
Course
Streamlined Data Ingestion with pandas
4 hr
62.7K
Airflow’s framework, as well as its architecture, have several key features that make it unique. First, let’s dig a little deeper into the most important features of Airflow’s framework.
The simplest unit of the Airflow framework are tasks. Tasks can be thought of as operations or, for most data teams, operations in a data pipeline.
A traditional ETL workflow has three tasks; extracting, transforming, and loading data. Dependencies define the relationships between tasks. Going back to our ETL example, the “load” task depends on the “transform” task, which, in turn, depends on the “extract” task. The combination of tasks and dependencies create DAGs, or directed-acyclic graphs. DAGs represent data pipelines in Airflow, and are a little convoluted to define. Instead, let’s take a look at a diagram of a basic ETL pipeline:
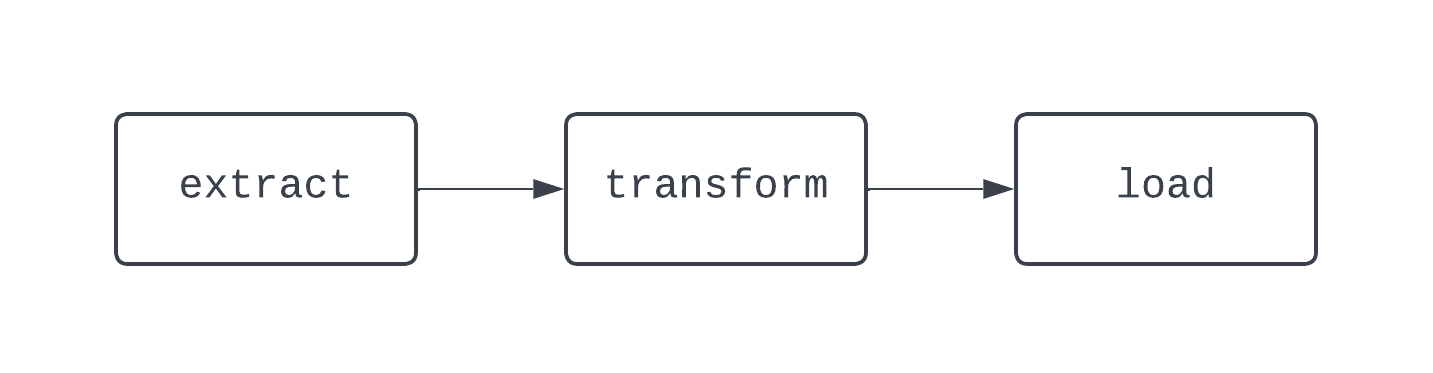
The DAG above has three tasks, with two dependencies. It’s considered a DAG because there are no loops (or cycles) between tasks. Here, the arrows show the directed nature of the process; first, the extract task is run, followed by the transform and load tasks. With DAGs, it’s easy to see a distinct start and end to the process, even if the logic is complex, like the DAG shown below:
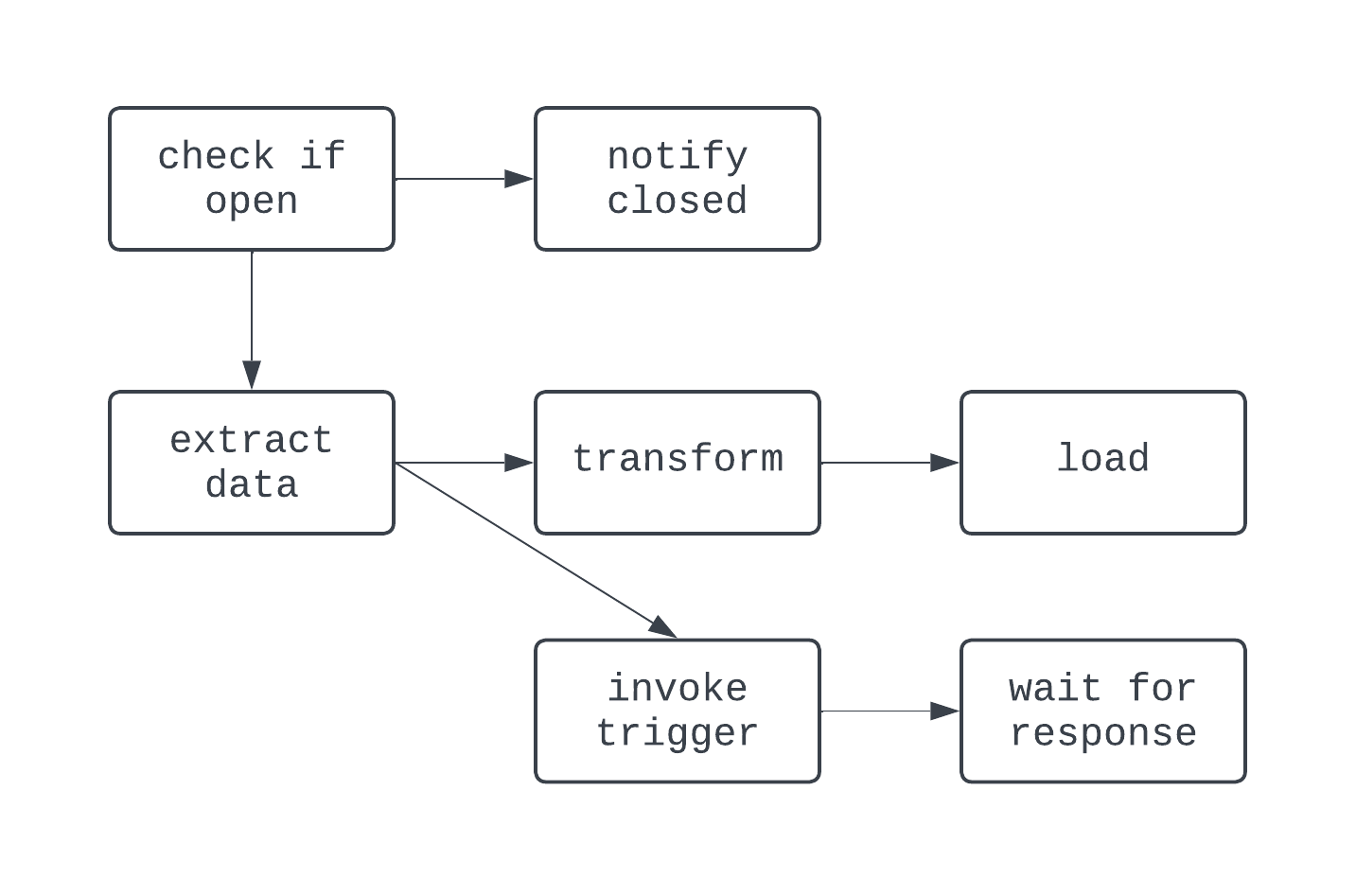
