programa
Fundamentos del aprendizaje automático en Python
16 h
La minería de reglas de asociación se ha vuelto esencial para las empresas que quieren entender el comportamiento de sus clientes y sus patrones de compra. Esta técnica identifica artículos que se compran juntos con frecuencia, lo que ayuda a optimizar la colocación de productos, las promociones y las recomendaciones. Este tipo de análisis mejora las estrategias de negocio al revelar con claridad tendencias que permanecen ocultas en los datos de transacciones.
El algoritmo Apriori es un método muy popular para extraer estas reglas de asociación por su sencillez y resultados prácticos. A diferencia de otros métodos más complejos, Apriori es directo, lo que lo hace ideal para empezar y eficaz en aplicaciones del mundo real.
Este artículo explica el algoritmo Apriori, ilustra su funcionamiento con ejemplos claros y te muestra cómo utilizarlo con eficacia. Si quieres poner en práctica conceptos de machine learning, echa un vistazo a nuestro Machine Learning Scientist in Python career track.
Como verás en nuestro tutorial de minería de reglas de asociación en Python, Apriori es un algoritmo diseñado para extraer conjuntos de ítems frecuentes de bases de datos transaccionales y generar reglas de asociación. Se basa en el principio de que si un conjunto de ítems es frecuente, todos sus subconjuntos también deben serlo. Esta suposición ayuda a reducir el número de conjuntos de ítems que hay que comprobar, haciendo el proceso más eficiente.
Un conjunto de datos para Apriori suele estar formado por transacciones, donde cada transacción es un conjunto de artículos comprados juntos. Por ejemplo, los datos de ventas de un supermercado pueden contener transacciones como:
Cada una de estas transacciones representa una cesta de productos comprados en una única compra. Nuestro curso de Market Basket Analysis en Python entra en más detalle sobre la aplicación de este concepto en Python.
La minería de reglas de asociación se apoya en tres métricas clave:
Soporte: La frecuencia con la que un ítem aparece en el conjunto de datos. Se calcula como:
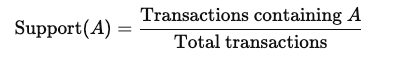
Confianza: La probabilidad de que se compre el ítem B cuando se compra el ítem A, dada por:

Lift: La fuerza de una regla; mide cuánto más probable es que se compre el ítem B cuando se compra el ítem A en comparación con comprarlo de forma independiente:
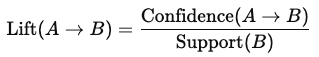
Un valor de lift mayor que 1 sugiere una asociación positiva fuerte entre ítems.
Veamos ahora cómo funciona el algoritmo Apriori.
Imagina un conjunto de datos con estas transacciones:
Usando un soporte mínimo del 50%, el algoritmo identifica conjuntos de ítems frecuentes y extrae reglas como:
Estas reglas ayudan a entender los hábitos de compra y a optimizar el inventario.
En esta sección aprenderás a implementar el algoritmo Apriori en Python.
Para usar Apriori en Python, instala las librerías necesarias:
pip install mlxtend pandasEl siguiente paso es cargar los paquetes y preparar los datos:
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
# Expanded dataset
data = {
'Milk': [1, 1, 0, 1, 0, 1, 0, 1, 1, 0],
'Bread': [1, 0, 1, 1, 1, 0, 1, 0, 1, 1],
'Butter': [0, 1, 1, 1, 1, 1, 0, 1, 1, 0],
'Eggs': [1, 0, 0, 1, 1, 1, 1, 0, 0, 1],
'Cheese': [0, 1, 1, 0, 1, 1, 0, 1, 0, 1],
'Diaper': [0, 1, 0, 1, 0, 1, 1, 1, 0, 0],
'Beer': [1, 0, 1, 0, 1, 0, 1, 0, 1, 1]
}
df = pd.DataFrame(data)A continuación, aplica el algoritmo.
