
Cursus
Schaalbare AI-modellen met PyTorch Lightning
3 Hr
1.1K
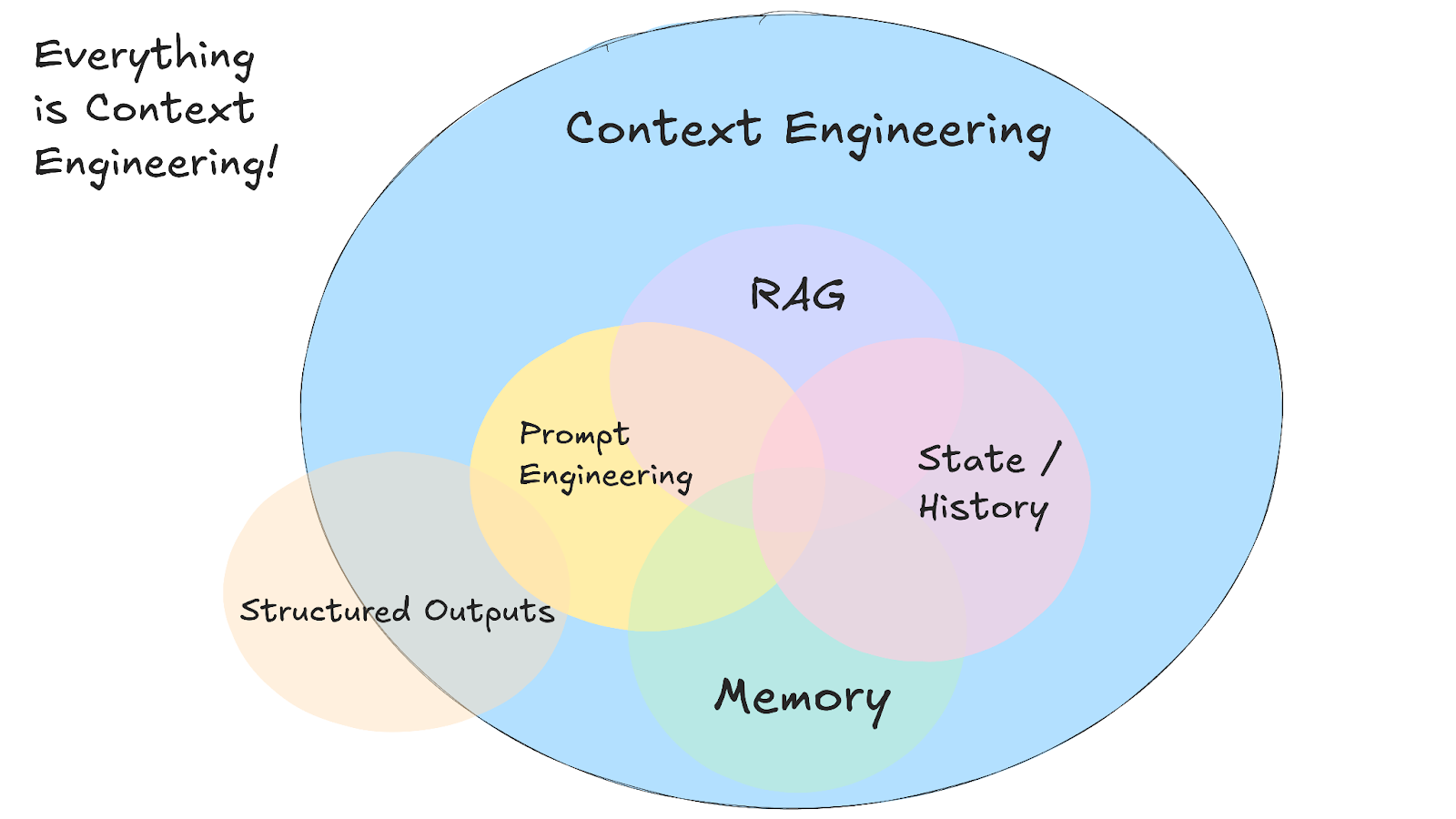
Context engineering is de praktijk van het ontwerpen van systemen die bepalen welke informatie een AI-model te zien krijgt voordat het een antwoord genereert.
Hoewel de term nieuw is, bestaan de principes achter context engineering al een hele tijd. Deze nieuwe abstractie stelt ons in staat na te denken over de meest wezenlijke en alomtegenwoordige kwestie: het ontwerpen van de informatiestroom die AI-systemen in- en uitgaat.
In plaats van perfecte prompts voor losse verzoeken te schrijven, maak je systemen die relevante details uit meerdere bronnen verzamelen en ze ordenen binnen het contextvenster van het model. Dat betekent dat je systeem gespreksgeschiedenis, gebruikersgegevens, externe documenten en beschikbare tools samenbrengt en ze zo opmaakt dat het model ermee kan werken.
