Program
Dasar-Dasar Pembelajaran Mesin dalam Python
16 Hr
Penambangan aturan asosiasi menjadi penting bagi bisnis yang ingin memahami perilaku pelanggan dan pola pembelian. Teknik ini mengidentifikasi item yang sering dibeli bersama, membantu perusahaan mengoptimalkan penempatan produk, promosi, dan rekomendasi. Analisis semacam ini meningkatkan strategi bisnis dengan mengungkap tren tersembunyi dalam data transaksi.
Algoritma Apriori adalah metode populer untuk menambang aturan asosiasi ini karena kesederhanaan dan hasilnya yang praktis. Berbeda dengan metode lain yang kompleks, Apriori langsung dan mudah dipahami, sehingga cocok untuk pemula serta efektif di aplikasi dunia nyata.
Artikel ini menjelaskan algoritma Apriori, menggambarkan alurnya dengan contoh yang jelas, dan menunjukkan cara menggunakannya secara efektif. Jika Anda ingin praktik langsung dengan konsep machine learning, lihat Machine Learning Scientist in Python career track kami.
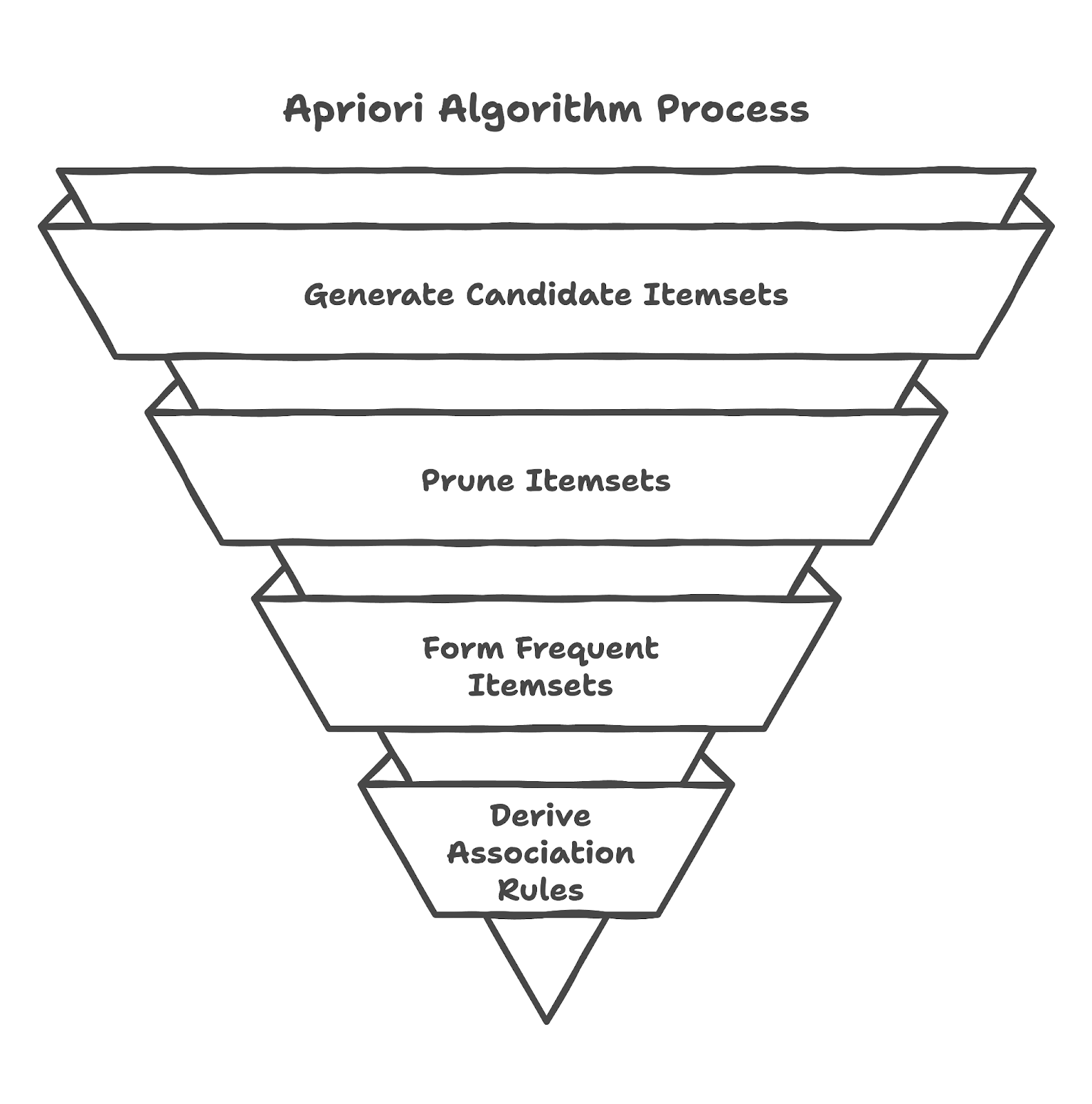
Seperti yang akan Anda temukan dari Tutorial Association Rule Mining in Python kami, Apriori adalah algoritma yang dirancang untuk mengekstrak himpunan item sering (frequent itemsets) dari basis data transaksional dan menghasilkan aturan asosiasi. Algoritma ini didasarkan pada prinsip bahwa jika suatu itemset sering muncul, maka semua subset-nya juga harus sering. Asumsi ini membantu mengurangi jumlah kemungkinan itemset yang perlu diperiksa, sehingga proses menjadi efisien.
