
Kurs
Skalierbare KI-Modelle mit PyTorch Lightning
3 Std.
1.1K
Du bist vielleicht ein Meister der Prompt-Engineering, aber im Laufe des Gesprächs vergisst dein Chatbot oft die ersten und wichtigsten Teile deiner Anweisungen, dein Code-Assistent verliert den Überblick über die Projektarchitektur und dein RAG-Tool kann Informationen aus komplexen Dokumenten und Domänen nicht miteinander verknüpfen.
Da KI-Anwendungsfälle immer komplexer werden, ist das Schreiben einer cleveren Eingabeaufforderung nur ein kleiner Teil einer viel größeren Herausforderung: Kontext-Engineering.
In diesem Tutorial erkläre ich, was Context Engineering ist, wie es funktioniert, wann man es anstelle von normalem Prompt Engineering verwenden sollte und welche praktischen Techniken KI-Systeme intelligenter und kontextbewusster machen.
Wir halten unsere Leser über die neuesten Entwicklungen im Bereich KI auf dem Laufenden, indem wir ihnen jeden Freitag unseren kostenlosen Newsletter „The Median“ schicken, der die wichtigsten Meldungen der Woche zusammenfasst. Abonniere unseren Newsletter und bleib in nur wenigen Minuten pro Woche auf dem Laufenden:
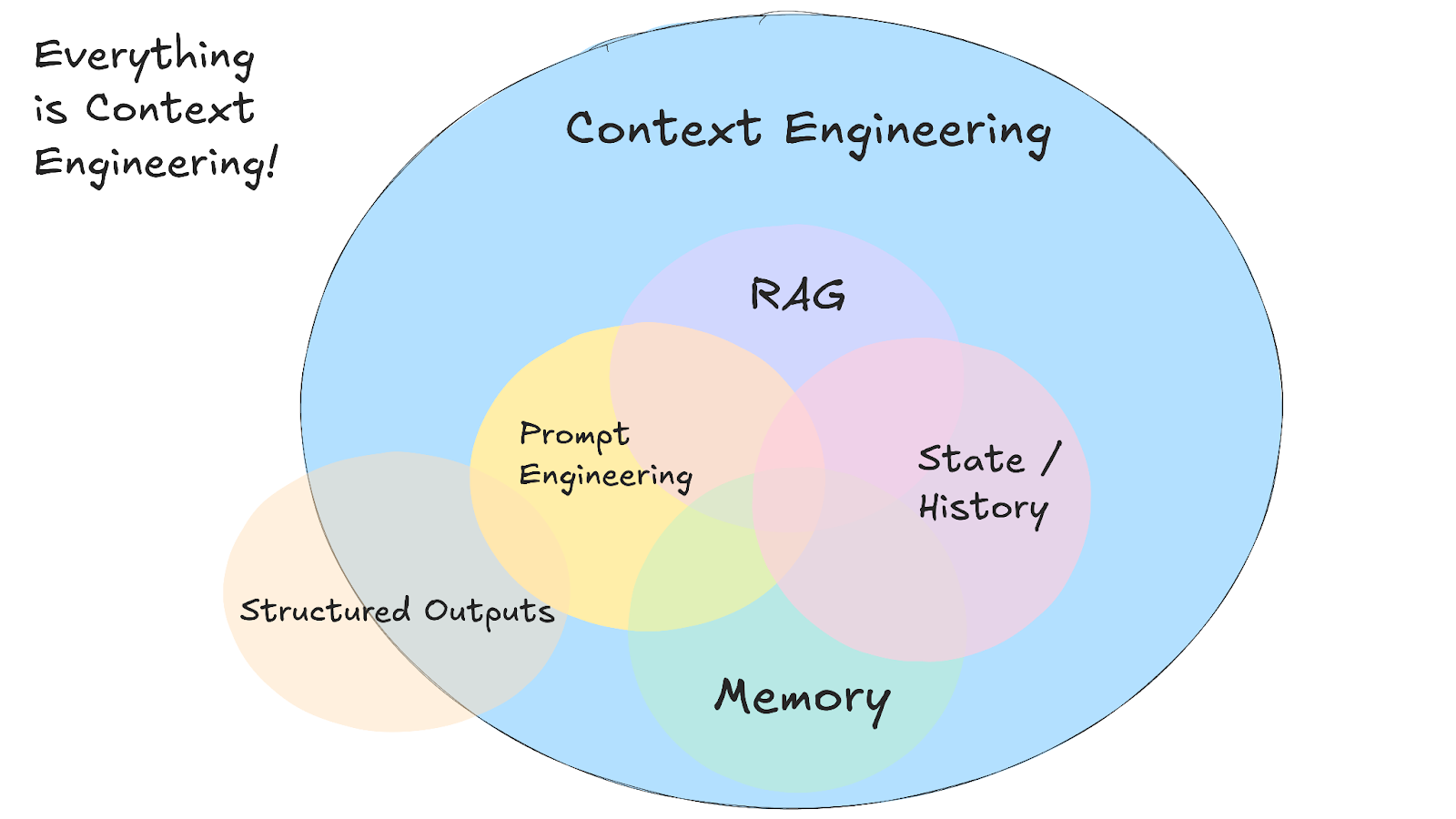
Kontext-Engineering ist die Praxis, Systeme zu entwickeln, die entscheiden, welche Infos ein KI-Modell sieht, bevor es eine Antwort gibt.