In this DAG, the logic is a bit crazier. There is branching based on a condition, and a few tasks are run in parallel. However, the graph is directed, and there are no cyclic dependencies between tasks. Now, let’s take a look at a process that is not a DAG:
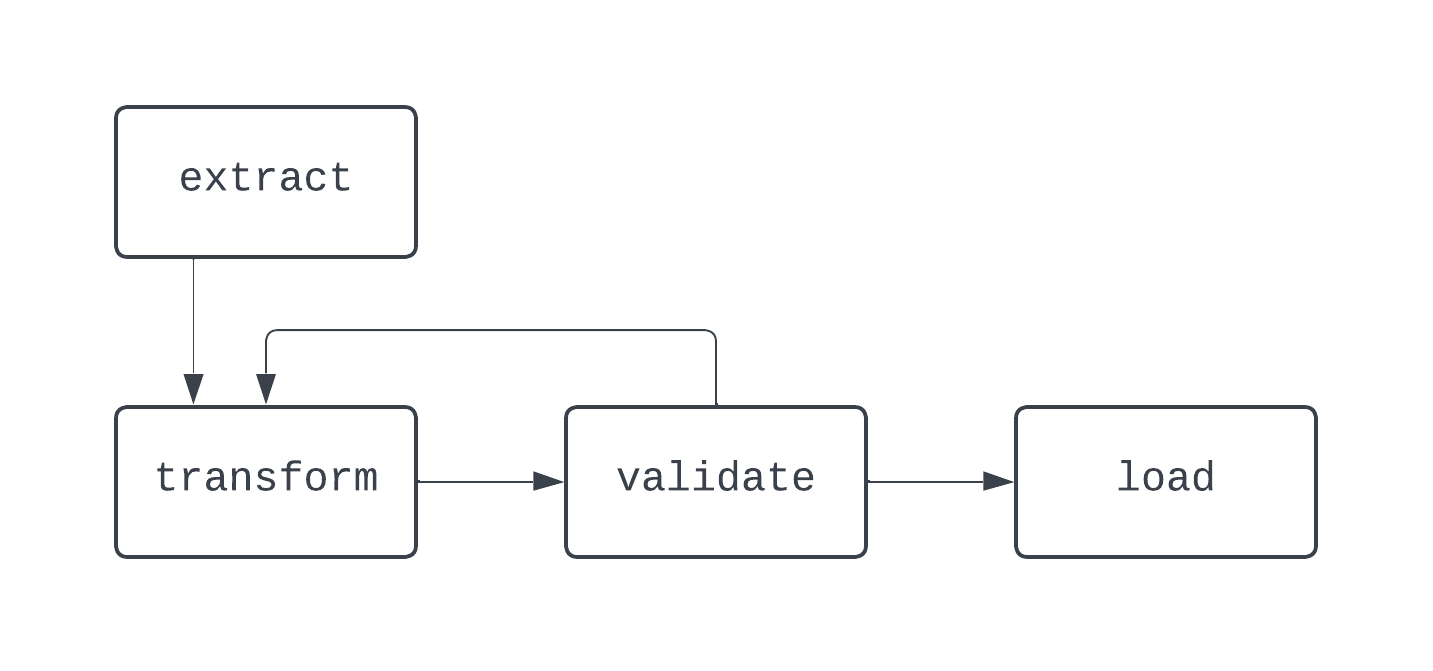
In this diagram, there is a distinct loop between the transform and validate tasks. In some cases, this DAG may run forever, if there is no way to break out of this loop.
When building data pipelines, even outside of Airflow, it’s best practice to stay away from creating workflows that can’t be represented as DAGs, as you may lose key features, such as determinism or idempotency.
To schedule DAGs, execute tasks, and provide visibility into data pipeline execution details, Airflow leverages a Python-based architecture made up of the components below:
Whether running Airflow locally or in a production environment, each of these components must be up and running for Airflow to function properly.
The scheduler is responsible for (you probably guessed it) scheduling DAGs. To schedule a DAG, a start date and schedule interval for the DAG must be provided when the DAG is written as Python code.
Once a DAG is scheduled, tasks within those DAGs need to be executed, which is where the executor comes in. The executor does not run the logic within each task; it just allocates the task to be run by whatever resources are configured to do so. The metadata database stores information about DAG runs, such as whether or not the DAG and its associated tasks ran successfully.
The metadata database also stores information such as user-defined variables and connections, which help when building production-grade data pipelines. Finally, the web server provides the user interface with Airflow.
This user interface, or UI, provides data teams with a central tool to manage their pipeline execution. In the Airflow UI, data teams can view the state of their DAGs, manually re-run DAG, store variables and connections, and so much more. The Airflow UI provides central visibility into data ingestion and delivery processes, helping to keep data teams informed and aware of their data pipeline performance.
There are a number of ways to install Apache Airflow. We’ll cover two of the most common.
pipPrerequisites:
python3 installedTo install Airflow with pip, Python’s package manner, you can run the following command:
pip install apache-airflowOnce the package completes installing, you’ll need to create all the components of an Airflow project, such as setting your Airflow home directory, creating an airflow.cfg file, spinning up the metadata database, and much more. This can be a lot of work, and require quite a bit of prerequisite experience with Airflow. Luckily, there is a much easier way with the Astro CLI.
Prerequisites:
python3 installedAstronomer, a managed Airflow provider, provides a number of free tools to help make working with Airflow easier. One of these tools is the Astro CLI.
