
Programma
Esperto di cloud AWS (CLF-C02)
10 h
L’IA generativa è diventata il fattore dirompente in tutti i settori, trainando i progressi nell’elaborazione del linguaggio naturale, nella computer vision e in molti altri ambiti. Tuttavia, sfruttarne il potenziale è spesso stato accompagnato da sfide legate a costi, infrastrutture complesse e ripide curve di apprendimento. È qui che entra in gioco AWS Bedrock: questa soluzione rimuove gli ostacoli permettendoti di usare foundation model senza dover gestire l’infrastruttura.
Questo tutorial vuole essere la tua guida completa ad Amazon Bedrock, spiegando cos’è, come funziona e come puoi usarlo. Al termine, avrai le informazioni e le competenze necessarie per sviluppare applicazioni di IA generativa—scalabili, flessibili e allineate ai tuoi obiettivi.
Amazon Bedrock è un servizio gestito di AWS per accedere e gestire foundation model (FM), i componenti di base dell’IA generativa di Amazon Web Services (AWS). Bedrock semplifica al punto che non devi preoccuparti di effettuare il provisioning di GPU, configurare pipeline di modelli o gestire altra infrastruttura.
AWS Bedrock è una porta d’accesso all’innovazione. È una piattaforma unificata che consente agli sviluppatori di esplorare, testare e distribuire modelli di IA all’avanguardia di provider di primo piano come Anthropic, Stability AI e Titan di Amazon.
Per esempio, immagina di sviluppare un chatbot per l’assistenza clienti. Con AWS Bedrock puoi selezionare un modello linguistico sofisticato, adattarlo alle esigenze della tua applicazione e integrarlo senza dover mai scrivere configurazioni del server nel codice.
Le funzionalità di AWS Bedrock sono pensate per semplificare e accelerare il passaggio dall’idea all’ambiente di produzione. Vediamole nel dettaglio.
Uno dei maggiori vantaggi di AWS Bedrock è la varietà di foundation model disponibili. Che tu stia lavorando su applicazioni testuali, contenuti visivi o IA sicura e interpretabile, Bedrock ti copre. Ecco alcuni modelli disponibili:
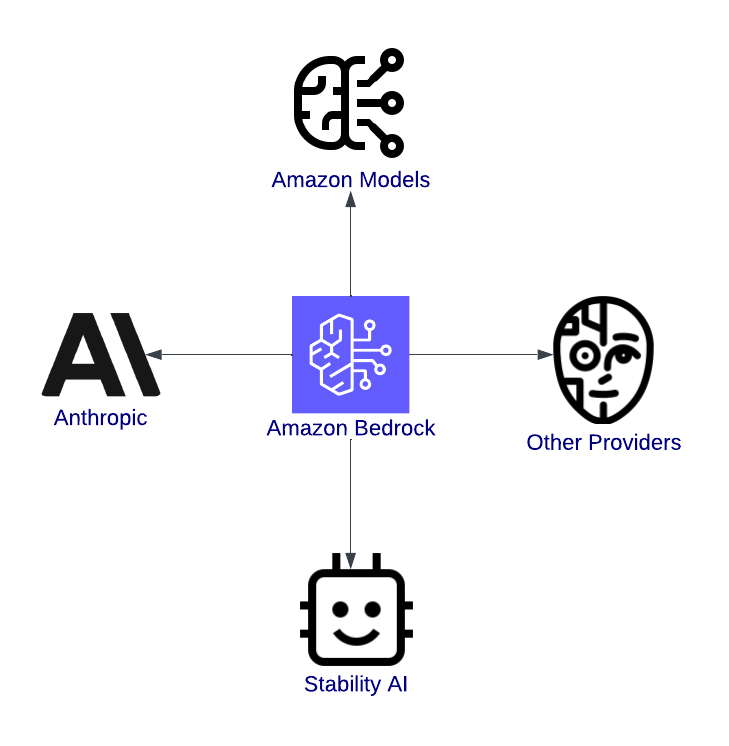
Panoramica di Amazon Bedrock, con evidenza dell’integrazione con i modelli.
AWS Bedrock astrae la gestione dell’infrastruttura, il che significa:
Le applicazioni di IA generativa hanno in genere una domanda imprevedibile. Un chatbot può rispondere a centinaia di utenti nelle ore di punta e a pochi durante la notte. AWS Bedrock risolve questo aspetto con la scalabilità integrata:
AWS Bedrock va oltre la fornitura di modelli potenti: si integra con altri servizi AWS per supportare workflow di IA end-to-end. Alcune integrazioni includono:
Questa sezione ti guida nella configurazione delle autorizzazioni necessarie, nella creazione di un account AWS e nell’avvio con AWS Bedrock.
Se non ne hai già uno, vai alla pagina di registrazione AWS e crea un account. Se sei già utente, assicurati che il tuo utente IAM abbia privilegi di amministratore.

La pagina di registrazione AWS, con l’esplorazione del Free Tier per i nuovi account.
Se cerchi i passaggi dettagliati, visita la guida ufficiale AWS.
