
Cursus
Gestroomlijnde data-inname met pandas
4 Hr
63.2K
Het framework en de architectuur van Airflow hebben een aantal kernfeatures die het uniek maken. Laten we eerst iets dieper ingaan op de belangrijkste features van Airflow’s framework.
De eenvoudigste eenheid binnen het Airflow-framework zijn taken. Taken kun je zien als bewerkingen of, voor de meeste datateams, stappen in een datapijplijn.
Een traditionele ETL-workflow heeft drie taken: data extraheren, transformeren en laden. Afhankelijkheden definiëren de relaties tussen taken. Terug naar ons ETL-voorbeeld: de “load”-taak is afhankelijk van de “transform”-taak, die op haar beurt afhankelijk is van de “extract”-taak. De combinatie van taken en afhankelijkheden creëert DAG’s, oftewel directed acyclic graphs. DAG’s representeren datapijplijnen in Airflow en zijn wat lastig om te definiëren. Laten we daarom kijken naar een diagram van een basis-ETL-pijplijn:
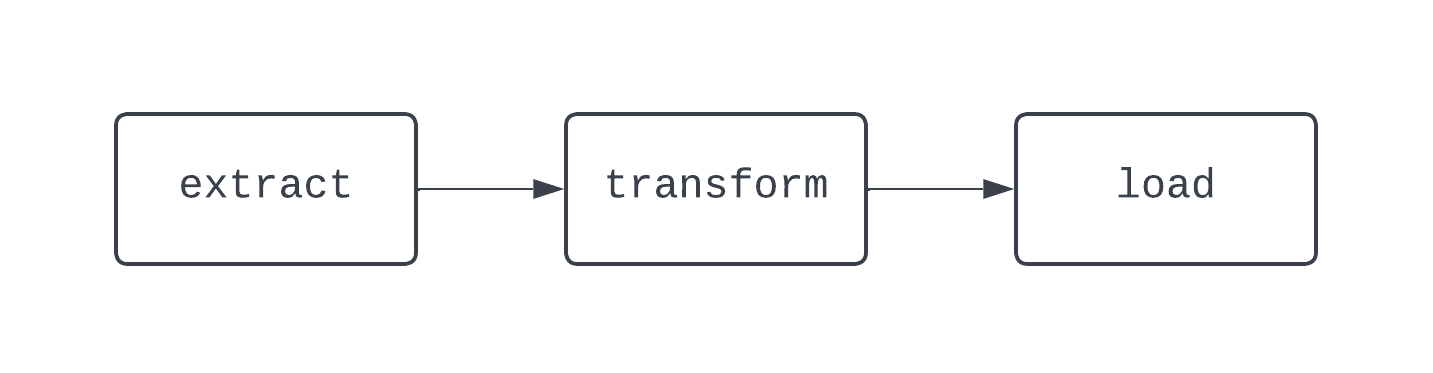
