
Courses
Nạp dữ liệu gọn nhẹ với pandas
4 giờ
63.2K
Framework cũng như kiến trúc của Airflow có một số tính năng chủ chốt khiến nó trở nên khác biệt. Trước hết, hãy đi sâu hơn một chút vào những tính năng quan trọng nhất của framework Airflow.
Đơn vị đơn giản nhất trong framework Airflow là task. Task có thể được hiểu là các thao tác, hoặc với hầu hết đội ngũ dữ liệu, là các thao tác trong một pipeline dữ liệu.
Một quy trình ETL truyền thống có ba task; trích xuất, chuyển đổi và nạp dữ liệu. Phụ thuộc (dependency) xác định mối quan hệ giữa các task. Quay lại ví dụ ETL của chúng ta, task “load” phụ thuộc vào task “transform”, và task này lại phụ thuộc vào task “extract”. Sự kết hợp giữa các task và phụ thuộc tạo thành DAG, hay đồ thị có hướng vô chu trình (directed-acyclic graphs). DAG đại diện cho pipeline dữ liệu trong Airflow, và hơi rắc rối khi định nghĩa. Thay vào đó, hãy xem sơ đồ của một pipeline ETL cơ bản:
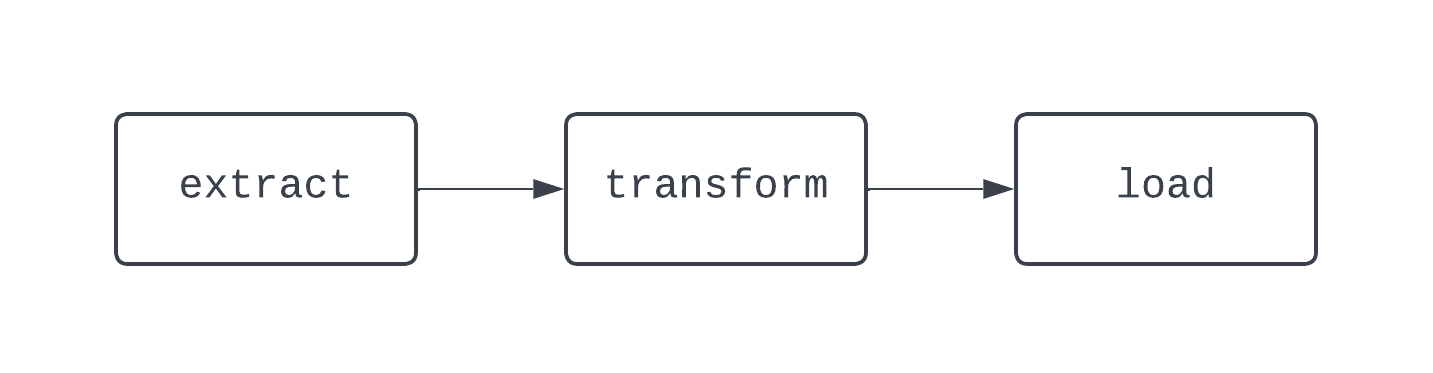
DAG ở trên có ba task, với hai phụ thuộc. Nó được coi là DAG vì không có vòng lặp (chu trình) giữa các task. Ở đây, các mũi tên thể hiện tính có hướng của quy trình; đầu tiên, task extract chạy, sau đó đến các task transform và load. Với DAG, bạn dễ dàng thấy điểm bắt đầu và kết thúc rõ ràng của quy trình, ngay cả khi logic phức tạp, như DAG bên dưới:
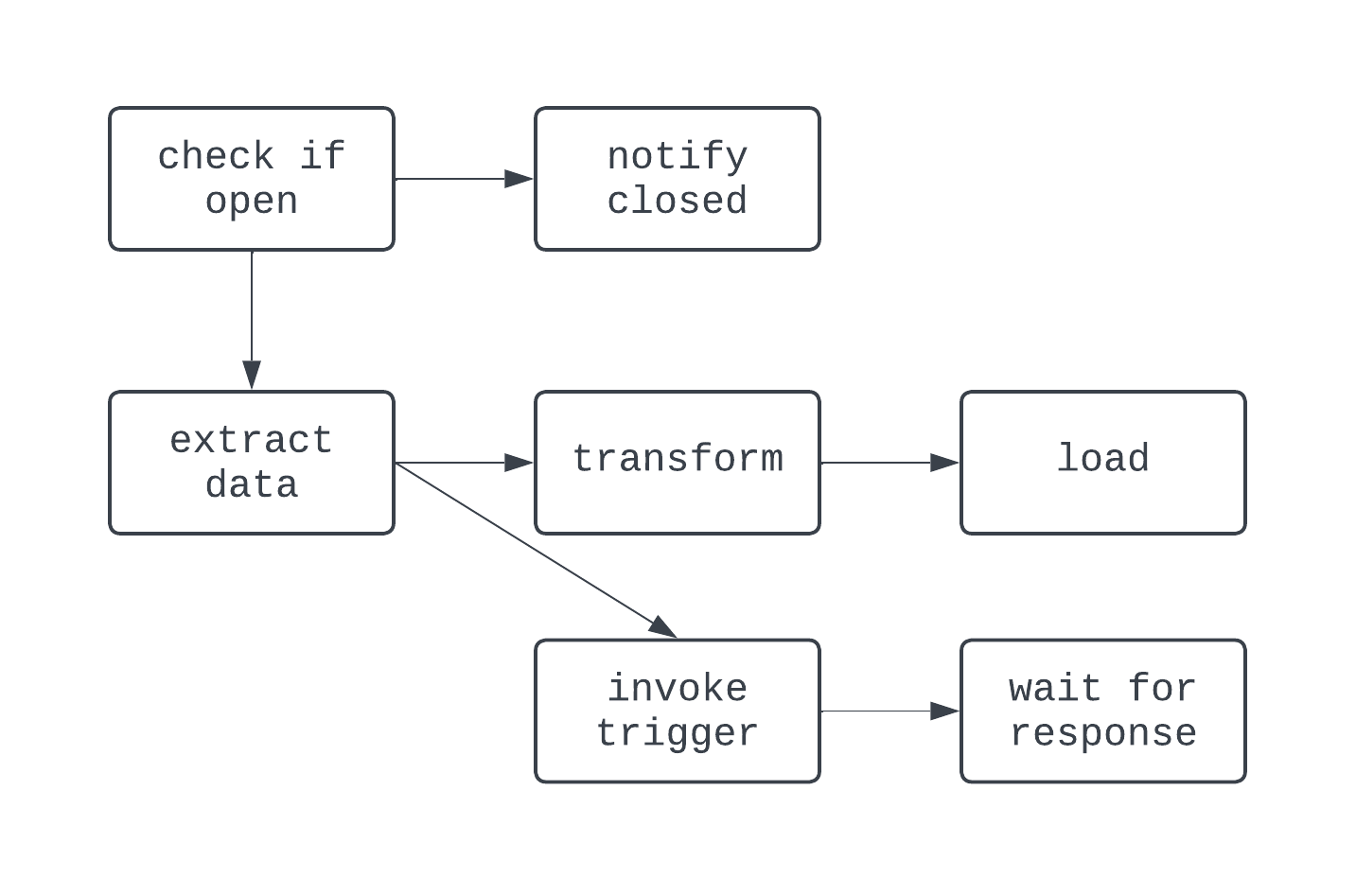
Trong DAG này, logic có phần “điên rồ” hơn. Có nhánh rẽ dựa trên điều kiện, và một vài task chạy song song. Tuy nhiên, đồ thị vẫn có hướng, và không có phụ thuộc vòng giữa các task. Giờ hãy xem một quy trình không phải là DAG:
