
Curso
Ingestão de dados simplificada com pandas
4 h
62.8K
A estrutura do Airflow, bem como sua arquitetura, tem vários recursos importantes que o tornam único. Primeiro, vamos nos aprofundar um pouco mais nos recursos mais importantes da estrutura do Airflow.
A unidade mais simples da estrutura do Airflow são as tarefas. As tarefas podem ser consideradas como operações ou, para a maioria das equipes de dados, operações em um pipeline de dados.
Um fluxo de trabalho tradicional de ETL tem três tarefas: extrair, transformar e carregar dados. As dependências definem os relacionamentos entre as tarefas. Voltando ao nosso exemplo de ETL, a tarefa "load" (carregar) depende da tarefa "transform" (transformar), que, por sua vez, depende da tarefa "extract" (extrair). A combinação de tarefas e dependências cria DAGs, ou gráficos acíclicos direcionados. Os DAGs representam pipelines de dados no Airflow e são um pouco complicados de definir. Em vez disso, vamos dar uma olhada em um diagrama de um pipeline básico de ETL:
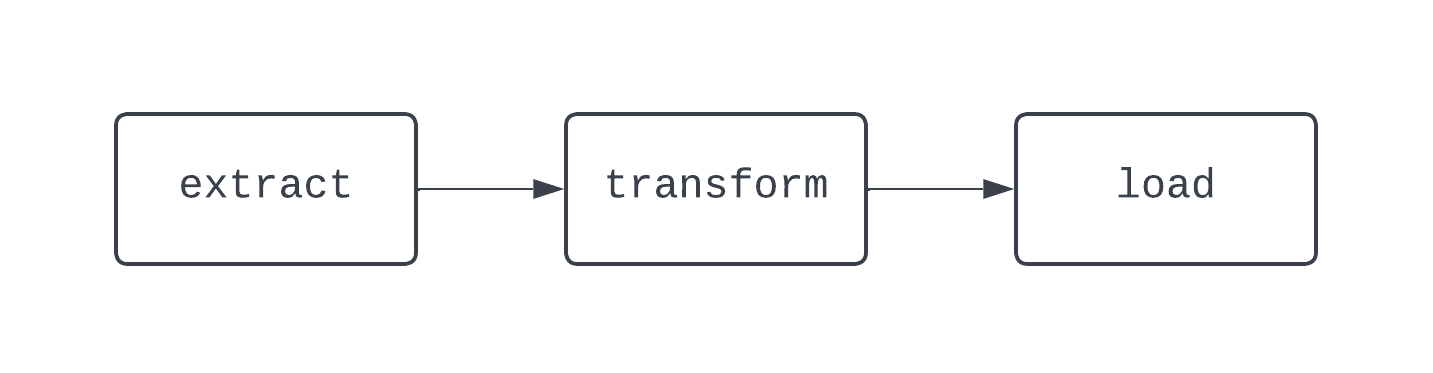
