
Cursus
AWS Cloud Practitioner (CLF-C02)
10 h
L'IA générative est devenue un perturbateur dans tous les secteurs, entraînant des progrès dans le traitement du langage naturel, la vision par ordinateur et bien d'autres domaines. Toutefois, l'exploitation de son potentiel s'est souvent accompagnée de problèmes de coûts, d'infrastructures complexes et de courbes d'apprentissage abruptes. C'est là qu'intervient AWS Bedrock, une solution qui vous aide à débloquer la situation en vous permettant d'utiliser des modèles de base sans avoir à gérer l'infrastructure.
Ce tutoriel a pour but d'être votre guide complet sur Amazon Bedrock, en décrivant ce qu'il est, comment il fonctionne, et comment vous pouvez l'utiliser. À la fin de ce guide, vous disposerez des informations et des compétences nécessaires pour développer vos propres applications d'IA générative - évolutives, flexibles et adaptées à vos objectifs.
Amazon Bedrock est un service AWS géré pour l'accès et la gestion des modèles de fondation (FM), les éléments de base de l'IA générative d'Amazon Web Services (AWS). Bedrock rend les choses si simples que vous n'avez pas besoin de vous préoccuper du provisionnement des GPU, de la configuration des pipelines de modèles, ou de la gestion de toute autre infrastructure.
AWS Bedrock est une passerelle vers l'innovation. Il s'agit d'une plateforme unifiée permettant aux développeurs d'explorer, de tester et de déployer des modèles d'IA de pointe provenant de fournisseurs de premier plan tels qu'Anthropic, Stability AI et Titan d'Amazon.
Imaginez, par exemple, que vous développiez un chatbot pour l'assistance à la clientèle. Avec AWS Bedrock, vous pouvez sélectionner un modèle de langage sophistiqué, l'adapter aux besoins de votre application et l'intégrer dans votre application sans jamais avoir à écrire la configuration du serveur dans le code.
Les fonctionnalités d'AWS Bedrock sont conçues pour simplifier et accélérer le passage du concept d'IA à la production. Examinons-les en détail.
L'un des avantages les plus significatifs d'AWS Bedrock est la variété des modèles de fondations disponibles. Que vous travailliez sur des applications textuelles, du contenu visuel ou une IA sûre et interprétable, Bedrock vous couvre. Voici quelques-uns des modèles disponibles :
Vue d'ensemble d'Amazon Bedrock, mettant en évidence son intégration avec les modèles.
AWS Bedrock fait abstraction de la gestion de l'infrastructure, ce qui signifie :
Les applications génératives d'IA ont généralement une demande imprévisible. Un chatbot peut répondre à des centaines d'utilisateurs pendant les heures de pointe et à seulement quelques uns pendant la nuit. Mais AWS Bedrock résout ce problème grâce à son évolutivité intégrée :
AWS Bedrock ne se contente pas de fournir des modèles puissants : il s'intègre à d'autres services AWS pour prendre en charge les flux de travail d'IA de bout en bout. Parmi les intégrations, citons
Cette section vous guidera dans la mise en place des autorisations nécessaires, la création d'un compte AWS et le démarrage d'AWS Bedrock.
Si vous n'en avez pas encore, rendez-vous sur la page d'inscription d'AWS et créez un compte. Pour les utilisateurs existants, assurez-vous que votre utilisateur IAM dispose de privilèges d'administrateur.

La page d'inscription à AWS, qui présente l'exploration du produit Free Tier pour les nouveaux comptes.
Si vous souhaitez connaître les étapes détaillées, consultez le guide officiel d'AWS.