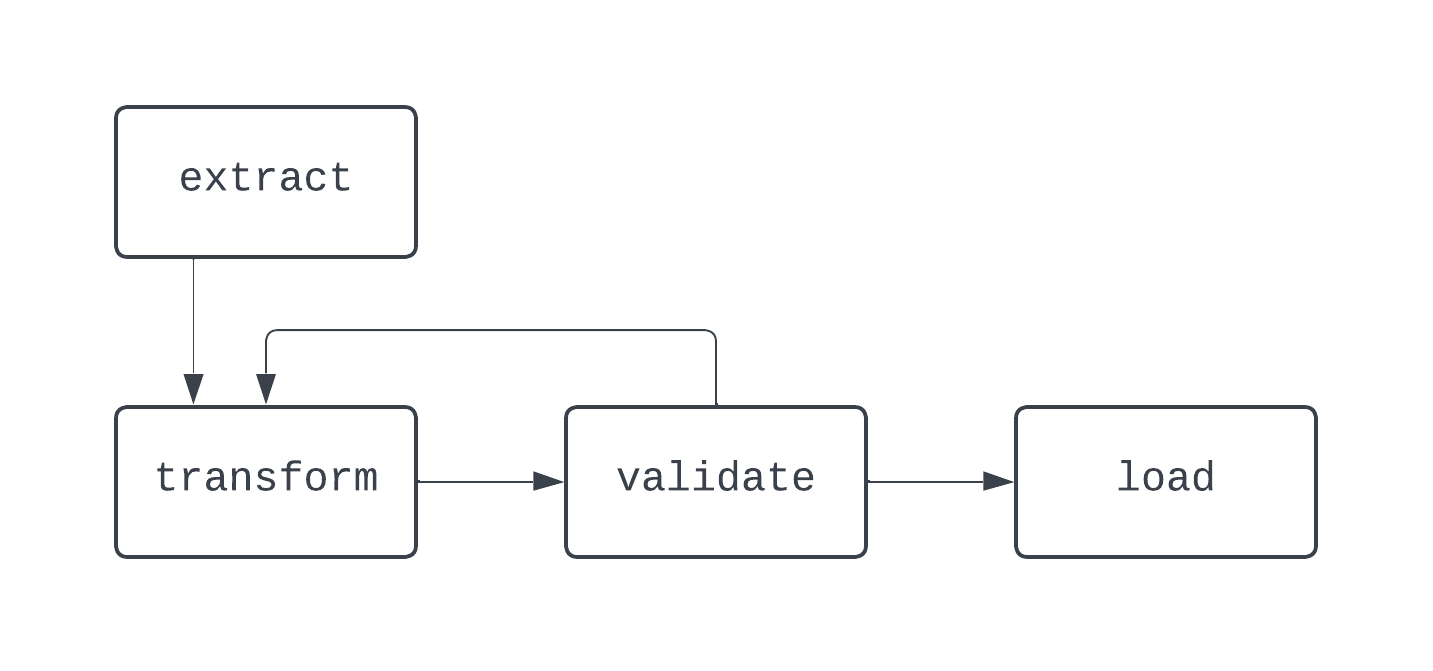
Trong sơ đồ này, có một vòng lặp rõ ràng giữa các task transform và validate. Trong một số trường hợp, DAG này có thể chạy mãi mãi nếu không có cách thoát khỏi vòng lặp.
Khi xây dựng pipeline dữ liệu, ngay cả ngoài Airflow, thực hành tốt nhất là tránh tạo các workflow không thể biểu diễn dưới dạng DAG, vì bạn có thể mất các tính năng then chốt như tính tất định hoặc tính idempotent.
Để lập lịch DAG, thực thi task và cung cấp khả năng quan sát chi tiết quá trình thực thi pipeline dữ liệu, Airflow tận dụng một kiến trúc dựa trên Python gồm các thành phần sau:
Dù chạy Airflow cục bộ hay trong môi trường sản xuất, mỗi thành phần này đều phải hoạt động để Airflow vận hành đúng.