# Generating frequent itemsets
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)Después, obtenemos las reglas de asociación:
# Generating frequent itemsets
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
# Generating association rules
rules = association_rules(frequent_itemsets, metric='confidence', min_threshold=0.6)
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])
antecedents consequents support confidence lift
0 (Butter) (Milk) 0.5 0.714286 1.190476
1 (Milk) (Butter) 0.5 0.833333 1.190476
2 (Bread) (Eggs) 0.5 0.714286 1.190476
3 (Eggs) (Bread) 0.5 0.833333 1.190476
4 (Bread) (Beer) 0.6 0.857143 1.428571
5 (Beer) (Bread) 0.6 1.000000 1.428571
6 (Butter) (Cheese) 0.5 0.714286 1.190476
7 (Cheese) (Butter) 0.5 0.833333 1.190476Los valores de soporte (0,5 a 0,6) indican que estas asociaciones aparecen en el 50-60% de todas las transacciones.
Las puntuaciones de confianza (0,71 a 1,0) muestran la fiabilidad de las reglas, con algunas como Beer → Bread siendo ciertas (confianza del 100%).
Los valores de lift (~1,2 a 1,4) sugieren asociaciones moderadas pero relevantes, lo que indica que estos pares de ítems ocurren juntos algo más a menudo de lo que cabría esperar por azar.
Para entender mejor las reglas de asociación generadas por el algoritmo Apriori, podemos visualizarlas con Matplotlib. Un diagrama de dispersión ayuda a analizar confianza frente a lift, mientras que un mapa de calor muestra el soporte de distintas combinaciones de ítems.
import matplotlib.pyplot as plt
import networkx as nx
# Scatter plot of confidence vs lift
plt.figure(figsize=(8,6))
plt.scatter(rules['confidence'], rules['lift'], alpha=0.7, color='b')
plt.xlabel('Confidence')
plt.ylabel('Lift')
plt.title('Confidence vs Lift in Association Rules')
plt.grid()
plt.show()
# Visualizing association rules as a network graph
G = nx.DiGraph()
for _, row in rules.iterrows():
G.add_edge(tuple(row['antecedents']), tuple(row['consequents']), weight=row['confidence'])
plt.figure(figsize=(10, 6))
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, node_color='lightblue', edge_color='gray', node_size=3000, font_size=10)
edge_labels = {(tuple(row['antecedents']), tuple(row['consequents'])): f"{row['confidence']:.2f}"
for _, row in rules.iterrows()}
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels)
plt.title("Association Rules Network")
plt.show()El diagrama de dispersión ayuda a identificar reglas con relaciones fuertes, mientras que el grafo de red representa visualmente cómo se asocian los distintos ítems. Estos insights guían la toma de decisiones en retail, recomendaciones y detección de fraude.
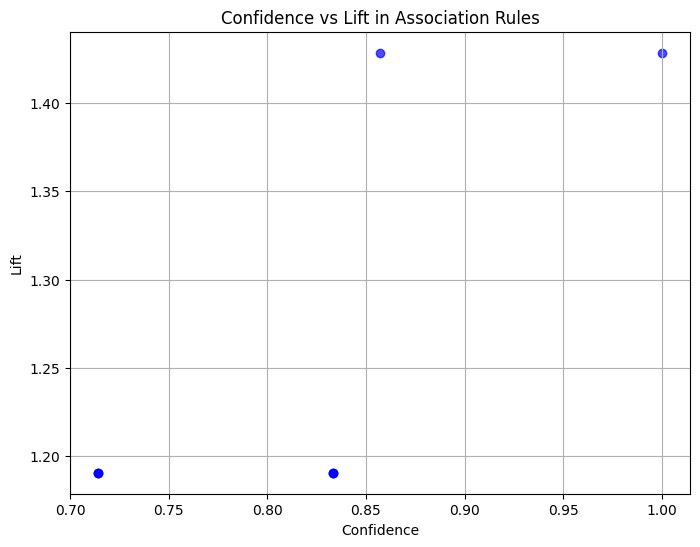
