
Cours
Modèles d'IA évolutifs avec PyTorch Lightning
3 h
1.1K
Vous êtes peut-être un ingénieur prompt hors pair, mais au fur et à mesure que la conversation avance, votre chatbot oublie souvent les éléments les plus importants de vos instructions, votre assistant de code perd le fil du projet et votre outil RAG n'arrive pas à relier les informations issues de documents et de domaines complexes.
À mesure que les cas d'utilisation de l'IA se complexifient, la rédaction d'une invite intelligente ne représente qu'une petite partie d'un défi beaucoup plus vaste : l' l'ingénierie contextuelle.
Dans ce tutoriel, je vais vous expliquer ce qu'est l'ingénierie contextuelle, comment elle fonctionne, quand l'utiliser à la place de l'ingénierie contextuelle classique, et les techniques pratiques qui rendent les systèmes d'IA plus intelligents et plus sensibles au contexte.
Nous tenons nos lecteurs informés des dernières actualités en matière d'IA en leur envoyant The Median, notre newsletter gratuite du vendredi qui résume les articles clés de la semaine. Abonnez-vous et restez informé en quelques minutes par semaine :
L'ingénierie contextuelle consiste à concevoir des systèmes qui déterminent les informations qu'un modèle d'IA doit prendre en compte avant de générer une réponse.
Même si le terme est nouveau, les principes qui sous-tendent l'ingénierie contextuelle existent depuis un certain temps déjà. Cette nouvelle abstraction nous permet de réfléchir à la question la plus importante et la plus récurrente de la conception du flux d'informations qui entrent et sortent des systèmes d'IA.
Au lieu de rédiger des invites parfaites pour chaque demande individuelle, vous créez des systèmes qui rassemblent des informations pertinentes provenant de plusieurs sources et les organisent dans la fenêtre contextuelle du modèle. Cela signifie que votre système rassemble l'historique des conversations, les données utilisateur, les documents externes et les outils disponibles, puis les formate afin que le modèle puisse les exploiter.
Source : 12 agents de facteur
Cette approche nécessite la gestion de plusieurs types d'informations qui constituent le contexte complet :
Le principal défi consiste à travailler dans les limites de la fenêtre contextuelle tout en maintenant la cohérence des conversations au fil du temps. Votre système doit déterminer ce qui est le plus pertinent pour chaque demande, ce qui implique généralement de mettre en place des systèmes de recherche capables de trouver les informations adéquates lorsque vous en avez besoin.
Cela implique la création de systèmes de mémoire qui suivent à la fois le flux des conversations à court terme et les préférences à long terme des utilisateurs, ainsi que la suppression des informations obsolètes afin de libérer de l'espace pour les besoins actuels.
Le véritable avantage apparaît lorsque différents types de contextes fonctionnent ensemble pour créer des systèmes d'IA qui semblent plus intelligents et plus conscients. Lorsque votre assistant IA est capable de se référer à des conversations précédentes, d'accéder à votre calendrier et de comprendre votre style de communication, les interactions ne semblent plus répétitives et vous avez l'impression de travailler avec un outil qui se souvient de vous.
Si vous demandez à ChatGPT de « rédiger un e-mail professionnel », il s'agit d'ingénierie de prompt : vous écrivez des instructions pour une seule tâche. Cependant, si vous développez un bot de service client qui doit se souvenir des tickets précédents, accéder aux détails du compte utilisateur et conserver l'historique des conversations sur plusieurs interactions, il s'agit alors d'ingénierie contextuelle.
Andrej Karpathy explique cela clairement:
Les gens associent les invites à de courtes descriptions de tâches que vous donneriez à un assistant juridique dans le cadre de votre utilisation quotidienne. Dans toutes les applications LLM de niveau industriel, l'ingénierie contextuelle est l'art et la science délicats qui consistent à remplir la fenêtre contextuelle avec les informations pertinentes pour l'étape suivante.
Andrej Karpathy
La baisse du coût des jetons LLM a également rendu possible la mise en place de systèmes multi-agents. Au lieu de tout regrouper dans la fenêtre contextuelle d'un seul modèle, vous pouvez disposer d'agents spécialisés qui traitent différents aspects d'un problème et partagent des informations entre eux via des protocoles tels que A2A ou MCP.