O DAG acima tem três tarefas, com duas dependências. Ele é considerado um DAG porque não há loops (ou ciclos) entre as tarefas. Aqui, as setas mostram a natureza direcionada do processo; primeiro, a tarefa extract é executada, seguida pelas tarefas transform e load. Com os DAGs, é fácil ver um início e um fim distintos para o processo, mesmo que a lógica seja complexa, como o DAG mostrado abaixo:
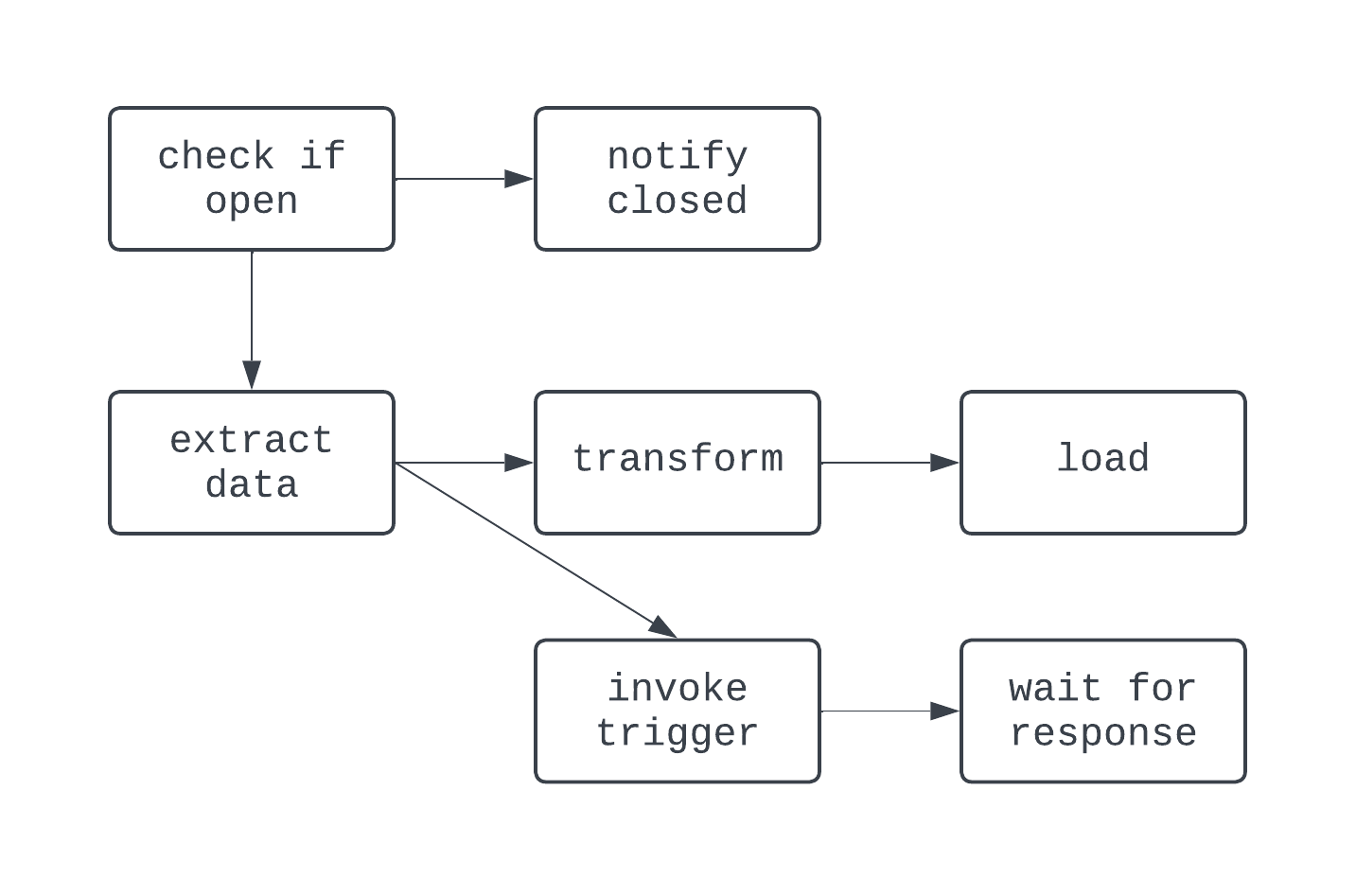
Nesse DAG, a lógica é um pouco mais maluca. Há uma ramificação baseada em uma condição e algumas tarefas são executadas em paralelo. No entanto, o gráfico é direcionado e não há dependências cíclicas entre as tarefas. Agora, vamos dar uma olhada em um processo que não é um DAG:
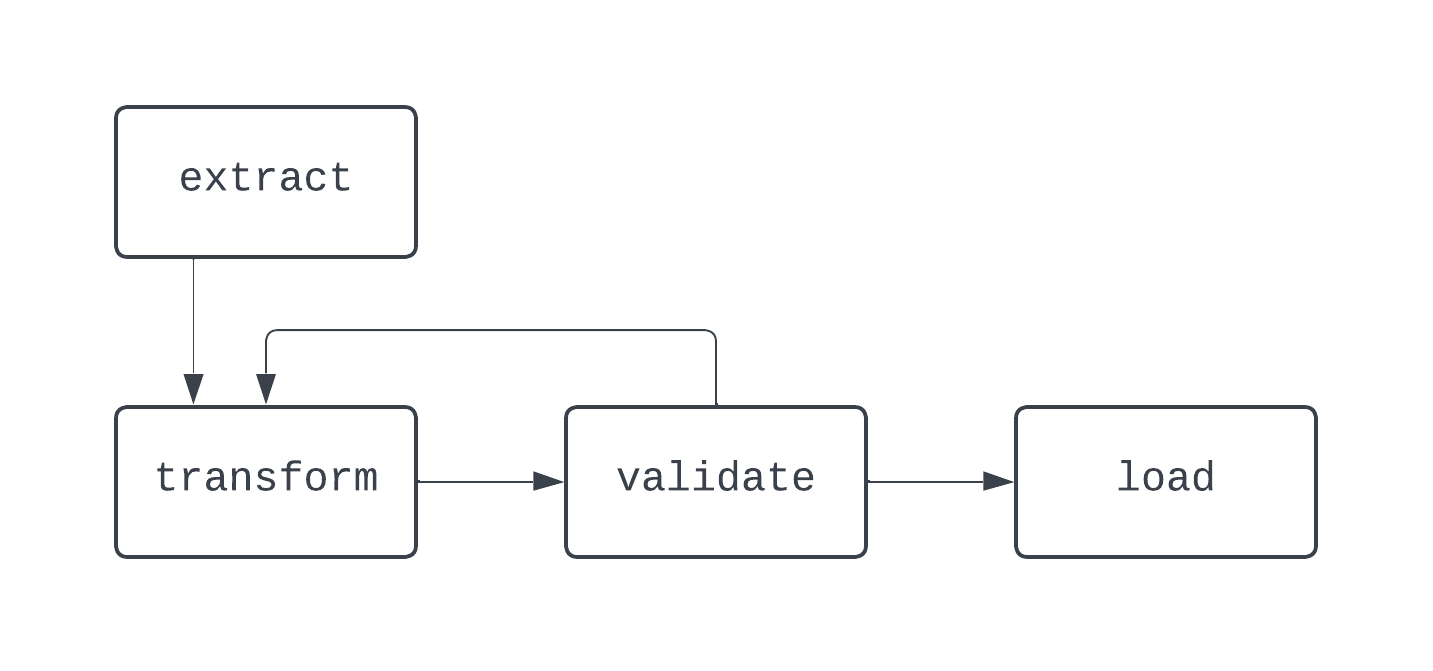
Nesse diagrama, há um loop distinto entre as tarefas transform e validate. Em alguns casos, esse DAG pode ser executado para sempre, se não houver nenhuma maneira de sair desse loop.
Ao criar pipelines de dados, mesmo fora do Airflow, é uma prática recomendada evitar a criação de fluxos de trabalho que não possam ser representados como DAGs, pois você pode perder recursos importantes, como determinismo ou idempotência.
Para agendar DAGs, executar tarefas e fornecer visibilidade dos detalhes de execução do pipeline de dados, o Airflow utiliza uma arquitetura baseada em Python composta pelos componentes abaixo:
Seja executando o Airflow localmente ou em um ambiente de produção, cada um desses componentes deve estar em funcionamento para que o Airflow funcione corretamente.
O agendador é responsável (você já deve ter adivinhado) pelo agendamento de DAGs. Para agendar um DAG, uma data de início e um intervalo de agendamento para o DAG devem ser fornecidos quando o DAG for escrito como código Python.
Depois que um DAG é agendado, as tarefas dentro desses DAGs precisam ser executadas, e é aí que entra o executor. O executor não executa a lógica em cada tarefa; ele apenas aloca a tarefa para ser executada por quaisquer recursos configurados para isso. O banco de dados de metadados armazena informações sobre as execuções do DAG, como, por exemplo, se o DAG e suas tarefas associadas foram executados com êxito ou não.