Auch wenn der Begriff neu ist, gibt es die Prinzipien hinter dem Context Engineering schon eine ganze Weile. Mit dieser neuen Abstraktion können wir uns mit dem wichtigsten und allgegenwärtigen Problem der Gestaltung des Informationsflusses in und aus KI-Systemen auseinandersetzen.
Anstatt perfekte Eingabeaufforderungen für einzelne Anfragen zu schreiben, erstellst du Systeme, die relevante Details aus mehreren Quellen sammeln und im Kontextfenster des Modells organisieren. Das heißt, dein System sammelt den Gesprächsverlauf, Benutzerdaten, externe Dokumente und verfügbare Tools und formatiert sie so, dass das Modell damit arbeiten kann.
Quelle: 12-Faktor-Agenten
Dieser Ansatz erfordert die Verwaltung mehrerer verschiedener Arten von Informationen, die den vollständigen Kontext bilden:
Die größte Herausforderung ist, innerhalb der Beschränkungen des Kontextfensters zu arbeiten und dabei die Gespräche über die Zeit hinweg zusammenhängend zu halten. Dein System muss entscheiden, was für jede Anfrage am relevantesten ist. Dazu musst du Abrufsysteme entwickeln, die die richtigen Details finden, wenn du sie brauchst.
Dazu muss man sich merken, wie Gespräche ablaufen und was man schon weiß, und alte Infos löschen, damit Platz für Neues ist.
Der eigentliche Vorteil zeigt sich, wenn verschiedene Arten von Kontexten zusammenarbeiten, um KI-Systeme zu schaffen, die intelligenter und bewusster wirken. Wenn dein KI-Assistent auf frühere Gespräche zurückgreifen, deinen Kalender checken und deinen Kommunikationsstil verstehen kann, fühlen sich Interaktionen nicht mehr langweilig an, sondern es ist, als würdest du mit jemandem arbeiten, der sich an dich erinnert.
Wenn du ChatGPT bittest, „eine professionelle E-Mail zu schreiben“, ist das Prompt Engineering – du schreibst Anweisungen für eine einzelne Aufgabe. Aber wenn du einen Kundenservice-Bot entwickelst, der sich frühere Tickets merken, auf Benutzerkontodaten zugreifen und den Gesprächsverlauf über mehrere Interaktionen hinweg speichern muss, dann ist das Context Engineering.
Andrej Karpathy erklärt das gut:
Leute denken bei Prompts an kurze Aufgabenbeschreibungen, die du einem LLM im Alltag gibst. In jeder industrietauglichen LLM-App ist Context Engineering die Kunst und Wissenschaft, das Kontextfenster mit genau den Infos zu füllen, die für den nächsten Schritt gebraucht werden.
Andrej Karpathy
Die sinkenden Kosten für LLM-Token haben auch Multi-Agenten-Systeme möglich gemacht. Anstatt alles in das Kontextfenster eines einzigen Modells zu stopfen, kannst du spezialisierte Agenten einsetzen, die verschiedene Aspekte eines Problems bearbeiten und Informationen über Protokolle wie A2A oder MCPaustauschen.
Wenn du mehr über KI-Agenten erfahren möchtest, schau dir diesen Spickzettel zu KI-Agenten.
KI-Coding-Assistenten – wie Cursor oder Windsurf– sind eine der modernsten Anwendungen von Context Engineering, weil sie sowohl RAG- als auch Agentenprinzipien kombinieren und dabei mit stark strukturierten, miteinander verbundenen Infos arbeiten.