Amazon Bedrock è accessibile dalla AWS Management Console. Segui questi passaggi per trovarlo e iniziare a usarlo:
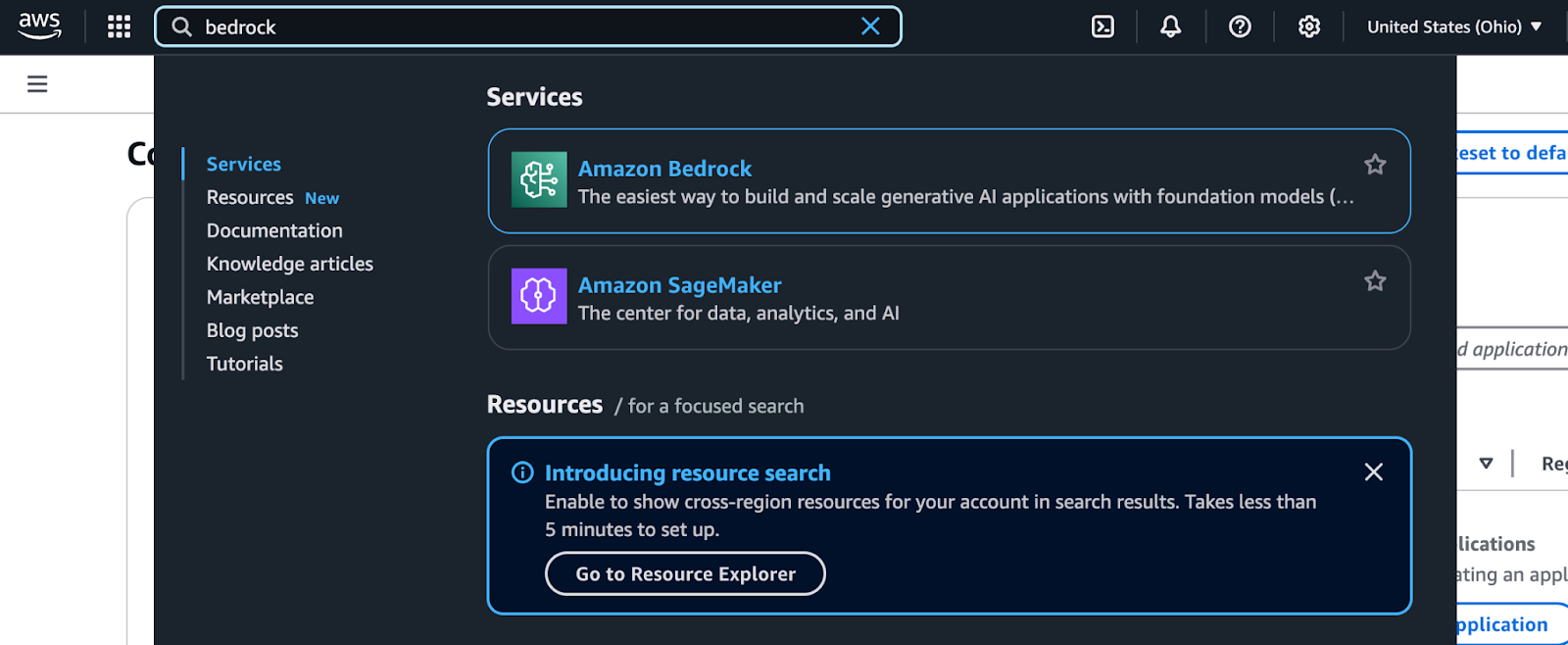
Risultati di ricerca della AWS Management Console per Bedrock.

Pagina dei provider di Amazon Bedrock con opzioni di modelli serverless di Amazon.
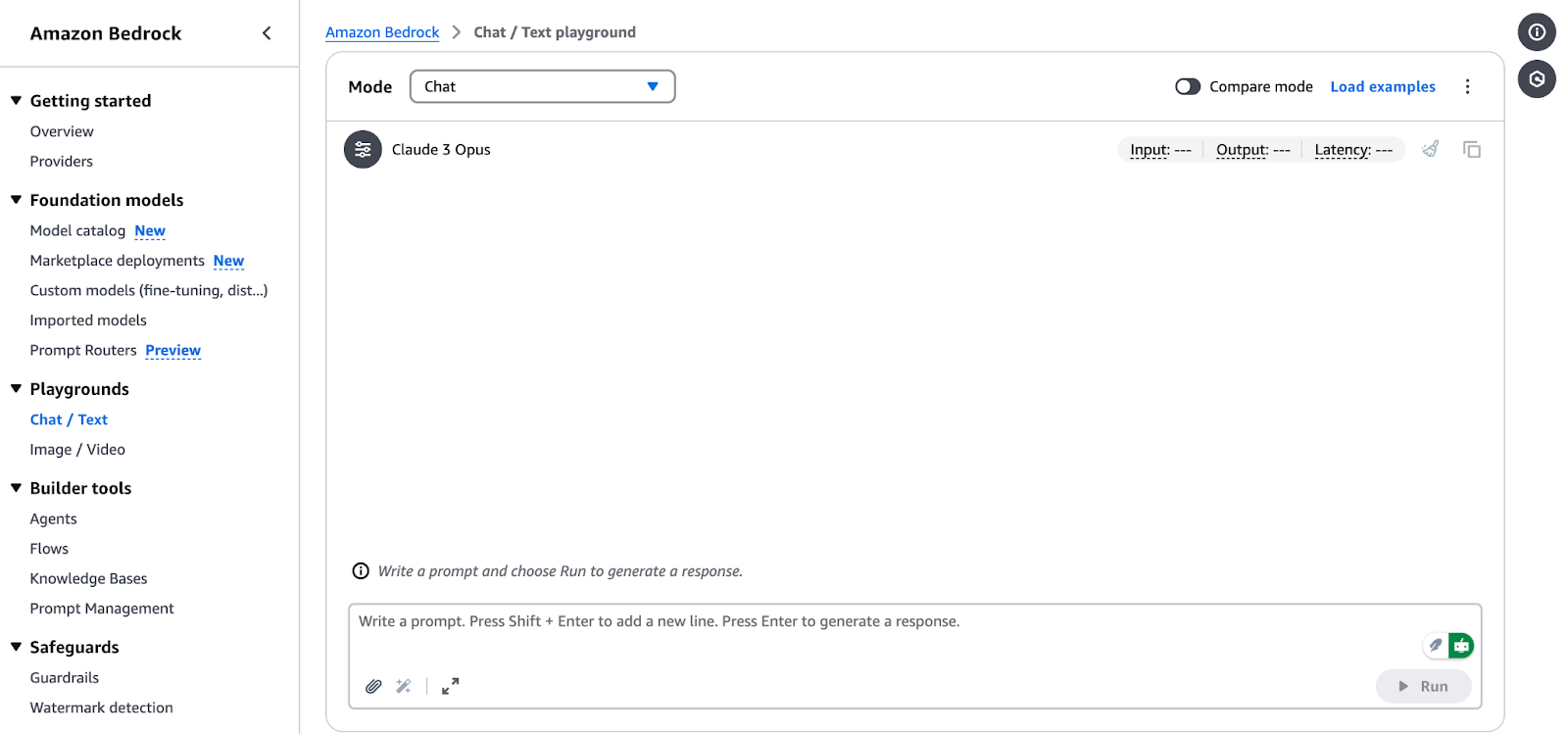
Interfaccia Chat/Text Playground di Amazon Bedrock.
