPy :
tabpyPour personnaliser TabPy, modifiez son fichier de configuration. Ces personnalisations vous permettent de modifier des éléments tels que le port que TabPy écoute pour obtenir des informations et le protocole de transfert qu'il utilise. Pour plus d'informations sur les paramètres de configuration, suivez le guide de configuration de TabPy.
Voici à quoi pourrait ressembler un fichier de configuration pour tabpy.
[TABPY]
TABPY_PORT = 9004
TABPY_TRANSFER_PROTOCOL = httpComme TabPy repose sur l'utilisation d'une connexion serveur de type Internet à vos ressources locales, il est préférable de suivre quelques conseils en matière de réseau et de sécurité :
Pour plus de détails sur l'utilisation de TabPy, suivez le tutoriel suivant tutoriel sur l'utilisation de TabPy.
Après avoir configuré TabPy, vous pouvez désormais intégrer Python directement dans les tableaux de bord Tableau. Vous devez d'abord activer les connexions d'extension dans Tableau. Ouvrez Tableau Desktop, allez dans Settings and Performance, Manage analytics Extension Connection, et sélectionnez TabPy. Ensuite, configurez-le en fonction des paramètres de votre fichier de configuration TabPy.
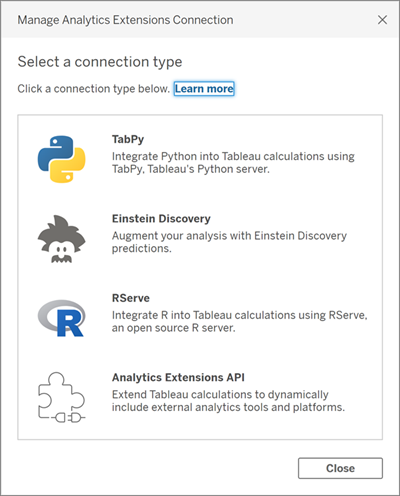
Écran de gestion de la connexion des extensions analytiques dans Tableau (help.tableau.com)
Il existe trois façons principales d'exécuter des scripts Python dans Tableau : les calculs de scripts en ligne à l'intérieur d'un champ calculé, le prétraitement avec les extensions Tableau et les points d'extrémité de modèle.
Utilisez les fonctions SCRIPT_REAL, SCRIPT_INT, SCRIPT_STR, ou SCRIPT_BOOL de Tableau. Ces fonctions transmettent directement des données au serveur TabPy sans exécuter de script externe. Vous pouvez écrire Python directement dans ces scripts.
Exemple : Normalisation du score Z
SCRIPT_REAL(
"import scipy.stats as stats
return stats.zscore(_arg1)",
SUM([Sales])
)
L'exemple ci-dessus vous permet d'importer le paquet stats à partir de scipyet de renvoyer le score Z de la colonne SUM([Sales]) dans votre tableau.
Utilisez les extensions Tableau pour effectuer un prétraitement avec Python en dehors de Tableau, puis importez les résultats.
Ces extensions sont activées à partir de la page Feuilles de votre classeur Tableau. Avec ces extensions, vous saisissez l'intégralité de votre script à l'aide de l'extension TabPy. Le script est alors exécuté sur l'ensemble de votre jeu de données, ce qui vous permet de prétraiter l'ensemble de vos données en une seule fois plutôt qu'au niveau des lignes. Cette opération génère souvent un tableau distinct en sortie.
La fonction d'extension du tableau est disponible au bas de la page des feuilles. (Extrait de la documentation de Tableau)
La dernière méthode est l'une des plus puissantes. Nous hébergeons un modèle en utilisant le serveur TabPy pour exécuter un script. Nous invoquons ensuite ce script dans Tableau lorsque nous souhaitons exécuter ce modèle sur un ensemble particulier de données.
Exemple : Déployer le modèle vers TabPy
La première étape consiste à créer un fichier qui sera déployé par TabPy. Après avoir lancé votre serveur TabPy (en suivant les étapes ci-dessus), vous pouvez l'utiliser pour exécuter votre script Python. Une fois ce script Python déployé, nous l'appellerons dans Tableau à l'aide de SCRIPT_REAL.
from tabpy.tabpy_tools.client import Client
import pickle
def predict_sales(input_features):
model = pickle.load(open(model.pkl, ‘rb’)) # This assumes you have a saved model
return model.predict(input_features)
client = Client(‘http://localhost:9004’)
client.deploy('predict_sales', predict_sales, 'Predict sales using linear model', override=True)Appel de script Tableau :
SCRIPT_REAL("return tabpy.query(‘predict_sales’, _arg1)[‘response’]", SUM[Feature1])Un peu comme pour l'exécution de scripts Python en dehors de Tableau, il faut se méfier des performances. Il y a des considérations particulières à prendre en compte lorsque vous exécutez des données dans Tableau.
