
Kurs
pandas ile Kolaylaştırılmış Veri Alımı
4 sa
63.2K
Airflow’un çerçevesi ve mimarisi onu benzersiz kılan birkaç temel özelliğe sahiptir. Önce, Airflow çerçevesinin en önemli özelliklerine biraz daha yakından bakalım.
Airflow çerçevesinin en basit birimi görevlerdir (tasks). Görevler, işlemler olarak düşünülebilir; çoğu veri ekibi için bir veri hattındaki işlemler.
Geleneksel bir ETL iş akışında üç görev vardır; veriyi çıkarma, dönüştürme ve yükleme. Bağımlılıklar, görevler arasındaki ilişkileri tanımlar. ETL örneğimize dönersek, “yükleme” görevi “dönüştürme” görevine, o da “çıkarma” görevine bağlıdır. Görevlerin ve bağımlılıkların birleşimi DAG’leri, yani yönlendirilmiş çevrimsiz grafikleri oluşturur. DAG’ler Airflow’da veri hatlarını temsil eder ve tanımlamaları biraz karmaşıktır. Bunun yerine, temel bir ETL hattının diyagramına bakalım:
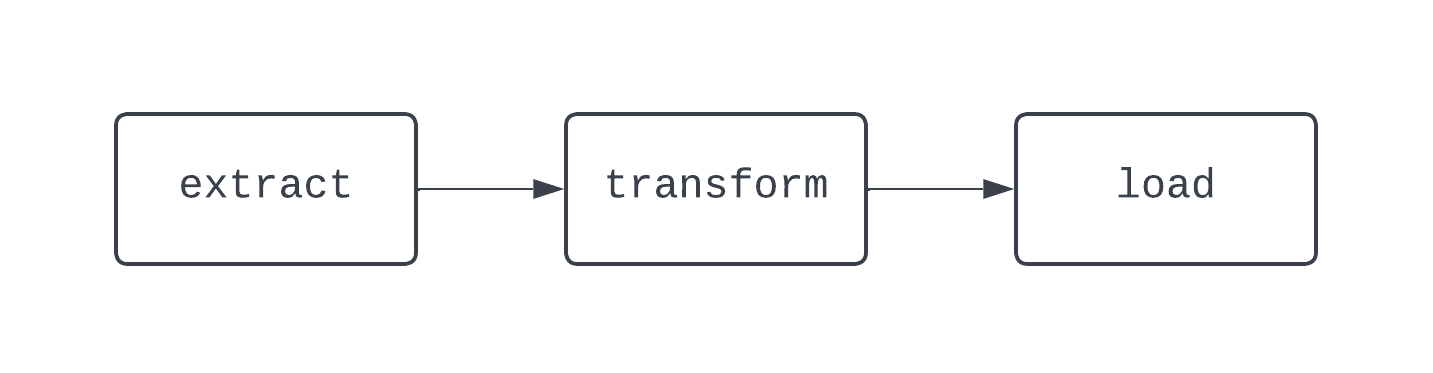
Yukarıdaki DAG’de üç görev ve iki bağımlılık vardır. Görevler arasında döngü (veya çevrim) olmadığı için DAG olarak kabul edilir. Burada oklar sürecin yönlendirilmiş doğasını gösterir; önce extract görevi çalışır, ardından transform ve load görevleri gelir. DAG’lerle, mantık karmaşık olsa bile (aşağıda gösterilen DAG gibi) sürecin belirgin bir başlangıç ve bitişini görmek kolaydır:
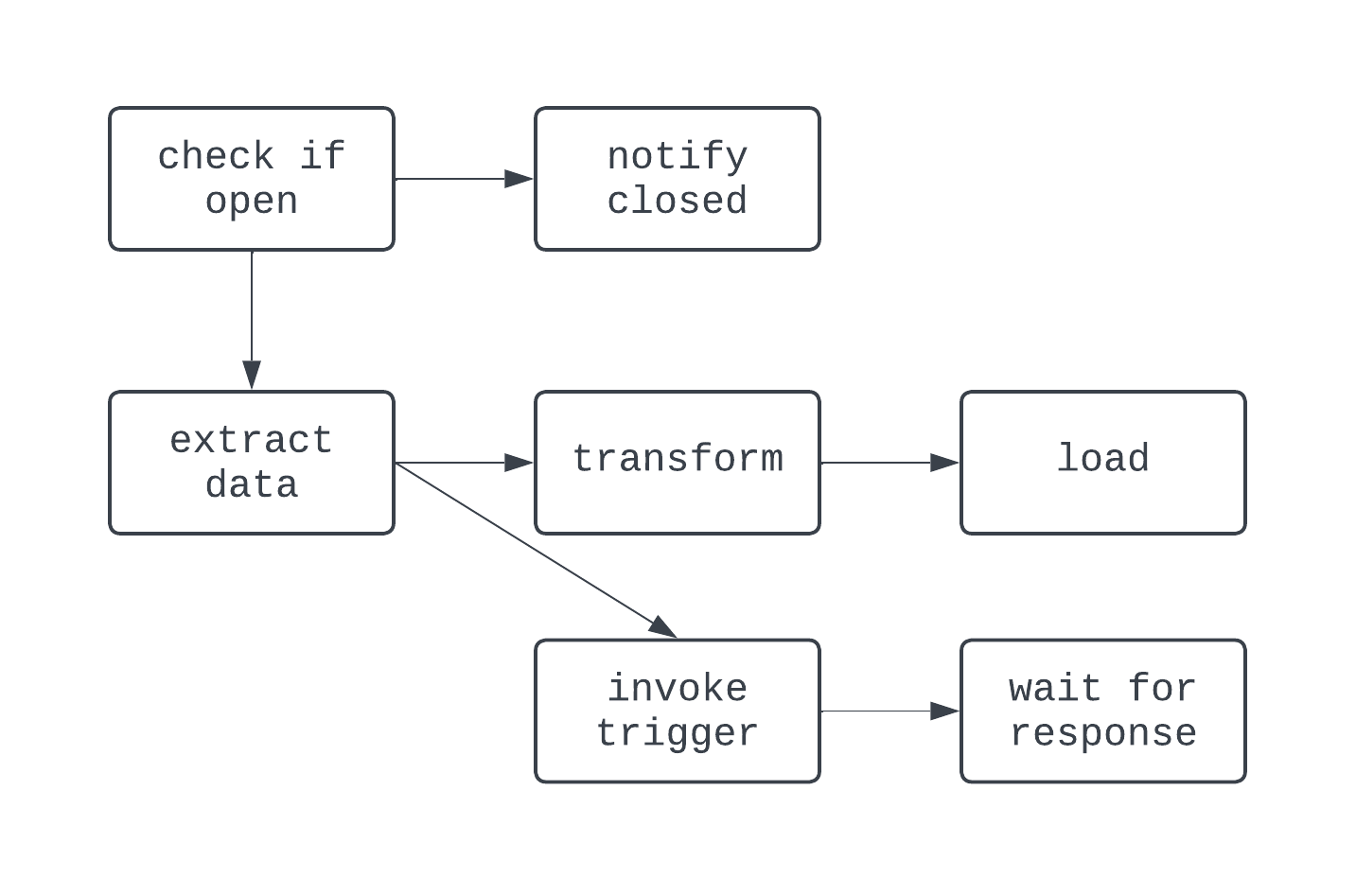
Bu DAG’de mantık biraz daha çılgın. Bir koşula bağlı dallanma var ve birkaç görev paralel çalışıyor. Ancak grafik yönlendirilmiş ve görevler arasında çevrimsel bağımlılıklar yok. Şimdi, DAG olmayan bir sürece bakalım:
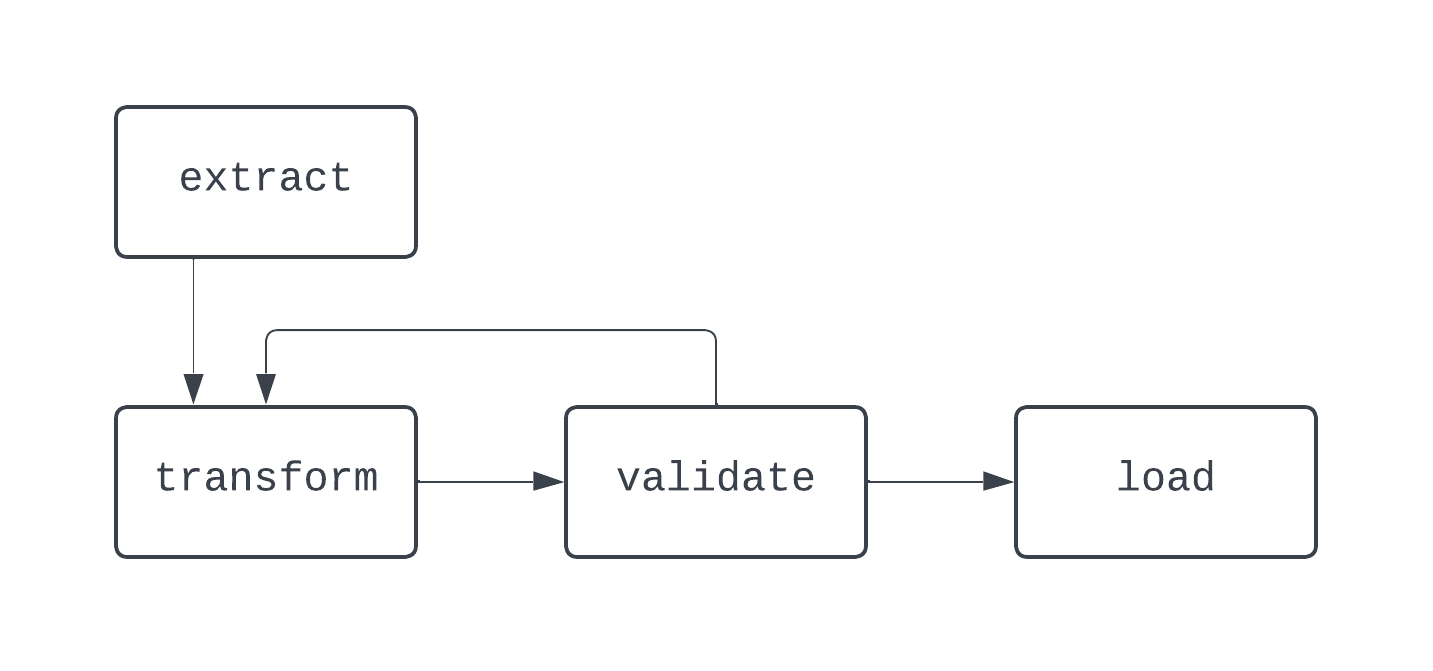
Bu diyagramda, transform ve validate görevleri arasında belirgin bir döngü var. Bazı durumlarda, bu DAG’in bu döngüden çıkış yolu yoksa sonsuza dek çalışması mümkündür.
Veri hatları oluştururken, Airflow dışında da, DAG olarak temsil edilemeyen iş akışları oluşturmaktan kaçınmak en iyi uygulamadır; aksi halde belirlilik veya idempotentlik gibi temel özellikleri kaybedebilirsiniz.
DAG’leri zamanlamak, görevleri yürütmek ve veri hattı yürütme ayrıntılarına görünürlük sağlamak için Airflow, aşağıdaki bileşenlerden oluşan Python tabanlı bir mimariden yararlanır:
Airflow’u yerelde veya üretim ortamında çalıştırıyor olun, Airflow’un düzgün çalışması için bu bileşenlerin her birinin çalışır durumda olması gerekir.
Zamanlayıcı, adından da tahmin edebileceğiniz gibi, DAG’leri zamanlamaktan sorumludur. Bir DAG’i zamanlamak için, DAG Python kodu olarak yazılırken bir başlangıç tarihi ve zamanlama aralığı sağlanmalıdır.
