
Corso
Acquisizione dati semplificata con pandas
4 h
63.2K
Il framework di Airflow, così come la sua architettura, hanno diverse caratteristiche chiave che lo rendono unico. Per prima cosa, analizziamo più a fondo le funzionalità più importanti del framework di Airflow.
L’unità più semplice del framework di Airflow è il task. I task possono essere considerati come operazioni o, per la maggior parte dei team dati, operazioni in una pipeline di dati.
Un tradizionale workflow ETL ha tre task: estrazione, trasformazione e caricamento dei dati. Le dipendenze definiscono le relazioni tra i task. Tornando al nostro esempio ETL, il task di “load” dipende dal task di “transform” che, a sua volta, dipende dal task di “extract”. La combinazione di task e dipendenze crea i DAG, ovvero grafi aciclici direzionati. I DAG rappresentano le pipeline di dati in Airflow e sono un po’ contorti da definire. Invece, diamo un’occhiata a un diagramma di una pipeline ETL di base:
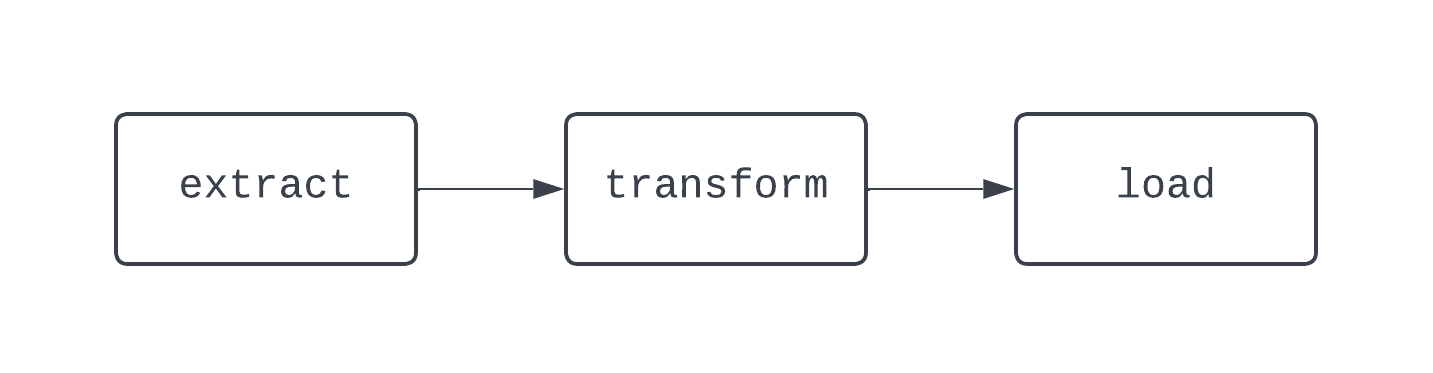
