
Lernpfad
AWS Cloud Practitioner (CLF-C02)
10 Std.
Generative KI hat sich zum Disruptor in allen Sektoren entwickelt und treibt den Fortschritt in der Verarbeitung natürlicher Sprache, der Computer Vision und vielen anderen Bereichen voran. Die Nutzung dieses Potenzials ist jedoch oft mit Herausforderungen wie Kosten, komplexer Infrastruktur und steilen Lernkurven verbunden. Hier kommt AWS Bedrock ins Spiel - diese Lösung hilft, die Blockade zu lösen, indem sie es dir ermöglicht, Basismodelle zu nutzen, ohne die Infrastruktur verwalten zu müssen.
Dieses Tutorial soll dein vollständiger Leitfaden für Amazon Bedrock sein. Es beschreibt, was es ist, wie es funktioniert und wie du es nutzen kannst. Am Ende dieses Leitfadens hast du die Informationen und Fähigkeiten, die du brauchst, um deine eigenen generativen KI-Anwendungen zu entwickeln - skalierbar, flexibel und auf deine Ziele ausgerichtet.
Amazon Bedrock ist ein verwalteter AWS-Service für den Zugriff auf und die Verwaltung von Foundation Models (FMs), den Grundbausteinen der generativen KI von Amazon Web Services (AWS). Bedrock macht alles so einfach, dass du dich nicht um die Bereitstellung von GPUs, die Konfiguration von Modellpipelines oder die Verwaltung anderer Infrastrukturen kümmern musst.
AWS Bedrock ist ein Tor zur Innovation. Es ist eine einheitliche Plattform, die es Entwicklern ermöglicht, modernste KI-Modelle von führenden Anbietern wie Anthropic, Stability AI und Amazon's Titan zu erforschen, zu testen und einzusetzen.
Stell dir zum Beispiel vor, du entwickelst einen Chatbot für den Kundensupport. Mit AWS Bedrock kannst du ein ausgeklügeltes Sprachmodell auswählen, es auf die Bedürfnisse deiner Anwendung abstimmen und in deine Anwendung einbetten, ohne jemals eine Serverkonfiguration in Code schreiben zu müssen.
Die Funktionen von AWS Bedrock wurden entwickelt, um den Weg vom KI-Konzept zur Produktion zu vereinfachen und zu beschleunigen. Wir wollen sie im Detail aufschlüsseln.
Einer der wichtigsten Vorteile von AWS Bedrock ist die Vielfalt der verfügbaren Gründungsmodelle. Egal, ob du an Textanwendungen, visuellen Inhalten oder sicherer und interpretierbarer KI arbeitest, Bedrock hat dich im Griff. Hier sind einige der verfügbaren Modelle:
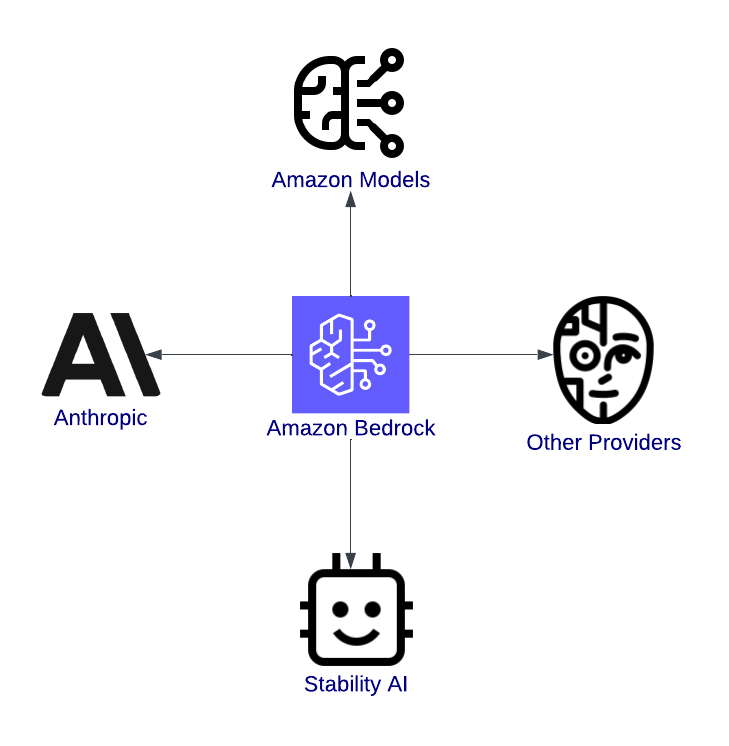
Überblick über Amazon Bedrock mit Schwerpunkt auf der Integration mit Modellen.
AWS Bedrock abstrahiert das Infrastrukturmanagement, was bedeutet:
Generative KI-Anwendungen haben in der Regel einen unvorhersehbaren Bedarf. Ein Chatbot kann zu Stoßzeiten Hunderten von Nutzern antworten und nachts nur einigen wenigen. Aber AWS Bedrock löst dieses Problem mit seiner eingebauten Skalierbarkeit:
AWS Bedrock bietet nicht nur leistungsstarke Modelle, sondern lässt sich auch in andere AWS-Services integrieren, um durchgängige KI-Workflows zu unterstützen. Einige Integrationen umfassen:
Dieser Abschnitt führt dich durch die Einrichtung der erforderlichen Berechtigungen, die Erstellung eines AWS-Kontos und die ersten Schritte mit AWS Bedrock.
Wenn du noch kein Konto hast, kannst du dich auf der AWS-Anmeldeseite anmelden und ein Konto erstellen. Bei bestehenden Benutzern musst du sicherstellen, dass dein IAM-Benutzer über Administratorrechte verfügt.

Die AWS-Anmeldeseite, auf der du die Free Tier-Produkte für neue Konten erkunden kannst.
Wenn du nach detaillierten Schritten suchst, besuche bitte die offizielle AWS-Anleitung.