Amazon Bedrock est accessible via la console de gestion AWS. Suivez les étapes suivantes pour le localiser et commencer à l'utiliser :
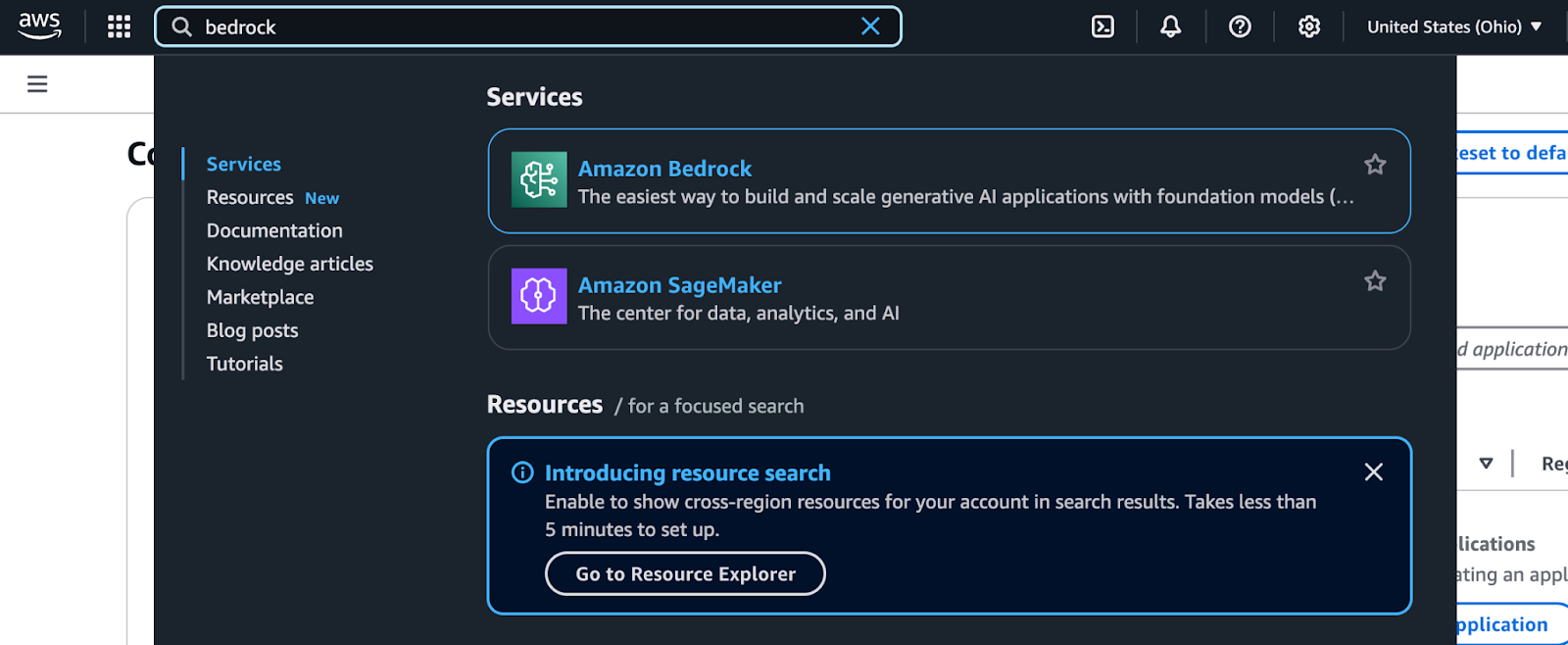
Résultats de la recherche de Bedrock dans la console de gestion AWS.

La page Amazon Bedrock Providers présente les options de modèles sans serveur d'Amazon.
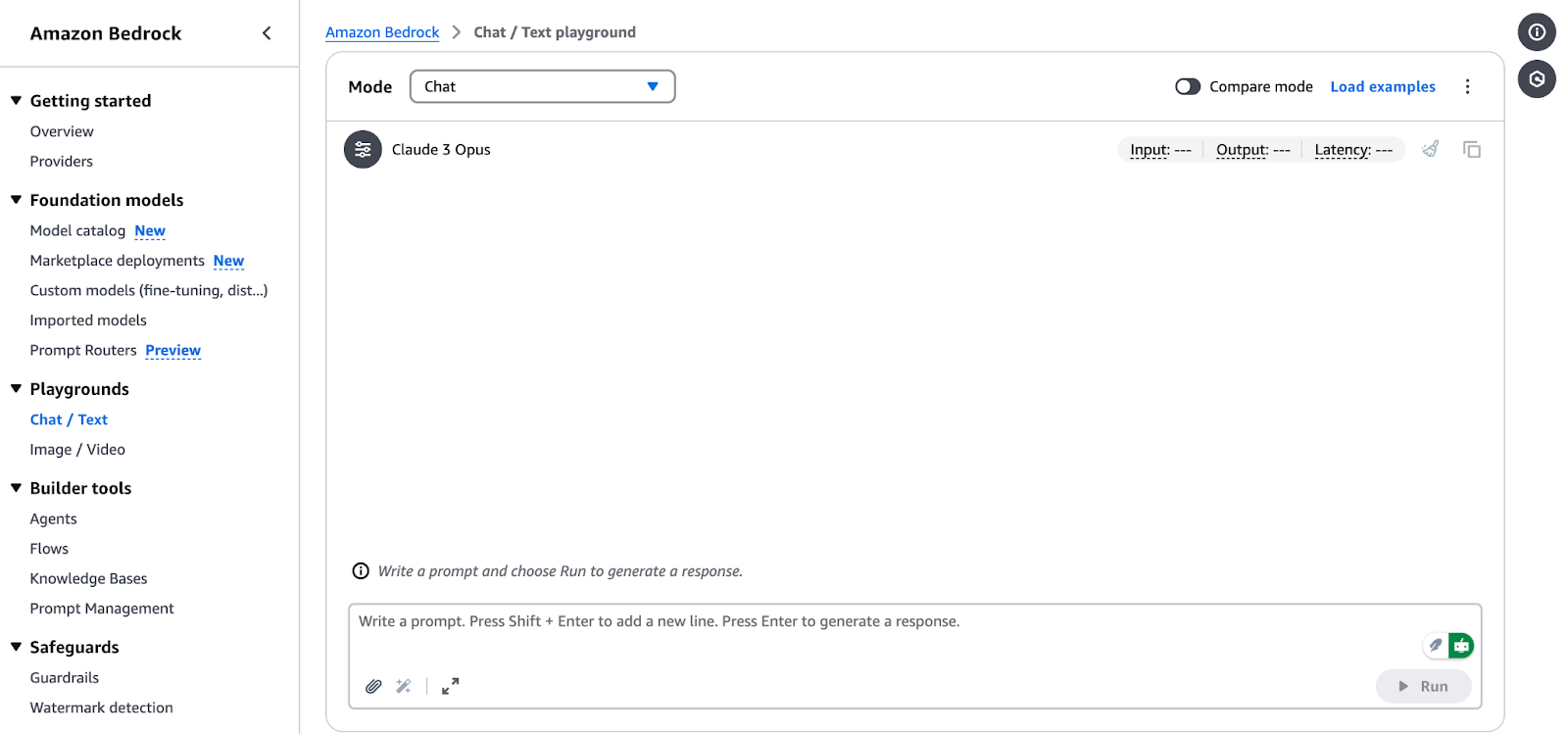
Interface Amazon Bedrock Chat/Text Playground.
