
Cours
Ingestion de données simplifiée avec pandas
4 h
62.7K
Le cadre d'Airflow, ainsi que son architecture, présentent plusieurs caractéristiques clés qui les rendent uniques. Tout d'abord, examinons plus en détail les principales caractéristiques du cadre d'Airflow.
Les unités les plus simples du système Airflow sont les tâches. Les tâches peuvent être considérées comme des opérations ou, pour la plupart des équipes de données, comme des opérations dans un pipeline de données.
Un flux de travail ETL traditionnel comporte trois tâches : l'extraction, la transformation et le chargement des données. Les dépendances définissent les relations entre les tâches. Pour revenir à notre exemple d'ETL, la tâche "load" dépend de la tâche "transform" qui, à son tour, dépend de la tâche "extract". La combinaison des tâches et des dépendances crée des DAG (directed-acyclic graphs). Les DAGs représentent les pipelines de données dans Airflow, et sont un peu compliqués à définir. Examinons plutôt le diagramme d'un pipeline ETL de base :
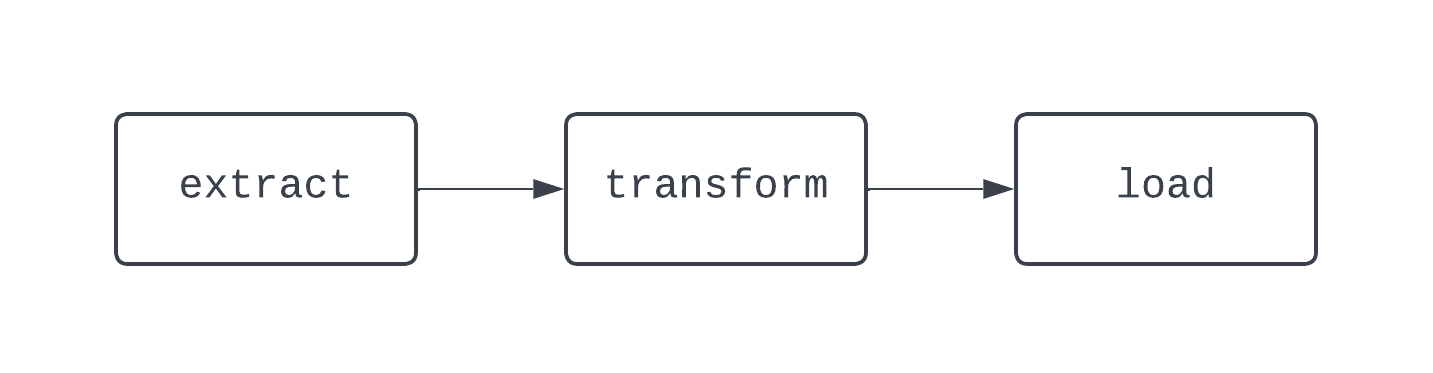
