Leerpad
Basisprincipes van machine learning in Python
16 Hr
Association rule mining is essentieel geworden voor bedrijven die klantgedrag en aankoopgedrag willen begrijpen. Deze techniek identificeert items die vaak samen worden gekocht, zodat bedrijven productplaatsing, promoties en aanbevelingen kunnen optimaliseren. Dergelijke analyses verbeteren bedrijfsstrategieën door trends die verborgen zitten in transactiegegevens helder zichtbaar te maken.
Het Apriori-algoritme is een populaire methode om deze associatieregels te ontginnen vanwege de eenvoud en praktische resultaten. In tegenstelling tot andere complexe methoden is Apriori rechtlijnig, waardoor het geschikt is voor beginners en effectief in toepassingen in de echte wereld.
Dit artikel legt het Apriori-algoritme uit, illustreert de workflow met duidelijke voorbeelden en laat je zien hoe je het effectief gebruikt. Wil je hands-on aan de slag met machinelearningconcepten, bekijk dan onze Machine Learning Scientist in Python-carrièretrack.
Zoals je zult ontdekken in onze Association Rule Mining in Python Tutorial, is Apriori een algoritme dat is ontworpen om frequente itemsets uit transactionele databases te halen en associatieregels te genereren. Het is gebaseerd op het principe dat als een itemset frequent is, alle deelverzamelingen daarvan ook frequent moeten zijn. Deze aanname helpt het aantal mogelijke itemsets dat moet worden gecontroleerd te verminderen, waardoor het proces efficiënt wordt.
Een dataset voor Apriori bestaat typisch uit transacties, waarbij elke transactie een verzameling items is die samen zijn gekocht. Bijvoorbeeld, de verkoopdata van een supermarkt kan transacties bevatten zoals:
Elk van deze transacties vertegenwoordigt een mandje met items die in één aankoop zijn gekocht. Onze Market Basket Analysis in Python-cursus gaat dieper in op de toepassing van dit concept in Python.
Association rule mining steunt op drie kernmetrics:
Support: De frequentie waarmee een item in de dataset voorkomt. Dit wordt berekend als:
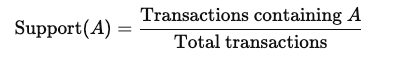
Confidence: De waarschijnlijkheid dat item B wordt gekocht wanneer item A wordt gekocht, gegeven door:

Lift: De sterkte van een regel; dit meet hoe veel waarschijnlijker item B wordt gekocht wanneer item A wordt gekocht vergeleken met onafhankelijk kopen:
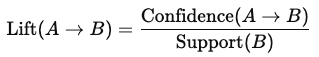
Een liftwaarde groter dan 1 suggereert een sterke positieve associatie tussen items.
Laten we nu ontdekken hoe het Apriori-algoritme werkt.
Neem een dataset met transacties:
Met een minimale support van 50% identificeert het algoritme frequente itemsets en extraheert het regels zoals:
Deze regels helpen bedrijven aankoopgedrag te begrijpen en hun voorraad te optimaliseren.
In deze sectie leer je hoe je het Apriori-algoritme in Python implementeert.
Om Apriori in Python te gebruiken, installeer je de benodigde libraries:
pip install mlxtend pandasDe volgende stap is packages laden en de data voorbereiden:
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
# Expanded dataset
data = {
'Milk': [1, 1, 0, 1, 0, 1, 0, 1, 1, 0],
'Bread': [1, 0, 1, 1, 1, 0, 1, 0, 1, 1],
'Butter': [0, 1, 1, 1, 1, 1, 0, 1, 1, 0],
'Eggs': [1, 0, 0, 1, 1, 1, 1, 0, 0, 1],
'Cheese': [0, 1, 1, 0, 1, 1, 0, 1, 0, 1],
'Diaper': [0, 1, 0, 1, 0, 1, 1, 1, 0, 0],
'Beer': [1, 0, 1, 0, 1, 0, 1, 0, 1, 1]
}
df = pd.DataFrame(data)Pas vervolgens het algoritme toe.