AWS Identity and Access Management (IAM) è fondamentale per accedere in modo sicuro ad AWS Bedrock. Segui questi passaggi per configurare i permessi:
Editor di policy AWS IAM in modalità JSON
{
"Version": "2012-10-17",
"Statement": [ {
"Sid": "BedrockFullAccess",
"Effect": "Allow",
"Action": ["bedrock:*"],
"Resource": "*"
}
]
}Nota: La policy sopra può essere associata a qualsiasi ruolo che debba accedere al servizio Amazon Bedrock. Può essere SageMaker o un utente. Quando usi Amazon SageMaker, il ruolo di esecuzione del tuo notebook è in genere diverso dall’utente o ruolo con cui accedi alla AWS Management Console. Per scoprire come esplorare il servizio Amazon Bedrock usando la Console AWS, assicurati di autorizzare il tuo utente o ruolo della Console. Puoi eseguire i notebook da qualsiasi ambiente con accesso al servizio AWS Bedrock e credenziali valide.
Le applicazioni di IA generativa si basano su foundation model adattati a un compito specifico, come generazione di testo, creazione di immagini o trasformazione dei dati. Di seguito trovi una guida passo passo per scegliere un foundation model, usare inferenze di base e modificare le risposte del modello in base alle tue esigenze.
Scegliere il foundation model giusto è importante perché dipende dalle necessità del progetto. Ecco come procedere:
1. Identifica il tuo caso d’uso:
2. Valuta le capacità dei modelli:
Prima di usare questi modelli, devi abilitare l’accesso ai modelli nel tuo account AWS. Ecco come impostarlo:
Pagina di gestione degli accessi ai modelli di Amazon Bedrock.
Per eseguire un’inferenza usando un foundation model selezionato in AWS Bedrock, segui questi passaggi:
pip install boto3import boto3
import json
from botocore.exceptions import ClientError
# Set the AWS Region
region = "us-east-1"
# Initialize the Bedrock Runtime client
client = boto3.client("bedrock-runtime", region_name=region)# Define the model ID for Amazon Titan Express v1
model_id = "amazon.titan-text-express-v1"
# Define the input prompt
prompt = """
Command: Compose an email from Tom, Customer Service Manager, to the customer "Nancy"
who provided negative feedback on the service provided by our customer support
Engineer"""# Configure inference parameters
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512, # Limit the response length
"temperature": 0.5, # Control the randomness of the output
},
}
# Convert the request payload to JSON
request_payload = json.dumps(inference_parameters)try:
# Invoke the model
response = client.invoke_model(
modelId=model_id,
body=request_payload,
contentType="application/json",
accept="application/json"
)
# Decode the response body
response_body = json.loads(response["body"].read())
# Extract and print the generated text
generated_text = response_body["results"][0]["outputText"]
print("Generated Text:\n", generated_text)
except ClientError as e:
print(f"ClientError: {e.response['Error']['Message']}")
except Exception as e:
print(f"An error occurred: {e}")Nota: puoi accedere e copiare il codice completo direttamente dal GitHub Gist.
Puoi aspettarti un output come quello sotto:
% python3 main.py
Generated Text:
Tom:
Nancy,
I am writing to express my sincere apologies for the negative experience you had with our customer support engineer. It is unacceptable that we did not meet your expectations, and I want to assure you that we are taking steps to prevent this from happening in the future.
Sincerely,
Tom
Customer Service ManagerPer rifinire il comportamento dell’output del modello, puoi regolare parametri come temperature e maxTokenCount:
temperature: controlla il grado di casualità dell’output. Valori più bassi aumentano la determinazione dell’output, valori più alti aumentano la variabilità.MaxTokenCount: imposta la lunghezza massima dell’output generato.Per esempio:
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 256, # Limit the response length
"temperature": 0.7, # Control the randomness of the output
},
}Regolando questi parametri, puoi adattare meglio creatività e lunghezza dei contenuti generati alle esigenze della tua applicazione.
Cambiamo marcia e concentriamoci su due approcci avanzati: potenziare l’IA con la Retrieval-Augmented Generation (RAG) e gestire e distribuire i modelli su larga scala.
RAG richiede una knowledge base. Prima di configurarla in Amazon Bedrock, devi creare un bucket S3 e caricare i file necessari. Segui questi passaggi:
Passo 2: Carica i file nel bucket S3
octank_financial_10K.pdf.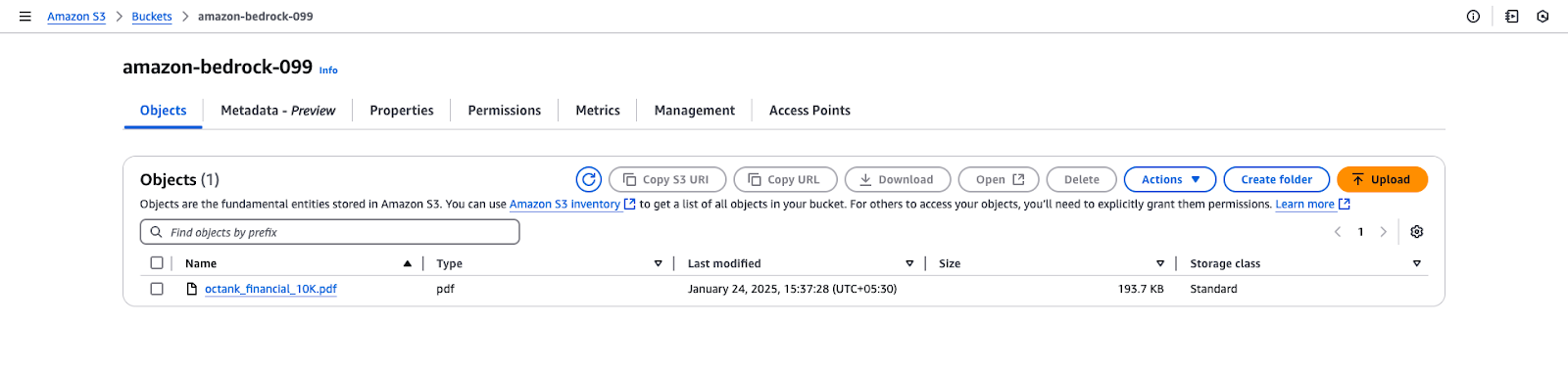
Vista del bucket Amazon S3 per "amazon-bedrock-099".
