Cours
Manipulation de données en SQL
4 h
324.1K
Nous utiliserons la base de données des entreprises licornes, qui est disponible sur DataLab, le carnet de données basé sur l'IA de DataCamp. Ces entreprises sont appelées "licornes" parce qu'il s'agit de startups dont l'évaluation dépasse le milliard de dollars. Cette base de données contient donc les données de ces entreprises licornes et est composée de sept tableaux. Pour simplifier, nous nous concentrerons sur trois tableaux : companies, sales, et product_emissions.
GROUP BYGROUP BY est une commande SQL couramment utilisée pour agréger les données afin d'en tirer des informations. Le regroupement des données se fait en trois phases :
GROUP BY Exemple 1Nous pouvons commencer par montrer un exemple simple de GROUP BY. Supposons que nous voulions trouver les dix pays qui comptent le plus grand nombre d'entreprises licornes.
SELECT *
FROM companies
Il serait également intéressant de classer les résultats par ordre décroissant en fonction du nombre d'entreprises.
SELECT country, COUNT(*) AS n_companies
FROM companies
GROUP BY country
ORDER BY n_companies DESC
LIMIT 10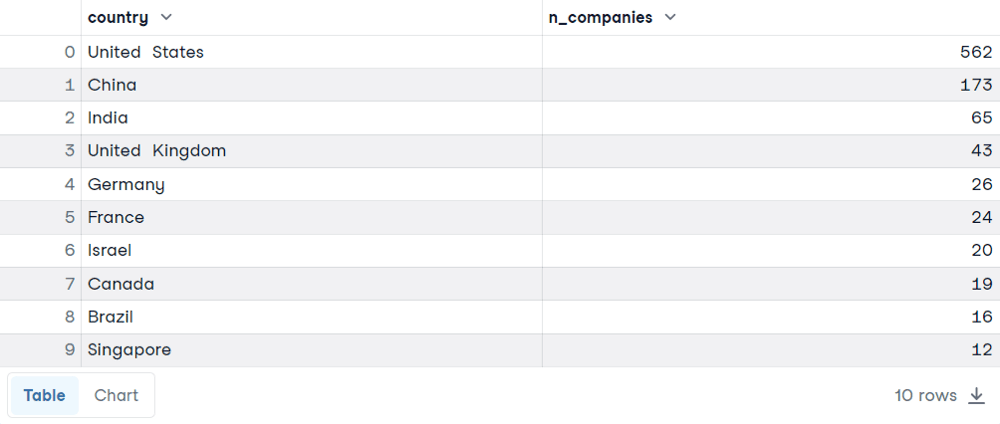
Voici les résultats. Vous ne serez probablement pas surpris de trouver les États-Unis, la Chine et l'Inde dans le classement. Expliquons la décision qui sous-tend cette requête :
COUNT(*) pour compter les lignes de chaque groupe, qui correspond au pays. En outre, nous avons également utilisé l'alias SQL pour renommer la colonne en un nom plus explicite. Cela est possible en utilisant le mot-clé AS, suivi du nouveau nom. COUNT est abordé plus en détail dans le tutoriel sur la FONCTION SQL COUNT(). GROUP BY pour agréger les données en fonction du pays. ORDER BY est nécessaire pour visualiser les pays dans le bon ordre, du plus grand au plus petit nombre d'entreprises. LIMIT, qui est suivi par le nombre de lignes que vous souhaitez voir apparaître dans les résultats.GROUP BY Exemple 2 Nous allons maintenant analyser le tableau des ventes. Pour chaque numéro de commande, nous avons le type de client, la ligne de produits, la quantité, le prix unitaire, le total, etc.
