Programma
Fondamenti di apprendimento automatico in Python
16 h
Il mining delle regole di associazione è diventato essenziale per le aziende che vogliono capire i comportamenti dei clienti e i modelli di acquisto. Questa tecnica identifica gli articoli spesso comprati insieme, aiutando le aziende a ottimizzare il posizionamento dei prodotti, le promozioni e le raccomandazioni. Un'analisi di questo tipo migliora le strategie aziendali perché mette in luce con chiarezza le tendenze nascoste nei dati transazionali.
L'algoritmo Apriori è un metodo popolare per estrarre queste regole di associazione grazie alla sua semplicità e ai risultati pratici. A differenza di altri metodi complessi, Apriori è lineare e intuitivo, adatto a chi inizia ed efficace nelle applicazioni reali.
Questo articolo spiega l'algoritmo Apriori, ne illustra il flusso di lavoro con esempi chiari e ti mostra come usarlo in modo efficace. Se vuoi mettere le mani in pasta con i concetti di machine learning, dai un'occhiata al nostro percorso di carriera Machine Learning Scientist in Python.
Come scoprirai dal nostro tutorial su Association Rule Mining in Python, Apriori è un algoritmo progettato per estrarre itemset frequenti da database transazionali e generare regole di associazione. Si basa sul principio secondo cui, se un itemset è frequente, allora anche tutti i suoi sottoinsiemi devono essere frequenti. Questa assunzione aiuta a ridurre il numero di itemset possibili da verificare, rendendo il processo efficiente.
Un dataset per Apriori è tipicamente composto da transazioni, dove ogni transazione è un insieme di articoli acquistati insieme. Per esempio, i dati di vendita di un supermercato possono contenere transazioni come:
Ognuna di queste transazioni rappresenta un carrello di articoli comprati in un unico acquisto. Il nostro corso Market Basket Analysis in Python approfondisce l'applicazione di questo concetto in Python.
Il mining delle regole di associazione si basa su tre metriche chiave:
Supporto: La frequenza con cui un articolo appare nel dataset. Si calcola come:
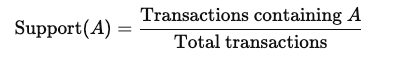
Confidenza: La probabilità che l'articolo B venga acquistato quando viene acquistato l'articolo A, data da:

Lift: La forza di una regola, che misura quanto è più probabile che l'articolo B venga comprato quando viene comprato l'articolo A rispetto a quando è comprato indipendentemente:
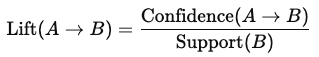
Un valore di lift maggiore di 1 suggerisce una forte associazione positiva tra gli articoli.
Vediamo ora come funziona l'algoritmo Apriori.
Considera un dataset con le seguenti transazioni:
Usando un supporto minimo del 50%, l'algoritmo identifica gli itemset frequenti ed estrae regole come:
Queste regole aiutano le aziende a comprendere i comportamenti d'acquisto e a ottimizzare l'inventario.
In questa sezione impari a implementare l'algoritmo Apriori in Python.
Per usare Apriori in Python, installa le librerie necessarie:
pip install mlxtend pandasIl passo successivo è caricare i pacchetti e preparare i dati:
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
# Expanded dataset
data = {
'Milk': [1, 1, 0, 1, 0, 1, 0, 1, 1, 0],
'Bread': [1, 0, 1, 1, 1, 0, 1, 0, 1, 1],
'Butter': [0, 1, 1, 1, 1, 1, 0, 1, 1, 0],
'Eggs': [1, 0, 0, 1, 1, 1, 1, 0, 0, 1],
'Cheese': [0, 1, 1, 0, 1, 1, 0, 1, 0, 1],
'Diaper': [0, 1, 0, 1, 0, 1, 1, 1, 0, 0],
'Beer': [1, 0, 1, 0, 1, 0, 1, 0, 1, 1]
}
df = pd.DataFrame(data)Ora applica l'algoritmo.