La gestion de l'identité et de l'accès à AWS (IAM) est essentielle pour accéder en toute sécurité à AWS Bedrock. Procédez comme suit pour configurer les autorisations :
Éditeur de politiques AWS IAM en mode JSON
{
"Version": "2012-10-17",
"Statement": [ {
"Sid": "BedrockFullAccess",
"Effect": "Allow",
"Action": ["bedrock:*"],
"Resource": "*"
}
]
}Note : La politique ci-dessus peut être attachée à n'importe quel rôle qui doit accéder au service Amazon Bedrock. Il peut s'agir de SageMaker ou d'un utilisateur. Lorsque vous utilisez Amazon SageMaker, le rôle d'exécution de votre bloc-notes est généralement un utilisateur ou un rôle différent de celui que vous utilisez pour vous connecter à la console de gestion AWS. Pour savoir comment explorer le service Amazon Bedrock à l'aide de la console AWS, assurez-vous d'autoriser votre utilisateur ou votre rôle dans la console. Vous pouvez exécuter les carnets à partir de n'importe quel environnement ayant accès au service AWS Bedrock et disposant d'informations d'identification valides.
Les applications d'IA générative reposent sur des modèles de base qui sont affinés pour une tâche particulière, comme la génération de texte, la création d'images ou la transformation de données. Vous trouverez ci-dessous un guide étape par étape sur le choix d'un modèle de base, l'utilisation des travaux d'inférence de base et la modification des réponses du modèle en fonction de vos besoins.
Le choix du bon modèle de fondation est important car il dépend des besoins de votre projet. Voici comment faire une sélection :
1. Identifiez votre cas d'utilisation :
2. Évaluer les capacités du modèle :
Avant d'utiliser ces modèles, vous devez activer l'accès aux modèles dans votre compte AWS. Voici les étapes à suivre pour le mettre en place :
Page de gestion de l'accès au modèle Amazon Bedrock.
Pour effectuer une inférence à l'aide d'un modèle de fondation sélectionné dans AWS Bedrock, procédez comme suit :
pip install boto3import boto3
import json
from botocore.exceptions import ClientError
# Set the AWS Region
region = "us-east-1"
# Initialize the Bedrock Runtime client
client = boto3.client("bedrock-runtime", region_name=region)# Define the model ID for Amazon Titan Express v1
model_id = "amazon.titan-text-express-v1"
# Define the input prompt
prompt = """
Command: Compose an email from Tom, Customer Service Manager, to the customer "Nancy"
who provided negative feedback on the service provided by our customer support
Engineer"""# Configure inference parameters
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512, # Limit the response length
"temperature": 0.5, # Control the randomness of the output
},
}
# Convert the request payload to JSON
request_payload = json.dumps(inference_parameters)try:
# Invoke the model
response = client.invoke_model(
modelId=model_id,
body=request_payload,
contentType="application/json",
accept="application/json"
)
# Decode the response body
response_body = json.loads(response["body"].read())
# Extract and print the generated text
generated_text = response_body["results"][0]["outputText"]
print("Generated Text:\n", generated_text)
except ClientError as e:
print(f"ClientError: {e.response['Error']['Message']}")
except Exception as e:
print(f"An error occurred: {e}")Note : Vous pouvez accéder et copier le code complet directement depuis la GitHub Gist.
Vous pouvez vous attendre au résultat suivant :
% python3 main.py
Generated Text:
Tom:
Nancy,
I am writing to express my sincere apologies for the negative experience you had with our customer support engineer. It is unacceptable that we did not meet your expectations, and I want to assure you that we are taking steps to prevent this from happening in the future.
Sincerely,
Tom
Customer Service ManagerPour affiner le comportement de la sortie du modèle, vous pouvez ajuster des paramètres tels que temperature et maxTokenCount:
temperature: Ce paramètre contrôle le caractère aléatoire de la sortie. Les valeurs inférieures augmentent la détermination de la sortie, et les valeurs supérieures augmentent la variabilité.MaxTokenCount: Définit la longueur maximale de la sortie générée.Par exemple :
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 256, # Limit the response length
"temperature": 0.7, # Control the randomness of the output
},
}En ajustant ces paramètres, vous pouvez mieux adapter la créativité et la longueur du contenu généré aux besoins de votre application.