Bir DAG zamanlandıktan sonra, bu DAG’lerdeki görevlerin yürütülmesi gerekir; burada yürütücü devreye girer. Yürütücü, her görevin içindeki mantığı çalıştırmaz; yalnızca, görevin çalıştırılması için yapılandırılmış kaynaklara görevi tahsis eder. Meta veri veritabanı, DAG çalıştırmalarına ilişkin, DAG ve ilişkili görevlerin başarıyla çalışıp çalışmadığı gibi bilgileri depolar.
Meta veri veritabanı ayrıca kullanıcı tanımlı değişkenler ve bağlantılar gibi bilgileri de depolar; bu, üretim seviyesinde veri hatları oluştururken yardımcı olur. Son olarak, web sunucusu Airflow’un kullanıcı arayüzünü sağlar.
Bu kullanıcı arayüzü (UI), veri ekiplerine hat yürütmelerini yönetmek için merkezi bir araç sunar. Airflow UI’da veri ekipleri DAG’lerinin durumunu görüntüleyebilir, DAG’i elle yeniden çalıştırabilir, değişkenleri ve bağlantıları saklayabilir ve çok daha fazlasını yapabilir. Airflow UI, veri alım ve teslim süreçlerine merkezi bir görünürlük sağlayarak veri ekiplerinin veri hattı performansları konusunda bilgili ve farkında kalmasına yardımcı olur.
Apache Airflow’u kurmanın birkaç yolu vardır. En yaygın iki yöntemi ele alacağız.
pip ile Airflow KurulumuÖnkoşullar:
python3 kuruluAirflow’u Python’un paket yöneticisi pip ile kurmak için aşağıdaki komutu çalıştırabilirsiniz:
pip install apache-airflowPaketin kurulumu tamamlandıktan sonra, Airflow ana dizininizi ayarlamak, bir airflow.cfg dosyası oluşturmak, meta veri veritabanını başlatmak ve çok daha fazlası gibi bir Airflow projesinin tüm bileşenlerini oluşturmanız gerekir. Bu oldukça fazla iş olabilir ve Airflow ile ilgili hatırı sayılır bir ön deneyim gerektirebilir. Neyse ki, Astro CLI ile çok daha kolay bir yol var.
Önkoşullar:
python3 kuruluYönetilen bir Airflow sağlayıcısı olan Astronomer, Airflow ile çalışmayı kolaylaştırmak için bir dizi ücretsiz araç sunar. Bu araçlardan biri Astro CLI’dır.
Astro CLI, Airflow’u çalıştırmak için ihtiyaç duyduğunuz her şeyi oluşturmayı ve yönetmeyi kolaylaştırır. Başlamak için önce CLI’ı kurmanız gerekir. Bunu makinenizde yapmak için Astronomer’ın belgelerine göz atın ve işletim sisteminize uygun adımları izleyin.
Astro CLI kurulduktan sonra, tüm bir Airflow projesini yapılandırmak yalnızca bir komut alır:
astro dev initBu komut, geçerli çalışma dizininizde bir Airflow projesi için gerekli tüm kaynakları yapılandıracaktır. Geçerli çalışma dizininiz ardından aşağıdakine benzer görünecektir:
.
├── dags/
├── include/
├── plugins/
├── tests/
├── airflow_settings.yaml
├── Dockerfile
├── packages.txt
└── requirements.txt
Proje oluşturulduktan sonra, projeyi başlatmak için astro dev start komutunu çalıştırın. Yaklaşık bir dakika sonra, tarayıcınızda https://localhost:8080/ adresindeki Airflow UI’ı açabilirsiniz. Artık ilk DAG’ınızı yazmaya hazırsınız!
Airflow’un çerçeve ve mimarisinin temel ve daha gelişmiş özelliklerini ele aldık. Artık Airflow kurulduğuna göre, ilk DAG’ınızı yazmaya hazırsınız. Önce, az önce oluşturduğunuz Airflow projesinin dags/ dizininde sample_dag.py adlı bir dosya oluşturun. Favori metin düzenleyiciniz veya IDE’nizle sample_dag.py dosyasını açın. Önce, DAG’i örnekleyelim.
from airflow import DAG
from datetime import datetime
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
...
