
Curso
Modelos de IA escalables con PyTorch Lightning
3 h
1.1K
Puede que seas un ingeniero de prompts experto, pero a medida que avanza la conversación, tu chatbot suele olvidar las partes más importantes y iniciales de tus instrucciones, tu asistente de código pierde el hilo de la arquitectura del proyecto y tu herramienta RAG no puede conectar la información de documentos y dominios complejos.
A medida que los casos de uso de la IA se vuelven más complejos, escribir un mensaje inteligente es solo una pequeña parte de un reto mucho mayor: la ingeniería de contexto.
En este tutorial, explicaré qué es la ingeniería de contexto, cómo funciona, cuándo utilizarla en lugar de la ingeniería de prompts habitual y las técnicas prácticas que hacen que los sistemas de IA sean más inteligentes y conscientes del contexto.
Mantenemos a nuestros lectores al día sobre las últimas novedades en IA mediante el envío de The Median, nuestro boletín informativo gratuito de los viernes que resume las noticias más importantes de la semana. Suscríbete y mantente al día en solo unos minutos a la semana:
La ingeniería de contexto es la práctica de diseñar sistemas que deciden qué información ve un modelo de IA antes de generar una respuesta.
Aunque el término es nuevo, los principios que subyacen a la ingeniería contextual existen desde hace bastante tiempo. Esta nueva abstracción nos permite razonar sobre el problema más importante y omnipresente del diseño del flujo de información que entra y sale de los sistemas de IA.
En lugar de escribir indicaciones perfectas para solicitudes individuales, creas sistemas que recopilan detalles relevantes de múltiples fuentes y los organizan dentro de la ventana de contexto del modelo. Esto significa que tu sistema recopila el historial de conversaciones, los datos de los usuarios, los documentos externos y las herramientas disponibles, y luego los formatea para que el modelo pueda trabajar con ellos.
Fuente: 12-agentes-factores
Este enfoque requiere gestionar varios tipos diferentes de información que conforman el contexto completo:
El principal reto es trabajar dentro de las limitaciones de la ventana contextual y mantener conversaciones coherentes a lo largo del tiempo. Tu sistema debe decidir qué es lo más relevante para cada solicitud, lo que normalmente implica crear sistemas de recuperación que encuentren los detalles adecuados cuando los necesites.
Esto implica crear sistemas de memoria que programen tanto el flujo de conversaciones a corto plazo como las preferencias a largo plazo de los usuarios, además de eliminar la información obsoleta para dejar espacio a las necesidades actuales.
El beneficio real se obtiene cuando diferentes tipos de contexto trabajan juntos para crear sistemas de IA que parecen más inteligentes y conscientes. Cuando tu asistente de IA puede consultar conversaciones anteriores, acceder a tu calendario y comprender tu estilo de comunicación, todo al mismo tiempo, las interacciones dejan de parecer repetitivas y empiezan a dar la sensación de que estás trabajando con algo que te recuerda quién eres.
Si le pides a ChatGPT que «escriba un correo electrónico profesional», eso es ingeniería de prompts: estás escribiendo instrucciones para una sola tarea. Pero si estás creando un bot de atención al cliente que necesita recordar tickets anteriores, acceder a los detalles de la cuenta del usuario y mantener el historial de conversaciones a lo largo de múltiples interacciones, eso es ingeniería de contexto.
Andrej Karpathy lo explica muy bien:
La gente asocia las indicaciones con descripciones breves de tareas que se le darían a un LLM en su uso diario. En todas las aplicaciones LLM de potencia industrial, la ingeniería de contexto es el delicado arte y ciencia de llenar la ventana de contexto con la información adecuada para el siguiente paso.
Andrej Karpathy
El coste decreciente de los tokens LLM también hizo posibles los sistemas multiagente. En lugar de abarcarlo todo en la ventana de contexto de un único modelo, puedes disponer de agentes especializados que se encarguen de diferentes aspectos de un problema y compartan información entre ellos a través de protocolos como A2A o MCP.
Para obtener más información sobre los agentes de IA, consulta esta hoja de referencia sobre agentes de IA.