Passons à la vitesse supérieure et concentrons-nous sur deux approches avancées : l'amélioration de l'IA à l'aide de la génération améliorée par récupération (RAG) et la gestion et le déploiement de modèles à grande échelle.
Les RAG exigent que nous disposions d'une base de connaissances. Avant de configurer la base de connaissances dans Amazon Bedrock, vous devez créer un seau S3 et télécharger les fichiers nécessaires. Procédez comme suit :
Étape 2 : Télécharger des fichiers vers le panier S3
octank_financial_10K.pdf.
Vue du panier Amazon S3 pour "amazon-bedrock-099".
Amazon Bedrock vous permet de créer une base de connaissances alimentée par des bases de données vectorielles. Les étapes suivantes vous guideront dans la création d'une base de connaissances, la configuration d'une source de données et la sélection d'embeddings et de magasins de vecteurs.
knowledge-base-quick-start).AmazonBedrockExecutionRoleForKnowledgeBase.
Assistant de création de la base de connaissances Amazon Bedrock.
Page de configuration de la source de données Amazon Bedrock pour l'intégration d'une base de connaissances basée sur S3.
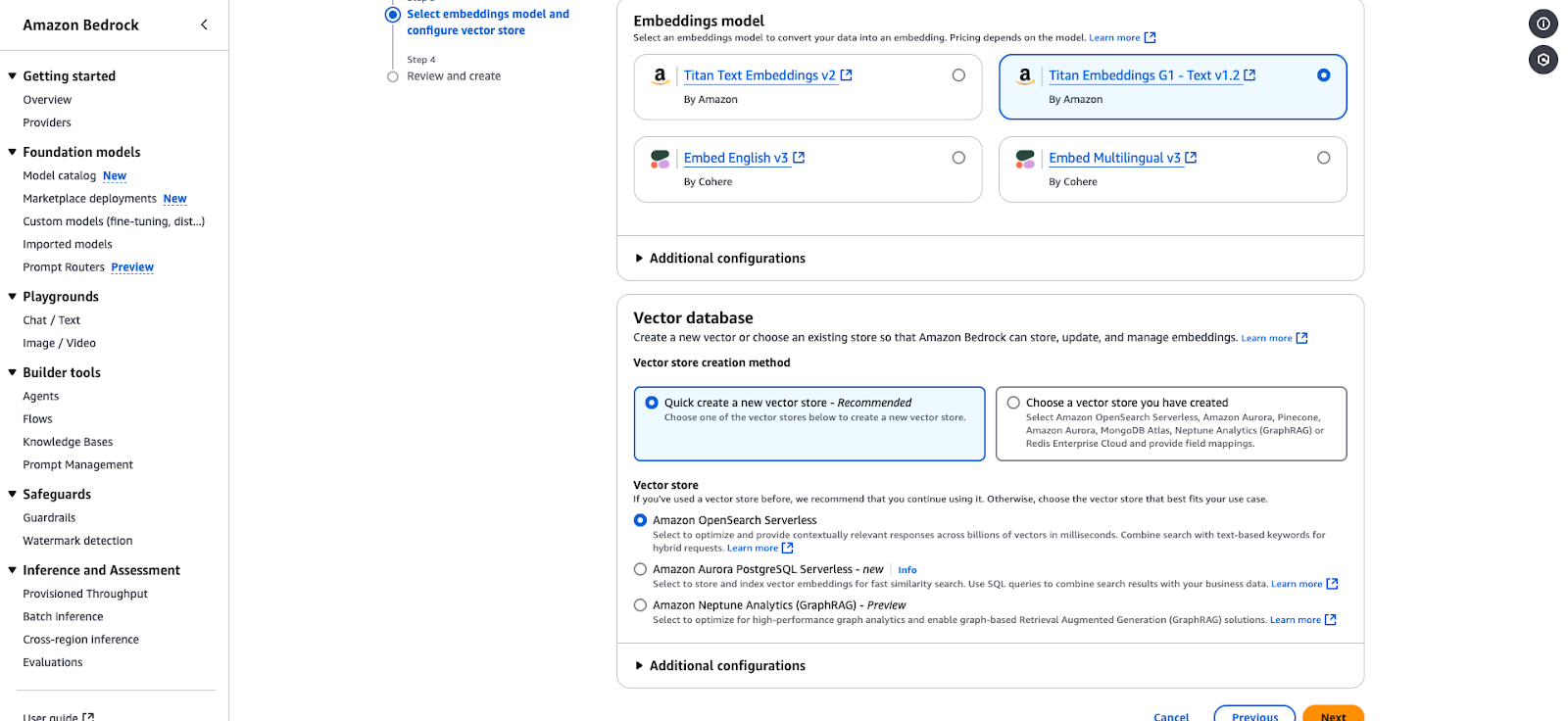
Page de configuration d'Amazon Bedrock pour la sélection d'un modèle d'intégration et d'un magasin de vecteurs.
