
programa
Profesional de AWS Cloud (CLF-C02)
10 h
La IA generativa se ha convertido en el elemento perturbador en todos los sectores, impulsando el progreso en el procesamiento del lenguaje natural, la visión por ordenador y muchas otras áreas. Sin embargo, el aprovechamiento de su potencial ha ido a menudo acompañado de retos de costes, infraestructuras complejas y pronunciadas curvas de aprendizaje. Ahí es donde entra AWS Bedrock: esta solución ayuda a desbloquear permitiendo utilizar modelos de cimientos sin necesidad de administrar la infraestructura.
Este tutorial pretende ser tu guía completa de Amazon Bedrock, describiendo qué es, cómo funciona y cómo puedes utilizarlo. Al final de esta guía, tendrás la información y las habilidades que necesitas para desarrollar tus propias aplicaciones de IA generativa: escalables, flexibles y alineadas con tus objetivos.
Amazon Bedrock es un servicio gestionado de AWS para acceder y administrar modelos de base (FM), los componentes básicos de la IA generativa de Amazon Web Services (AWS). Bedrock simplifica tanto las cosas que no tienes que preocuparte de aprovisionar GPUs, configurar pipelines de modelos ni gestionar ninguna otra infraestructura.
AWS Bedrock es una puerta a la innovación. Es una plataforma unificada que permite a los desarrolladores explorar, probar y desplegar modelos de IA de vanguardia de proveedores líderes como Anthropic, Stability AI y Titan de Amazon.
Por ejemplo, imagina que estás desarrollando un chatbot de atención al cliente. Con AWS Bedrock, puedes seleccionar un modelo de lenguaje sofisticado, ajustarlo a las necesidades de tu aplicación e incrustarlo en ella sin tener que escribir nunca la configuración del servidor en código.
Las características de AWS Bedrock están diseñadas para simplificar y acelerar el viaje desde el concepto de IA hasta la producción. Vamos a desglosarlos en detalle.
Una de las ventajas más significativas de AWS Bedrock es la variedad de modelos de cimentación disponibles. Tanto si trabajas en aplicaciones de texto, contenido visual o IA segura e interpretable, Bedrock te tiene cubierto. Aquí tienes algunos de los modelos disponibles:
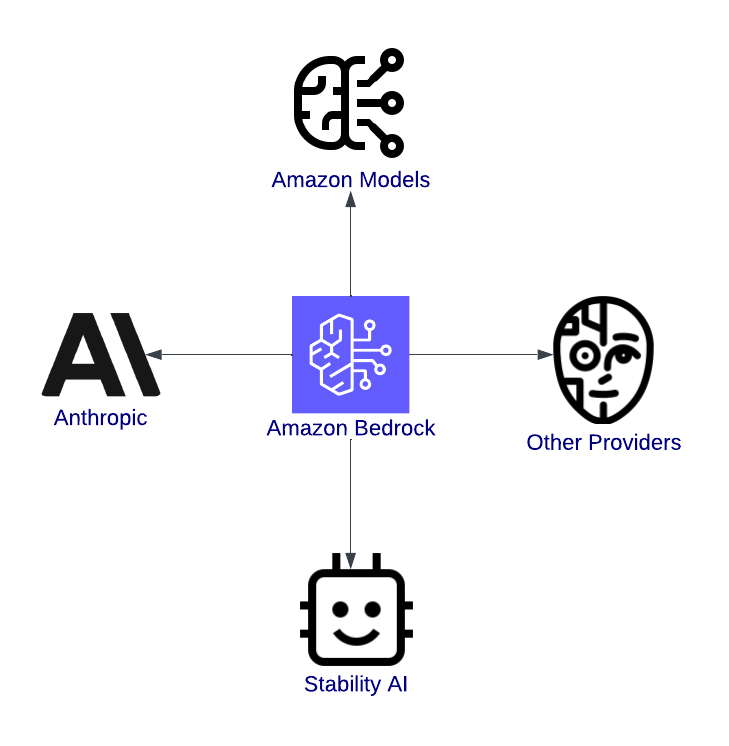
Visión general de Amazon Bedrock, destacando su integración con los modelos.
AWS Bedrock abstrae la gestión de la infraestructura, lo que significa:
Las aplicaciones generativas de IA suelen tener una demanda impredecible. Un chatbot puede responder a cientos de usuarios en horas punta y sólo a unos pocos por la noche. Pero AWS Bedrock lo resuelve con su escalabilidad integrada:
AWS Bedrock va más allá de proporcionar potentes modelos: se integra con otros servicios de AWS para respaldar flujos de trabajo de IA de extremo a extremo. Algunas integraciones son:
Esta sección te guiará a través de la configuración de los permisos necesarios, la creación de una cuenta de AWS y la puesta en marcha de AWS Bedrock.
Si aún no tienes una, dirígete a la página de registro de AWS y crea una cuenta. Para los usuarios existentes, asegúrate de que tu usuario IAM tiene privilegios de administrador.

La página de registro de AWS, que muestra la exploración de productos de la capa gratuita para cuentas nuevas.
Si buscas pasos detallados, visita la guía oficial de AWS.