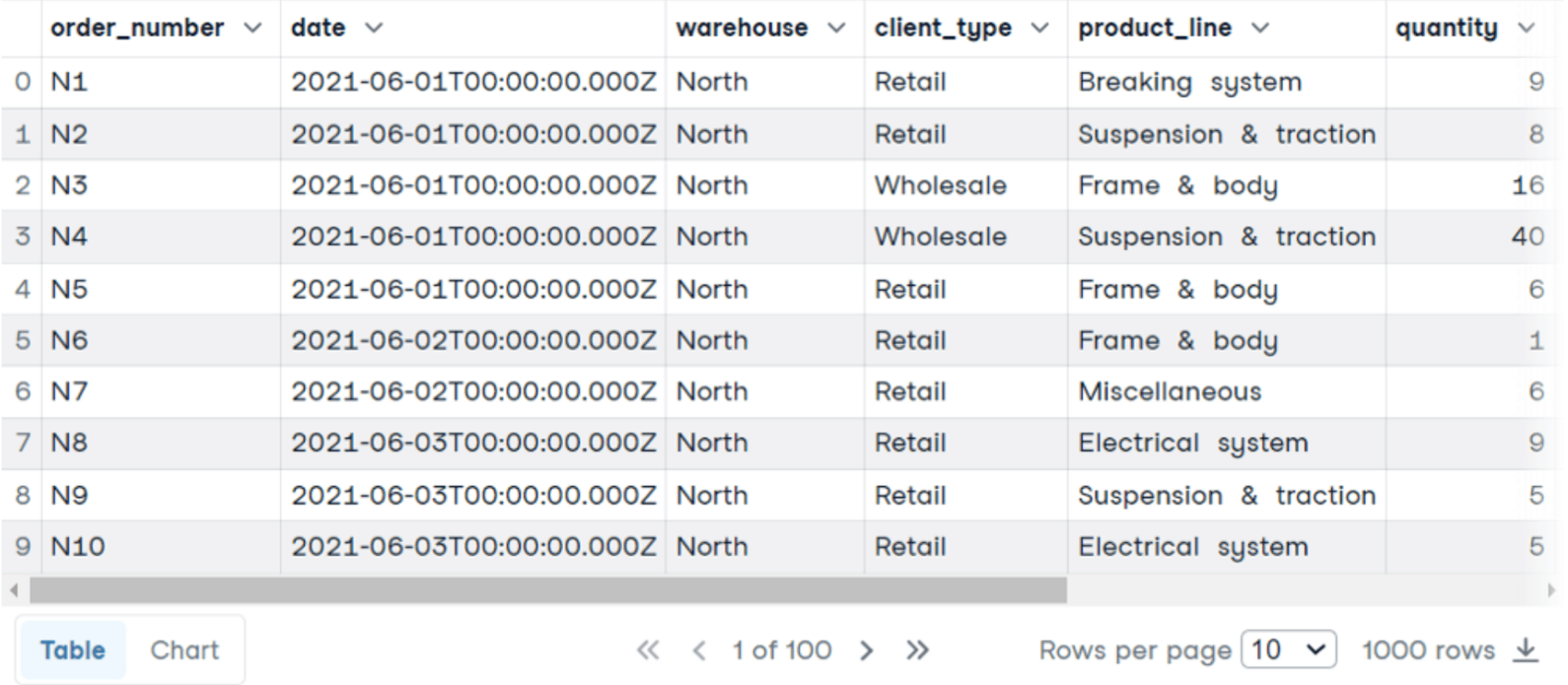
Cette fois, nous souhaitons connaître le prix moyen par unité, le nombre total de commandes et le gain total pour chaque ligne de produits :
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
GROUP BY product_line
ORDER BY total_gain DESC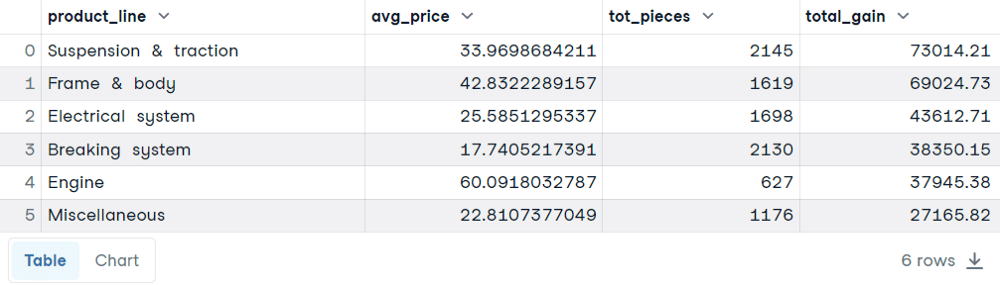
AVG() pour obtenir le prix moyen et de la fonction SUM() pour calculer le nombre total de commandes et le gain total pour chaque ligne de produits. ORDER BY est facultatif. Il a été inclus pour souligner le fait que les gains totaux plus élevés ne sont pas toujours proportionnels à des prix moyens ou à des pièces totales plus élevés. WHEREReprenons l'exemple précédent. Nous voulons maintenant ajouter une condition à la requête : nous ne voulons filtrer que le nombre total de commandes supérieur à 40 000. Essayons la clause WHERE:
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
WHERE SUM(total) > 40000
GROUP BY product_line
ORDER BY total_gain DESCCette requête renvoie l'erreur suivante :

Cette erreur ne permet pas de passer des fonctions agrégées dans la clause WHERE. Nous avons besoin d'une nouvelle commande pour résoudre ce problème.