knowledge-base-quick-start).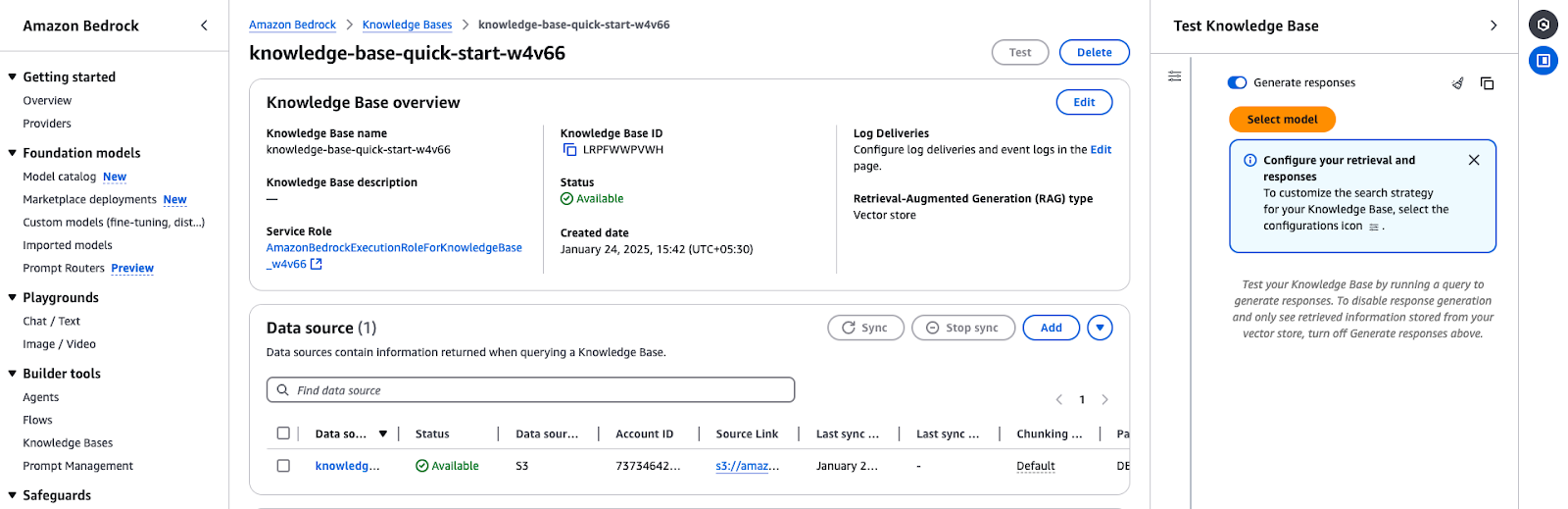
L'aperçu de la base de connaissances Amazon Bedrock montre les détails de la configuration et l'état de la source de données.
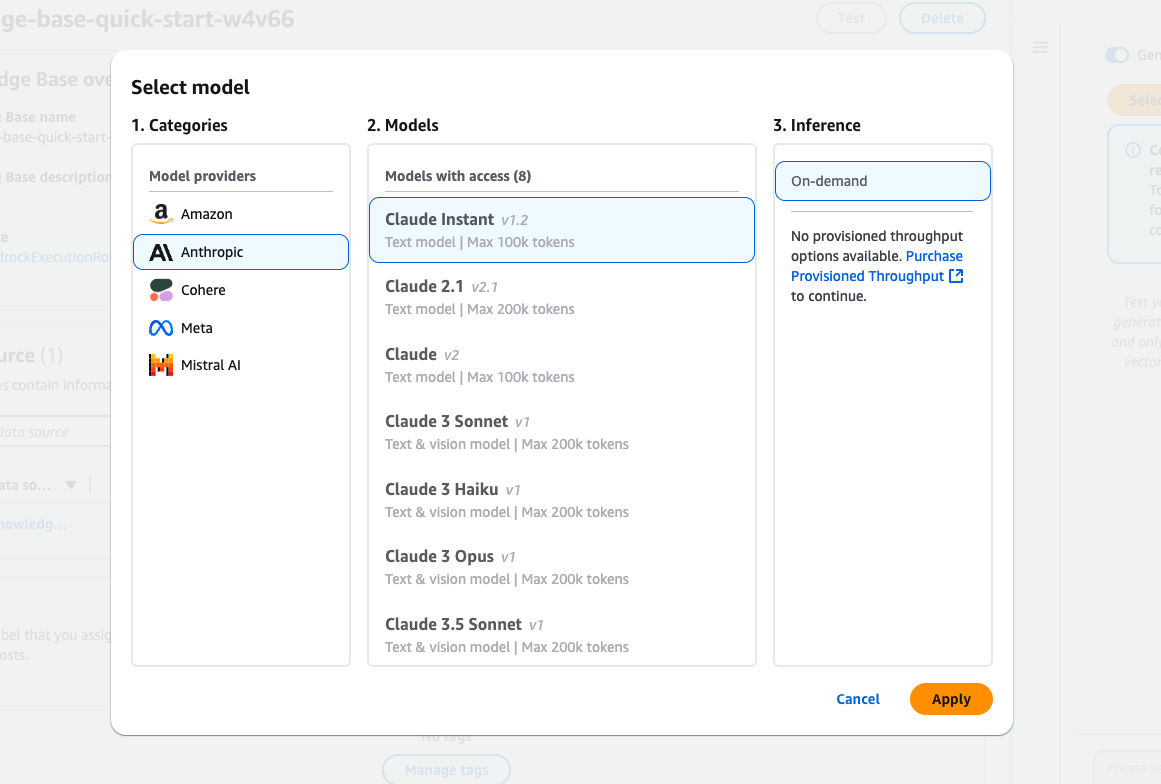
L'interface de sélection du modèle Amazon Bedrock propose différents modèles Claude d'Anthropic.
