
Programa
Profissional de nuvem da AWS (CLF-C02)
10 h
A IA generativa se tornou um fator de desestabilização em todos os setores, impulsionando o progresso no processamento de linguagem natural, na visão computacional e em muitas outras áreas. No entanto, o uso de seu potencial tem sido frequentemente acompanhado por desafios de custos, infraestrutura complexa e curvas de aprendizado acentuadas. É aí que entra o AWS Bedrock - essa solução ajuda a desbloquear, permitindo que você use modelos de base sem a necessidade de gerenciar a infraestrutura.
Este tutorial tem como objetivo ser o seu guia completo para o Amazon Bedrock, descrevendo o que ele é, como funciona e como você pode usá-lo. Ao final deste guia, você terá as informações e as habilidades necessárias para desenvolver seus próprios aplicativos de IA generativa - escalonáveis, flexíveis e alinhados às suas metas.
O Amazon Bedrock é um serviço gerenciado da AWS para acessar e gerenciar modelos de fundação (FMs), os blocos de construção básicos da IA generativa da Amazon Web Services (AWS). O Bedrock torna as coisas tão simples que você não precisa se preocupar em provisionar GPUs, configurar pipelines de modelos ou gerenciar qualquer outra infraestrutura.
O AWS Bedrock é uma porta de entrada para a inovação. É uma plataforma unificada que permite aos desenvolvedores explorar, testar e implantar modelos de IA de ponta dos principais fornecedores, como Anthropic, Stability AI e Titan da Amazon.
Por exemplo, imagine que você está desenvolvendo um chatbot de suporte ao cliente. Com o AWS Bedrock, você pode selecionar um modelo de linguagem sofisticado, ajustá-lo às necessidades do seu aplicativo e incorporá-lo ao seu aplicativo sem precisar escrever a configuração do servidor no código.
Os recursos do AWS Bedrock foram projetados para simplificar e acelerar a jornada do conceito de IA à produção. Vamos analisá-los em detalhes.
Um dos benefícios mais significativos do AWS Bedrock é a variedade de modelos de fundação disponíveis. Não importa se você está trabalhando em aplicativos de texto, conteúdo visual ou IA segura e interpretável, a Bedrock tem o que você precisa. Aqui estão alguns dos modelos disponíveis:
Visão geral do Amazon Bedrock, destacando sua integração com modelos.
O AWS Bedrock abstrai o gerenciamento da infraestrutura, o que significa que você pode usar o AWS Bedrock para fazer o gerenciamento da infraestrutura:
Os aplicativos geradores de IA normalmente têm uma demanda imprevisível. Um chatbot pode responder a centenas de usuários nos horários de pico e a apenas alguns à noite. Mas o AWS Bedrock resolve isso com sua escalabilidade integrada:
O AWS Bedrock vai além de fornecer modelos avançados - ele se integra a outros serviços da AWS para oferecer suporte a fluxos de trabalho de IA de ponta a ponta. Algumas integrações incluem:
Esta seção orientará você na configuração das permissões necessárias, na criação de uma conta da AWS e na introdução ao AWS Bedrock.
Se você ainda não tiver uma, vá para a página de inscrição da AWS e crie uma conta. Para usuários existentes, verifique se o usuário do IAM tem privilégios de administrador.

A página de registro do AWS, que mostra a exploração do produto Free Tier para novas contas.
Se você estiver procurando por etapas detalhadas, visite o guia oficial da AWS.
Você pode acessar o Amazon Bedrock por meio do console de gerenciamento do AWS. Siga estas etapas para localizar e começar a usá-la:
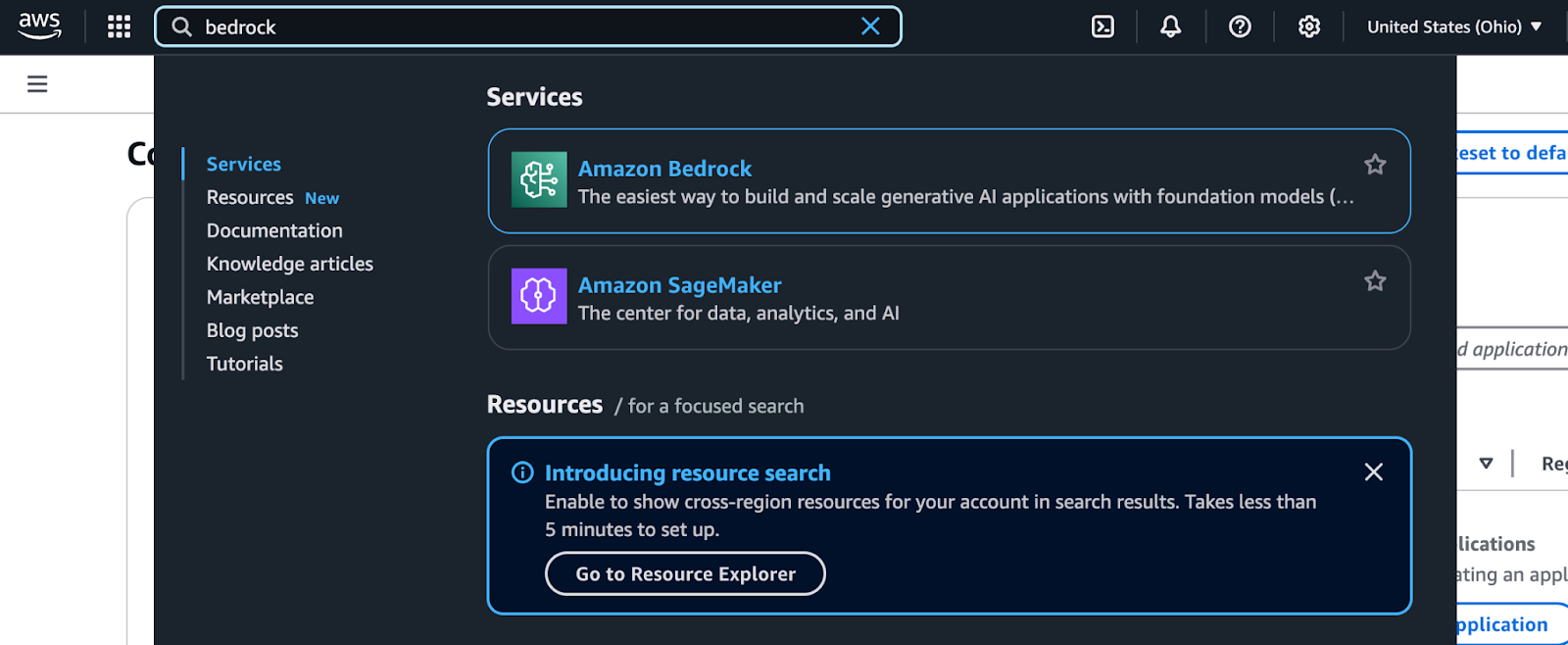
Resultados da pesquisa do AWS Management Console para Bedrock.