Se puede acceder a Amazon Bedrock a través de la consola de administración de AWS. Sigue estos pasos para localizarlo y empezar a utilizarlo:
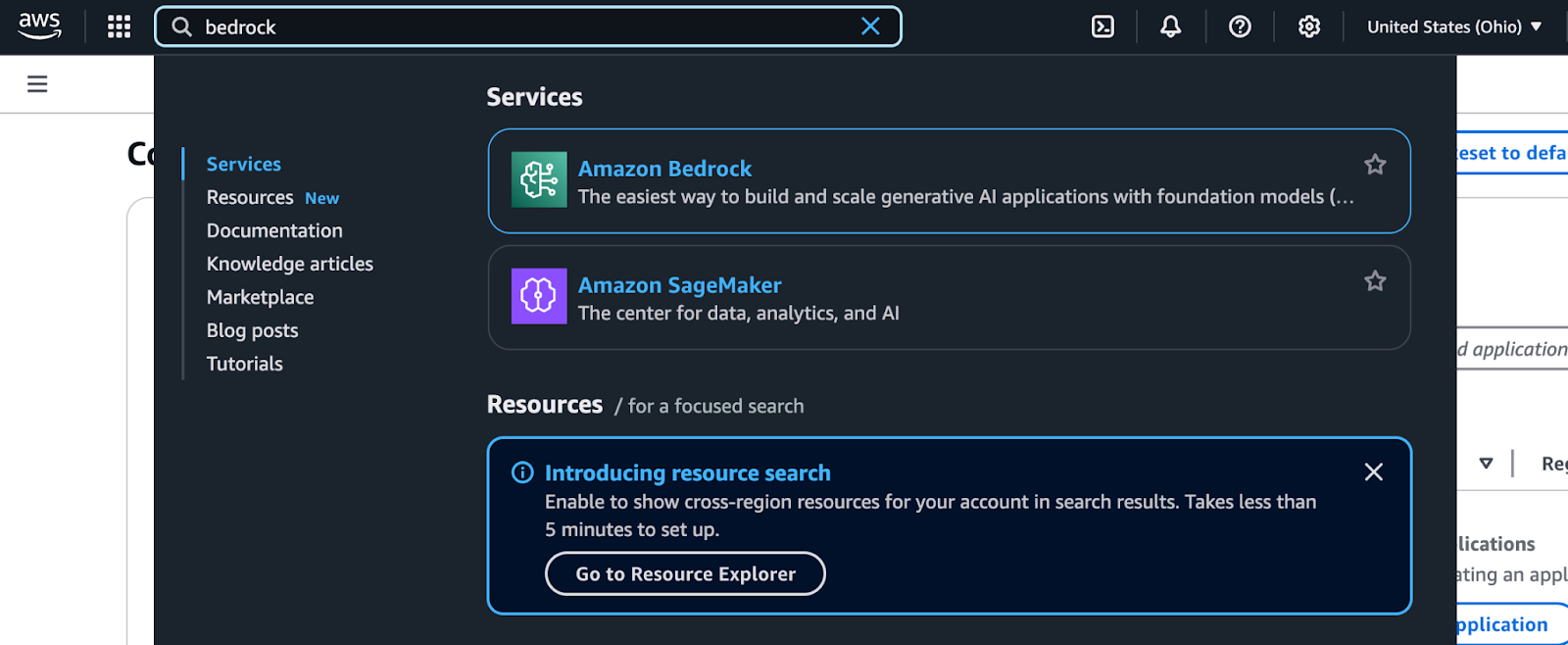
Resultados de la búsqueda de Bedrock en la consola de administración de AWS.

Página de proveedores de Amazon Bedrock que muestra las opciones de modelos sin servidor de Amazon.
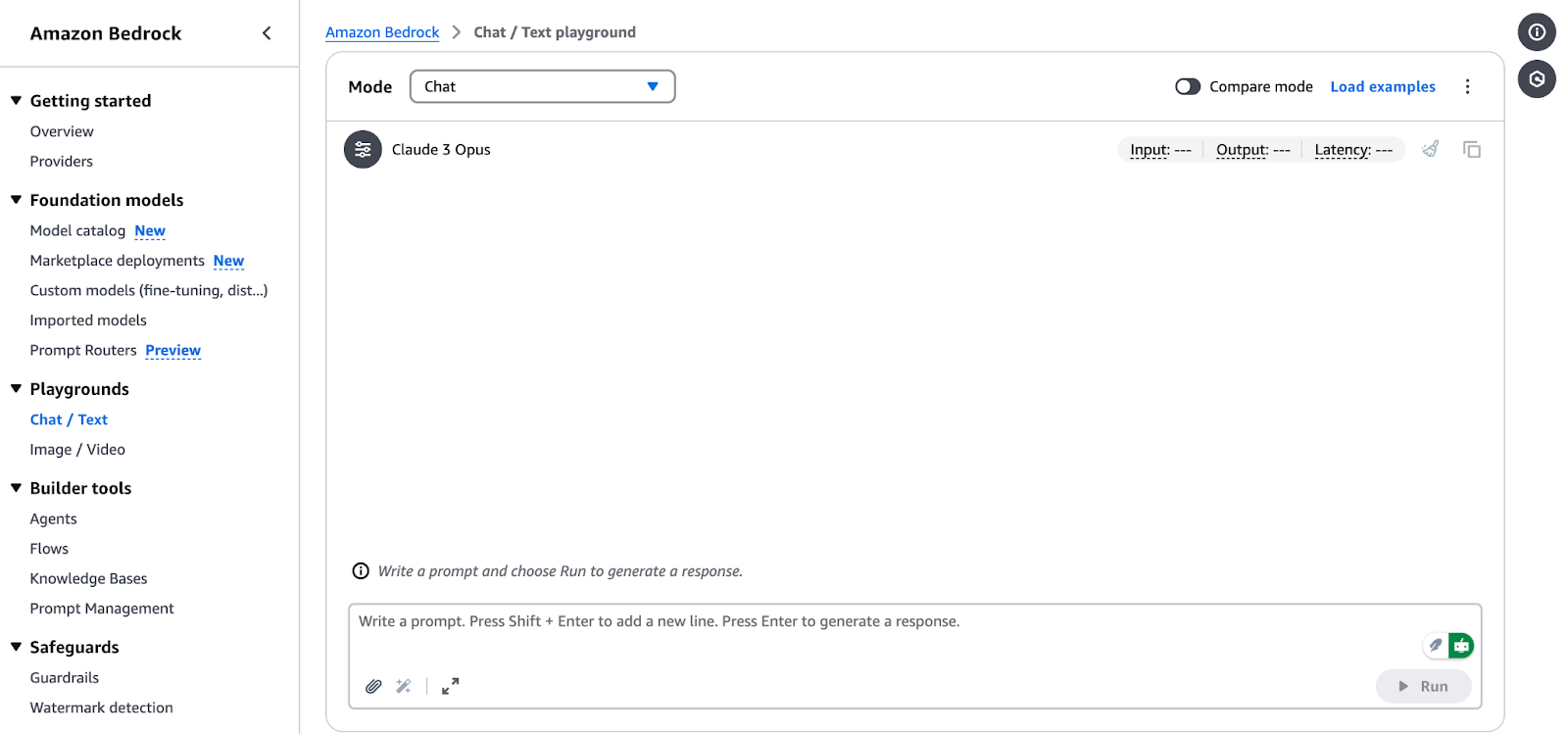
Interfaz de Amazon Bedrock Chat/Text Playground.
AWS Identity and Access Management (IAM) es fundamental para acceder de forma segura a AWS Bedrock. Sigue estos pasos para configurar los permisos:
Editor de políticas de AWS IAM en modo JSON
{
"Version": "2012-10-17",
"Statement": [ {
"Sid": "BedrockFullAccess",
"Effect": "Allow",
"Action": ["bedrock:*"],
"Resource": "*"
}
]
}Nota: La política anterior puede adjuntarse a cualquier rol que necesite acceder al servicio Amazon Bedrock. Puede ser SageMaker o un usuario. Al utilizar Amazon SageMaker, el rol de ejecución de tu bloc de notas suele ser un usuario o rol distinto del que utilizas para iniciar sesión en la consola de administración de AWS. Para saber cómo explorar el servicio Amazon Bedrock utilizando la Consola de AWS, asegúrate de autorizar tu usuario o rol de la Consola. Puedes ejecutar los cuadernos desde cualquier entorno con acceso al servicio AWS Bedrock y credenciales válidas.