De DAG hierboven heeft drie taken met twee afhankelijkheden. Het wordt een DAG genoemd omdat er geen lussen (of cycli) tussen taken zijn. De pijlen tonen de richting van het proces: eerst draait de taak extract, gevolgd door de taken transform en load. Met DAG’s is het gemakkelijk om een duidelijk begin en einde van het proces te zien, zelfs als de logica complex is, zoals in de onderstaande DAG:
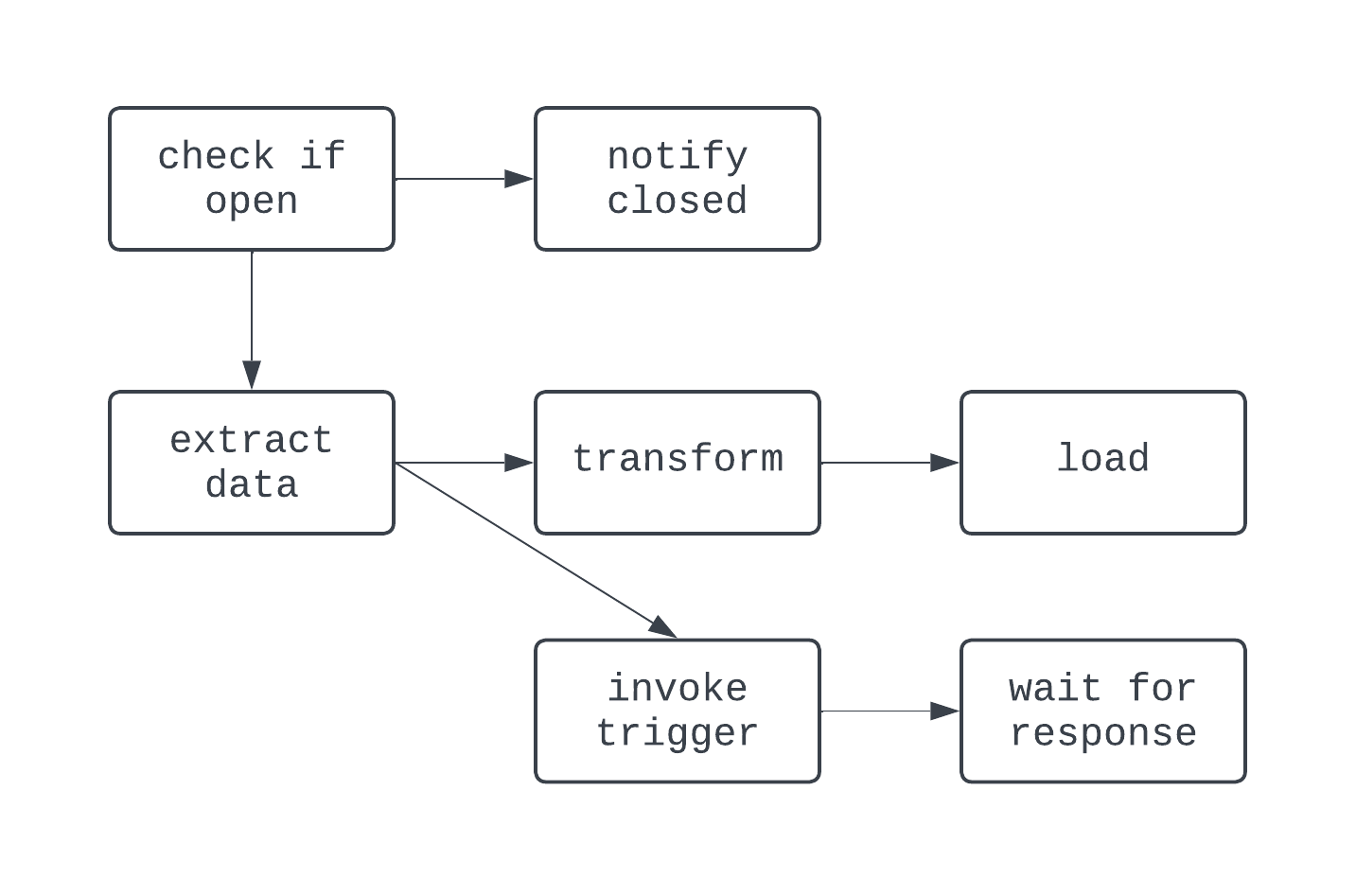
In deze DAG is de logica wat gekker. Er is een vertakking op basis van een voorwaarde en een paar taken draaien parallel. Toch is de grafiek gericht en zijn er geen cyclische afhankelijkheden tussen taken. Laten we nu kijken naar een proces dat geen DAG is:
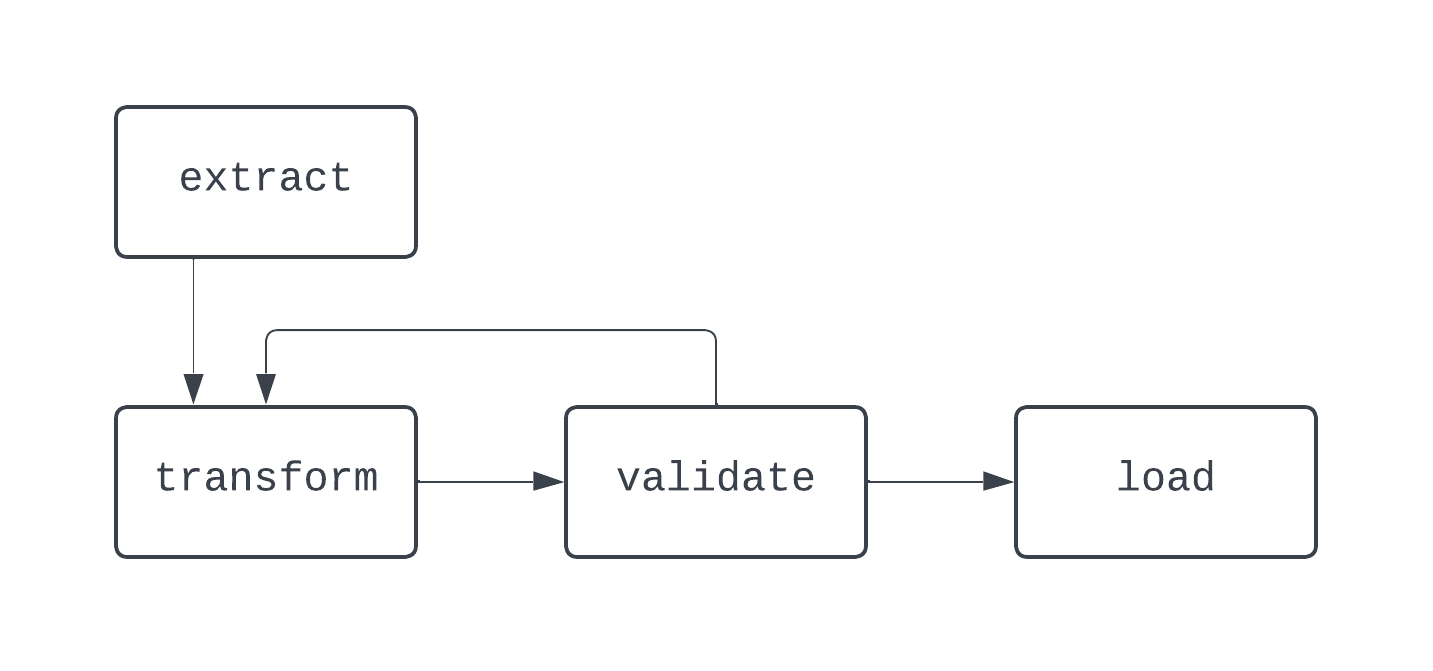
In dit diagram is er een duidelijke lus tussen de taken transform en validate. In sommige gevallen kan deze DAG voor altijd blijven draaien als er geen manier is om uit deze lus te breken.
Bij het bouwen van datapijplijnen, ook buiten Airflow, is het best practice om weg te blijven van workflows die niet als DAG’s kunnen worden weergegeven, omdat je dan mogelijk belangrijke eigenschappen verliest, zoals determinisme of idempotentie.
Om DAG’s te plannen, taken uit te voeren en inzicht te geven in de uitvoeringsdetails van datapijplijnen, maakt Airflow gebruik van een op Python gebaseerde architectuur met de volgende componenten:
Of je Airflow nu lokaal of in een productieomgeving draait, elk van deze componenten moet actief zijn voor een goede werking.
De scheduler is verantwoordelijk voor (je raadt het al) het plannen van DAG’s. Om een DAG te plannen, moeten bij het schrijven van de DAG in Python een startdatum en een planningsinterval worden opgegeven.
Zodra een DAG is ingepland, moeten de taken binnen die DAG’s worden uitgevoerd, en daar komt de executor om de hoek kijken. De executor voert de logica binnen elke taak niet uit; hij wijst de taak alleen toe om uitgevoerd te worden door de geconfigureerde resources. De metadatadatabase slaat informatie op over DAG-runs, zoals of de DAG en de bijbehorende taken succesvol zijn uitgevoerd.
De metadatadatabase slaat ook informatie op zoals door de gebruiker gedefinieerde variabelen en verbindingen, die helpen bij het bouwen van datapijplijnen van productiekwaliteit. Tot slot biedt de webserver de gebruikersinterface van Airflow.