Scheduler chịu trách nhiệm (chắc bạn đoán được rồi) lập lịch cho DAG. Để lập lịch một DAG, khi viết DAG bằng mã Python, bạn phải cung cấp ngày bắt đầu và khoảng thời gian lập lịch cho DAG.
Khi một DAG đã được lập lịch, các task trong DAG đó cần được thực thi, và đó là lúc executor phát huy tác dụng. Executor không chạy logic trong từng task; nó chỉ phân bổ task để được chạy bởi tài nguyên đã cấu hình. Cơ sở dữ liệu metadata lưu trữ thông tin về các lần chạy DAG, như việc DAG và các task liên quan có chạy thành công hay không.
Cơ sở dữ liệu metadata cũng lưu thông tin như biến và kết nối do người dùng định nghĩa, hỗ trợ khi xây dựng pipeline dữ liệu cấp sản xuất. Cuối cùng, web server cung cấp giao diện người dùng cho Airflow.
Giao diện người dùng này, hay UI, cung cấp cho đội ngũ dữ liệu một công cụ trung tâm để quản lý việc thực thi pipeline. Trong UI của Airflow, đội ngũ dữ liệu có thể xem trạng thái DAG, chạy lại DAG thủ công, lưu biến và kết nối, và còn nhiều hơn thế. UI của Airflow cung cấp khả năng quan sát tập trung vào quy trình nạp và phân phối dữ liệu, giúp đội ngũ dữ liệu luôn nắm bắt và theo dõi hiệu năng pipeline của họ.
Có nhiều cách để cài đặt Apache Airflow. Chúng tôi sẽ đề cập đến hai cách phổ biến nhất.
pipYêu cầu tiên quyết:
python3Để cài đặt Airflow bằng pip, trình quản lý gói của Python, bạn có thể chạy lệnh sau:
pip install apache-airflowSau khi gói được cài đặt xong, bạn sẽ cần tạo tất cả các thành phần của một dự án Airflow, như đặt thư mục home của Airflow, tạo tệp airflow.cfg, khởi tạo cơ sở dữ liệu metadata, và còn nhiều việc khác. Điều này có thể khá vất vả và đòi hỏi khá nhiều kinh nghiệm tiền đề với Airflow. May mắn thay, có một cách dễ hơn nhiều với Astro CLI.
Yêu cầu tiên quyết:
python3Astronomer, nhà cung cấp Airflow quản lý, cung cấp một số công cụ miễn phí để giúp việc làm việc với Airflow dễ dàng hơn. Một trong các công cụ đó là Astro CLI.
Astro CLI giúp bạn dễ dàng tạo và quản lý mọi thứ cần thiết để chạy Airflow. Để bắt đầu, trước tiên bạn phải cài đặt CLI. Để thực hiện trên máy của bạn, hãy xem liên kết đến tài liệu của Astronomer và làm theo các bước cho hệ điều hành của bạn.
Khi đã cài đặt Astro CLI, việc cấu hình toàn bộ một dự án Airflow chỉ cần một lệnh:
astro dev initLệnh này sẽ cấu hình tất cả tài nguyên cần thiết cho một dự án Airflow trong thư mục làm việc hiện tại của bạn. Thư mục làm việc hiện tại của bạn sẽ trông như sau:
.
├── dags/
├── include/
├── plugins/
├── tests/
├── airflow_settings.yaml
├── Dockerfile
├── packages.txt
└── requirements.txt
Sau khi dự án được tạo, để khởi động dự án, chạy astro dev start. Sau khoảng một phút, bạn có thể mở UI của Airflow trong trình duyệt tại địa chỉ https://localhost:8080/. Bây giờ, bạn đã sẵn sàng viết DAG đầu tiên!