Il DAG sopra ha tre task, con due dipendenze. È considerato un DAG perché non ci sono loop (o cicli) tra i task. Qui le frecce mostrano la natura direzionale del processo; prima viene eseguito il task extract, seguito dai task transform e load. Con i DAG è facile vedere un inizio e una fine distinti del processo, anche se la logica è complessa, come nel DAG mostrato sotto:
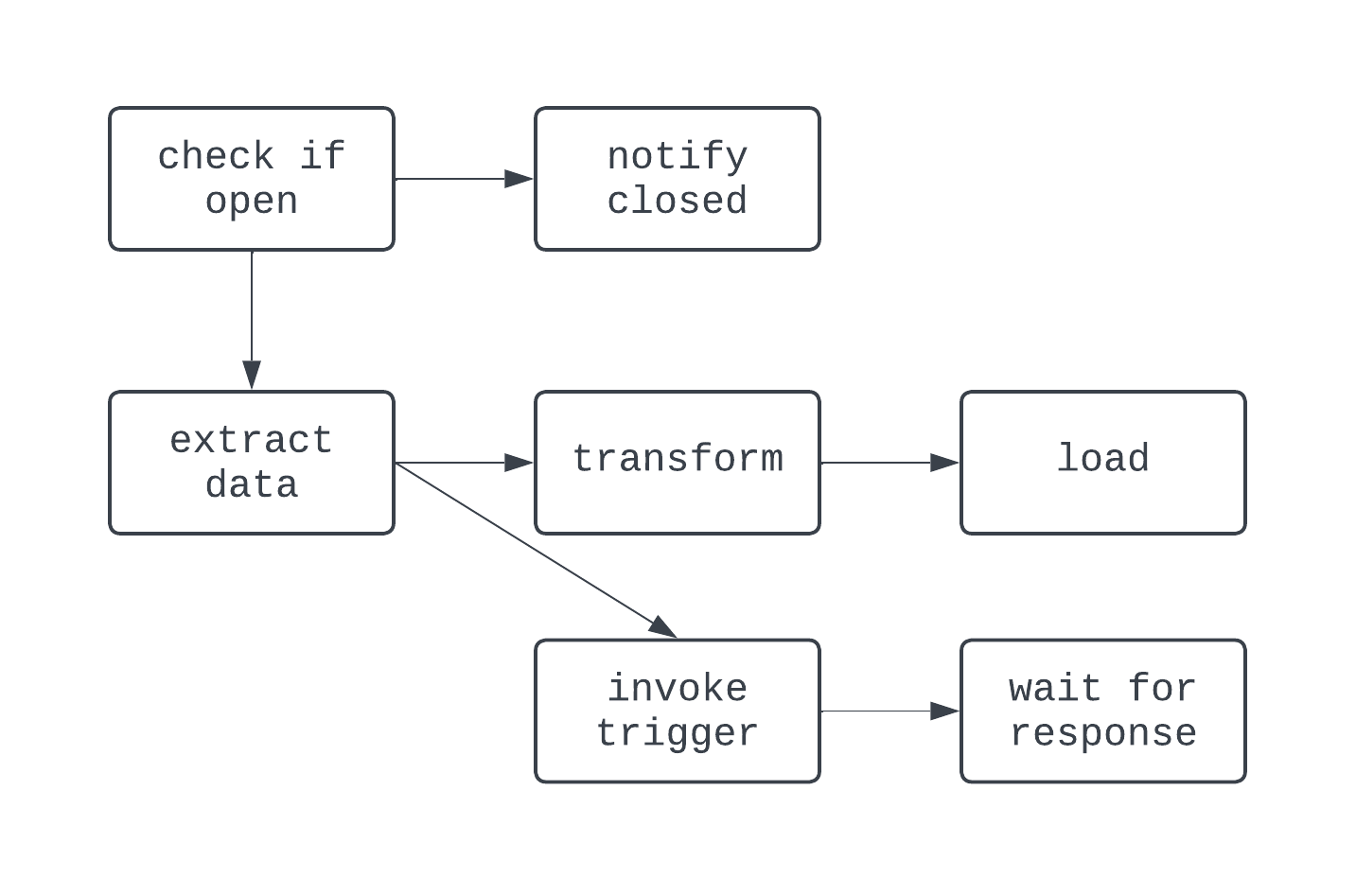
In questo DAG, la logica è un po’ più movimentata. C’è un branching basato su una condizione e alcuni task vengono eseguiti in parallelo. Tuttavia, il grafo è direzionato e non ci sono dipendenze cicliche tra i task. Ora, vediamo un processo che non è un DAG:
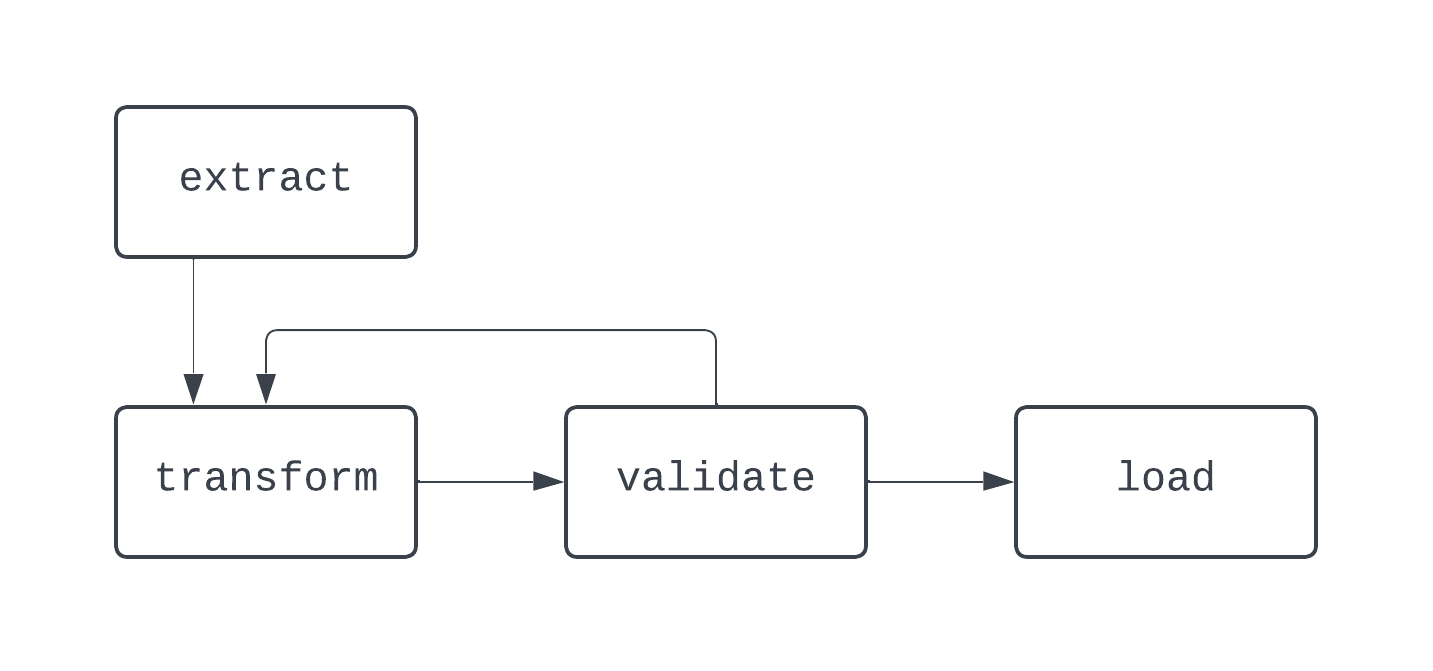
In questo diagramma, c’è un loop evidente tra i task transform e validate. In alcuni casi, questo DAG potrebbe andare avanti all’infinito, se non esiste un modo per uscire da questo loop.
Quando costruisci pipeline di dati, anche al di fuori di Airflow, è buona pratica evitare workflow che non possono essere rappresentati come DAG, perché potresti perdere caratteristiche chiave come la deterministicità o l’idempotenza.
Per pianificare i DAG, eseguire i task e fornire visibilità sui dettagli di esecuzione delle pipeline di dati, Airflow sfrutta un’architettura basata su Python composta dai seguenti componenti:
Che tu esegua Airflow in locale o in un ambiente di produzione, ognuno di questi componenti deve essere in esecuzione perché Airflow funzioni correttamente.
Lo scheduler è responsabile (lo avrai probabilmente intuito) della pianificazione dei DAG. Per pianificare un DAG, bisogna fornire una data di inizio e un intervallo di scheduling quando il DAG viene scritto in Python.
Una volta pianificato un DAG, i task al suo interno devono essere eseguiti: qui entra in gioco l’executor. L’executor non esegue la logica di ciascun task; si limita ad allocare il task alle risorse configurate per farlo. Il database dei metadati memorizza informazioni sulle esecuzioni dei DAG, come se il DAG e i task associati siano andati a buon fine o meno.
