
Program
AWS Cloud Practitioner (CLF-C02)
10 Hr
AI generatif telah menjadi disruptor di semua sektor, mendorong kemajuan dalam pemrosesan bahasa alami, visi komputer, dan banyak bidang lainnya. Namun, memanfaatkan potensinya sering kali disertai tantangan biaya, infrastruktur yang kompleks, dan kurva pembelajaran yang curam. Di sinilah AWS Bedrock berperan—solusi ini membantu mengatasi hambatan dengan memungkinkan Anda menggunakan foundation model tanpa perlu mengelola infrastruktur.
Tutorial ini bertujuan menjadi panduan lengkap Anda untuk Amazon Bedrock, menjelaskan apa itu, bagaimana cara kerjanya, dan bagaimana Anda dapat menggunakannya. Di akhir panduan ini, Anda akan memiliki informasi dan keterampilan yang diperlukan untuk mengembangkan aplikasi AI generatif Anda sendiri—yang dapat diskalakan, fleksibel, dan selaras dengan tujuan Anda.
Amazon Bedrock adalah layanan terkelola AWS untuk mengakses dan mengelola foundation model (FM), blok bangunan dasar AI generatif oleh Amazon Web Services (AWS). Bedrock membuat semuanya sederhana sehingga Anda tidak perlu khawatir tentang provisioning GPU, mengonfigurasi pipeline model, atau mengelola infrastruktur lainnya.
AWS Bedrock adalah gerbang menuju inovasi. Ini adalah platform terpadu yang memungkinkan pengembang mengeksplorasi, menguji, dan menerapkan model AI mutakhir dari penyedia terkemuka seperti Anthropic, Stability AI, dan Titan milik Amazon.
Sebagai contoh, bayangkan Anda sedang mengembangkan chatbot dukungan pelanggan. Dengan AWS Bedrock, Anda dapat memilih model bahasa yang canggih, menyetelnya untuk kebutuhan aplikasi Anda, dan menanamkannya ke dalam aplikasi tanpa perlu menulis konfigurasi server dalam kode.
Fitur AWS Bedrock dirancang untuk menyederhanakan dan mempercepat perjalanan dari konsep AI ke produksi. Mari kita uraikan secara rinci.
Salah satu manfaat paling signifikan dari AWS Bedrock adalah ragam foundation model yang tersedia. Baik Anda mengerjakan aplikasi teks, konten visual, atau AI yang aman dan dapat ditafsirkan, Bedrock siap membantu. Berikut beberapa model yang tersedia:
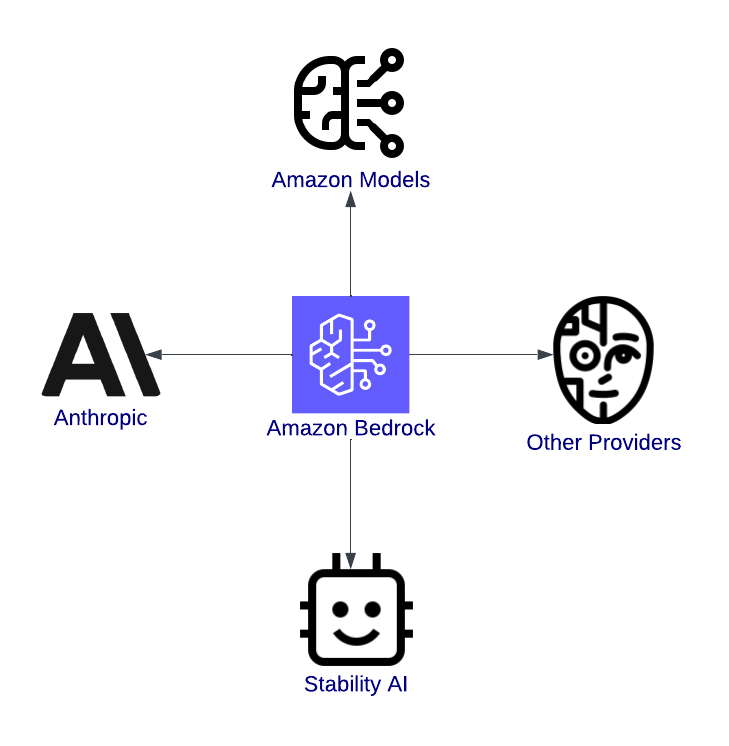
Gambaran umum Amazon Bedrock, menyoroti integrasinya dengan model-model.
AWS Bedrock melakukan abstraksi pengelolaan infrastruktur, yang berarti:
Aplikasi AI generatif umumnya memiliki permintaan yang tidak dapat diprediksi. Sebuah chatbot mungkin merespons ratusan pengguna saat jam sibuk dan hanya beberapa di malam hari. AWS Bedrock mengatasinya dengan skalabilitas bawaan:
AWS Bedrock melampaui penyediaan model yang kuat—layanan ini terintegrasi dengan layanan AWS lainnya untuk mendukung alur kerja AI end-to-end. Beberapa integrasi meliputi:
Bagian ini akan memandu Anda menyiapkan izin yang diperlukan, membuat akun AWS, dan memulai dengan AWS Bedrock.
Jika Anda belum memiliki akun, buka halaman pendaftaran AWS dan buat akun. Untuk pengguna yang sudah ada, pastikan pengguna IAM Anda memiliki hak administrator.

Halaman pendaftaran AWS, menampilkan eksplorasi Free Tier untuk akun baru.
Jika Anda mencari langkah terperinci, silakan kunjungi panduan resmi AWS.