Asistentes de codificación con IA, como Cursor o Windsurf—representan una de las aplicaciones más avanzadas de la ingeniería contextual, ya que combinan los principios de RAG y de los agentes mientras trabajan con información altamente estructurada e interconectada.
Estos sistemas deben comprender no solo los archivos individuales, sino también las arquitecturas completas de los proyectos, las dependencias entre módulos y los patrones de codificación de todo el código base.
Cuando le piden a un asistente de codificación que refactorice una función, necesita contexto sobre dónde se utiliza esa función, qué tipos de datos espera y cómo los cambios podrían afectar a otras partes de tu proyecto.
La ingeniería de contexto se vuelve fundamental aquí porque el código tiene relaciones que abarcan varios archivos e incluso varios repositorios. Un buen asistente de programación mantiene el contexto sobre la estructura de tu proyecto, los cambios recientes que has realizado, tu estilo de programación y los marcos de trabajo que utilizas.
Por eso, herramientas como Cursor funcionan mejor cuanto más tiempo las usas en un proyecto. Crean un contexto sobre tu código específico y pueden hacer sugerencias más relevantes basadas en tus patrones y preferencias.
A medida que leas el artículo, es posible que pienses que la ingeniería de contexto es innecesaria o que lo será en un futuro próximo, a medida que las ventanas de contexto de los modelos de vanguardia sigan creciendo. Esta sería una suposición lógica, ya que si el contexto es lo suficientemente amplio, podría introducir todo en un prompt (herramientas, documentos, instrucciones y mucho más) y dejar que el modelo se encargara del resto.
Sin embargo, este excelente artículo escrito por Drew Breunig muestra cuatro formas sorprendentes en las que el contexto puede salirse de control, incluso cuando el modelo en cuestión admite ventanas de contexto de 1 millón de tokens. En esta sección, describiré brevemente los problemas descritos por Drew Breunig y los patrones de ingeniería de contexto que los resuelven. Recomiendo encarecidamente leer el artículo de Breunig para obtener más detalles.
El envenenamiento del contexto se produce cuando una alucinación o un error acaba en el contexto de tu sistema de IA y luego se hace referencia a él una y otra vez en respuestas futuras. El equipo de DeepMind identificó este problema en su informe técnico Gemini 2.5 mientras creaba un agente para jugar a Pokémon. Cuando el agente tenía alucinaciones sobre el estado del juego, esta información falsa contaminaba la sección «objetivos» de su contexto, lo que provocaba que el agente desarrollara estrategias sin sentido y persiguiera objetivos imposibles durante mucho tiempo.
Este problema se agrava en los flujos de trabajo de los agentes, donde se acumula mucha información. Una vez que se establece un contexto contaminado, puede llevar mucho tiempo solucionarlo, ya que el modelo sigue haciendo referencia a la información falsa como si fuera verdadera.
La mejor solución es la validación del contexto y la cuarentena. Puedes aislar diferentes tipos de contexto en hilos separados y validar la información antes de que se añada a la memoria a largo plazo. La cuarentena de contexto significa iniciar nuevos hilos cuando detectas un posible envenenamiento, lo que evita que la información errónea se propague a futuras interacciones.
La distracción del contexto se produce cuando el contexto se vuelve tan amplio que el modelo comienza a centrarse demasiado en el historial acumulado en lugar de utilizar lo que ha aprendido durante el entrenamiento. El agente Gemini que jugaba a Pokémon lo demostró: una vez que el contexto superó los 100 000 tokens, el agente comenzó a repetir acciones de su vasto historial en lugar de desarrollar nuevas estrategias.
Un estudio de Databricks (muy interesante, vale la pena leerlo) descubrió que la precisión del modelo comenzaba a disminuir en torno a los 32 000 tokens para Llama 3.1 405b, y que los modelos más pequeños alcanzaban su límite mucho antes. Esto significa que los modelos comienzan a cometer errores mucho antes de que sus ventanas de contexto estén realmente llenas, lo que te lleva a cuestionar el valor real de las ventanas de contexto muy grandes para tareas de razonamiento complejo.