Dataset untuk Apriori biasanya terdiri dari transaksi, di mana setiap transaksi adalah kumpulan item yang dibeli bersamaan. Misalnya, data penjualan supermarket dapat berisi transaksi seperti:
Setiap transaksi ini mewakili keranjang item yang dibeli dalam satu kali pembelian. Kursus Market Basket Analysis in Python kami membahas lebih detail tentang penerapan konsep ini di Python.
Penambangan aturan asosiasi bergantung pada tiga metrik utama:
Support: Frekuensi kemunculan suatu item dalam dataset. Dihitung sebagai:
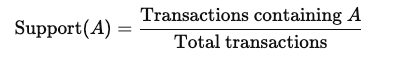
Confidence: Kemungkinan item B dibeli ketika item A dibeli, diberikan oleh:

Lift: Kekuatan suatu aturan, mengukur seberapa jauh item B lebih mungkin dibeli ketika item A dibeli dibandingkan saat dibeli secara independen:
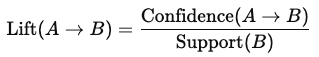
Nilai lift lebih dari 1 menunjukkan asosiasi positif yang kuat antar item.
Mari kita lihat bagaimana algoritma Apriori bekerja.
Pertimbangkan dataset dengan transaksi:
Dengan minimum support 50%, algoritma mengidentifikasi itemset sering dan mengekstrak aturan seperti:
Aturan-aturan ini membantu bisnis memahami perilaku pembelian dan mengoptimalkan persediaan.
Pada bagian ini, Anda mempelajari cara mengimplementasikan algoritma Apriori di Python.
Untuk menggunakan Apriori di Python, pasang pustaka yang diperlukan:
pip install mlxtend pandasLangkah berikutnya adalah memuat paket dan menyiapkan data:
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
# Expanded dataset
data = {
'Milk': [1, 1, 0, 1, 0, 1, 0, 1, 1, 0],
'Bread': [1, 0, 1, 1, 1, 0, 1, 0, 1, 1],
'Butter': [0, 1, 1, 1, 1, 1, 0, 1, 1, 0],
'Eggs': [1, 0, 0, 1, 1, 1, 1, 0, 0, 1],
'Cheese': [0, 1, 1, 0, 1, 1, 0, 1, 0, 1],
'Diaper': [0, 1, 0, 1, 0, 1, 1, 1, 0, 0],
'Beer': [1, 0, 1, 0, 1, 0, 1, 0, 1, 1]
}
df = pd.DataFrame(data)Berikutnya, terapkan algoritmanya.
# Generating frequent itemsets
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)Lalu, kita memperoleh aturan asosiasi:
# Generating frequent itemsets
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
# Generating association rules
rules = association_rules(frequent_itemsets, metric='confidence', min_threshold=0.6)
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])
antecedents consequents support confidence lift
0 (Butter) (Milk) 0.5 0.714286 1.190476
1 (Milk) (Butter) 0.5 0.833333 1.190476
2 (Bread) (Eggs) 0.5 0.714286 1.190476
3 (Eggs) (Bread) 0.5 0.833333 1.190476
4 (Bread) (Beer) 0.6 0.857143 1.428571
5 (Beer) (Bread) 0.6 1.000000 1.428571
6 (Butter) (Cheese) 0.5 0.714286 1.190476
7 (Cheese) (Butter) 0.5 0.833333 1.190476Nilai support (0,5 hingga 0,6) menunjukkan bahwa asosiasi ini muncul dalam 50–60% dari seluruh transaksi.