O banco de dados de metadados também armazena informações como variáveis e conexões definidas pelo usuário, que ajudam na criação de pipelines de dados de nível de produção. Por fim, o servidor da Web fornece a interface do usuário com o Airflow.
Essa interface de usuário, ou UI, fornece às equipes de dados uma ferramenta central para gerenciar a execução do pipeline. Na interface de usuário do Airflow, as equipes de dados podem visualizar o estado de seus DAGs, reexecutar manualmente o DAG, armazenar variáveis e conexões e muito mais. A interface de usuário do Airflow oferece visibilidade central dos processos de ingestão e entrega de dados, ajudando a manter as equipes de dados informadas e cientes do desempenho do pipeline de dados.
Há várias maneiras de instalar o Apache Airflow. Abordaremos dois dos mais comuns.
pipPré-requisitos:
python3 instaladoPara instalar o Airflow com pip, a forma de pacote do Python, você pode executar o seguinte comando:
pip install apache-airflowApós a conclusão da instalação do pacote, você precisará criar todos os componentes de um projeto do Airflow, como definir o diretório inicial do Airflow, criar um arquivo airflow.cfg, ativar o banco de dados de metadados e muito mais. Isso pode dar muito trabalho e exigir um pouco de experiência prévia com o Airflow. Felizmente, há uma maneira muito mais fácil com a CLI do Astro.
Pré-requisitos:
python3 instaladoO Astronomer, um provedor de Airflow gerenciado, oferece várias ferramentas gratuitas para ajudar a facilitar o trabalho com o Airflow. Uma dessas ferramentas é a CLI do Astro.
A CLI do Astro facilita a criação e o gerenciamento de tudo o que você precisa para executar o Airflow. Para começar, primeiro você precisa instalar o CL. Para fazer isso em seu computador, confira este link para a documentação do Astronomer e siga as etapas para seu sistema operacional.
Depois que a CLI do Astro é instalada, a configuração de um projeto Airflow inteiro requer apenas um comando:
astro dev initIsso configurará todos os recursos necessários para um projeto do Airflow no seu diretório de trabalho atual. Seu diretório de trabalho atual terá a seguinte aparência:
.
├── dags/
├── include/
├── plugins/
├── tests/
├── airflow_settings.yaml
├── Dockerfile
├── packages.txt
└── requirements.txt
Depois que o projeto tiver sido criado, para iniciá-lo, execute astro dev start. Após cerca de um minuto, você poderá abrir a interface do usuário do Airflow em seu navegador, no endereço https://localhost:8080/. Agora, você está pronto para escrever seu primeiro DAG!
Cobrimos os recursos básicos e mais avançados da estrutura e da arquitetura do Airflow. Agora que o Airflow foi instalado, você está pronto para escrever seu primeiro DAG. Primeiro, crie um arquivo chamado sample_dag.py no diretório dags/ do projeto Airflow que você acabou de criar. Usando seu editor de texto ou IDE favorito, abra o arquivo sample_dag.py. Primeiro, vamos instanciar o DAG.
from airflow import DAG
from datetime import datetime
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
...
Acima, usamos a função DAG do módulo airflow para definir um DAG em conjunto com o gerenciador de contexto with.
São fornecidos um start_date, um intervalo schedule e um valor para catchup. Esse DAG será executado todos os dias às 9:00 AM UTC. Como catchup está definido como True, esse DAG será executado para cada dia entre o dia em que for acionado pela primeira vez e 1º de janeiro de 2024, e max_active_runs=1 garante que somente um DAG possa ser executado por vez.
Agora, vamos adicionar algumas tarefas! Primeiro, criaremos uma tarefa para simular a extração de dados de uma API. Confira o código abaixo:
...
# Import the PythonOperator
from airflow.operators.python import PythonOperator
...
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
Em seguida, queremos criar uma tarefa para transformar os dados retornados pela tarefa extract_data. Isso pode ser feito com o seguinte código. Aqui, estamos usando um recurso do Airflow chamado XComs para recuperar dados da tarefa anterior.