Las aplicaciones de IA generativa se construyen sobre modelos básicos que se ajustan para una tarea concreta, como la generación de texto, la creación de imágenes o la transformación de datos. A continuación encontrarás una guía paso a paso para elegir un modelo básico, utilizar trabajos de inferencia básicos y modificar las respuestas del modelo para adaptarlas a tus necesidades.
Elegir el modelo de cimentación adecuado es importante porque depende de lo que necesite tu proyecto. He aquí cómo hacer una selección:
1. Identifica tu caso de uso:
2. Evalúa las capacidades del modelo:
Antes de utilizar estos modelos, debes habilitar el acceso al modelo en tu cuenta de AWS. Aquí tienes los pasos para configurarlo:
Página de gestión de acceso al modelo de Amazon Bedrock.
Para realizar una inferencia utilizando un modelo de cimentación seleccionado en AWS Bedrock, sigue estos pasos:
pip install boto3import boto3
import json
from botocore.exceptions import ClientError
# Set the AWS Region
region = "us-east-1"
# Initialize the Bedrock Runtime client
client = boto3.client("bedrock-runtime", region_name=region)# Define the model ID for Amazon Titan Express v1
model_id = "amazon.titan-text-express-v1"
# Define the input prompt
prompt = """
Command: Compose an email from Tom, Customer Service Manager, to the customer "Nancy"
who provided negative feedback on the service provided by our customer support
Engineer"""# Configure inference parameters
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512, # Limit the response length
"temperature": 0.5, # Control the randomness of the output
},
}
# Convert the request payload to JSON
request_payload = json.dumps(inference_parameters)try:
# Invoke the model
response = client.invoke_model(
modelId=model_id,
body=request_payload,
contentType="application/json",
accept="application/json"
)
# Decode the response body
response_body = json.loads(response["body"].read())
# Extract and print the generated text
generated_text = response_body["results"][0]["outputText"]
print("Generated Text:\n", generated_text)
except ClientError as e:
print(f"ClientError: {e.response['Error']['Message']}")
except Exception as e:
print(f"An error occurred: {e}")Nota: Puedes acceder y copiar el código completo directamente desde el Gist de GitHub.
Puedes esperar el siguiente resultado:
% python3 main.py
Generated Text:
Tom:
Nancy,
I am writing to express my sincere apologies for the negative experience you had with our customer support engineer. It is unacceptable that we did not meet your expectations, and I want to assure you that we are taking steps to prevent this from happening in the future.
Sincerely,
Tom
Customer Service ManagerPara afinar el comportamiento de la salida del modelo, puedes ajustar parámetros como temperature y maxTokenCount:
temperature: Este parámetro controla la aleatoriedad de la salida. Los valores más bajos aumentan la determinación de la salida, y los valores más altos aumentan la variabilidad.MaxTokenCount: Establece la longitud máxima de la salida generada.Por ejemplo:
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 256, # Limit the response length
"temperature": 0.7, # Control the randomness of the output
},
}Ajustando estos parámetros, puedes adaptar mejor la creatividad y la longitud del contenido generado a las necesidades de tu aplicación.
Cambiemos de marcha y centrémonos en dos enfoques avanzados: la mejora de la IA mediante la Generación Aumentada por Recuperación (GAR) y la gestión y despliegue de modelos a escala.
El GAR requiere que tengamos una base de conocimientos. Antes de configurar la base de conocimientos en Amazon Bedrock, tienes que crear un bucket S3 y subir los archivos necesarios. Sigue estos pasos:
Paso 2: Subir archivos al bucket S3
octank_financial_10K.pdf.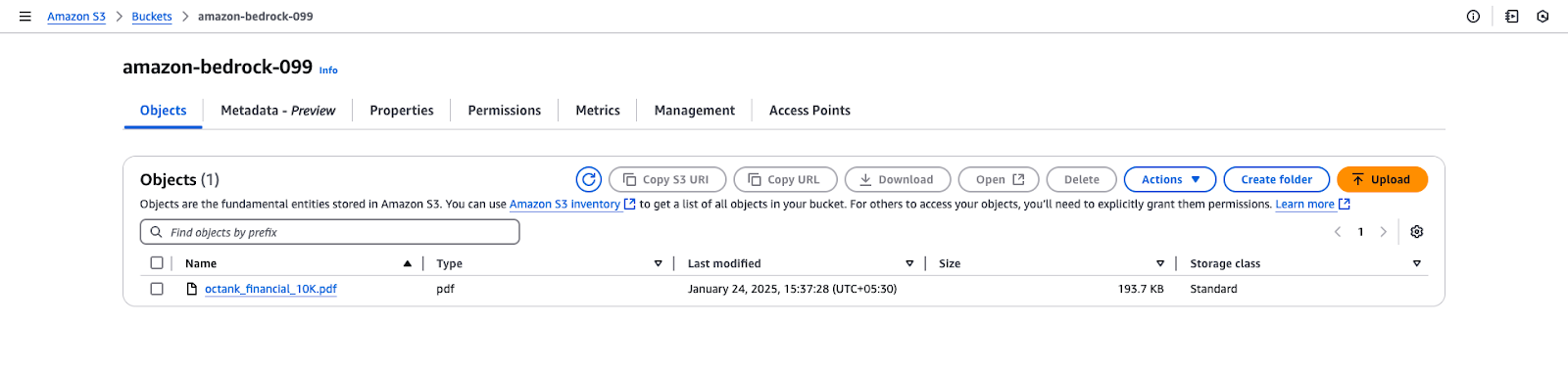
Vista del bucket de Amazon S3 para "amazon-bedrock-099".