Pour en savoir plus sur les agents IA, veuillez consulter cette fiche récapitulative sur les agents IA.
Les assistants de codage IA, tels que Cursor ou Windsurf, représentent l'une des applications les plus avancées de l'ingénierie contextuelle, car ils combinent les principes du RAG et ceux des agents tout en travaillant avec des informations hautement structurées et interconnectées.
Ces systèmes doivent comprendre non seulement les fichiers individuels, mais également l'architecture globale des projets, les dépendances entre les modules et les modèles de codage utilisés dans l'ensemble de votre base de code.
Lorsque vous demandez à un assistant de codage de refactoriser une fonction, il a besoin de contexte pour savoir où cette fonction est utilisée, quels types de données elle attend et comment les modifications pourraient affecter d'autres parties de votre projet.
L'ingénierie contextuelle devient essentielle ici, car le code comporte des relations qui s'étendent sur plusieurs fichiers, voire plusieurs référentiels. Un bon assistant de codage conserve le contexte de la structure de votre projet, les modifications récentes que vous avez apportées, votre style de codage et les frameworks que vous utilisez.
C'est pourquoi les outils tels que Cursor sont d'autant plus efficaces que vous les utilisez longtemps dans le cadre d'un projet. Ils établissent un contexte autour de votre base de code spécifique et peuvent vous faire des suggestions plus pertinentes en fonction de vos habitudes et de vos préférences.
En lisant cet article, vous pourriez penser que l'ingénierie contextuelle est inutile ou qu'elle deviendra superflue dans un avenir proche, à mesure que les fenêtres contextuelles des modèles de pointe continueront de s'étendre. Ce serait une hypothèse naturelle, car si le contexte est suffisamment large, vous pourriez tout intégrer dans une invite (outils, documents, instructions, etc.) et laisser le modèle s'occuper du reste.
Cependant, cet excellent article rédigé par Drew Breunig montre quatre façons surprenantes dont le contexte peut devenir incontrôlable, même lorsque le modèle en question prend en charge des fenêtres contextuelles d'un million de tokens. Dans cette section, je vais décrire brièvement les problèmes soulevés par Drew Breunig et les modèles d'ingénierie contextuelle qui permettent de les résoudre. Je vous recommande vivement de lire l'article de Breunig pour plus de détails.
L'empoisonnement du contexte se produit lorsqu'une hallucination ou une erreur se retrouve dans le contexte de votre système d'IA et est ensuite référencée à plusieurs reprises dans les réponses ultérieures. L'équipe DeepMind a identifié ce problème dans son rapport technique sur Gemini 2.5. rapport technique Gemini 2.5 lors de la création d'un agent capable de jouer à Pokémon. Lorsque l'agent avait parfois des hallucinations sur l'état du jeu, ces informations erronées polluaient la section « objectifs » de son contexte, ce qui l'amenait à développer des stratégies absurdes et à poursuivre pendant longtemps des objectifs irréalisables.
Ce problème devient particulièrement grave dans les flux de travail des agents, où les informations s'accumulent. Une fois qu'un contexte erroné est établi, il peut être extrêmement difficile à corriger, car le modèle continue de faire référence aux informations incorrectes comme si elles étaient correctes.
La meilleure solution consiste à valider le contexte et à mettre en quarantaine. Vous pouvez isoler différents types de contexte dans des threads distincts et valider les informations avant qu'elles ne soient ajoutées à la mémoire à long terme. La mise en quarantaine du contexte consiste à créer de nouveaux threads lorsque vous détectez un risque de contamination, ce qui empêche les informations erronées de se propager aux interactions futures.
La distraction contextuelle se produit lorsque votre contexte devient si vaste que le modèle commence à se concentrer excessivement sur l'historique accumulé au lieu d'utiliser ce qu'il a appris pendant l'entraînement. L'agent Gemini jouant à Pokémon a démontré ce phénomène : une fois le contexte dépassé les 100 000 jetons, l'agent a commencé à répéter des actions issues de son vaste historique plutôt que de développer de nouvelles stratégies.
Une étude Databricks (étude très intéressante, à lire absolument) a révélé que l'exactitude des modèles commençait à diminuer à partir de 32 000 jetons pour Llama 3.1 405b, les modèles plus petits atteignant leur limite beaucoup plus tôt. Cela signifie que les modèles commencent à commettre des erreurs bien avant que leurs fenêtres contextuelles ne soient réellement pleines, ce qui remet en question la valeur réelle des fenêtres contextuelles très grandes pour les tâches de raisonnement complexes.