# Generating frequent itemsets
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)Daarna verkrijgen we de associatieregels:
# Generating frequent itemsets
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
# Generating association rules
rules = association_rules(frequent_itemsets, metric='confidence', min_threshold=0.6)
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])
antecedents consequents support confidence lift
0 (Butter) (Milk) 0.5 0.714286 1.190476
1 (Milk) (Butter) 0.5 0.833333 1.190476
2 (Bread) (Eggs) 0.5 0.714286 1.190476
3 (Eggs) (Bread) 0.5 0.833333 1.190476
4 (Bread) (Beer) 0.6 0.857143 1.428571
5 (Beer) (Bread) 0.6 1.000000 1.428571
6 (Butter) (Cheese) 0.5 0.714286 1.190476
7 (Cheese) (Butter) 0.5 0.833333 1.190476De supportwaarden (0,5 tot 0,6) geven aan dat deze associaties in 50–60% van alle transacties voorkomen.
De confidence-scores (0,71 tot 1,0) tonen de betrouwbaarheid van de regels, waarbij sommige zoals Bier → Brood zeker zijn (100% confidence).
De liftwaarden (~1,2 tot 1,4) suggereren matige maar betekenisvolle associaties: deze itemparen komen iets vaker samen voor dan op basis van toeval.
Om de door het Apriori-algoritme gegenereerde associatieregels beter te begrijpen, kunnen we ze visualiseren met Matplotlib. Een scatterplot helpt bij het bekijken van confidence versus lift, terwijl een heatmap de support voor verschillende itemcombinaties toont.
import matplotlib.pyplot as plt
import networkx as nx
# Scatter plot of confidence vs lift
plt.figure(figsize=(8,6))
plt.scatter(rules['confidence'], rules['lift'], alpha=0.7, color='b')
plt.xlabel('Confidence')
plt.ylabel('Lift')
plt.title('Confidence vs Lift in Association Rules')
plt.grid()
plt.show()
# Visualizing association rules as a network graph
G = nx.DiGraph()
for _, row in rules.iterrows():
G.add_edge(tuple(row['antecedents']), tuple(row['consequents']), weight=row['confidence'])
plt.figure(figsize=(10, 6))
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, node_color='lightblue', edge_color='gray', node_size=3000, font_size=10)
edge_labels = {(tuple(row['antecedents']), tuple(row['consequents'])): f"{row['confidence']:.2f}"
for _, row in rules.iterrows()}
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels)
plt.title("Association Rules Network")
plt.show()De scatterplot helpt regels met sterke relaties te identificeren, terwijl de netwerkgraph visueel laat zien hoe verschillende items met elkaar samenhangen. Deze inzichten sturen besluitvorming in retail, aanbevelingen en fraudedetectie.