Amazon Bedrock dapat diakses melalui AWS Management Console. Ikuti langkah-langkah ini untuk menemukan dan mulai menggunakannya:
Hasil pencarian AWS Management Console untuk Bedrock.

Halaman Amazon Bedrock Providers menampilkan opsi model tanpa server dari Amazon.
Antarmuka Amazon Bedrock Chat/Text Playground.
AWS Identity and Access Management (IAM) sangat penting untuk mengakses AWS Bedrock dengan aman. Ikuti langkah-langkah berikut untuk mengonfigurasi izin:
AWS IAM Policy Editor dalam mode JSON
{
"Version": "2012-10-17",
"Statement": [ {
"Sid": "BedrockFullAccess",
"Effect": "Allow",
"Action": ["bedrock:*"],
"Resource": "*"
}
]
}Catatan: Kebijakan di atas dapat dilampirkan ke peran apa pun yang perlu mengakses layanan Amazon Bedrock. Bisa ke SageMaker atau pengguna. Saat menggunakan Amazon SageMaker, execution role untuk notebook Anda biasanya merupakan pengguna atau peran yang berbeda dari yang Anda gunakan untuk masuk ke AWS Management Console. Untuk mengetahui cara menjelajahi layanan Amazon Bedrock menggunakan AWS Console, pastikan Anda mengotorisasi pengguna atau peran Console Anda. Anda dapat menjalankan notebook dari lingkungan apa pun yang memiliki akses ke layanan AWS Bedrock dan kredensial yang valid.
Aplikasi AI generatif dibangun di atas foundation model yang di-fine-tune untuk tugas tertentu, seperti pembuatan teks, pembuatan gambar, atau transformasi data. Berikut panduan langkah demi langkah untuk memilih foundation model, menggunakan pekerjaan inferensi dasar, dan memodifikasi respons model agar sesuai dengan kebutuhan Anda.
Memilih foundation model yang tepat itu penting karena bergantung pada kebutuhan proyek Anda. Berikut cara membuat pilihan:
1. Identifikasi use case Anda:
2. Evaluasi kemampuan model:
Sebelum menggunakan model ini, Anda perlu mengaktifkan akses model dalam akun AWS Anda. Berikut langkah-langkah penyiapannya:
Halaman manajemen akses model Amazon Bedrock.
Untuk melakukan inferensi menggunakan foundation model yang dipilih di AWS Bedrock, ikuti langkah-langkah berikut:
pip install boto3import boto3
import json
from botocore.exceptions import ClientError
# Set the AWS Region
region = "us-east-1"
# Initialize the Bedrock Runtime client
client = boto3.client("bedrock-runtime", region_name=region)# Define the model ID for Amazon Titan Express v1
model_id = "amazon.titan-text-express-v1"
# Define the input prompt
prompt = """
Command: Compose an email from Tom, Customer Service Manager, to the customer "Nancy"
who provided negative feedback on the service provided by our customer support
Engineer"""# Configure inference parameters
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512, # Limit the response length
"temperature": 0.5, # Control the randomness of the output
},
}
# Convert the request payload to JSON
request_payload = json.dumps(inference_parameters)try:
# Invoke the model
response = client.invoke_model(
modelId=model_id,
body=request_payload,
contentType="application/json",
accept="application/json"
)
# Decode the response body
response_body = json.loads(response["body"].read())
# Extract and print the generated text
generated_text = response_body["results"][0]["outputText"]
print("Generated Text:\n", generated_text)
except ClientError as e:
print(f"ClientError: {e.response['Error']['Message']}")
except Exception as e:
print(f"An error occurred: {e}")Catatan: Anda dapat mengakses dan menyalin kode lengkap langsung dari GitHub Gist.
Anda dapat mengharapkan output berikut:
% python3 main.py
Generated Text:
Tom:
Nancy,
I am writing to express my sincere apologies for the negative experience you had with our customer support engineer. It is unacceptable that we did not meet your expectations, and I want to assure you that we are taking steps to prevent this from happening in the future.
Sincerely,
Tom
Customer Service ManagerUntuk menyetel perilaku output model, Anda dapat menyesuaikan parameter seperti temperature dan maxTokenCount:
temperature: Parameter ini mengontrol kerandoman output. Nilai lebih rendah meningkatkan ketetapan output, dan nilai lebih tinggi meningkatkan variasi.MaxTokenCount: Menetapkan panjang maksimum output yang dihasilkan.Contoh:
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 256, # Limit the response length
"temperature": 0.7, # Control the randomness of the output
},
}Dengan menyesuaikan parameter ini, Anda dapat menyesuaikan tingkat kreativitas dan panjang konten yang dihasilkan agar lebih sesuai dengan kebutuhan aplikasi Anda.
Mari beralih fokus ke dua pendekatan lanjutan: meningkatkan AI menggunakan Retrieval-Augmented Generation (RAG) serta mengelola dan menerapkan model dalam skala besar.