Amazon Bedrock te permite crear una base de conocimientos impulsada por bases de datos vectoriales. Los pasos siguientes te guiarán a través de la creación de una base de conocimientos, la configuración de una fuente de datos y la selección de incrustaciones y almacenes vectoriales.
knowledge-base-quick-start).AmazonBedrockExecutionRoleForKnowledgeBase.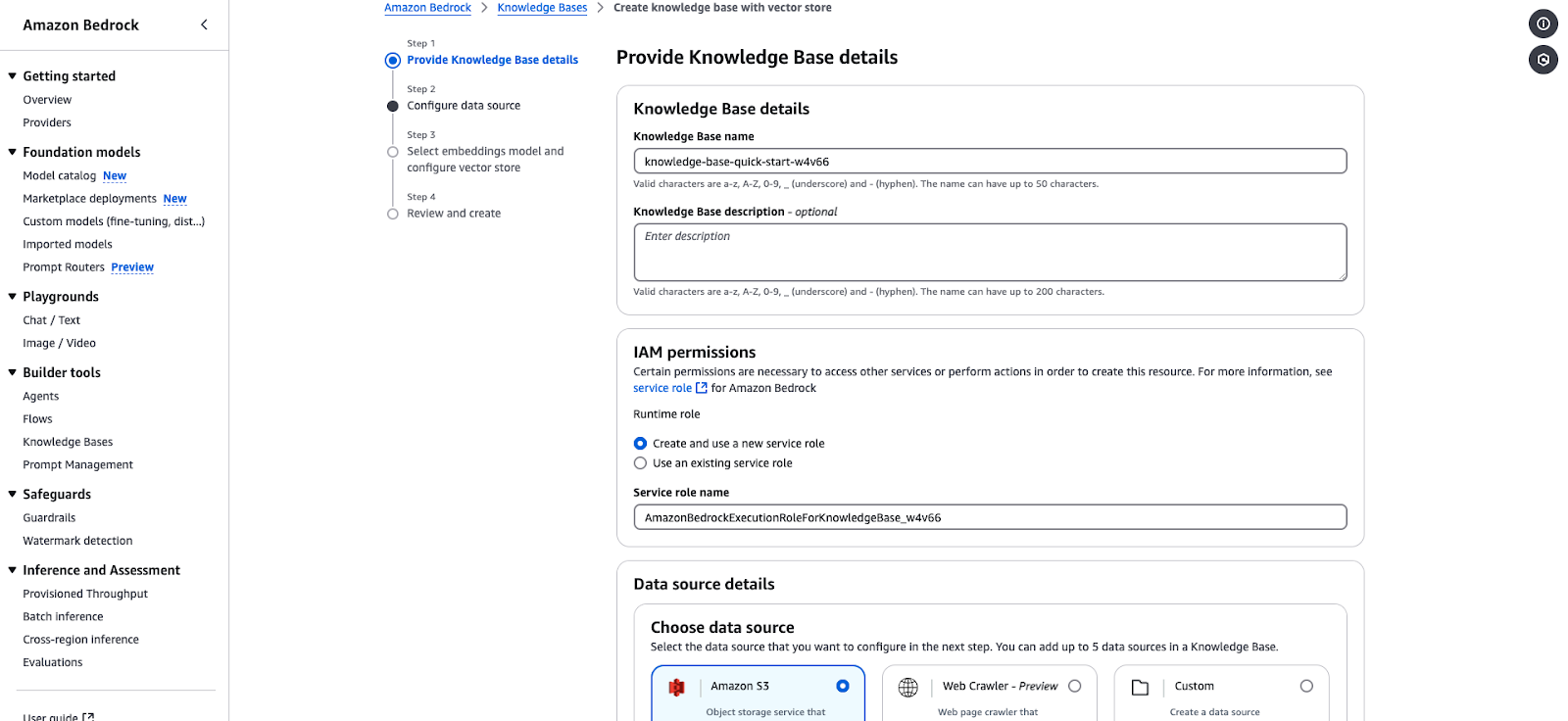
Asistente de creación de la Base de Conocimientos de Amazon Bedrock.
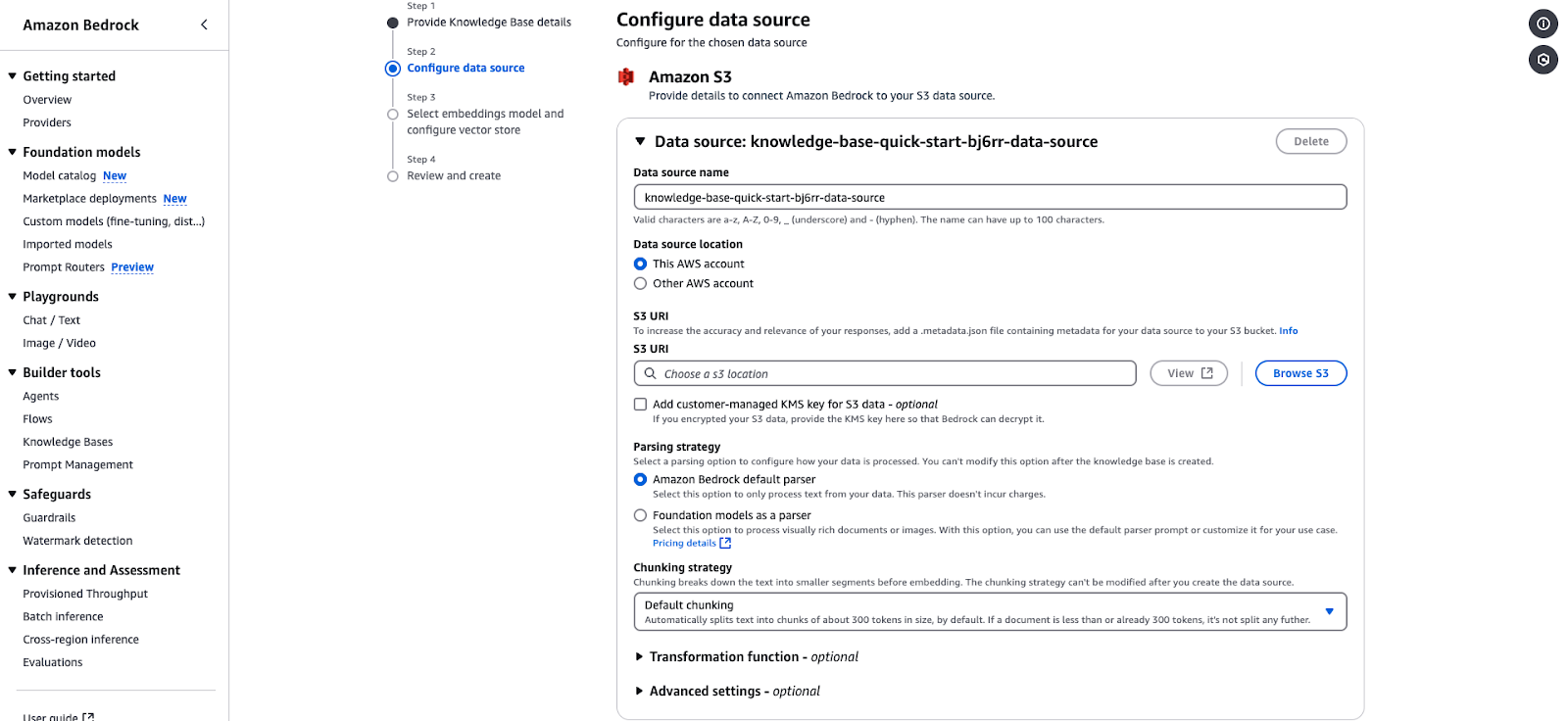
Página de configuración de la fuente de datos de Amazon Bedrock para integrar una base de conocimientos basada en S3.
