
Kursus
Model AI yang Dapat Diskalakan dengan PyTorch Lightning
3 Hr
1.1K
Rekayasa konteks adalah praktik merancang sistem yang memutuskan informasi apa yang dilihat model AI sebelum menghasilkan respons.
Meskipun istilahnya baru, prinsip di balik rekayasa konteks telah ada cukup lama. Abstraksi baru ini memungkinkan kita menalar isu paling penting dan selalu hadir: merancang alur informasi yang masuk dan keluar dari sistem AI.
Alih-alih menulis prompt sempurna untuk setiap permintaan, Anda membuat sistem yang mengumpulkan detail relevan dari berbagai sumber dan menyusunnya dalam jendela konteks model. Artinya, sistem Anda menggabungkan riwayat percakapan, data pengguna, dokumen eksternal, dan alat yang tersedia, lalu memformatnya agar dapat diproses oleh model.
Sumber: 12-factor-agents
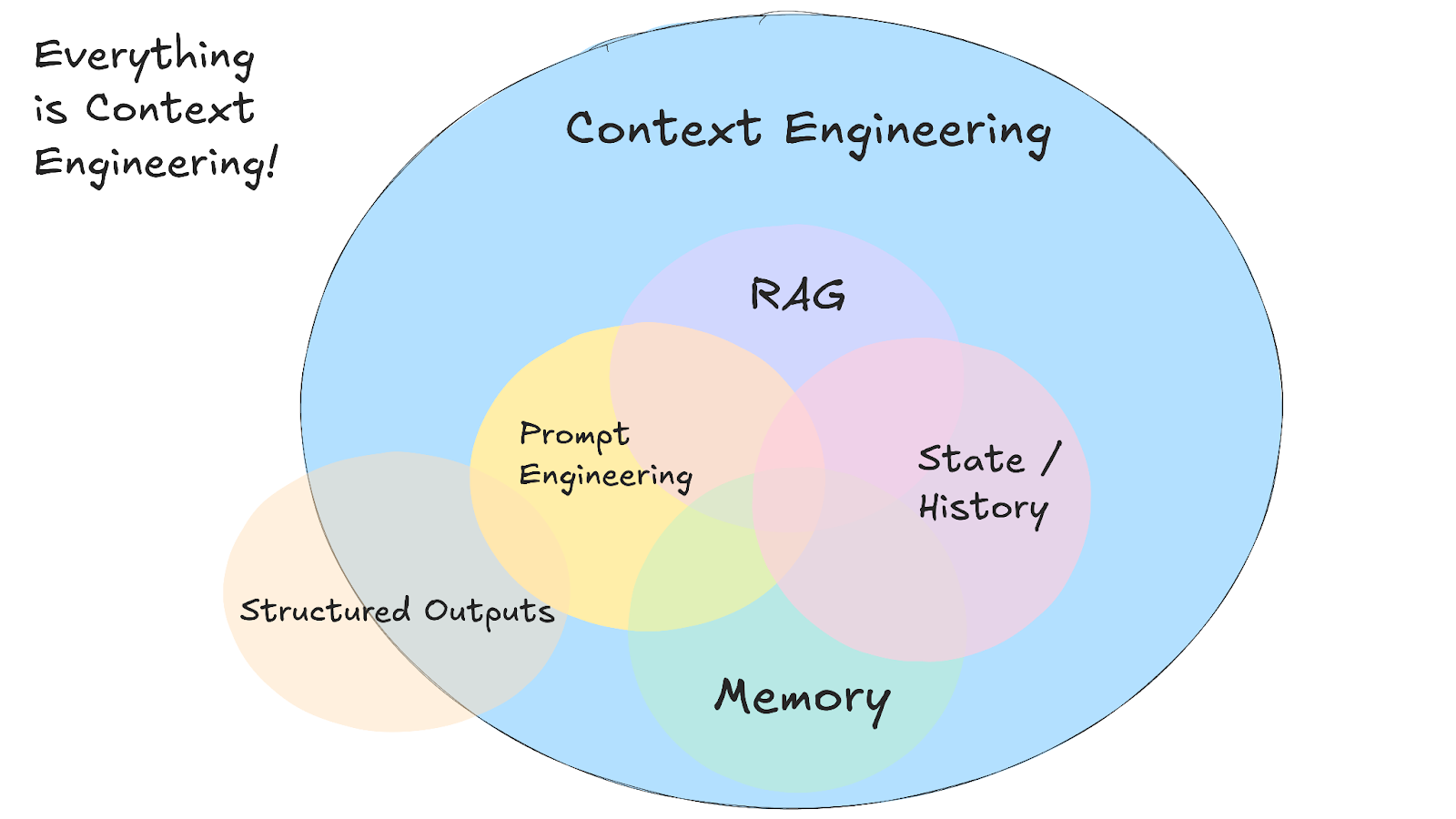
Pendekatan ini memerlukan pengelolaan beberapa jenis informasi berbeda yang membentuk konteks penuh:
Tantangan utama adalah bekerja dalam keterbatasan jendela konteks sambil mempertahankan percakapan yang koheren dari waktu ke waktu. Sistem Anda perlu memutuskan apa yang paling relevan untuk setiap permintaan, yang biasanya berarti membangun sistem pengambilan yang menemukan detail tepat saat Anda membutuhkannya.
Ini melibatkan pembuatan sistem memori yang melacak alur percakapan jangka pendek dan preferensi pengguna jangka panjang, serta menghapus informasi usang untuk memberi ruang bagi kebutuhan saat ini.
Manfaat nyata muncul ketika berbagai jenis konteks bekerja bersama untuk menciptakan sistem AI yang terasa lebih cerdas dan lebih sadar. Ketika asisten AI Anda dapat merujuk percakapan sebelumnya, mengakses kalender Anda, dan memahami gaya komunikasi Anda secara bersamaan, interaksi tidak lagi terasa berulang dan mulai terasa seperti Anda bekerja dengan sesuatu yang mengingat Anda.
