Track
Machine Learning Fundamentals in Python
16 hr
Association rule mining has become essential for businesses aiming to understand customer behaviors and purchasing patterns. This technique identifies items frequently bought together, helping companies optimize product placement, promotions, and recommendations. Such analysis improves business strategies by clearly revealing trends hidden within transaction data.
The Apriori Algorithm is a popular method for mining these association rules because of its simplicity and practical results. Unlike other complex methods, Apriori is straightforward, making it suitable for beginners and effective in real-world applications.
This article explains the Apriori algorithm, illustrates its workflow with clear examples, and shows you how to use it effectively. If you want to get hands-on with machine learning concepts, check out our Machine Learning Scientist in Python career track.
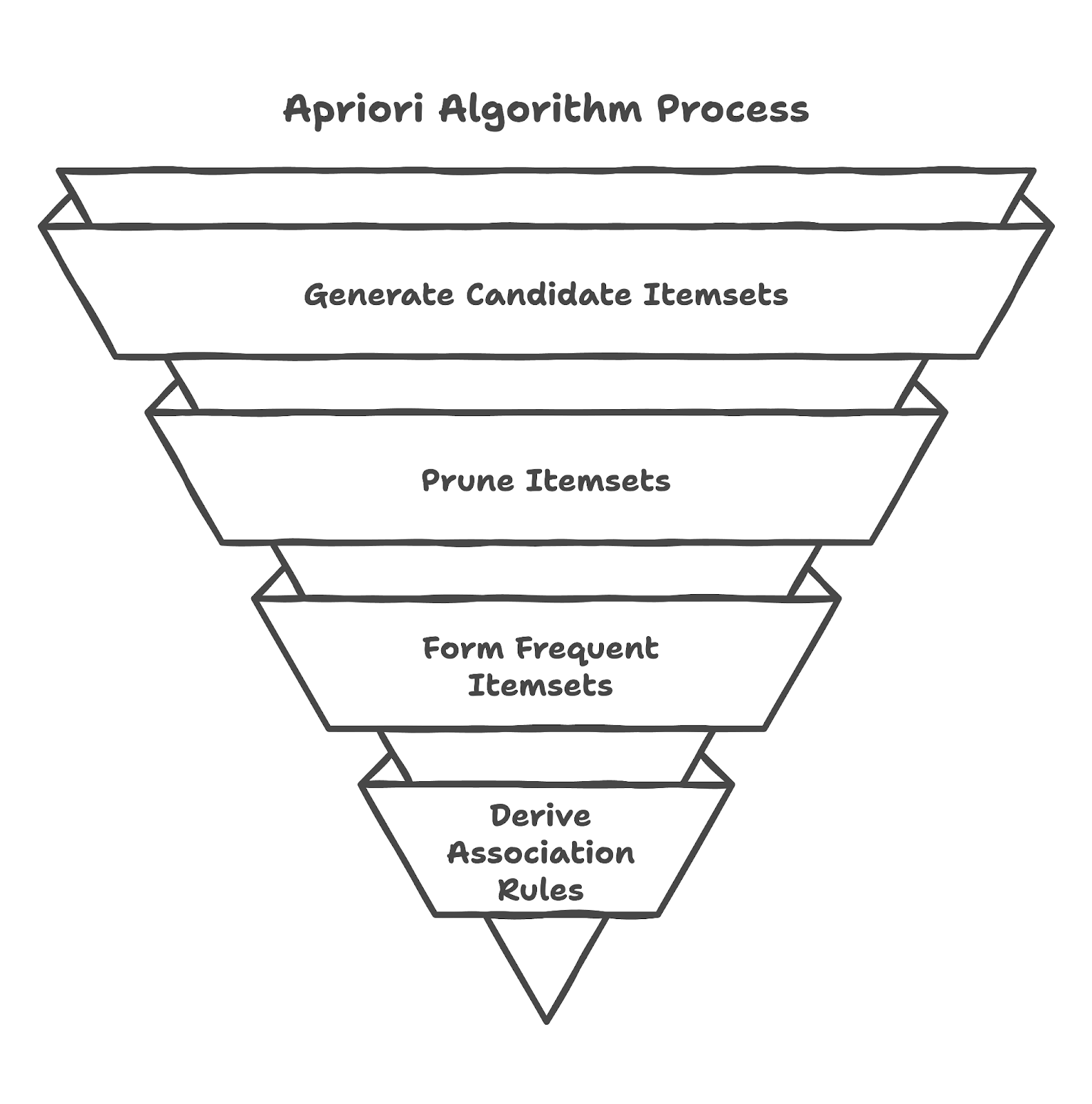
As you will discover from our Association Rule Mining in Python Tutorial, Apriori is an algorithm designed to extract frequent itemsets from transactional databases and generate association rules. It is based on the principle that if an itemset is frequent, all its subsets must also be frequent. This assumption helps reduce the number of possible itemsets that need to be checked, making the process efficient.