Le DAG ci-dessus comporte trois tâches, avec deux dépendances. Il est considéré comme un DAG parce qu'il n'y a pas de boucles (ou de cycles) entre les tâches. Ici, les flèches montrent la nature dirigée du processus ; la tâche extract est d'abord exécutée, suivie des tâches transform et load. Avec les DAG, il est facile de voir un début et une fin distincts pour le processus, même si la logique est complexe, comme dans le cas du DAG illustré ci-dessous :
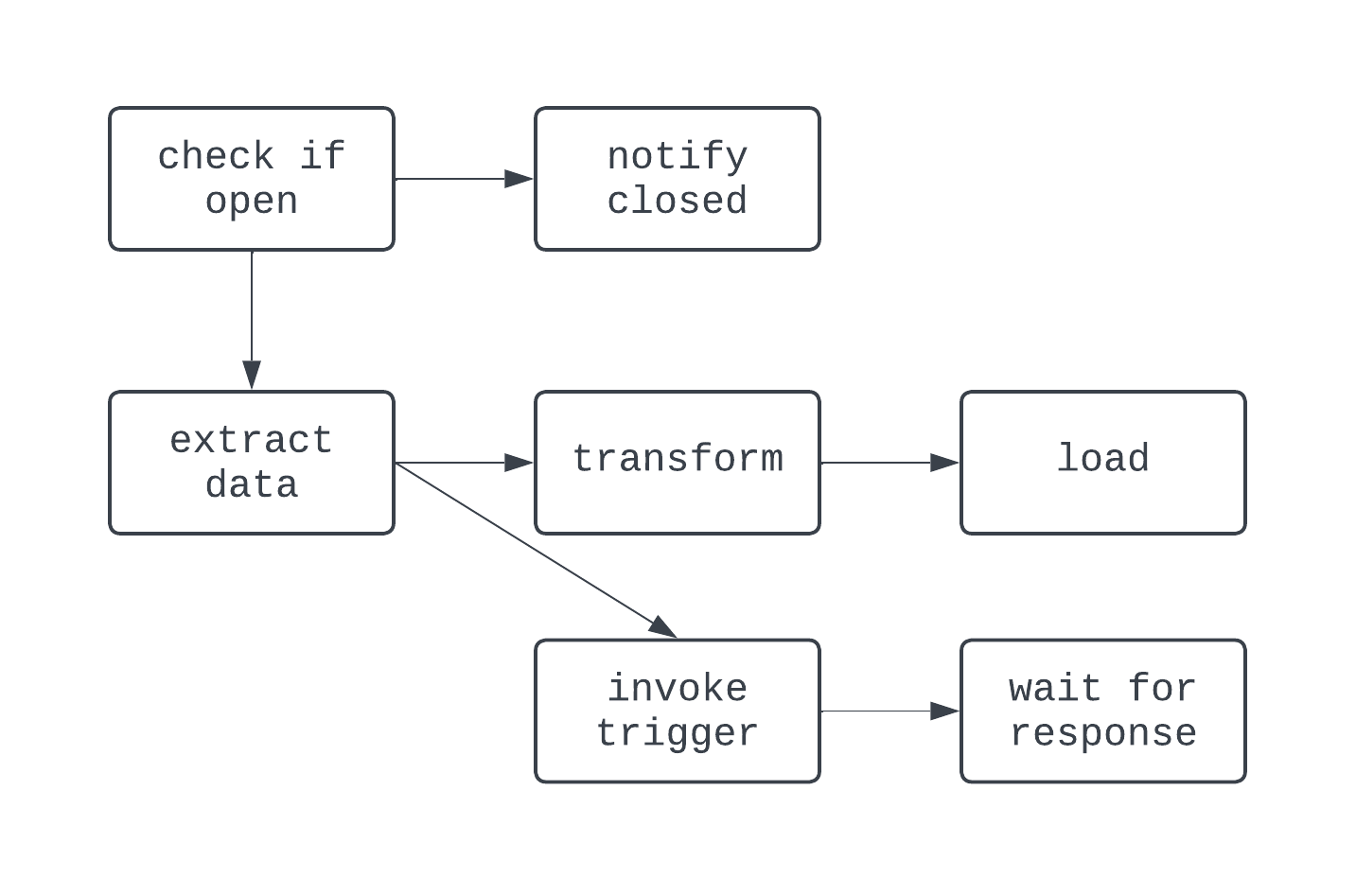
Dans ce DAG, la logique est un peu plus folle. Il y a un branchement basé sur une condition, et quelques tâches sont exécutées en parallèle. Cependant, le graphe est orienté et il n'y a pas de dépendances cycliques entre les tâches. Examinons maintenant un processus qui n'est pas un DAG :
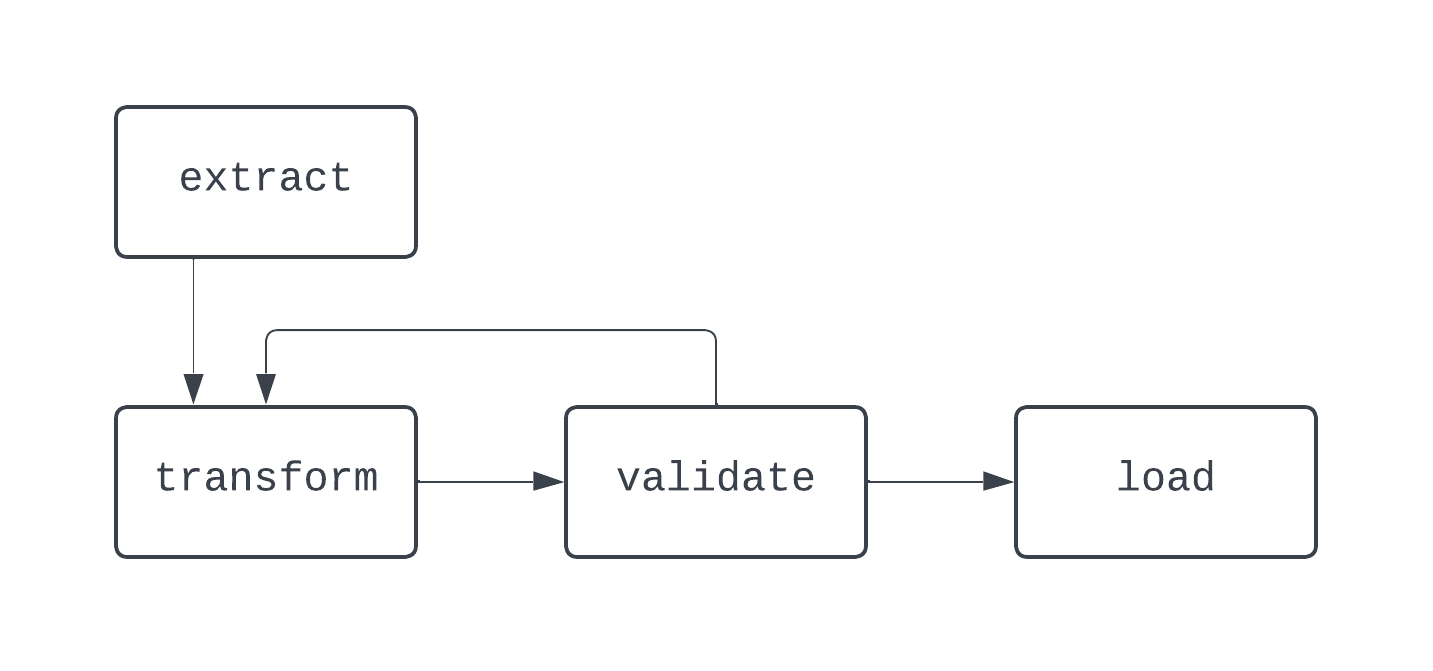
Dans ce diagramme, il existe une boucle distincte entre les tâches transform et validate. Dans certains cas, ce DAG peut fonctionner indéfiniment, s'il n'existe aucun moyen de sortir de cette boucle.
Lorsque vous construisez des pipelines de données, même en dehors d'Airflow, il est préférable d'éviter de créer des workflows qui ne peuvent pas être représentés comme des DAGs, car vous pourriez perdre des caractéristiques clés, telles que le déterminisme ou l'idempotence.
Pour planifier les DAG, exécuter les tâches et fournir une visibilité sur les détails d'exécution du pipeline de données, Airflow s'appuie sur une architecture basée sur Python composée des éléments ci-dessous :
Que vous utilisiez Airflow localement ou dans un environnement de production, chacun de ces composants doit être opérationnel pour que Airflow fonctionne correctement.
L'ordonnanceur est responsable (vous l'avez probablement deviné) de l'ordonnancement des DAG. Pour planifier un DAG, une date de début et un intervalle de planification pour le DAG doivent être fournis lorsque le DAG est écrit sous forme de code Python.
Une fois qu'un DAG est programmé, les tâches qu'il contient doivent être exécutées, et c'est là qu'intervient l'exécuteur. L'exécuteur n'exécute pas la logique de chaque tâche ; il se contente d'allouer la tâche pour qu'elle soit exécutée par les ressources configurées à cet effet. La base de données de métadonnées stocke des informations sur les exécutions de DAG, telles que le succès ou l'échec de l'exécution du DAG et de ses tâches associées.
La base de métadonnées stocke également des informations telles que les variables et les connexions définies par l'utilisateur, ce qui facilite la création de pipelines de données de niveau production. Enfin, le serveur web fournit l'interface utilisateur avec Airflow.