Amazon Bedrock ti consente di creare una knowledge base alimentata da database vettoriali. I seguenti passaggi ti guidano nella creazione di una knowledge base, nella configurazione di una sorgente dati e nella selezione di embeddings e archivi vettoriali.
knowledge-base-quick-start).AmazonBedrockExecutionRoleForKnowledgeBase.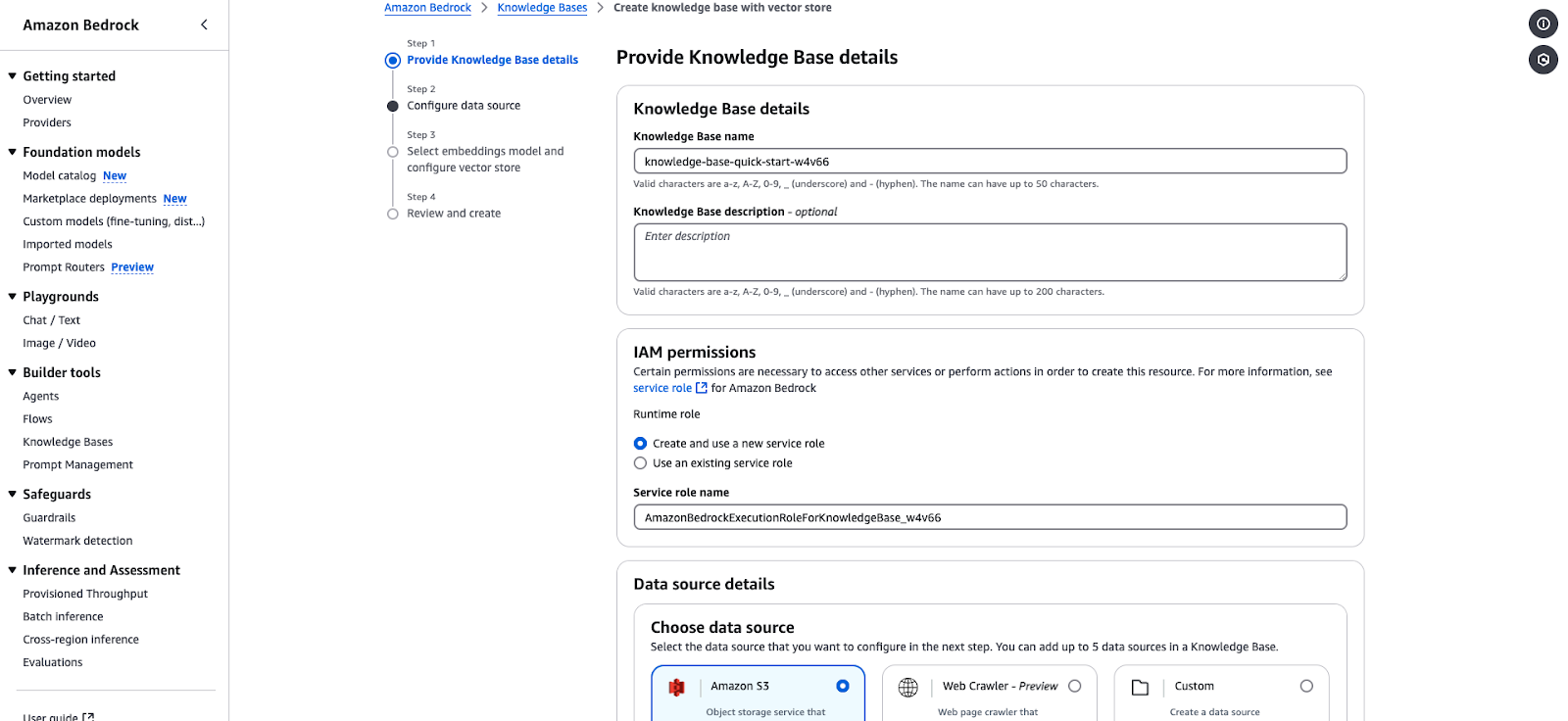
Procedura guidata di creazione della Knowledge Base in Amazon Bedrock.
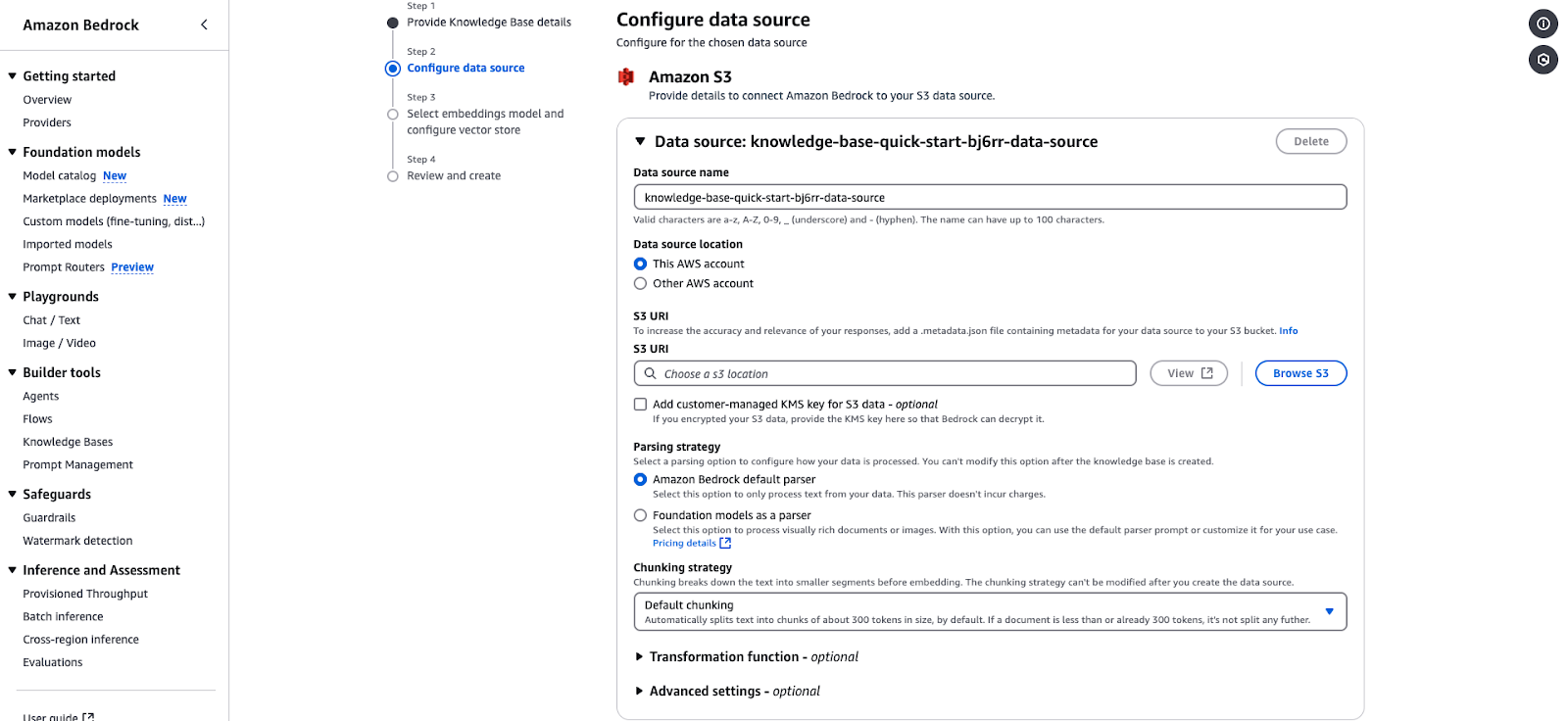
Pagina di configurazione della sorgente dati di Amazon Bedrock per integrare una knowledge base basata su S3.