A dataset for Apriori typically consists of transactions, where each transaction is a collection of items purchased together. For example, a supermarket's sales data may contain transactions such as:
Each of these transactions represents a basket of items bought in a single purchase. Our Market Basket Analysis in Python course goes into more detail about the application of this concept in Python.
Association rule mining relies on three key metrics:
Support: The frequency with which an item appears in the dataset. It is calculated as:
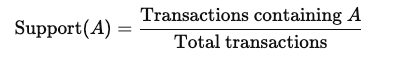
Confidence: The likelihood that item B is purchased when item A is purchased, given by:

Lift: The strength of a rule, measuring how much more likely item B is bought when item A is bought compared to when bought independently:
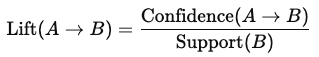
A lift value greater than 1 suggests a strong positive association between items.
Let’s now discover how the Apriori algorithm works.
Consider a dataset with transactions:
Using a minimum support of 50%, the algorithm identifies frequent itemsets and extracts rules such as:
These rules help businesses understand purchasing behaviors and optimize their inventory.
In this section, you learn how to implement the Apriori algorithm in Python.
To use Apriori in Python, install the necessary libraries:
pip install mlxtend pandasThe next step is to load packages and prepare the data:
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
# Expanded dataset
data = {
'Milk': [1, 1, 0, 1, 0, 1, 0, 1, 1, 0],
'Bread': [1, 0, 1, 1, 1, 0, 1, 0, 1, 1],
'Butter': [0, 1, 1, 1, 1, 1, 0, 1, 1, 0],
'Eggs': [1, 0, 0, 1, 1, 1, 1, 0, 0, 1],
'Cheese': [0, 1, 1, 0, 1, 1, 0, 1, 0, 1],
'Diaper': [0, 1, 0, 1, 0, 1, 1, 1, 0, 0],
'Beer': [1, 0, 1, 0, 1, 0, 1, 0, 1, 1]
}
df = pd.DataFrame(data)Next, apply the algorithm.
# Generating frequent itemsets
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)Then, we obtain the association rules:
# Generating frequent itemsets
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)
# Generating association rules
rules = association_rules(frequent_itemsets, metric='confidence', min_threshold=0.6)
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])
antecedents consequents support confidence lift
0 (Butter) (Milk) 0.5 0.714286 1.190476
1 (Milk) (Butter) 0.5 0.833333 1.190476
2 (Bread) (Eggs) 0.5 0.714286 1.190476
3 (Eggs) (Bread) 0.5 0.833333 1.190476
4 (Bread) (Beer) 0.6 0.857143 1.428571
5 (Beer) (Bread) 0.6 1.000000 1.428571
6 (Butter) (Cheese) 0.5 0.714286 1.190476
7 (Cheese) (Butter) 0.5 0.833333 1.190476The support values (0.5 to 0.6) indicate that these associations appear in 50-60% of all transactions.
The confidence scores (0.71 to 1.0) show the reliability of the rules, with some like Beer → Bread being certain (100% confidence).
The lift values (~1.2 to 1.4) suggest moderate but meaningful associations, indicating these pairs of items occur together somewhat more frequently than random chance.
To better understand the association rules generated by the Apriori algorithm, we can visualize them using Matplotlib. A scatter plot helps in examining confidence versus lift, while a heatmap shows support for various item combinations.
import matplotlib.pyplot as plt
import networkx as nx
# Scatter plot of confidence vs lift
plt.figure(figsize=(8,6))
plt.scatter(rules['confidence'], rules['lift'], alpha=0.7, color='b')
plt.xlabel('Confidence')
plt.ylabel('Lift')
plt.title('Confidence vs Lift in Association Rules')
plt.grid()
plt.show()
# Visualizing association rules as a network graph
G = nx.DiGraph()
for _, row in rules.iterrows():
G.add_edge(tuple(row['antecedents']), tuple(row['consequents']), weight=row['confidence'])
plt.figure(figsize=(10, 6))
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, node_color='lightblue', edge_color='gray', node_size=3000, font_size=10)
edge_labels = {(tuple(row['antecedents']), tuple(row['consequents'])): f"{row['confidence']:.2f}"
for _, row in rules.iterrows()}
nx.draw_networkx_edge_labels(G, pos, edge_labels=edge_labels)
plt.title("Association Rules Network")
plt.show()The scatter plot helps identify rules with strong relationships, while the network graph visually represents how different items are associated. These insights guide decision-making in retail, recommendations, and fraud detection.