Bron: 12-factor-agents
Deze aanpak vereist het beheren van verschillende informatietypen die samen de volledige context vormen:
De grootste uitdaging is werken binnen de beperkingen van het contextvenster en toch door de tijd heen coherente gesprekken behouden. Je systeem moet beslissen wat het meest relevant is voor elk verzoek, wat meestal betekent dat je retrievalsystemen bouwt die de juiste details vinden wanneer je ze nodig hebt.
Dit houdt in dat je geheugensystemen maakt die zowel de kortetermijn-gespreksflow als langetermijn-gebruikersvoorkeuren bijhouden, plus verouderde informatie verwijderen om ruimte te maken voor de huidige behoeften.
De echte winst ontstaat wanneer verschillende soorten context samenwerken en AI-systemen creëren die intelligenter en alerter aanvoelen. Wanneer je AI-assistent eerdere gesprekken kan aanhalen, je agenda kan raadplegen en je communicatiestijl tegelijk begrijpt, voelen interacties niet langer repetitief maar juist alsof je werkt met iets dat je onthoudt.
Als je ChatGPT vraagt om “een professionele e-mail te schrijven”, is dat prompt engineering — je schrijft instructies voor één taak. Maar als je een klantenservicebot bouwt die eerdere tickets moet onthouden, gebruikersgegevens moet raadplegen en gespreksgeschiedenis over meerdere interacties moet bijhouden, dan is dat context engineering.
Andrej Karpathy legt dit goed uit:
Mensen associëren prompts met korte taakbeschrijvingen die je een LLM geeft in je dagelijks gebruik. Terwijl in elke industriële LLM-app context engineering de delicate kunst en wetenschap is van het vullen van het contextvenster met precies de juiste informatie voor de volgende stap.
Andrej Karpathy
De dalende kosten van LLM-tokens maakten ook multi-agentsystemen mogelijk. In plaats van alles in het contextvenster van één model te proppen, kun je gespecialiseerde agents hebben die verschillende aspecten van een probleem afhandelen en informatie tussen hen delen via protocollen zoals A2A of MCP.
Wil je meer leren over AI-agents, bekijk dan deze cheat sheet over AI-agents.
AI-codeassistenten — zoals Cursor of Windsurf — behoren tot de meest geavanceerde toepassingen van context engineering, omdat ze zowel RAG- als agentprincipes combineren terwijl ze werken met sterk gestructureerde, onderling verbonden informatie.
Deze systemen moeten niet alleen individuele bestanden begrijpen, maar hele projectarchitecturen, afhankelijkheden tussen modules en codeerpatronen in je codebase.
Als je een codeassistent vraagt om een functie te refactoren, heeft die context nodig over waar die functie wordt gebruikt, welke datatypes worden verwacht en hoe wijzigingen andere delen van je project kunnen beïnvloeden.
Context engineering is hier cruciaal omdat code relaties heeft die meerdere bestanden en zelfs meerdere repositories overspannen. Een goede codeassistent bewaart context over je projectstructuur, recente wijzigingen die je hebt aangebracht, je codeerstijl en de frameworks die je gebruikt.
Daarom werken tools zoals Cursor beter naarmate je ze langer binnen een project gebruikt. Ze bouwen context op over jouw specifieke codebase en kunnen relevantere suggesties doen op basis van je patronen en voorkeuren.
Terwijl je dit artikel leest, denk je misschien dat context engineering onnodig is of zal worden in de nabije toekomst, aangezien contextvensters van de meest geavanceerde modellen blijven groeien. Dat is een logische aanname, want als de context maar groot genoeg is, zou je alles in een prompt kunnen gooien (tools, documenten, instructies en meer) en het model de rest laten doen.
Toch laat dit uitstekende artikel van Drew Breunig vier verrassende manieren zien waarop de context ontspoort, zelfs wanneer het model in kwestie contextvensters van 1 miljoen tokens ondersteunt. In deze sectie beschrijf ik kort de problemen die Drew Breunig toelicht en de context engineering-patronen die ze oplossen — ik raad sterk aan om Breunigs artikel voor meer details te lezen.
Contextvergiftiging treedt op wanneer een hallucinatie of fout in de context van je AI-systeem belandt en vervolgens steeds opnieuw wordt aangehaald in toekomstige reacties. Het DeepMind-team identificeerde dit probleem in hun technisch rapport over Gemini 2.5 bij het bouwen van een Pokémon-spelende agent. Wanneer de agent soms hallucineerde over de spelstatus, vergiftigde deze valse informatie de “doelen”-sectie van zijn context, waardoor de agent onzinnige strategieën ontwikkelde en lange tijd onmogelijke doelen nastreefde.