Diese Systeme müssen nicht nur einzelne Dateien verstehen, sondern auch ganze Projektarchitekturen, Abhängigkeiten zwischen Modulen und Codierungsmuster in deiner gesamten Codebasis.
Wenn du einen Programmierassistenten bittest, eine Funktion umzugestalten, braucht er Infos darüber, wo diese Funktion verwendet wird, welche Datentypen sie erwartet und wie sich Änderungen auf andere Teile deines Projekts auswirken könnten.
Hier wird Context Engineering echt wichtig, weil Code Beziehungen hat, die sich über mehrere Dateien und sogar mehrere Repositorys erstrecken. Ein guter Programmierassistent behält den Überblick über deine Projektstruktur, die letzten Änderungen, deinen Programmierstil und die verwendeten Frameworks.
Deshalb funktionieren Tools wie Cursor umso besser, je länger du sie in einem Projekt benutzt. Sie sammeln Infos über deine spezifische Codebasis und können dir so bessere Vorschläge machen, die zu deinen Mustern und Vorlieben passen.
Beim Lesen des Artikels denkst du vielleicht, dass Context Engineering unnötig ist oder in naher Zukunft unnötigsein wird, da die Kontextfenster von Frontier-Modellen immer größer werden. Das wäre eine logische Annahme, denn wenn der Kontext groß genug ist,könntest du einfach alles in eine Eingabeaufforderung werfen (Tools, Dokumente, Anweisungen und mehr) und das Modell den Rest erledigen lassen.
Allerdings dieser super Artikel von Drew Breunig zeigt vier überraschende Möglichkeiten auf, wie der Kontext außer Kontrolle geraten kann, selbst wenn das betreffende Modell 1 Million Token-Kontextfenster unterstützt. In diesem Abschnitt werde ich kurz die von Drew Breunig beschriebenen Probleme und die Context Engineering-Muster zu ihrer Lösung erläutern. Für weitere Details empfehle ich dringend, den Artikel von Breunig zu lesen.
Kontextvergiftung passiert, wenn eine Halluzination oder Fehler in den Kontext deines KI-Systems gelangt und dann in zukünftigen Antworten immer wieder referenziert wird. Das DeepMind-Team hat dieses Problem in seinem technischen Bericht zu Gemini 2.5 erkannt und erklärt, dass es sich um ein Problem mit technischen Bericht „Gemini 2.5”, als es einen Agenten zum Spielen von Pokémon entwickelt hat. Wenn der Agent manchmal Halluzinationen über den Spielstand hatte, haben diese falschen Infos den Abschnitt „Ziele“ seines Kontexts durcheinandergebracht, sodass der Agent unsinnige Strategien entwickelt und lange Zeit unmögliche Ziele verfolgt hat.
Dieses Problem wird in Agent-Workflows, wo sich Informationen ansammeln, richtig schlimm. Sobald ein vergifteter Kontext entstanden ist, kann es ewig dauern, ihn zu beheben, weil das Modell immer wieder auf die falschen Infos zugreift, als wären sie richtig.
Die beste Lösung ist die Kontextüberprüfung und Quarantäne. Du kannst verschiedene Arten von Kontext in separaten Threads isolieren und Infos überprüfen, bevor sie in den Langzeitgedächtnis gespeichert werden. Kontext-Quarantäne heißt, dass neue Threads gestartet werden, wenn du potenzielle Vergiftungen findest. So wird verhindert, dass schlechte Infos in zukünftige Interaktionen gelangen.
Kontextablenkung passiert, wenn der Kontext so groß wird, dass das Modell sich zu sehr auf die gesammelten Daten konzentriert, anstatt das anzuwenden, was es beim Training gelernt hat. Der Gemini-Agent, der Pokémon spielte, zeigte das – sobald der Kontext über 100.000 Tokens hinausging, fing der Agent an, Aktionen aus seiner umfangreichen Historie zu wiederholen, anstatt neue Strategien zu entwickeln.
Eine Databricks-Studie (sehr interessante Studie, die man unbedingt lesen sollte) hat herausgefunden, dass die Modellgenauigkeit bei etwa 32.000 Tokens für Llama 3.1 405b, wobei kleinere Modelle ihre Grenze schon viel früher erreichten. Das heißt, dass die Modelle schon Fehler machen, lange bevor ihre Kontextfenster voll sind. Da fragt man sich, wie sinnvoll richtig große Kontextfenster für komplexe Denkaufgaben wirklich sind.
