
Leerpad
AWS Cloud Practitioner (CLF-C02)
10 Hr
Generatieve AI is de gamechanger in alle sectoren en stuwt de vooruitgang in natural language processing, computervisie en veel andere gebieden. Het benutten van het potentieel ging echter vaak gepaard met uitdagingen zoals kosten, complexe infrastructuur en steile leercurves. Daar komt AWS Bedrock om de hoek kijken: deze oplossing helpt blokkades op te heffen door je foundation models te laten gebruiken zonder dat je infrastructuur hoeft te beheren.
Deze tutorial is je complete gids voor Amazon Bedrock: wat het is, hoe het werkt en hoe jij het kunt gebruiken. Aan het einde beschik je over de kennis en vaardigheden om je eigen generatieve AI-toepassingen te ontwikkelen—schaalbaar, flexibel en afgestemd op jouw doelen.
Amazon Bedrock is een beheerde AWS-service voor toegang tot en beheer van foundation models (FM’s), de basisbouwstenen van generatieve AI van Amazon Web Services (AWS). Bedrock maakt het zo eenvoudig dat je je geen zorgen hoeft te maken over het inrichten van GPU’s, het configureren van modelpijplijnen of het beheren van andere infrastructuur.
AWS Bedrock is een toegangspoort tot innovatie. Het is een geïntegreerd platform waarmee ontwikkelaars geavanceerde AI-modellen van toonaangevende aanbieders zoals Anthropic, Stability AI en Amazon’s Titan kunnen verkennen, testen en implementeren.
Stel bijvoorbeeld dat je een klantenservicechatbot ontwikkelt. Met AWS Bedrock kun je een geavanceerd taalmodel kiezen, het afstemmen op de behoeften van je applicatie en het in je toepassing opnemen zonder ooit serverconfiguratie in code te hoeven schrijven.
De functies van AWS Bedrock zijn ontworpen om de weg van AI-concept naar productie te vereenvoudigen en te versnellen. Laten we ze in detail bekijken.
Een van de grootste voordelen van AWS Bedrock is de variëteit aan foundation models. Of je nu werkt aan teksttoepassingen, visuele content, of veilige en interpreteerbare AI, Bedrock heeft wat je nodig hebt. Enkele beschikbare modellen:
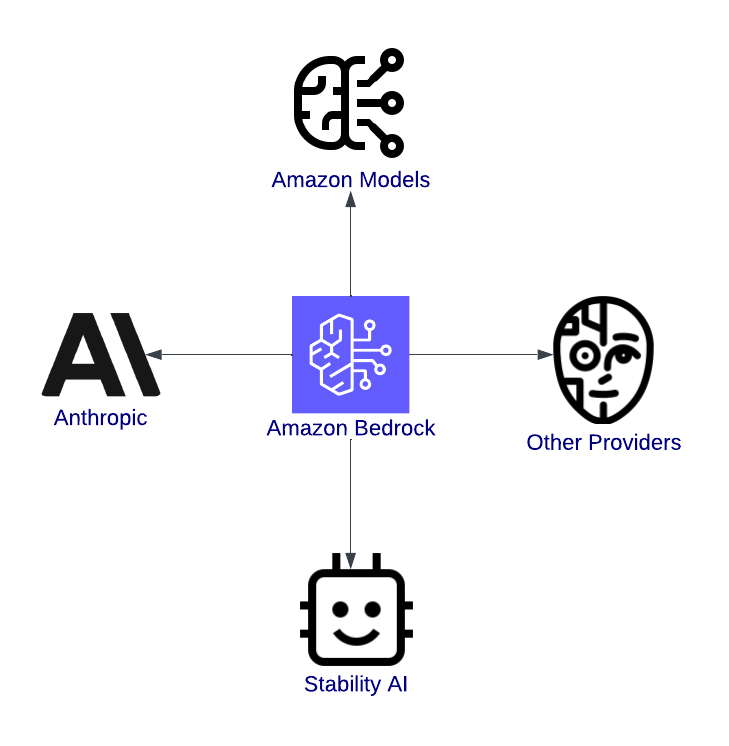
Overzicht van Amazon Bedrock, met de integratie met modellen.
AWS Bedrock abstraheert infrastructuurbeheer, wat betekent:
Generatieve AI-toepassingen hebben doorgaans een onvoorspelbare vraag. Een chatbot kan tijdens piekuren honderden gebruikers bedienen en ’s nachts slechts enkele. AWS Bedrock lost dit op met ingebouwde schaalbaarheid:
AWS Bedrock gaat verder dan alleen krachtige modellen bieden—het integreert met andere AWS-services om end-to-end AI-workflows te ondersteunen. Enkele integraties zijn:
Dit onderdeel leidt je door het instellen van de benodigde permissies, het aanmaken van een AWS-account en het starten met AWS Bedrock.
Als je er nog geen hebt, ga dan naar de aanmeldpagina van AWS en maak een account aan. Zorg er voor bestaande gebruikers voor dat je IAM-gebruiker beheerdersrechten heeft.

De AWS-aanmeldpagina, met verkenning van Free Tier-producten voor nieuwe accounts.
Als je op zoek bent naar gedetailleerde stappen, bezoek dan de officiële handleiding van AWS.
Amazon Bedrock is toegankelijk via de AWS Management Console. Volg deze stappen om het te vinden en te gebruiken:
Zoekresultaten in de AWS Management Console voor Bedrock.