Como render_templat_as_native_obj está definido como True, esses valores são compartilhados como objetos Python em vez de cadeias de caracteres. Os dados brutos da tarefa extract_data são então passados para transform_data_callable como um argumento de palavra-chave. Esses dados são então transformados e retornados, onde serão usados pela tarefa load_data de maneira semelhante.
...
# Import pandas
import pandas as pd
...
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
...
Por fim, as dependências são definidas entre as tarefas. O código aqui define as dependências entre as tarefas extract_data, transform_data e load_data para criar um DAG ETL básico.
...
extract_data >> transform_data >> load_data
O produto final será parecido com este!
from airflow import DAG
from datetime import datetime
from airflow.operators.python import PythonOperator
import pandas as pd
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
# Set dependencies between tasks
extract_data >> transform_data >> load_data
Depois de definir o pipeline como código Python, você pode usar a UI do Airflow para ativar o DAG. Clique no DAG weather_etl e ative a chave no canto superior esquerdo. Observe como suas tarefas e a execução do DAG são concluídas com êxito.
Parabéns, você escreveu e executou seu primeiro Airflow DAG!
Além de usar os operadores tradicionais, o Airflow introduziu a API TaskFlow, que facilita a definição de DAGs e tarefas usando decoradores e código Python nativo.
Em vez de usar explicitamente XComs para compartilhar dados entre tarefas, a API do TaskFlow abstrai essa lógica e, em vez disso, usa XComs nos bastidores. O código abaixo mostra exatamente a mesma lógica e a mesma funcionalidade acima, desta vez implementadas com a API TaskFlow, que é mais intuitiva para analistas de dados e cientistas acostumados a criar lógica ETL baseada em script.
from airflow.decorators import dag, task
from datetime import datetime
import pandas as pd
@dag(
start_date=datetime(year=2023, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1
)
def weather_etl():
@task()
def extract_data():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
@task()
def transform_data(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
@task()
def load_data(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
# Set dependencies using function calls
raw_dataset = extract_data()