Skor confidence (0,71 hingga 1,0) menunjukkan keandalan aturan, dengan beberapa aturan seperti Bir → Roti yang pasti (confidence 100%).
Nilai lift (~1,2 hingga 1,4) menunjukkan asosiasi yang moderat namun bermakna, mengindikasikan pasangan item ini muncul bersama sedikit lebih sering daripada kebetulan acak.
Untuk lebih memahami aturan asosiasi yang dihasilkan oleh algoritma Apriori, kita dapat memvisualisasikannya menggunakan Matplotlib. Scatter plot membantu menelaah hubungan antara confidence dan lift, sementara heatmap menunjukkan support untuk berbagai kombinasi item.
import matplotlib.pyplot as plt
import networkx as nx
# Scatter plot of confidence vs lift
plt.figure(figsize=(8,6))
plt.scatter(rules['confidence'], rules['lift'], alpha=0.7, color='b')
plt.xlabel('Confidence')
plt.ylabel('Lift')
plt.title('Confidence vs Lift in Association Rules')
plt.grid()
plt.show()
# Visualizing association rules as a network graph
G = nx.DiGraph()
for _, row in rules.iterrows():
G.add_edge(tuple(row['antecedents']), tuple(row['consequents']), weight=row['confidence'])
plt.figure(figsize=(10, 6))
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, node_color='lightblue', edge_color='gray', node_size=3000, font_size=10)
edge_labels = {(tuple(row['antecedents']), tuple(row['consequents'])): f"{row['confidence']:.2f}"
for _, row in rules.iterrows()}
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels)
plt.title("Association Rules Network")
plt.show()Scatter plot membantu mengidentifikasi aturan dengan hubungan yang kuat, sementara grafik jaringan merepresentasikan secara visual bagaimana item berbeda saling terkait. Wawasan ini memandu pengambilan keputusan di ritel, rekomendasi, dan deteksi kecurangan.
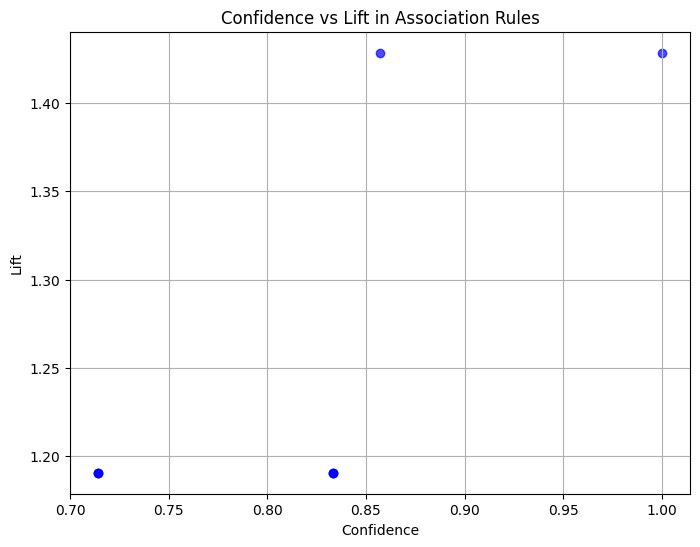
Scatter plot menunjukkan hubungan antara confidence dan lift untuk aturan asosiasi yang dihasilkan. Pengamatan utama adalah:
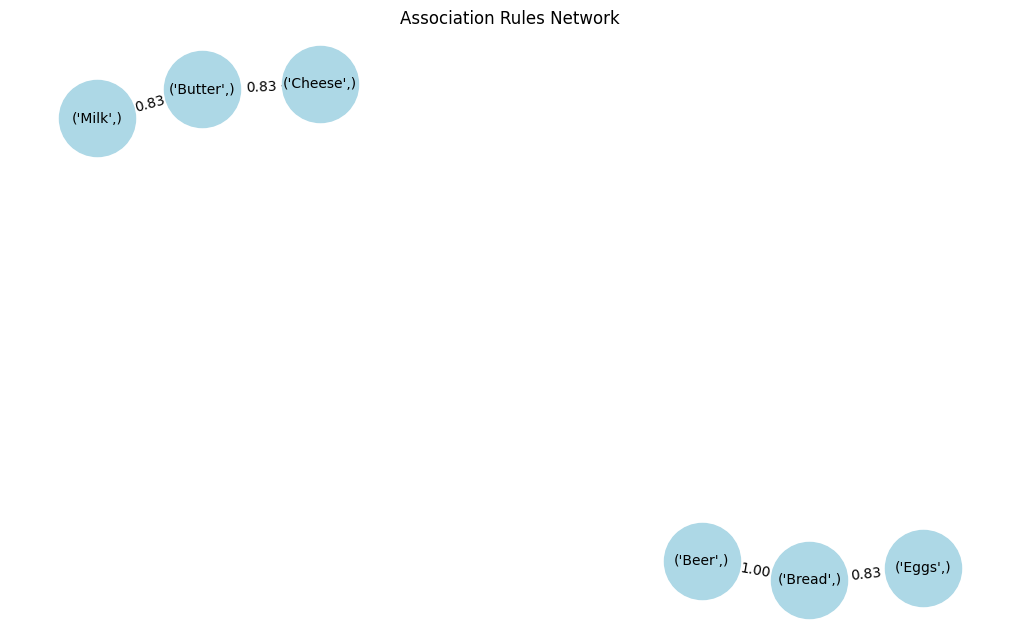
Grafik jaringan merepresentasikan secara visual asosiasi antar berbagai item:
Bisnis secara luas menerapkan algoritma Apriori untuk menyelesaikan berbagai masalah. Mari kita temukan di bawah ini.