Deze gebruikersinterface, of UI, geeft datateams een centrale tool om hun pijplijnuitvoering te beheren. In de Airflow-UI kunnen datateams de status van hun DAG’s bekijken, een DAG handmatig opnieuw draaien, variabelen en verbindingen opslaan en nog veel meer. De Airflow-UI biedt centraal inzicht in processen voor data-inname en -levering en helpt datateams op de hoogte te blijven van de prestaties van hun datapijplijnen.
Er zijn verschillende manieren om Apache Airflow te installeren. We behandelen er twee die het vaakst voorkomen.
pipVereisten:
python3 geïnstalleerdOm Airflow met pip, de pakketmanager van Python, te installeren, kun je het volgende commando draaien:
pip install apache-airflowZodra het pakket klaar is met installeren, moet je alle componenten van een Airflow-project aanmaken, zoals het instellen van je Airflow-homedirectory, het creëren van een airflow.cfg-bestand, het opzetten van de metadatadatabase en nog veel meer. Dit kan veel werk zijn en vereist best wat voorkennis van Airflow. Gelukkig is er een veel eenvoudigere manier met de Astro CLI.
Vereisten:
python3 geïnstalleerdAstronomer, een managed Airflow-provider, biedt een aantal gratis tools om het werken met Airflow makkelijker te maken. Een van die tools is de Astro CLI.
De Astro CLI maakt het eenvoudig om alles te creëren en beheren wat je nodig hebt om Airflow te draaien. Om te beginnen moet je eerst de CLI installeren. Hoe je dit op je machine doet, vind je in deze link naar de documentatie van Astronomer; volg de stappen voor jouw besturingssysteem.
Als de Astro CLI eenmaal is geïnstalleerd, kost het configureren van een volledig Airflow-project slechts één commando:
astro dev initDit configureert alle resources die nodig zijn voor een Airflow-project in je huidige werkdirectory. Je huidige werkdirectory ziet er dan ongeveer zo uit:
.
├── dags/
├── include/
├── plugins/
├── tests/
├── airflow_settings.yaml
├── Dockerfile
├── packages.txt
└── requirements.txt
Zodra het project is aangemaakt, start je het met astro dev start. Na ongeveer een minuut kun je de Airflow-UI in je browser openen op het adres https://localhost:8080/. Nu ben je klaar om je eerste DAG te schrijven!
We hebben de basis en meer geavanceerde features van Airflow’s framework en architectuur behandeld. Nu Airflow is geïnstalleerd, ben je klaar om je eerste DAG te schrijven. Maak eerst een bestand met de naam sample_dag.py in de directory dags/ van het zojuist aangemaakte Airflow-project. Open het bestand sample_dag.py met je favoriete teksteditor of IDE. Laten we eerst de DAG instantiëren.
from airflow import DAG
from datetime import datetime
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
...
Hierboven gebruiken we de functie DAG uit de module airflow om een DAG te definiëren in combinatie met de with-contextmanager.
Er worden een start_date, een schedule-interval en een waarde voor catchup opgegeven. Deze DAG draait elke dag om 09:00 uur UTC. Omdat catchup op True staat, draait deze DAG voor elke dag tussen de dag waarop hij voor het eerst wordt getriggerd en 1 januari 2024, en max_active_runs=1 zorgt ervoor dat er maar één DAG tegelijk kan draaien.
Laten we nu een paar taken toevoegen! Eerst maken we een taak om het extraheren van data uit een API te simuleren. Bekijk de onderstaande code:
...
# Import the PythonOperator
from airflow.operators.python import PythonOperator
...
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
Vervolgens willen we een taak maken om de data die door de taak extract_data wordt geretourneerd te transformeren. Dit kan met de volgende code. Hier gebruiken we een Airflow-feature genaamd XComs om data op te halen uit de vorige taak.
Omdat render_templat_as_native_obj is ingesteld op True, worden deze waarden gedeeld als Python-objecten in plaats van strings. De ruwe data van de taak extract_data wordt vervolgens als keywordargument doorgegeven aan transform_data_callable. Deze data wordt daarna getransformeerd en geretourneerd, waarna deze op een vergelijkbare manier door de taak load_data wordt gebruikt.