transformed_dataset = transform_data(raw_dataset)
load_data(transformed_dataset)
# Allow the DAG to be run
weather_etl()
A criação de DAGs de fluxo de ar pode ser complicada. Há algumas práticas recomendadas que você deve ter em mente ao criar pipelines e fluxos de trabalho de dados, não apenas com o Airflow, mas com outras ferramentas.
Com as tarefas, o Airflow ajuda a tornar a modularidade mais fácil de ser visualizada. Não tente fazer muita coisa em uma única tarefa. Embora todo um pipeline de ETL possa ser criado em uma única tarefa, isso dificultaria a solução de problemas. Isso também dificultaria a visualização do desempenho de um DAG.
Ao criar uma tarefa, é importante que você se certifique de que ela fará apenas uma coisa, assim como as funções em Python.
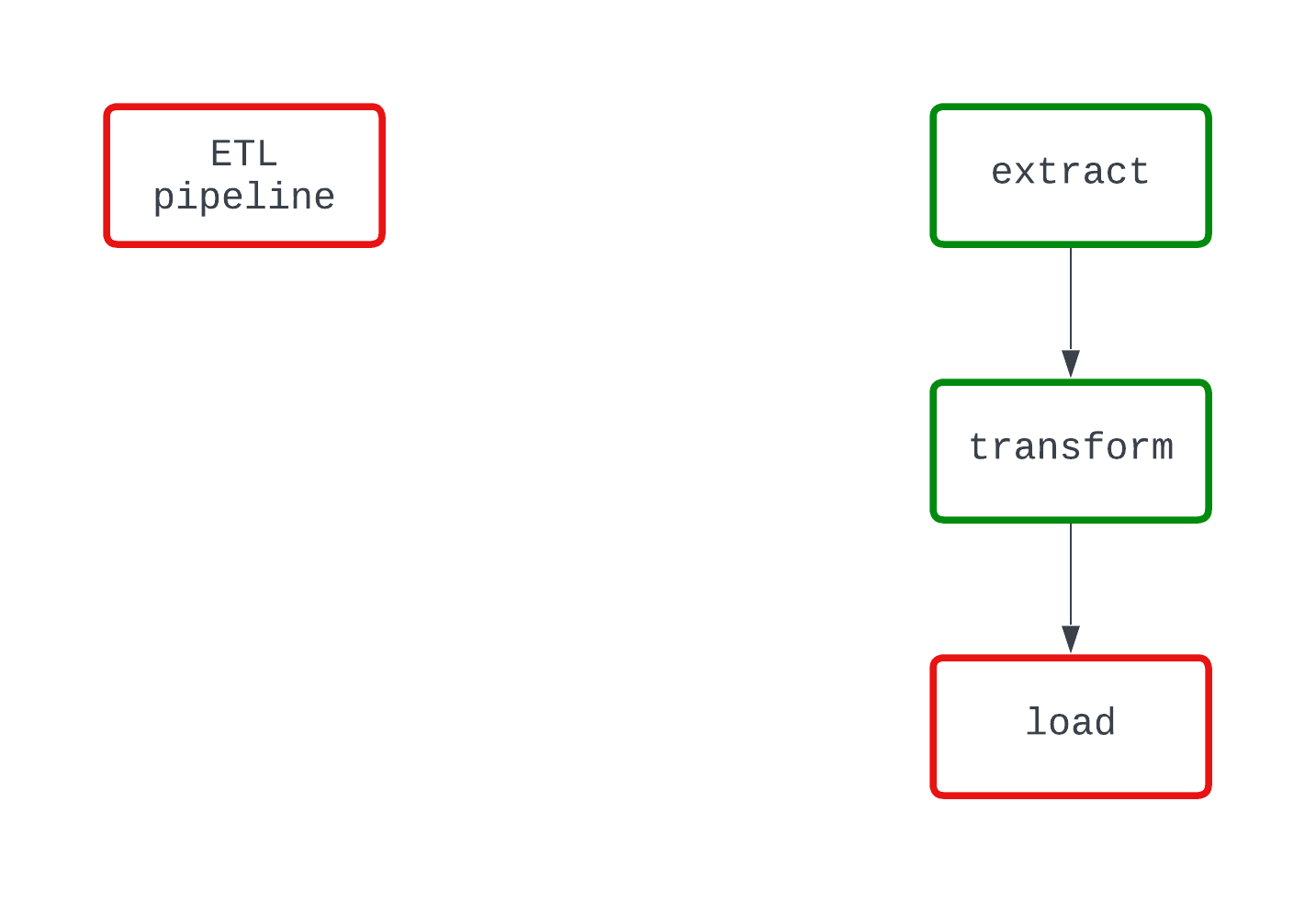
Dê uma olhada no exemplo abaixo. Ambos os DAGs fazem a mesma coisa e falham no mesmo ponto do código. No entanto, no DAG à esquerda, fica claro que a lógica load está causando a falha, enquanto isso não fica muito claro no DAG à direita.
Um processo determinístico é aquele que produz o mesmo resultado, dada a mesma entrada. Quando um DAG é executado em um intervalo específico, ele deve gerar os mesmos resultados todas as vezes. Embora seja uma característica mais complexa dos pipelines de dados, o determinismo é importante para garantir resultados consistentes.
Com o Airflow, aproveite a modelagem Jinja para passar campos modelados para os operadores do Airflow em vez de usar a função datetime.now() para criar dados temporais.
O que acontece se você executar um DAG para o mesmo intervalo duas vezes? Que tal 10 vezes? Você acabará com dados duplicados na mídia de armazenamento de destino? A idempotência garante que, mesmo que um pipeline de dados seja executado várias vezes, é como se o pipeline tivesse sido executado apenas uma vez.
Para tornar os pipelines de dados determinísticos, pense em incorporar a seguinte lógica em seus DAGs:
INSERT, o que pode causar duplicatas.O Airflow não foi projetado para processar grandes quantidades de dados. Se você deseja executar transformações em mais de alguns gigabytes de dados, o Airflow ainda é a ferramenta certa para o trabalho; no entanto, o Airflow deve invocar outra ferramenta, como o dbt ou o Databricks, para executar a transformação.