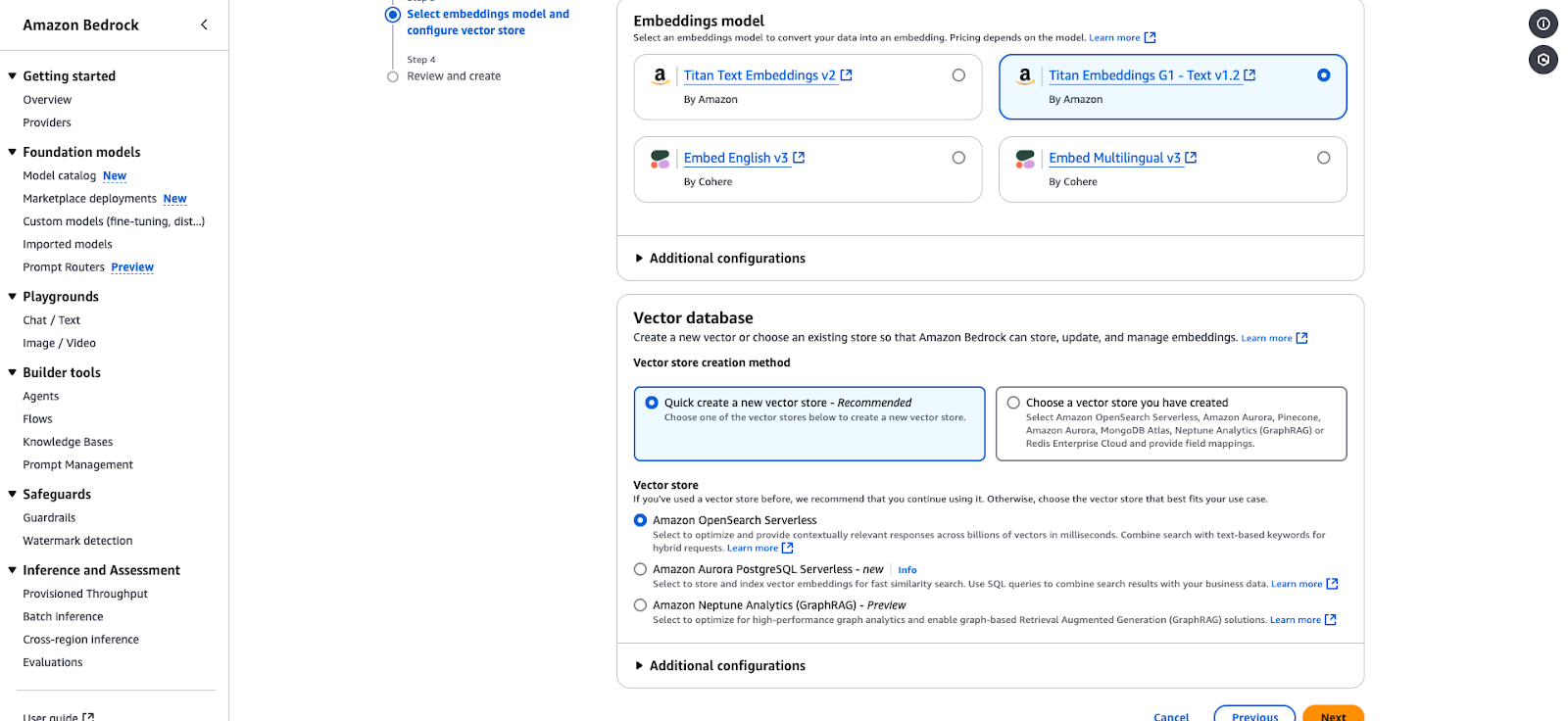
Página de configuración de Amazon Bedrock para seleccionar un modelo de incrustación y un almacén vectorial.
knowledge-base-quick-start).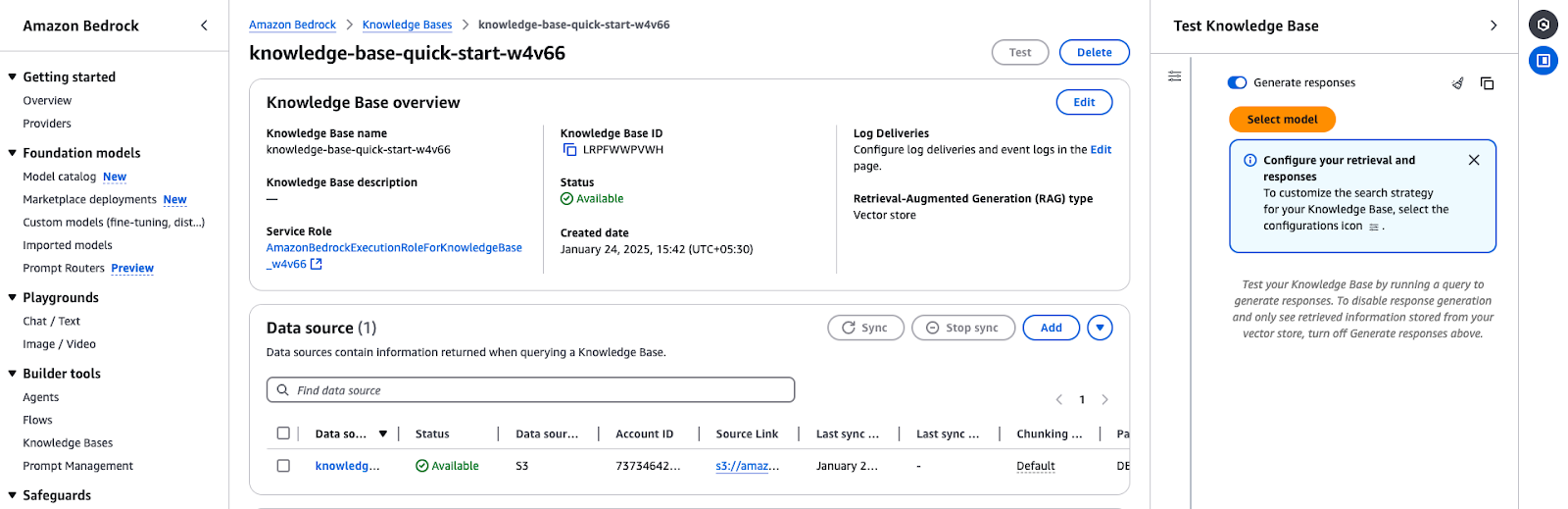
La visión general de la Base de Conocimientos de Amazon Bedrock muestra los detalles de la configuración y el estado de la fuente de datos.