Dit probleem wordt erg groot in agent-workflows waarin informatie zich ophoopt. Zodra een vergiftigde context is ontstaan, kan het eeuwig duren om dit te herstellen, omdat het model de onjuiste informatie blijft aanhalen alsof die waar is.
Contextvalidatie en quarantaine is de beste oplossing. Je kunt verschillende soorten context in aparte threads isoleren en informatie valideren voordat die wordt toegevoegd aan het langetermijngeheugen. Contextquarantaine houdt in dat je nieuwe threads start zodra je mogelijke vergiftiging detecteert, zodat slechte informatie zich niet verspreidt naar toekomstige interacties.
Contextafleiding ontstaat wanneer je context zo groot wordt dat het model te veel focust op de opgebouwde geschiedenis in plaats van op wat het tijdens training heeft geleerd. De Gemini-agent die Pokémon speelde liet dit zien — zodra de context boven de 100.000 tokens kwam, begon de agent acties uit zijn enorme geschiedenis te herhalen in plaats van nieuwe strategieën te ontwikkelen.
Een Databricks-studie (zeer interessant; zeker het lezen waard) vond dat de nauwkeurigheid van modellen begon te dalen rond 32.000 tokens voor Llama 3.1 405b, waarbij kleinere modellen veel eerder hun limiet bereikten. Dit betekent dat modellen al fouten gaan maken lang voordat hun contextvensters daadwerkelijk vol zijn, wat doet afvragen wat de echte waarde is van zeer grote contextvensters voor complexe redeneertaken.
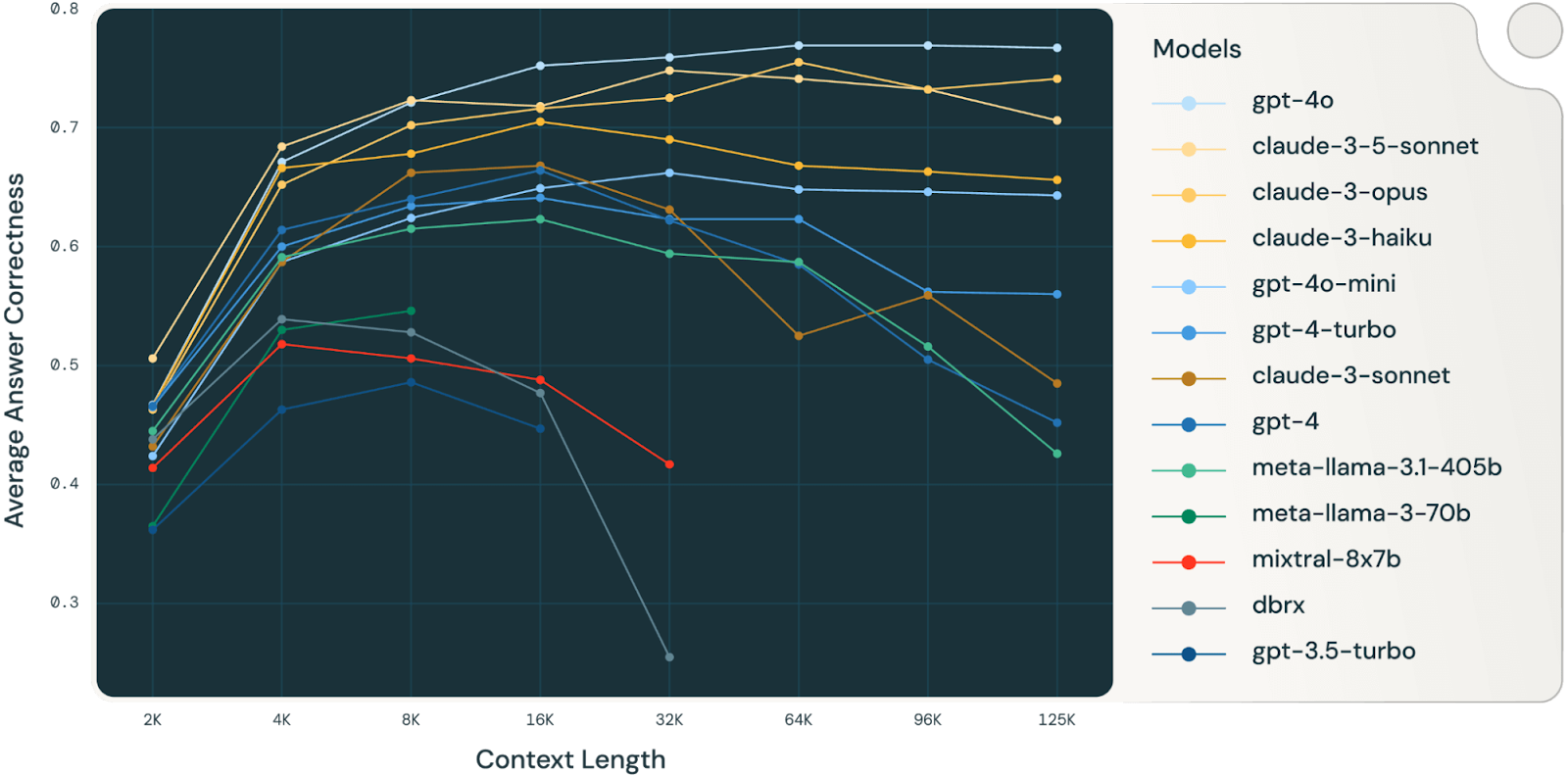
Bron: Databricks
De beste aanpak is contextsamenvatting. In plaats van context eindeloos te laten groeien, kun je opgehoopte informatie comprimeren tot kortere samenvattingen die belangrijke details behouden en redundante geschiedenis verwijderen. Dit helpt wanneer je het afleidingsplafond raakt — je kunt het gesprek tot nu toe samenvatten en met een schone lei verdergaan, terwijl je consistent blijft.