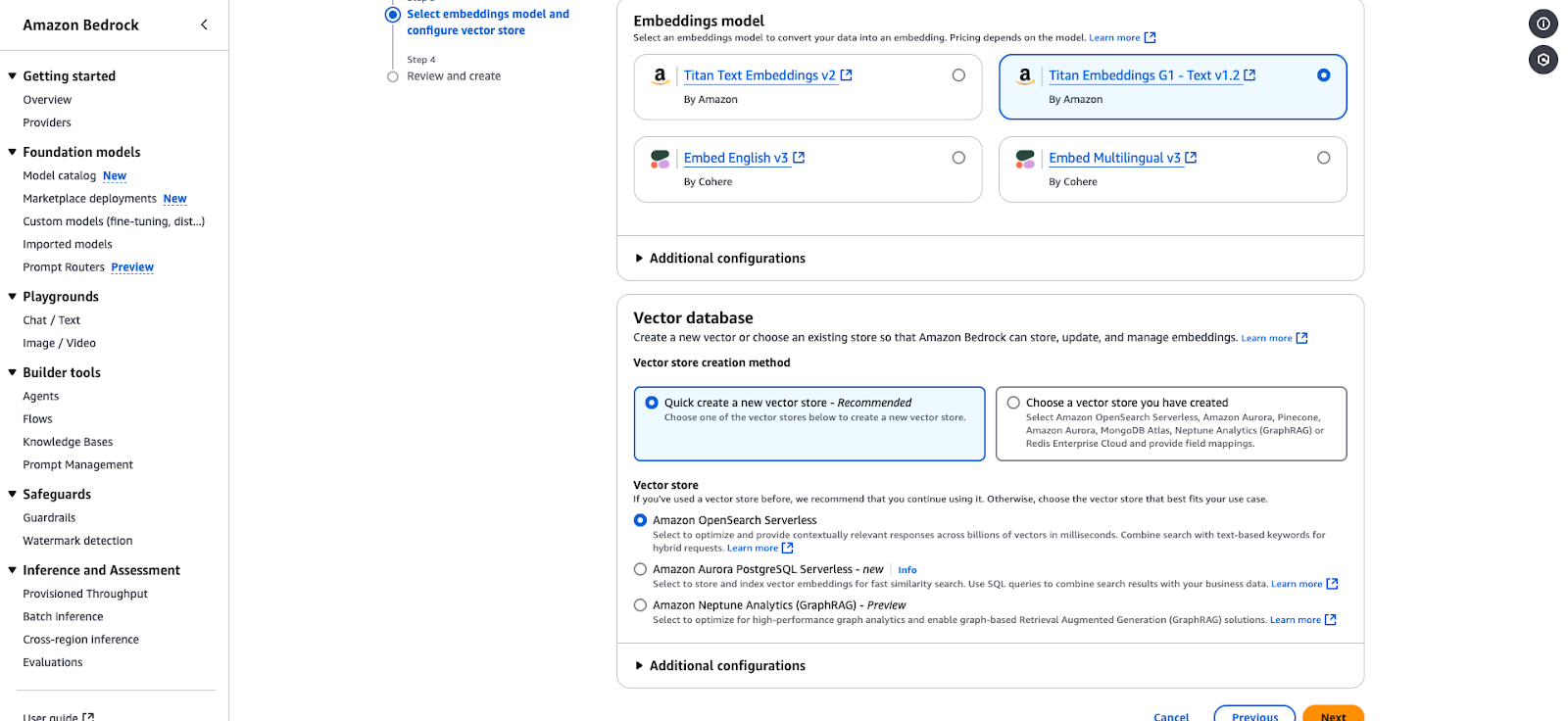
Pagina di configurazione di Amazon Bedrock per la scelta di un embedding model e del vector store.
knowledge-base-quick-start).
Panoramica della Knowledge Base in Amazon Bedrock con dettagli di configurazione e stato della sorgente dati.