RAG mengharuskan kita memiliki knowledge base. Sebelum menyiapkan knowledge base di Amazon Bedrock, Anda perlu membuat bucket S3 dan mengunggah file yang diperlukan. Ikuti langkah-langkah berikut:
Langkah 2: Unggah file ke bucket S3
octank_financial_10K.pdf.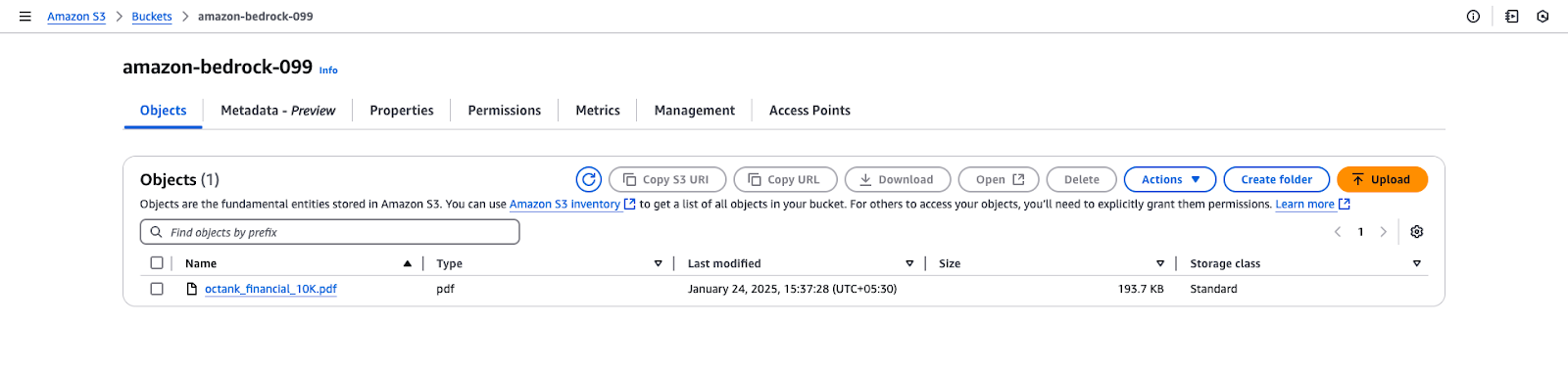
Tampilan bucket Amazon S3 untuk "amazon-bedrock-099".
Amazon Bedrock memungkinkan Anda membuat knowledge base yang didukung oleh database vektor. Langkah-langkah berikut akan memandu Anda membuat knowledge base, mengonfigurasi sumber data, serta memilih embeddings dan penyimpanan vektor.
knowledge-base-quick-start).AmazonBedrockExecutionRoleForKnowledgeBase.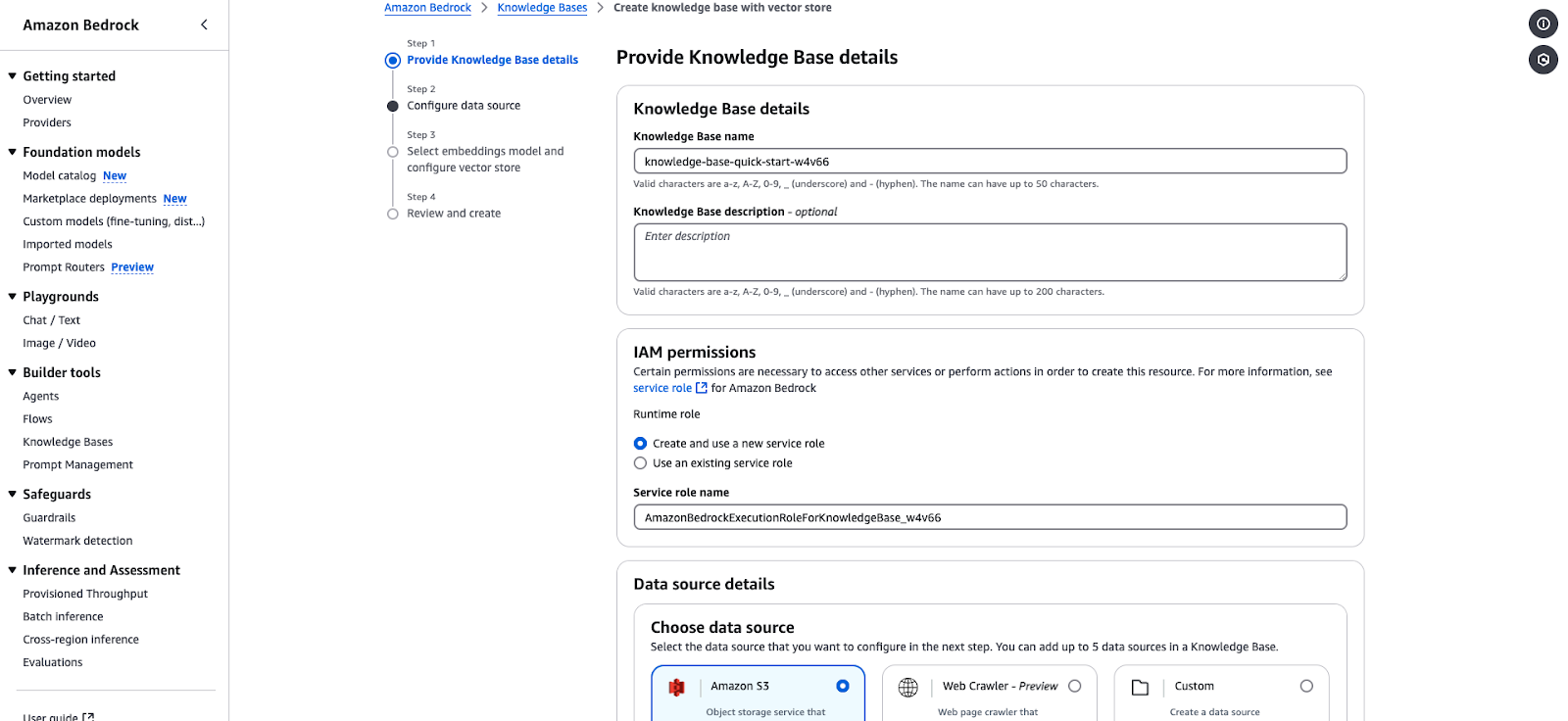
Wizard pembuatan Amazon Bedrock Knowledge Base.