...
# Import pandas
import pandas as pd
...
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
...
Tot slot worden afhankelijkheden tussen taken ingesteld. De code hier stelt afhankelijkheden in tussen de taken extract_data, transform_data en load_data om een basis-ETL-DAG te maken.
...
extract_data >> transform_data >> load_data
Het eindresultaat ziet er zo uit!
from airflow import DAG
from datetime import datetime
from airflow.operators.python import PythonOperator
import pandas as pd
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
# Set dependencies between tasks
extract_data >> transform_data >> load_data
Zodra je je pijplijn als Python-code hebt gedefinieerd, kun je in de Airflow-UI je DAG inschakelen. Klik op de DAG weather_etl en zet de schakelaar linksboven om. Kijk hoe je taken en DAG succesvol worden uitgevoerd.
Gefeliciteerd, je hebt je eerste Airflow-DAG geschreven en gedraaid!
Naast het gebruik van traditionele operators heeft Airflow de TaskFlow API geïntroduceerd, die het makkelijker maakt om DAG’s en taken te definiëren met decorators en native Python-code.
In plaats van expliciet XComs te gebruiken om data tussen taken te delen, abstraheert de TaskFlow API deze logica en gebruikt onder de motorkap XComs. De onderstaande code laat exact dezelfde logica en functionaliteit zien als hierboven, maar dan geïmplementeerd met de TaskFlow API, die intuïtiever is voor data-analisten en -wetenschappers die gewend zijn scriptgebaseerde ETL-logica te bouwen.
from airflow.decorators import dag, task
from datetime import datetime
import pandas as pd
@dag(
start_date=datetime(year=2023, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1
)
def weather_etl():
@task()
def extract_data():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
@task()
def transform_data(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
@task()
def load_data(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
# Set dependencies using function calls
raw_dataset = extract_data()
transformed_dataset = transform_data(raw_dataset)
load_data(transformed_dataset)
# Allow the DAG to be run
weather_etl()
Airflow-DAG’s bouwen kan lastig zijn. Er zijn een paar best practices om in gedachten te houden bij het bouwen van datapijplijnen en workflows, niet alleen met Airflow, maar ook met andere tools.
Met taken helpt Airflow om modulariteit makkelijker te visualiseren. Probeer niet te veel in één enkele taak te doen. Hoewel je een volledige ETL-pijplijn in één taak kunt bouwen, maakt dat het troubleshootten lastig. Ook wordt het dan moeilijker om de prestaties van een DAG te visualiseren.
Als je een taak maakt, is het belangrijk dat de taak maar één ding doet, net als functies in Python.
Bekijk het onderstaande voorbeeld. Beide DAG’s doen hetzelfde en falen op hetzelfde punt in de code. In de DAG links is echter duidelijk dat de load-logica de fout veroorzaakt, terwijl dat in de DAG rechts niet meteen duidelijk is.