Yukarıda, airflow modülünden DAG fonksiyonunu, with bağlam yöneticisiyle birlikte bir DAG tanımlamak için kullanıyoruz.
start_date, schedule aralığı ve catchup için bir değer sağlanmıştır. Bu DAG her gün UTC 09:00’da çalışacaktır. catchup True olarak ayarlandığı için, bu DAG ilk tetiklendiği gün ile 1 Ocak 2024 arasındaki her gün için çalışacaktır ve max_active_runs=1 aynı anda yalnızca bir DAG çalışabileceğini garanti eder.
Şimdi birkaç görev ekleyelim! Önce, bir API’den veri çıkarmayı taklit edecek bir görev oluşturacağız. Aşağıdaki koda göz atın:
...
# Import the PythonOperator
from airflow.operators.python import PythonOperator
...
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
Sırada, extract_data görevinin döndürdüğü verileri dönüştürecek bir görev oluşturmak var. Bunu aşağıdaki kodla yapabiliriz. Burada, önceki görevden veri almak için XComs adı verilen bir Airflow özelliğini kullanıyoruz.
render_templat_as_native_obj True olarak ayarlandığından, bu değerler dizeler yerine Python nesneleri olarak paylaşılır. extract_data görevinden gelen ham veri daha sonra anahtar sözcük argümanı olarak transform_data_callable fonksiyonuna aktarılır. Bu veri dönüştürülüp döndürülür ve benzer şekilde load_data görevi tarafından kullanılır.
...
# Import pandas
import pandas as pd
...
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
...
Son olarak, görevler arasında bağımlılıklar ayarlanır. Buradaki kod, extract_data, transform_data ve load_data görevleri arasında bağımlılıkları ayarlayarak temel bir ETL DAG’i oluşturur.
...
extract_data >> transform_data >> load_data
Nihai ürün şöyle görünecek!
from airflow import DAG
from datetime import datetime
from airflow.operators.python import PythonOperator
import pandas as pd
with DAG(
dag_id="weather_etl",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1,
render_template_as_native_obj=True
) as dag:
def extract_data_callable():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
extract_data = PythonOperator(
dag=dag,
task_id="extract_data",
python_callable=extract_data_callable
)
def transform_data_callable(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
transform_data = PythonOperator(
dag=dag,
task_id="transform_data",
python_callable=transform_data_callable,
op_kwargs={"raw_data": "{{ ti.xcom_pull(task_ids='extract_data') }}"}
)
def load_data_callable(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
load_data = PythonOperator(
dag=dag,
task_id="load_data",
python_callable=load_data_callable,
op_kwargs={"transformed_data": "{{ ti.xcom_pull(task_ids='transform_data') }}"}
)
# Set dependencies between tasks
extract_data >> transform_data >> load_data
Boru hattınızı Python kodu olarak tanımladıktan sonra, DAG’inizi açmak için Airflow UI’ı kullanabilirsiniz. weather_etl DAG’ine tıklayın ve sol üstteki anahtarı açın. Görevlerinizin ve DAG’inizin başarıyla tamamlandığını izleyin.
Tebrikler, ilk Airflow DAG’inizi yazıp çalıştırdınız!
Geleneksel operatörleri kullanmanın yanı sıra, Airflow, dekoratörler ve yerel Python koduyla DAG ve görev tanımlamayı kolaylaştıran TaskFlow API’sini de sunar.
Görevler arasında veri paylaşmak için XComs’u açıkça kullanmak yerine, TaskFlow API bu mantığı soyutlar ve perde arkasında XComs kullanır. Aşağıdaki kod, yukarıdakiyle tamamen aynı mantık ve işlevselliği gösterir; bu kez, betik tabanlı ETL mantığı kurmaya alışkın veri analistleri ve bilim insanları için daha sezgisel olan TaskFlow API ile uygulanmıştır.
from airflow.decorators import dag, task
from datetime import datetime
import pandas as pd
@dag(
start_date=datetime(year=2023, month=1, day=1, hour=9, minute=0),
schedule="@daily",
catchup=True,
max_active_runs=1
)
def weather_etl():
@task()
def extract_data():
# Print message, return a response
print("Extracting data from an weather API")
return {
"date": "2023-01-01",
"location": "NYC",
"weather": {
"temp": 33,
"conditions": "Light snow and wind"
}
}
@task()
def transform_data(raw_data):
# Transform response to a list
transformed_data = [
[
raw_data.get("date"),
raw_data.get("location"),
raw_data.get("weather").get("temp"),
raw_data.get("weather").get("conditions")
]
]
return transformed_data
@task()
def load_data(transformed_data):
# Load the data to a DataFrame, set the columns
loaded_data = pd.DataFrame(transformed_data)
loaded_data.columns = [
"date",
"location",
"weather_temp",
"weather_conditions"
]
print(loaded_data)
# Set dependencies using function calls
raw_dataset = extract_data()
transformed_dataset = transform_data(raw_dataset)
load_data(transformed_dataset)
# Allow the DAG to be run
weather_etl()
Airflow DAG’leri oluşturmak zor olabilir. Veri hatları ve iş akışları oluştururken, yalnızca Airflow ile değil, diğer araçlarla çalışırken de akılda tutulması gereken bazı en iyi uygulamalar vardır.
Görevlerle birlikte Airflow, modülerliği görselleştirmeyi kolaylaştırır. Tek bir görevde çok fazla şey yapmaya çalışmayın. Tüm bir ETL hattı tek bir görevde oluşturulabilse de bu, sorun gidermeyi zorlaştırır. Ayrıca bir DAG’in performansını görselleştirmeyi de güçleştirir.
Bir görev oluştururken, tıpkı Python’daki fonksiyonlar gibi, görevin yalnızca tek bir şey yapacağından emin olmak önemlidir.
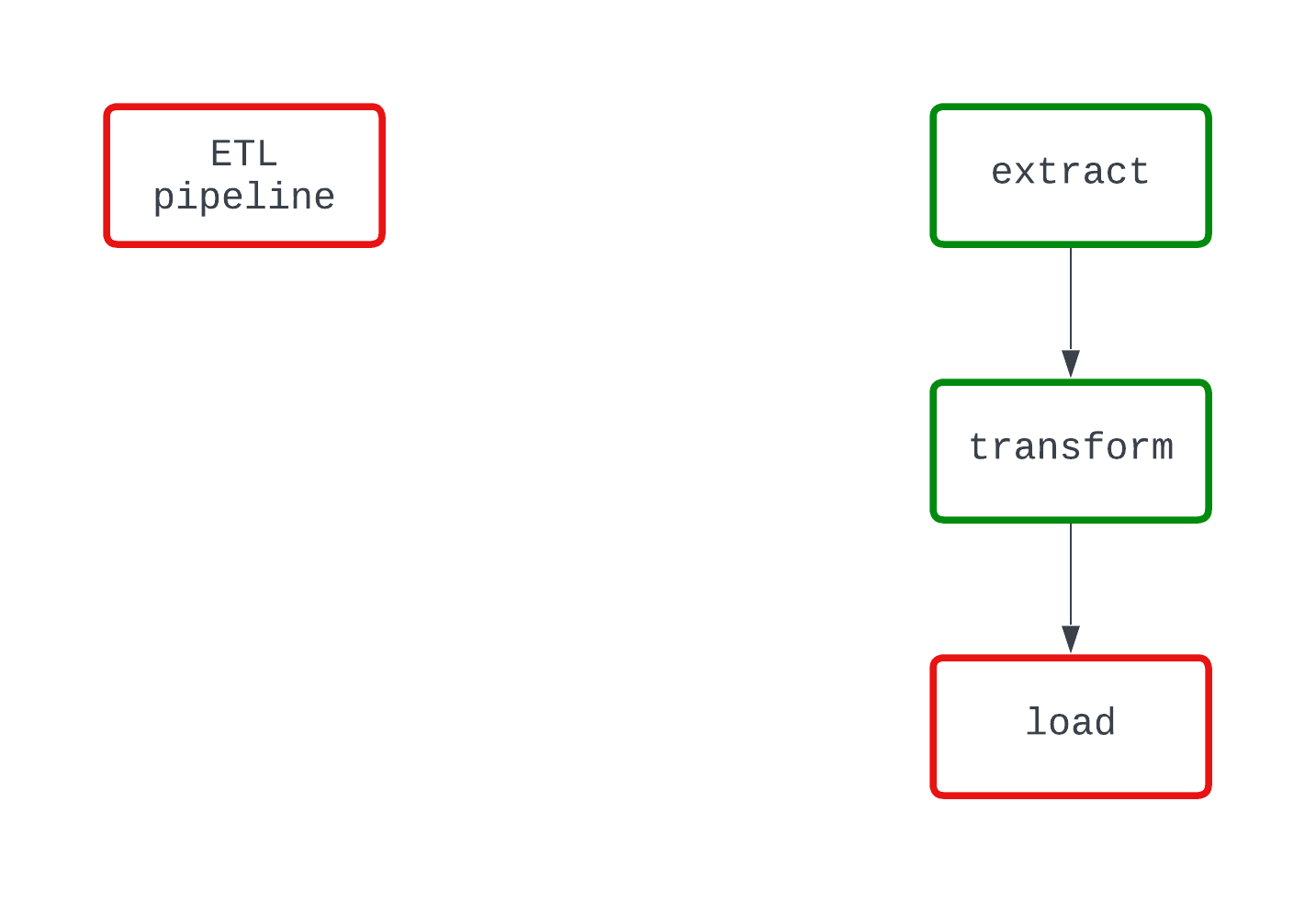
Aşağıdaki örneğe bakın. Her iki DAG de aynı şeyi yapar ve kodun aynı noktasında başarısız olur. Ancak soldaki DAG’de, hataya load mantığının neden olduğu açıktır; sağdaki DAG’den ise bu pek belli değildir.
Belirlenimci (deterministic) bir süreç, aynı girdi verildiğinde aynı sonucu üreten süreçtir. Bir DAG belirli bir aralık için çalıştığında, her seferinde aynı sonuçları üretmelidir. Veri hatlarının daha karmaşık bir özelliği olsa da, tutarlı sonuçları sağlamak için belirlilik önemlidir.
Airflow ile, zamansal veriler oluşturmak için datetime.now() fonksiyonunu kullanmak yerine, şablonlu alanları Airflow operatörlerine iletmek için Jinja şablonlamadan yararlanın.
Aynı aralık için bir DAG’i iki kez çalıştırırsanız ne olur? Peki ya 10 kez? Hedef depolama ortamınızda mükerrer verilerle mi karşılaşacaksınız? İdempotentlik, bir veri hattı birden çok kez yürütülse bile sanki yalnızca bir kez yürütülmüş gibi olmasını sağlar.
Veri hatlarını belirlenimci hale getirmek için, DAG’lerinize aşağıdaki mantığı eklemeyi düşünün:
INSERT kullanmak yerine yinelenen kayıtlara yol açmayacak sil-yaz (delete-write) desenini kullanın.Airflow, devasa miktarda veriyi işlemeye yönelik değildir. Birkaç gigabayttan fazla veri üzerinde dönüşüm çalıştırmak istiyorsanız, Airflow hâlâ iş için doğru araçtır; ancak dönüşümü çalıştırmak için Airflow’un dbt veya Databricks gibi başka bir aracı tetiklemesi gerekir.
Tipik olarak, görevler yerelde makinenizde veya üretimde çalışan düğümlerde yürütülür. Her iki durumda da gerekli hesaplamalar için yalnızca birkaç gigabayt bellek kullanılabilir olacaktır.
Daha büyük verileri düzenlerken Airflow’u çok hafif veri dönüşümleri ve bir orkestrasyon aracı olarak kullanmaya odaklanın.
Airflow’un veri hatlarını kod olarak tanımlama yeteneği ve çok çeşitli bağlayıcılar ve operatörleriyle, dünyanın dört bir yanındaki şirketler veri platformlarını güçlendirmeye yardımcı olması için Airflow’a güveniyor.
Sektörde bir veri ekibi, SFTP sitelerinden bulut dosya depolama sistemlerine ve bir veri lakehouse’una kadar çok çeşitli araçlarla çalışabilir. Bir veri platformu oluşturmak için bu farklı sistemlerin entegre edilmesi çok önemlidir.
Canlı bir açık kaynak topluluğuyla, veri araçlarınızı entegre etmeye yardımcı olacak binlerce hazır bağlayıcı vardır. S3’ten Snowflake’e bir dosya bırakmak mı istiyorsunuz? Şanslısınız, S3ToSnowflakeOperator tam da bunu kolaylaştırıyor! Great Expectations ile veri kalitesi kontrolleri nasıl olacak? O da zaten inşa edildi.
İşe uygun hazır bir araç bulamazsanız sorun değil. Airflow genişletilebilir olduğundan, ihtiyaçlarınıza uygun özel araçlarınızı kolayca oluşturabilirsiniz.
Airflow’u üretimde çalıştırırken, altyapıyı yönetmek için kullandığınız araçları da düşünmek isteyeceksiniz. Bunu yapmanın, Astronomer gibi premium çözümlerden MWAA gibi bulut yerel seçeneklere, hatta kendi geliştirdiğiniz bir çözüme kadar birçok yolu var.
Genellikle bu, maliyet ve altyapı yönetimi arasında bir ödünleşim içerir; daha pahalı çözümler daha az şey yönetmek anlamına gelebilirken, her şeyi tek bir EC2 örneğinde çalıştırmak ucuz olabilir ama bakımı zorlayıcıdır.
Apache Airflow, veri hatlarını üretimde çalıştırmak için sektör lideri bir araçtır. Zamanlama, genişletilebilirlik ve gözlemlenebilirlik gibi işlevler sunarken veri analistlerinin, bilim insanlarının ve mühendislerin veri hatlarını kod olarak tanımlamasına olanak tanıyarak, Airflow veri profesyonellerinin iş etkisine odaklanmasına yardımcı olur.
Özellikle Astro CLI ile Airflow’a başlamak kolaydır ve geleneksel operatörler ile TaskFlow API ilk DAG’lerinizi yazmayı basitleştirir. Airflow ile veri hatları oluştururken, tasarım kararlarınızın merkezine modülerlik, belirlilik ve idempotentliği koymayı unutmayın; bu en iyi uygulamalar, özellikle DAG’leriniz bir hatayla karşılaştığında ileride baş ağrılarından kaçınmanıza yardımcı olacaktır.
Airflow ile öğrenilecek çok şey var. Bir sonraki veri analitiği veya veri bilimi projenizde Airflow’a bir şans verin. Hazır operatörlerle denemeler yapın veya kendi operatörlerinizi oluşturun. Geleneksel operatörler ve TaskFlow API ile görevler arasında veri paylaşmayı deneyin. Sınırları zorlamaktan çekinmeyin. Başlamaya hazırsanız, Airflow’un temellerini kapsayan ve üretimde karmaşık veri mühendisliği hatlarının nasıl uygulanacağını inceleyen DataCamp’in Python ile Airflow’a Giriş kursuna göz atın.
Veri Hatlarına Giriş kursumuza da başlayabilir, etkili, verimli ve güvenilir veri hatları kurma becerilerinizi geliştirebilirsiniz. Son olarak, sizin için en iyi aracın hangisi olduğuna bakmak üzere Airflow ve Prefect karşılaştırmamızı inceleyebilirsiniz.
Daha fazlasını isterseniz aşağıdaki kaynaklara göz atın. Bol şans ve iyi kodlamalar!
https://airflow.apache.org/docs/apache-airflow/stable/project.html
https://airflow.apache.org/blog/airflow-survey-2022/
https://airflow.apache.org/docs/apache-airflow/1.10.9/installation.html
https://docs.astronomer.io/astro/cli/get-started-cli
https://airflow.apache.org/docs/apache-airflow/stable/tutorial/taskflow.html
https://airflow.apache.org/docs/apache-airflow/stable/templates-ref.html
Veri Hatları Yolculuğunuza Bugün Başlayın
Kurs
Kurs