# Generating frequent itemsets
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)Poi otteniamo le regole di associazione:
# Generating frequent itemsets
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
# Generating association rules
rules = association_rules(frequent_itemsets, metric='confidence', min_threshold=0.6)
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])
antecedents consequents support confidence lift
0 (Butter) (Milk) 0.5 0.714286 1.190476
1 (Milk) (Butter) 0.5 0.833333 1.190476
2 (Bread) (Eggs) 0.5 0.714286 1.190476
3 (Eggs) (Bread) 0.5 0.833333 1.190476
4 (Bread) (Beer) 0.6 0.857143 1.428571
5 (Beer) (Bread) 0.6 1.000000 1.428571
6 (Butter) (Cheese) 0.5 0.714286 1.190476
7 (Cheese) (Butter) 0.5 0.833333 1.190476I valori di supporto (da 0,5 a 0,6) indicano che queste associazioni compaiono nel 50-60% di tutte le transazioni.
I punteggi di confidenza (da 0,71 a 1,0) mostrano l'affidabilità delle regole, con alcune come Birra → Pane che sono certe (confidenza 100%).
I valori di lift (~1,2-1,4) suggeriscono associazioni moderate ma significative, indicando che queste coppie di articoli si presentano insieme un po' più frequentemente del caso.
Per comprendere meglio le regole di associazione generate dall'algoritmo Apriori, possiamo visualizzarle con Matplotlib. Uno scatter plot aiuta a esaminare confidenza e lift, mentre una heatmap mostra il supporto per varie combinazioni di articoli.
import matplotlib.pyplot as plt
import networkx as nx
# Scatter plot of confidence vs lift
plt.figure(figsize=(8,6))
plt.scatter(rules['confidence'], rules['lift'], alpha=0.7, color='b')
plt.xlabel('Confidence')
plt.ylabel('Lift')
plt.title('Confidence vs Lift in Association Rules')
plt.grid()
plt.show()
# Visualizing association rules as a network graph
G = nx.DiGraph()
for _, row in rules.iterrows():
G.add_edge(tuple(row['antecedents']), tuple(row['consequents']), weight=row['confidence'])
plt.figure(figsize=(10, 6))
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, node_color='lightblue', edge_color='gray', node_size=3000, font_size=10)
edge_labels = {(tuple(row['antecedents']), tuple(row['consequents'])): f"{row['confidence']:.2f}"
for _, row in rules.iterrows()}
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels)
plt.title("Association Rules Network")
plt.show()Lo scatter plot aiuta a identificare le regole con relazioni forti, mentre il grafo di rete rappresenta visivamente come sono associati i vari articoli. Queste intuizioni guidano le decisioni in ambito retail, raccomandazioni e rilevamento frodi.