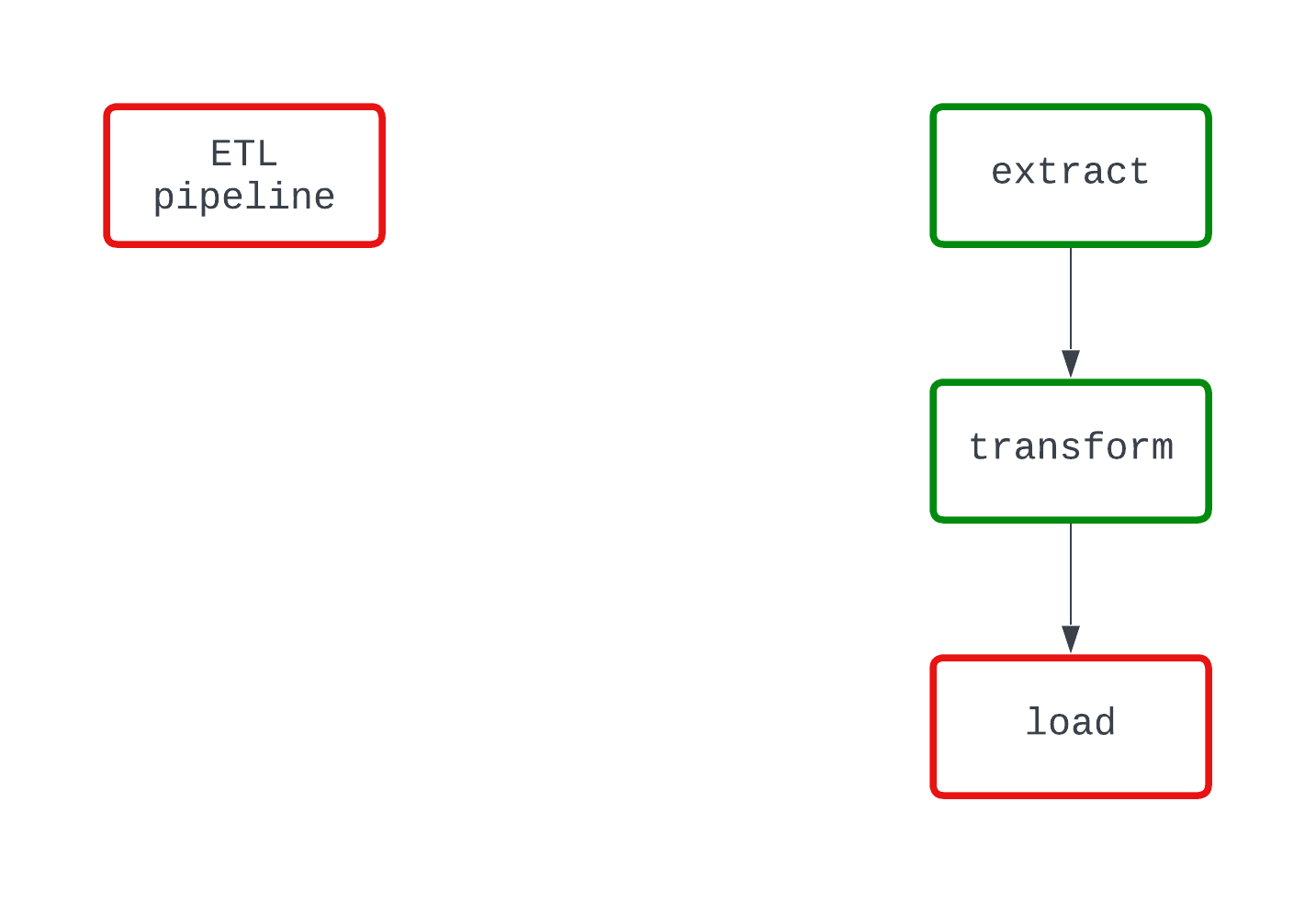
Een deterministisch proces is een proces dat hetzelfde resultaat produceert, gegeven dezelfde input. Wanneer een DAG voor een specifieke periode draait, zou die elke keer dezelfde resultaten moeten opleveren. Hoewel dit een complexere eigenschap van datapijplijnen is, is determinisme belangrijk om consistente resultaten te garanderen.
Gebruik in Airflow Jinja-templating om getemplate velden aan operators door te geven in plaats van de functie datetime.now() te gebruiken om tijdelijke data te creëren.
Wat gebeurt er als je een DAG twee keer voor hetzelfde interval draait? Of 10 keer? Eindig je met dubbele data in je doelsysteem? Idempotentie zorgt ervoor dat, zelfs als een datapijplijn meerdere keren wordt uitgevoerd, het is alsof de pijplijn maar één keer is uitgevoerd.
Om datapijplijnen deterministisch te maken, kun je het volgende in je DAG’s opnemen:
INSERTen, wat duplicaten kan veroorzaken.Airflow is niet bedoeld om enorme hoeveelheden data te verwerken. Als je transformaties op meer dan een paar gigabyte aan data wilt draaien, is Airflow nog steeds het juiste gereedschap; maar Airflow zou dan een andere tool, zoals dbt of Databricks, moeten aanroepen om de transformatie uit te voeren.