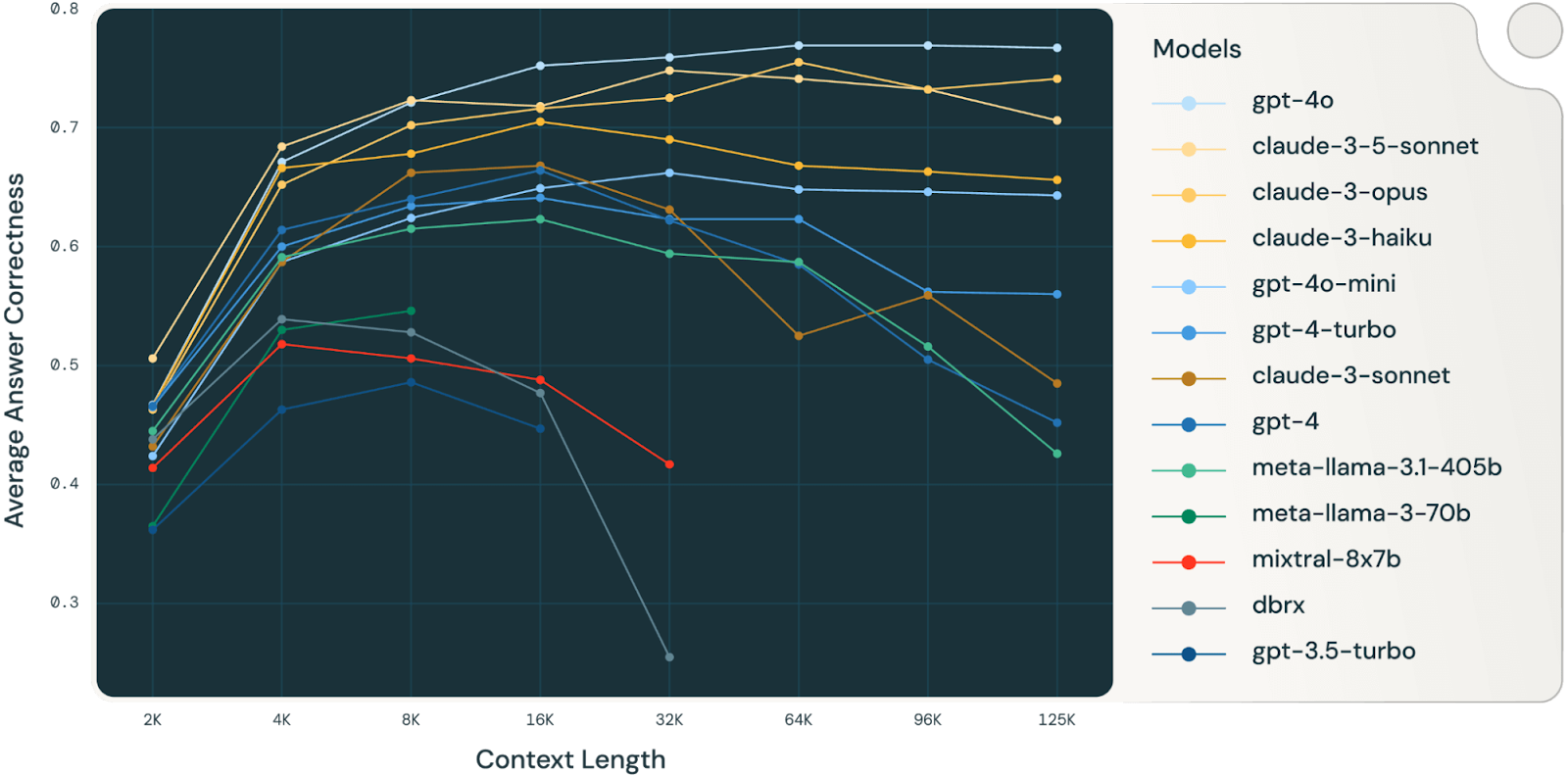
Quelle: Databricks
Am besten ist es, den Kontext zusammenzufassen. Anstatt den Kontext immer weiter wachsen zu lassen, kannst du gesammelte Infos in kürzere Zusammenfassungen packen, die wichtige Details behalten und überflüssige Infos weglassen. Das ist super, wenn du mal nicht weiter weißt – du kannst das bisher Gesagte zusammenfassen und dann frisch weitermachen, ohne den Faden zu verlieren.