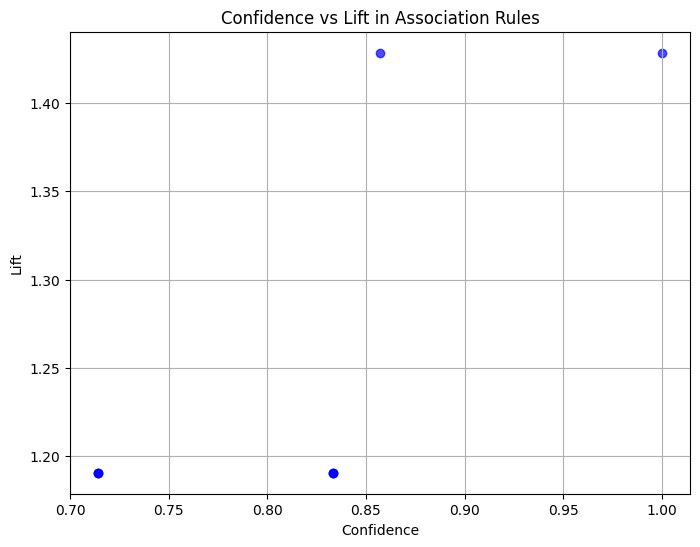
Lo scatter plot mostra la relazione tra confidenza e lift per le regole di associazione generate. Le osservazioni chiave sono:
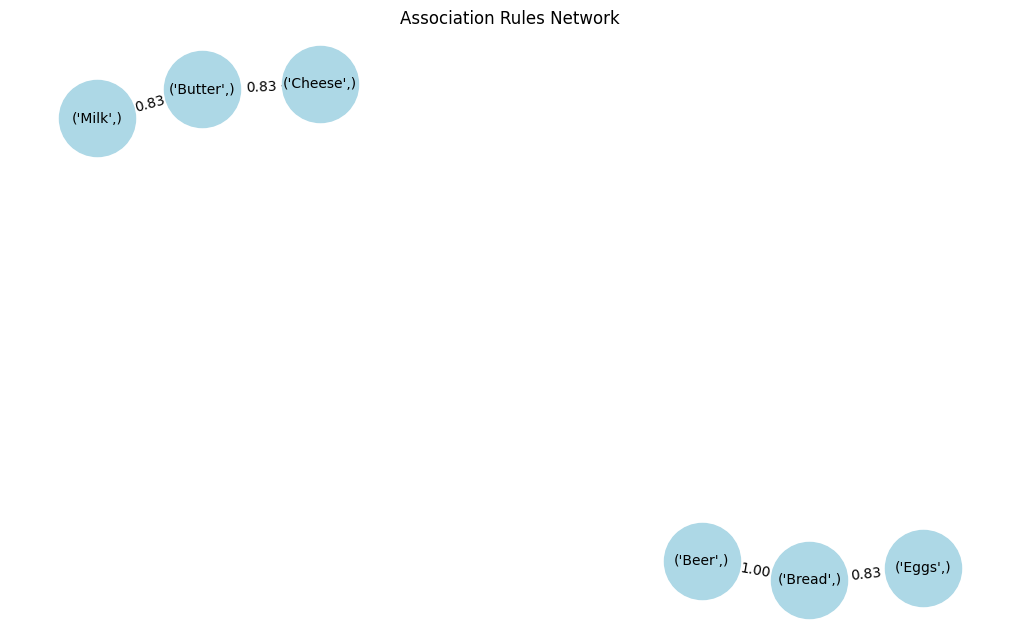
Il grafo di rete rappresenta visivamente le associazioni tra i diversi articoli:
Le aziende applicano ampiamente l'algoritmo Apriori per risolvere vari problemi. Scopriamoli qui sotto.
I retailer usano Apriori per analizzare i modelli di acquisto, aiutandoli a disporre i prodotti per favorire acquisti combinati. Per esempio, se pane e burro compaiono spesso insieme, un negozio può posizionarli vicini per aumentare le vendite. Scopri di più sulla market basket analysis con il nostro tutorial sulla market basket analysis in R.
Le piattaforme online usano Apriori per suggerire prodotti in base agli acquisti precedenti. Se un cliente compra un laptop, tra le raccomandazioni potrebbero esserci accessori come un mouse o una tastiera.
Nel rilevamento delle frodi, Apriori individua transazioni insolite confrontandole con i modelli attesi. Se una transazione con carta di credito devia in modo significativo dalle regole stabilite, può attivare un controllo di sicurezza. Nel contesto dell'anomaly detection, pur non essendo usato direttamente per identificare le anomalie, può aiutare a rilevare combinazioni di articoli rare o inattese che deviano in modo significativo dai modelli di acquisto comuni.
Ci sono diversi vantaggi e svantaggi nell'uso dell'algoritmo Apriori, come vedrai qui sotto.
Apriori è semplice da comprendere ed efficace nel rilevare itemset frequenti in dataset strutturati. È ampiamente usato in settori come retail e sanità per la scoperta di pattern.
L'algoritmo diventa lento con dataset di grandi dimensioni perché genera molti itemset candidati. In presenza di grandi volumi di dati, metodi alternativi come FP-Growth offrono prestazioni migliori.
Apriori resta una delle tecniche più utili per trovare associazioni nei dati. Nonostante le sfide computazionali, fornisce insight preziosi che le aziende usano per migliorare l'esperienza dei clienti e aumentare le vendite.
Pur non essendo l'approccio più veloce per dataset molto grandi, rimane uno strumento fondamentale nel data mining, nell'analytics e nel machine learning. Per saperne di più, esplora il machine learning con Python e avvicinati a diventare machine learning scientist con il nostro percorso di carriera Machine Learning Scientist in Python.
I migliori corsi DataCamp
Programma
Programma
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