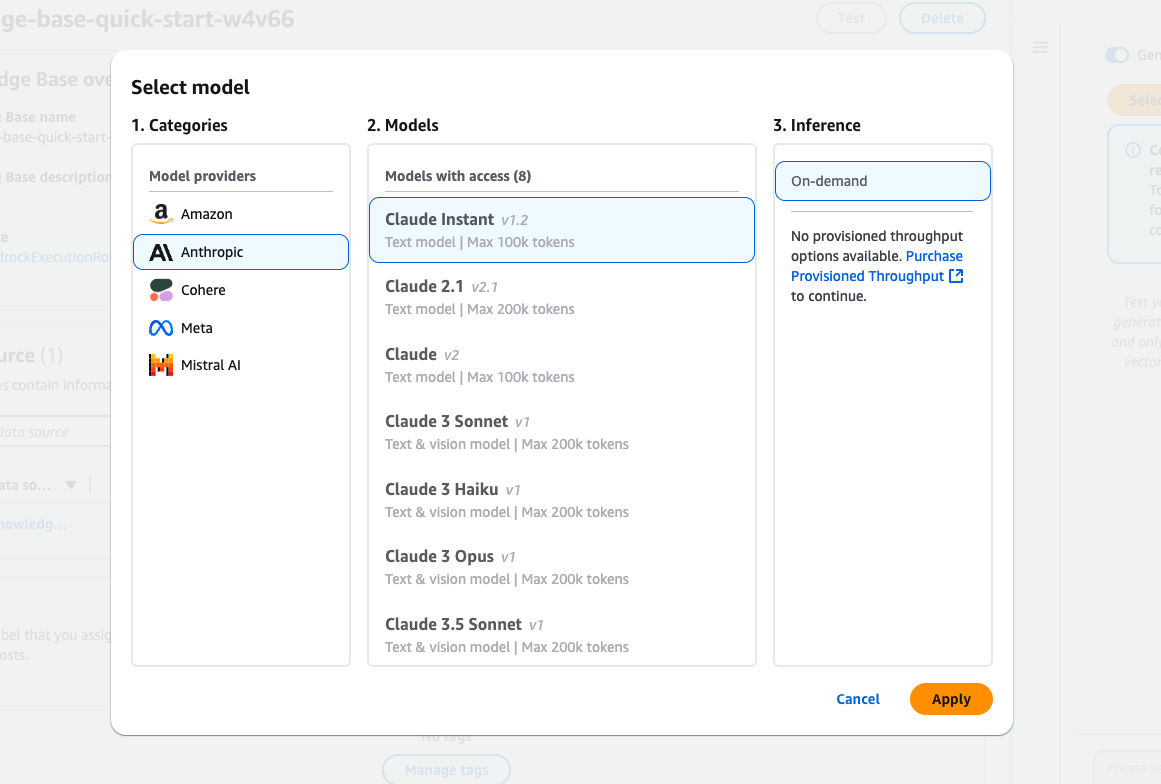
La interfaz de selección de modelos de Amazon Bedrock presenta varios modelos Claude de Anthropic.
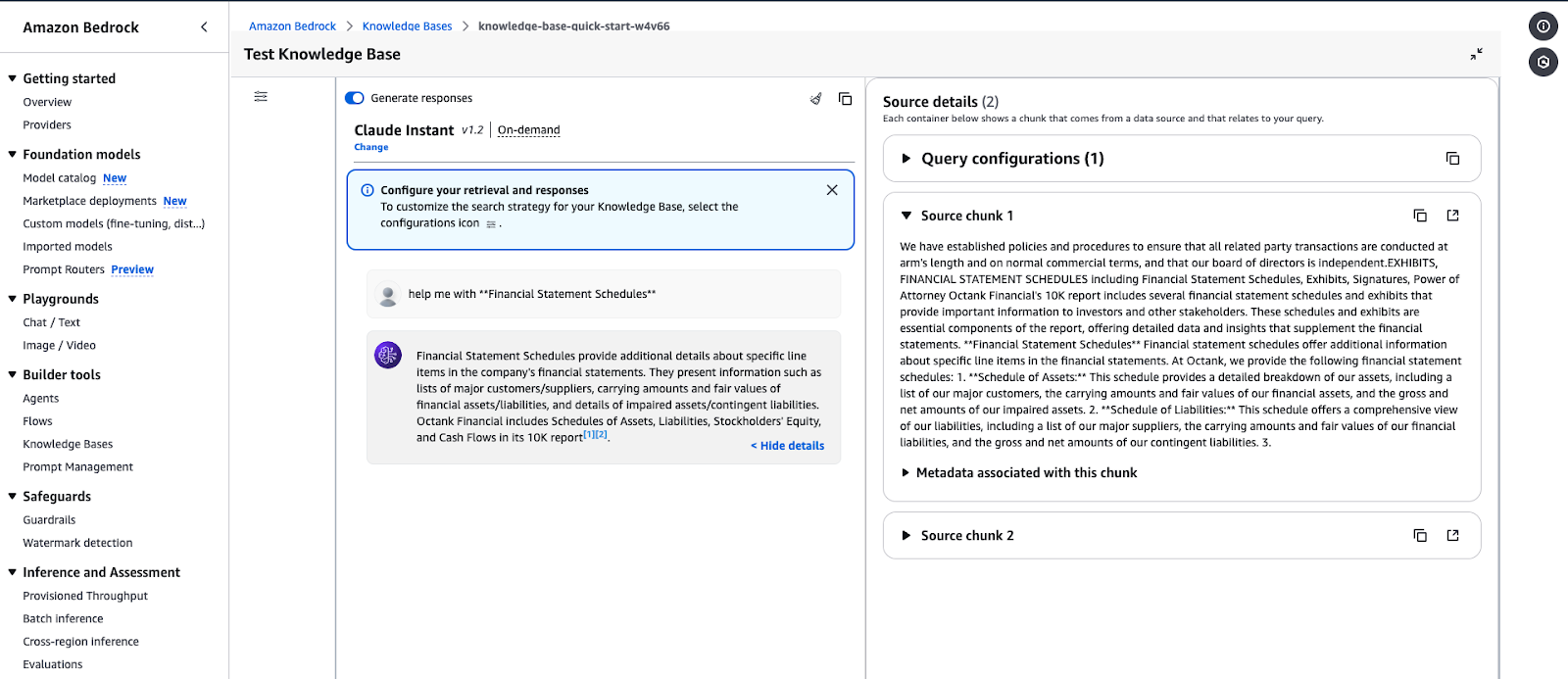
Interfaz de prueba de la Base de Conocimientos de Amazon Bedrock mostrando la respuesta a una consulta.
