
Curso
Modelos de IA escaláveis com PyTorch Lightning
3 h
1.1K
Você pode ser um mestre em engenharia de prompts, mas, conforme a conversa rola, seu chatbot muitas vezes esquece as partes mais importantes das suas instruções, seu assistente de código perde o controle da arquitetura do projeto e sua ferramenta RAG não consegue conectar informações entre documentos e domínios complexos.
À medida que os casos de uso da IA ficam mais complexos, escrever um prompt inteligente é só uma pequena parte de um desafio muito maior: engenharia de contexto.
Neste tutorial, vou explicar o que é engenharia de contexto, como funciona, quando usar em vez da engenharia de prompt normal e as técnicas práticas que tornam os sistemas de IA mais inteligentes e mais conscientes do contexto.
A gente mantém nossos leitores por dentro das últimas novidades em IA com o The Median, nosso boletim informativo gratuito que sai toda sexta-feira e traz as principais notícias da semana. Inscreva-se e fique por dentro em só alguns minutos por semana:
Engenharia de contexto é quando a gente cria sistemas que decidem quais informações um modelo de IA vai ver antes de dar uma resposta.
Mesmo que o termo seja novo, os princípios por trás da engenharia de contexto já existem há um tempão. Essa nova abstração nos permite pensar sobre a questão mais importante e sempre presente do design do fluxo de informações que entra e sai dos sistemas de IA.
Em vez de escrever prompts perfeitos para pedidos individuais, você cria sistemas que juntam detalhes relevantes de várias fontes e os organizam dentro da janela de contexto do modelo. Isso quer dizer que o seu sistema junta o histórico de conversas, os dados do usuário, os documentos externos e as ferramentas disponíveis, e depois organiza tudo para que o modelo possa trabalhar com eles.
Fonte: 12-factor-agents
Essa abordagem precisa de gerenciar vários tipos diferentes de informações que formam todo o contexto:
O principal desafio é trabalhar dentro das limitações da janela de contexto e, ao mesmo tempo, manter conversas coerentes ao longo do tempo. Seu sistema precisa decidir o que é mais relevante para cada solicitação, o que geralmente significa criar sistemas de recuperação que encontram os detalhes certos quando você precisa deles.
Isso envolve criar sistemas de memória que acompanham tanto o fluxo de conversas de curto prazo quanto as preferências de longo prazo do usuário, além de remover informações desatualizadas para liberar espaço para as necessidades atuais.
A verdadeira vantagem aparece quando diferentes tipos de contexto se juntam para criar sistemas de IA que parecem mais inteligentes e conscientes. Quando seu assistente de IA consegue consultar conversas anteriores, acessar sua agenda e entender seu estilo de comunicação, tudo ao mesmo tempo, as interações deixam de parecer repetitivas e passam a parecer que você está trabalhando com algo que se lembra de você.
Se você pedir ao ChatGPT para “escrever um e-mail profissional”, isso é engenharia de prompt — você está escrevendo instruções para uma única tarefa. Mas se você está criando um bot de atendimento ao cliente que precisa lembrar tickets anteriores, acessar detalhes da conta do usuário e manter o histórico de conversas em várias interações, isso é engenharia de contexto.
Andrej Karpathy explica isso muito bem:
As pessoas associam prompts a descrições curtas de tarefas que você daria a um LLM no seu dia a dia. Em todos os aplicativos LLM de nível industrial, a engenharia de contexto é a arte e a ciência de preencher a janela de contexto com as informações certas para o próximo passo.
Andrej Karpathy
O custo cada vez menor dos tokens LLM também tornou possível a criação de sistemas multiagentes. Em vez de enfiar tudo na janela de contexto de um único modelo, você pode ter agentes especializados que cuidam de diferentes partes de um problema e trocam informações entre si usando protocolos como A2A ou MCP.
Para saber mais sobre agentes de IA, dá uma olhada nessa folha de dicas sobre agentes de IA.