Página do Amazon Bedrock Providers apresentando opções de modelos sem servidor da Amazon.
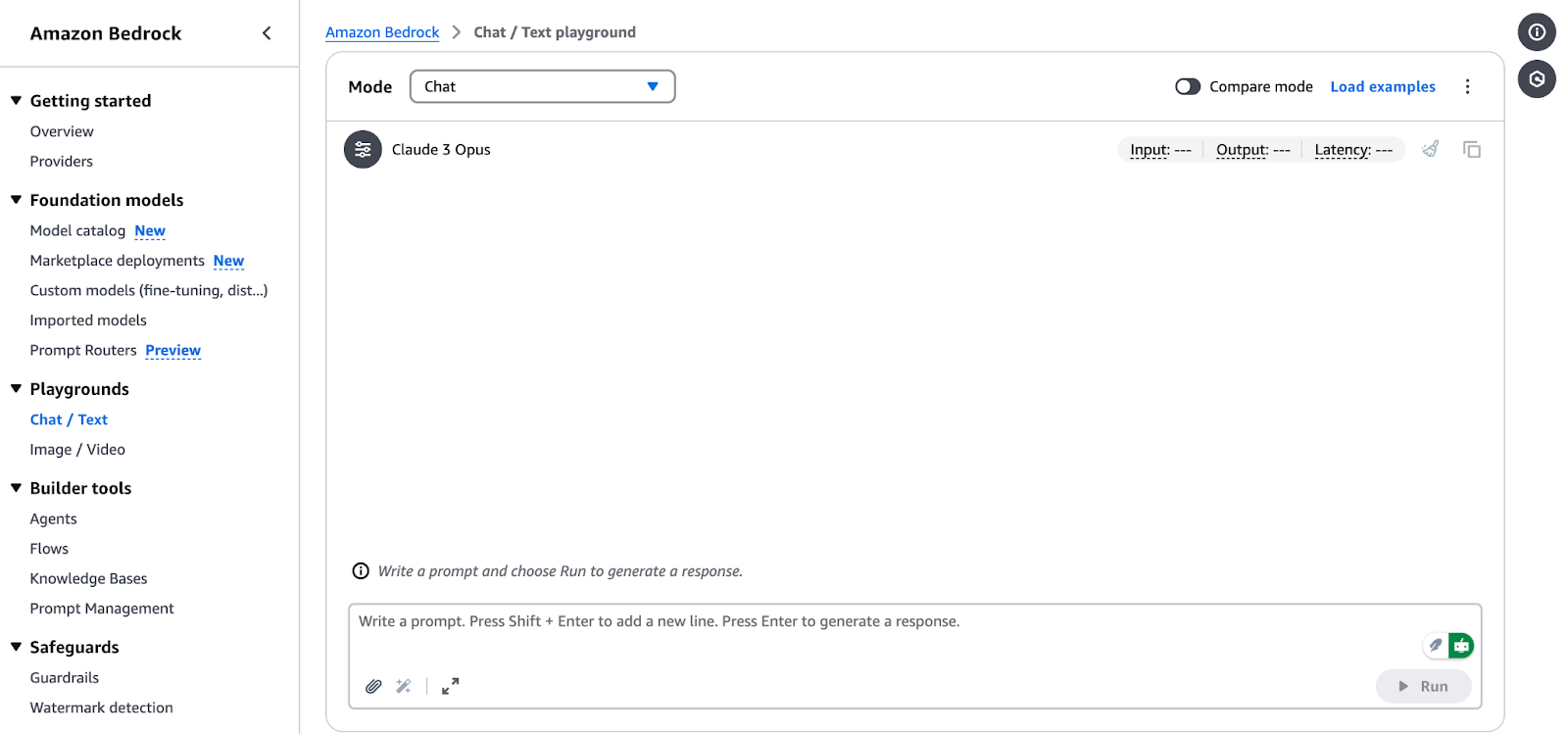
Interface do Amazon Bedrock Chat/Text Playground.
O AWS Identity and Access Management (IAM) é essencial para que você acesse o AWS Bedrock com segurança. Siga estas etapas para configurar as permissões:
Editor de políticas do AWS IAM no modo JSON
{
"Version": "2012-10-17",
"Statement": [ {
"Sid": "BedrockFullAccess",
"Effect": "Allow",
"Action": ["bedrock:*"],
"Resource": "*"
}
]
}Observação: A política acima pode ser anexada a qualquer função que precise acessar o serviço Amazon Bedrock. Pode ser o SageMaker ou um usuário. Ao usar o Amazon SageMaker, a função de execução do notebook normalmente é um usuário ou função diferente daquele que você usa para fazer login no AWS Management Console. Para saber como explorar o serviço Amazon Bedrock usando o Console da AWS, certifique-se de que você autorizou seu usuário ou função no Console. Você pode executar os notebooks em qualquer ambiente com acesso ao serviço AWS Bedrock e credenciais válidas.
Os aplicativos de IA generativa são desenvolvidos com base em modelos básicos que são ajustados para uma tarefa específica, como geração de texto, criação de imagens ou transformação de dados. A seguir, você encontrará um guia passo a passo sobre como escolher um modelo básico, usar trabalhos de inferência básicos e modificar as respostas do modelo para atender às suas necessidades.