The Astro CLI makes it easy to create and manage everything you need to run Airflow. To get started, you’ll first have to install the CL. To do this on your machine, check out this link to Astronomer’s documentation, and follow the steps for your operating system.
Once the Astro CLI is installed, configuring an entire Airflow project takes only one command:
astro dev initThis will configure all the resources needed for an Airflow project in your current working directory. Your current working directory will then look something like this:
.
├── dags/
├── include/
├── plugins/
├── tests/
├── airflow_settings.yaml
├── Dockerfile
├── packages.txt
└── requirements.txt
Once the project has been created, to start the project, run astro dev start. After about a minute, you can open the Airflow UI in your browser, at the address https://localhost:8080/. Now, you’re ready to write your first DAG!
We’ve covered the basics and more advanced features of Airflow’s framework and architecture. Now that Airflow has been installed, you’re ready to write your first DAG. First, create a file called sample_dag.py in the dags/ directory of the Airflow project you just created. Using your favorite text editor or IDE, open the sample_dag.py file. First, let’s instantiate the DAG.
from airflow import DAG
from datetime import datetime
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
...
Above, we use the DAG function from the airflow module to define a DAG in conjunction with the with context-manager.
A start_date, schedule interval, and value for catchup are provided. This DAG will run each day at 9:00 AM UTC. Since catchup is set to True, this DAG will run for each day between the day it is first triggered and January 1, 2024, and max_active_runs=1 ensures that only one DAG can run at a time.
Now, let’s add a few tasks! First, we’ll create a task to mock extracting data from an API. Check out the code below:
...
# Import the PythonOperator
from airflow.operators.python import PythonOperator
...
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
Next, we’ll want to create a task to transform the data returned by the extract_data task. This can be done with the following code. Here, we’re using an Airflow feature called XComs to retrieve data from the previous task.
Since render_templat_as_native_obj is set to True, these values are shared as Python objects rather than strings. The raw data from the extract_data task is then passed to the transform_data_callable as a keyword argument. This data is then transformed and returned, where it will be used by the load_data task in a similar manner.
...
# Import pandas
import pandas as pd
...
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
...
Finally, dependencies are set between tasks. The code here sets dependencies between the extract_data, transform_data, and load_data tasks to create a basic ETL DAG.
...
extract_data >> transform_data >> load_data
The final product will look like this!
from airflow import DAG
from datetime import datetime
from airflow.operators.python import PythonOperator
import pandas as pd
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
# Set dependencies between tasks
extract_data >> transform_data >> load_data
Once you’ve defined your pipeline as Python code, you can use the Airflow UI to turn on your DAG. Click on the weather_etl DAG and toggle on the switch in the upper left. Watch as your tasks and DAG run successfully complete.
Congrats, you’ve written and run your first Airflow DAG!
In addition to using traditional operators, Airflow has introduced the TaskFlow API, which makes it easier to define DAGs and tasks using decorators and native Python code.
Rather than explicitly using XComs to share data between tasks, the TaskFlow API abstracts away this logic, instead using XComs behind the scenes. The code below shows the same exact logic and functionality as above, this time implemented with the TaskFlow API, which is more intuitive for data analysts and scientists used to build script-based ETL logic.
from airflow.decorators import dag, task
from datetime import datetime
import pandas as pd
@dag(
start_date=datetime(year=2023, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1
)
def weather_etl():
@task()
def extract_data():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
@task()
def transform_data(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
@task()
def load_data(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
# Set dependencies using function calls
raw_dataset = extract_data()
transformed_dataset = transform_data(raw_dataset)
load_data(transformed_dataset)
# Allow the DAG to be run
weather_etl()
Building Airflow DAGs can be tricky. There are a few best practices to keep in mind when building data pipelines and workflows, not only with Airflow, but with other tooling.
With tasks, Airflow helps to make modularity easier to visualize. Don’t try to do too much in a single task. While an entire ETL pipeline can be built in a single task, this would make troubleshooting difficult. It would also make visualizing the performance of a DAG difficult.
When creating a task, it’s important to make sure the task will only do one thing, much like functions in Python.