Assistentes de codificação de IA — como o Cursor ou Windsurf— são uma das aplicações mais avançadas da engenharia de contexto, porque juntam os princípios do RAG e do agente enquanto trabalham com informações super estruturadas e interligadas.
Esses sistemas precisam entender não só arquivos individuais, mas toda a arquitetura do projeto, as dependências entre os módulos e os padrões de codificação em toda a sua base de código.
Quando você pede a um assistente de codificação para refatorar uma função, ele precisa saber onde essa função é usada, que tipos de dados ela espera e como as mudanças podem afetar outras partes do seu projeto.
A engenharia de contexto é super importante aqui porque o código tem relações que vão além de vários arquivos e até vários repositórios. Um bom assistente de codificação mantém o contexto sobre a estrutura do seu projeto, as alterações recentes que você fez, seu estilo de codificação e as estruturas que você está usando.
É por isso que ferramentas como o Cursor funcionam melhor quanto mais você usa em um projeto. Eles criam um contexto sobre sua base de código específica e podem dar sugestões mais relevantes com base nos seus padrões e preferências.
Ao ler o artigo, você pode achar que a engenharia de contexto é desnecessária ou que vai ser desnecessária num futuro próximo, já que as janelas de contexto dos modelos de ponta continuam a crescer. Isso seria uma suposição natural, porque se o contexto for grande o suficiente, você poderia jogar tudo em um prompt (ferramentas, documentos, instruções e muito mais) e deixar o modelo cuidar do resto.
Mas, esse artigo incrível escrito por Drew Breunig mostra quatro maneiras surpreendentes pelas quais o contexto pode sair do controle, mesmo quando o modelo em questão suporta janelas de contexto de 1 milhão de tokens. Nesta seção, vou falar rapidinho sobre os problemas que o Drew Breunig falou e os padrões de engenharia de contexto que resolvem esses problemas — recomendo muito ler o artigo do Breunig pra saber mais.
O envenenamento de contexto rola quando uma alucinação ou erro acaba no contexto do seu sistema de IA e depois é referenciada repetidamente em respostas futuras. A equipe da DeepMind percebeu esse problema no seu relatório técnico Gemini 2.5 enquanto criava um agente pra jogar Pokémon. Quando o agente às vezes tinha alucinações sobre o estado do jogo, essas informações falsas contaminavam a seção “objetivos” do seu contexto, fazendo com que ele criasse estratégias sem sentido e perseguisse objetivos impossíveis por muito tempo.
Esse problema fica bem complicado em fluxos de trabalho de agentes, onde as informações se acumulam. Depois que um contexto errado é criado, pode demorar uma eternidade para consertar, porque o modelo continua usando as informações erradas como se fossem certas.
A melhor solução é validar o contexto e colocar em quarentena. Você pode separar diferentes tipos de contexto em threads diferentes e checar as informações antes que elas sejam adicionadas à memória de longo prazo. Quarentena de contexto é começar novas threads quando você percebe um possível problema, o que evita que informações ruins se espalhem para interações futuras.
A distração do contexto rola quando o contexto fica tão grande que o modelo começa a se concentrar demais no histórico acumulado, em vez de usar o que aprendeu durante o treinamento. O agente Gemini que jogava Pokémon mostrou isso: quando o contexto passou de 100.000 tokens, o agente começou a repetir ações do seu vasto histórico, em vez de criar novas estratégias.
Um estudo da Databricks (muito interessante, vale a pena ler) descobriu que a precisão do modelo começou a cair por volta de 32.000 tokens para o Llama 3.1 405b, com modelos menores atingindo seu limite muito antes. Isso quer dizer que os modelos começam a errar muito antes de suas janelas de contexto ficarem realmente cheias, o que faz você questionar o valor real de janelas de contexto muito grandes para tarefas de raciocínio complexas.
