Programa
Fundamentos de machine learning Em Python
16 h
A mineração de regras de associação se tornou essencial para empresas que querem entender o comportamento do cliente e seus padrões de compra. Essa técnica identifica itens frequentemente comprados juntos, ajudando a otimizar a disposição de produtos, promoções e recomendações. Essa análise melhora as estratégias do negócio ao revelar com clareza tendências escondidas nos dados de transações.
O algoritmo Apriori é um método popular para minerar essas regras de associação pela sua simplicidade e resultados práticos. Diferente de outros métodos mais complexos, o Apriori é direto, ideal para iniciantes e eficaz em aplicações do mundo real.
Este artigo explica o algoritmo Apriori, ilustra seu fluxo de trabalho com exemplos claros e mostra como você pode usá-lo com eficiência. Se quer colocar a mão na massa com conceitos de machine learning, confira nossa Machine Learning Scientist in Python career track.
Como você vai ver no nosso tutorial de mineração de regras de associação em Python, o Apriori é um algoritmo projetado para extrair itemsets frequentes de bases de dados transacionais e gerar regras de associação. Ele se baseia no princípio de que, se um itemset é frequente, todos os seus subconjuntos também devem ser frequentes. Essa suposição ajuda a reduzir a quantidade de itemsets possíveis a verificar, tornando o processo eficiente.
Um dataset para Apriori normalmente é composto por transações, em que cada transação é um conjunto de itens comprados juntos. Por exemplo, os dados de vendas de um supermercado podem conter transações como:
Cada uma dessas transações representa uma cesta de itens comprados em uma única compra. Nosso curso de Market Basket Analysis em Python traz mais detalhes sobre a aplicação desse conceito em Python.
A mineração de regras de associação se apoia em três métricas principais:
Support: A frequência com que um item aparece no dataset. É calculado como:
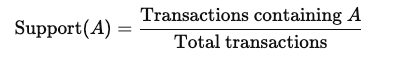
Confidence: A probabilidade de o item B ser comprado quando o item A é comprado, dada por:

Lift: A força de uma regra, medindo quanto mais provável é comprar o item B quando o item A é comprado, em comparação com comprá-lo de forma independente:
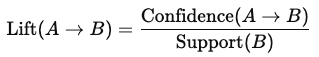
Um valor de lift maior que 1 sugere uma associação positiva forte entre os itens.
Vamos ver agora como o algoritmo Apriori funciona.
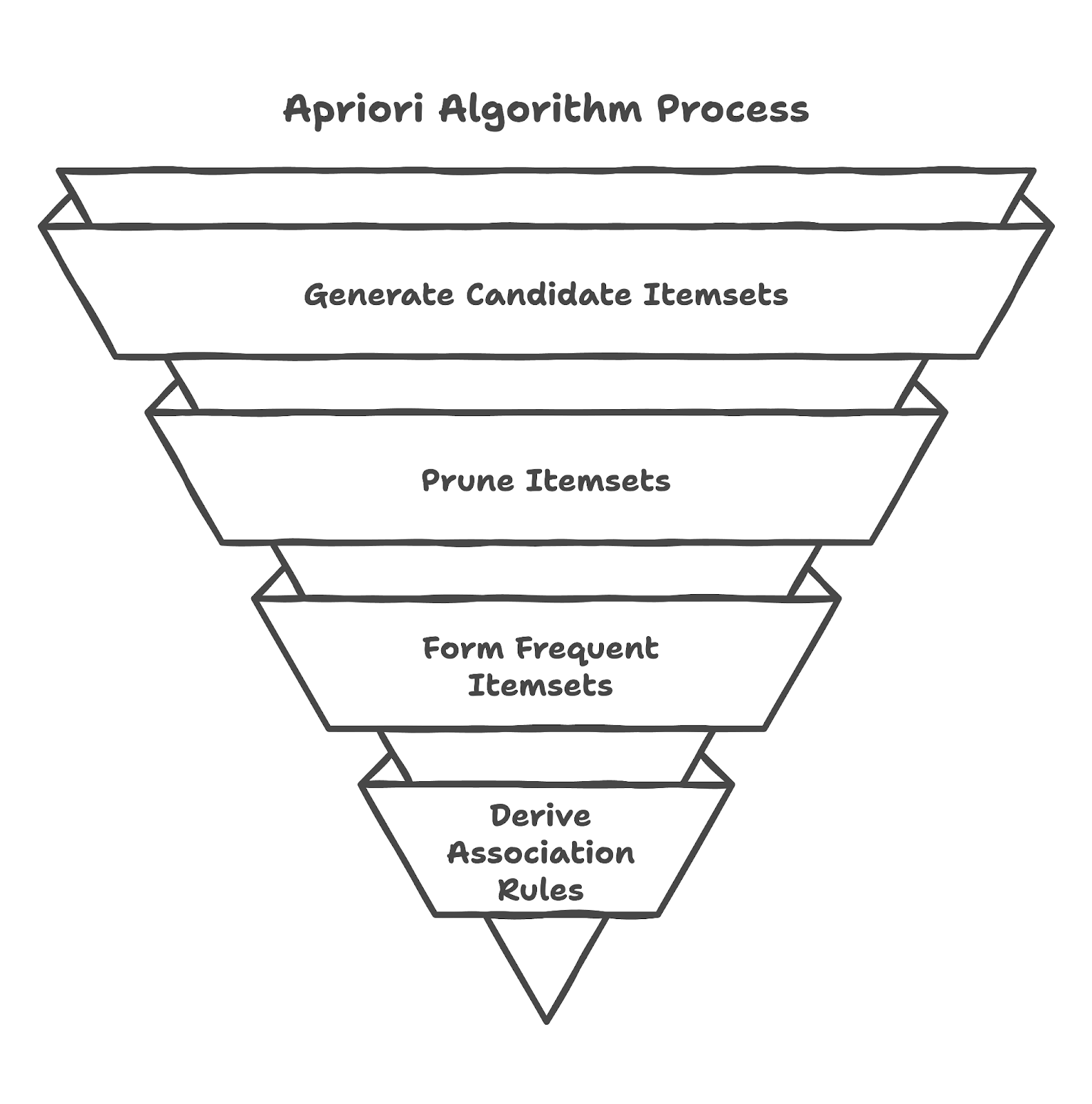
Considere um dataset com as transações:
Usando um suporte mínimo de 50%, o algoritmo identifica itemsets frequentes e extrai regras como:
Essas regras ajudam as empresas a entender o comportamento de compra e otimizar o estoque.
Nesta seção, você aprende a implementar o algoritmo Apriori em Python.
Para usar o Apriori em Python, instale as bibliotecas necessárias:
pip install mlxtend pandasO próximo passo é carregar os pacotes e preparar os dados:
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
# Expanded dataset
data = {
'Milk': [1, 1, 0, 1, 0, 1, 0, 1, 1, 0],
'Bread': [1, 0, 1, 1, 1, 0, 1, 0, 1, 1],
'Butter': [0, 1, 1, 1, 1, 1, 0, 1, 1, 0],
'Eggs': [1, 0, 0, 1, 1, 1, 1, 0, 0, 1],
'Cheese': [0, 1, 1, 0, 1, 1, 0, 1, 0, 1],
'Diaper': [0, 1, 0, 1, 0, 1, 1, 1, 0, 0],
'Beer': [1, 0, 1, 0, 1, 0, 1, 0, 1, 1]
}
df = pd.DataFrame(data)Em seguida, aplique o algoritmo.
# Generating frequent itemsets
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)Depois, obtemos as regras de associação:
# Generating frequent itemsets
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
# Generating association rules
rules = association_rules(frequent_itemsets, metric='confidence', min_threshold=0.6)
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])
antecedents consequents support confidence lift
0 (Butter) (Milk) 0.5 0.714286 1.190476
1 (Milk) (Butter) 0.5 0.833333 1.190476
2 (Bread) (Eggs) 0.5 0.714286 1.190476
3 (Eggs) (Bread) 0.5 0.833333 1.190476
4 (Bread) (Beer) 0.6 0.857143 1.428571
5 (Beer) (Bread) 0.6 1.000000 1.428571
6 (Butter) (Cheese) 0.5 0.714286 1.190476
7 (Cheese) (Butter) 0.5 0.833333 1.190476Os valores de support (0,5 a 0,6) indicam que essas associações aparecem em 50% a 60% de todas as transações.
