
Kursus
Pemasukan Data yang Efisien dengan pandas
4 Hr
63.2K
Kerangka kerja Airflow, serta arsitekturnya, memiliki beberapa fitur kunci yang membuatnya unik. Pertama, mari kita telusuri lebih dalam fitur terpenting dari kerangka kerja Airflow.
Unit paling sederhana dalam kerangka kerja Airflow adalah task. Task dapat dianggap sebagai operasi atau, bagi sebagian besar tim data, operasi dalam pipeline data.
Sebuah alur kerja ETL tradisional memiliki tiga task: mengekstrak, mentransformasi, dan memuat data. Dependensi mendefinisikan hubungan antar-task. Kembali ke contoh ETL kita, task “load” bergantung pada task “transform”, yang pada gilirannya bergantung pada task “extract”. Kombinasi antara task dan dependensi membentuk DAG, atau directed-acyclic graph. DAG merepresentasikan pipeline data di Airflow, dan agak berbelit untuk didefinisikan. Sebagai gantinya, mari lihat diagram pipeline ETL dasar berikut:
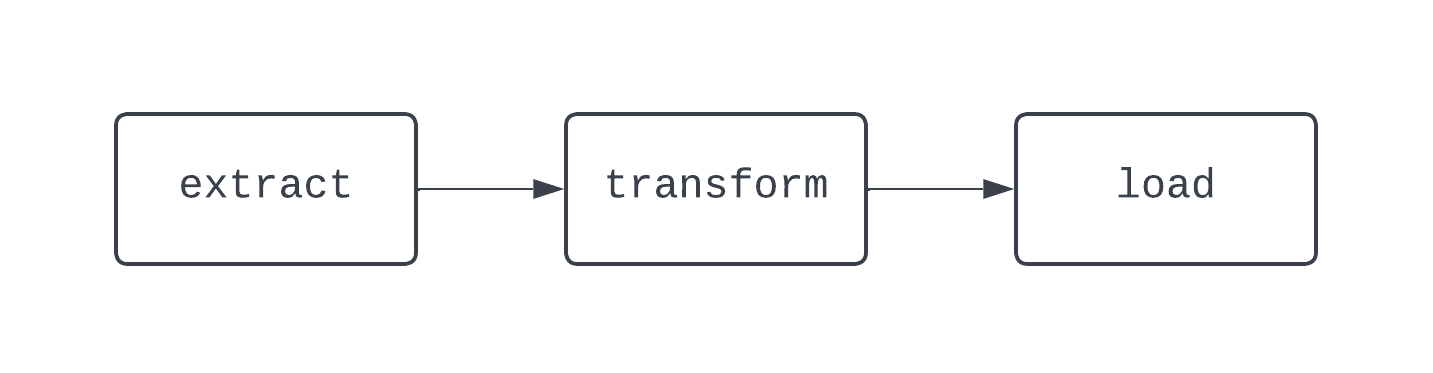