Kontextverwirrung passiert, wenn du zusätzliche Infos in deinen Kontext packst, die das Modell dann für falsche Antworten nutzt, auch wenn diese Infos für die aktuelle Aufgabe gar nicht wichtig sind. Die Berkeley-Rangliste für Funktionsaufrufe zeigt das – jedes Modell schneidet schlechter ab, wenn es mehr als ein Tool bekommt, und manchmal rufen die Modelle Tools auf, die gar nichts mit der Aufgabe zu tun haben.
Das Problem wird bei kleineren Modellen und mehr Tools noch schlimmer. Eine aktuelle Studie hat gezeigt, dass ein quantisiertes Llama 3.1 8b beim GeoEngine-Benchmark mit allen 46 verfügbaren Tools durchgefallen ist, obwohl der Kontext locker innerhalb der 16k-Fenstergrenze lag. Aber als die Forscher dem gleichen Modell nur 19 Werkzeuge gaben, funktionierte es einwandfrei.
Die Lösung ist Verwaltung der Werkzeugausstattung mit RAG-Techniken. Eine Studie von Tiantian Gan und Qiyao Sun „ ” hat gezeigt, dass die Anwendung von RAG auf Werkzeugbeschreibungen die Leistung wirklich verbessern kann. Durch das Speichern von Werkzeugbeschreibungen in einer Vektordatenbankkannst du für jede Aufgabe nur die relevantesten Werkzeuge auswählen. Ihre Studie hat gezeigt, dass man mit weniger als 30 Tools dreimal genauer das richtige Tool findet und die Eingabeaufforderungen viel kürzer sind.
Ein Kontextkonflikt tritt auf, wenn du in deinem Kontext Infos und Tools sammelst, die direkt mit anderen Infos, die schon da sind, nicht zusammenpassen. Eine Studie von Microsoft und Salesforce hat das gezeigt, indem sie Benchmark-Eingabeaufforderungen genommen und die Infos über mehrere Gesprächsrunden verteilt haben, anstatt alles auf einmal zu liefern. Die Ergebnisse waren echt krass – ein durchschnittlicher Leistungsabfall von 39 %, wobei OpenAI-Modell o3 von 98,1 auf 64,1.
Quelle: Laban et al., 2025
Das Problem passiert, weil, wenn Infos in Etappen reinkommen, der zusammengesetzte Kontext frühe Versuche des Modells enthält, Fragen zu beantworten, bevor es alle Infos hat. Diese falschen ersten Antworten bleiben im Kontext und beeinflussen das Modell, wenn es die endgültigen Antworten generiert.
Die besten Lösungen sind das Bereinigen des Kontexts und das Auslagern von. Kontextbereinigung heißt, dass man alte oder widersprüchliche Infos löscht, wenn neue Details auftauchen. Kontext-Offloading, wie zum Beispiel das „Think”-Tool von Anthropic, gibt Modellen einen separaten Arbeitsbereich, um Infos zu verarbeiten, ohne den Hauptkontext zu überladen. Dieser Scratchpad-Ansatz kann bis zu 54 % Verbesserung bei speziellen Agenten-Benchmarks bringen, indem er verhindert, dass interne Widersprüche die Argumentation durcheinanderbringen.
Kontext-Engineering ist die nächste Stufe in der KI-Entwicklung, wo es nicht mehr nur darum geht, perfekte Eingabeaufforderungen zu erstellen, sondern Systeme zu entwickeln, die den Informationsfluss über einen längeren Zeitraum verwalten. Ob deine KI intelligent wirkt oder nur gute Antworten gibt, hängt davon ab, ob sie den Kontext über mehrere Interaktionen hinweg im Blick behalten kann.
Die in diesem Tutorial behandelten Techniken – von RAG-Systemen über Kontextvalidierung bis hin zum Tool-Management – werden bereits in Produktionssystemen eingesetzt, die Millionen von Nutzern bedienen.
Wenn du was Komplexeres als einen einfachen Content-Generator baust, brauchst du wahrscheinlich Context-Engineering-Techniken. Die gute Nachricht ist, dass du mit einfachen RAG-Implementierungen klein anfangen und nach und nach komplexere Speicher- und Tool-Management-Funktionen hinzufügen kannst, wenn dein Bedarf wächst.
Für mehr Infos empfehle ich dir diese Quellen:
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Mark Pedigo
Tutorial
Derrick Mwiti
Tutorial
Matt Crabtree
Tutorial
Moez Ali