Take a look at the example below. Both DAGs do the same thing and fail at the same point in the code. However, in the DAG on the left, it’s clear that the load logic is causing the failure, while this is not quite clear from the DAG on the right.
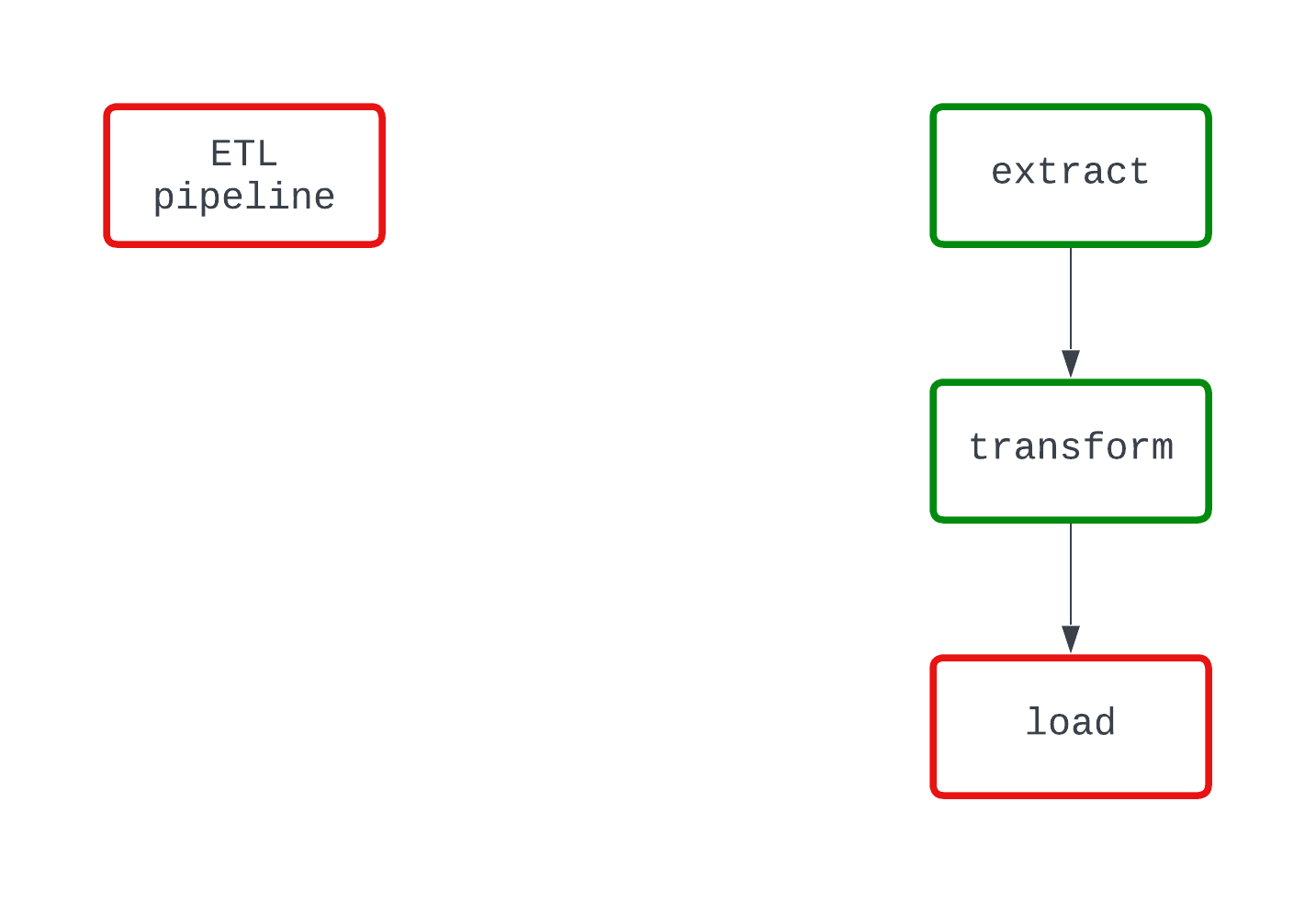
A deterministic process is one that produces the same result, given the same input. When a DAG runs for a specific interval, it should generate the same results every time. While a more complex characteristic of data pipelines, determinism is important to ensure consistent results.