Si vous utilisez Tableau Server, vous pouvez optimiser davantage en utilisant la mise en commun des connexions. La mise en commun des connexions en général est l'idée de maintenir des connexions persistantes avec les sources de données afin de minimiser les frais généraux.
Vous pouvez faire de même pour vos sources de données et TabPy afin d'empêcher Tableau de "rouvrir" la connexion à TabPy chaque fois que vous exécutez un script ou un nouveau calcul.
Maintenant que les bases sont couvertes, vous pouvez mettre en œuvre des analyses hautement personnalisées. Ces méthodes impliquent l'élaboration de scripts plus avancés qui interagissent avec votre tableau de bord de manière intéressante.
Un excellent modèle consiste à déployer des modèles de séries temporelles (par exemple, ARIMA, Prophet) qui se mettent à jour en fonction des entrées de l'utilisateur, comme dans ce guide sur le déploiement de fonctions et de Prophet avec TabPy.
Une fois que vous avez construit votre modèle, vous pouvez l'intégrer dans un script qui peut être déployé par TabPy. Nous connectons ensuite ce modèle à notre Tableau en utilisant la même fonction SCRIPT_REAL pour faire appel à notre modèle déployé.
Désormais, si quelqu'un modifie des filtres tels que le lieu, l'heure ou le produit, Tableau génère de nouvelles prévisions en temps réel avec ces nouveaux filtres.
Étant donné que nous ouvrons nos connexions à TabPy, il est essentiel de suivre les protocoles de sécurité et de gouvernance appropriés.
TabPy offre une variété de protocoles d'authentification pour aider les utilisateurs à rester en sécurité. Les éléments suivants sont pris en charge et peuvent être configurés :
La meilleure pratique consiste à toujours utiliser HTTPS et des jetons sécurisés pour les déploiements en production.
Lors de la connexion entre Tableau et TabPy, nous devons nous assurer que nous suivons une gouvernance appropriée en matière de protection des données. Il s'agit notamment de s'assurer que les données passent par les bons canaux de connexion et ne peuvent pas utiliser d'autres ports, et que les données sont cryptées à tout moment lorsqu'elles sont en mouvement. Voici quelques bonnes pratiques à suivre :
Enfin, si votre organisation est tenue de se conformer à certaines réglementations, assurez-vous de continuer à suivre leurs meilleures pratiques. Assurez-vous que le GDPR et le CCPR sont respectés en anonymisant et en tokenisant les IIP avant qu'elles ne soient envoyées à TabPy. De plus, utilisez un stockage sécurisé pour les résultats intermédiaires de Python afin de minimiser les fuites.
Les problèmes sont inévitables, mais la plupart peuvent être résolus rapidement.
|
Enjeu |
Résolution |
|
Tableau ne peut pas se connecter à TabPy |
Vérifiez le pare-feu, confirmez le port (9004), et vérifiez que TabPy est en cours d'exécution. |
|
Le script renvoie des valeurs NULL |
Valider les types d'entrée et vérifier les journaux d'erreurs de Python |
|
Lenteur des performances |
Optimisez les données envoyées à Python, réduisez la fréquence des appels, utilisez la mise en cache. |
Si vous rencontrez des problèmes avec votre code, suivez ces étapes de débogage (qui fonctionnent pour n'importe quel script) :
L'intégration de Python avec Tableau débloque une puissance analytique avancée directement dans vos tableaux de bord visuels. Avec TabPy, vous pouvez :
Que vous exécutiez des modèles statistiques, traitiez des données textuelles ou visualisiez des prédictions, Python apporte une nouvelle dimension d'intelligence aux tableaux de bord Tableau.
En suivant les étapes décrites dans ce guide, vous serez en mesure d'exploiter Python pour réaliser des analyses plus perspicaces, plus souples et plus interactives. Pour plus d'informations sur Tableau et ses possibilités, consultez les guides suivants :
Les meilleurs cours de DataCamp
Cours
Cours
Cours