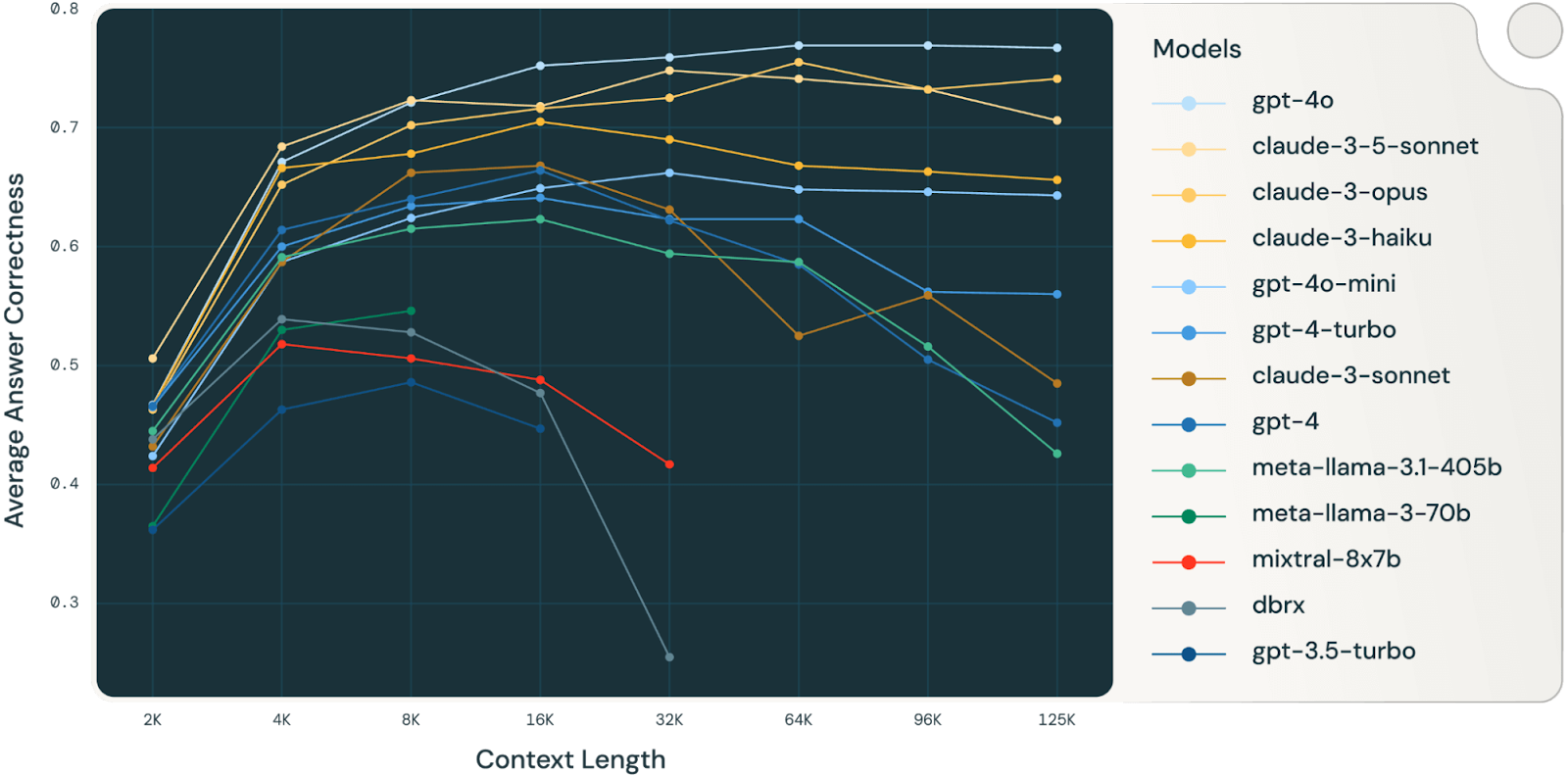
Fuente: Databricks
El mejor enfoque es la síntesis contextual. En lugar de dejar que el contexto crezca sin fin, puedes comprimir la información acumulada en resúmenes más breves que conservan los detalles importantes y eliminan el historial redundante. Esto resulta útil cuando alcanzas el límite de distracción: puedes resumir la conversación hasta ese momento y empezar de nuevo sin perder el hilo.