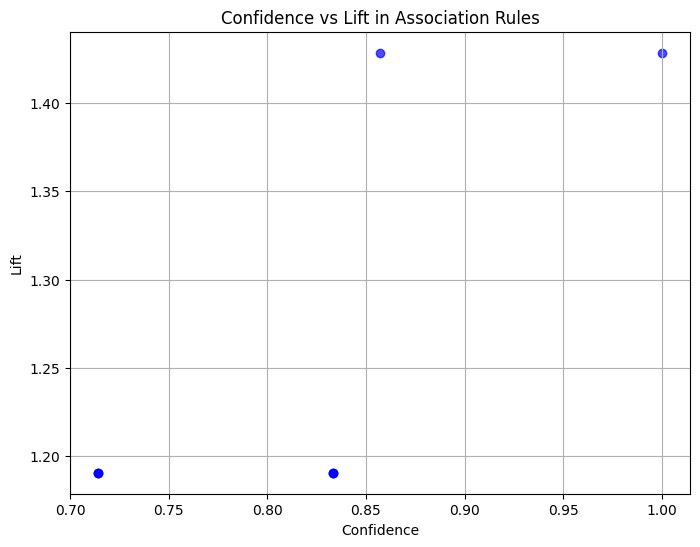
The scatter plot shows the relationship between confidence and lift for the association rules generated. The key observations are:
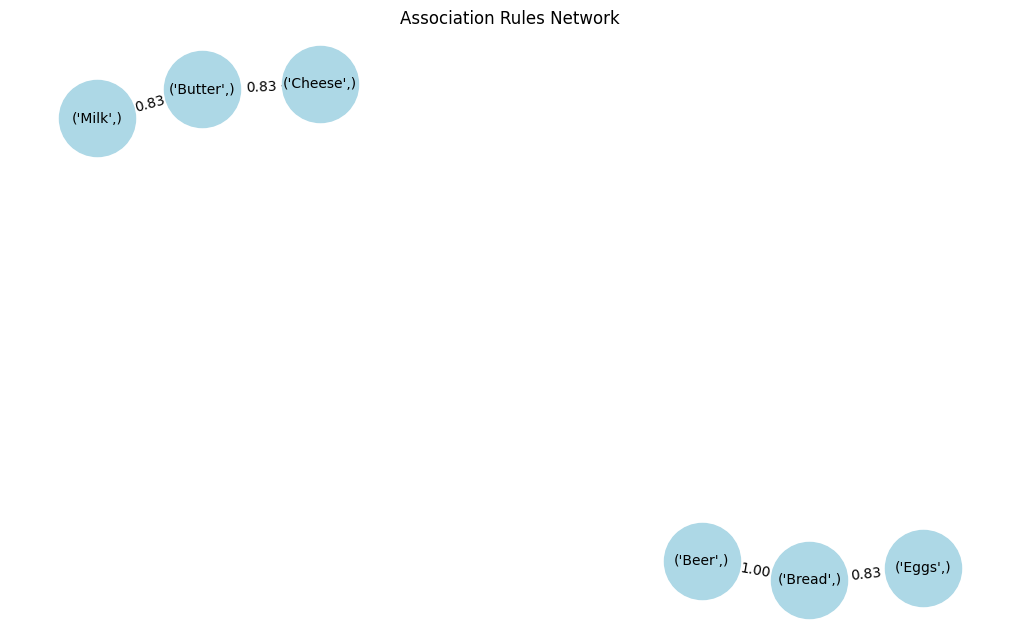
The network graph visually represents the associations between different items:
Businesses widely apply the Apriori algorithm to solve various problems. Let’s discover them below.
Retailers use Apriori to analyze purchase patterns, helping them arrange products to encourage combined purchases. For example, if bread and butter frequently appear together, a store may place them in close proximity to boost sales. Learn more about market basket analysis from our market basket analysis using R tutorial.
Online platforms use Apriori to suggest products based on previous purchases. If a customer buys a laptop, recommendations may include accessories like a mouse or a keyboard.
In fraud detection, Apriori identifies unusual transactions by comparing them to expected patterns. If a credit card transaction deviates significantly from established rules, it may trigger a security check. In anomaly detection, while Apriori is not directly used to identify anomalies, it can help detect rare or unexpected item combinations that deviate significantly from common purchasing patterns.
There are several advantages and disadvantages of using the Apriori algorithm, as you will discover below.
Apriori is simple to understand and effective at discovering frequent itemsets in structured datasets. It is widely used in industries like retail and healthcare for pattern discovery.
The algorithm becomes slow when working with large datasets because it generates many candidate itemsets. In cases with a high volume of data, alternative methods like FP-Growth offer better performance.
Apriori remains one of the most useful techniques for finding associations in data. Despite its computational challenges, it provides valuable insights that businesses use to enhance customer experiences and increase sales.
While it may not be the fastest approach for large datasets, it remains an essential tool in the field of data mining, analytics, and machine learning. To learn more, explore machine learning with Python and work toward becoming a machine learning scientist with our Machine Learning Scientist in Python career track.
Top DataCamp Courses
Track
Track
Course
Tutorial
Moez Ali
Tutorial
Avinash Navlani
Tutorial
Rajesh Kumar
Tutorial
Zoumana Keita
Tutorial
Hafsa Jabeen
Tutorial
Austin Chia