Amazon Bedrock Providers-pagina met serverloze modelopties van Amazon.
Amazon Bedrock Chat/Text Playground-interface.
AWS Identity and Access Management (IAM) is cruciaal voor veilige toegang tot AWS Bedrock. Volg deze stappen om permissies te configureren:
AWS IAM Policy Editor in JSON-modus
{
"Version": "2012-10-17",
"Statement": [ {
"Sid": "BedrockFullAccess",
"Effect": "Allow",
"Action": ["bedrock:*"],
"Resource": "*"
}
]
}Opmerking: Het bovenstaande beleid kan worden gekoppeld aan elke role die toegang nodig heeft tot de Amazon Bedrock-service. Dat kan SageMaker zijn of een gebruiker. Wanneer je Amazon SageMaker gebruikt, is de execution role voor je notebook doorgaans een andere gebruiker of role dan die waarmee je inlogt op de AWS Management Console. Als je wilt ontdekken hoe je de Amazon Bedrock-service via de AWS Console gebruikt, zorg er dan voor dat je je Console-gebruiker of -role autoriseert. Je kunt de notebooks uitvoeren vanuit elke omgeving met toegang tot de AWS Bedrock-service en geldige referenties.
Generatieve AI-toepassingen zijn gebaseerd op foundation models die zijn afgestemd op een specifieke taak, zoals tekstgeneratie, beeldcreatie of datatransformatie. Hieronder vind je een stapsgewijze gids voor het kiezen van een foundation model, het uitvoeren van basisinferences en het aanpassen van modelantwoorden aan jouw behoeften.
Het kiezen van het juiste foundation model is belangrijk en hangt af van wat je project nodig heeft. Zo maak je een keuze:
1. Bepaal je use-case:
2. Beoordeel modelcapaciteiten:
Voordat je deze modellen gebruikt, moet je modeltoegang inschakelen binnen je AWS-account. Zo stel je het in:
Pagina voor beheer van modeltoegang in Amazon Bedrock.
Volg deze stappen om inference uit te voeren met een geselecteerd foundation model in AWS Bedrock:
pip install boto3import boto3
import json
from botocore.exceptions import ClientError
# Set the AWS Region
region = "us-east-1"
# Initialize the Bedrock Runtime client
client = boto3.client("bedrock-runtime", region_name=region)# Define the model ID for Amazon Titan Express v1
model_id = "amazon.titan-text-express-v1"
# Define the input prompt
prompt = """
Command: Compose an email from Tom, Customer Service Manager, to the customer "Nancy"
who provided negative feedback on the service provided by our customer support
Engineer"""# Configure inference parameters
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512, # Limit the response length
"temperature": 0.5, # Control the randomness of the output
},
}
# Convert the request payload to JSON
request_payload = json.dumps(inference_parameters)try:
# Invoke the model
response = client.invoke_model(
modelId=model_id,
body=request_payload,
contentType="application/json",
accept="application/json"
)
# Decode the response body
response_body = json.loads(response["body"].read())
# Extract and print the generated text
generated_text = response_body["results"][0]["outputText"]
print("Generated Text:\n", generated_text)
except ClientError as e:
print(f"ClientError: {e.response['Error']['Message']}")
except Exception as e:
print(f"An error occurred: {e}")Opmerking: Je kunt de volledige code direct openen en kopiëren vanuit de GitHub Gist.
Je kunt ongeveer onderstaande output verwachten:
% python3 main.py
Generated Text:
Tom:
Nancy,
I am writing to express my sincere apologies for the negative experience you had with our customer support engineer. It is unacceptable that we did not meet your expectations, and I want to assure you that we are taking steps to prevent this from happening in the future.
Sincerely,
Tom
Customer Service ManagerOm het gedrag van de modeloutput te fine-tunen, kun je parameters aanpassen zoals temperature en maxTokenCount:
temperature: Deze parameter bepaalt de willekeur van de output. Lagere waarden maken de output meer vastberaden, hogere waarden verhogen de variatie.MaxTokenCount: Stelt de maximale lengte van de gegenereerde output in.Bijvoorbeeld:
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 256, # Limit the response length
"temperature": 0.7, # Control the randomness of the output
},
}Door deze parameters aan te passen, kun je de creativiteit en lengte van de gegenereerde content beter afstemmen op de behoeften van je applicatie.
Laten we schakelen naar twee geavanceerde benaderingen: AI verbeteren met Retrieval-Augmented Generation (RAG) en modellen op schaal beheren en implementeren.