Pengecer menggunakan Apriori untuk menganalisis pola pembelian, membantu mereka menata produk guna mendorong pembelian gabungan. Misalnya, jika roti dan mentega sering muncul bersama, toko dapat menempatkannya berdekatan untuk meningkatkan penjualan. Pelajari lebih lanjut tentang market basket analysis dari tutorial market basket analysis menggunakan R kami.
Platform online menggunakan Apriori untuk menyarankan produk berdasarkan pembelian sebelumnya. Jika pelanggan membeli laptop, rekomendasi mungkin mencakup aksesori seperti tetikus atau papan ketik.
Dalam deteksi kecurangan, Apriori mengidentifikasi transaksi tidak biasa dengan membandingkannya dengan pola yang diharapkan. Jika transaksi kartu kredit menyimpang secara signifikan dari aturan yang sudah mapan, hal tersebut dapat memicu pemeriksaan keamanan. Dalam deteksi anomali, meskipun Apriori tidak digunakan secara langsung untuk mengidentifikasi anomali, algoritma ini dapat membantu mendeteksi kombinasi item yang jarang atau tidak terduga yang menyimpang secara signifikan dari pola pembelian umum.
Ada beberapa kelebihan dan kekurangan dalam menggunakan algoritma Apriori, seperti yang akan Anda temukan di bawah ini.
Apriori mudah dipahami dan efektif untuk menemukan itemset sering dalam dataset terstruktur. Algoritma ini banyak digunakan di industri seperti ritel dan layanan kesehatan untuk penemuan pola.
Algoritma menjadi lambat saat bekerja dengan dataset besar karena menghasilkan banyak kandidat itemset. Dalam kasus dengan volume data tinggi, metode alternatif seperti FP-Growth menawarkan kinerja yang lebih baik.
Apriori tetap menjadi salah satu teknik paling berguna untuk menemukan asosiasi dalam data. Terlepas dari tantangan komputasinya, algoritma ini memberikan wawasan berharga yang digunakan bisnis untuk meningkatkan pengalaman pelanggan dan meningkatkan penjualan.
Meskipun mungkin bukan pendekatan tercepat untuk dataset besar, Apriori tetap menjadi alat penting di bidang penambangan data, analitik, dan machine learning. Untuk mempelajari lebih lanjut, jelajahi machine learning dengan Python dan capai tujuan menjadi machine learning scientist melalui Machine Learning Scientist in Python career track kami.
Kursus Teratas DataCamp
Program
Program
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