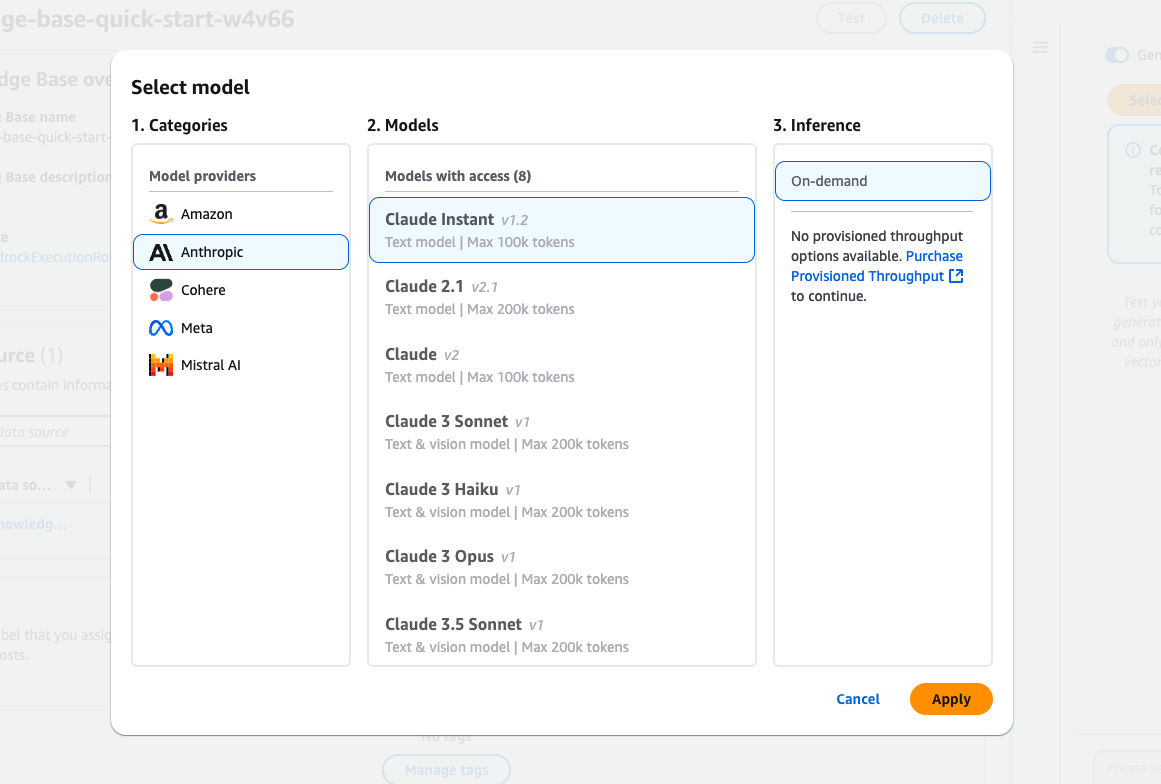
Interfaccia di selezione dei modelli di Amazon Bedrock con vari modelli Claude di Anthropic.
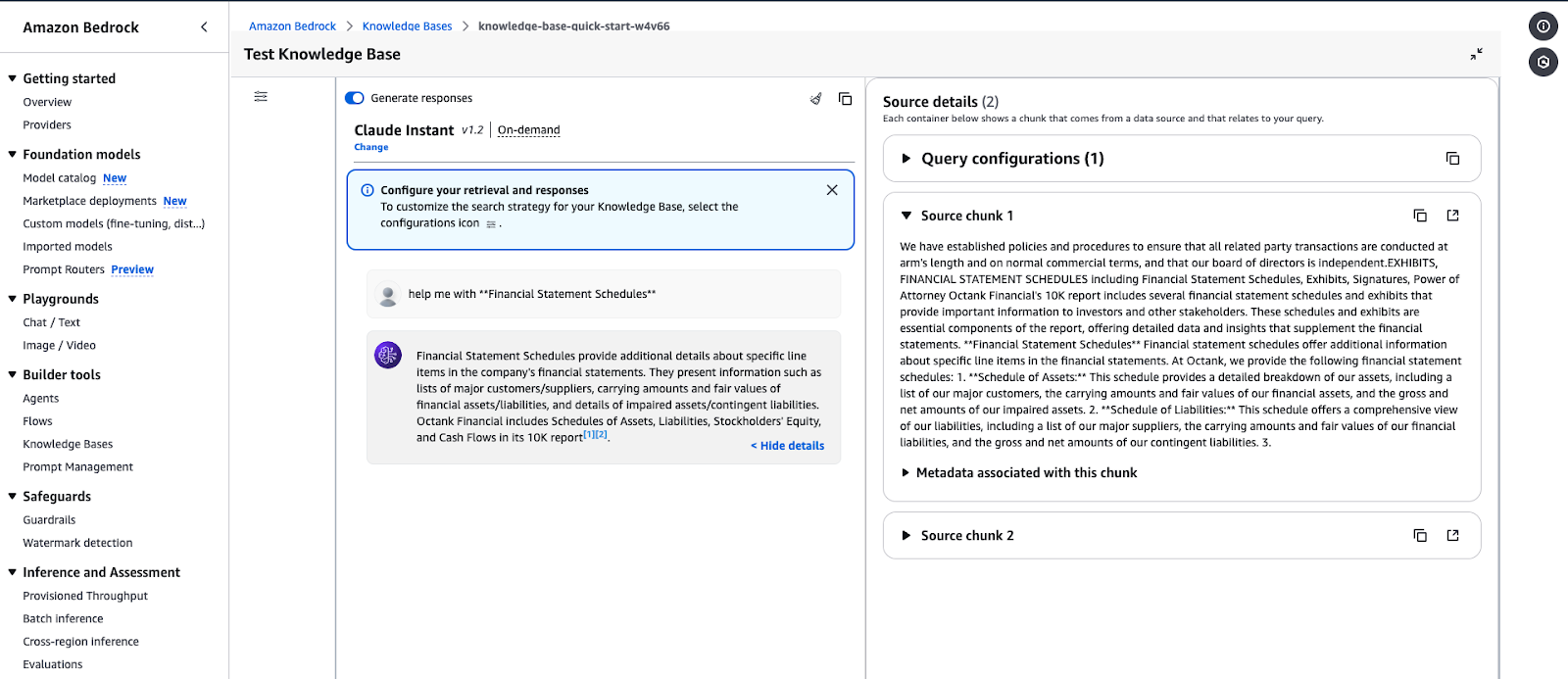
Interfaccia di test della Knowledge Base in Amazon Bedrock che mostra una risposta a una query.
Esempio di output della query:
Usando servizi AWS come Lambda, Amazon Bedrock può gestire e distribuire modelli di IA su larga scala. Questo approccio, efficiente in termini di costi, garantisce alta disponibilità e scalabilità automatica per applicazioni basate su IA.