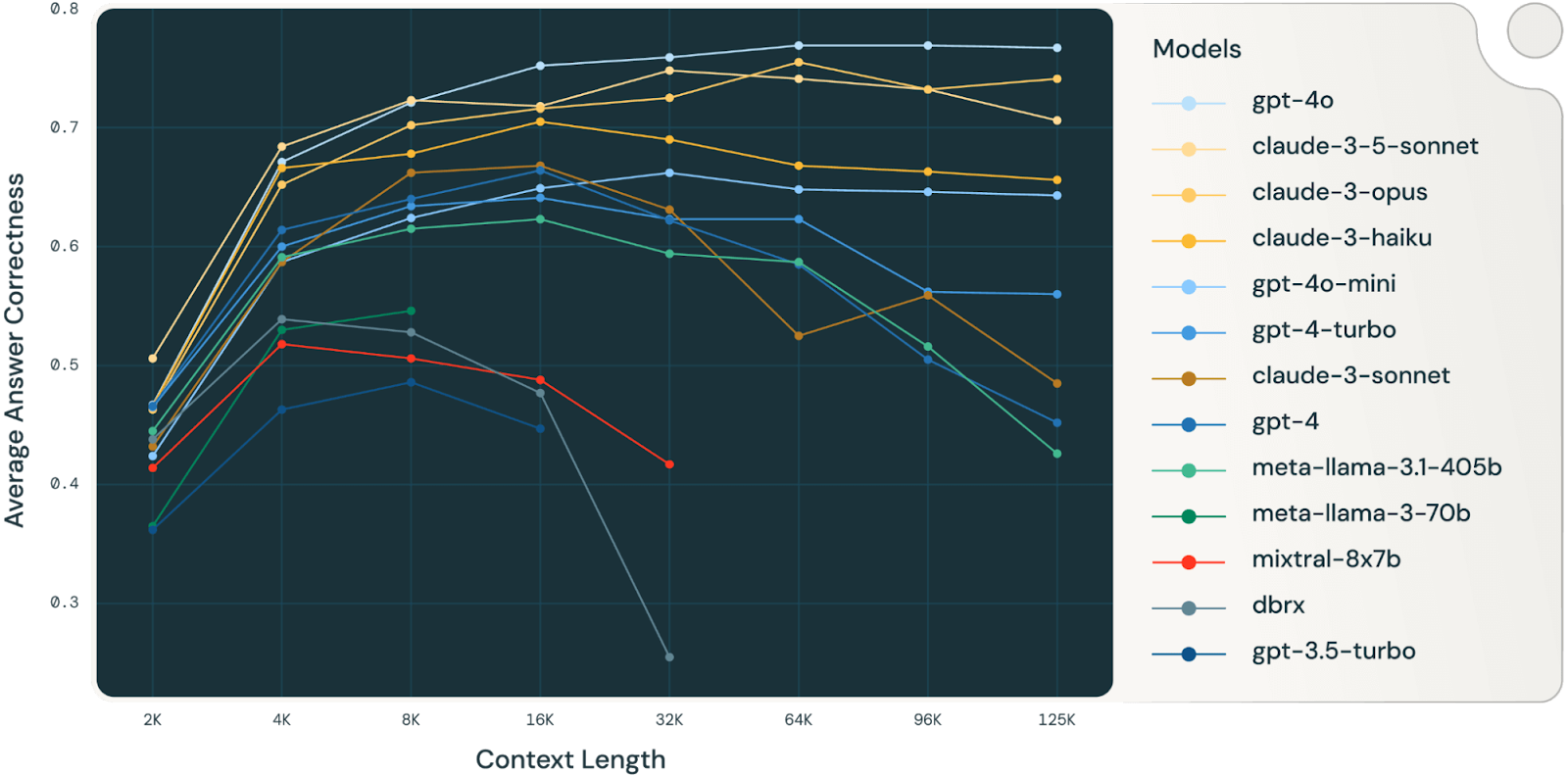
Fonte: Databricks
A melhor maneira é resumir o contexto. Em vez de deixar o contexto crescer sem fim, você pode juntar as informações acumuladas em resumos mais curtos que mantêm os detalhes importantes e tiram o histórico que já não serve mais. Isso ajuda quando você chega ao limite da distração — você pode resumir a conversa até aquele momento e recomeçar, mantendo a coerência.