RAG vereist een knowledge base. Voordat je de knowledge base in Amazon Bedrock instelt, moet je een S3-bucket maken en de benodigde bestanden uploaden. Volg deze stappen:
Stap 2: Upload bestanden naar de S3-bucket
octank_financial_10K.pdf.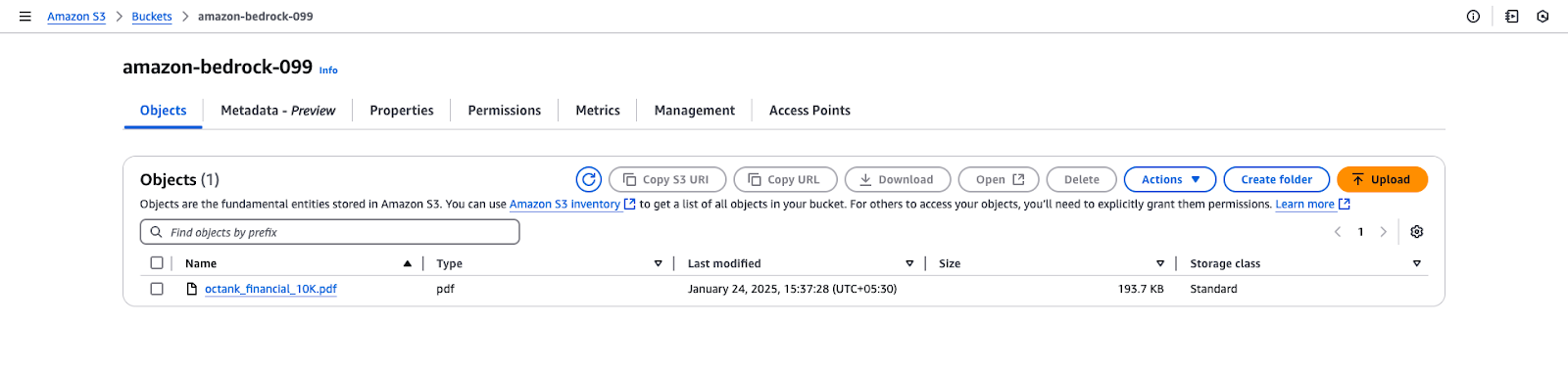
Amazon S3-bucketweergave voor "amazon-bedrock-099".
Amazon Bedrock laat je een knowledge base maken die wordt ondersteund door vectordatabases. De volgende stappen leiden je door het aanmaken van een knowledge base, het configureren van een gegevensbron en het selecteren van embeddings en vectorstores.
knowledge-base-quick-start).AmazonBedrockExecutionRoleForKnowledgeBase.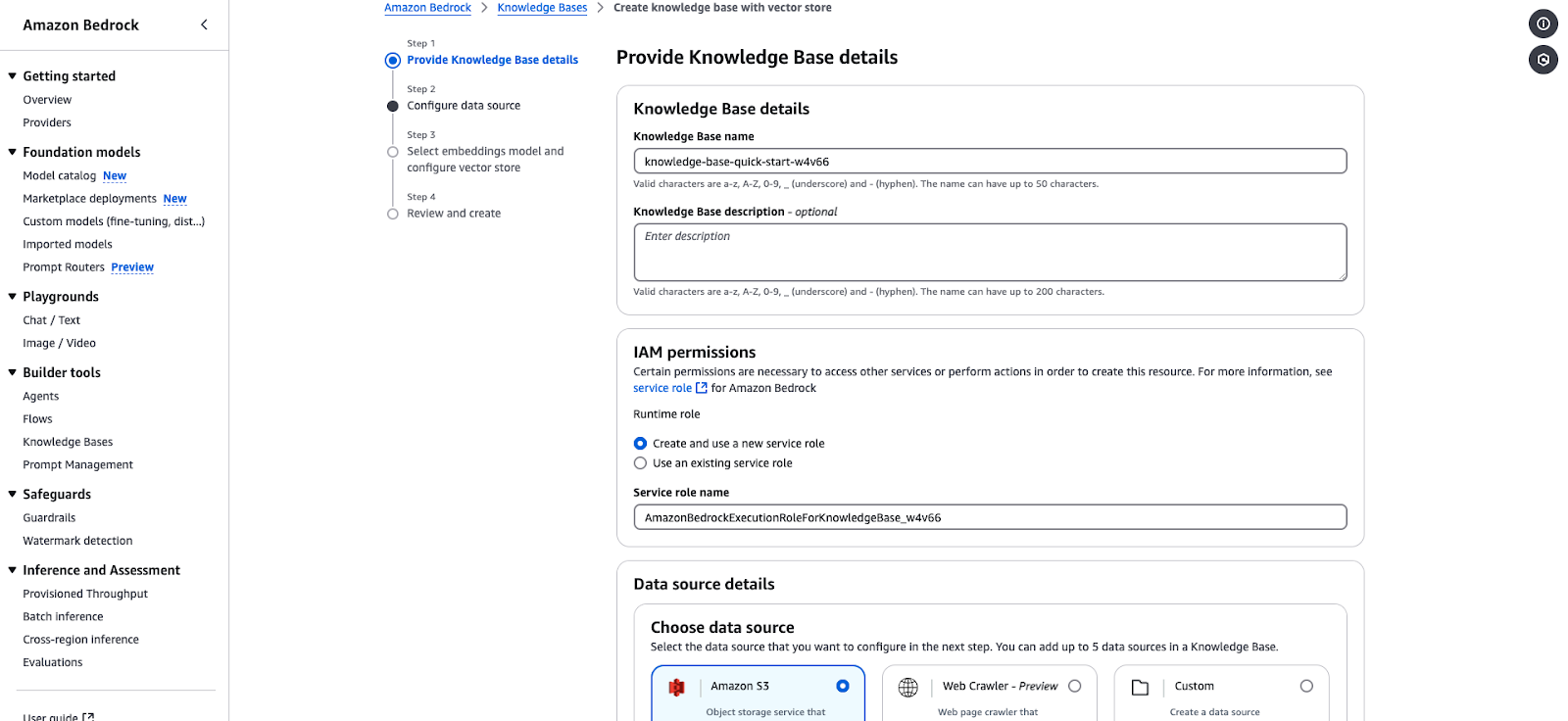
Wizard voor het aanmaken van een Amazon Bedrock Knowledge Base.