In questa sezione useremo AWS Lambda per invocare dinamicamente un modello Bedrock, così da poter elaborare prompt on demand.
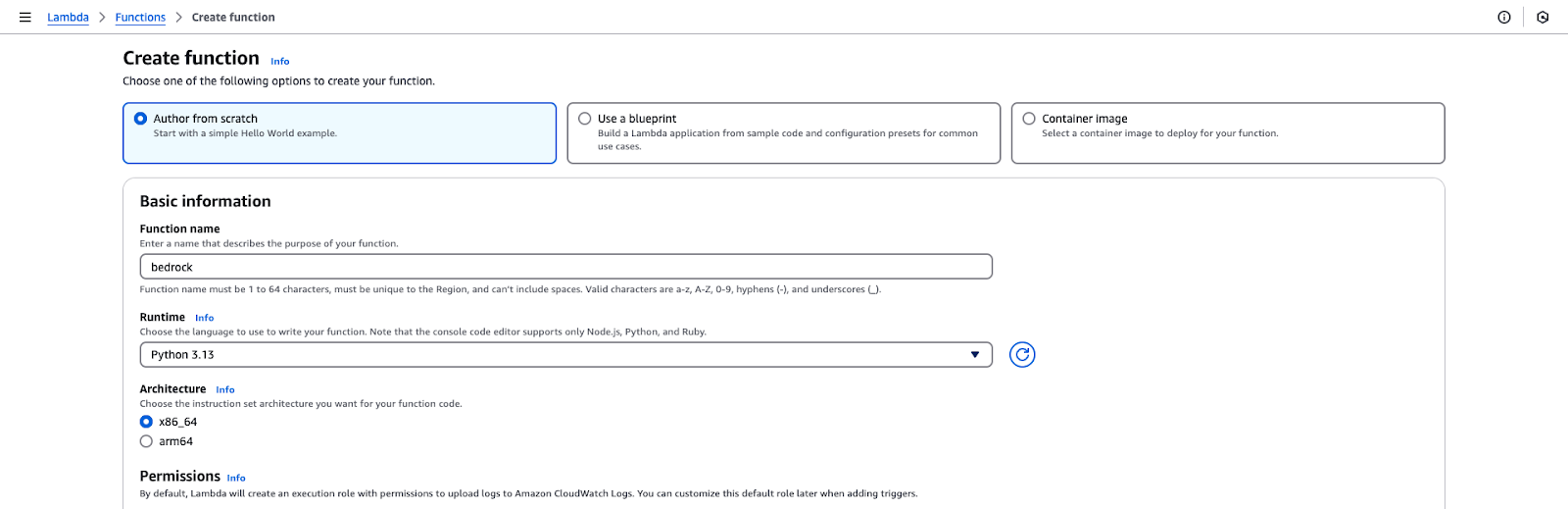
Pagina di creazione di una funzione AWS Lambda.
{
"prompt": "Write a formal apology letter for a late delivery."
}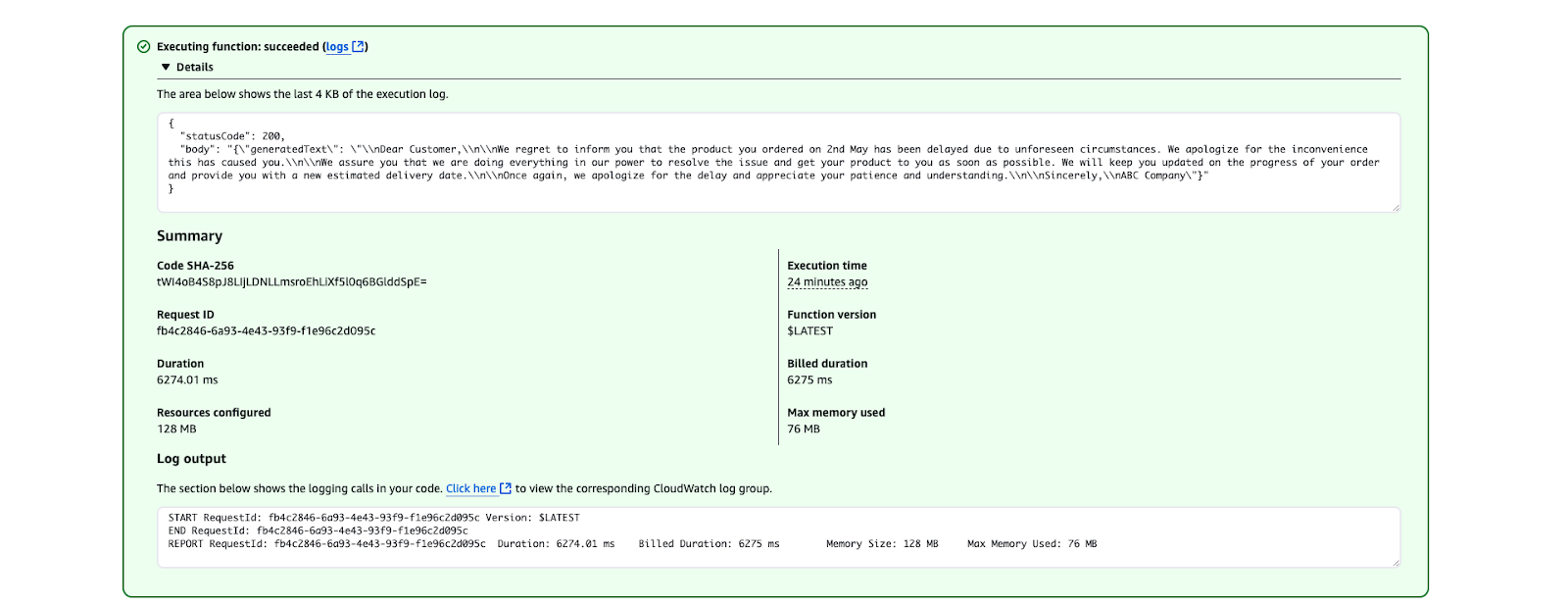
Risultato di esecuzione AWS Lambda che mostra un’esecuzione riuscita.