Contextverwarring treedt op wanneer je extra informatie in je context opneemt die het model gebruikt om slechte antwoorden te genereren, zelfs wanneer die informatie niet relevant is voor de huidige taak. De Berkeley Function-Calling Leaderboard laat dit zien — elk model presteert slechter wanneer het meer dan één tool krijgt, en modellen roepen soms tools aan die niets met de taak te maken hebben.
Het probleem wordt erger bij kleinere modellen en meer tools. Een recente studie vond dat een gequantiseerde Llama 3.1 8b faalde op de GeoEngine-benchmark wanneer het alle 46 beschikbare tools kreeg, zelfs al viel de context ruim binnen de 16k-windowlimiet. Maar toen onderzoekers hetzelfde model slechts 19 tools gaven, werkte het prima.
De oplossing is toolloadoutmanagement met RAG-technieken. Onderzoek van Tiantian Gan en Qiyao Sun liet zien dat het toepassen van RAG op toolbeschrijvingen de prestaties sterk kan verbeteren. Door toolbeschrijvingen op te slaan in een vectordatabank kun je per taak alleen de meest relevante tools selecteren. Hun studie vond dat het aantal tools onder de 30 houden driemaal betere toolselectienauwkeurigheid gaf en veel kortere prompts.
Contextconflict treedt op wanneer je informatie en tools in je context verzamelt die direct in tegenspraak zijn met andere informatie die er al staat. Een studie van Microsoft en Salesforce toonde dit aan door benchmarkprompts te nemen en hun informatie te “sharden” over meerdere gespreksbeurten in plaats van alles in één keer te geven. De resultaten waren enorm — een gemiddelde prestatiedaling van 39%, waarbij het model van OpenAI’s o3 daalde van 98,1 naar 64,1.
Bron: Laban et. al, 2025
Het probleem ontstaat omdat, wanneer informatie in etappes binnenkomt, de samengestelde context vroege pogingen van het model bevat om vragen te beantwoorden voordat het alle informatie heeft. Deze onjuiste vroege antwoorden blijven in de context en beïnvloeden het model bij het genereren van definitieve antwoorden.
Context snoeien en offloaden zijn de beste oplossingen. Context snoeien betekent verouderde of conflicterende informatie verwijderen zodra er nieuwe details binnenkomen. Context offloaden, zoals Anthropic’s “think”-tool, geeft modellen een aparte werkruimte om informatie te verwerken zonder de hoofdcontext te vervuilen. Deze kladblokaanpak kan tot 54% verbetering geven in gespecialiseerde agentbenchmarks door te voorkomen dat interne tegenstrijdigheden de redenering verstoren.
Context engineering vertegenwoordigt de volgende fase van AI-ontwikkeling, waarin de focus verschuift van het perfectioneren van prompts naar het bouwen van systemen die de informatiestroom door de tijd heen beheren. Het vermogen om relevante context over meerdere interacties te behouden, bepaalt of je AI intelligent aanvoelt of alleen goede losse antwoorden geeft.
De technieken in deze tutorial — van RAG-systemen tot contextvalidatie en toolmanagement — worden al gebruikt in productiesystemen die miljoenen gebruikers bedienen.
Als je iets bouwt dat complexer is dan een simpele contentgenerator, heb je waarschijnlijk context engineering-technieken nodig. Het goede nieuws is dat je klein kunt beginnen met basisimplementaties van RAG en geleidelijk geavanceerder geheugen- en toolmanagement kunt toevoegen naarmate je behoeften groeien.
Wil je meer leren, dan raad ik deze bronnen aan:
Leer AI met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