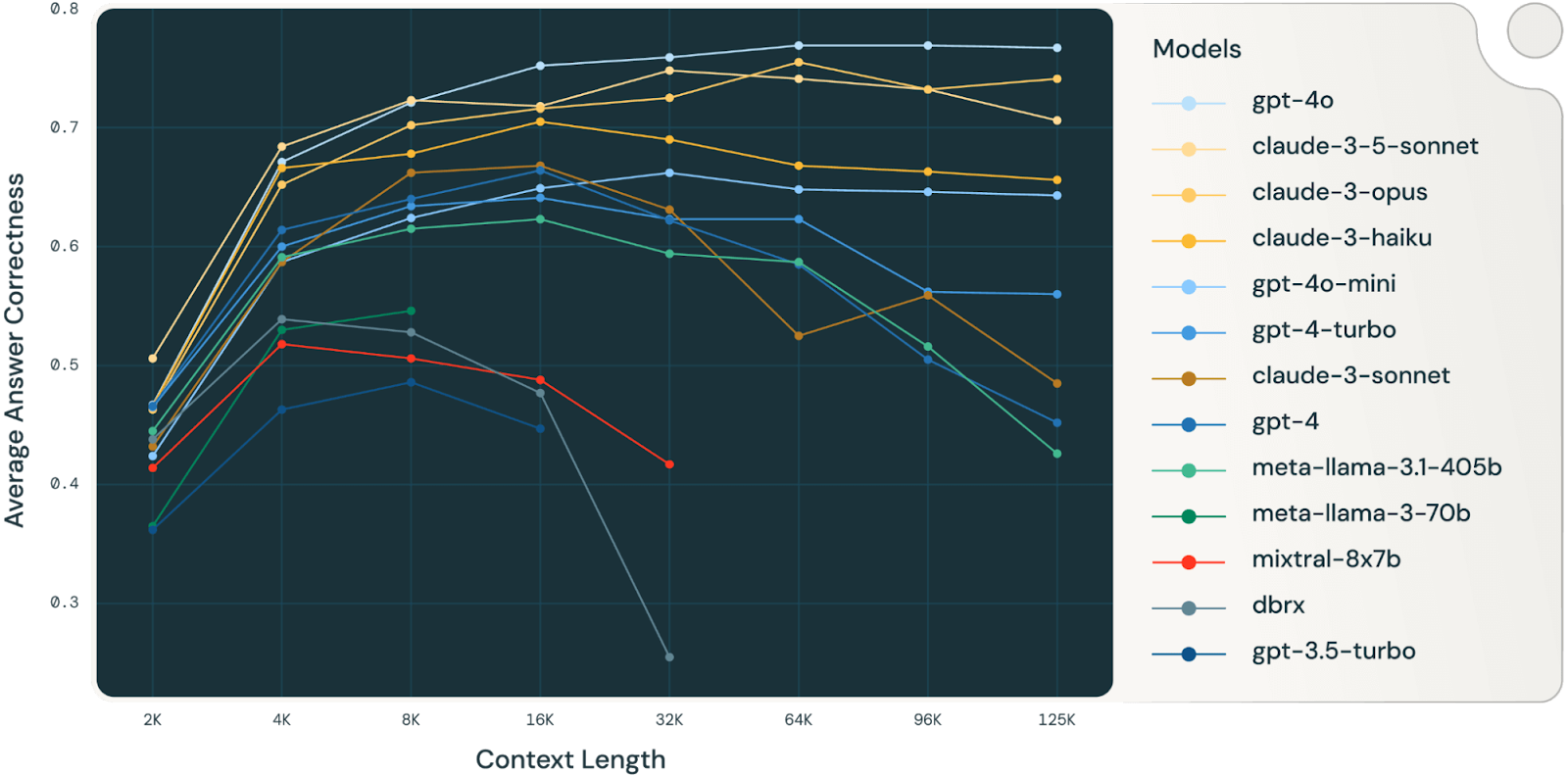
Source : Databricks
La meilleure approche consiste à résumer le contexte. Au lieu de laisser le contexte s'étoffer indéfiniment, vous pouvez compresser les informations accumulées en résumés plus courts qui conservent les détails importants tout en supprimant l'historique redondant. Cela est utile lorsque vous atteignez le seuil de distraction : vous pouvez résumer la conversation jusqu'à présent et repartir sur de bases solides tout en restant cohérent.