Ottimizza i costi:
Metti in sicurezza la funzione Lambda:
Monitora e registra i log:
In questa sezione condivido alcune best practice quando lavori con Amazon Bedrock, dall’ottimizzazione dei costi alla sicurezza e all’accuratezza.
La gestione dei costi in AWS Bedrock può includere l’uso di Amazon SageMaker per distribuire modelli e utilizzare Spot Instances per risparmiare fino al 90% delle spese. Ecco alcune delle mie best practice:
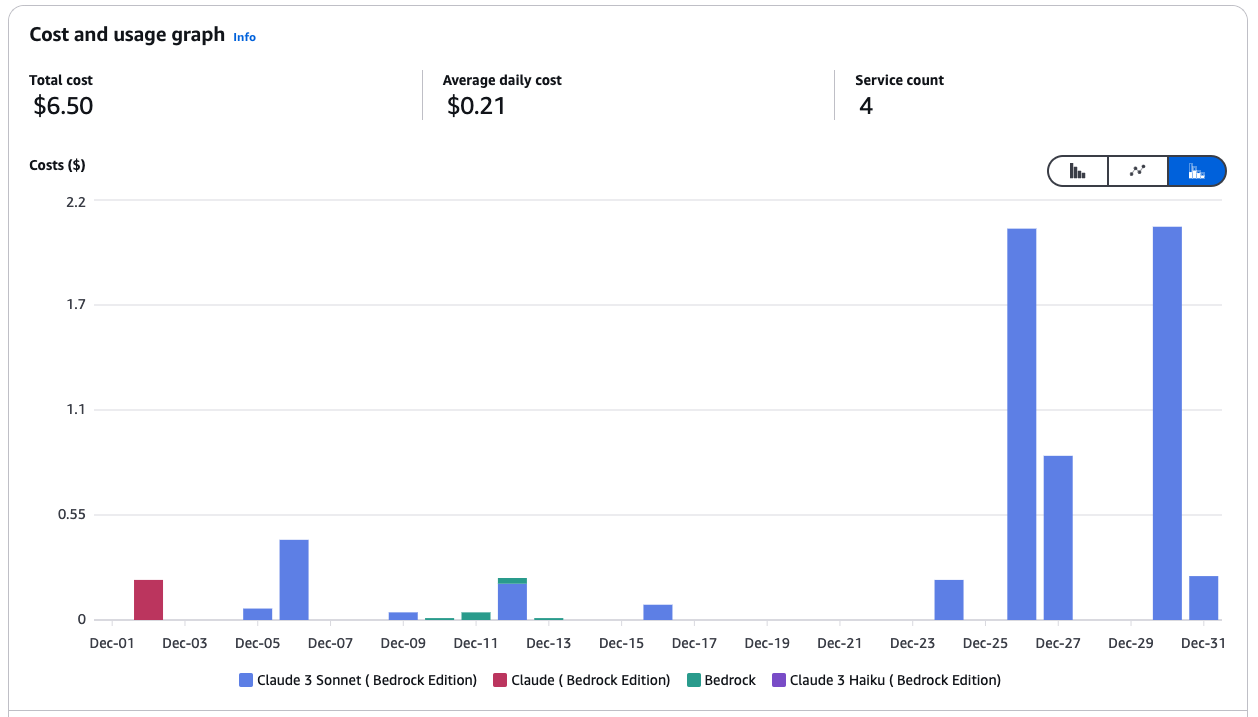
Grafico di costi e utilizzo per i servizi Amazon Bedrock.
from sagemaker.mxnet import MXNet
# Use spot instances for cost efficiency
use_spot_instances = True
# Maximum runtime for the training job (in seconds)
max_run = 600
# Maximum wait time for Spot instance availability (in seconds); set only if using Spot instances
max_wait = 1200 if use_spot_instances else None
# Define the MXNet estimator for the training job
mnist_estimator = MXNet(
entry_point='source_dir/mnist.py', # Path to the script that contains the model training code
role=role, # IAM role used for accessing AWS resources (e.g., S3, SageMaker)
output_path=model_artifacts_location, # S3 location to save the trained model artifacts
code_location=custom_code_upload_location, # S3 location to upload the training script
instance_count=1, # Number of instances to use for training
instance_type='ml.m4.xlarge', # Instance type for the training job
framework_version='1.6.0', # Version of the MXNet framework to use
py_version='py3', # Python version for the environment
distribution={'parameter_server': {'enabled': True}}, # Enable distributed training with a parameter server
hyperparameters={ # Training hyperparameters
'learning-rate': 0.1, # Learning rate for the training job
'epochs': 5 # Number of training epochs
},
use_spot_instances=use_spot_instances, # Enable Spot instances for cost savings
max_run=max_run, # Maximum runtime for the training job
max_wait=max_wait, # Maximum wait time for Spot instance availability
checkpoint_s3_uri=checkpoint_s3_uri # S3 URI for saving intermediate checkpoints
)
# Start the training job and specify the locations of training and testing datasets
mnist_estimator.fit({
'train': train_data_location, # S3 location of the training dataset
'test': test_data_location # S3 location of the testing/validation dataset
})
Log di AWS CloudWatch
Per garantire sicurezza, conformità e prestazioni di Amazon Bedrock, è importante seguire le best practice. Ecco le mie raccomandazioni:
Garantire che i modelli siano accurati, affidabili e allineati agli obiettivi di business si ottiene monitorandoli e valutandoli. Ecco alcune best practice:
La dashboard delle metriche mostra conteggio invocazioni, latenza e token per vari modelli in Amazon Bedrock.
AWS Bedrock cambia le regole su come si sviluppano le applicazioni di IA generativa ed è una piattaforma centralizzata per usare foundation model senza preoccuparsi dell’infrastruttura.
Da qui in avanti, questo tutorial passo passo dovrebbe aiutarti a identificare i modelli giusti, creare workflow sicuri e scalabili e integrare funzionalità come la retrieval-augmented generation (RAG) per una personalizzazione maggiore. Con best practice su costi, sicurezza e monitoraggio, sei pronto a sviluppare e gestire le tue soluzioni di IA per raggiungere i tuoi obiettivi.
Per approfondire ulteriormente le tue competenze su AWS, esplora questi corsi:
Learn more about AWS with these courses!
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min