Normalmente, as tarefas são executadas localmente em seu computador ou com nós de trabalho na produção. De qualquer forma, apenas alguns gigabytes de memória estarão disponíveis para qualquer trabalho computacional necessário.
Concentre-se em usar o Airflow para uma transformação de dados muito leve e como uma ferramenta de orquestração ao lidar com dados maiores.
Com a capacidade do Airflow de definir pipelines de dados como código e sua ampla variedade de conectores e operadores, empresas de todo o mundo confiam no Airflow para ajudar a potencializar suas plataformas de dados.
No setor, uma equipe de dados pode trabalhar com uma grande variedade de ferramentas, desde sites SFTP até sistemas de armazenamento de arquivos na nuvem e um data lakehouse. Para criar uma plataforma de dados, é fundamental que esses sistemas diferentes sejam integrados.
Com uma vibrante comunidade de código aberto, há milhares de conectores pré-construídos para ajudar a integrar suas ferramentas de dados. Você quer soltar um arquivo do S3 no Snowflake? Para a sorte de vocês, o site S3ToSnowflakeOperator facilita exatamente isso! O que você acha das verificações de qualidade dos dados com o Great Expectations? Isso também já foi construído.
Se você não conseguir encontrar a ferramenta pré-construída certa para o trabalho, não tem problema. O Airflow é extensível, o que facilita para você criar suas próprias ferramentas personalizadas para atender às suas necessidades.
Ao executar o Airflow na produção, você também deve pensar nas ferramentas que está usando para gerenciar a infraestrutura. Há várias maneiras de fazer isso, com ofertas premium, como o Astronomer, opções nativas da nuvem, como o MWAA, ou até mesmo uma solução desenvolvida internamente.
Normalmente, isso envolve uma compensação entre o custo e o gerenciamento da infraestrutura; soluções mais caras podem significar menos gerenciamento, enquanto a execução de tudo em uma única instância do EC2 pode ser barata, mas difícil de manter.
O Apache Airflow é uma ferramenta líder do setor para executar pipelines de dados na produção. Ao fornecer funcionalidades como agendamento, extensibilidade e observabilidade, permitindo que analistas de dados, cientistas e engenheiros definam pipelines de dados como código, o Airflow ajuda os profissionais de dados a se concentrarem em causar impacto nos negócios.
É fácil começar a usar o Airflow, especialmente com a CLI do Astro, e os operadores tradicionais e a API do TaskFlow simplificam a criação de seus primeiros DAGs. Ao criar pipelines de dados com o Airflow, certifique-se de manter a modularidade, o determinismo e a idempotência na vanguarda de suas decisões de projeto; essas práticas recomendadas ajudarão você a evitar dores de cabeça no futuro, especialmente quando seus DAGs encontrarem um erro.
Com o Airflow, você tem muito a aprender. Para seu próximo projeto de análise de dados ou ciência de dados, experimente o Airflow. Faça experiências com operadores pré-construídos ou crie o seu próprio. Tente compartilhar dados entre tarefas com operadores tradicionais e a API do TaskFlow. Não tenha medo de ultrapassar os limites. Se você estiver pronto para começar, confira o curso Introdução ao Airflow em Python da DataCamp, que aborda os conceitos básicos do Airflow e explora como implementar pipelines complexos de engenharia de dados na produção.
Você também pode iniciar nosso curso Introdução aos pipelines de dados, que o ajudará a aprimorar as habilidades para criar pipelines de dados eficazes, eficientes e confiáveis. Por fim, você pode conferir nossa comparação entre o Airflow e o Prefect para ver qual é a melhor ferramenta para você.
Se você quiser saber mais, confira alguns dos recursos abaixo. Boa sorte e boa codificação!
https://airflow.apache.org/docs/apache-airflow/stable/project.html
https://airflow.apache.org/blog/airflow-survey-2022/
https://airflow.apache.org/docs/apache-airflow/1.10.9/installation.html
https://docs.astronomer.io/astro/cli/get-started-cli
https://airflow.apache.org/docs/apache-airflow/stable/tutorial/taskflow.html
https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html
Comece sua jornada de pipelines de dados hoje mesmo
Curso
Curso