Jika Anda meminta ChatGPT untuk “menulis email profesional,” itu adalah rekayasa prompt — Anda menulis instruksi untuk satu tugas. Namun jika Anda membangun bot layanan pelanggan yang perlu mengingat tiket sebelumnya, mengakses detail akun pengguna, dan mempertahankan riwayat percakapan di banyak interaksi, itu adalah rekayasa konteks.
Andrej Karpathy menjelaskan ini dengan baik:
Orang mengasosiasikan prompt dengan deskripsi tugas singkat yang Anda berikan kepada LLM dalam penggunaan sehari-hari. Padahal, di setiap aplikasi LLM kelas industri, rekayasa konteks adalah seni dan ilmu yang cermat untuk mengisi jendela konteks dengan informasi yang tepat untuk langkah berikutnya.
Andrej Karpathy
Turunnya biaya token LLM juga memungkinkan sistem multi-agen. Alih-alih memaksakan semuanya ke jendela konteks satu model, Anda dapat memiliki agen-agen khusus yang menangani aspek berbeda dari suatu masalah dan saling berbagi informasi melalui protokol seperti A2A atau MCP.
Untuk mempelajari lebih lanjut tentang agen AI, lihat lembar contekan agen AI ini.
Asisten coding AI—seperti Cursor atau Windsurf—merupakan salah satu penerapan rekayasa konteks paling maju karena menggabungkan prinsip RAG dan agen sekaligus bekerja dengan informasi yang sangat terstruktur dan saling terhubung.
Sistem ini perlu memahami bukan hanya file individual, tetapi juga seluruh arsitektur proyek, ketergantungan antarmodul, dan pola pengodean di seluruh basis kode Anda.
Ketika Anda meminta asisten coding untuk merapikan (refactor) sebuah fungsi, ia memerlukan konteks tentang di mana fungsi itu digunakan, tipe data yang diharapkan, dan bagaimana perubahan dapat memengaruhi bagian lain dari proyek Anda.