Typisch worden taken lokaal op je machine uitgevoerd of met workernodes in productie. In beide gevallen is er slechts een paar gigabyte geheugen beschikbaar voor eventuele rekenwerkzaamheden.
Gebruik Airflow vooral voor lichte datatransformaties en als orkestratietool bij het verwerken van grotere data.
Dankzij Airflow’s mogelijkheid om datapijplijnen als code te definiëren en de grote verscheidenheid aan connectors en operators vertrouwen bedrijven wereldwijd op Airflow om hun dataplatforms aan te drijven.
In het bedrijfsleven werkt een datateam vaak met een breed scala aan tools, van SFTP-sites tot cloudbestandsopslag en een datalakehouse. Om een dataplatform te bouwen, is het cruciaal dat deze uiteenlopende systemen geïntegreerd worden.
Met een levendige opensourcestructuur zijn er duizenden kant-en-klare connectors om je datatooling te integreren. Een bestand van S3 naar Snowflake verplaatsen? Gelukkig maakt de S3ToSnowflakeOperator dat eenvoudig! En datakwaliteitscontroles met Great Expectations? Die zijn ook al gebouwd.
Kun je niet de juiste kant-en-klare tool vinden? Geen probleem. Airflow is uitbreidbaar, waardoor je eenvoudig je eigen maatwerktools kunt bouwen die aan je behoeften voldoen.
Als je Airflow in productie draait, is het ook belangrijk om na te denken over de tooling die je gebruikt om de infrastructuur te beheren. Daar zijn verschillende manieren voor, met premiumoplossingen zoals Astronomer, cloud-native opties zoals MWAA, of zelfs een eigen oplossing.
Meestal gaat dit gepaard met een afweging tussen kosten en infrastructuurbeheer; duurdere oplossingen betekenen vaak minder beheer, terwijl alles op één enkele EC2-instantie draaien goedkoop kan zijn maar lastig te onderhouden.
Apache Airflow is een toonaangevende tool voor het draaien van datapijplijnen in productie. Door functionaliteit te bieden zoals scheduling, uitbreidbaarheid en observeerbaarheid, en tegelijk data-analisten, -wetenschappers en -engineers in staat te stellen datapijplijnen als code te definiëren, helpt Airflow dataprofessionals zich te richten op impact voor het bedrijf.
Het is makkelijk om met Airflow te beginnen, zeker met de Astro CLI, en met traditionele operators en de TaskFlow API schrijf je eenvoudig je eerste DAG’s. Houd bij het bouwen van datapijplijnen met Airflow modulariteit, determinisme en idempotentie voor ogen; deze best practices helpen je hoofdpijn te voorkomen, vooral wanneer je DAG’s een fout tegenkomen.
Met Airflow valt er ontzettend veel te leren. Probeer Airflow bij je volgende data-analyse- of datascienceproject. Experimenteer met kant-en-klare operators of bouw je eigen. Probeer data te delen tussen taken met traditionele operators en de TaskFlow API. Wees niet bang om de grenzen op te zoeken. Als je klaar bent om te starten, bekijk dan DataCamp’s cursus Introduction to Airflow in Python, die de basis van Airflow behandelt en laat zien hoe je complexe data-engineeringpijplijnen in productie implementeert.
Je kunt ook onze cursus Introduction to Data Pipelines volgen, die je helpt de skills te ontwikkelen om effectieve, performante en betrouwbare datapijplijnen te bouwen. Tot slot kun je onze vergelijking van Airflow vs Prefect bekijken om te zien welke tool het beste bij jou past.
Wil je meer? Bekijk dan de onderstaande resources. Succes, en veel codeplezier!
https://airflow.apache.org/docs/apache-airflow/stable/project.html
https://airflow.apache.org/blog/airflow-survey-2022/
https://airflow.apache.org/docs/apache-airflow/1.10.9/installation.html
https://docs.astronomer.io/astro/cli/get-started-cli
https://airflow.apache.org/docs/apache-airflow/stable/tutorial/taskflow.html
https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html
Begin vandaag nog aan je datapijplijn-reis
Cursus
Cursus