Chúng ta đã điểm qua các kiến thức cơ bản và các tính năng nâng cao hơn của framework và kiến trúc Airflow. Giờ Airflow đã được cài đặt, bạn sẵn sàng viết DAG đầu tiên. Trước tiên, tạo một tệp tên sample_dag.py trong thư mục dags/ của dự án Airflow bạn vừa tạo. Dùng trình soạn thảo hoặc IDE yêu thích, mở tệp sample_dag.py. Đầu tiên, hãy khởi tạo DAG.
from airflow import DAG
from datetime import datetime
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
...
Ở trên, chúng ta dùng hàm DAG từ module airflow để định nghĩa một DAG cùng với context-manager with.
Một start_date, khoảng thời gian schedule và giá trị cho catchup được cung cấp. DAG này sẽ chạy mỗi ngày lúc 9:00 AM UTC. Vì catchup được đặt là True, DAG này sẽ chạy cho mỗi ngày giữa ngày nó được kích hoạt lần đầu và ngày 1 tháng 1 năm 2024, và max_active_runs=1 đảm bảo chỉ có một lần chạy DAG hoạt động tại một thời điểm.
Giờ, hãy thêm vài task! Đầu tiên, chúng ta sẽ tạo một task để mô phỏng việc trích xuất dữ liệu từ một API. Xem đoạn mã dưới đây:
...
# Import the PythonOperator
from airflow.operators.python import PythonOperator
...
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
Tiếp theo, chúng ta sẽ tạo một task để chuyển đổi dữ liệu trả về từ task extract_data. Có thể làm điều này với đoạn mã sau. Ở đây, chúng ta dùng một tính năng của Airflow gọi là XCom để lấy dữ liệu từ task trước đó.
Vì render_templat_as_native_obj được đặt là True, các giá trị này được chia sẻ dưới dạng đối tượng Python thay vì chuỗi. Dữ liệu thô từ task extract_data sau đó được truyền vào transform_data_callable dưới dạng đối số từ khóa. Dữ liệu này được chuyển đổi và trả về, nơi nó sẽ được task load_data sử dụng theo cách tương tự.
...
# Import pandas
import pandas as pd
...
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
...
Cuối cùng, thiết lập phụ thuộc giữa các task. Đoạn mã này thiết lập phụ thuộc giữa các task extract_data, transform_data và load_data để tạo một DAG ETL cơ bản.
...
extract_data >> transform_data >> load_data
Thành phẩm cuối cùng sẽ trông như thế này!
from airflow import DAG
from datetime import datetime
from airflow.operators.python import PythonOperator
import pandas as pd
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
# Set dependencies between tasks
extract_data >> transform_data >> load_data
Khi bạn đã định nghĩa pipeline dưới dạng mã Python, bạn có thể dùng UI của Airflow để bật DAG. Nhấp vào DAG weather_etl và gạt công tắc ở góc trên bên trái. Hãy theo dõi khi các task và DAG của bạn hoàn tất chạy thành công.
Chúc mừng, bạn đã viết và chạy DAG Airflow đầu tiên!
Bên cạnh việc dùng các operator truyền thống, Airflow đã giới thiệu TaskFlow API, giúp việc định nghĩa DAG và task dễ dàng hơn bằng decorator và mã Python thuần.
Thay vì dùng XCom một cách tường minh để chia sẻ dữ liệu giữa các task, TaskFlow API trừu tượng hóa phần logic này, thay vào đó dùng XCom ở phía sau. Đoạn mã dưới đây thể hiện chính xác logic và chức năng như trên, nhưng lần này được triển khai với TaskFlow API, trực quan hơn cho các nhà phân tích và khoa học dữ liệu vốn quen xây dựng logic ETL dạng script.
from airflow.decorators import dag, task
from datetime import datetime
import pandas as pd
@dag(
start_date=datetime(year=2023, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1
)
def weather_etl():
@task()
def extract_data():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
@task()
def transform_data(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
@task()
def load_data(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
# Set dependencies using function calls
raw_dataset = extract_data()
transformed_dataset = transform_data(raw_dataset)
load_data(transformed_dataset)
# Allow the DAG to be run
weather_etl()
Xây dựng DAG Airflow có thể không đơn giản. Có một vài thực hành tốt cần ghi nhớ khi xây dựng pipeline và workflow dữ liệu, không chỉ với Airflow mà còn với các công cụ khác.