With Airflow, leverage Jinja-templating to pass templated fields into Airflow operators rather than using the datetime.now() function to create temporal data.
What happens if you run a DAG for the same interval twice? How about 10 times? Will you end up with duplicate data in your target storage medium? Idempotency ensures that even if a data pipeline is executed multiple times, it was as if the pipeline was only executed once.
To make data pipelines deterministic, think about incorporating the following logic into your DAGs:
INSERTing, which may cause duplicates.Airflow isn’t meant to process massive amounts of data. If looking to run transformations on more than a couple gigabytes of data, Airflow is still the right tool for the job; however, Airflow should be invoking another tool, such as dbt or Databricks, to run the transformation.
Typically, tasks are executed locally on your machine or with worker nodes in production. Either way, only a few gigabytes of memory will be available for any computational work that is needed.
Focus on using Airflow for very light data transformation and as an orchestration tool when wrangling larger data.
With Airflow’s ability to define data pipelines as code and its wide variety of connectors and operators, companies across the world rely on Airflow to help power their data platforms.
In industry, a data team may work with a wide variety of tools, from SFTP sites to cloud file storage systems to a data lakehouse. To build a data platform, it’s paramount for these disparate systems to be integrated.
With a vibrant open-source community, there are thousands of prebuilt connectors to help integrate your data tooling. Want to drop a file from S3 into Snowflake? Lucky for you, the S3ToSnowflakeOperator makes it easy to do just that! How about data quality checks with Great Expectations? That’s already been built too.
If you can’t find the right prebuilt tool for the job, that’s okay. Airflow is extensible, making it easy for you to build your own custom tools to meet your needs.
When running Airflow in production, you’ll also want to think about the tooling that you’re using to manage the infrastructure. There are a number of ways to do this, with premium offerings such as Astronomer, cloud-native options like MWAA, or even a homegrown solution.
Typically, this involves a tradeoff between cost and infrastructure management; more expensive solutions may mean less to manage, while running everything on a single EC2 instance may be inexpensive but tricky to maintain.
Apache Airflow is an industry-leading tool for running data pipelines in production. Providing functionality such as scheduling, extensibility, and observability while allowing data analysts, scientists, and engineers to define data pipelines as code, Airflow helps data professionals focus on making business impact.
It’s easy to get started with Airflow, especially with the Astro CLI, and traditional operators and the TaskFlow API make it simple to write your first DAGs. When building data pipelines with Airflow, make sure to keep modularity, determinism, and idempotency at the forefront of your design decisions; these best practices will help you avoid headaches down the road, especially when your DAGs encounter an error.
With Airflow, there’s tons to learn. For your next data analytics or data science project, give Airflow a try. Experiment with prebuilt operators, or build your own. Try sharing data between tasks with traditional operators and the TaskFlow API. Don’t be afraid to push the limits. If you’re ready to get started, check out DataCamp’s Introduction to Airflow in Python course, which covers the basics of Airflow and explores how to implement complex data engineering pipelines in production.
You can also start our Introduction to Data Pipelines course, which will help you hone the skills to build effective, performant, and reliable data pipelines. Finally, you can check out our comparison of Airflow vs Prefect to see which is the best tool for you.
If you want more, check out some of the resources below. Best of luck, and happy coding!
https://airflow.apache.org/docs/apache-airflow/stable/project.html
https://airflow.apache.org/blog/airflow-survey-2022/
https://airflow.apache.org/docs/apache-airflow/1.10.9/installation.html
https://docs.astronomer.io/astro/cli/get-started-cli
https://airflow.apache.org/docs/apache-airflow/stable/tutorial/taskflow.html
https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html
Start Your Data Pipelines Journey Today
Course
Course
blog
Don Kaluarachchi
15 min
Tutorial
Jake Roach
Tutorial
Amberle McKee
code-along
Jake McGrath
code-along
Mike Metzger
code-along
Jake Roach