DAG di atas memiliki tiga task, dengan dua dependensi. Ini dianggap sebagai DAG karena tidak ada loop (atau siklus) antar-task. Di sini, panah menunjukkan sifat terarah dari proses; pertama, task extract dijalankan, diikuti oleh task transform dan load. Dengan DAG, mudah untuk melihat awal dan akhir proses yang jelas, bahkan jika logikanya kompleks, seperti DAG yang ditunjukkan di bawah ini:
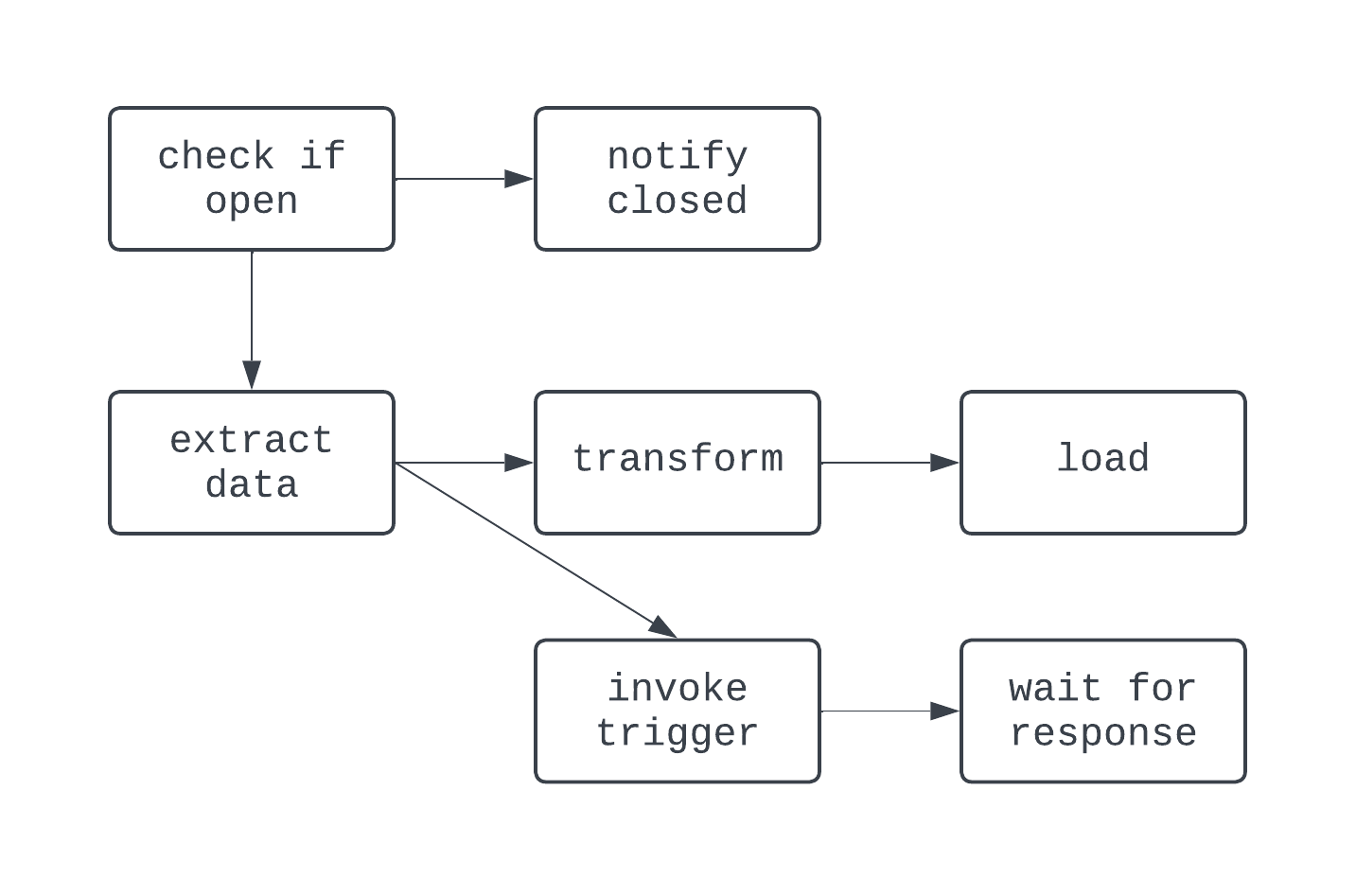
Dalam DAG ini, logikanya sedikit lebih rumit. Ada percabangan berdasarkan suatu kondisi, dan beberapa task dijalankan secara paralel. Namun, grafnya tetap terarah, dan tidak ada dependensi siklik antar-task. Sekarang, mari lihat proses yang bukan DAG:
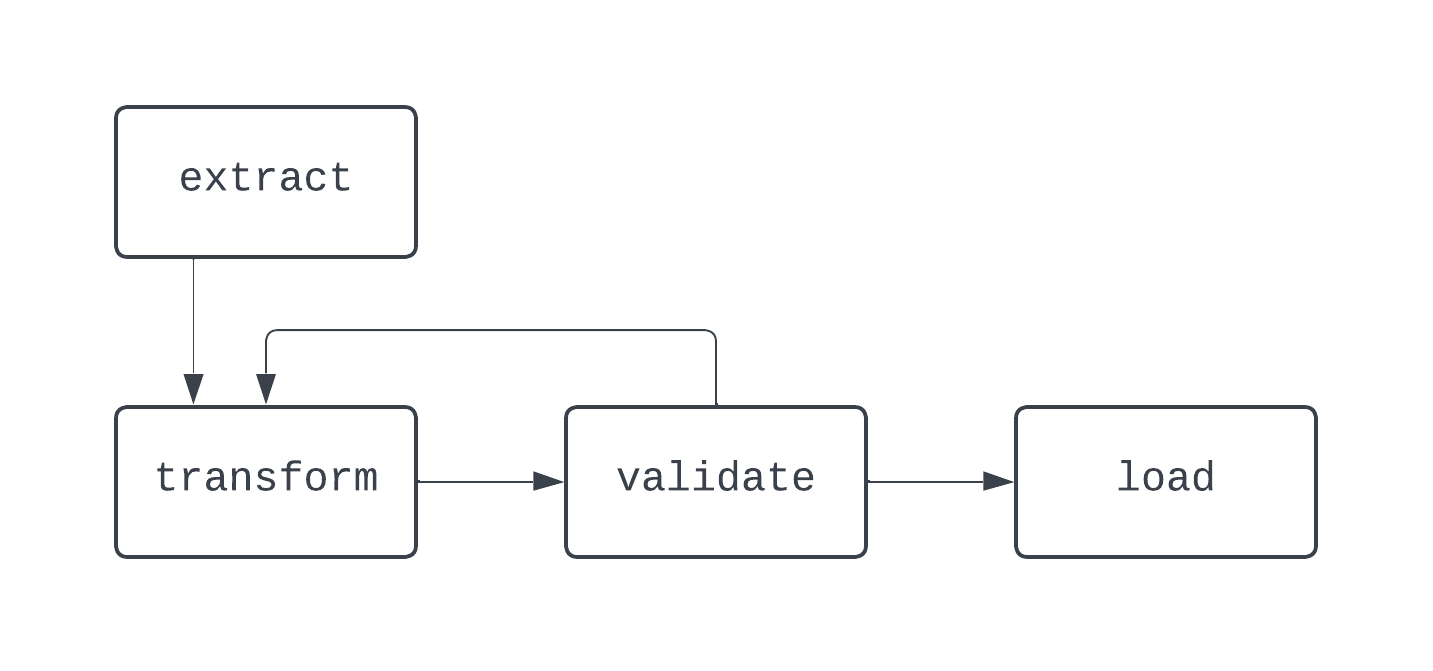
Dalam diagram ini, ada loop yang jelas antara task transform dan validate. Dalam beberapa kasus, DAG ini dapat berjalan selamanya jika tidak ada cara untuk keluar dari loop ini.
Saat membangun pipeline data, bahkan di luar Airflow, praktik terbaiknya adalah menghindari pembuatan alur kerja yang tidak dapat direpresentasikan sebagai DAG, karena Anda dapat kehilangan fitur kunci seperti determinisme atau idempoten.