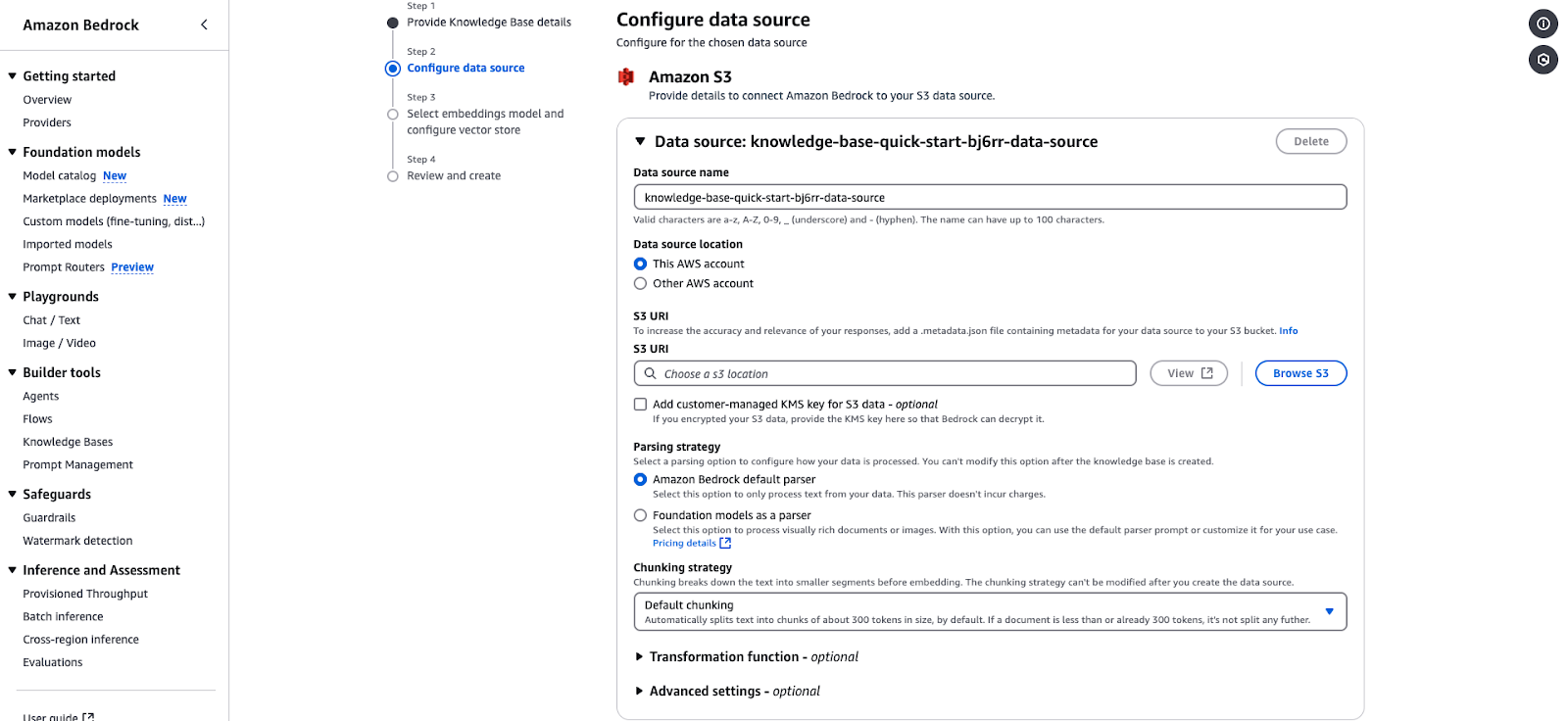
Halaman konfigurasi sumber data Amazon Bedrock untuk mengintegrasikan knowledge base berbasis S3.