Cette interface utilisateur, ou UI, fournit aux équipes chargées des données un outil central pour gérer l'exécution de leur pipeline. Dans l'interface Airflow, les équipes chargées des données peuvent visualiser l'état de leurs DAG, réexécuter manuellement les DAG, stocker les variables et les connexions, et bien d'autres choses encore. L'interface Airflow offre une visibilité centrale sur les processus d'ingestion et de livraison des données, ce qui permet aux équipes de données d'être informées et conscientes de la performance de leur pipeline de données.
Il existe plusieurs façons d'installer Apache Airflow. Nous aborderons deux des plus courantes.
pipPrérequis :
python3 installéPour installer Airflow à l'aide de pip, la méthode des paquets de Python, vous pouvez exécuter la commande suivante :
pip install apache-airflowUne fois l'installation du paquet terminée, vous devrez créer tous les composants d'un projet Airflow, tels que la configuration de votre répertoire personnel Airflow, la création d'un fichier airflow.cfg, la création de la base de données de métadonnées, et bien d'autres choses encore. Cela peut représenter beaucoup de travail et nécessiter une certaine expérience préalable avec Airflow. Heureusement, il existe un moyen beaucoup plus simple avec l'Astro CLI.
Prérequis :
python3 installéAstronomer, un fournisseur d'Airflow, propose un certain nombre d'outils gratuits pour faciliter l'utilisation d'Airflow. L'un de ces outils est l'Astro CLI.
L'Astro CLI facilite la création et la gestion de tout ce dont vous avez besoin pour faire fonctionner Airflow. Pour commencer, vous devez d'abord installer le CL. Pour le faire sur votre machine, consultez ce lien vers la documentation d'Astronomer, et suivez les étapes correspondant à votre système d'exploitation.
Une fois l'Astro CLI installé, la configuration d'un projet Airflow complet ne nécessite qu'une seule commande :
astro dev initCeci configurera toutes les ressources nécessaires pour un projet Airflow dans votre répertoire de travail actuel. Votre répertoire de travail actuel ressemblera alors à ceci :
.
├── dags/
├── include/
├── plugins/
├── tests/
├── airflow_settings.yaml
├── Dockerfile
├── packages.txt
└── requirements.txt
Une fois le projet créé, pour le lancer, exécutez astro dev start. Après environ une minute, vous pouvez ouvrir l'interface utilisateur Airflow dans votre navigateur, à l'adresse https://localhost:8080/. Vous êtes maintenant prêt à écrire votre premier DAG !
Nous avons couvert les bases et les caractéristiques plus avancées du cadre et de l'architecture d'Airflow. Maintenant qu'Airflow est installé, vous êtes prêt à écrire votre premier DAG. Tout d'abord, créez un fichier appelé sample_dag.py dans le répertoire dags/ du projet Airflow que vous venez de créer. À l'aide de votre éditeur de texte ou IDE préféré, ouvrez le fichier sample_dag.py. Commençons par instancier le DAG.
from airflow import DAG
from datetime import datetime
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
...
Ci-dessus, nous utilisons la fonction DAG du module airflow pour définir un DAG en conjonction avec le gestionnaire de contexte with.
Un start_date, un intervalle schedule et une valeur pour catchup sont fournis. Ce DAG sera exécuté chaque jour à 9h00 UTC. Comme catchup a la valeur True, ce DAG s'exécutera chaque jour entre le jour de son premier déclenchement et le 1er janvier 2024, et max_active_runs=1 garantit qu'un seul DAG peut s'exécuter à la fois.
Ajoutons maintenant quelques tâches ! Tout d'abord, nous allons créer une tâche pour simuler l'extraction de données à partir d'une API. Consultez le code ci-dessous :
...
# Import the PythonOperator
from airflow.operators.python import PythonOperator
...
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
Ensuite, nous allons créer une tâche pour transformer les données renvoyées par la tâche extract_data. Pour ce faire, vous pouvez utiliser le code suivant. Ici, nous utilisons une fonctionnalité d'Airflow appelée XComs pour récupérer les données de la tâche précédente.
Étant donné que render_templat_as_native_obj est défini sur True, ces valeurs sont partagées comme des objets Python plutôt que comme des chaînes de caractères. Les données brutes de la tâche extract_data sont ensuite transmises à la tâche transform_data_callable en tant que mot-clé. Ces données sont ensuite transformées et renvoyées, où elles seront utilisées par la tâche load_data de la même manière.