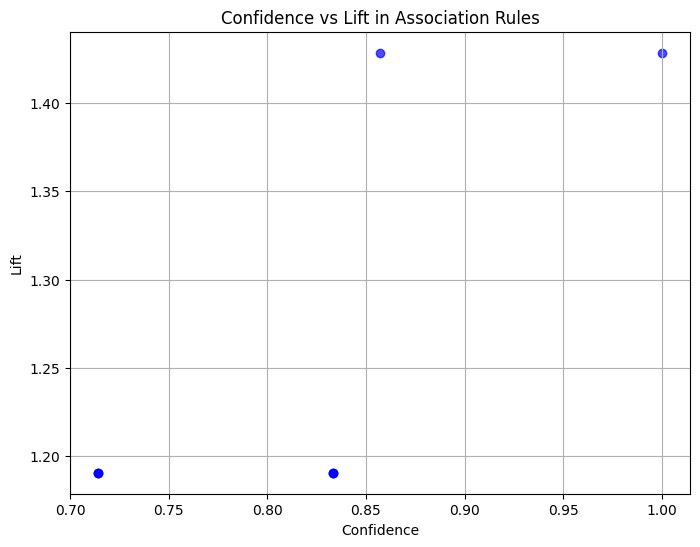
De scatterplot toont de relatie tussen confidence en lift voor de gegenereerde associatieregels. De belangrijkste observaties zijn:
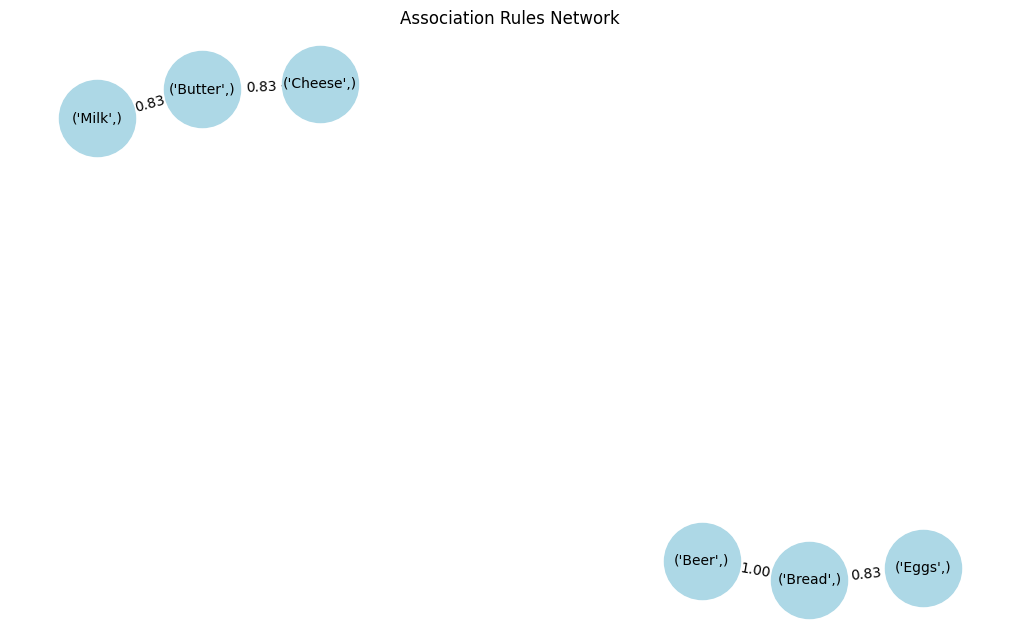
De netwerkgraph geeft de associaties tussen verschillende items visueel weer:
Bedrijven passen het Apriori-algoritme op grote schaal toe om diverse problemen op te lossen. Laten we ze hieronder ontdekken.
Retailers gebruiken Apriori om aankoopPatronen te analyseren, zodat ze producten kunnen rangschikken om gecombineerde aankopen te stimuleren. Als brood en boter bijvoorbeeld vaak samen voorkomen, kan een winkel ze dicht bij elkaar plaatsen om de verkoop te verhogen. Lees meer over market-basketanalyse in onze tutorial market-basketanalyse met R.
Online platforms gebruiken Apriori om producten aan te bevelen op basis van eerdere aankopen. Als een klant een laptop koopt, kunnen aanbevelingen accessoires zoals een muis of toetsenbord bevatten.
Bij fraudedetectie identificeert Apriori ongewone transacties door ze te vergelijken met verwachte patronen. Als een creditcardtransactie aanzienlijk afwijkt van gevestigde regels, kan dit een veiligheidscontrole activeren. Bij anomaliedetectie wordt Apriori niet direct gebruikt om anomalieën te identificeren, maar het kan wel helpen zeldzame of onverwachte itemcombinaties te detecteren die sterk afwijken van gangbare aankoopPatronen.
Er zijn verschillende voordelen en nadelen verbonden aan het gebruik van het Apriori-algoritme, zoals je hieronder zult ontdekken.
Apriori is eenvoudig te begrijpen en effectief in het ontdekken van frequente itemsets in gestructureerde datasets. Het wordt veel gebruikt in sectoren als retail en zorg voor patroonontdekking.
Het algoritme wordt traag bij grote datasets omdat het veel kandidaat-itemsets genereert. In gevallen met een hoog datavolume bieden alternatieve methoden zoals FP-Growth betere prestaties.
Apriori blijft een van de meest bruikbare technieken om associaties in data te vinden. Ondanks de computationele uitdagingen levert het waardevolle inzichten op die bedrijven gebruiken om klantervaringen te verbeteren en de verkoop te verhogen.
Hoewel het misschien niet de snelste aanpak is voor grote datasets, blijft het een essentieel hulpmiddel in data mining, analytics en machine learning. Wil je meer leren, verken dan machine learning met Python en werk toe naar een rol als machine learning scientist met onze Machine Learning Scientist in Python-carrièretrack.
Topcursussen bij DataCamp
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