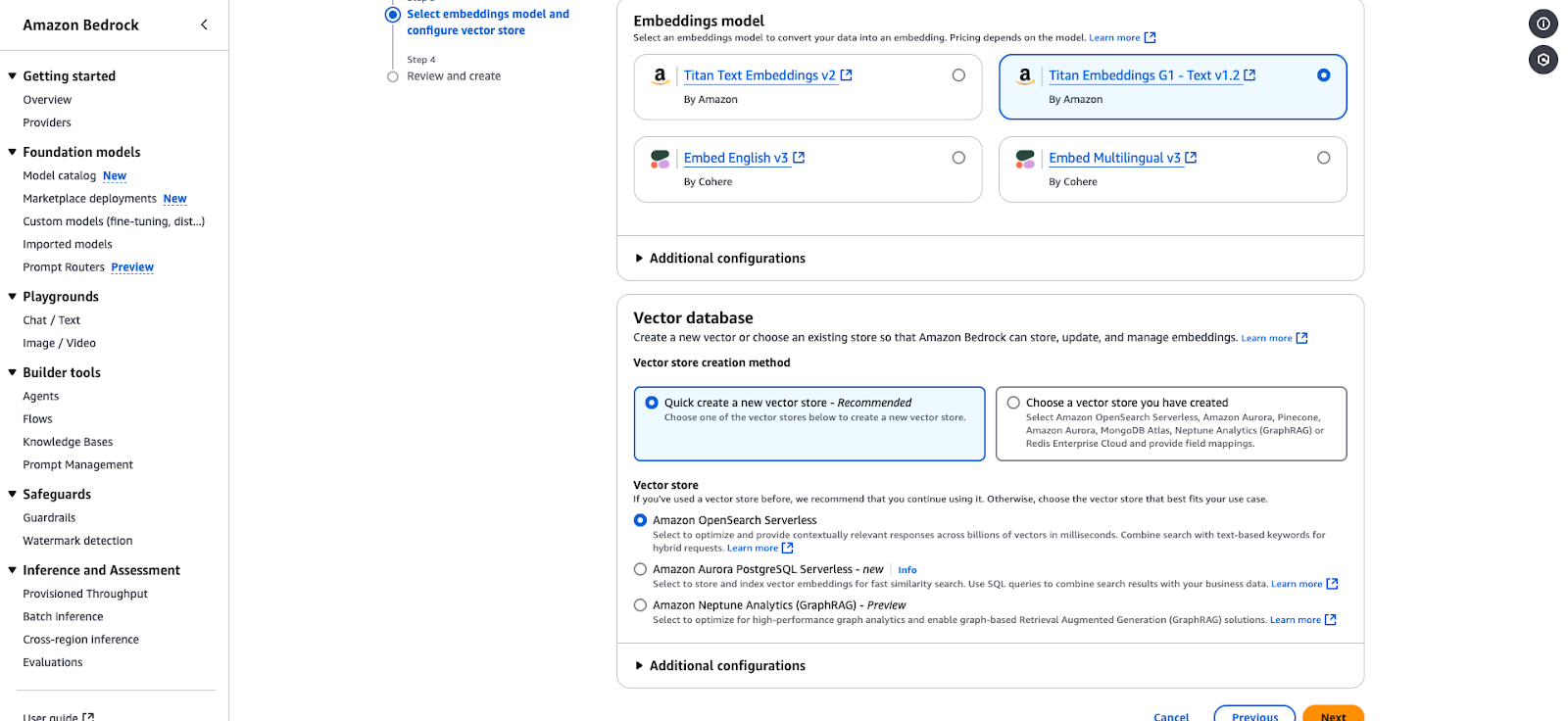
Halaman konfigurasi Amazon Bedrock untuk memilih model embedding dan vector store.
knowledge-base-quick-start).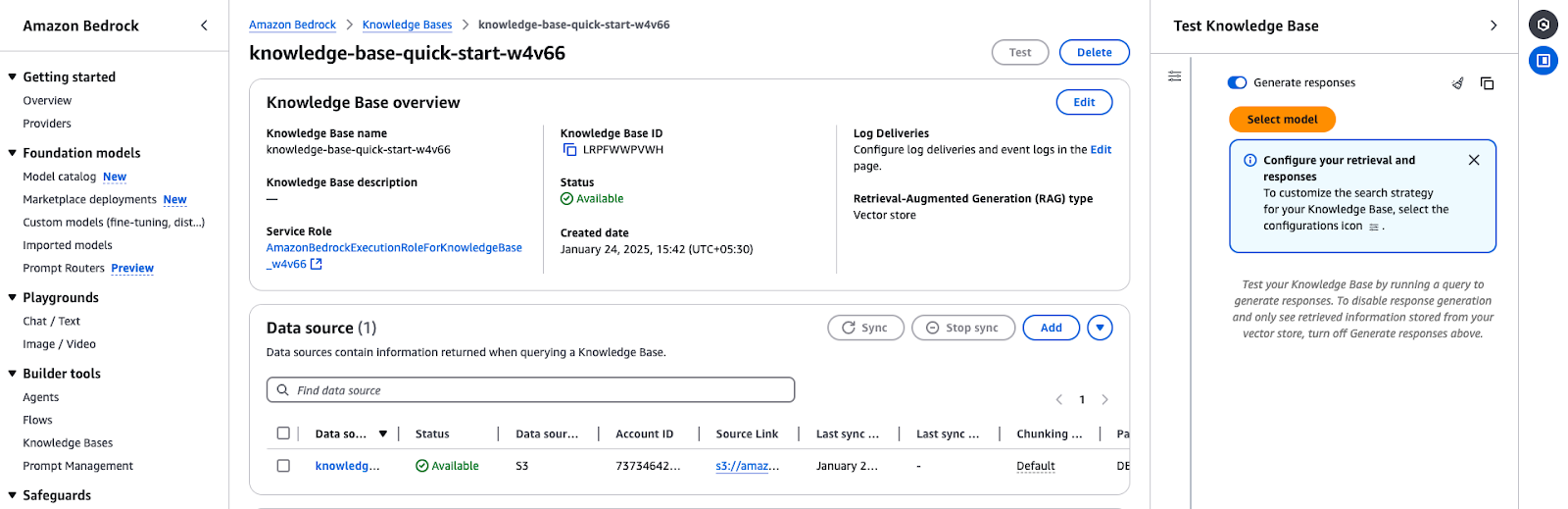
Ringkasan Amazon Bedrock Knowledge Base menampilkan detail konfigurasi dan status sumber data.