A escolha do modelo de fundação correto é importante porque depende das necessidades do seu projeto. Veja como você pode fazer uma seleção:
1. Identifique seu caso de uso:
2. Avalie os recursos do modelo:
Antes de usar esses modelos, você precisa habilitar o acesso ao modelo na sua conta do AWS. Aqui estão as etapas para você configurá-lo:
Página de gerenciamento de acesso ao modelo Amazon Bedrock.
Para realizar a inferência usando um modelo de fundação selecionado no AWS Bedrock, siga estas etapas:
pip install boto3import boto3
import json
from botocore.exceptions import ClientError
# Set the AWS Region
region = "us-east-1"
# Initialize the Bedrock Runtime client
client = boto3.client("bedrock-runtime", region_name=region)# Define the model ID for Amazon Titan Express v1
model_id = "amazon.titan-text-express-v1"
# Define the input prompt
prompt = """
Command: Compose an email from Tom, Customer Service Manager, to the customer "Nancy"
who provided negative feedback on the service provided by our customer support
Engineer"""# Configure inference parameters
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512, # Limit the response length
"temperature": 0.5, # Control the randomness of the output
},
}
# Convert the request payload to JSON
request_payload = json.dumps(inference_parameters)try:
# Invoke the model
response = client.invoke_model(
modelId=model_id,
body=request_payload,
contentType="application/json",
accept="application/json"
)
# Decode the response body
response_body = json.loads(response["body"].read())
# Extract and print the generated text
generated_text = response_body["results"][0]["outputText"]
print("Generated Text:\n", generated_text)
except ClientError as e:
print(f"ClientError: {e.response['Error']['Message']}")
except Exception as e:
print(f"An error occurred: {e}")Observação: Você pode acessar e copiar o código completo diretamente do Gist do GitHub.
Você pode esperar o resultado abaixo:
% python3 main.py
Generated Text:
Tom:
Nancy,
I am writing to express my sincere apologies for the negative experience you had with our customer support engineer. It is unacceptable that we did not meet your expectations, and I want to assure you that we are taking steps to prevent this from happening in the future.
Sincerely,
Tom
Customer Service ManagerPara ajustar o comportamento da saída do modelo, você pode ajustar parâmetros como temperature e maxTokenCount:
temperature: Esse parâmetro controla a aleatoriedade da saída. Valores mais baixos aumentam a determinação do resultado, e valores mais altos aumentam a variabilidade.MaxTokenCount: Define o comprimento máximo da saída gerada.Por exemplo:
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 256, # Limit the response length
"temperature": 0.7, # Control the randomness of the output
},
}Ao ajustar esses parâmetros, você pode adaptar melhor a criatividade e a duração do conteúdo gerado às necessidades do seu aplicativo.
Vamos mudar de marcha e nos concentrar em duas abordagens avançadas: aprimorar a IA usando Retrieval-Augmented Generation (RAG) e gerenciar e implantar modelos em escala.
O RAG exige que você tenha uma base de conhecimento. Antes de configurar a base de conhecimento no Amazon Bedrock, você precisa criar um bucket S3 e carregar os arquivos necessários. Siga estas etapas:
Etapa 2: Fazer upload de arquivos para o bucket S3
octank_financial_10K.pdf.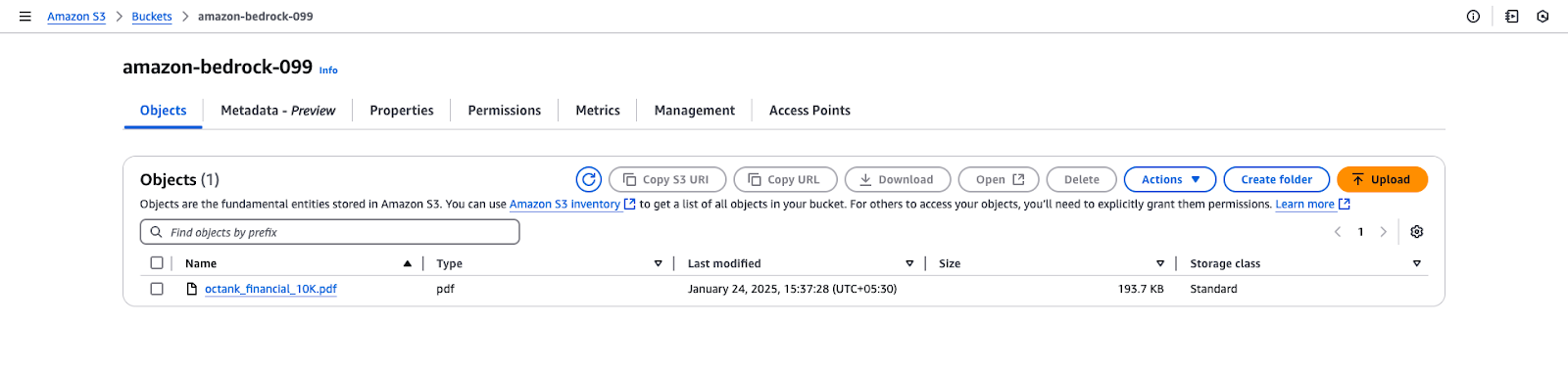
Visualização do bucket do Amazon S3 para "amazon-bedrock-099".