A confusão de contexto rola quando você coloca informações extras no seu contexto que o modelo usa pra gerar respostas ruins, mesmo quando essas informações não têm nada a ver com a tarefa atual. O Ranking de Chamadas de Funções de Berkeley mostra isso: todos os modelos têm um desempenho pior quando recebem mais de uma ferramenta, e às vezes os modelos chamam ferramentas que não têm nada a ver com a tarefa.
O problema fica pior com modelos menores e mais ferramentas. Um estudo recente descobriu que um Llama 3.1 8b quantizado falhou no benchmark GeoEngine quando recebeu todas as 46 ferramentas disponíveis, mesmo que o contexto estivesse bem dentro do limite de 16k janelas. Mas quando os pesquisadores deram ao mesmo modelo só 19 ferramentas, ele funcionou bem.
A solução é gerenciamento de ferramentas usando técnicas RAG. Uma pesquisa feita por Tiantian Gan e Qiyao Sun mostrou que usar RAG nas descrições de ferramentas pode realmente melhorar o desempenho. Ao guardar as descrições das ferramentas em um banco de dados vetorial, você pode escolher só as ferramentas mais relevantes para cada tarefa. O estudo deles descobriu que manter a seleção de ferramentas abaixo de 30 ferramentas proporcionava uma precisão três vezes maior na seleção de ferramentas e prompts muito mais curtos.
O conflito de contexto rola quando você junta informações e ferramentas no seu contexto que entram em conflito direto com outras informações que já estão lá. Um estudo da Microsoft e da Salesforce mostrou isso usando prompts de referência e “fragmentando” as informações em várias conversas, em vez de fornecer tudo de uma vez. Os resultados foram impressionantes: uma queda média de 39% no desempenho, com o modelo o3 da OpenAI caindo de 98,1 para 64,1.
Fonte: Laban e outros, 2025
O problema rola porque, quando as informações chegam em etapas, o contexto montado tem as primeiras tentativas do modelo de responder às perguntas antes de ter todas as informações. Essas respostas erradas que você deu no começo ficam no contexto e afetam o modelo quando ele gera as respostas finais.
As melhores soluções são a poda de contexto e o offloading. Poda de contexto é quando a gente tira informações que já não servem mais ou que estão confusas quando surgem novos detalhes. Descarregamento de contexto, como a ferramenta “think” da Anthropic, dá aos modelos um espaço de trabalho separado para processar informações sem bagunçar o contexto principal. Essa abordagem de bloco de notas pode melhorar em até 54% os benchmarks de agentes especializados, evitando que contradições internas atrapalhem o raciocínio.
A engenharia de contexto é a próxima fase do desenvolvimento da IA, onde o foco passa de criar prompts perfeitos para construir sistemas que gerenciam o fluxo de informações ao longo do tempo. A capacidade de manter o contexto relevante em várias interações é o que faz a sua IA parecer inteligente ou só dar respostas boas de vez em quando.
As técnicas abordadas neste tutorial — desde sistemas RAG até validação de contexto e gerenciamento de ferramentas — já estão sendo usadas em sistemas de produção que lidam com milhões de usuários.
Se você estiver criando algo mais complexo do que um simples gerador de conteúdo, provavelmente precisará de técnicas de engenharia de contexto. A boa notícia é que você pode começar aos poucos com implementações básicas do RAG e, aos poucos, adicionar gerenciamento de memória e ferramentas mais sofisticados conforme suas necessidades crescerem.
Para saber mais, recomendo estes recursos:
Aprenda IA com esses cursos!
Curso
Curso
Curso
blog
Srujana Maddula
9 min
blog
Matt Crabtree
11 min
blog
Nahla Davies
15 min
Tutorial
Matt Crabtree