Os escores de confidence (0,71 a 1,0) mostram a confiabilidade das regras, com algumas como Beer → Bread sendo certas (100% de confidence).
Os valores de lift (~1,2 a 1,4) sugerem associações moderadas porém relevantes, indicando que esses pares de itens ocorrem juntos um pouco mais frequentemente do que o acaso.
Para entender melhor as regras de associação geradas pelo algoritmo Apriori, podemos visualizá-las com Matplotlib. Um gráfico de dispersão ajuda a analisar confidence versus lift, enquanto um heatmap mostra o support de várias combinações de itens.
import matplotlib.pyplot as plt
import networkx as nx
# Scatter plot of confidence vs lift
plt.figure(figsize=(8,6))
plt.scatter(rules['confidence'], rules['lift'], alpha=0.7, color='b')
plt.xlabel('Confidence')
plt.ylabel('Lift')
plt.title('Confidence vs Lift in Association Rules')
plt.grid()
plt.show()
# Visualizing association rules as a network graph
G = nx.DiGraph()
for _, row in rules.iterrows():
G.add_edge(tuple(row['antecedents']), tuple(row['consequents']), weight=row['confidence'])
plt.figure(figsize=(10, 6))
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, node_color='lightblue', edge_color='gray', node_size=3000, font_size=10)
edge_labels = {(tuple(row['antecedents']), tuple(row['consequents'])): f"{row['confidence']:.2f}"
for _, row in rules.iterrows()}
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels)
plt.title("Association Rules Network")
plt.show()O gráfico de dispersão ajuda a identificar regras com relações fortes, enquanto o grafo em rede representa visualmente como diferentes itens se associam. Esses insights orientam a tomada de decisão em varejo, recomendações e detecção de fraudes.
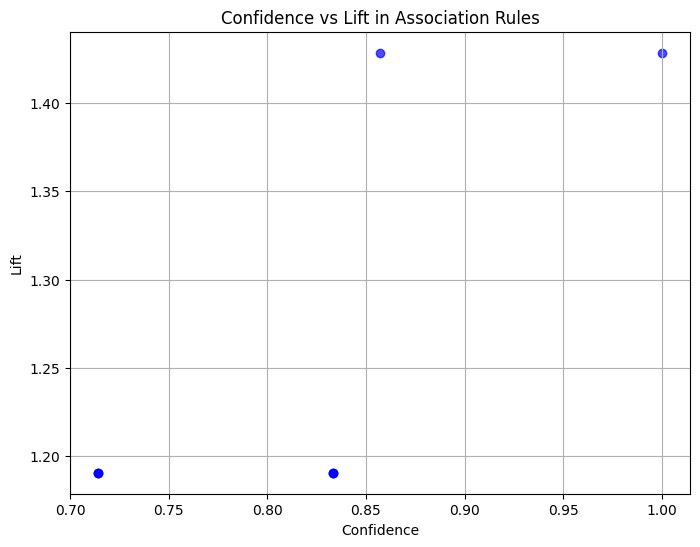
O gráfico de dispersão mostra a relação entre confidence e lift para as regras de associação geradas. Os principais pontos são:
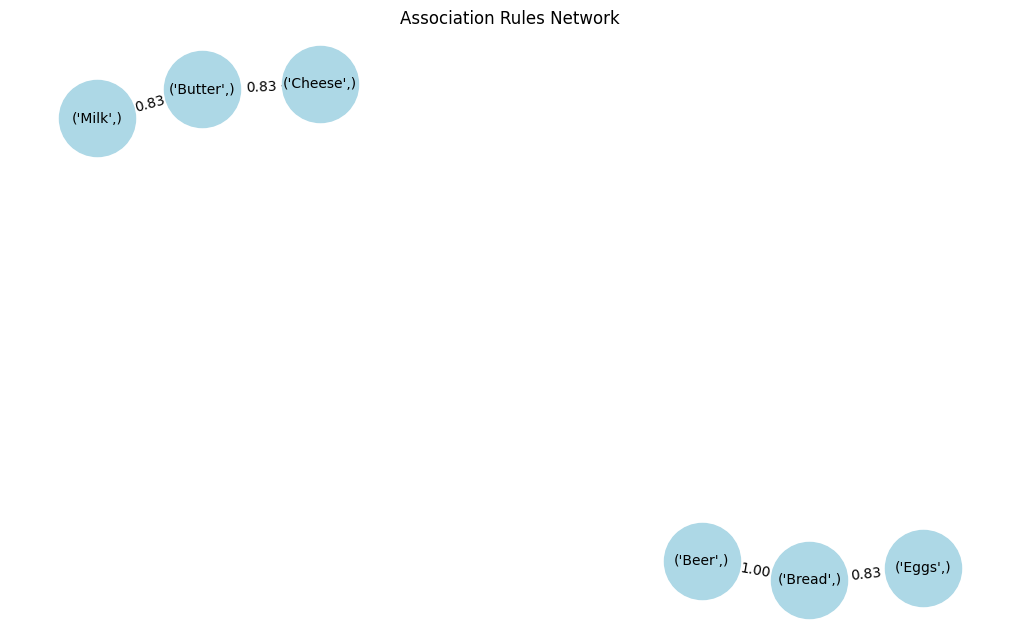
O grafo em rede representa visualmente as associações entre diferentes itens:
Empresas aplicam amplamente o algoritmo Apriori para resolver diversos problemas. Confira alguns exemplos abaixo.