Với các task, Airflow giúp việc mô-đun hóa dễ hình dung hơn. Đừng cố làm quá nhiều trong một task. Dù một pipeline ETL hoàn chỉnh có thể được xây dựng trong một task, việc này sẽ gây khó khăn khi khắc phục sự cố. Nó cũng khiến việc hình dung hiệu năng của DAG trở nên khó khăn.
Khi tạo một task, điều quan trọng là đảm bảo task chỉ làm một việc, giống như các hàm trong Python.
Xem ví dụ dưới đây. Cả hai DAG đều làm cùng một việc và thất bại tại cùng một điểm trong mã. Tuy nhiên, ở DAG bên trái, rõ ràng logic load gây ra lỗi, trong khi điều này không rõ ràng ở DAG bên phải.
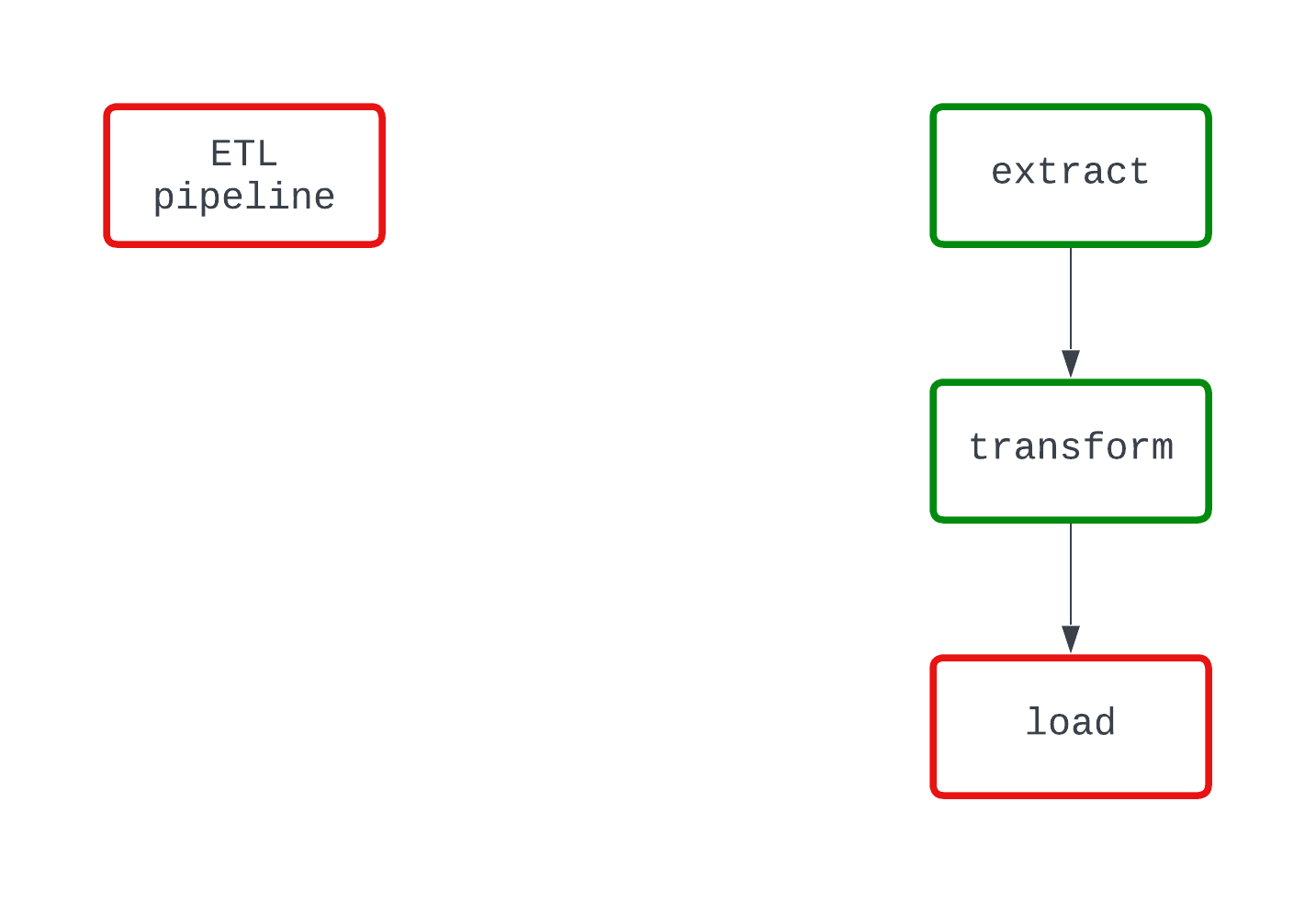
Một quy trình tất định là quy trình tạo ra cùng một kết quả với cùng một đầu vào. Khi một DAG chạy cho một khoảng thời gian cụ thể, nó nên tạo ra cùng kết quả mỗi lần. Dù là một đặc tính phức tạp hơn của pipeline dữ liệu, tính tất định rất quan trọng để đảm bảo kết quả nhất quán.
Với Airflow, hãy tận dụng Jinja-templating để truyền các trường được template vào operator của Airflow thay vì dùng hàm datetime.now() để tạo dữ liệu thời gian.
Điều gì xảy ra nếu bạn chạy một DAG cho cùng một khoảng thời gian hai lần? Còn 10 lần thì sao? Bạn có kết thúc với dữ liệu trùng lặp trong nơi lưu trữ đích không? Tính idempotent đảm bảo rằng ngay cả khi một pipeline dữ liệu được thực thi nhiều lần, thì vẫn như thể pipeline chỉ được thực thi một lần.