Il database dei metadati memorizza anche informazioni come variabili e connessioni definite dall’utente, utili nella creazione di pipeline di dati di livello produttivo. Infine, il web server fornisce l’interfaccia utente di Airflow.
Questa interfaccia utente, o UI, offre ai team dati uno strumento centrale per gestire l’esecuzione delle pipeline. Nell’UI di Airflow, i team possono visualizzare lo stato dei propri DAG, rieseguire manualmente i DAG, memorizzare variabili e connessioni e molto altro. L’UI di Airflow offre visibilità centrale sui processi di ingestione e delivery dei dati, aiutando i team a restare informati e consapevoli delle prestazioni delle loro pipeline.
Esistono diversi modi per installare Apache Airflow. Vedremo due dei più comuni.
pipPrerequisiti:
python3 installatoPer installare Airflow con pip, il gestore di pacchetti di Python, puoi eseguire il seguente comando:
pip install apache-airflowUna volta completata l’installazione del pacchetto, dovrai creare tutti i componenti di un progetto Airflow, ad esempio impostare la tua directory home di Airflow, creare un file airflow.cfg, avviare il database dei metadati e molto altro. Può essere un bel po’ di lavoro e richiedere una discreta esperienza pregressa con Airflow. Per fortuna, c’è un modo molto più semplice con l’Astro CLI.
Prerequisiti:
python3 installatoAstronomer, un provider gestito di Airflow, mette a disposizione vari strumenti gratuiti per semplificare il lavoro con Airflow. Uno di questi è l’Astro CLI.
L’Astro CLI rende semplice creare e gestire tutto ciò che ti serve per eseguire Airflow. Per iniziare, devi prima installare la CLI. Per farlo sulla tua macchina, consulta questo link alla documentazione di Astronomer e segui i passaggi per il tuo sistema operativo.
Una volta installata l’Astro CLI, configurare un intero progetto Airflow richiede un solo comando:
astro dev initQuesto configurerà tutte le risorse necessarie per un progetto Airflow nella tua directory di lavoro corrente. La tua directory di lavoro apparirà più o meno così:
.
├── dags/
├── include/
├── plugins/
├── tests/
├── airflow_settings.yaml
├── Dockerfile
├── packages.txt
└── requirements.txt
Una volta creato il progetto, per avviarlo esegui astro dev start. Dopo circa un minuto, puoi aprire l’UI di Airflow nel browser, all’indirizzo https://localhost:8080/. Ora sei pronto per scrivere il tuo primo DAG!
Abbiamo visto le basi e le funzionalità più avanzate del framework e dell’architettura di Airflow. Ora che Airflow è installato, sei pronto per scrivere il tuo primo DAG. Per prima cosa, crea un file chiamato sample_dag.py nella directory dags/ del progetto Airflow che hai appena creato. Con il tuo editor di testo o IDE preferito, apri il file sample_dag.py. Per iniziare, istanziamo il DAG.
from airflow import DAG
from datetime import datetime
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
...
Sopra, usiamo la funzione DAG dal modulo airflow per definire un DAG insieme al context manager with.
Sono forniti una start_date, un intervallo di schedule e un valore per catchup. Questo DAG verrà eseguito ogni giorno alle 9:00 UTC. Poiché catchup è impostato su True, questo DAG verrà eseguito per ogni giorno tra il giorno in cui viene avviato per la prima volta e il 1° gennaio 2024, e max_active_runs=1 garantisce che possa essere in esecuzione solo un DAG alla volta.
Ora aggiungiamo alcuni task! Per prima cosa, creeremo un task per simulare l’estrazione di dati da un’API. Guarda il codice qui sotto:
...
# Import the PythonOperator
from airflow.operators.python import PythonOperator
...
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
Successivamente, vogliamo creare un task per trasformare i dati restituiti dal task extract_data. Possiamo farlo con il codice seguente. Qui utilizziamo una funzionalità di Airflow chiamata XCom per recuperare i dati dal task precedente.