Comme WHERE, la clause HAVING filtre les tableaux. Alors que WHERE essayait de filtrer l'ensemble du tableau, HAVING filtre les tableaux à l'intérieur de chacun des groupes définis par GROUP BY
Reprenez l'exemple précédent en remplaçant le mot WHERE par HAVING.
SELECT
product_line,
AVG(unit_price) AS avg_price,
SUM(quantity) AS tot_pieces,
SUM(total) AS total_gain
FROM sales
GROUP BY product_line
HAVING SUM(total) > 40000
ORDER BY total_gain DESC
Cette fois-ci, il produira trois lignes. Les autres lignes de produits ne correspondaient pas au critère, de sorte que nous sommes passés de six à trois résultats.
Que remarquez-vous d'autre dans la requête ? Nous n'avons pas transmis l'alias de la colonne à HAVING, mais l'agrégation du champ original. Vous demandez-vous pourquoi ? Vous découvrirez le mystère dans l'exemple suivant.
Comme dernier exemple, nous utiliserons le tableau appelé product_emissions, qui contient l'émission des produits fournis par les entreprises.
Cette fois-ci, nous souhaitons montrer l'empreinte carbone moyenne des produits (pcf) pour chaque entreprise appartenant au groupe industriel "Matériel et équipement technologique". En outre, il serait utile de connaître le nombre de produits de chaque entreprise pour comprendre s'il existe une relation entre le nombre de produits et l'empreinte carbone. Nous utilisons également HAVING pour extraire les entreprises dont l'empreinte carbone moyenne est supérieure à 100.
SELECT pe.company, count(product_name) AS n_products, avg(carbon_footprint_pcf) AS avg_carbon_footprint_pcf
FROM product_emissions AS pe
WHERE industry_group = 'Technology Hardware & Equipment'
GROUP BY pe.company, industry_group
having avg_carbon_footprint_pcf>100
ORDER BY n_products
Une erreur est apparue après avoir essayé d'utiliser l'alias. Pour la clause HAVING, le nom de la nouvelle colonne n'existe pas, elle ne pourra donc pas filtrer la requête. Corrigeons la demande :
SELECT pe.company, count(product_name) AS n_products, avg(carbon_footprint_pcf) AS avg_carbon_footprint_pcf
FROM product_emissions AS pe
WHERE industry_group = 'Technology Hardware & Equipment'
GROUP BY pe.company, industry_group
having avg(carbon_footprint_pcf)>100
ORDER BY n_products
Cette fois, la condition a fonctionné et nous pouvons visualiser les résultats dans le tableau. Nous venons d'apprendre que les alias de colonne ne peuvent pas être utilisés dans HAVING parce que cette condition est appliquée avant SELECT. C'est pourquoi il ne peut pas reconnaître les champs à partir des nouveaux noms.
Il s'agit de l'ordre des commandes lors de la rédaction de la requête :
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BYMais il y a une question que vous devez vous poser. Dans quel ordre les commandes SQL s'exécutent-elles ? En tant qu'humains, nous tenons souvent pour acquis que l'ordinateur lit et interprète SQL de haut en bas. Mais la réalité est différente de ce que l'on pourrait croire. C'est le bon ordre d'exécution :
FROM
WHERE
GROUP BY
HAVING
SELECT
ORDER BY
LIMIT Ainsi, le processeur de requêtes ne commence pas à partir de SELECT, mais il commence par sélectionner les tableaux à inclure, et SELECT est exécuté après HAVING. Cela explique pourquoi HAVING ne permet pas l'utilisation de ALIAS, alors que ORDER BY n'a pas de problème avec elle. Outre cet aspect, cet ordre d'exécution clarifie la raison pour laquelle HAVING est utilisé avec GROUP BY pour appliquer des conditions aux données agrégées, alors que WHERE ne le peut pas.
Après avoir lu ce tutoriel, vous devriez avoir une idée claire de la différence entre GROUP BY et HAVING. Vous pouvez vous entraîner sur DataLab pour maîtriser ces concepts.
Si vous souhaitez passer au niveau suivant du parcours d'apprentissage SQL, vous pouvez suivre notre cours SQL intermédiaire. Si vous avez encore besoin de renforcer vos bases en SQL, vous pouvez revenir au cours Introduction à SQL pour apprendre les principes fondamentaux du langage.
Cours SQL
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Matt Crabtree
Tutoriel
DataCamp Team
Tutoriel
Samuel Shaibu
Tutoriel
Sejal Jaiswal