Amazon Bedrock ist über die AWS Management Console zugänglich. Folge diesen Schritten, um sie zu finden und zu benutzen:
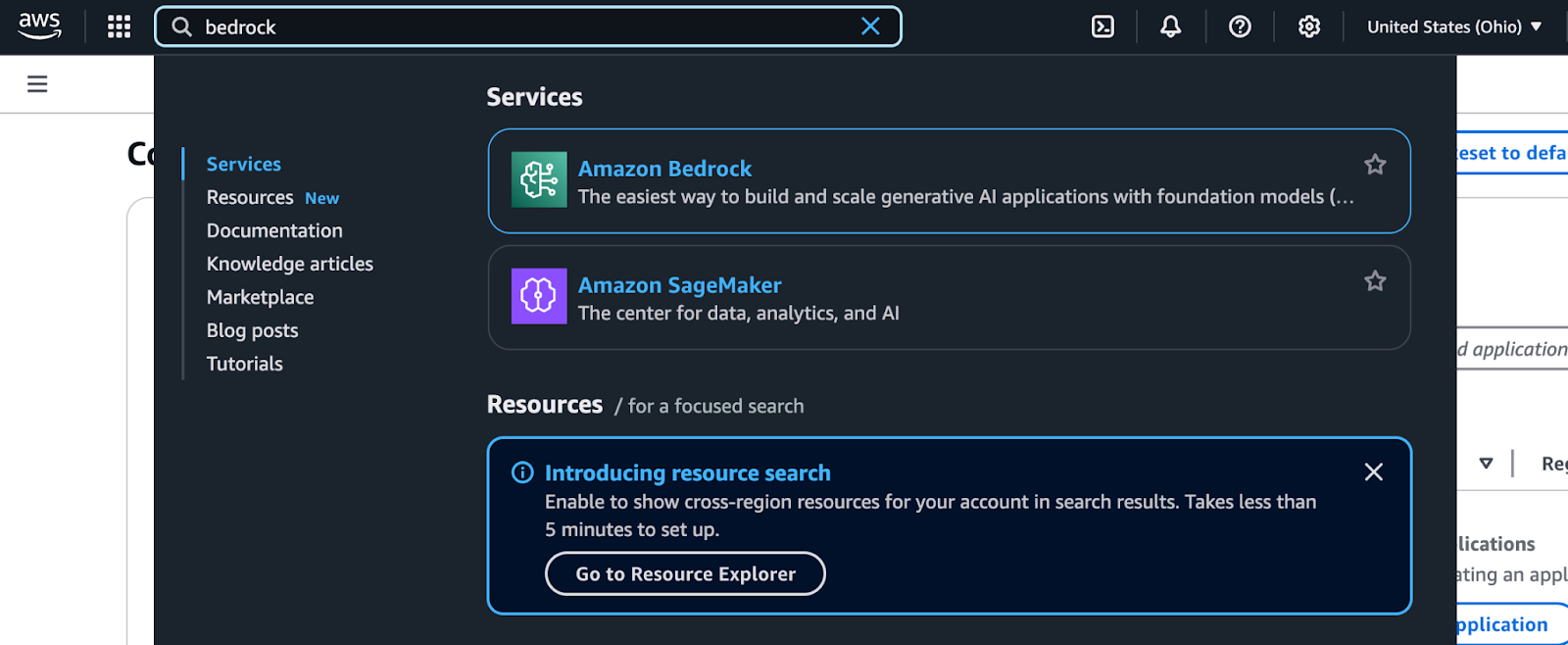
AWS Management Console Suchergebnisse für Bedrock.

Amazon Bedrock Providers Seite, die die Serverless-Modelle von Amazon vorstellt.
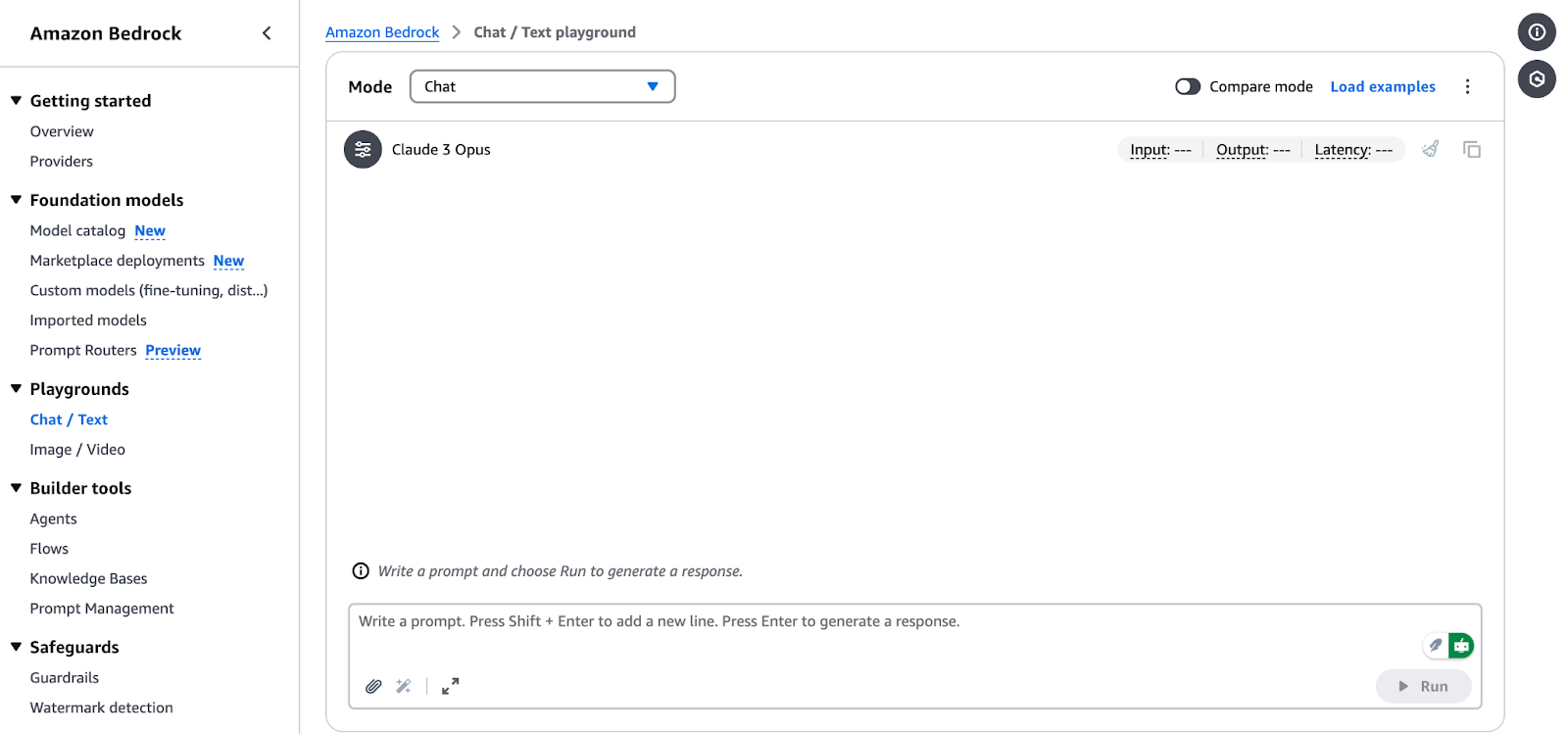
Amazon Bedrock Chat/Text Playground Schnittstelle.