Varejistas usam Apriori para analisar padrões de compra, ajudando a organizar produtos de forma a incentivar compras combinadas. Por exemplo, se bread e butter aparecem com frequência juntos, a loja pode colocá-los próximos para aumentar as vendas. Saiba mais sobre análise de cesta de mercado no nosso tutorial usando R.
Plataformas online usam Apriori para sugerir produtos com base em compras anteriores. Se um cliente compra um laptop, as recomendações podem incluir acessórios como mouse ou teclado.
Na detecção de fraudes, o Apriori identifica transações incomuns ao compará-las com os padrões esperados. Se uma transação no cartão de crédito se desvia significativamente das regras estabelecidas, ela pode acionar uma checagem de segurança. Em detecção de anomalias, embora o Apriori não seja usado diretamente para identificar anomalias, ele pode ajudar a detectar combinações raras ou inesperadas de itens que se desviam bastante dos padrões comuns de compra.
Há várias vantagens e desvantagens em usar o algoritmo Apriori, como você vai ver abaixo.
O Apriori é simples de entender e eficaz para descobrir itemsets frequentes em datasets estruturados. Ele é amplamente usado em setores como varejo e saúde para descoberta de padrões.
O algoritmo fica lento ao trabalhar com grandes volumes de dados porque gera muitos itemsets candidatos. Em casos com alto volume, métodos alternativos como o FP-Growth oferecem melhor desempenho.
O Apriori continua sendo uma das técnicas mais úteis para encontrar associações em dados. Apesar dos desafios computacionais, ele fornece insights valiosos que as empresas usam para melhorar a experiência do cliente e aumentar as vendas.
Embora não seja a abordagem mais rápida para datasets muito grandes, segue como uma ferramenta essencial nas áreas de data mining, analytics e machine learning. Para aprender mais, explore machine learning com Python e avance rumo a se tornar um cientista de machine learning com nossa Machine Learning Scientist in Python career track.
Principais cursos da DataCamp
Programa
Programa
Curso
blog
DataCamp Team
11 min
Tutorial
Moez Ali
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan
Tutorial
Kevin Babitz
Tutorial
Moez Ali