O Amazon Bedrock permite que você crie uma base de conhecimento alimentada por bancos de dados vetoriais. As etapas a seguir orientarão você na criação de uma base de conhecimento, na configuração de uma fonte de dados e na seleção de embeddings e armazenamentos de vetores.
knowledge-base-quick-start).AmazonBedrockExecutionRoleForKnowledgeBase.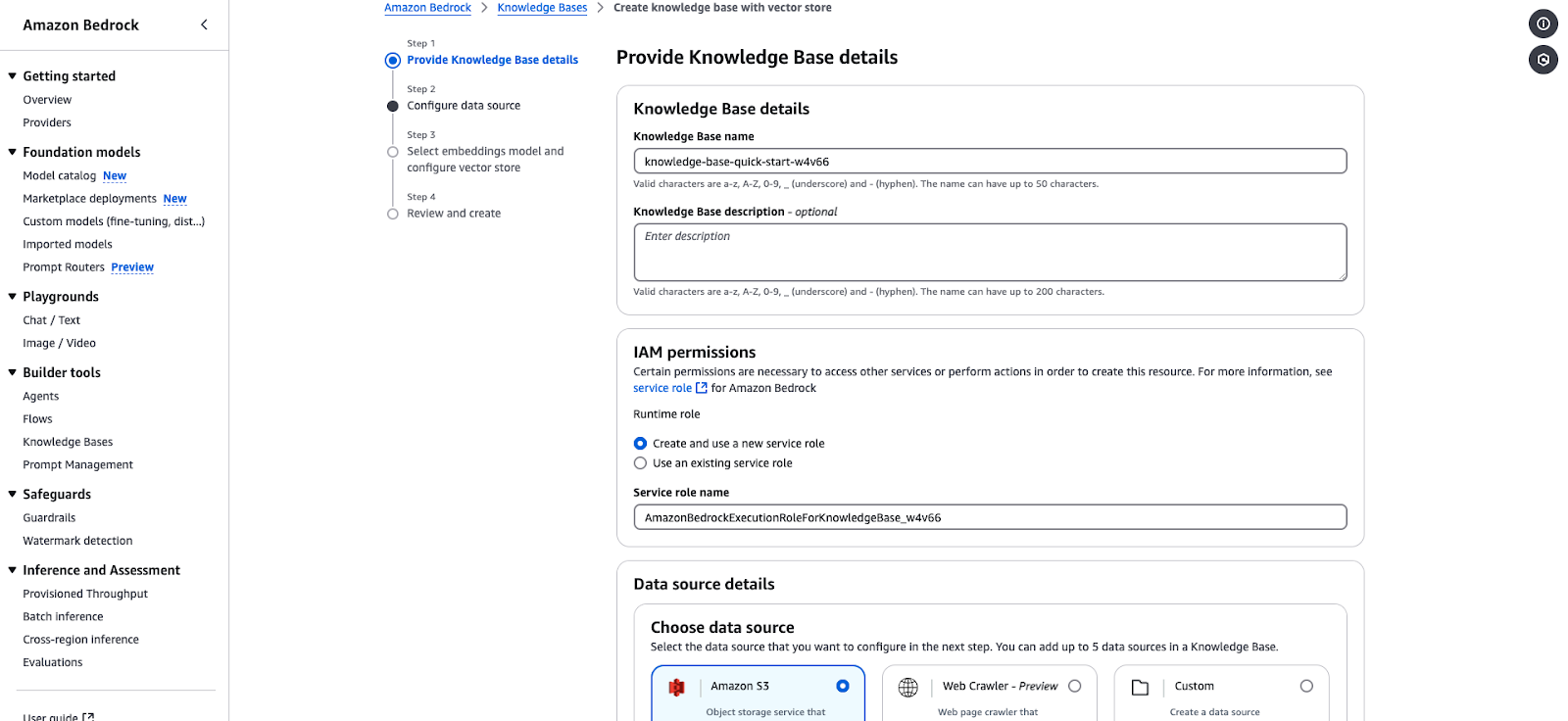
Assistente de criação da Base de Conhecimento do Amazon Bedrock.
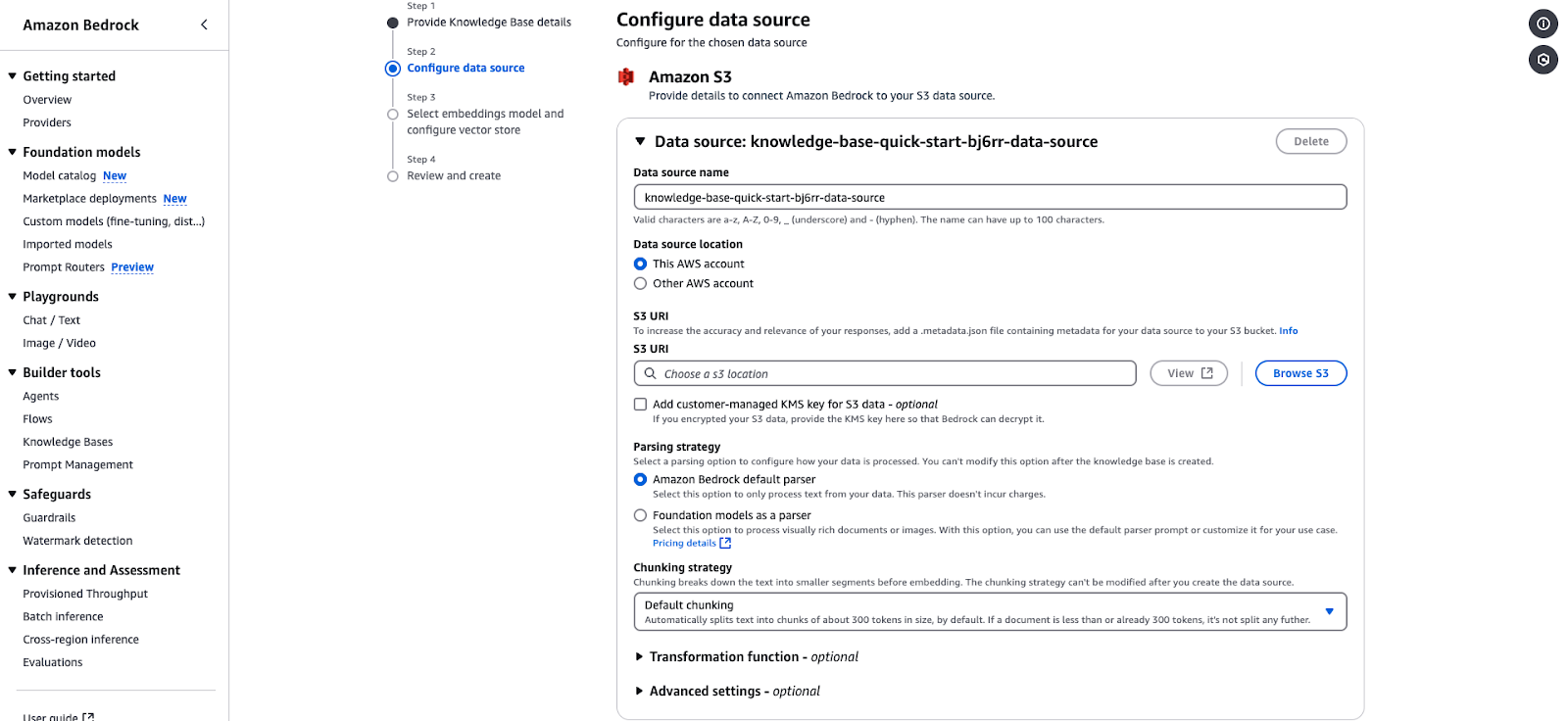
Página de configuração da fonte de dados Amazon Bedrock para integração de uma base de conhecimento baseada em S3.