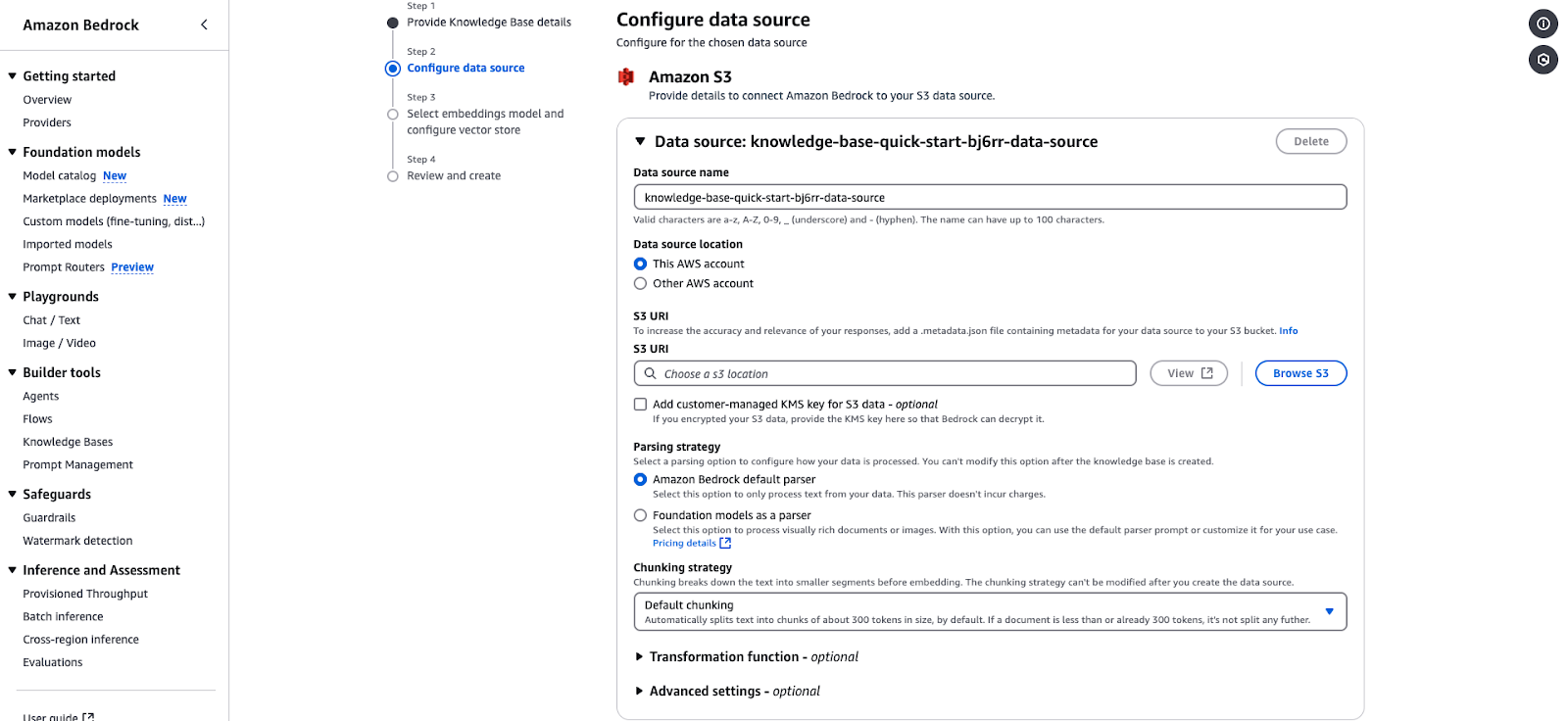
Configuratiepagina voor Amazon Bedrock-gegevensbron voor integratie van een S3-gebaseerde knowledge base.
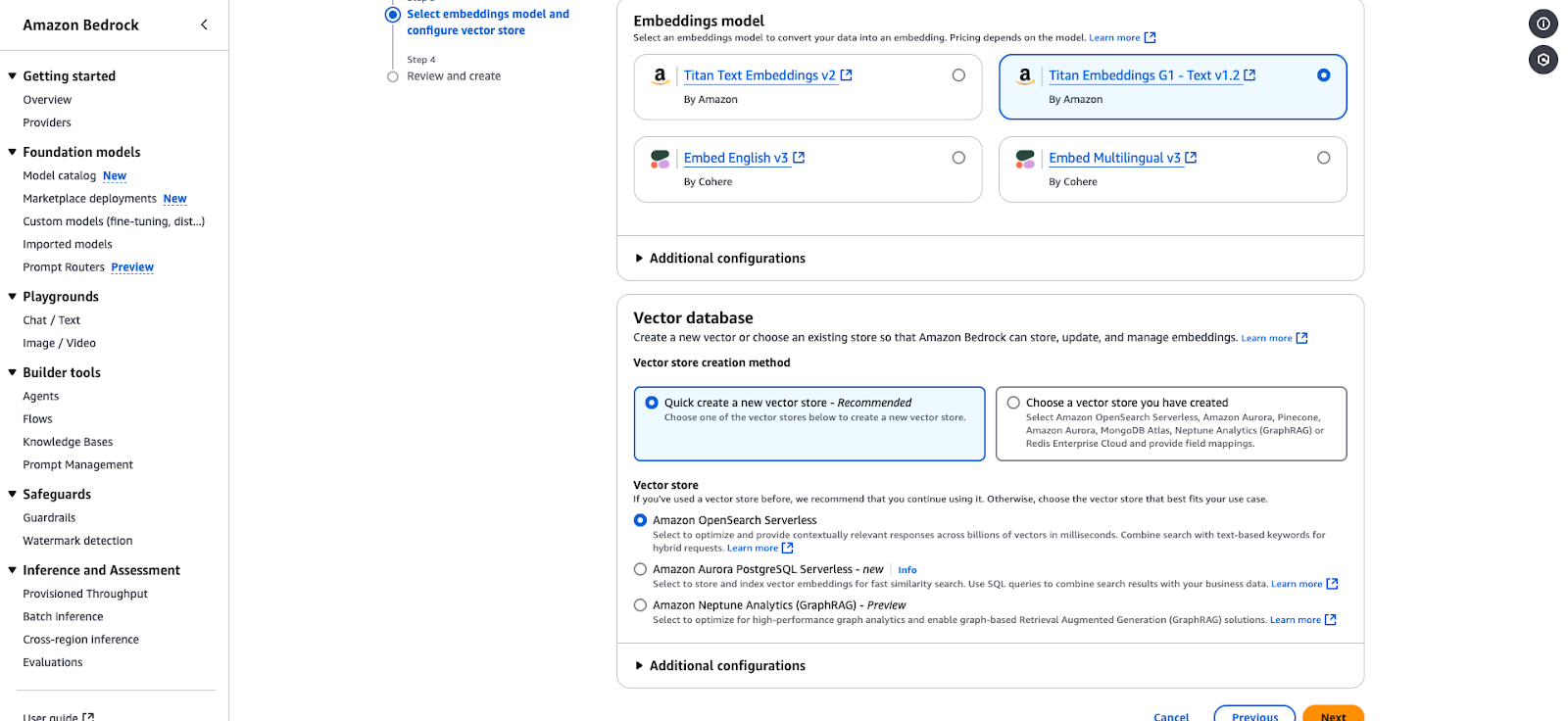
Configuratiepagina van Amazon Bedrock