Để khiến pipeline dữ liệu có tính idempotent, hãy cân nhắc đưa các logic sau vào DAG của bạn:
INSERT, vốn có thể gây trùng lặp.Airflow không được thiết kế để xử lý lượng dữ liệu khổng lồ. Nếu bạn muốn chạy các chuyển đổi trên nhiều hơn vài gigabyte dữ liệu, Airflow vẫn là công cụ phù hợp; tuy nhiên, Airflow nên gọi một công cụ khác, như dbt hoặc Databricks, để thực hiện chuyển đổi.
Thông thường, các task được thực thi cục bộ trên máy của bạn hoặc với các node worker trong môi trường sản xuất. Dù theo cách nào, chỉ có vài gigabyte bộ nhớ sẵn có cho bất kỳ công việc tính toán nào cần thiết.
Hãy tập trung dùng Airflow cho các chuyển đổi dữ liệu nhẹ và như một công cụ điều phối khi xử lý dữ liệu lớn hơn.
Với khả năng định nghĩa pipeline dữ liệu dưới dạng mã và sự đa dạng lớn về connector và operator, các công ty trên toàn thế giới dựa vào Airflow để hỗ trợ nền tảng dữ liệu của họ.
Trong thực tế, một đội ngũ dữ liệu có thể làm việc với nhiều công cụ khác nhau, từ các site SFTP đến hệ thống lưu trữ tệp trên đám mây đến data lakehouse. Để xây dựng một nền tảng dữ liệu, việc tích hợp các hệ thống rời rạc này là tối quan trọng.