La confusión contextual se produce cuando incluyes información adicional en el contexto que el modelo utiliza para generar respuestas erróneas, incluso cuando dicha información no es relevante para la tarea actual. El clasificación de Berkeley sobre llamadas a funciones lo demuestra: todos los modelos obtienen peores resultados cuando se les proporciona más de una herramienta y, en ocasiones, los modelos llaman a herramientas que no tienen nada que ver con la tarea.
El problema se agrava con modelos más pequeños y más herramientas. Un estudio reciente descubrió que un Llama 3.1 8b cuantificado falló en la prueba GeoEngine cuando se le proporcionaron las 46 herramientas disponibles, a pesar de que el contexto se encontraba dentro del límite de 16 000 ventanas. Pero cuando los investigadores proporcionaron al mismo modelo solo 19 herramientas, funcionó correctamente.
La solución es gestión de la carga de herramientas mediante técnicas RAG. La investigación realizada por Tiantian Gan y Qiyao Sun demostró que aplicar RAG a las descripciones de herramientas puede mejorar realmente el rendimiento. Al almacenar las descripciones de las herramientas en una base de datos vectorial, puedes seleccionar solo las herramientas más relevantes para cada tarea. Su estudio reveló que limitar la selección de herramientas a menos de 30 proporcionaba una precisión tres veces mayor y mensajes mucho más breves.
El conflicto de contexto se produce cuando recopilas información y herramientas en tu contexto que entran en conflicto directo con otra información ya existente. Un estudio realizado por Microsoft y Salesforce lo demostró tomando indicaciones de referencia y «fragmentando» su información en múltiples turnos de conversación en lugar de proporcionar toda la información de una sola vez. Los resultados fueron enormes: una caída media del rendimiento del 39 %, con el modelo o3 de OpenAI de OpenAI pasó de 98,1 a 64,1.
Fuente: Laban et. al, 2025
El problema se produce porque, cuando la información llega por etapas, el contexto recopilado contiene los primeros intentos del modelo por responder a las preguntas antes de disponer de toda la información. Estas respuestas incorrectas iniciales permanecen en el contexto y afectan al modelo cuando genera las respuestas finales.
Las mejores soluciones son la poda de contexto y la descarga. La poda contextual consiste en eliminar información obsoleta o contradictoria a medida que se obtienen nuevos datos. Descarga de contexto, como la herramienta «think» de Anthropic, proporciona a los modelos un espacio de trabajo independiente para procesar la información sin saturar el contexto principal. Este enfoque de bloc de notas puede proporcionar hasta un 54 % de mejora en las pruebas de rendimiento de agentes especializados, al evitar que las contradicciones internas alteren el razonamiento.
La ingeniería contextual representa la siguiente fase del desarrollo de la IA, en la que el enfoque pasa de crear indicaciones perfectas a construir sistemas que gestionen el flujo de información a lo largo del tiempo. La capacidad de mantener un contexto relevante a lo largo de múltiples interacciones determina si tu IA parece inteligente o si solo da buenas respuestas puntuales.
Las técnicas que se tratan en este tutorial, desde los sistemas RAG hasta la validación del contexto y la gestión de herramientas, ya se están utilizando en sistemas de producción que gestionan millones de usuarios.
Si estás creando algo más complejo que un simple generador de contenido, probablemente necesitarás técnicas de ingeniería de contexto. La buena noticia es que puedes empezar poco a poco con implementaciones básicas de RAG y añadir gradualmente una gestión más sofisticada de la memoria y las herramientas a medida que crezcan tus necesidades.
Para obtener más información, te recomiendo los siguientes recursos:
¡Aprende IA con estos cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
blog
Zoumana Keita
14 min
blog
Adel Nehme
15 min
Tutorial