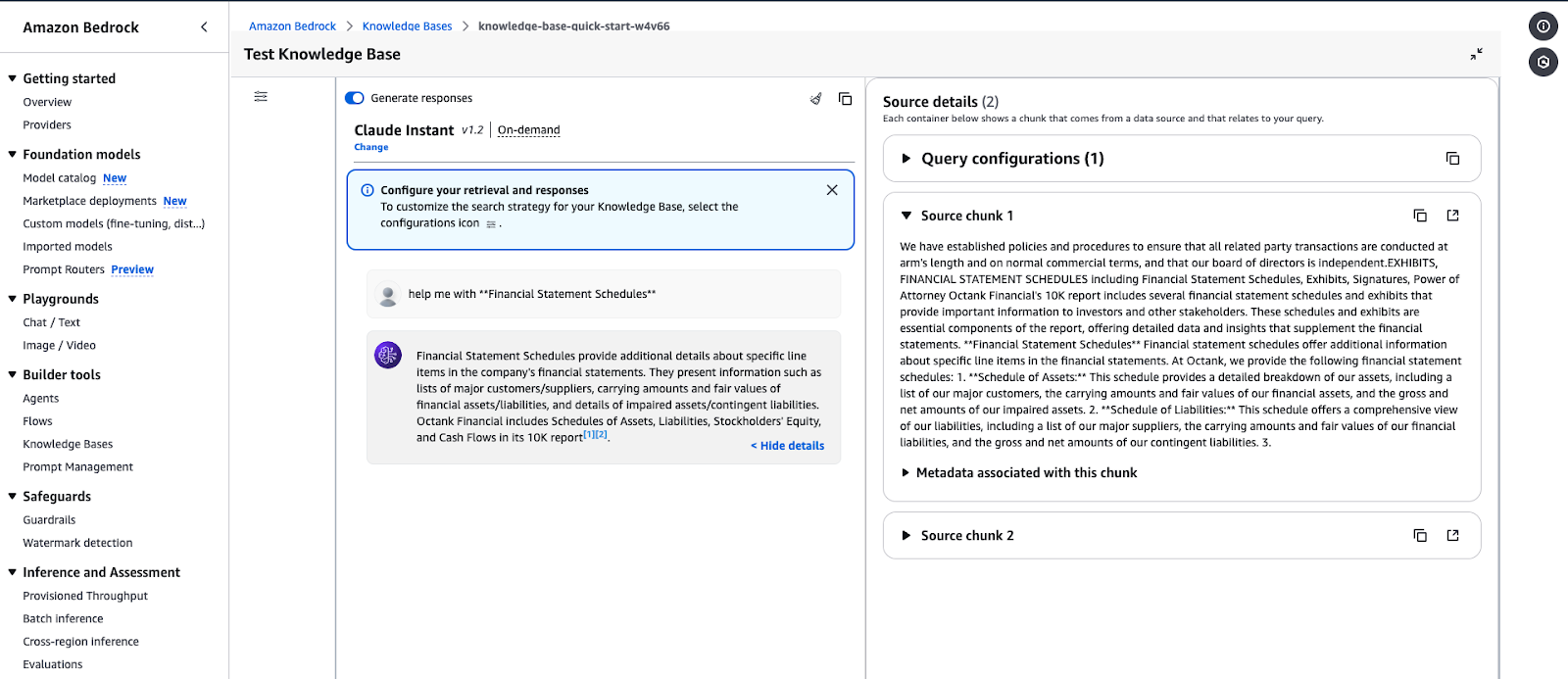
Interface de test de la base de connaissances Amazon Bedrock affichant une réponse à une requête.
Exemple de résultat de requête :
En utilisant des services AWS comme Lambda, Amazon Bedrock peut gérer et déployer des modèles d'IA à l'échelle. Cette approche rentable garantit une haute disponibilité et s'adapte automatiquement aux applications alimentées par l'IA.
Dans cette section, nous utiliserons AWS Lambda pour invoquer un modèle Bedrock de manière dynamique afin que vous puissiez traiter les invites à la demande.