Với cộng đồng mã nguồn mở sôi động, có hàng nghìn connector dựng sẵn để giúp tích hợp công cụ dữ liệu của bạn. Muốn thả một tệp từ S3 vào Snowflake? May mắn cho bạn, S3ToSnowflakeOperator giúp việc đó trở nên dễ dàng! Còn kiểm tra chất lượng dữ liệu với Great Expectations thì sao? Cũng đã có sẵn rồi.
Nếu bạn không thể tìm được công cụ dựng sẵn phù hợp, cũng không sao. Airflow có thể mở rộng, giúp bạn dễ dàng xây dựng công cụ tùy chỉnh đáp ứng nhu cầu của mình.
Khi chạy Airflow trong môi trường sản xuất, bạn cũng sẽ muốn cân nhắc các công cụ dùng để quản lý hạ tầng. Có nhiều cách để làm điều này, với các lựa chọn cao cấp như Astronomer, các tùy chọn gốc đám mây như MWAA, hoặc thậm chí là giải pháp tự xây dựng.
Thông thường, điều này liên quan đến sự đánh đổi giữa chi phí và quản lý hạ tầng; giải pháp đắt hơn có thể đồng nghĩa với việc ít phải quản lý hơn, trong khi chạy mọi thứ trên một instance EC2 duy nhất có thể rẻ nhưng khó bảo trì.
Apache Airflow là công cụ hàng đầu để vận hành pipeline dữ liệu trong môi trường sản xuất. Cung cấp các chức năng như lập lịch, khả năng mở rộng và quan sát, đồng thời cho phép nhà phân tích, nhà khoa học và kỹ sư dữ liệu định nghĩa pipeline dữ liệu dưới dạng mã, Airflow giúp các chuyên gia dữ liệu tập trung tạo tác động kinh doanh.
Bắt đầu với Airflow rất dễ, đặc biệt với Astro CLI, và các operator truyền thống cùng TaskFlow API giúp bạn viết các DAG đầu tiên một cách đơn giản. Khi xây dựng pipeline dữ liệu với Airflow, hãy luôn ưu tiên tính mô-đun, tính tất định và tính idempotent trong các quyết định thiết kế; những thực hành tốt này sẽ giúp bạn tránh khỏi đau đầu về sau, đặc biệt khi DAG của bạn gặp lỗi.
Với Airflow, có rất nhiều điều để học. Cho dự án phân tích dữ liệu hoặc khoa học dữ liệu tiếp theo, hãy thử Airflow. Thử nghiệm các operator dựng sẵn, hoặc tự xây dựng. Thử chia sẻ dữ liệu giữa các task với operator truyền thống và TaskFlow API. Đừng ngại đẩy giới hạn. Nếu bạn sẵn sàng bắt đầu, hãy xem khóa học Introduction to Airflow in Python của DataCamp, khóa học này bao quát những điều cơ bản của Airflow và khám phá cách triển khai các pipeline kỹ thuật dữ liệu phức tạp trong sản xuất.
Bạn cũng có thể bắt đầu với khóa học Introduction to Data Pipelines của chúng tôi, giúp bạn rèn luyện kỹ năng xây dựng pipeline dữ liệu hiệu quả, hiệu năng cao và đáng tin cậy. Cuối cùng, bạn có thể xem so sánh Airflow và Prefect để xem công cụ nào phù hợp nhất với bạn.
Nếu bạn muốn nhiều hơn, hãy xem một số tài nguyên dưới đây. Chúc bạn may mắn và mãi đam mê viết code!
https://airflow.apache.org/docs/apache-airflow/stable/project.html
https://airflow.apache.org/blog/airflow-survey-2022/
https://airflow.apache.org/docs/apache-airflow/1.10.9/installation.html
https://docs.astronomer.io/astro/cli/get-started-cli
https://airflow.apache.org/docs/apache-airflow/stable/tutorial/taskflow.html
https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html
Bắt đầu hành trình Data Pipeline của bạn ngay hôm nay
Courses
Courses