La confusion contextuelle survient lorsque vous incluez dans votre contexte des informations supplémentaires que le modèle utilise pour générer des réponses incorrectes, même si ces informations ne sont pas pertinentes pour la tâche en cours. Le classement Berkeley Function-Calling le démontre : tous les modèles obtiennent de moins bons résultats lorsqu'on leur fournit plusieurs outils, et ils font parfois appel à des outils qui n'ont aucun rapport avec la tâche à accomplir.
Le problème s'aggrave avec des modèles plus petits et davantage d'outils. Une étude récente a révélé qu'un Llama 3.1 8b quantifié échouait au benchmark GeoEngine lorsqu'on lui fournissait les 46 outils disponibles, même si le contexte restait largement dans la limite de 16 ko. Cependant, lorsque les chercheurs ont fourni seulement 19 outils au même modèle, celui-ci a fonctionné correctement.
La solution réside dans la gestion des outils à l'aide des techniques RAG. Les recherches menées par Tiantian Gan et Qiyao Sun ont démontré que l'application du RAG aux descriptions d'outils peut réellement améliorer les performances. En stockant les descriptions des outils dans une base de données vectorielle, vous pouvez sélectionner uniquement les outils les plus pertinents pour chaque tâche. Leur étude a démontré que le fait de limiter le nombre d'outils à moins de 30 permettait d'obtenir une précision trois fois supérieure dans la sélection des outils et des invites beaucoup plus courtes.
Un conflit de contexte survient lorsque vous rassemblez dans votre contexte des informations et des outils qui sont en contradiction directe avec d'autres informations déjà présentes. Une étude menée par Microsoft et Salesforce a démontré ce fait en utilisant des invites de référence et en « fragmentant » leurs informations sur plusieurs tours de conversation au lieu de tout fournir en une seule fois. Les résultats ont été impressionnants : une baisse moyenne des performances de 39 %, avec modèle o3 d'OpenAI passant de 98,1 à 64,1.
Source : Laban et al., 2025
Le problème survient lorsque les informations arrivent par étapes, car le contexte assemblé contient les premières tentatives du modèle pour répondre aux questions avant qu'il ne dispose de toutes les informations nécessaires. Ces réponses incorrectes initiales restent dans le contexte et affectent le modèle lorsqu'il génère les réponses finales.
Les meilleures solutions consistent à élaguer le contexte età décharger l'. Le « context pruning » consiste à supprimer les informations obsolètes ou contradictoires à mesure que de nouveaux détails apparaissent. Le déchargement contextuel, tel que proposé par l'outil « think » d'Anthropic, offre aux modèles un espace de travail distinct pour traiter les informations sans encombrer le contexte principal. Cette approche de bloc-notes peut améliorer jusqu'à 54 % les performances des agents spécialisés en empêchant les contradictions internes de perturber le raisonnement.
L'ingénierie contextuelle représente la prochaine étape du développement de l'IA, où l'accent est mis non plus sur la création de messages parfaits, mais sur la mise en place de systèmes capables de gérer le flux d'informations au fil du temps. La capacité à maintenir un contexte pertinent au cours de multiples interactions détermine si votre IA semble intelligente ou si elle se contente de fournir de bonnes réponses ponctuelles.
Les techniques abordées dans ce tutoriel, des systèmes RAG à la validation contextuelle et à la gestion des outils, sont déjà utilisées dans des systèmes de production qui traitent des millions d'utilisateurs.
Si vous développez un système plus complexe qu'un simple générateur de contenu, vous aurez probablement besoin de techniques d'ingénierie contextuelle. La bonne nouvelle, c'est que vous pouvez commencer modestement avec des implémentations RAG de base, puis ajouter progressivement des fonctionnalités plus sophistiquées de gestion de la mémoire et des outils à mesure que vos besoins évoluent.
Pour en savoir plus, je vous recommande les ressources suivantes :
Apprenez l'IA grâce à ces cours !
Cours
Cours
Cours
blog
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
blog
Lynn Heidmann
Tutoriel