El diagrama de dispersión muestra la relación entre confianza y lift para las reglas de asociación generadas. Las observaciones clave son:
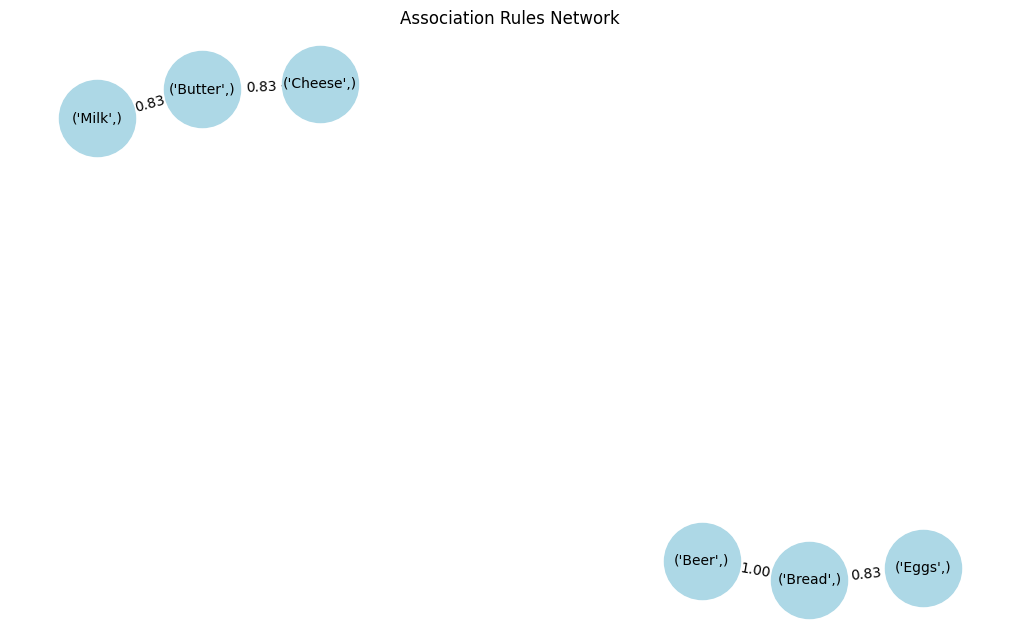
El grafo de red representa visualmente las asociaciones entre distintos ítems:
Las empresas aplican ampliamente el algoritmo Apriori para resolver diversos problemas. Descúbrelos a continuación.
Los retailers utilizan Apriori para analizar patrones de compra, lo que les ayuda a colocar productos para fomentar compras combinadas. Por ejemplo, si pan y mantequilla aparecen juntos con frecuencia, una tienda puede situarlos cerca para impulsar las ventas. Aprende más sobre market basket analysis en nuestro tutorial de market basket analysis con R.
Las plataformas online usan Apriori para sugerir productos en función de compras anteriores. Si un cliente compra un portátil, las recomendaciones pueden incluir accesorios como un ratón o un teclado.
En la detección de fraude, Apriori identifica transacciones inusuales comparándolas con los patrones esperados. Si una transacción con tarjeta de crédito se desvía significativamente de las reglas establecidas, puede activar una revisión de seguridad. En detección de anomalías, aunque Apriori no se usa directamente para identificar anomalías, puede ayudar a detectar combinaciones de ítems raras o inesperadas que se alejan de los patrones de compra comunes.
Existen varias ventajas y desventajas al usar el algoritmo Apriori, como verás a continuación.
Apriori es fácil de entender y eficaz para descubrir conjuntos de ítems frecuentes en datos estructurados. Se usa ampliamente en sectores como retail y salud para el descubrimiento de patrones.
El algoritmo se vuelve lento al trabajar con conjuntos de datos grandes porque genera muchos candidatos. En escenarios con gran volumen de datos, métodos alternativos como FP-Growth ofrecen un mejor rendimiento.
Apriori sigue siendo una de las técnicas más útiles para encontrar asociaciones en los datos. A pesar de sus retos computacionales, aporta insights valiosos que las empresas utilizan para mejorar la experiencia del cliente y aumentar las ventas.
Aunque no sea el enfoque más rápido para conjuntos de datos muy grandes, sigue siendo una herramienta esencial en minería de datos, analítica y machine learning. Para saber más, explora machine learning con Python y avanza hacia convertirte en machine learning scientist con nuestro Machine Learning Scientist in Python career track.
Los mejores cursos de DataCamp
programa
programa
Curso
blog
DataCamp Team
11 min
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Avinash Navlani
Tutorial
DataCamp Team