Das AWS Identitäts- und Zugriffsmanagement (IAM) ist entscheidend für den sicheren Zugriff auf AWS Bedrock. Befolge diese Schritte, um die Berechtigungen zu konfigurieren:
AWS IAM Policy Editor im JSON-Modus
{
"Version": "2012-10-17",
"Statement": [ {
"Sid": "BedrockFullAccess",
"Effect": "Allow",
"Action": ["bedrock:*"],
"Resource": "*"
}
]
}Hinweis: Die obige Richtlinie kann an jede Rolle angehängt werden, die auf den Amazon Bedrock Service zugreifen muss. Das kann SageMaker oder ein Benutzer sein. Wenn du Amazon SageMaker verwendest, ist die Ausführungsrolle für dein Notebook in der Regel ein anderer Benutzer oder eine andere Rolle als die, die du für die Anmeldung an der AWS Management Console verwendest. Um herauszufinden, wie du den Amazon Bedrock Service mit der AWS Console erkunden kannst, stelle sicher, dass du deinen Console-Benutzer oder deine Rolle autorisierst. Du kannst die Notebooks von jeder Umgebung aus ausführen, die Zugriff auf den AWS Bedrock Service und gültige Anmeldedaten hat.
Generative KI-Anwendungen basieren auf Grundmodellen, die auf eine bestimmte Aufgabe abgestimmt sind, wie z.B. Texterstellung, Bilderzeugung oder Datentransformation. Im Folgenden findest du eine Schritt-für-Schritt-Anleitung, wie du ein Basismodell auswählst, grundlegende Schlussfolgerungen ziehst und die Antworten des Modells an deine Bedürfnisse anpasst.
Die Wahl des richtigen Gründungsmodells ist wichtig, denn sie hängt davon ab, was dein Projekt braucht. Hier erfährst du, wie du eine Auswahl treffen kannst:
1. Identifiziere deinen Anwendungsfall:
2. Beurteile die Fähigkeiten des Modells:
Bevor du diese Modelle nutzen kannst, musst du den Modellzugriff in deinem AWS-Konto aktivieren. Hier sind die Schritte, um es einzurichten:
Amazon Bedrock Model Access Management Seite.
Um ein ausgewähltes Gründungsmodell in AWS Bedrock zu verwenden, befolge diese Schritte:
pip install boto3import boto3
import json
from botocore.exceptions import ClientError
# Set the AWS Region
region = "us-east-1"
# Initialize the Bedrock Runtime client
client = boto3.client("bedrock-runtime", region_name=region)# Define the model ID for Amazon Titan Express v1
model_id = "amazon.titan-text-express-v1"
# Define the input prompt
prompt = """
Command: Compose an email from Tom, Customer Service Manager, to the customer "Nancy"
who provided negative feedback on the service provided by our customer support
Engineer"""# Configure inference parameters
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512, # Limit the response length
"temperature": 0.5, # Control the randomness of the output
},
}
# Convert the request payload to JSON
request_payload = json.dumps(inference_parameters)try:
# Invoke the model
response = client.invoke_model(
modelId=model_id,
body=request_payload,
contentType="application/json",
accept="application/json"
)
# Decode the response body
response_body = json.loads(response["body"].read())
# Extract and print the generated text
generated_text = response_body["results"][0]["outputText"]
print("Generated Text:\n", generated_text)
except ClientError as e:
print(f"ClientError: {e.response['Error']['Message']}")
except Exception as e:
print(f"An error occurred: {e}")Hinweis: Du kannst den kompletten Code direkt von der GitHub Gist.
Du kannst die folgende Ausgabe erwarten:
% python3 main.py
Generated Text:
Tom:
Nancy,
I am writing to express my sincere apologies for the negative experience you had with our customer support engineer. It is unacceptable that we did not meet your expectations, and I want to assure you that we are taking steps to prevent this from happening in the future.
Sincerely,
Tom
Customer Service ManagerUm das Verhalten der Modellausgabe fein abzustimmen, kannst du Parameter wie temperature und maxTokenCount anpassen:
temperature: Dieser Parameter steuert die Zufälligkeit der Ausgabe. Niedrigere Werte erhöhen die Bestimmtheit des Outputs und höhere Werte erhöhen die Variabilität.MaxTokenCount: Legt die maximale Länge der erzeugten Ausgabe fest.Zum Beispiel:
inference_parameters = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 256, # Limit the response length
"temperature": 0.7, # Control the randomness of the output
},
}Indem du diese Parameter anpasst, kannst du die Kreativität und Länge der generierten Inhalte besser an die Bedürfnisse deiner Anwendung anpassen.
Schalten wir einen Gang höher und konzentrieren uns auf zwei fortschrittliche Ansätze: die Verbesserung der KI durch Retrieval-Augmented Generation (RAG) und die Verwaltung und Bereitstellung von Modellen in großem Maßstab.
Die RAG verlangt, dass wir eine Wissensbasis haben. Bevor du die Wissensdatenbank in Amazon Bedrock einrichtest, musst du einen S3-Bucket erstellen und die erforderlichen Dateien hochladen. Befolge diese Schritte:
Schritt 2: Dateien in den S3-Bucket hochladen
octank_financial_10K.pdf aus.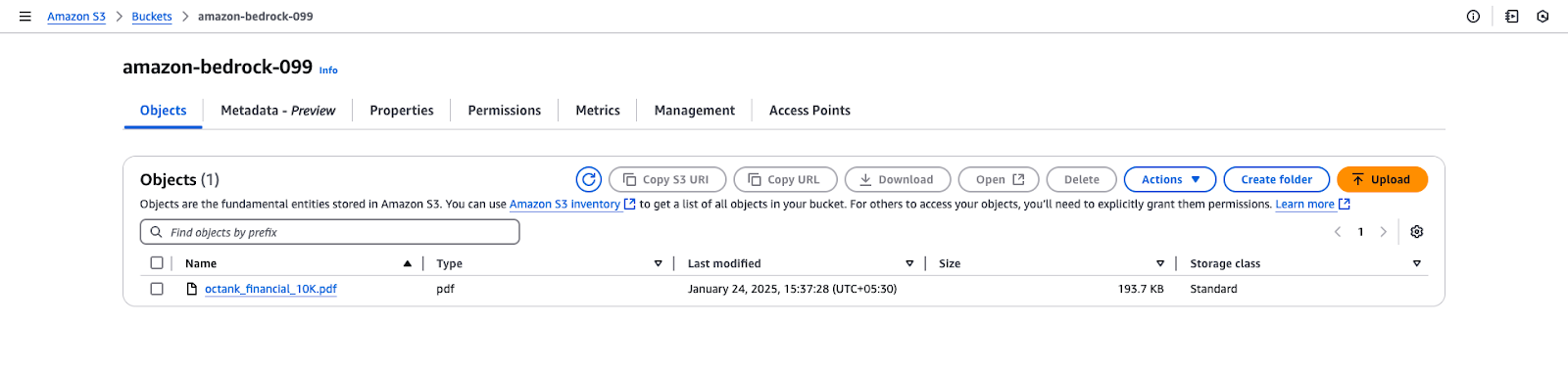
Amazon S3 Bucket View für "amazon-bedrock-099".