...
# Import pandas
import pandas as pd
...
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
...
Enfin, des dépendances sont établies entre les tâches. Le code ici définit les dépendances entre les tâches extract_data, transform_data, et load_data pour créer un DAG ETL de base.
...
extract_data >> transform_data >> load_data
Le produit final ressemblera à ceci !
from airflow import DAG
from datetime import datetime
from airflow.operators.python import PythonOperator
import pandas as pd
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
# Set dependencies between tasks
extract_data >> transform_data >> load_data
Une fois que vous avez défini votre pipeline sous forme de code Python, vous pouvez utiliser l'interface utilisateur Airflow pour activer votre DAG. Cliquez sur le DAG weather_etl et activez l'interrupteur en haut à gauche. Observez l'exécution réussie de vos tâches et de votre DAG.
Félicitations, vous avez écrit et exécuté votre premier DAG Airflow !
En plus d'utiliser les opérateurs traditionnels, Airflow a introduit l'API TaskFlow, qui facilite la définition des DAG et des tâches à l'aide de décorateurs et de code Python natif.
Plutôt que d'utiliser explicitement les XComs pour partager des données entre les tâches, l'API TaskFlow fait abstraction de cette logique et utilise les XComs en coulisses. Le code ci-dessous montre exactement la même logique et la même fonctionnalité que ci-dessus, mais cette fois-ci avec l'API TaskFlow, qui est plus intuitive pour les analystes de données et les scientifiques habitués à construire une logique ETL basée sur des scripts.
from airflow.decorators import dag, task
from datetime import datetime
import pandas as pd
@dag(
start_date=datetime(year=2023, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1
)
def weather_etl():
@task()
def extract_data():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
@task()
def transform_data(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
@task()
def load_data(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
# Set dependencies using function calls
raw_dataset = extract_data()
transformed_dataset = transform_data(raw_dataset)
load_data(transformed_dataset)
# Allow the DAG to be run
weather_etl()
La construction de DAG de flux d'air peut s'avérer délicate. Il y a quelques bonnes pratiques à garder à l'esprit lorsque vous construisez des pipelines de données et des flux de travail, non seulement avec Airflow, mais aussi avec d'autres outils.
Avec les tâches, Airflow aide à rendre la modularité plus facile à visualiser. N'essayez pas d'en faire trop en une seule tâche. Bien qu'un pipeline ETL complet puisse être construit en une seule tâche, cela rendrait le dépannage difficile. Cela rendrait également difficile la visualisation des performances d'un DAG.
Lors de la création d'une tâche, il est important de s'assurer que la tâche ne fera qu'une seule chose, un peu comme les fonctions dans Python.
Regardez l'exemple ci-dessous. Les deux DAG font la même chose et échouent au même endroit du code. Toutefois, dans le DAG de gauche, il est clair que la logique load est à l'origine de l'échec, alors que ce n'est pas tout à fait clair dans le DAG de droite.