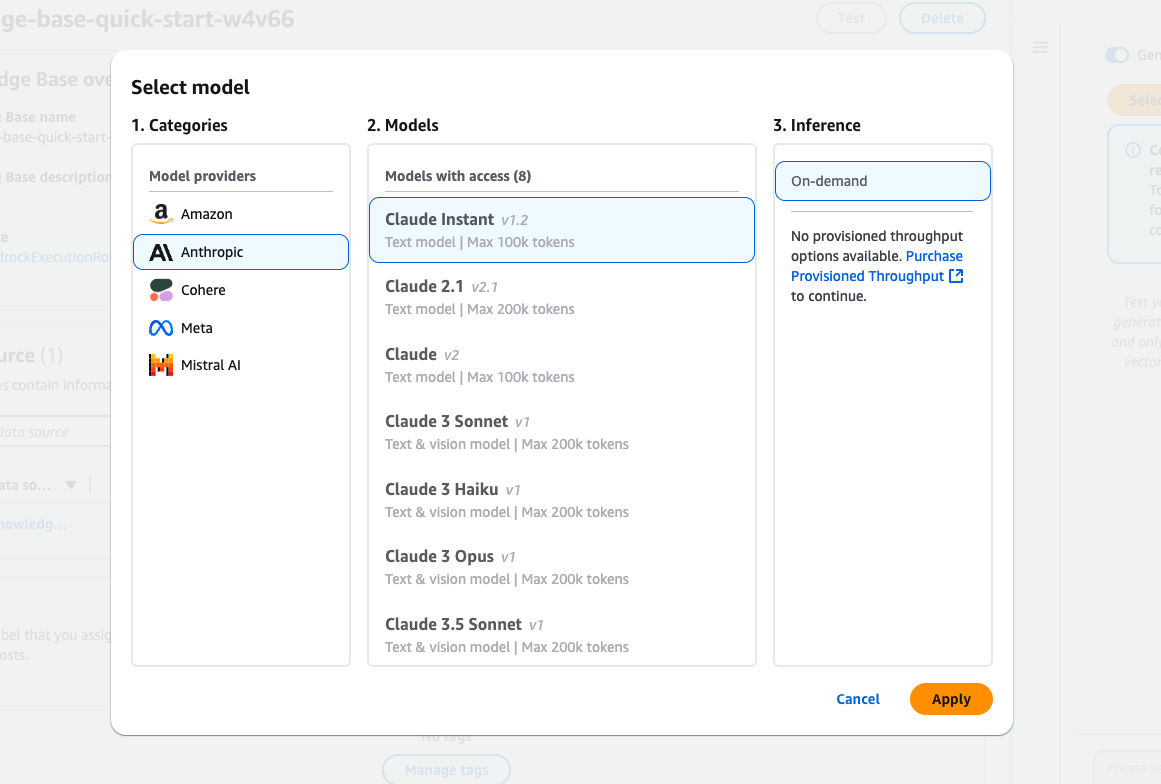
Antarmuka pemilihan model Amazon Bedrock menampilkan berbagai model Claude dari Anthropic.
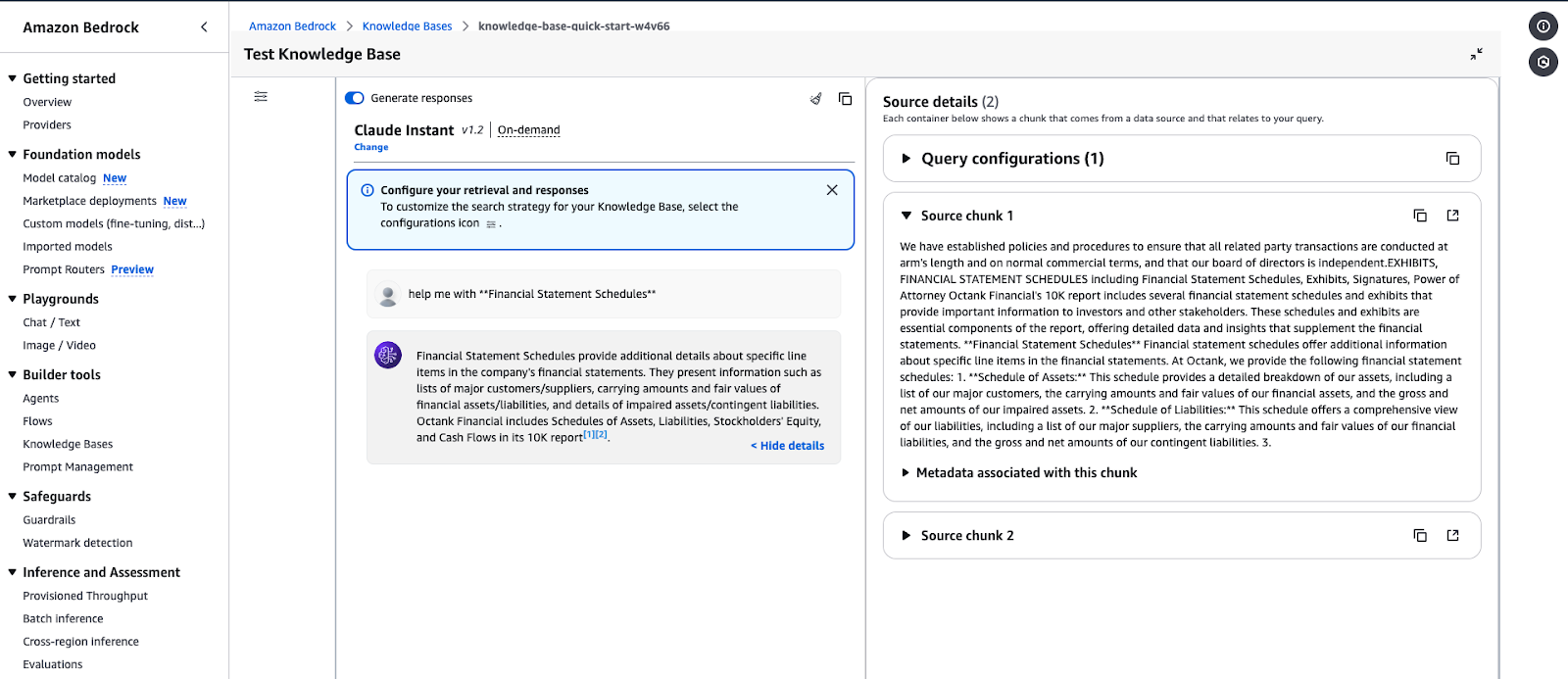
Antarmuka pengujian Amazon Bedrock Knowledge Base menampilkan respons untuk sebuah kueri.