Mit Amazon Bedrock kannst du eine Wissensdatenbank erstellen, die auf Vektordatenbanken basiert. Die folgenden Schritte führen dich durch das Erstellen einer Wissensdatenbank, das Konfigurieren einer Datenquelle und das Auswählen von Einbettungen und Vektorspeichern.
knowledge-base-quick-start).AmazonBedrockExecutionRoleForKnowledgeBase.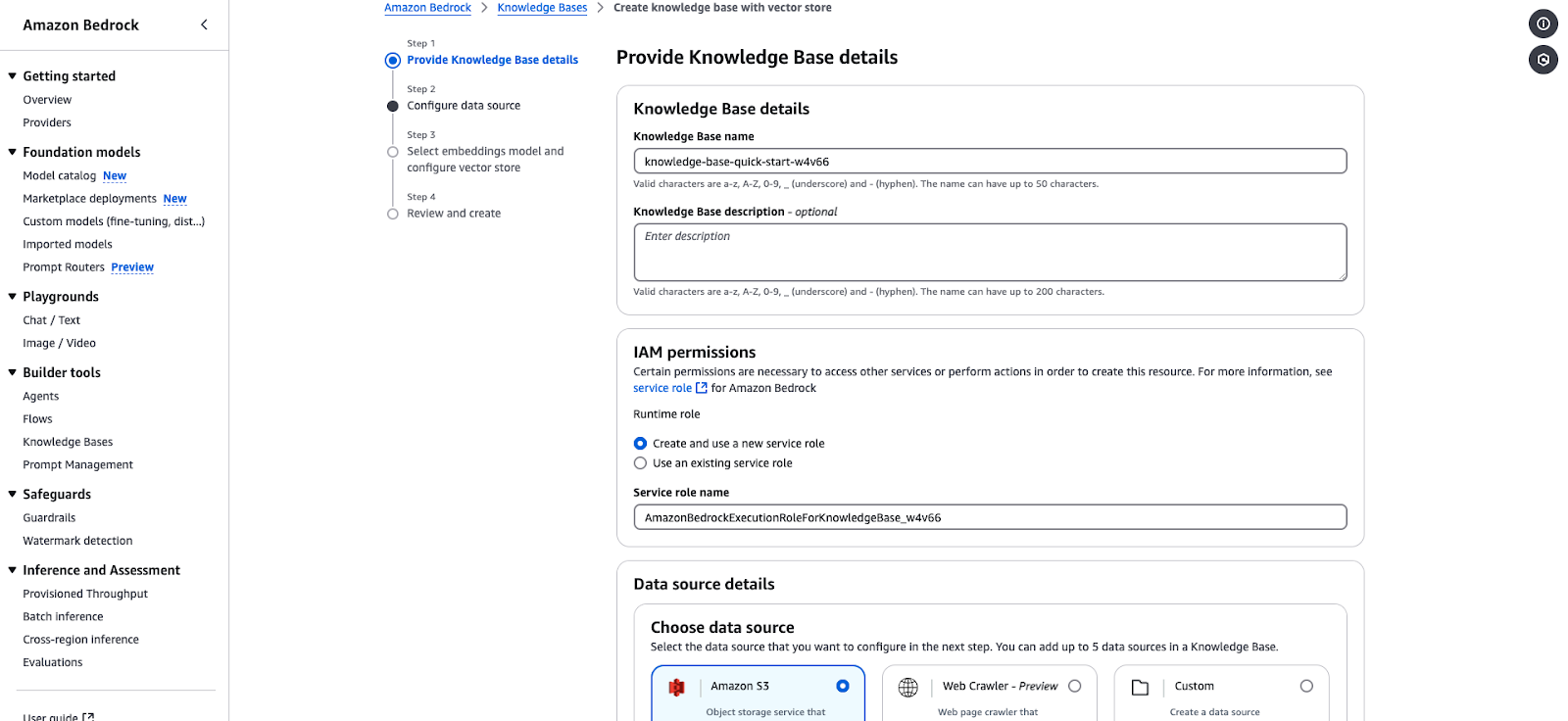
Assistent zur Erstellung der Amazon Bedrock Knowledge Base.
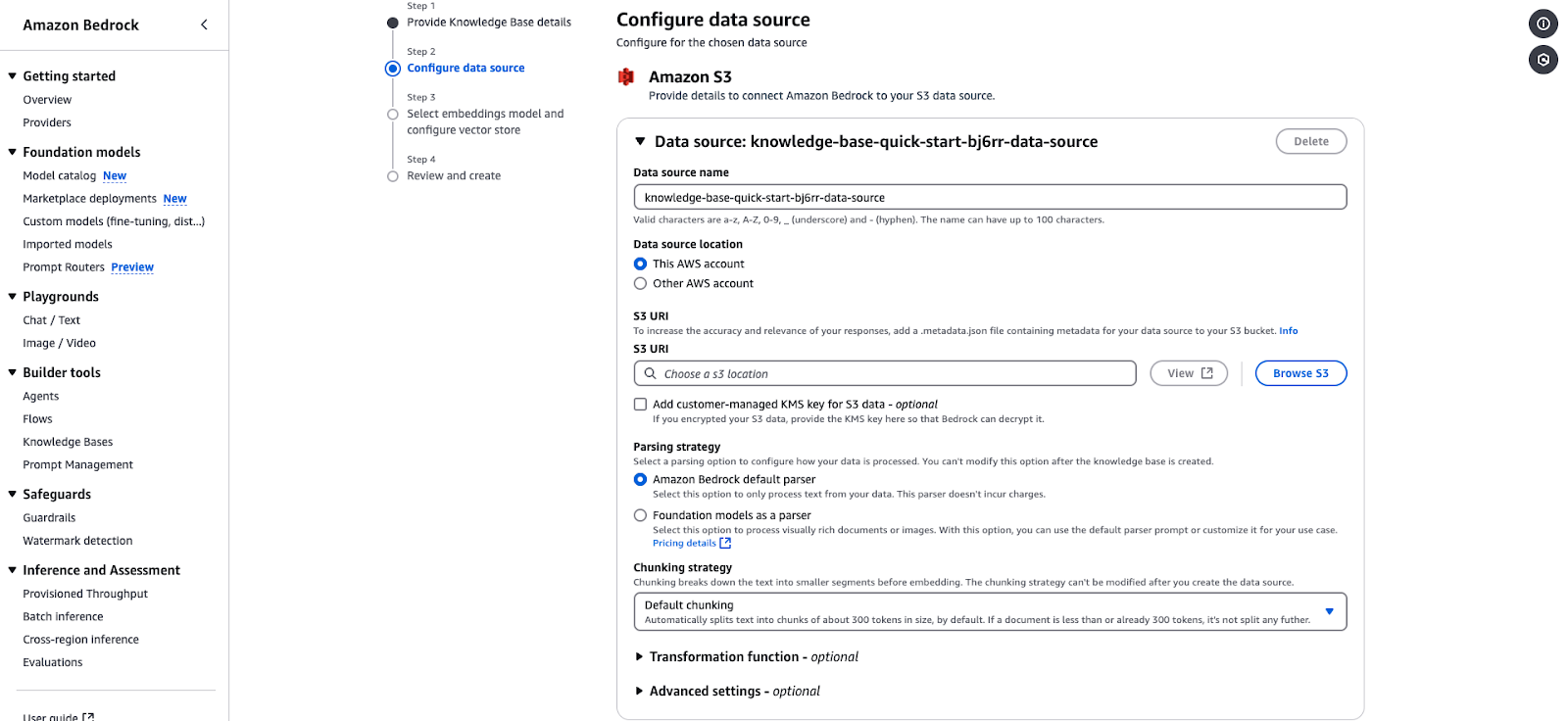
Amazon Bedrock Datenquellen-Konfigurationsseite für die Integration einer S3-basierten Wissensdatenbank.