Page de création d'une fonction AWS Lambda.
{
"prompt": "Write a formal apology letter for a late delivery."
}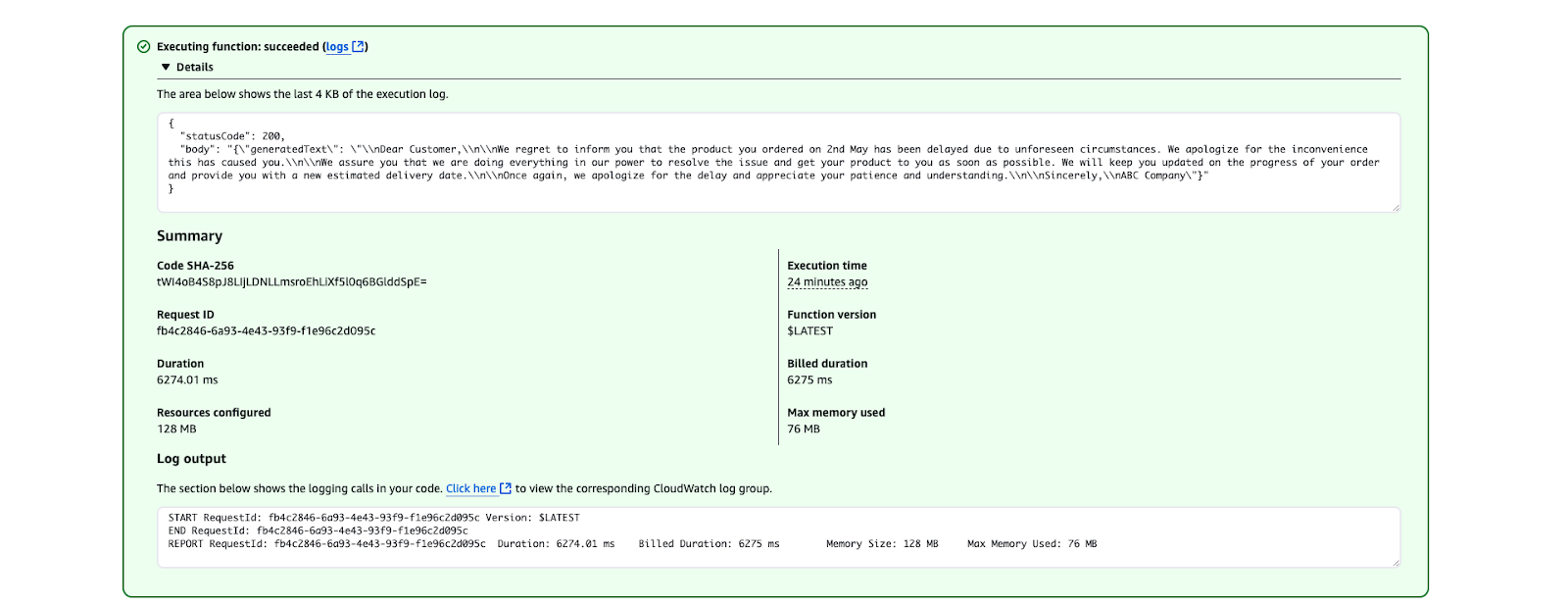
Résultat de l'exécution d'AWS Lambda montrant une exécution réussie de la fonction.
Optimisez les coûts:
Sécuriser la fonction Lambda:
Moniteur et journal:
Dans cette section, je partage quelques bonnes pratiques pour travailler avec Amazon Bedrock, de l'optimisation des coûts au maintien de la sécurité et de la précision.