Rekayasa konteks menjadi krusial di sini karena kode memiliki relasi yang melintasi banyak file bahkan banyak repositori. Asisten coding yang baik mempertahankan konteks tentang struktur proyek Anda, perubahan terbaru yang Anda buat, gaya pengodean Anda, dan kerangka kerja yang Anda gunakan.
Inilah mengapa alat seperti Cursor bekerja lebih baik semakin lama Anda menggunakannya dalam sebuah proyek. Mereka membangun konteks tentang basis kode spesifik Anda dan dapat memberikan saran yang lebih relevan berdasarkan pola dan preferensi Anda.
Saat membaca artikel ini, Anda mungkin berpikir bahwa rekayasa konteks tidak perlu atau akan menjadi tidak perlu dalam waktu dekat karena jendela konteks model terdepan terus bertambah. Ini asumsi yang wajar karena jika konteks cukup besar, Anda bisa saja memasukkan semuanya ke dalam prompt (alat, dokumen, instruksi, dan lainnya) dan membiarkan model mengurus sisanya.
Namun, artikel yang sangat baik ini yang ditulis oleh Drew Breunig menunjukkan empat cara mengejutkan bagaimana konteks bisa lepas kendali, bahkan ketika model yang dimaksud mendukung jendela konteks 1 juta token. Pada bagian ini, saya akan dengan cepat menjelaskan masalah yang diuraikan oleh Drew Breunig dan pola rekayasa konteks yang menyelesaikannya—saya sangat merekomendasikan membaca artikel Breunig untuk detail lebih lanjut.
Peracunan konteks terjadi ketika sebuah halusinasi atau kesalahan masuk ke dalam konteks sistem AI Anda dan kemudian dirujuk berulang kali dalam respons di masa mendatang. Tim DeepMind mengidentifikasi masalah ini dalam laporan teknis Gemini 2.5 saat membangun agen yang memainkan Pokémon. Ketika agen sesekali berhalusinasi tentang status permainan, informasi palsu ini meracuni bagian “tujuan” dari konteksnya, menyebabkan agen mengembangkan strategi yang tidak masuk akal dan mengejar tujuan yang mustahil dalam waktu lama.
Masalah ini menjadi sangat buruk dalam alur kerja agen di mana informasi menumpuk. Setelah konteks yang teracuni terbentuk, butuh waktu lama untuk memperbaikinya karena model terus merujuk informasi palsu seolah-olah benar.
Perbaikan terbaik adalah validasi dan karantina konteks. Anda dapat mengisolasi berbagai jenis konteks dalam thread terpisah dan memvalidasi informasi sebelum ditambahkan ke memori jangka panjang. Karantina konteks berarti memulai thread baru saat Anda mendeteksi potensi peracunan, yang mencegah informasi buruk menyebar ke interaksi selanjutnya.
Gangguan konteks terjadi ketika konteks Anda tumbuh begitu besar sehingga model mulai terlalu fokus pada riwayat yang menumpuk alih-alih menggunakan apa yang dipelajarinya saat pelatihan. Agen Gemini yang memainkan Pokémon menunjukkan ini — begitu konteks melampaui 100.000 token, agen mulai mengulangi tindakan dari sejarahnya yang luas daripada mengembangkan strategi baru.
Sebuah studi Databricks (studi yang sangat menarik; sangat layak dibaca) menemukan bahwa ketepatan model mulai turun sekitar 32.000 token untuk Llama 3.1 405b, dengan model yang lebih kecil mencapai batasnya jauh lebih awal. Ini berarti model mulai membuat kesalahan jauh sebelum jendela konteks benar-benar penuh, yang membuat kita mempertanyakan nilai sebenarnya dari jendela konteks yang sangat besar untuk tugas penalaran kompleks.