Contoh output kueri:
Dengan menggunakan layanan AWS seperti Lambda, Amazon Bedrock dapat mengelola dan menerapkan model AI dalam skala besar. Pendekatan hemat biaya ini memastikan ketersediaan tinggi dan penskalaan otomatis untuk aplikasi bertenaga AI.
Di bagian ini, kita akan menggunakan AWS Lambda untuk memanggil model Bedrock secara dinamis sehingga Anda dapat memproses prompt sesuai permintaan.
Halaman pembuatan fungsi AWS Lambda.
{
"prompt": "Write a formal apology letter for a late delivery."
}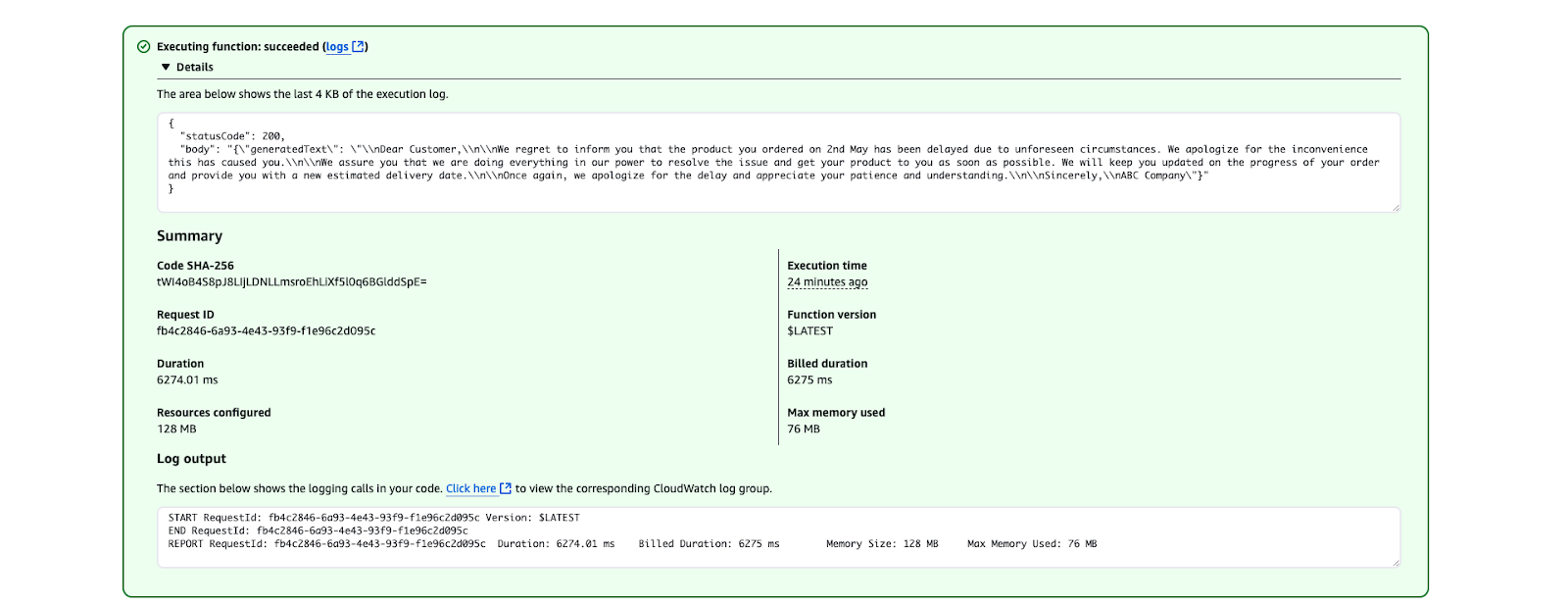
Hasil eksekusi AWS Lambda menunjukkan fungsi berjalan sukses.
Optimalkan biaya:
Amankan fungsi Lambda:
Pantau dan catat log:
Di bagian ini, saya membagikan beberapa praktik terbaik saat bekerja dengan Amazon Bedrock, mulai dari mengoptimalkan biaya hingga menjaga keamanan dan akurasi.