La gestion des coûts dans AWS Bedrock peut impliquer l'utilisation d'Amazon SageMaker pour déployer des modèles et utiliser des instances Spot pour économiser jusqu'à 90 % des dépenses. Voici quelques-unes de mes meilleures pratiques :
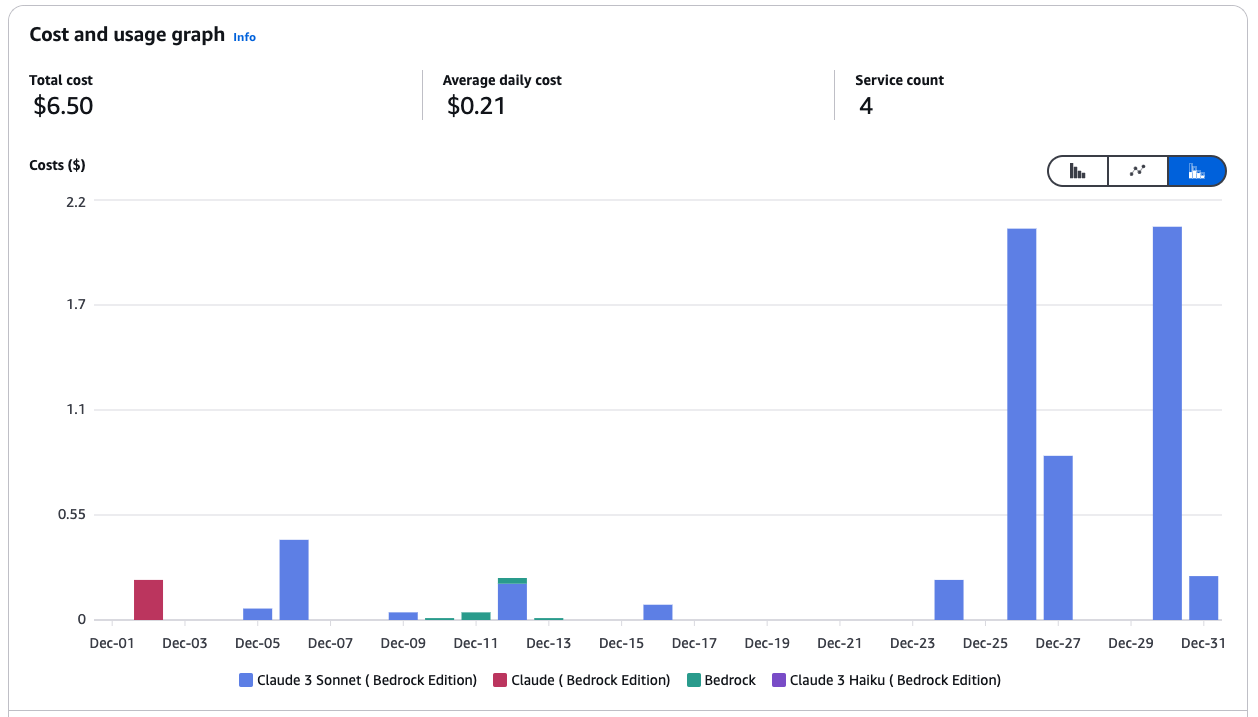
Graphique des coûts et de l'utilisation des services Amazon Bedrock.
from sagemaker.mxnet import MXNet
# Use spot instances for cost efficiency
use_spot_instances = True
# Maximum runtime for the training job (in seconds)
max_run = 600
# Maximum wait time for Spot instance availability (in seconds); set only if using Spot instances
max_wait = 1200 if use_spot_instances else None
# Define the MXNet estimator for the training job
mnist_estimator = MXNet(
entry_point='source_dir/mnist.py', # Path to the script that contains the model training code
role=role, # IAM role used for accessing AWS resources (e.g., S3, SageMaker)
output_path=model_artifacts_location, # S3 location to save the trained model artifacts
code_location=custom_code_upload_location, # S3 location to upload the training script
instance_count=1, # Number of instances to use for training
instance_type='ml.m4.xlarge', # Instance type for the training job
framework_version='1.6.0', # Version of the MXNet framework to use
py_version='py3', # Python version for the environment
distribution={'parameter_server': {'enabled': True}}, # Enable distributed training with a parameter server
hyperparameters={ # Training hyperparameters
'learning-rate': 0.1, # Learning rate for the training job
'epochs': 5 # Number of training epochs
},
use_spot_instances=use_spot_instances, # Enable Spot instances for cost savings
max_run=max_run, # Maximum runtime for the training job
max_wait=max_wait, # Maximum wait time for Spot instance availability
checkpoint_s3_uri=checkpoint_s3_uri # S3 URI for saving intermediate checkpoints
)
# Start the training job and specify the locations of training and testing datasets
mnist_estimator.fit({
'train': train_data_location, # S3 location of the training dataset
'test': test_data_location # S3 location of the testing/validation dataset
})
Journaux AWS CloudWatch
Pour garantir la sécurité, la conformité et la performance d'Amazon Bedrock, il est important de suivre les meilleures pratiques. Voici mes recommandations :
Le contrôle et l'évaluation des modèles permettent de s'assurer qu'ils sont précis, fiables et conformes aux objectifs de l'entreprise. Voici quelques bonnes pratiques :
Le tableau de bord des métriques affiche le nombre d'invocations, la latence et le nombre de jetons pour différents modèles dans Amazon Bedrock.
AWS Bedrock change la donne dans la manière dont les applications d'IA générative sont développées et constitue une plateforme centralisée permettant d'utiliser des modèles de base sans se soucier de l'infrastructure.
À partir de là, ce tutoriel étape par étape devrait vous aider à identifier les bons modèles, à créer des flux de travail sécurisés et évolutifs, et à intégrer des fonctionnalités telles que la génération augmentée par récupération (RAG) pour une plus grande personnalisation. Une fois les meilleures pratiques en matière de coûts, de sécurité et de surveillance mises en place, vous êtes prêt à développer et à gérer vos solutions d'IA pour atteindre vos objectifs.
Pour approfondir votre expertise AWS, découvrez ces cours :
Apprenez-en plus sur AWS grâce à ces cours !
Cursus
Cours
Cours
blog
Zoumana Keita
15 min
blog
Kurtis Pykes
9 min
blog
blog
Kurtis Pykes
15 min
blog
Lynn Heidmann
Tutoriel