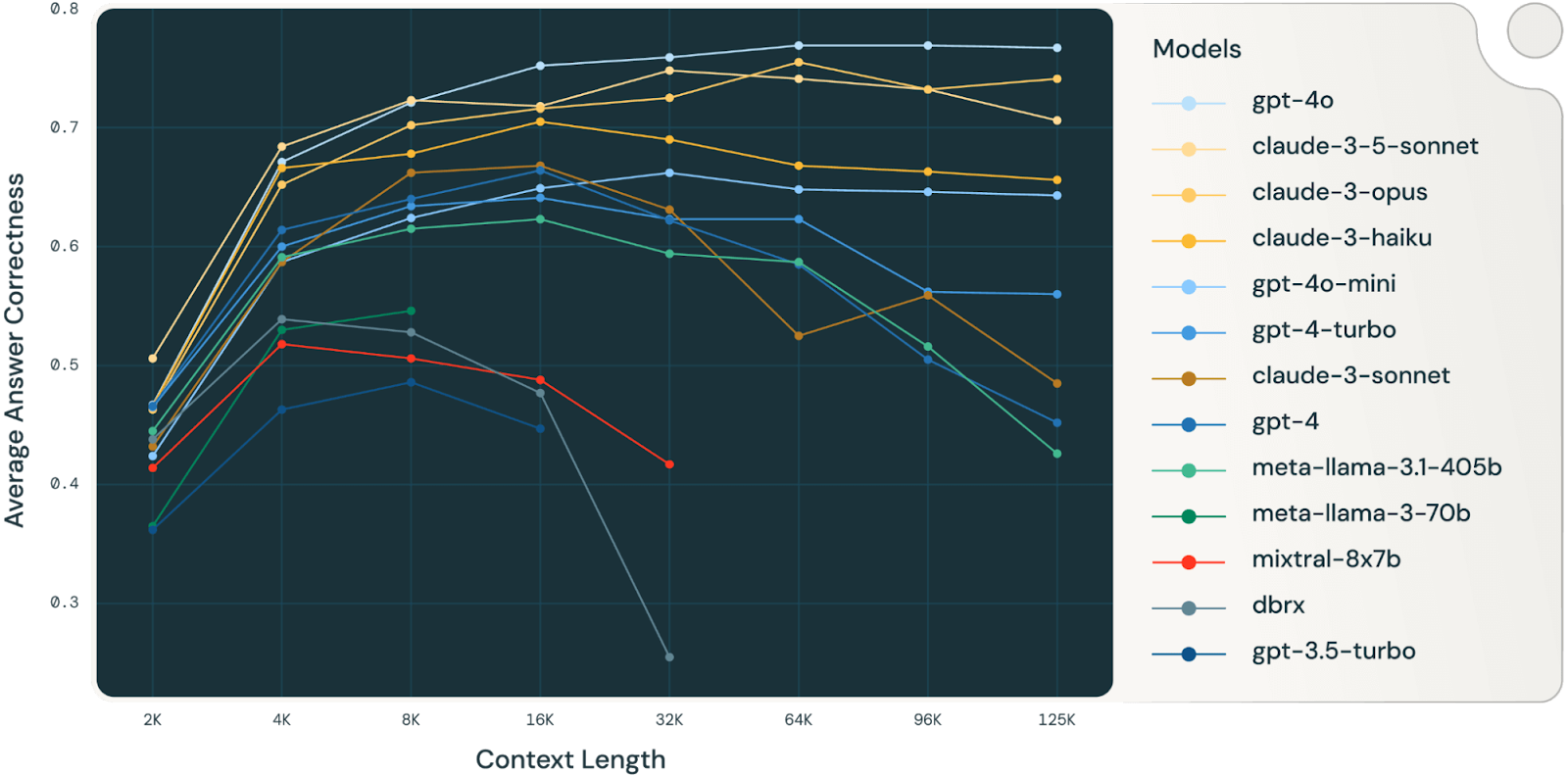
Sumber: Databricks
Pendekatan terbaik adalah peringkasan konteks. Alih-alih membiarkan konteks tumbuh tanpa batas, Anda dapat memadatkan informasi yang terkumpul menjadi ringkasan lebih pendek yang mempertahankan detail penting sambil menghapus riwayat yang redundan. Ini membantu ketika Anda mencapai ambang gangguan — Anda dapat merangkum percakapan sejauh ini dan memulai kembali sambil menjaga konsistensi.