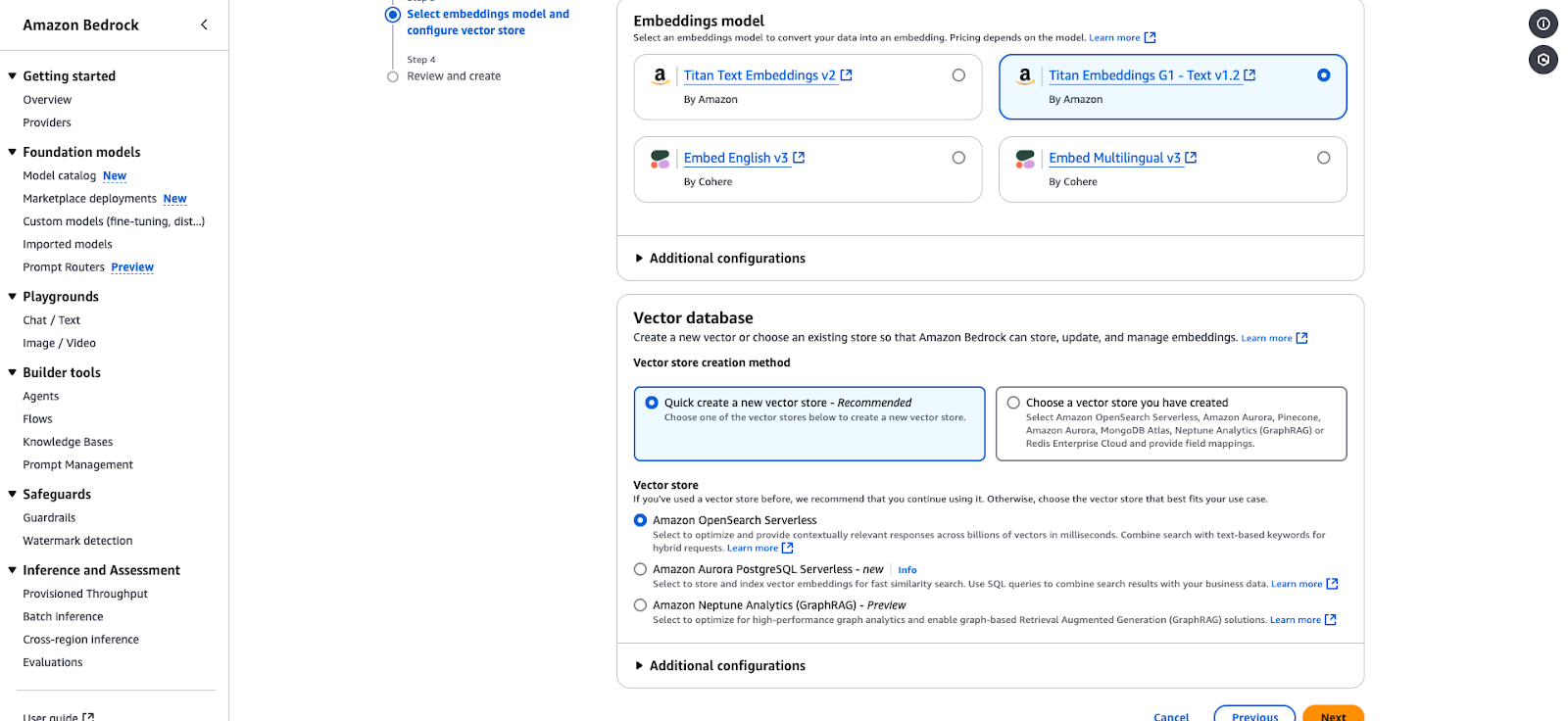
Amazon Bedrock Konfigurationsseite zur Auswahl eines Einbettungsmodells und eines Vektorspeichers.
knowledge-base-quick-start).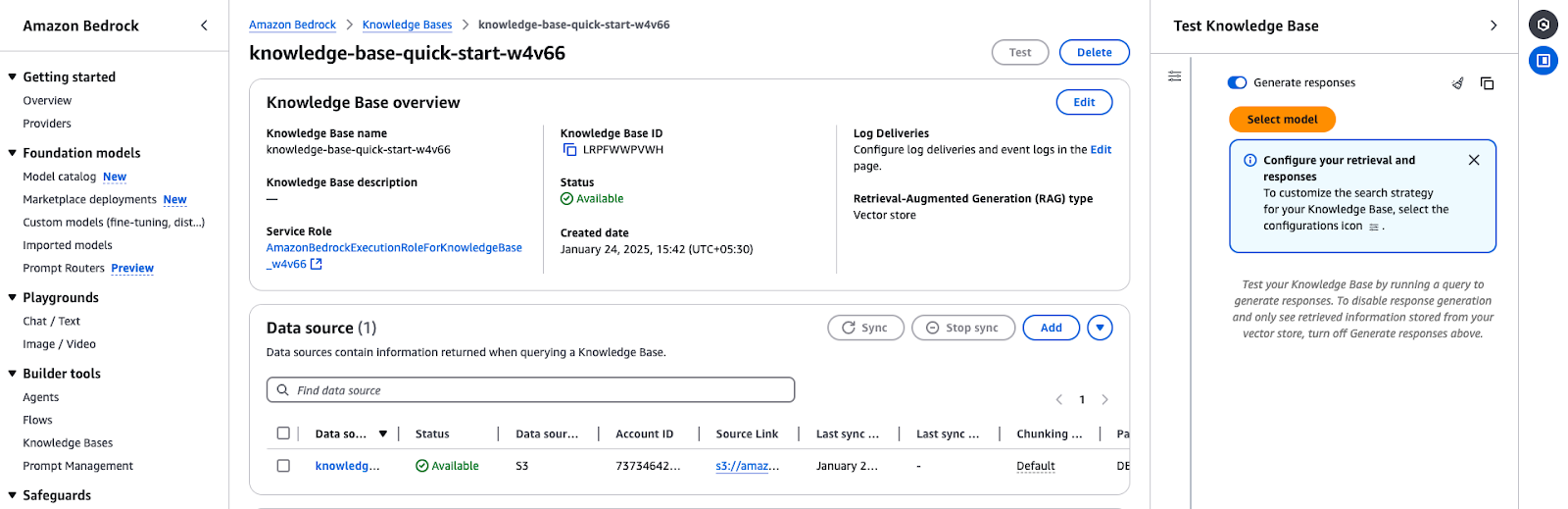
Die Übersicht der Amazon Bedrock Knowledge Base zeigt Konfigurationsdetails und den Status der Datenquelle.