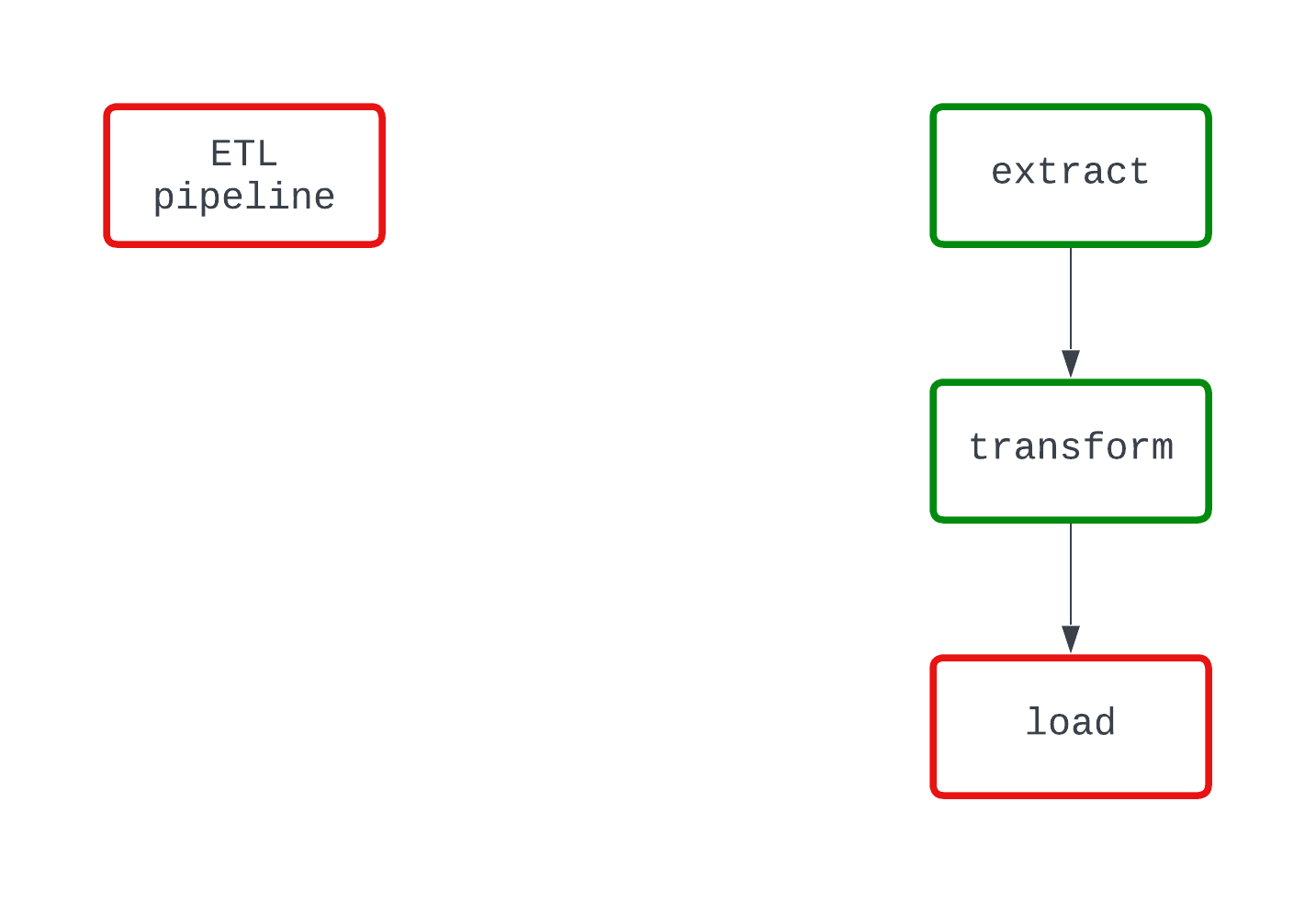
Un processus déterministe est un processus qui produit le même résultat avec les mêmes données d'entrée. Lorsqu'un DAG s'exécute pendant un intervalle spécifique, il doit produire les mêmes résultats à chaque fois. Bien qu'il s'agisse d'une caractéristique plus complexe des pipelines de données, le déterminisme est important pour garantir des résultats cohérents.
Avec Airflow, tirez parti de la modélisation Jinja pour passer des champs modélisés dans les opérateurs Airflow plutôt que d'utiliser la fonction datetime.now() pour créer des données temporelles.
Que se passe-t-il si vous exécutez un DAG deux fois pour le même intervalle ? Que diriez-vous de 10 fois ? Vous retrouverez-vous avec des données en double sur votre support de stockage cible ? L'idempotence garantit que même si un pipeline de données est exécuté plusieurs fois, c'est comme s'il n'avait été exécuté qu'une seule fois.
Pour rendre les pipelines de données déterministes, pensez à incorporer la logique suivante dans vos DAG :
INSERT, ce qui peut entraîner des doublons.Airflow n'est pas conçu pour traiter des quantités massives de données. Si vous souhaitez exécuter des transformations sur plus de quelques gigaoctets de données, Airflow reste l'outil adéquat. Cependant, Airflow devrait invoquer un autre outil, tel que dbt ou Databricks, pour exécuter la transformation.
En règle générale, les tâches sont exécutées localement sur votre machine ou avec des nœuds de travail en production. Quoi qu'il en soit, seuls quelques gigaoctets de mémoire seront disponibles pour tout travail de calcul nécessaire.