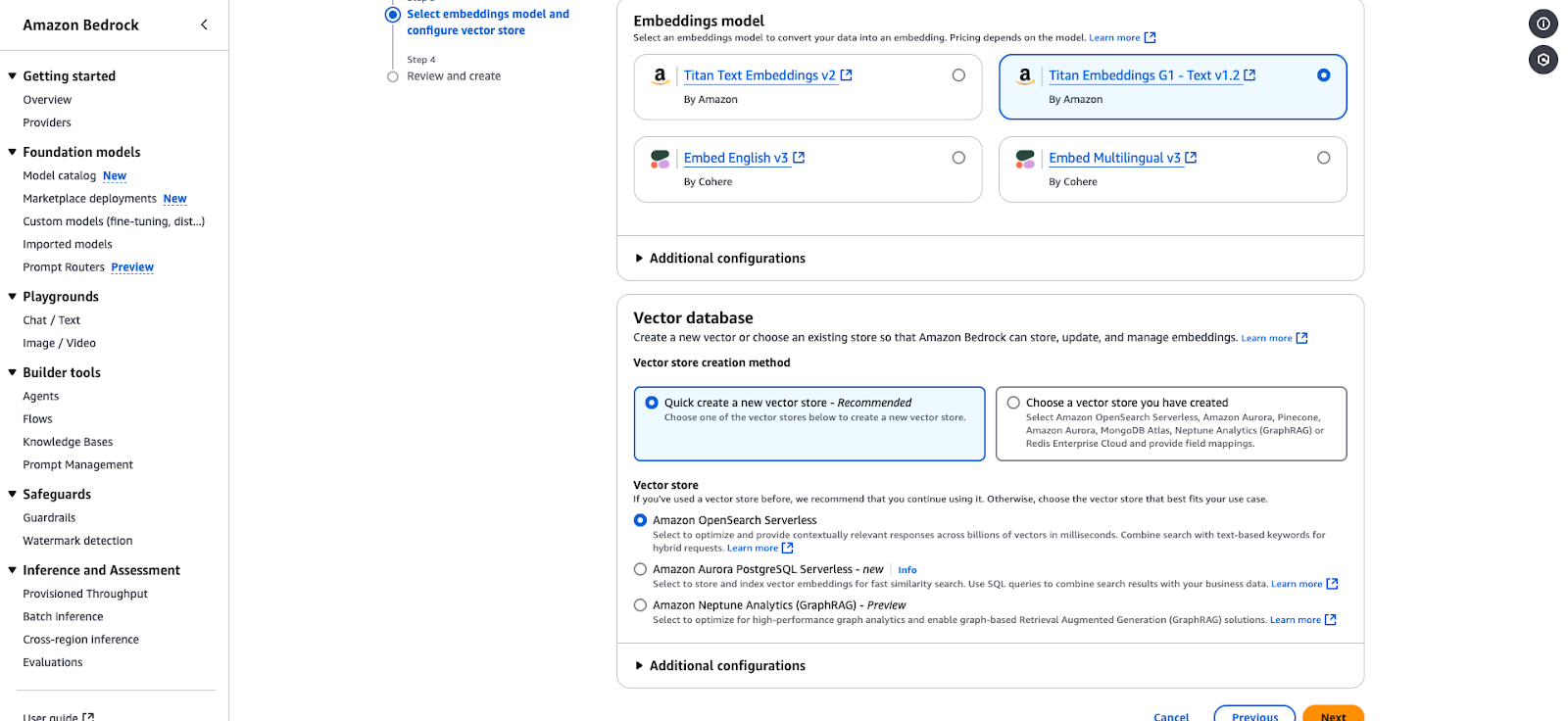
Página de configuração do Amazon Bedrock para selecionar um modelo de incorporação e um armazenamento de vetores.
knowledge-base-quick-start).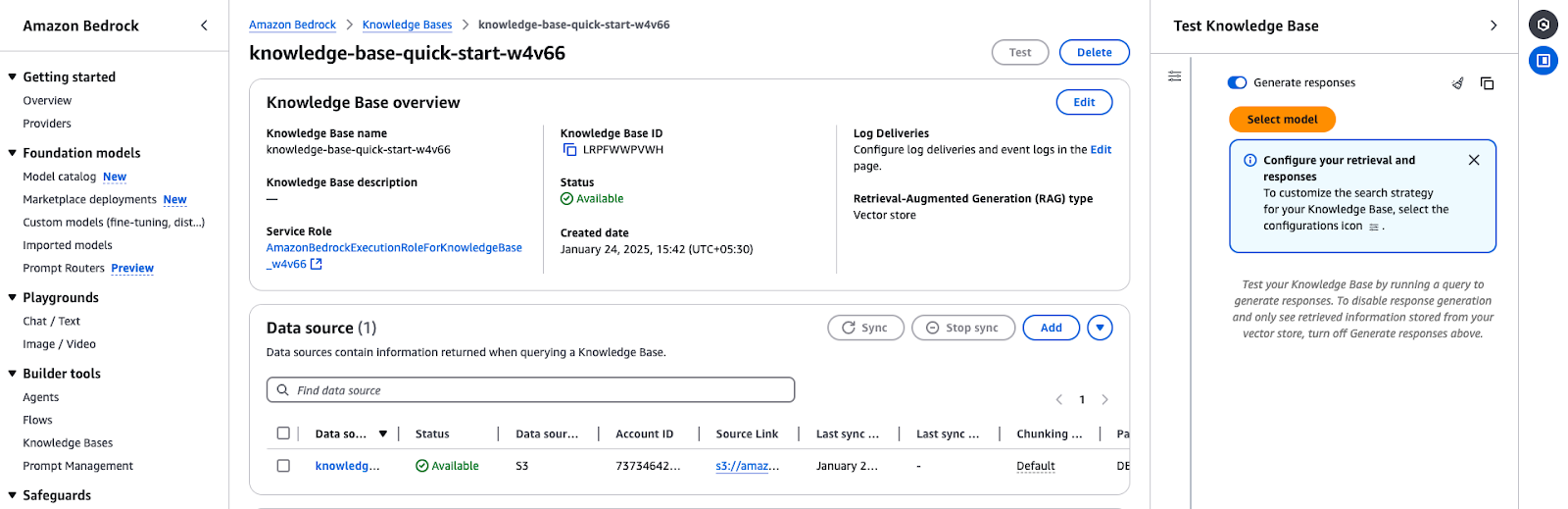
A visão geral da Base de Conhecimento do Amazon Bedrock mostra detalhes de configuração e status da fonte de dados.