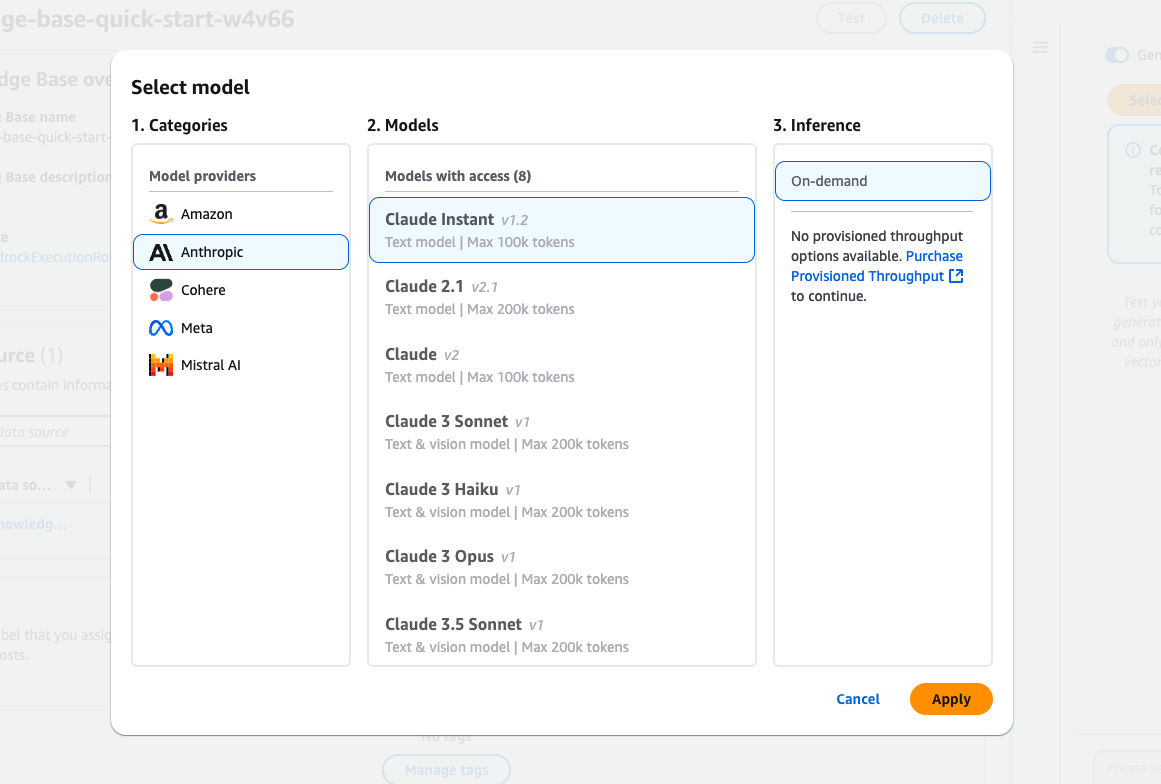
In der Amazon Bedrock Modellauswahl stehen verschiedene Claude Modelle von Anthropic zur Verfügung.
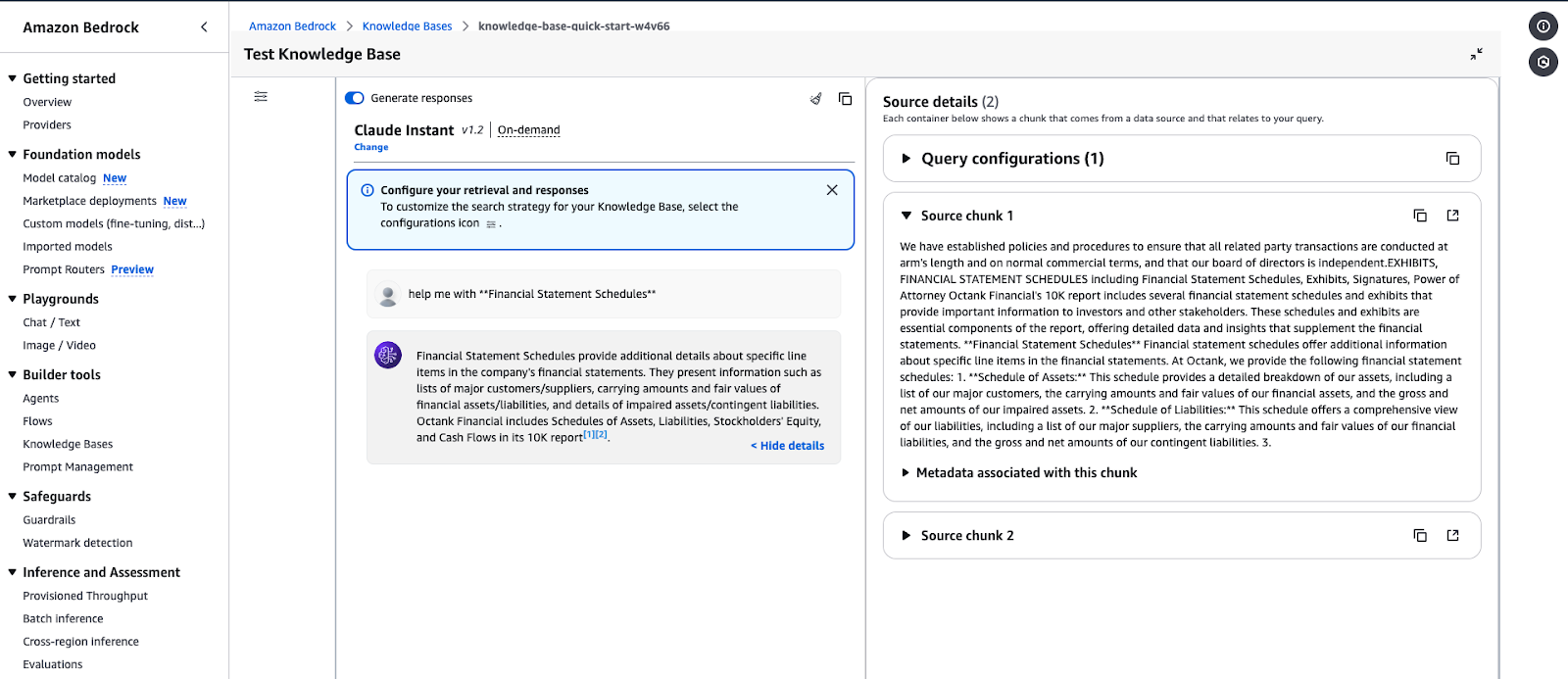
Amazon Bedrock Knowledge Base Testoberfläche, die eine Antwort auf eine Abfrage anzeigt.