Untuk menjadwalkan DAG, mengeksekusi task, dan memberikan visibilitas ke detail eksekusi pipeline data, Airflow memanfaatkan arsitektur berbasis Python yang terdiri dari komponen di bawah ini:
Baik menjalankan Airflow secara lokal maupun di lingkungan produksi, masing-masing komponen ini harus aktif dan berjalan agar Airflow berfungsi dengan baik.
Scheduler bertanggung jawab untuk (Anda mungkin sudah menebaknya) menjadwalkan DAG. Untuk menjadwalkan sebuah DAG, tanggal mulai dan interval jadwal harus ditentukan saat DAG ditulis sebagai kode Python.
Setelah sebuah DAG dijadwalkan, task di dalam DAG tersebut perlu dieksekusi, di sinilah executor berperan. Executor tidak menjalankan logika di dalam setiap task; ia hanya mengalokasikan task untuk dijalankan oleh sumber daya yang dikonfigurasi untuk melakukannya. Metadata database menyimpan informasi tentang run DAG, seperti apakah DAG dan task terkaitnya berhasil dijalankan atau tidak.
Metadata database juga menyimpan informasi seperti variabel dan koneksi yang didefinisikan pengguna, yang membantu saat membangun pipeline data tingkat produksi. Terakhir, web server menyediakan antarmuka pengguna untuk Airflow.