Poiché render_templat_as_native_obj è impostato su True, questi valori sono condivisi come oggetti Python anziché come stringhe. I dati grezzi dal task extract_data vengono quindi passati a transform_data_callable come argomento keyword. Questi dati vengono quindi trasformati e restituiti, e verranno usati dal task load_data in modo analogo.
...
# Import pandas
import pandas as pd
...
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
...
Infine, vengono impostate le dipendenze tra i task. Il codice qui imposta le dipendenze tra i task extract_data, transform_data e load_data per creare un DAG ETL di base.
...
extract_data >> transform_data >> load_data
Il risultato finale sarà così!
from airflow import DAG
from datetime import datetime
from airflow.operators.python import PythonOperator
import pandas as pd
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
# Set dependencies between tasks
extract_data >> transform_data >> load_data
Una volta definita la tua pipeline come codice Python, puoi usare l’UI di Airflow per attivare il DAG. Clicca sul DAG weather_etl e attiva l’interruttore in alto a sinistra. Osserva l’esecuzione dei tuoi task e il completamento con successo del DAG.
Complimenti, hai scritto ed eseguito il tuo primo DAG di Airflow!
Oltre agli operatori tradizionali, Airflow ha introdotto la TaskFlow API, che rende più semplice definire DAG e task usando decorator e codice Python nativo.
Invece di usare esplicitamente gli XCom per condividere dati tra i task, la TaskFlow API astrae questa logica, utilizzando XCom dietro le quinte. Il codice qui sotto mostra la stessa identica logica e funzionalità di prima, questa volta implementata con la TaskFlow API, più intuitiva per analisti e data scientist abituati a costruire logiche ETL basate su script.
from airflow.decorators import dag, task
from datetime import datetime
import pandas as pd
@dag(
start_date=datetime(year=2023, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1
)
def weather_etl():
@task()
def extract_data():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
@task()
def transform_data(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
@task()
def load_data(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