Mengelola biaya di AWS Bedrock dapat melibatkan pemanfaatan Amazon SageMaker untuk menerapkan model dan menggunakan Spot instance guna menghemat hingga 90% biaya. Berikut beberapa praktik terbaik saya:
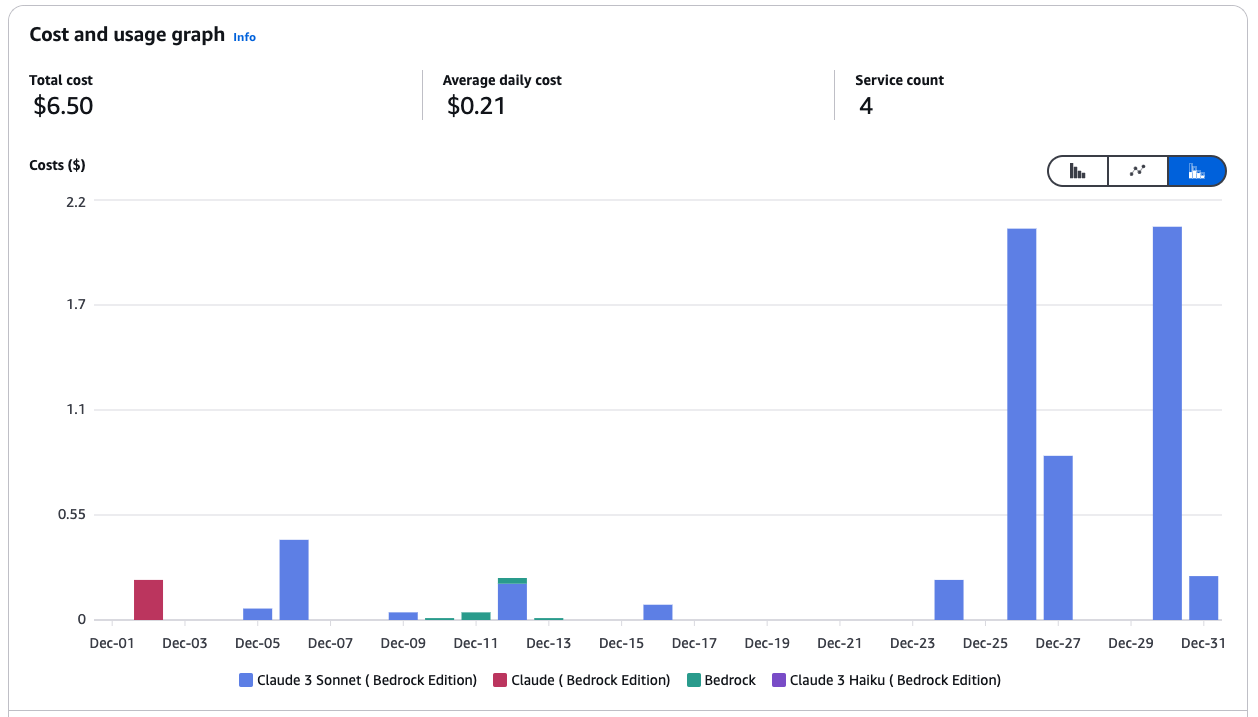
Grafik biaya dan penggunaan untuk layanan Amazon Bedrock.
from sagemaker.mxnet import MXNet
# Use spot instances for cost efficiency
use_spot_instances = True
# Maximum runtime for the training job (in seconds)
max_run = 600
# Maximum wait time for Spot instance availability (in seconds); set only if using Spot instances
max_wait = 1200 if use_spot_instances else None
# Define the MXNet estimator for the training job
mnist_estimator = MXNet(
entry_point='source_dir/mnist.py', # Path to the script that contains the model training code
role=role, # IAM role used for accessing AWS resources (e.g., S3, SageMaker)
output_path=model_artifacts_location, # S3 location to save the trained model artifacts
code_location=custom_code_upload_location, # S3 location to upload the training script
instance_count=1, # Number of instances to use for training
instance_type='ml.m4.xlarge', # Instance type for the training job
framework_version='1.6.0', # Version of the MXNet framework to use
py_version='py3', # Python version for the environment
distribution={'parameter_server': {'enabled': True}}, # Enable distributed training with a parameter server
hyperparameters={ # Training hyperparameters
'learning-rate': 0.1, # Learning rate for the training job
'epochs': 5 # Number of training epochs
},
use_spot_instances=use_spot_instances, # Enable Spot instances for cost savings
max_run=max_run, # Maximum runtime for the training job
max_wait=max_wait, # Maximum wait time for Spot instance availability
checkpoint_s3_uri=checkpoint_s3_uri # S3 URI for saving intermediate checkpoints
)
# Start the training job and specify the locations of training and testing datasets
mnist_estimator.fit({
'train': train_data_location, # S3 location of the training dataset
'test': test_data_location # S3 location of the testing/validation dataset
})
Log AWS CloudWatch
Untuk memastikan keamanan, kepatuhan, dan kinerja Amazon Bedrock, penting untuk mengikuti praktik terbaik. Berikut rekomendasi saya:
Memastikan model akurat, andal, dan selaras dengan tujuan bisnis dicapai dengan memantau dan mengevaluasi model. Berikut beberapa praktik terbaik:
Dasbor metrik menampilkan jumlah pemanggilan, latensi, dan jumlah token untuk berbagai model di Amazon Bedrock.
AWS Bedrock mengubah cara aplikasi AI generatif dikembangkan dan menjadi platform terpusat untuk menggunakan foundation model tanpa perlu memikirkan infrastruktur.
Mulai dari titik ini, tutorial langkah demi langkah ini seharusnya membantu Anda mengidentifikasi model yang tepat, membuat alur kerja yang aman dan dapat diskalakan, serta mengintegrasikan fitur seperti retrieval-augmented generation (RAG) untuk kustomisasi yang lebih luas. Dengan praktik terbaik untuk biaya, keamanan, dan pemantauan yang diterapkan, Anda siap mengembangkan dan mengelola solusi AI untuk memenuhi tujuan Anda.
Untuk memperdalam keahlian AWS Anda, jelajahi kursus berikut:
Pelajari lebih lanjut tentang AWS dengan kursus-kursus ini!
Program
Kursus
Kursus