voor het selecteren van een embeddingmodel en vectorstore.
knowledge-base-quick-start).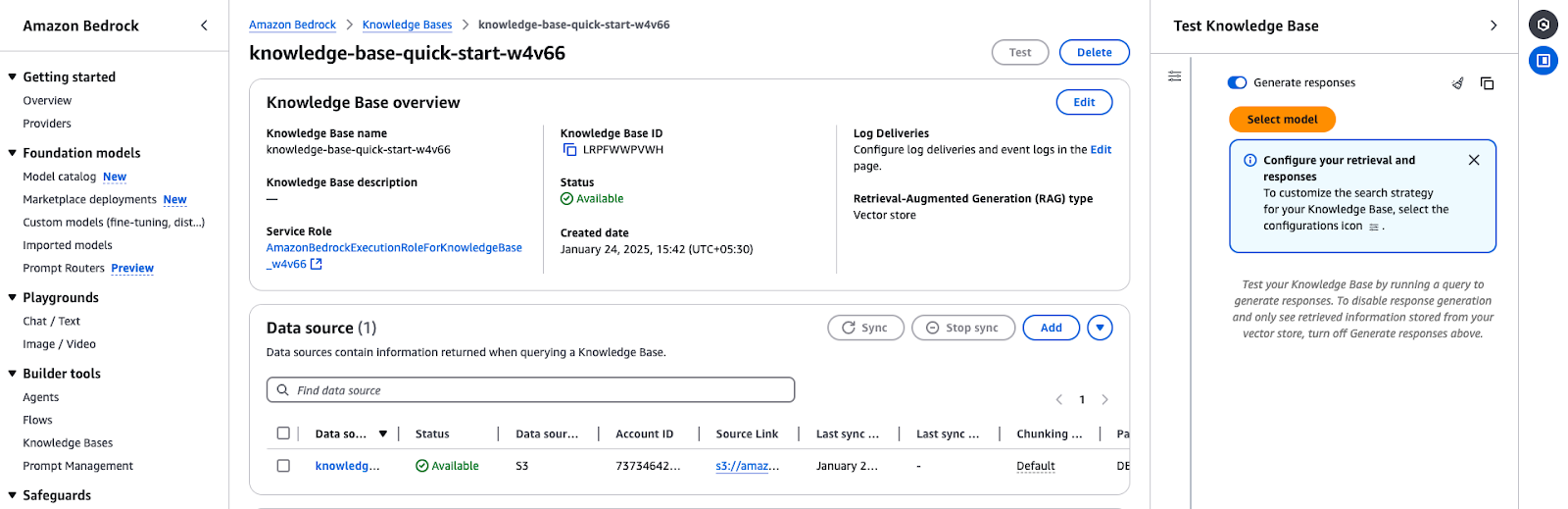
Overzicht van Amazon Bedrock Knowledge Base toont configuratiedetails en status van gegevensbronnen.
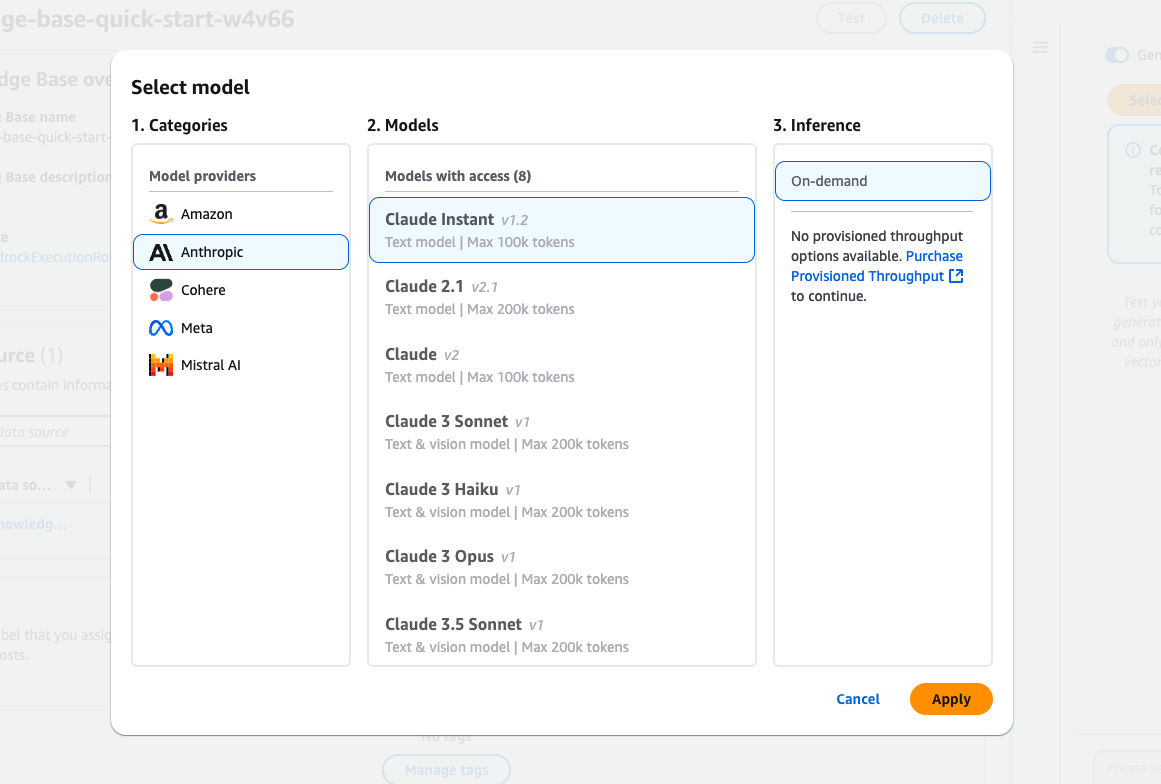
Modelselectie-interface in Amazon Bedrock met diverse Claude-modellen van Anthropic.
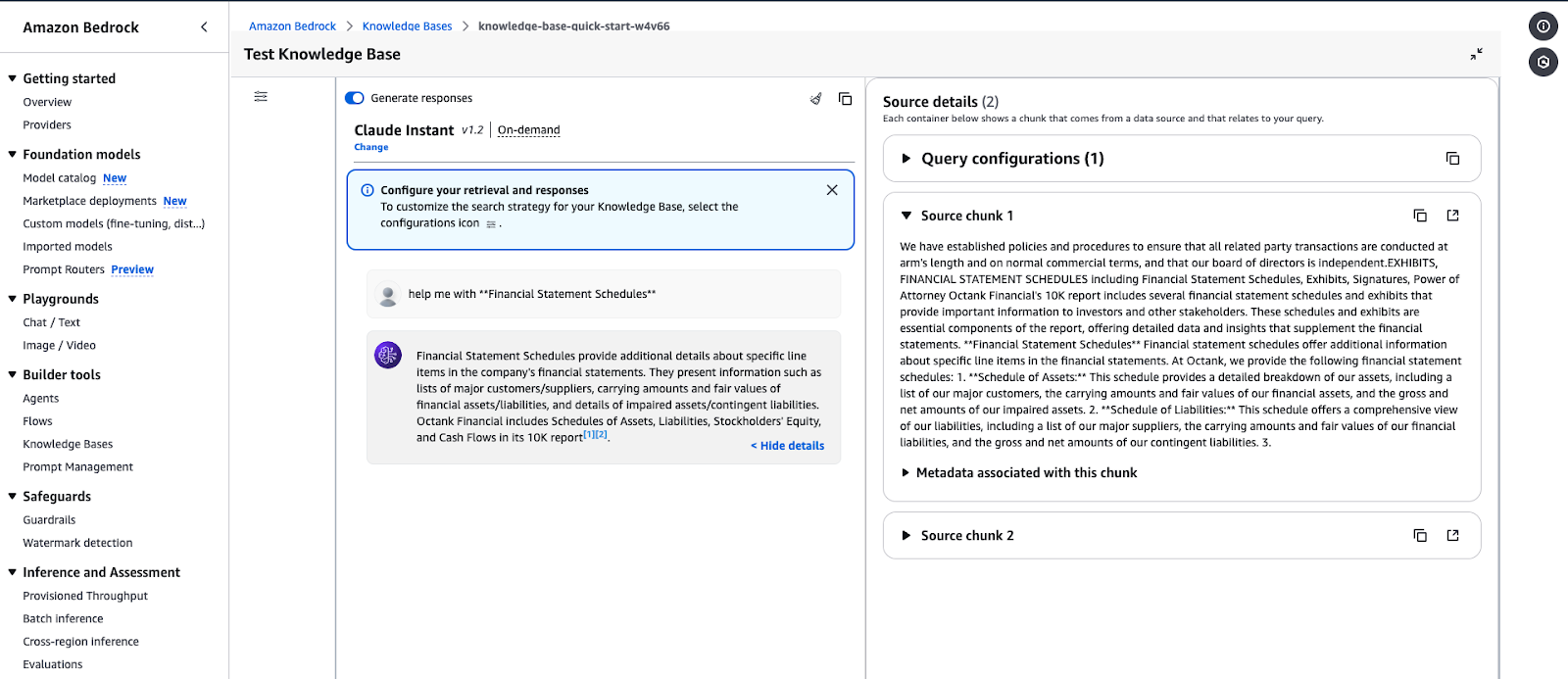
Testinterface voor Amazon Bedrock Knowledge Base met een antwoord op een query.
Voorbeeld van een query-output:
Met AWS-services zoals Lambda kan Amazon Bedrock AI-modellen op schaal beheren en implementeren. Deze kostenefficiënte aanpak zorgt voor hoge beschikbaarheid en schaalt automatisch voor AI-gedreven applicaties.
In dit onderdeel gebruiken we AWS Lambda om een Bedrock-model dynamisch aan te roepen zodat je prompts on demand kunt verwerken.
Pagina voor het aanmaken van een AWS Lambda-functie.
{
"prompt": "Write a formal apology letter for a late delivery."
}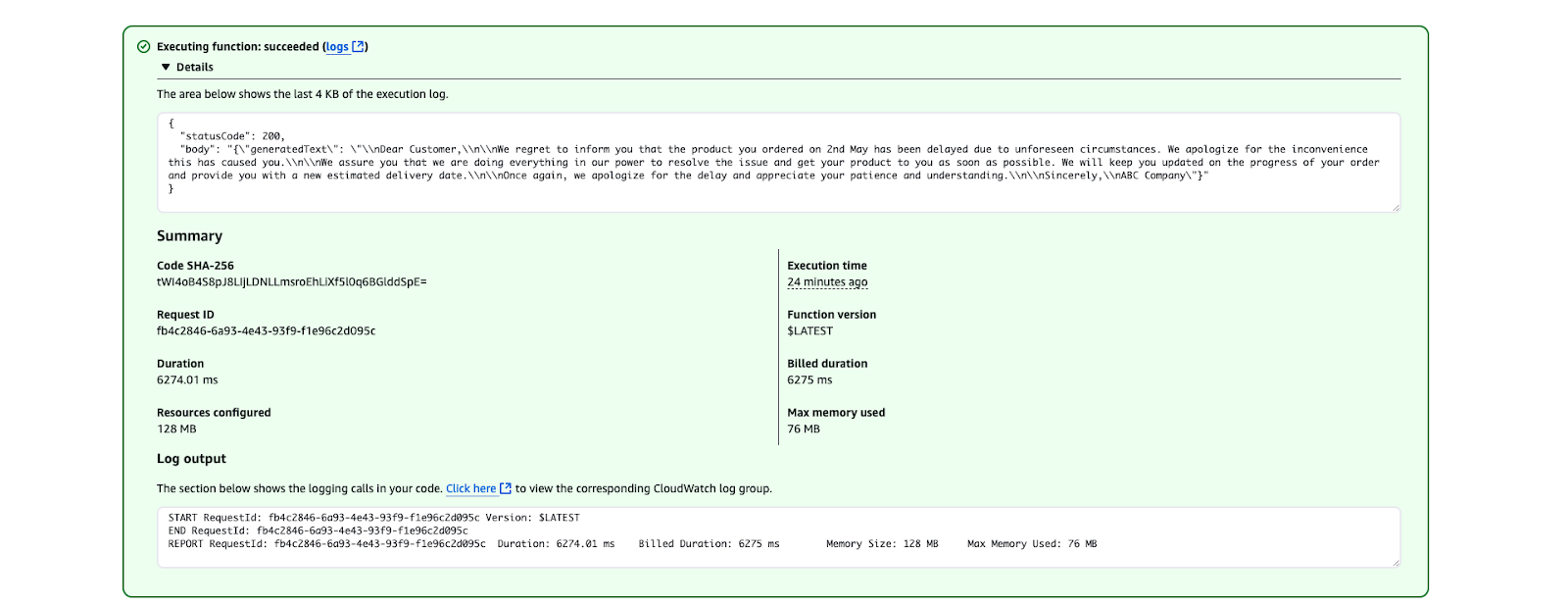
AWS Lambda-uitvoeringsresultaat met een succesvolle functierun.
Optimaliseer kosten:
Beveilig de Lambda-functie:
Monitor en log:
In dit onderdeel deel ik enkele best practices voor het werken met Amazon Bedrock, van kostenoptimalisatie tot het waarborgen van veiligheid en nauwkeurigheid.
Kosten beheren in AWS Bedrock kan inhouden dat je Amazon SageMaker benut om modellen te implementeren en Spot-instances te gebruiken om tot 90% te besparen. Dit zijn enkele van mijn best practices:
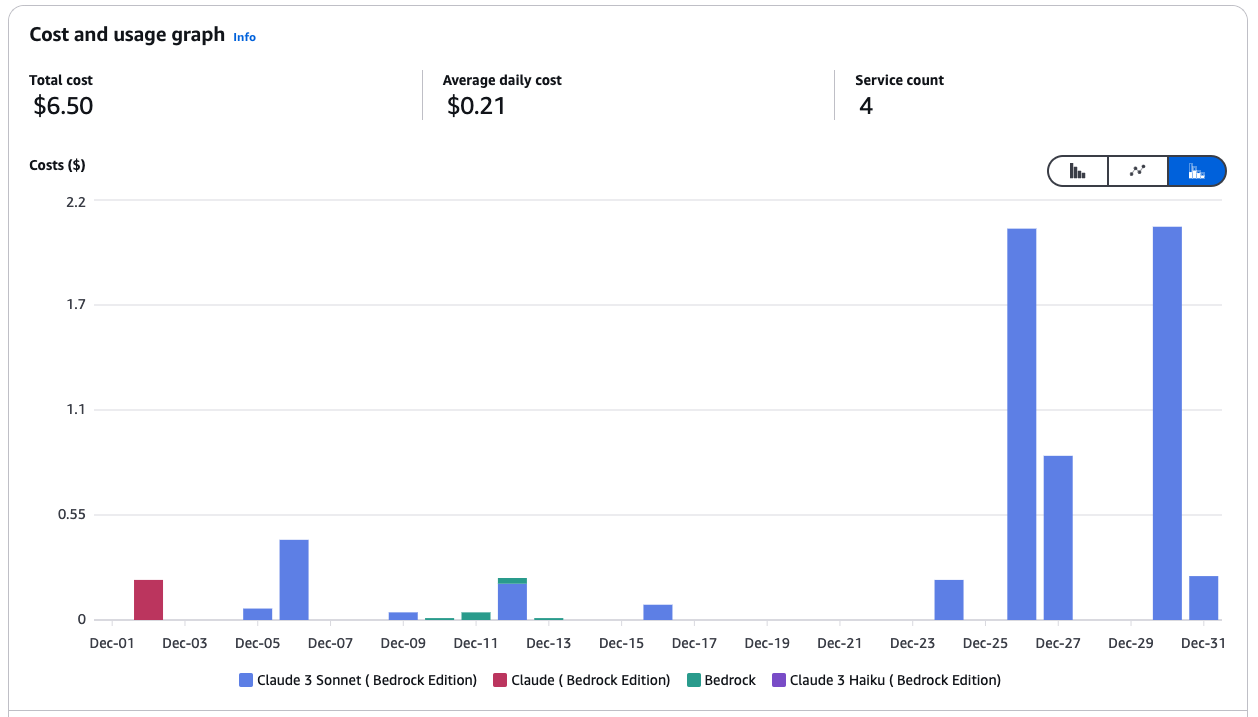
Kosten- en gebruiksgrafiek voor Amazon Bedrock-services.
from sagemaker.mxnet import MXNet
# Use spot instances for cost efficiency
use_spot_instances = True
# Maximum runtime for the training job (in seconds)
max_run = 600
# Maximum wait time for Spot instance availability (in seconds); set only if using Spot instances
max_wait = 1200 if use_spot_instances else None
# Define the MXNet estimator for the training job
mnist_estimator = MXNet(
entry_point='source_dir/mnist.py', # Path to the script that contains the model training code
role=role, # IAM role used for accessing AWS resources (e.g., S3, SageMaker)
output_path=model_artifacts_location, # S3 location to save the trained model artifacts
code_location=custom_code_upload_location, # S3 location to upload the training script
instance_count=1, # Number of instances to use for training
instance_type='ml.m4.xlarge', # Instance type for the training job
framework_version='1.6.0', # Version of the MXNet framework to use
py_version='py3', # Python version for the environment
distribution={'parameter_server': {'enabled': True}}, # Enable distributed training with a parameter server
hyperparameters={ # Training hyperparameters
'learning-rate': 0.1, # Learning rate for the training job
'epochs': 5 # Number of training epochs
},
use_spot_instances=use_spot_instances, # Enable Spot instances for cost savings
max_run=max_run, # Maximum runtime for the training job
max_wait=max_wait, # Maximum wait time for Spot instance availability
checkpoint_s3_uri=checkpoint_s3_uri # S3 URI for saving intermediate checkpoints
)
# Start the training job and specify the locations of training and testing datasets
mnist_estimator.fit({
'train': train_data_location, # S3 location of the training dataset
'test': test_data_location # S3 location of the testing/validation dataset
})
AWS CloudWatch-logs
Om de veiligheid, compliance en prestaties van Amazon Bedrock te waarborgen, is het belangrijk best practices te volgen. Dit zijn mijn aanbevelingen:
Zekerstellen dat modellen nauwkeurig, betrouwbaar en afgestemd op bedrijfsdoelen zijn, bereik je door modellen te monitoren en te evalueren. Enkele best practices:
Het metricsdashboard toont het aantal aanroepen, latency en tokenaantallen voor diverse modellen in Amazon Bedrock.
AWS Bedrock verandert de manier waarop generatieve AI-toepassingen worden ontwikkeld en biedt een gecentraliseerd platform om foundation models te gebruiken zonder je zorgen te maken over de infrastructuur.
Met deze stapsgewijze tutorial kun je de juiste modellen identificeren, veilige en schaalbare workflows creëren en functies zoals retrieval-augmented generation (RAG) integreren voor meer maatwerk. Met best practices voor kosten, beveiliging en monitoring ben je klaar om AI-oplossingen te ontwikkelen en te beheren die aan je doelstellingen voldoen.
Wil je je AWS-expertise verder verdiepen? Bekijk dan deze cursussen:
Leer meer over AWS met deze cursussen!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