Antarmuka pengguna ini, atau UI, memberikan tim data alat terpusat untuk mengelola eksekusi pipeline mereka. Di UI Airflow, tim data dapat melihat status DAG mereka, menjalankan ulang DAG secara manual, menyimpan variabel dan koneksi, dan masih banyak lagi. UI Airflow menyediakan visibilitas terpusat ke proses pemasukan dan pengiriman data, membantu menjaga tim data tetap terinformasi dan menyadari kinerja pipeline data mereka.
Ada sejumlah cara untuk menginstal Apache Airflow. Kami akan membahas dua yang paling umum.
pipPrasyarat:
python3 terpasangUntuk menginstal Airflow dengan pip, pengelola paket Python, Anda dapat menjalankan perintah berikut:
pip install apache-airflowSetelah paket selesai dipasang, Anda perlu membuat semua komponen proyek Airflow, seperti menetapkan direktori home Airflow Anda, membuat file airflow.cfg, menyalakan metadata database, dan banyak lagi. Ini bisa menjadi banyak pekerjaan, dan memerlukan cukup banyak pengalaman prasyarat dengan Airflow. Untungnya, ada cara yang jauh lebih mudah dengan Astro CLI.
Prasyarat:
python3 terpasangAstronomer, penyedia Airflow terkelola, menyediakan sejumlah alat gratis untuk membantu mempermudah bekerja dengan Airflow. Salah satu alat tersebut adalah Astro CLI.
Astro CLI memudahkan pembuatan dan pengelolaan semua yang Anda perlukan untuk menjalankan Airflow. Untuk memulai, pertama Anda harus memasang CLI-nya. Untuk melakukannya di mesin Anda, lihat tautan ke dokumentasi Astronomer, dan ikuti langkah-langkah sesuai sistem operasi Anda.
Setelah Astro CLI terpasang, mengonfigurasi keseluruhan proyek Airflow hanya memerlukan satu perintah:
astro dev initIni akan mengonfigurasi semua sumber daya yang diperlukan untuk sebuah proyek Airflow di direktori kerja Anda saat ini. Direktori kerja Anda saat ini kemudian akan terlihat seperti ini:
.
├── dags/
├── include/
├── plugins/
├── tests/
├── airflow_settings.yaml
├── Dockerfile
├── packages.txt
└── requirements.txt
Setelah proyek dibuat, untuk memulainya, jalankan astro dev start. Setelah sekitar satu menit, Anda dapat membuka UI Airflow di peramban Anda, pada alamat https://localhost:8080/. Sekarang, Anda siap menulis DAG pertama Anda!
Kita telah membahas dasar-dasar dan fitur yang lebih lanjut dari kerangka kerja dan arsitektur Airflow. Sekarang Airflow sudah terpasang, Anda siap menulis DAG pertama Anda. Pertama, buat file bernama sample_dag.py di direktori dags/ pada proyek Airflow yang baru saja Anda buat. Menggunakan editor teks atau IDE favorit Anda, buka file sample_dag.py. Pertama, mari kita instansiasi DAG.
from airflow import DAG
from datetime import datetime
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
...
Di atas, kita menggunakan fungsi DAG dari modul airflow untuk mendefinisikan sebuah DAG bersama dengan pengelola konteks with.
Sebuah start_date, interval schedule, dan nilai untuk catchup disediakan. DAG ini akan berjalan setiap hari pukul 09.00 UTC. Karena catchup disetel ke True, DAG ini akan berjalan untuk setiap hari antara hari saat pertama kali dipicu dan 1 Januari 2024, dan max_active_runs=1 memastikan hanya satu DAG yang dapat berjalan pada suatu waktu.
Sekarang, mari tambahkan beberapa task! Pertama, kita akan membuat task untuk memalsukan ekstraksi data dari sebuah API. Lihat kode di bawah:
...
# Import the PythonOperator
from airflow.operators.python import PythonOperator
...
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
Selanjutnya, kita ingin membuat task untuk mentransformasi data yang dikembalikan oleh task extract_data. Ini dapat dilakukan dengan kode berikut. Di sini, kita menggunakan fitur Airflow bernama XCom untuk mengambil data dari task sebelumnya.
Karena render_templat_as_native_obj disetel ke True, nilai-nilai ini dibagikan sebagai objek Python alih-alih string. Data mentah dari task extract_data kemudian diteruskan ke transform_data_callable sebagai argumen kata kunci. Data ini kemudian ditransformasi dan dikembalikan, yang akan digunakan oleh task load_data dengan cara serupa.