Concentrez-vous sur l'utilisation d'Airflow pour la transformation de données très légères et comme outil d'orchestration lorsque vous traitez des données plus volumineuses.
Grâce à la capacité d'Airflow à définir des pipelines de données sous forme de code et à sa grande variété de connecteurs et d'opérateurs, les entreprises du monde entier font confiance à Airflow pour alimenter leurs plateformes de données.
Dans l'industrie, une équipe chargée des données peut travailler avec une grande variété d'outils, des sites SFTP aux systèmes de stockage de fichiers dans le cloud en passant par un lac de données. Pour construire une plateforme de données, il est primordial d'intégrer ces systèmes disparates.
Grâce à une communauté open-source dynamique, il existe des milliers de connecteurs prédéfinis pour faciliter l'intégration de vos outils de données. Vous souhaitez déposer un fichier depuis S3 dans Snowflake ? Heureusement pour vous, le site S3ToSnowflakeOperator vous permet de le faire facilement. Que diriez-vous d'un contrôle de la qualité des données avec Great Expectations ? Elle a déjà été construite.
Si vous ne trouvez pas l'outil préfabriqué qui convient à votre travail, ce n'est pas grave. Airflow est extensible, ce qui vous permet de créer facilement vos propres outils personnalisés pour répondre à vos besoins.
Lorsque vous utilisez Airflow en production, vous devez également penser à l'outil que vous utilisez pour gérer l'infrastructure. Il existe plusieurs façons de procéder, avec des offres premium comme Astronomer, des options cloud-natives comme MWAA, ou même une solution maison.
Généralement, cela implique un compromis entre le coût et la gestion de l'infrastructure ; des solutions plus coûteuses peuvent signifier moins à gérer, tandis que tout exécuter sur une seule instance EC2 peut être peu coûteux mais délicat à maintenir.
Apache Airflow est un outil de pointe pour l'exécution de pipelines de données en production. En offrant des fonctionnalités telles que la planification, l'extensibilité et l'observabilité, tout en permettant aux analystes de données, aux scientifiques et aux ingénieurs de définir des pipelines de données sous forme de code, Airflow aide les professionnels des données à se concentrer sur l'impact commercial.
Il est facile de démarrer avec Airflow, en particulier avec l'Astro CLI, et les opérateurs traditionnels et l'API TaskFlow facilitent l'écriture de vos premiers DAGs. Lorsque vous construisez des pipelines de données avec Airflow, assurez-vous de garder la modularité, le déterminisme et l'idempotence au premier plan de vos décisions de conception ; ces meilleures pratiques vous aideront à éviter les maux de tête à l'avenir, en particulier lorsque vos DAGs rencontrent une erreur.
Avec Airflow, il y a beaucoup à apprendre. Pour votre prochain projet d'analyse de données ou de science des données, essayez Airflow. Expérimentez les opérateurs prédéfinis ou créez les vôtres. Essayez de partager des données entre les tâches avec les opérateurs traditionnels et l'API TaskFlow. N'ayez pas peur de repousser les limites. Si vous êtes prêt à commencer, consultez le cours Introduction à Airflow en Python de DataCamp, qui couvre les bases d'Airflow et explore comment mettre en œuvre des pipelines d'ingénierie de données complexes en production.
Vous pouvez également commencer notre cours Introduction aux pipelines de données, qui vous aidera à perfectionner les compétences nécessaires pour construire des pipelines de données efficaces, performants et fiables. Enfin, vous pouvez consulter notre comparatif Airflow vs Prefect pour savoir quel est le meilleur outil pour vous.
Si vous souhaitez en savoir plus, consultez les ressources ci-dessous. Bonne chance et bon codage !
https://airflow.apache.org/docs/apache-airflow/stable/project.html
https://airflow.apache.org/blog/airflow-survey-2022/
https://airflow.apache.org/docs/apache-airflow/1.10.9/installation.html
https://docs.astronomer.io/astro/cli/get-started-cli
https://airflow.apache.org/docs/apache-airflow/stable/tutorial/taskflow.html
https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html
Commencez dès aujourd'hui votre voyage vers les pipelines de données
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach