
Kurs
Vereinfachte Datenaufnahme mit pandas
4 Std.
62.7K
Das Airflow-Framework und seine Architektur haben mehrere wichtige Eigenschaften, die es einzigartig machen. Zunächst wollen wir uns die wichtigsten Funktionen des Airflow-Frameworks etwas genauer ansehen.
Die einfachste Einheit des Airflow-Frameworks sind Aufgaben. Aufgaben können als Operationen oder, für die meisten Datenteams, als Operationen in einer Datenpipeline betrachtet werden.
Ein traditioneller ETL-Workflow hat drei Aufgaben: Daten extrahieren, transformieren und laden. Abhängigkeiten definieren die Beziehungen zwischen Aufgaben. Um auf unser ETL-Beispiel zurückzukommen: Die Aufgabe "Laden" hängt von der Aufgabe "Transformieren" ab, die wiederum von der Aufgabe "Extrahieren" abhängt. Durch die Kombination von Aufgaben und Abhängigkeiten entstehen DAGs, also gerichtete-acyclische Graphen. DAGs stellen in Airflow Datenpipelines dar und sind ein wenig kompliziert zu definieren. Werfen wir stattdessen einen Blick auf das Diagramm einer grundlegenden ETL-Pipeline:
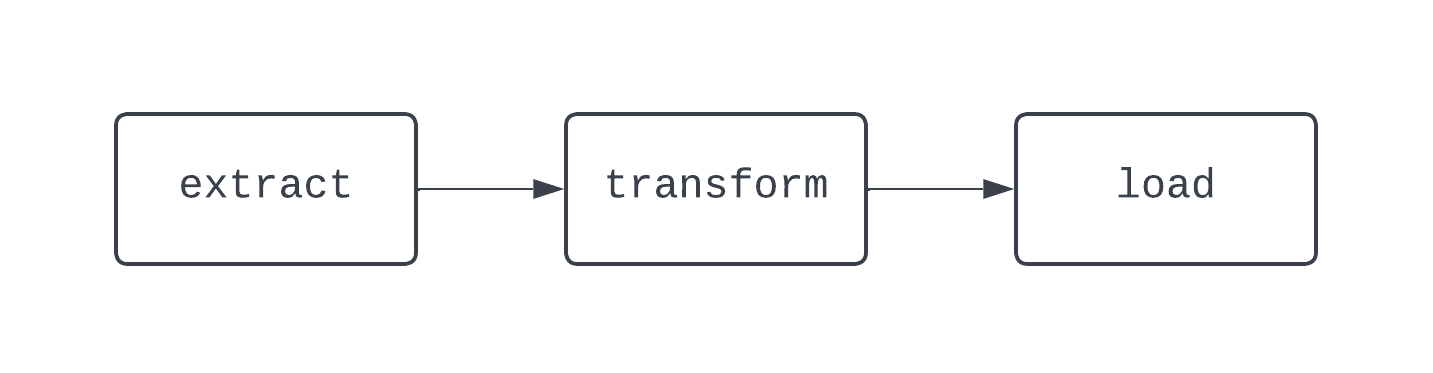
Die obige DAG hat drei Aufgaben mit zwei Abhängigkeiten. Sie wird als DAG bezeichnet, weil es keine Schleifen (oder Zyklen) zwischen den Aufgaben gibt. Hier zeigen die Pfeile die gerichtete Natur des Prozesses; zuerst wird die Aufgabe extract ausgeführt, gefolgt von den Aufgaben transform und load. Mit DAGs ist es einfach, einen eindeutigen Anfang und ein eindeutiges Ende des Prozesses zu erkennen, selbst wenn die Logik komplex ist, wie bei dem unten abgebildeten DAG:
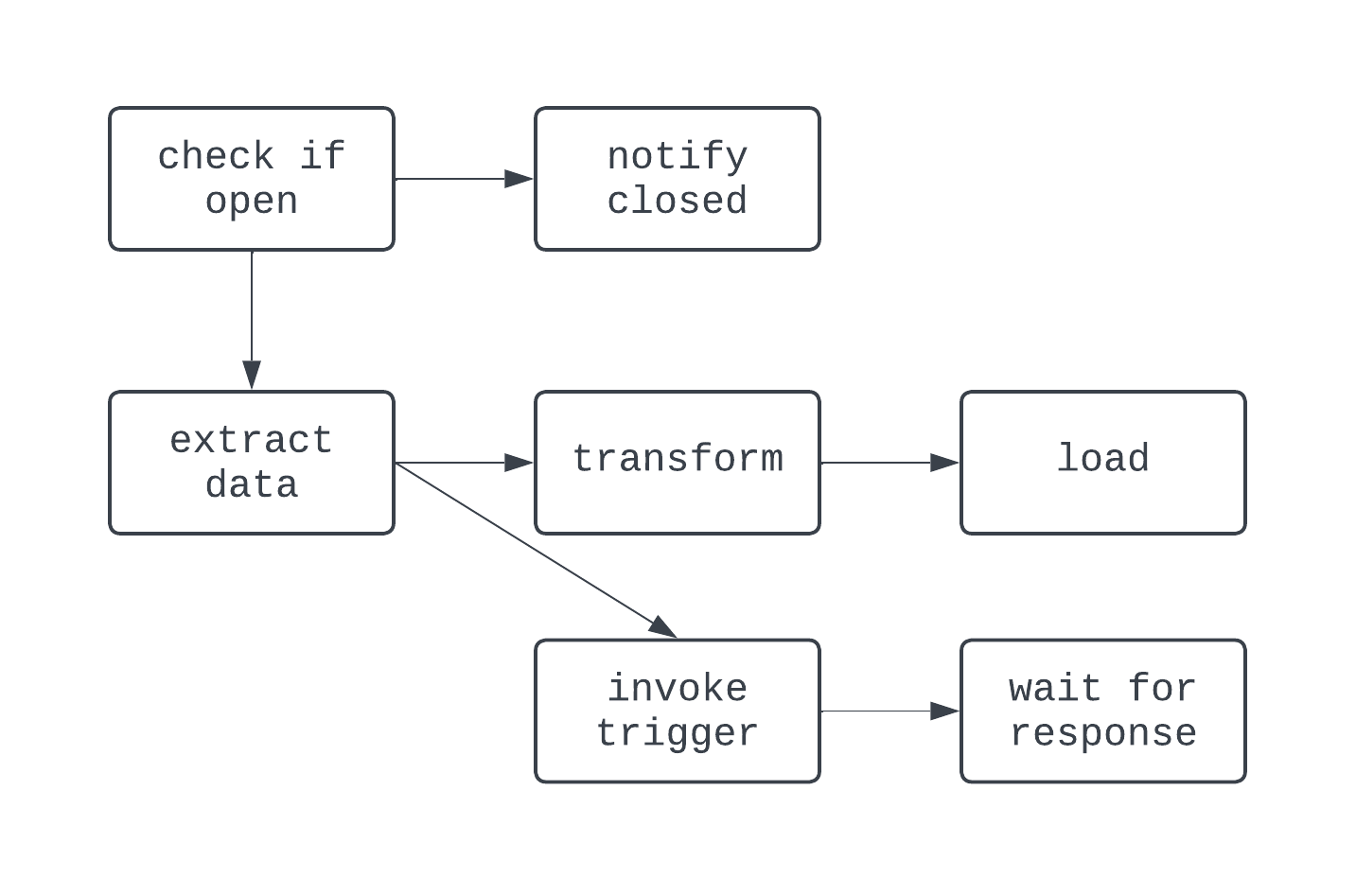
In dieser DAG ist die Logik ein bisschen verrückter. Es gibt Verzweigungen, die auf einer Bedingung basieren, und ein paar Aufgaben werden parallel ausgeführt. Der Graph ist jedoch gerichtet, und es gibt keine zyklischen Abhängigkeiten zwischen den Aufgaben. Werfen wir nun einen Blick auf einen Prozess, der keine DAG ist:
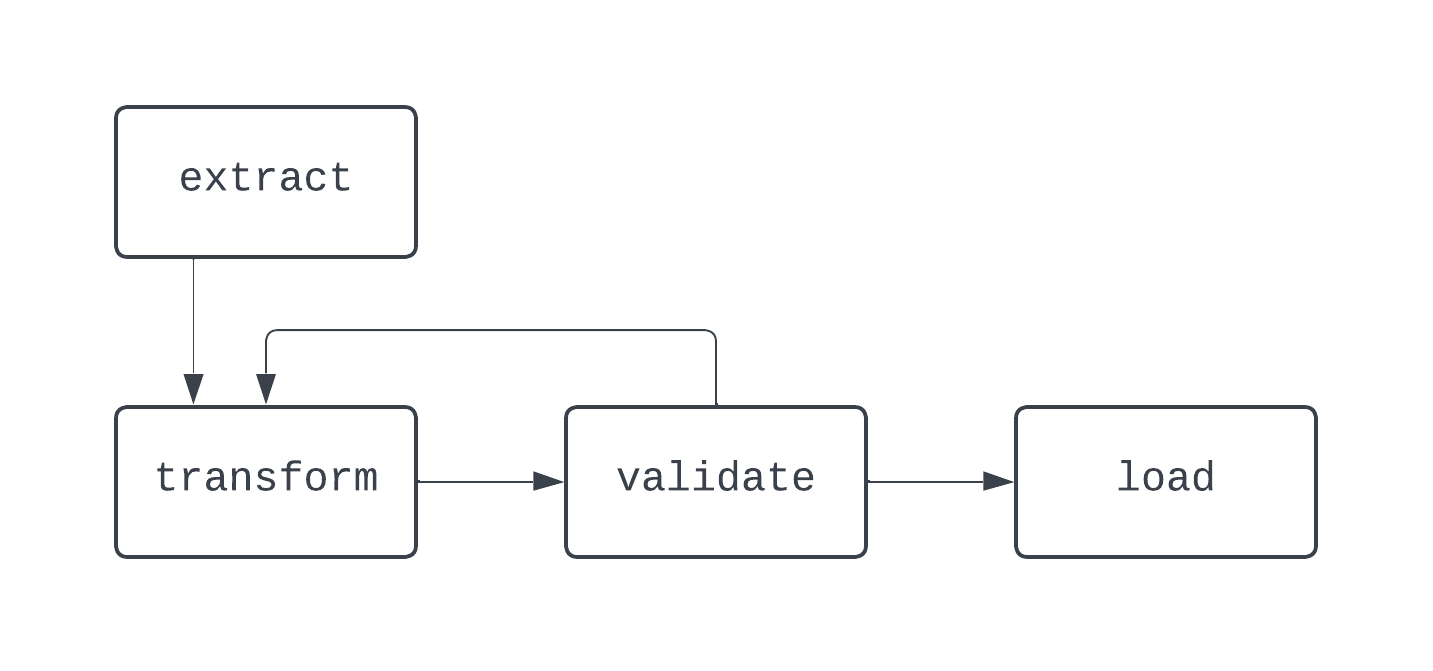
In diesem Diagramm gibt es eine eindeutige Schleife zwischen den Aufgaben transform und validate. In manchen Fällen kann diese DAG ewig laufen, wenn es keine Möglichkeit gibt, aus dieser Schleife auszubrechen.
Bei der Erstellung von Datenpipelines, auch außerhalb von Airflow, ist es ratsam, keine Workflows zu erstellen, die nicht als DAGs dargestellt werden können, da du sonst wichtige Funktionen wie Determinismus oder Idempotenz verlierst.
Um DAGs zu planen, Aufgaben auszuführen und Einblicke in die Details der Datenpipeline-Ausführung zu erhalten, nutzt Airflow eine Python-basierte Architektur, die aus den folgenden Komponenten besteht:
Egal, ob Airflow lokal oder in einer Produktionsumgebung eingesetzt wird, jede dieser Komponenten muss vorhanden sein, damit Airflow richtig funktioniert.
Der Scheduler ist für die Planung der DAGs zuständig (du hast es wahrscheinlich schon erraten). Um eine DAG zu planen, müssen ein Startdatum und ein Zeitintervall für die DAG angegeben werden, wenn die DAG als Python-Code geschrieben wird.
Sobald eine DAG geplant ist, müssen die Aufgaben innerhalb dieser DAGs ausgeführt werden, und hier kommt der Executor ins Spiel. Der Executor führt nicht die Logik innerhalb jeder Aufgabe aus; er weist die Aufgabe lediglich den Ressourcen zu, die dafür konfiguriert sind. Die Metadaten-Datenbank speichert Informationen über DAG-Läufe, z.B. ob die DAG und die zugehörigen Aufgaben erfolgreich gelaufen sind oder nicht.
In der Metadaten-Datenbank werden auch Informationen wie benutzerdefinierte Variablen und Verbindungen gespeichert, die beim Aufbau produktionsgerechter Datenpipelines hilfreich sind. Schließlich stellt der Webserver die Benutzeroberfläche für Airflow bereit.
Diese Benutzeroberfläche (UI) bietet Datenteams ein zentrales Tool zur Verwaltung ihrer Pipeline-Ausführung. In der Airflow-Benutzeroberfläche können Datenteams den Status ihrer DAGs einsehen, DAGs manuell neu starten, Variablen und Verbindungen speichern und vieles mehr. Die Airflow-Benutzeroberfläche bietet einen zentralen Einblick in die Dateneingabe- und -übermittlungsprozesse und hilft den Datenteams dabei, die Leistung ihrer Datenpipelines im Blick zu behalten.
Es gibt verschiedene Möglichkeiten, Apache Airflow zu installieren. Wir werden zwei der gängigsten behandeln.
pipVoraussetzungen:
python3 installiertUm Airflow mit pip zu installieren, kannst du auf die Art und Weise, wie Python Pakete erstellt, den folgenden Befehl ausführen:
pip install apache-airflowSobald die Installation des Pakets abgeschlossen ist, musst du alle Komponenten eines Airflow-Projekts erstellen, z. B. dein Airflow-Stammverzeichnis einrichten, eine airflow.cfg -Datei erstellen, die Metadaten-Datenbank einrichten und vieles mehr. Das kann eine Menge Arbeit sein und erfordert ein gewisses Maß an Erfahrung mit Airflow. Zum Glück gibt es einen viel einfacheren Weg mit dem Astro CLI.
Voraussetzungen:
python3 installiertAstronomer, ein Anbieter von verwaltetem Airflow, stellt eine Reihe von kostenlosen Tools zur Verfügung, die die Arbeit mit Airflow erleichtern. Eines dieser Tools ist das Astro CLI.
Mit der Astro CLI kannst du alles, was du zum Betrieb von Airflow brauchst, ganz einfach erstellen und verwalten. Um loszulegen, musst du zuerst die CL installieren. Um dies auf deinem Rechner zu tun, schau dir diesen Link zur Astronomer-Dokumentation an und befolge die Schritte für dein Betriebssystem.
Sobald die Astro CLI installiert ist, brauchst du nur noch einen einzigen Befehl, um ein ganzes Airflow-Projekt zu konfigurieren:
astro dev initDamit konfigurierst du alle Ressourcen, die du für ein Airflow-Projekt brauchst, in deinem aktuellen Arbeitsverzeichnis. Dein aktuelles Arbeitsverzeichnis sieht dann etwa so aus:
.
├── dags/
├── include/
├── plugins/
├── tests/
├── airflow_settings.yaml
├── Dockerfile
├── packages.txt
└── requirements.txt
Sobald das Projekt erstellt wurde, rufe astro dev start auf, um das Projekt zu starten. Nach etwa einer Minute kannst du die Airflow UI in deinem Browser unter der Adresse https://localhost:8080/ öffnen. Jetzt bist du bereit, deine erste DAG zu schreiben!
Wir haben uns mit den Grundlagen und fortgeschrittenen Funktionen des Airflow-Frameworks und der Airflow-Architektur beschäftigt. Jetzt, wo Airflow installiert ist, kannst du deine erste DAG schreiben. Erstelle zunächst eine Datei namens sample_dag.py im Verzeichnis dags/ des Airflow-Projekts, das du gerade erstellt hast. Öffne die Datei sample_dag.py mit deinem bevorzugten Texteditor oder deiner IDE. Lass uns zunächst die DAG instanziieren.
from airflow import DAG
from datetime import datetime
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
...
Oben haben wir die Funktion DAG aus dem Modul airflow verwendet, um eine DAG in Verbindung mit dem Kontext-Manager with zu definieren.
Es werden start_date, schedule und ein Wert für catchup angegeben. Diese DAG wird jeden Tag um 9:00 Uhr UTC durchgeführt. Da catchup auf True gesetzt ist, wird diese DAG für jeden Tag zwischen dem Tag, an dem sie zum ersten Mal ausgelöst wird, und dem 1. Januar 2024 ausgeführt, und max_active_runs=1 stellt sicher, dass immer nur eine DAG gleichzeitig ausgeführt werden kann.
Jetzt lass uns ein paar Aufgaben hinzufügen! Zuerst erstellen wir eine Aufgabe, die das Extrahieren von Daten aus einer API simuliert. Schau dir den Code unten an:
...
# Import the PythonOperator
from airflow.operators.python import PythonOperator
...
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
Als Nächstes wollen wir eine Aufgabe erstellen, die die von der Aufgabe extract_data zurückgegebenen Daten umwandelt. Das kannst du mit dem folgenden Code tun. Hier verwenden wir eine Airflow-Funktion namens XComs, um Daten aus der vorherigen Aufgabe abzurufen.
Da render_templat_as_native_obj auf True gesetzt ist, werden diese Werte als Python-Objekte und nicht als Strings freigegeben. Die Rohdaten aus der extract_data Aufgabe werden dann als Schlüsselwortargument an die transform_data_callable übergeben. Diese Daten werden dann umgewandelt und zurückgegeben, wo sie von der Aufgabe load_data auf ähnliche Weise verwendet werden.
...
# Import pandas
import pandas as pd
...
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
...
Schließlich werden die Abhängigkeiten zwischen den Aufgaben festgelegt. Der Code hier stellt Abhängigkeiten zwischen den Aufgaben extract_data, transform_data und load_data her, um eine grundlegende ETL-DAG zu erstellen.
...
extract_data >> transform_data >> load_data
So wird das Endprodukt aussehen!
from airflow import DAG
from datetime import datetime
from airflow.operators.python import PythonOperator
import pandas as pd
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
# Set dependencies between tasks
extract_data >> transform_data >> load_data
Sobald du deine Pipeline als Python-Code definiert hast, kannst du die Airflow-Benutzeroberfläche verwenden, um deine DAG zu aktivieren. Klicke auf die weather_etl DAG und schalte den Schalter oben links um. Sieh zu, wie deine Aufgaben und der DAG-Lauf erfolgreich abgeschlossen werden.
Glückwunsch, du hast deine erste Airflow DAG geschrieben und ausgeführt!
Zusätzlich zu den traditionellen Operatoren hat Airflow die TaskFlow-API eingeführt, die es einfacher macht, DAGs und Aufgaben mithilfe von Dekoratoren und nativem Python-Code zu definieren.
Anstatt explizit XComs zu verwenden, um Daten zwischen Aufgaben auszutauschen, abstrahiert die TaskFlow-API diese Logik und verwendet stattdessen XComs hinter den Kulissen. Der folgende Code zeigt genau dieselbe Logik und Funktionalität wie oben, diesmal jedoch mit der TaskFlow-API implementiert, die für Datenanalysten und Wissenschaftler, die an die Erstellung skriptbasierter ETL-Logik gewöhnt sind, intuitiver ist.
from airflow.decorators import dag, task
from datetime import datetime
import pandas as pd
@dag(
start_date=datetime(year=2023, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1
)
def weather_etl():
@task()
def extract_data():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
@task()
def transform_data(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
@task()
def load_data(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
# Set dependencies using function calls
raw_dataset = extract_data()
transformed_dataset = transform_data(raw_dataset)
load_data(transformed_dataset)
# Allow the DAG to be run
weather_etl()
Der Aufbau von Airflow-DAGs kann knifflig sein. Bei der Erstellung von Datenpipelines und Workflows, nicht nur mit Airflow, sondern auch mit anderen Werkzeugen, gibt es einige bewährte Verfahren zu beachten.
Mit Aufgaben hilft Airflow dabei, die Modularität einfacher zu visualisieren. Versuche nicht, zu viel in einer einzigen Aufgabe zu erledigen. Zwar kann eine ganze ETL-Pipeline in einer einzigen Aufgabe erstellt werden, aber das würde die Fehlersuche erschweren. Es würde auch die Visualisierung der Leistung einer DAG erschweren.
Wenn du eine Aufgabe erstellst, musst du darauf achten, dass die Aufgabe nur eine einzige Aufgabe hat, ähnlich wie Funktionen in Python.
Sieh dir das folgende Beispiel an. Beide DAGs machen das Gleiche und scheitern an der gleichen Stelle im Code. In der DAG auf der linken Seite ist es jedoch klar, dass die Logik von load den Fehler verursacht, während dies in der DAG auf der rechten Seite nicht ganz klar ist.
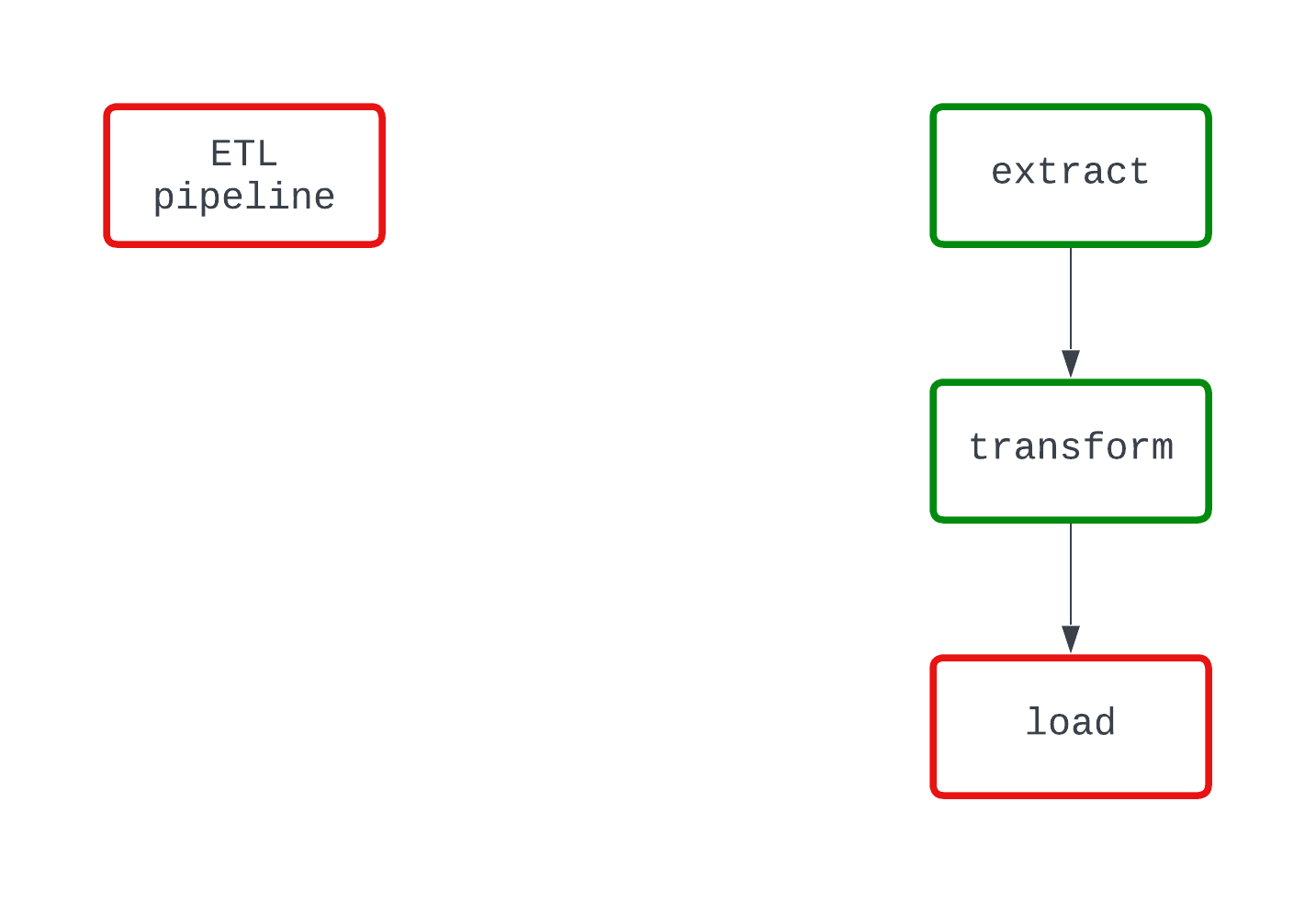
Ein deterministischer Prozess ist ein Prozess, der bei gleichem Input das gleiche Ergebnis liefert. Wenn eine DAG für ein bestimmtes Intervall läuft, sollte sie jedes Mal die gleichen Ergebnisse liefern. Der Determinismus ist zwar ein komplexeres Merkmal von Datenpipelines, aber er ist wichtig, um konsistente Ergebnisse zu gewährleisten.
Mit Airflow kannst du Jinja-templating nutzen, um Felder mit Vorlagen an Airflow-Operatoren zu übergeben, anstatt die Funktion datetime.now() zu verwenden, um temporäre Daten zu erstellen.
Was passiert, wenn du eine DAG zweimal für dasselbe Intervall ausführst? Wie wäre es mit 10 Mal? Wirst du am Ende doppelte Daten auf deinem Zielspeichermedium haben? Die Idempotenz stellt sicher, dass selbst wenn eine Datenpipeline mehrfach ausgeführt wird, es so ist, als wäre die Pipeline nur einmal ausgeführt worden.
Um Datenpipelines deterministisch zu machen, solltest du die folgende Logik in deine DAGs einbauen:
INSERTzu verwenden, was zu Duplikaten führen kann.Airflow ist nicht dafür gedacht, große Datenmengen zu verarbeiten. Wenn du Transformationen für mehr als ein paar Gigabyte Daten durchführen willst, ist Airflow immer noch das richtige Tool für diese Aufgabe. Allerdings sollte Airflow ein anderes Tool wie dbt oder Databricks aufrufen, um die Transformation durchzuführen.
Normalerweise werden die Aufgaben lokal auf deinem Rechner oder mit Worker Nodes in der Produktion ausgeführt. So oder so stehen nur ein paar Gigabyte Arbeitsspeicher für die notwendigen Berechnungen zur Verfügung.
Konzentriere dich darauf, Airflow für eine sehr einfache Datenumwandlung und als Orchestrierungswerkzeug bei der Verarbeitung größerer Daten zu nutzen.
Dank der Fähigkeit von Airflow, Datenpipelines als Code zu definieren, und der großen Auswahl an Konnektoren und Operatoren verlassen sich Unternehmen auf der ganzen Welt auf Airflow, um ihre Datenplattformen zu betreiben.
In der Industrie kann ein Datenteam mit einer Vielzahl von Tools arbeiten, von SFTP-Sites über Cloud-Dateispeichersysteme bis hin zu einem Data Lakehouse. Um eine Datenplattform aufzubauen, müssen diese unterschiedlichen Systeme unbedingt integriert werden.
Dank einer dynamischen Open-Source-Community gibt es Tausende von vorgefertigten Konnektoren, die dir bei der Integration deiner Daten helfen. Du möchtest eine Datei aus S3 in Snowflake ablegen? Zum Glück macht es dir die S3ToSnowflakeOperator leicht, genau das zu tun! Wie wäre es mit Datenqualitätsprüfungen mit Great Expectations? Das ist auch schon gebaut worden.
Wenn du nicht das richtige vorgefertigte Werkzeug für deine Aufgabe findest, ist das okay. Airflow ist erweiterbar und macht es dir leicht, deine eigenen Tools für deine Bedürfnisse zu entwickeln.
Wenn du Airflow in der Produktion einsetzt, solltest du auch über die Werkzeuge nachdenken, die du für die Verwaltung der Infrastruktur verwendest. Dafür gibt es eine Reihe von Möglichkeiten: Premium-Angebote wie Astronomer, Cloud-native Optionen wie MWAA oder sogar eine eigene Lösung.
In der Regel geht es dabei um einen Kompromiss zwischen Kosten und Infrastrukturmanagement: Teurere Lösungen bedeuten möglicherweise weniger Verwaltungsaufwand, während der Betrieb auf einer einzigen EC2-Instanz zwar kostengünstig, aber schwierig zu warten ist.
Apache Airflow ist ein branchenführendes Tool für den Betrieb von Datenpipelines in der Produktion. Airflow bietet Funktionen wie Zeitplanung, Erweiterbarkeit und Beobachtbarkeit und ermöglicht es Datenanalysten, Wissenschaftlern und Ingenieuren, Datenpipelines als Code zu definieren, so dass sich Datenexperten auf den Geschäftserfolg konzentrieren können.
Der Einstieg in Airflow ist einfach, vor allem mit der Astro CLI, und die traditionellen Operatoren und die TaskFlow-API machen es einfach, deine ersten DAGs zu schreiben. Wenn du Datenpipelines mit Airflow erstellst, solltest du darauf achten, dass Modularität, Determinismus und Idempotenz bei deinen Designentscheidungen an erster Stelle stehen.
Bei Airflow gibt es eine Menge zu lernen. Für dein nächstes Datenanalyse- oder Data Science-Projekt solltest du Airflow ausprobieren. Experimentiere mit vorgefertigten Operatoren oder baue deine eigenen. Versuche, Daten zwischen Aufgaben mit traditionellen Operatoren und der TaskFlow-API auszutauschen. Hab keine Angst, an deine Grenzen zu gehen. Wenn du bereit bist, loszulegen, schau dir den DataCamp-Kurs Einführung in Airflow in Python an, der die Grundlagen von Airflow vermittelt und zeigt, wie man komplexe Data-Engineering-Pipelines in der Produktion implementiert.
Du kannst auch mit unserem Kurs Einführung in Datenpipelines beginnen, der dir hilft, effektive, leistungsfähige und zuverlässige Datenpipelines zu erstellen. In unserem Vergleich zwischen Airflow und Prefect kannst du herausfinden, welches Werkzeug für dich am besten geeignet ist.
Wenn du mehr wissen willst, schau dir die folgenden Ressourcen an. Viel Glück und viel Spaß beim Codieren!
https://airflow.apache.org/docs/apache-airflow/stable/project.html
https://airflow.apache.org/blog/airflow-survey-2022/
https://airflow.apache.org/docs/apache-airflow/1.10.9/installation.html
https://docs.astronomer.io/astro/cli/get-started-cli
https://airflow.apache.org/docs/apache-airflow/stable/tutorial/taskflow.html
https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html
Beginne deine Data Pipelines-Reise noch heute
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