Ejemplo de salida de consulta:
Utilizando servicios de AWS como Lambda, Amazon Bedrock puede administrar y desplegar modelos de IA a escala. Este enfoque rentable garantiza una alta disponibilidad y escala automáticamente para las aplicaciones impulsadas por IA.
En esta sección, utilizaremos AWS Lambda para invocar un modelo de Bedrock de forma dinámica, de modo que puedas procesar las peticiones bajo demanda.
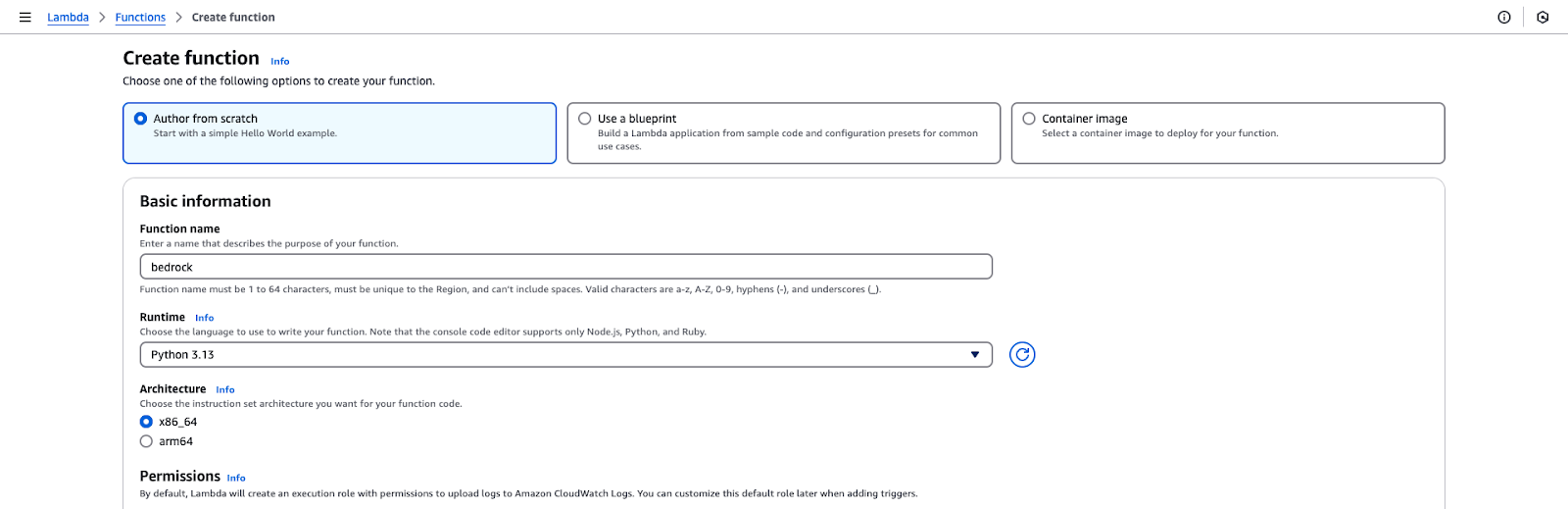
Página de creación de funciones AWS Lambda.
{
"prompt": "Write a formal apology letter for a late delivery."
}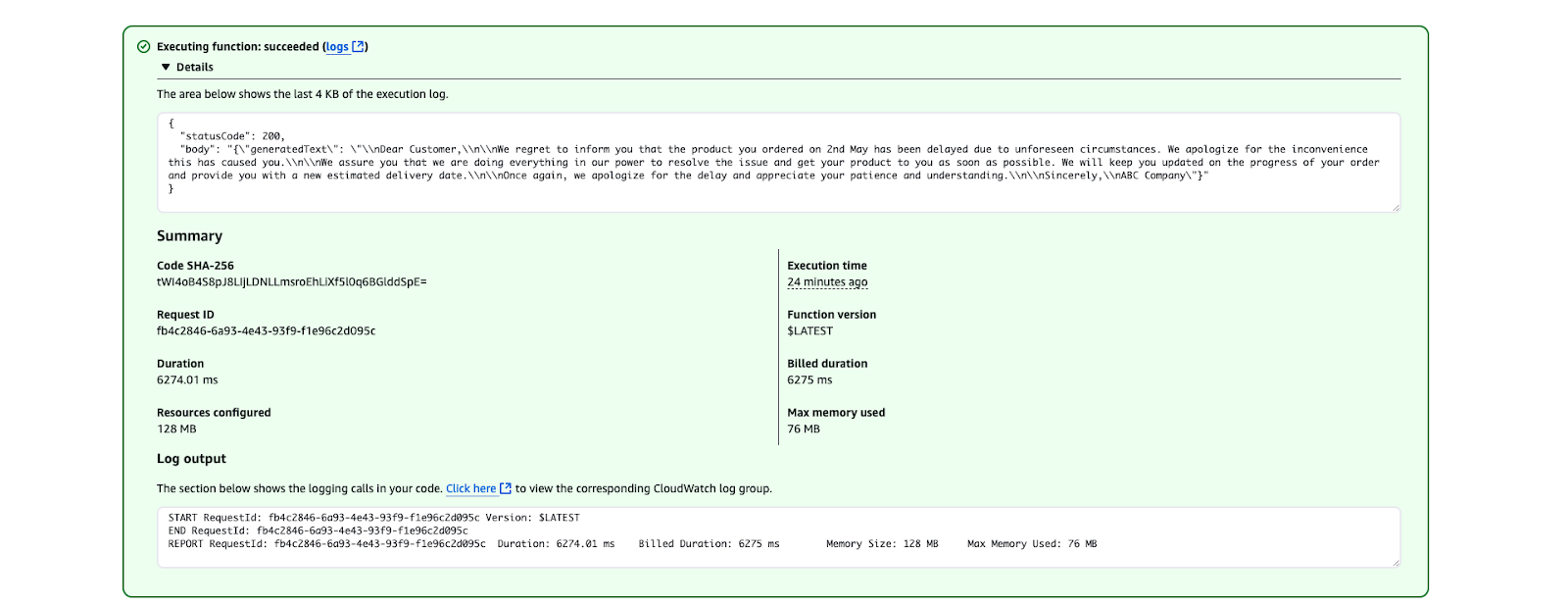
Resultado de la ejecución de AWS Lambda que muestra una ejecución correcta de la función.