# Set dependencies using function calls
raw_dataset = extract_data()
transformed_dataset = transform_data(raw_dataset)
load_data(transformed_dataset)
# Allow the DAG to be run
weather_etl()
Costruire DAG in Airflow può essere complicato. Ci sono alcune buone pratiche da tenere a mente quando si costruiscono pipeline e workflow di dati, non solo con Airflow ma anche con altri strumenti.
Con i task, Airflow aiuta a rendere la modularità più facile da visualizzare. Non cercare di fare troppo in un singolo task. Anche se un’intera pipeline ETL può essere costruita in un unico task, questo renderebbe difficile il troubleshooting. Inoltre, renderebbe complicata la visualizzazione delle prestazioni di un DAG.
Quando crei un task, è importante assicurarsi che faccia una sola cosa, proprio come le funzioni in Python.
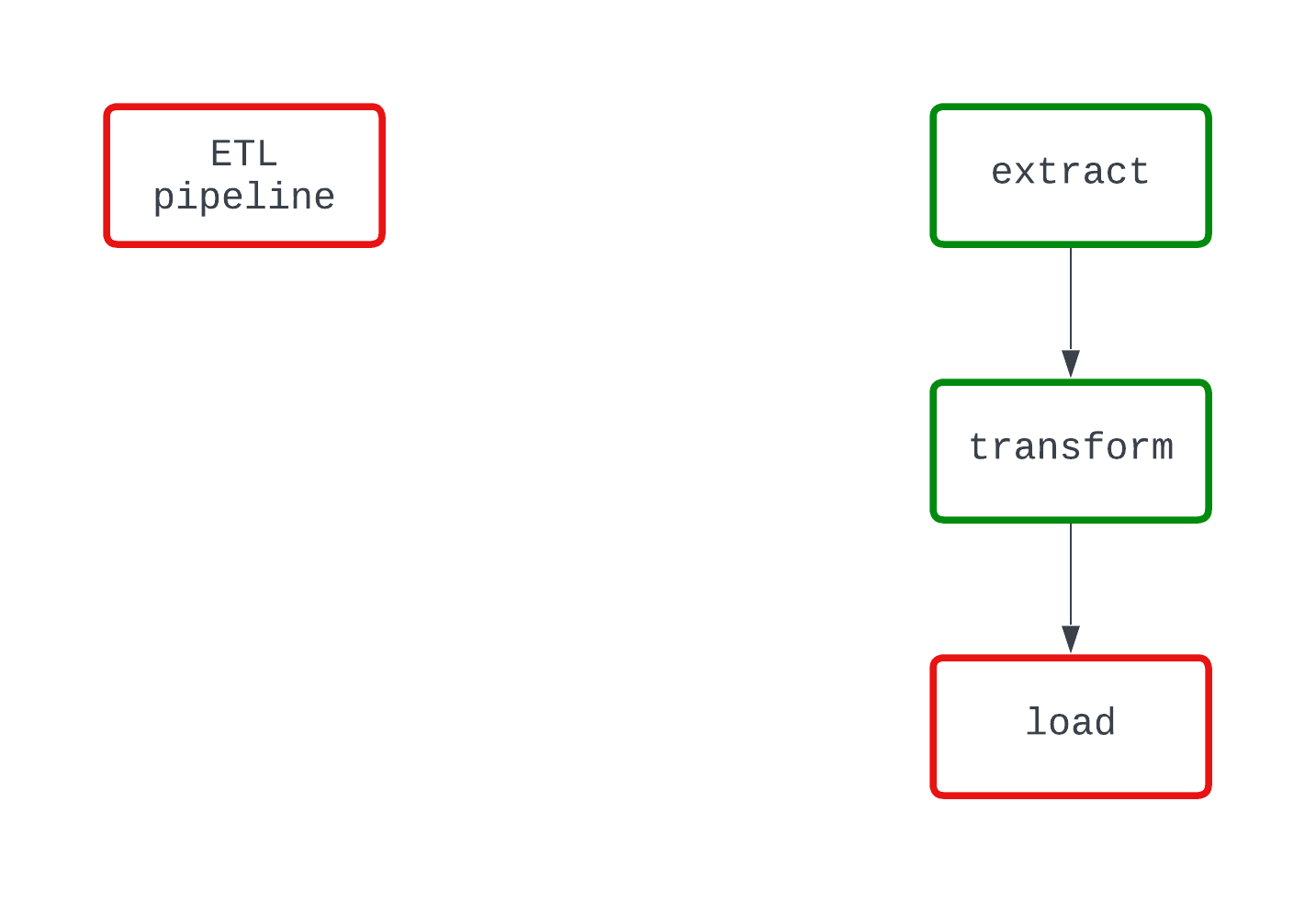
Guarda l’esempio qui sotto. Entrambi i DAG fanno la stessa cosa e falliscono nello stesso punto del codice. Tuttavia, nel DAG a sinistra è chiaro che la logica di load sta causando il fallimento, mentre questo non è altrettanto evidente dal DAG a destra.
Un processo deterministico è quello che produce lo stesso risultato, dato lo stesso input. Quando un DAG gira per un intervallo specifico, dovrebbe generare sempre gli stessi risultati. Pur essendo una caratteristica più complessa delle pipeline di dati, la deterministicità è importante per garantire risultati coerenti.
Con Airflow, sfrutta il Jinja-templating per passare campi templati agli operatori di Airflow invece di usare la funzione datetime.now() per creare dati temporali.
Cosa succede se esegui un DAG due volte per lo stesso intervallo? E per 10 volte? Finirai con dati duplicati nel tuo sistema di archiviazione di destinazione? L’idempotenza garantisce che, anche se una pipeline di dati viene eseguita più volte, è come se fosse stata eseguita una sola volta.
Per rendere le pipeline deterministiche, pensa a incorporare la seguente logica nei tuoi DAG:
INSERT, che potrebbe causare duplicati.Airflow non è pensato per elaborare enormi quantità di dati. Se vuoi eseguire trasformazioni su più di un paio di gigabyte di dati, Airflow è comunque lo strumento giusto; tuttavia, dovrebbe invocare un altro strumento, come dbt o Databricks, per eseguire la trasformazione.