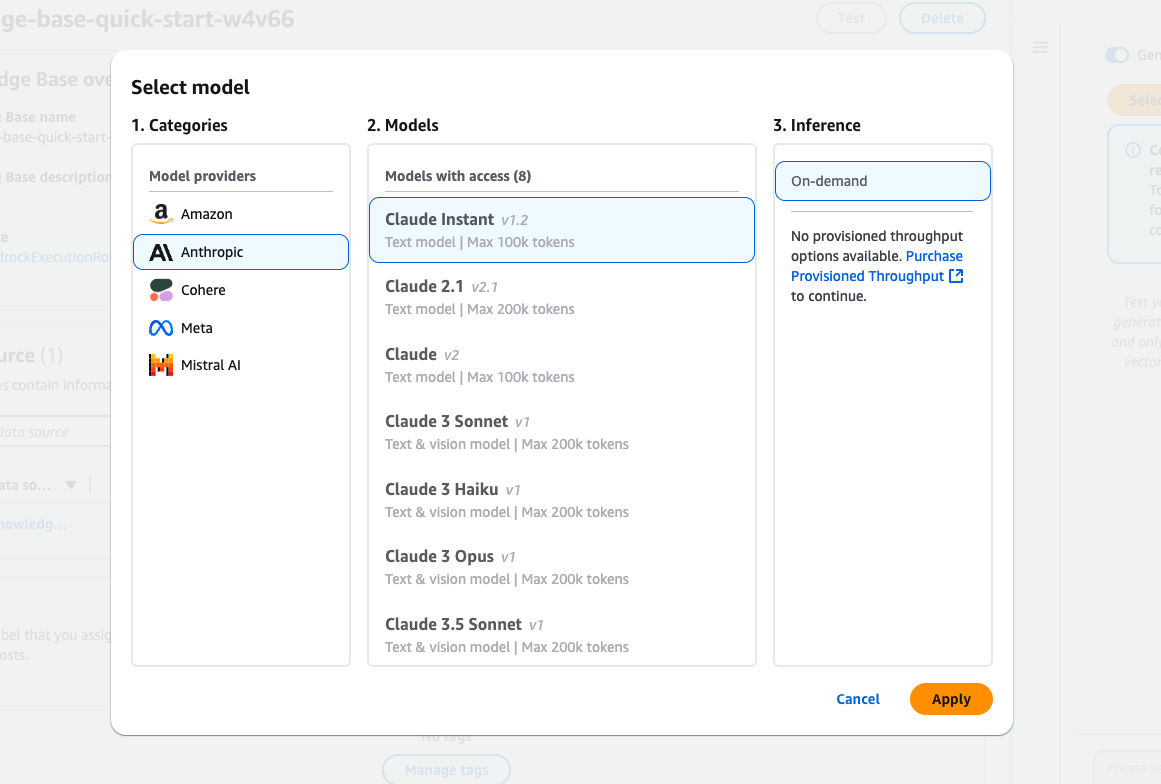
A interface de seleção de modelos do Amazon Bedrock apresenta vários modelos Claude da Anthropic.
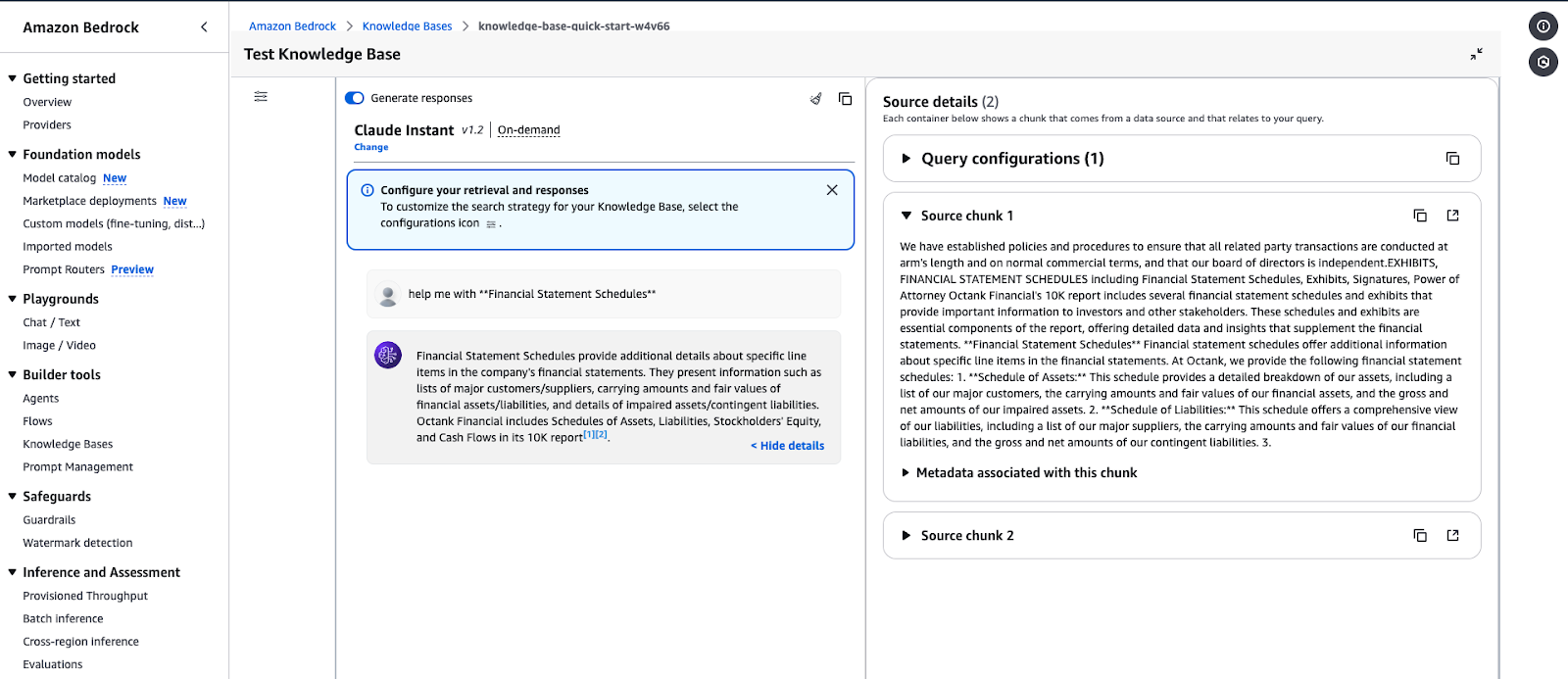
Interface de teste da Base de Conhecimento do Amazon Bedrock exibindo uma resposta para uma consulta.
Exemplo de saída de consulta:
Usando os serviços da AWS, como o Lambda, o Amazon Bedrock pode gerenciar e implementar modelos de IA em escala. Essa abordagem econômica garante alta disponibilidade e é dimensionada automaticamente para aplicativos alimentados por IA.
Nesta seção, usaremos o AWS Lambda para invocar um modelo do Bedrock dinamicamente para que você possa processar prompts sob demanda.
Página de criação da função AWS Lambda.
{
"prompt": "Write a formal apology letter for a late delivery."
}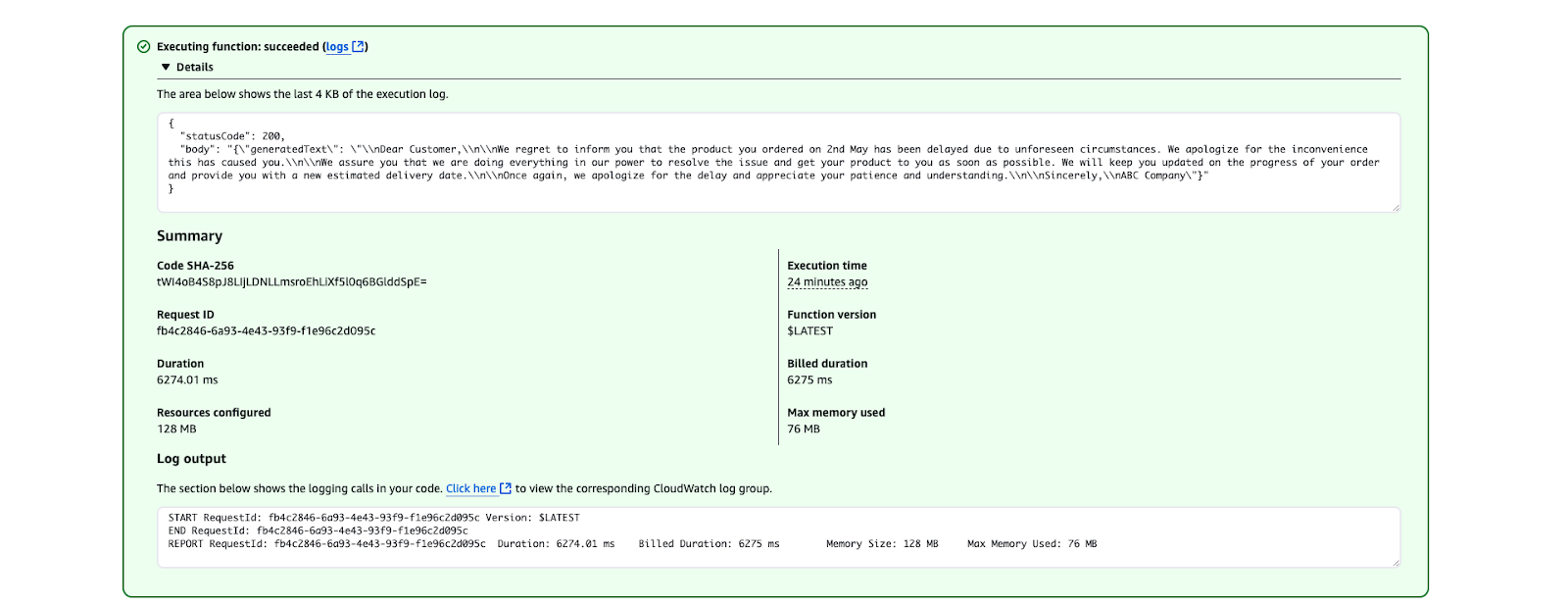
Resultado da execução do AWS Lambda mostrando uma execução bem-sucedida da função.
Otimizar o custo:
Proteja a função Lambda:
Monitoramento e registro:
Nesta seção, compartilho algumas práticas recomendadas ao trabalhar com o Amazon Bedrock, desde a otimização de custos até a manutenção da segurança e da precisão.