Beispiel für die Ausgabe der Abfrage:
Mit AWS-Diensten wie Lambda kann Amazon Bedrock KI-Modelle in großem Umfang verwalten und bereitstellen. Dieser kosteneffiziente Ansatz gewährleistet eine hohe Verfügbarkeit und skaliert automatisch für KI-gestützte Anwendungen.
In diesem Abschnitt werden wir AWS Lambda verwenden, um ein Bedrock-Modell dynamisch aufzurufen, damit du Prompts nach Bedarf verarbeiten kannst.
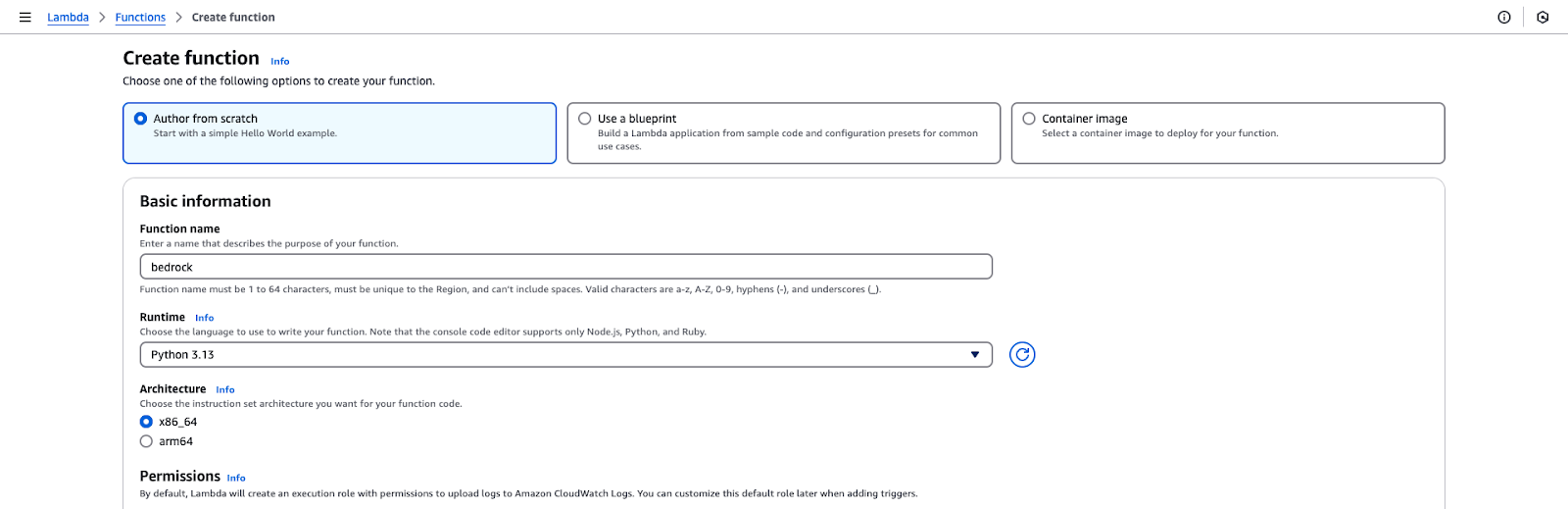
Seite zur Erstellung von AWS Lambda-Funktionen.
{
"prompt": "Write a formal apology letter for a late delivery."
}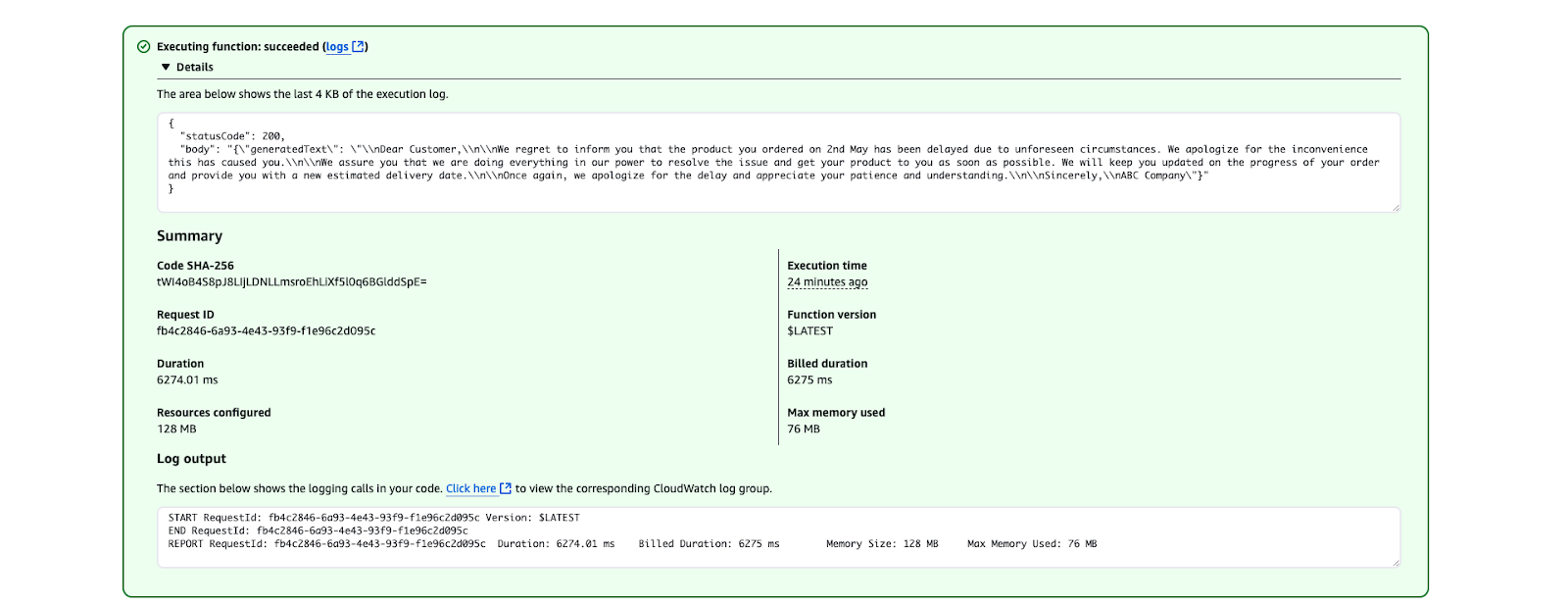
Das Ergebnis der AWS Lambda-Ausführung zeigt einen erfolgreichen Funktionslauf.
Optimiere die Kosten:
Sichern Sie die Lambda-Funktion:
Überwachen und protokollieren:
In diesem Abschnitt teile ich einige Best Practices für die Arbeit mit Amazon Bedrock, von der Optimierung der Kosten bis hin zur Sicherheit und Genauigkeit der Dinge.
Die Verwaltung der Kosten in AWS Bedrock kann die Nutzung von Amazon SageMaker für die Bereitstellung von Modellen und die Verwendung von Spot-Instanzen beinhalten, um bis zu 90 % der Kosten zu sparen. Hier sind einige meiner besten Praktiken:
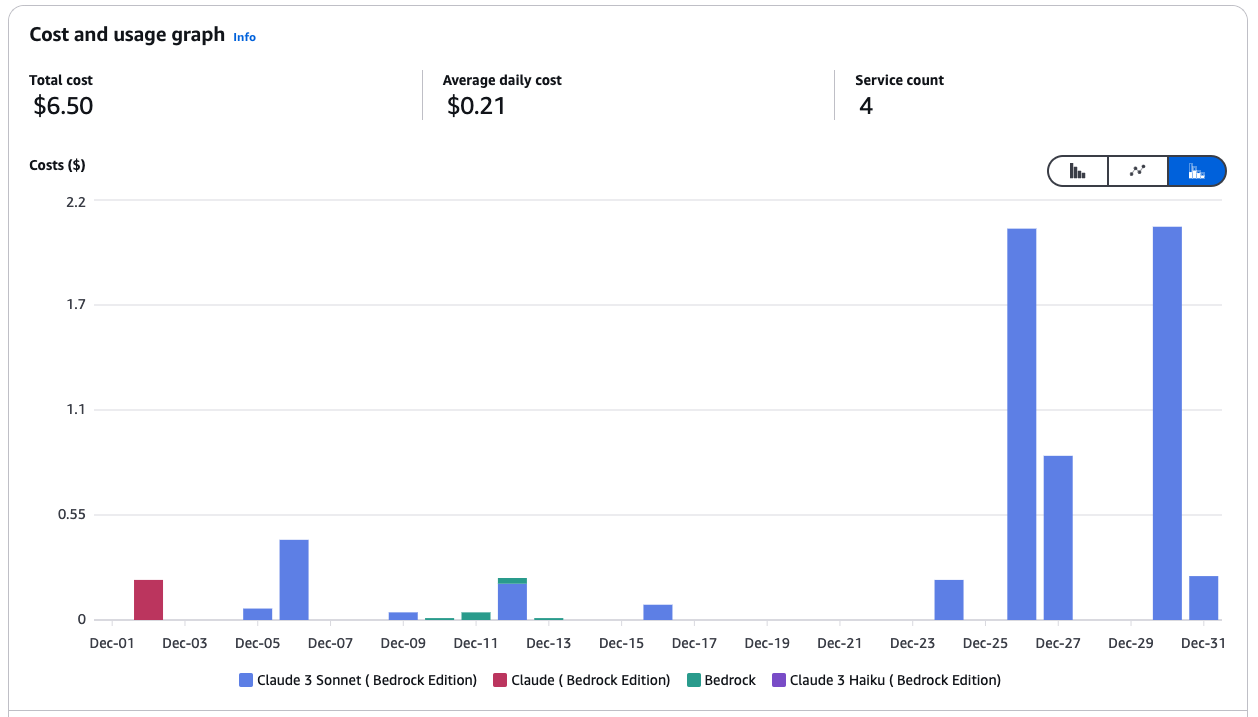
Kosten- und Nutzungsdiagramm für Amazon Bedrock Services.
from sagemaker.mxnet import MXNet
# Use spot instances for cost efficiency
use_spot_instances = True
# Maximum runtime for the training job (in seconds)
max_run = 600
# Maximum wait time for Spot instance availability (in seconds); set only if using Spot instances
max_wait = 1200 if use_spot_instances else None
# Define the MXNet estimator for the training job
mnist_estimator = MXNet(
entry_point='source_dir/mnist.py', # Path to the script that contains the model training code
role=role, # IAM role used for accessing AWS resources (e.g., S3, SageMaker)
output_path=model_artifacts_location, # S3 location to save the trained model artifacts
code_location=custom_code_upload_location, # S3 location to upload the training script
instance_count=1, # Number of instances to use for training
instance_type='ml.m4.xlarge', # Instance type for the training job
framework_version='1.6.0', # Version of the MXNet framework to use
py_version='py3', # Python version for the environment
distribution={'parameter_server': {'enabled': True}}, # Enable distributed training with a parameter server
hyperparameters={ # Training hyperparameters
'learning-rate': 0.1, # Learning rate for the training job
'epochs': 5 # Number of training epochs
},
use_spot_instances=use_spot_instances, # Enable Spot instances for cost savings
max_run=max_run, # Maximum runtime for the training job
max_wait=max_wait, # Maximum wait time for Spot instance availability
checkpoint_s3_uri=checkpoint_s3_uri # S3 URI for saving intermediate checkpoints
)
# Start the training job and specify the locations of training and testing datasets
mnist_estimator.fit({
'train': train_data_location, # S3 location of the training dataset
'test': test_data_location # S3 location of the testing/validation dataset
})
AWS CloudWatch-Protokolle
Um die Sicherheit, Compliance und Leistung von Amazon Bedrock zu gewährleisten, ist es wichtig, die Best Practices zu befolgen. Hier sind meine Empfehlungen:
Durch die Überwachung und Bewertung von Modellen wird sichergestellt, dass sie genau und zuverlässig sind und mit den Unternehmenszielen übereinstimmen. Hier sind einige Best Practices:
Das Metrik-Dashboard zeigt die Anzahl der Aufrufe, die Latenz und die Anzahl der Token für verschiedene Modelle in Amazon Bedrock an.
AWS Bedrock verändert die Art und Weise, wie generative KI-Anwendungen entwickelt werden, und ist eine zentrale Plattform für die Nutzung von Basismodellen, ohne sich um die Infrastruktur kümmern zu müssen.
Diese Schritt-für-Schritt-Anleitung soll dir dabei helfen, die richtigen Modelle zu finden, sichere und skalierbare Workflows zu erstellen und Funktionen wie die Retrieval-Augmented Generation (RAG) für eine bessere Anpassung zu integrieren. Wenn du die besten Praktiken für Kosten, Sicherheit und Überwachung kennst, bist du bereit, deine KI-Lösungen zu entwickeln und zu verwalten, um deine Ziele zu erreichen.
Wenn du deine AWS-Kenntnisse weiter vertiefen möchtest, solltest du diese Kurse besuchen:
Lerne mehr über AWS mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Zoumana Keita
15 Min.
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree
Tutorial
Moez Ali