In genere, i task vengono eseguiti in locale sulla tua macchina o con nodi worker in produzione. In entrambi i casi, saranno disponibili solo pochi gigabyte di memoria per eventuali elaborazioni computazionali necessarie.
Concentrati sull’uso di Airflow per trasformazioni leggere e come strumento di orchestrazione quando gestisci dati più grandi.
Grazie alla possibilità di definire pipeline di dati come codice e alla sua ampia varietà di connettori e operatori, aziende in tutto il mondo si affidano ad Airflow per supportare le loro piattaforme dati.
Nel settore, un team dati può lavorare con una grande varietà di strumenti, da siti SFTP a sistemi di archiviazione file cloud fino a un data lakehouse. Per costruire una piattaforma dati, è fondamentale integrare questi sistemi eterogenei.
Con una vivace community open-source, esistono migliaia di connettori predefiniti per integrare i tuoi strumenti dati. Vuoi spostare un file da S3 a Snowflake? Per fortuna, lo S3ToSnowflakeOperator rende facile farlo! E per i controlli di qualità con Great Expectations? Anche quello è già stato sviluppato.
Se non trovi lo strumento predefinito giusto per il tuo caso, nessun problema. Airflow è estensibile, quindi puoi creare facilmente i tuoi strumenti personalizzati per soddisfare le tue esigenze.
Quando esegui Airflow in produzione, dovrai anche considerare gli strumenti che usi per gestire l’infrastruttura. Ci sono diversi modi per farlo: con soluzioni premium come Astronomer, opzioni cloud-native come MWAA o anche una soluzione interna.
In genere, si tratta di un compromesso tra costi e gestione dell’infrastruttura; soluzioni più costose possono significare meno attività di gestione, mentre eseguire tutto su una singola istanza EC2 può essere economico ma difficile da mantenere.
Apache Airflow è uno strumento leader per eseguire pipeline di dati in produzione. Fornendo funzionalità come scheduling, estendibilità e osservabilità e permettendo ad analisti, data scientist e ingegneri di definire le pipeline come codice, Airflow aiuta i professionisti dei dati a concentrarsi sull’impatto sul business.
Iniziare con Airflow è semplice, soprattutto con l’Astro CLI, e gli operatori tradizionali e la TaskFlow API rendono facile scrivere i primi DAG. Quando costruisci pipeline con Airflow, assicurati di tenere modularità, deterministicità e idempotenza al centro delle tue decisioni progettuali; queste best practice ti aiuteranno a evitare grattacapi in futuro, soprattutto quando i tuoi DAG incontrano un errore.
Con Airflow, c’è tantissimo da imparare. Per il tuo prossimo progetto di data analytics o data science, prova Airflow. Sperimenta operatori predefiniti o costruisci i tuoi. Prova a condividere dati tra task con operatori tradizionali e la TaskFlow API. Non aver paura di spingerti oltre. Se sei pronto a iniziare, dai un’occhiata al corso di DataCamp Introduction to Airflow in Python, che copre le basi di Airflow ed esplora come implementare pipeline di data engineering complesse in produzione.
Puoi anche iniziare il nostro corso Introduction to Data Pipelines, che ti aiuterà a sviluppare le competenze per costruire pipeline efficaci, performanti e affidabili. Infine, puoi consultare il nostro confronto tra Airflow e Prefect per capire qual è lo strumento migliore per te.
Se vuoi approfondire, dai un’occhiata alle risorse qui sotto. Buona fortuna e buon coding!
https://airflow.apache.org/docs/apache-airflow/stable/project.html
https://airflow.apache.org/blog/airflow-survey-2022/
https://airflow.apache.org/docs/apache-airflow/1.10.9/installation.html
https://docs.astronomer.io/astro/cli/get-started-cli
https://airflow.apache.org/docs/apache-airflow/stable/tutorial/taskflow.html
https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html
Inizia oggi il tuo percorso con le pipeline di dati
Corso
Corso