...
# Import pandas
import pandas as pd
...
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
...
Terakhir, dependensi ditetapkan antar-task. Kode di sini menetapkan dependensi antara task extract_data, transform_data, dan load_data untuk membuat DAG ETL dasar.
...
extract_data >> transform_data >> load_data
Hasil akhirnya akan terlihat seperti ini!
from airflow import DAG
from datetime import datetime
from airflow.operators.python import PythonOperator
import pandas as pd
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
# Set dependencies between tasks
extract_data >> transform_data >> load_data
Setelah Anda mendefinisikan pipeline sebagai kode Python, Anda dapat menggunakan UI Airflow untuk menyalakan DAG Anda. Klik pada DAG weather_etl dan aktifkan tombol sakelar di kiri atas. Amati saat task dan DAG Anda berhasil diselesaikan.
Selamat, Anda telah menulis dan menjalankan DAG Airflow pertama Anda!
Selain menggunakan operator tradisional, Airflow memperkenalkan TaskFlow API, yang memudahkan pendefinisian DAG dan task menggunakan dekorator dan kode Python native.
Alih-alih secara eksplisit menggunakan XCom untuk berbagi data antar-task, TaskFlow API mengabstraksi logika ini, dan tetap menggunakan XCom di balik layar. Kode di bawah menunjukkan logika dan fungsi yang sama persis seperti di atas, kali ini diimplementasikan dengan TaskFlow API, yang lebih intuitif bagi analis dan ilmuwan data yang terbiasa membangun logika ETL berbasis skrip.
from airflow.decorators import dag, task
from datetime import datetime
import pandas as pd
@dag(
start_date=datetime(year=2023, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1
)
def weather_etl():
@task()
def extract_data():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
@task()
def transform_data(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
@task()
def load_data(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
# Set dependencies using function calls
raw_dataset = extract_data()
transformed_dataset = transform_data(raw_dataset)
load_data(transformed_dataset)
# Allow the DAG to be run
weather_etl()
Membangun DAG Airflow bisa jadi rumit. Ada beberapa praktik terbaik yang perlu diingat saat membangun pipeline dan alur kerja data, tidak hanya dengan Airflow, tetapi juga dengan alat lainnya.
Dengan task, Airflow membantu memudahkan visualisasi modularitas. Jangan mencoba melakukan terlalu banyak dalam satu task. Walaupun seluruh pipeline ETL dapat dibangun dalam satu task, hal ini akan menyulitkan penelusuran masalah. Ini juga akan menyulitkan visualisasi kinerja sebuah DAG.
Saat membuat task, penting untuk memastikan task hanya melakukan satu hal, mirip seperti fungsi di Python.
Lihat contoh di bawah. Kedua DAG melakukan hal yang sama dan gagal pada titik kode yang sama. Namun, pada DAG di sebelah kiri, jelas bahwa logika load menyebabkan kegagalan, sementara hal ini tidak begitu jelas pada DAG di sebelah kanan.
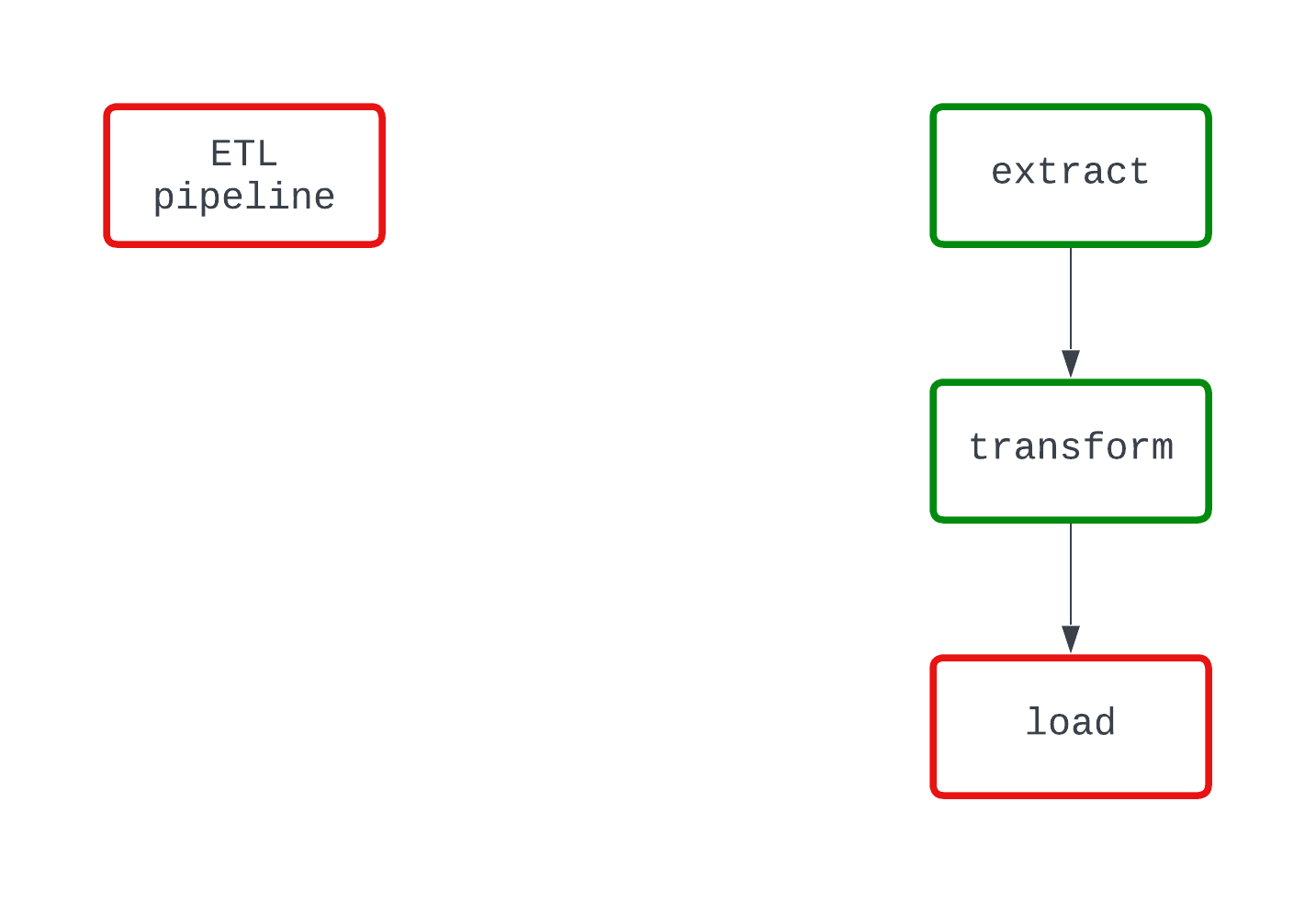
Proses deterministik adalah proses yang menghasilkan hasil yang sama, dengan masukan yang sama. Ketika sebuah DAG berjalan untuk interval tertentu, hasilnya harus sama setiap kali. Meskipun merupakan karakteristik pipeline data yang lebih kompleks, determinisme penting untuk memastikan hasil yang konsisten.
Dengan Airflow, manfaatkan Jinja-templating untuk memasukkan field templat ke dalam operator Airflow alih-alih menggunakan fungsi datetime.now() untuk membuat data temporal.
Apa yang terjadi jika Anda menjalankan sebuah DAG untuk interval yang sama dua kali? Bagaimana jika 10 kali? Apakah Anda akan mendapatkan data duplikat di media penyimpanan target Anda? Idempoten memastikan bahwa meskipun sebuah pipeline data dijalankan berkali-kali, hasil akhirnya seolah-olah pipeline hanya dijalankan sekali.
Untuk membuat pipeline data deterministik, pertimbangkan untuk memasukkan logika berikut ke dalam DAG Anda:
INSERT, yang dapat menyebabkan duplikasi.Airflow tidak dimaksudkan untuk memproses data dalam jumlah besar. Jika ingin menjalankan transformasi pada lebih dari beberapa gigabita data, Airflow tetap merupakan alat yang tepat; namun, Airflow sebaiknya memanggil alat lain, seperti dbt atau Databricks, untuk menjalankan transformasi tersebut.
Biasanya, task dieksekusi secara lokal di mesin Anda atau dengan node pekerja di produksi. Bagaimanapun, hanya beberapa gigabita memori yang akan tersedia untuk pekerjaan komputasi yang diperlukan.
Fokuslah menggunakan Airflow untuk transformasi data yang sangat ringan dan sebagai alat orkestrasi saat menangani data yang lebih besar.
Dengan kemampuan Airflow untuk mendefinisikan pipeline data sebagai kode dan beragam konektor serta operatornya, perusahaan di seluruh dunia mengandalkan Airflow untuk membantu menjalankan platform data mereka.
Di industri, sebuah tim data mungkin bekerja dengan berbagai alat, mulai dari situs SFTP hingga sistem penyimpanan file cloud hingga data lakehouse. Untuk membangun platform data, sangat penting agar sistem-sistem yang berbeda ini terintegrasi.
Dengan komunitas open-source yang dinamis, ada ribuan konektor siap pakai untuk membantu mengintegrasikan peralatan data Anda. Ingin memindahkan file dari S3 ke Snowflake? Untungnya, S3ToSnowflakeOperator memudahkan hal itu! Bagaimana dengan pemeriksaan kualitas data dengan Great Expectations? Itu juga sudah tersedia.
Jika Anda tidak dapat menemukan alat siap pakai yang tepat untuk pekerjaan tersebut, tidak masalah. Airflow bersifat extensible, sehingga memudahkan Anda membangun alat kustom sendiri untuk memenuhi kebutuhan Anda.
Saat menjalankan Airflow di produksi, Anda juga perlu memikirkan alat yang Anda gunakan untuk mengelola infrastrukturnya. Ada sejumlah cara untuk melakukannya, dengan penawaran premium seperti Astronomer, opsi cloud-native seperti MWAA, atau bahkan solusi buatan sendiri.
Biasanya, ini melibatkan pertukaran antara biaya dan pengelolaan infrastruktur; solusi yang lebih mahal mungkin berarti lebih sedikit yang harus dikelola, sementara menjalankan semuanya pada satu instance EC2 mungkin murah namun sulit dipelihara.
Apache Airflow adalah alat terdepan di industri untuk menjalankan pipeline data di produksi. Menyediakan fungsionalitas seperti penjadwalan, extensibility, dan observability sembari memungkinkan analis, ilmuwan, dan engineer data untuk mendefinisikan pipeline data sebagai kode, Airflow membantu profesional data fokus pada dampak bisnis.
Memulai dengan Airflow itu mudah, terutama dengan Astro CLI, dan operator tradisional serta TaskFlow API memudahkan Anda menulis DAG pertama. Saat membangun pipeline data dengan Airflow, pastikan untuk menempatkan modularitas, determinisme, dan idempoten di garis depan keputusan desain Anda; praktik terbaik ini akan membantu Anda menghindari sakit kepala di kemudian hari, terutama ketika DAG Anda mengalami kesalahan.
Dengan Airflow, ada banyak hal untuk dipelajari. Untuk proyek analitik atau sains data Anda berikutnya, cobalah Airflow. Bereksperimenlah dengan operator siap pakai, atau bangun sendiri. Cobalah berbagi data antar-task dengan operator tradisional dan TaskFlow API. Jangan takut untuk mendorong batasan. Jika Anda siap memulai, lihat kursus Introduction to Airflow in Python dari DataCamp, yang membahas dasar-dasar Airflow dan mengeksplorasi cara menerapkan pipeline rekayasa data yang kompleks di produksi.
Anda juga dapat memulai kursus Introduction to Data Pipelines kami, yang akan membantu Anda mengasah keterampilan untuk membangun pipeline data yang efektif, berkinerja tinggi, dan andal. Terakhir, Anda dapat melihat perbandingan kami tentang Airflow vs Prefect untuk melihat mana alat terbaik bagi Anda.
Jika Anda ingin lebih banyak, lihat beberapa sumber daya di bawah ini. Semoga sukses, dan selamat ngoding!
https://airflow.apache.org/docs/apache-airflow/stable/project.html
https://airflow.apache.org/blog/airflow-survey-2022/
https://airflow.apache.org/docs/apache-airflow/1.10.9/installation.html
https://docs.astronomer.io/astro/cli/get-started-cli
https://airflow.apache.org/docs/apache-airflow/stable/tutorial/taskflow.html
https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html
Mulai Perjalanan Data Pipelines Anda Hari Ini
Kursus
Kursus