Optimiza los costes:
Asegurar la función Lambda:
Monitorizar y registrar:
En esta sección, comparto algunas de las mejores prácticas a la hora de trabajar con Amazon Bedrock, desde optimizar los costes hasta mantener las cosas seguras y precisas.
Administrar los costes en AWS Bedrock puede implicar aprovechar Amazon SageMaker para desplegar modelos y utilizar instancias Spot para ahorrar hasta un 90% en gastos. He aquí algunas de mis mejores prácticas:
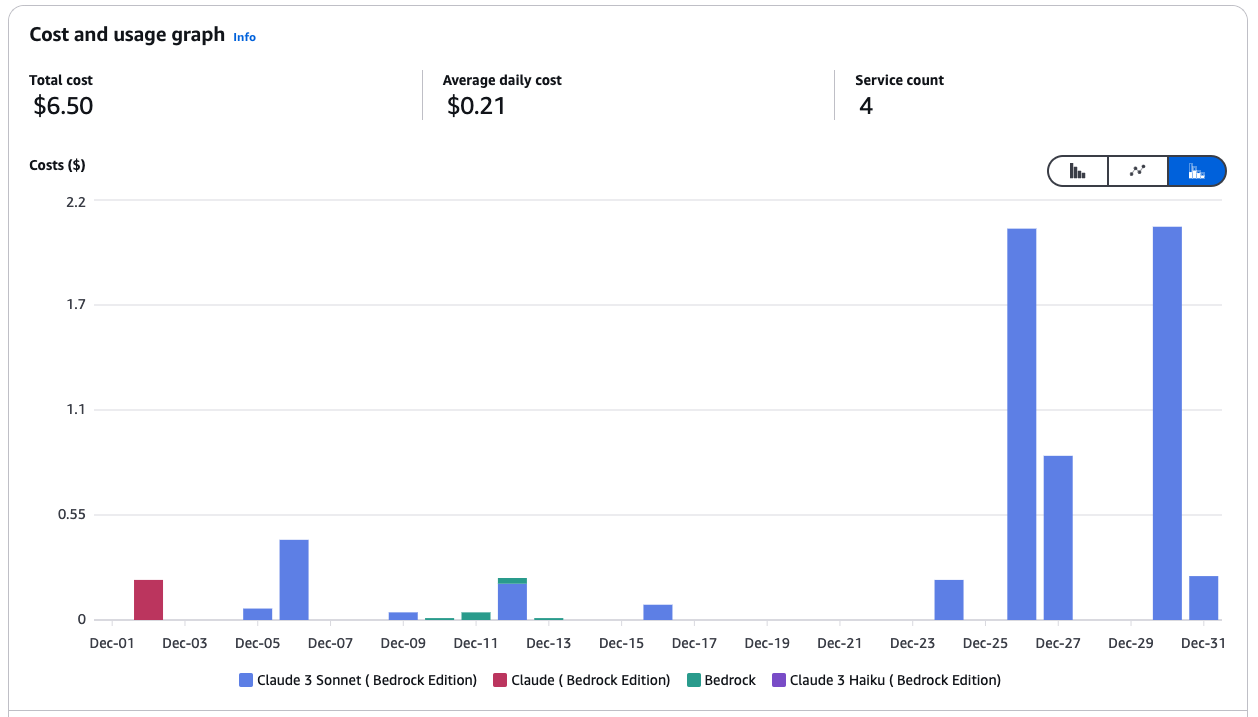
Gráfico de coste y uso de los servicios de Amazon Bedrock.
from sagemaker.mxnet import MXNet
# Use spot instances for cost efficiency
use_spot_instances = True
# Maximum runtime for the training job (in seconds)
max_run = 600
# Maximum wait time for Spot instance availability (in seconds); set only if using Spot instances
max_wait = 1200 if use_spot_instances else None
# Define the MXNet estimator for the training job
mnist_estimator = MXNet(
entry_point='source_dir/mnist.py', # Path to the script that contains the model training code
role=role, # IAM role used for accessing AWS resources (e.g., S3, SageMaker)
output_path=model_artifacts_location, # S3 location to save the trained model artifacts
code_location=custom_code_upload_location, # S3 location to upload the training script
instance_count=1, # Number of instances to use for training
instance_type='ml.m4.xlarge', # Instance type for the training job
framework_version='1.6.0', # Version of the MXNet framework to use
py_version='py3', # Python version for the environment
distribution={'parameter_server': {'enabled': True}}, # Enable distributed training with a parameter server
hyperparameters={ # Training hyperparameters
'learning-rate': 0.1, # Learning rate for the training job
'epochs': 5 # Number of training epochs
},
use_spot_instances=use_spot_instances, # Enable Spot instances for cost savings
max_run=max_run, # Maximum runtime for the training job
max_wait=max_wait, # Maximum wait time for Spot instance availability
checkpoint_s3_uri=checkpoint_s3_uri # S3 URI for saving intermediate checkpoints
)
# Start the training job and specify the locations of training and testing datasets
mnist_estimator.fit({
'train': train_data_location, # S3 location of the training dataset
'test': test_data_location # S3 location of the testing/validation dataset
})
Registros de AWS CloudWatch
Para garantizar la seguridad, la conformidad y el rendimiento de Amazon Bedrock, es importante seguir las mejores prácticas. Estas son mis recomendaciones:
Garantizar que los modelos son precisos, fiables y están alineados con los objetivos empresariales se consigue supervisando y evaluando los modelos. Aquí tienes algunas buenas prácticas:
El panel de métricas muestra el recuento de invocaciones, la latencia y el recuento de tokens de varios modelos de Amazon Bedrock.
AWS Bedrock supone un cambio en la forma de desarrollar aplicaciones de IA generativa y una plataforma centralizada para utilizar modelos de base sin preocuparse de la infraestructura.
A partir de aquí, este tutorial paso a paso debería ayudarte a identificar los modelos adecuados, crear flujos de trabajo seguros y escalables, e integrar funciones como la generación aumentada por recuperación (RAG) para una mayor personalización. Una vez establecidas las mejores prácticas en materia de costes, seguridad y supervisión, estarás preparado para desarrollar y gestionar tus soluciones de IA para cumplir tus objetivos.
Para profundizar aún más en tus conocimientos de AWS, explora estos cursos:
Aprende más sobre AWS con estos cursos
programa
Curso
Curso
blog
Abid Ali Awan
10 min
blog
Adel Nehme
15 min
Tutorial
Tim Lu
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
Tutorial
Arunn Thevapalan