Kebingungan konteks terjadi ketika Anda menyertakan informasi tambahan dalam konteks yang kemudian digunakan model untuk menghasilkan respons buruk, meskipun informasi itu tidak relevan dengan tugas saat ini. Papan Peringkat Function-Calling Berkeley menunjukkan hal ini — setiap model berkinerja lebih buruk ketika diberi lebih dari satu alat, dan model terkadang memanggil alat yang tidak ada hubungannya dengan tugas.
Masalahnya semakin buruk pada model yang lebih kecil dan semakin banyak alat. Sebuah studi terbaru menemukan bahwa Llama 3.1 8b yang di-kuantisasi gagal pada benchmark GeoEngine ketika diberi semua 46 alat yang tersedia, meski konteks masih jauh di dalam batas jendela 16k. Namun ketika peneliti hanya memberikan 19 alat pada model yang sama, hasilnya baik.
Solusinya adalah pengelolaan perbekalan alat menggunakan teknik RAG. Riset oleh Tiantian Gan dan Qiyao Sun menunjukkan bahwa menerapkan RAG pada deskripsi alat benar-benar dapat meningkatkan kinerja. Dengan menyimpan deskripsi alat dalam sebuah basis data vektor, Anda dapat memilih hanya alat yang paling relevan untuk setiap tugas. Studi mereka menemukan bahwa menjaga pilihan alat di bawah 30 alat memberikan akurasi pemilihan alat tiga kali lebih baik dan prompt yang jauh lebih pendek.
Benturan konteks terjadi ketika Anda mengumpulkan informasi dan alat dalam konteks yang secara langsung bertentangan dengan informasi lain yang sudah ada. Sebuah studi Microsoft dan Salesforce menunjukkan hal ini dengan mengambil prompt benchmark dan “membagi” informasinya ke beberapa giliran percakapan alih-alih memberikan semuanya sekaligus. Hasilnya besar — penurunan kinerja rata-rata 39%, dengan model o3 OpenAI turun dari 98,1 menjadi 64,1.
Sumber: Laban et. al, 2025
Masalah ini terjadi karena ketika informasi datang bertahap, konteks yang tersusun berisi upaya awal model untuk menjawab pertanyaan sebelum memiliki semua informasi. Jawaban awal yang keliru ini tetap berada dalam konteks dan memengaruhi model saat menghasilkan respons akhir.
Perbaikan terbaik adalah pemangkasan konteks dan offloading. Pemangkasan konteks berarti menghapus informasi yang usang atau bertentangan saat detail baru datang. Offloading konteks, seperti alat “think” Anthropic, memberi model ruang kerja terpisah untuk memproses informasi tanpa mengacaukan konteks utama. Pendekatan catatan coret ini dapat memberikan peningkatan hingga 54% pada benchmark agen khusus dengan mencegah kontradiksi internal mengacaukan penalaran.
Rekayasa konteks mewakili fase berikutnya dalam pengembangan AI, di mana fokus bergeser dari menyusun prompt sempurna ke membangun sistem yang mengelola aliran informasi dari waktu ke waktu. Kemampuan mempertahankan konteks yang relevan di banyak interaksi menentukan apakah AI Anda terasa cerdas atau hanya memberi respons sekali jalan yang bagus.
Teknik yang dibahas dalam tutorial ini — dari sistem RAG hingga validasi konteks dan pengelolaan alat — sudah digunakan dalam sistem produksi yang menangani jutaan pengguna.
Jika Anda membangun sesuatu yang lebih kompleks daripada sekadar pembuat konten sederhana, Anda mungkin memerlukan teknik rekayasa konteks. Kabar baiknya, Anda bisa mulai dari yang kecil dengan implementasi RAG dasar dan secara bertahap menambahkan manajemen memori dan alat yang lebih canggih sesuai kebutuhan yang berkembang.
Untuk belajar lebih lanjut, saya merekomendasikan sumber berikut:
Pelajari AI dengan kursus-kursus ini!
Kursus
Kursus
Kursus