O gerenciamento de custos no AWS Bedrock pode envolver o uso do Amazon SageMaker para implementar modelos e utilizar instâncias Spot para economizar até 90% das despesas. Aqui estão algumas de minhas práticas recomendadas:
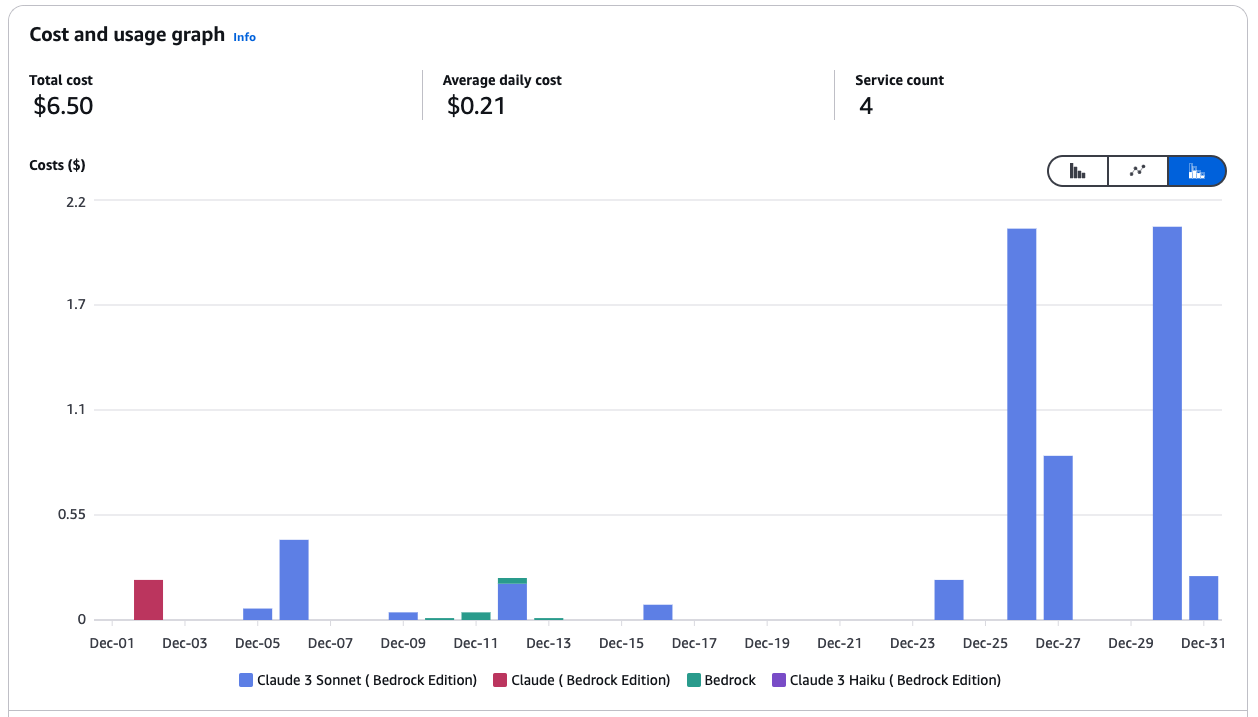
Gráfico de custo e uso dos serviços do Amazon Bedrock.
from sagemaker.mxnet import MXNet
# Use spot instances for cost efficiency
use_spot_instances = True
# Maximum runtime for the training job (in seconds)
max_run = 600
# Maximum wait time for Spot instance availability (in seconds); set only if using Spot instances
max_wait = 1200 if use_spot_instances else None
# Define the MXNet estimator for the training job
mnist_estimator = MXNet(
entry_point='source_dir/mnist.py', # Path to the script that contains the model training code
role=role, # IAM role used for accessing AWS resources (e.g., S3, SageMaker)
output_path=model_artifacts_location, # S3 location to save the trained model artifacts
code_location=custom_code_upload_location, # S3 location to upload the training script
instance_count=1, # Number of instances to use for training
instance_type='ml.m4.xlarge', # Instance type for the training job
framework_version='1.6.0', # Version of the MXNet framework to use
py_version='py3', # Python version for the environment
distribution={'parameter_server': {'enabled': True}}, # Enable distributed training with a parameter server
hyperparameters={ # Training hyperparameters
'learning-rate': 0.1, # Learning rate for the training job
'epochs': 5 # Number of training epochs
},
use_spot_instances=use_spot_instances, # Enable Spot instances for cost savings
max_run=max_run, # Maximum runtime for the training job
max_wait=max_wait, # Maximum wait time for Spot instance availability
checkpoint_s3_uri=checkpoint_s3_uri # S3 URI for saving intermediate checkpoints
)
# Start the training job and specify the locations of training and testing datasets
mnist_estimator.fit({
'train': train_data_location, # S3 location of the training dataset
'test': test_data_location # S3 location of the testing/validation dataset
})
Registros do AWS CloudWatch
Para garantir a segurança, a conformidade e o desempenho do Amazon Bedrock, é importante que você siga as práticas recomendadas. Aqui estão minhas recomendações:
A garantia de que os modelos sejam precisos, confiáveis e alinhados aos objetivos comerciais é obtida por meio do monitoramento e da avaliação dos modelos. Aqui estão algumas práticas recomendadas:
O painel de métricas exibe a contagem de invocações, a latência e a contagem de tokens para vários modelos no Amazon Bedrock.
O AWS Bedrock é um divisor de águas na forma como os aplicativos de IA generativa são desenvolvidos e uma plataforma centralizada para usar modelos básicos sem se preocupar com a infraestrutura.
Deste ponto em diante, este tutorial passo a passo deve ajudar você a identificar os modelos certos, criar fluxos de trabalho seguros e dimensionáveis e integrar recursos como a geração aumentada por recuperação (RAG) para maior personalização. Com as práticas recomendadas de custo, segurança e monitoramento em vigor, você está pronto para desenvolver e gerenciar suas soluções de IA para atender aos seus objetivos.
Para aprofundar ainda mais sua experiência em AWS, explore estes cursos:
Saiba mais sobre a AWS com estes cursos!
Programa
Curso
Curso
blog
Adel Nehme
15 min
blog
Dr Ana Rojo-Echeburúa
9 min
Tutorial
Bex Tuychiev
Tutorial
Tim Lu
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes


