
Kursus
Merancang Alur Kerja Machine Learning di Python
4 Hr
12.6K
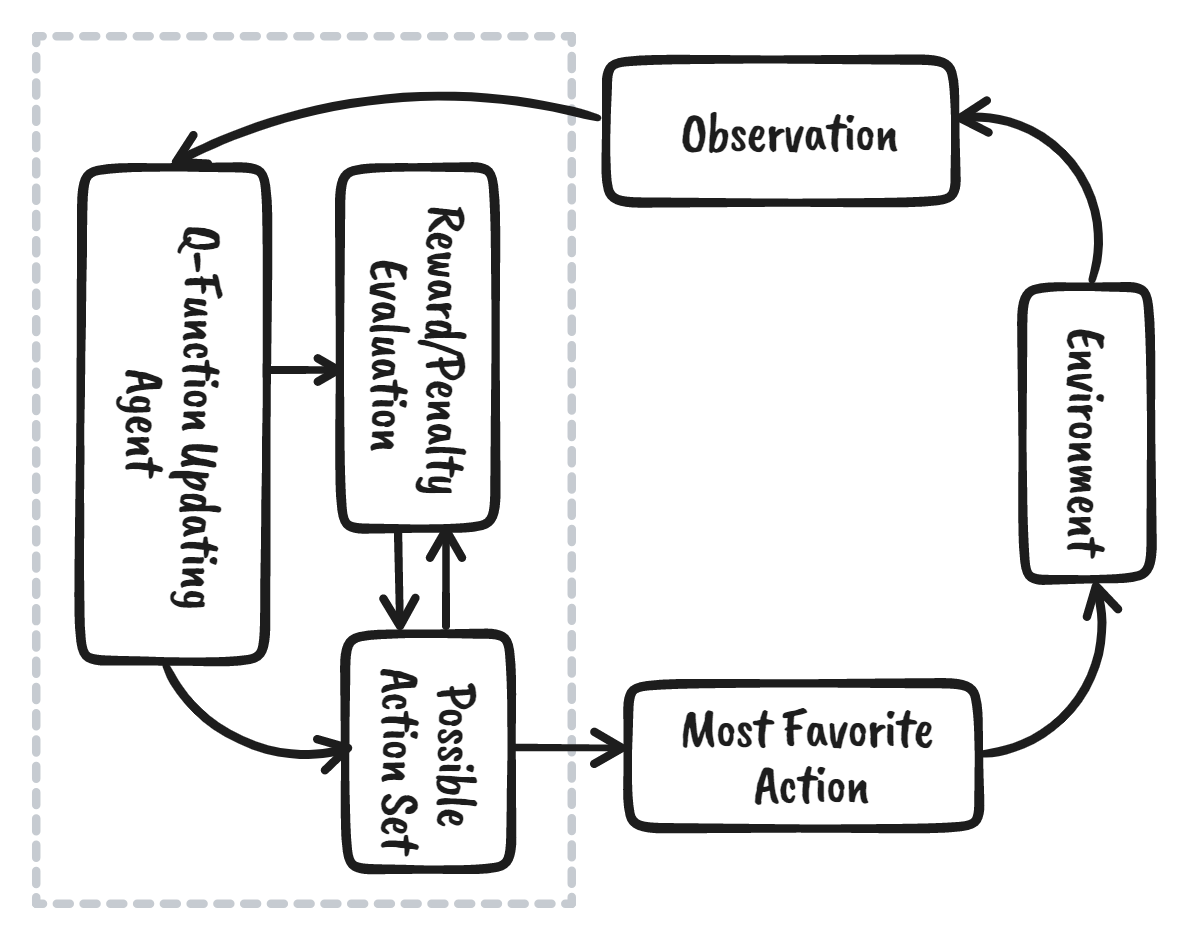
Reinforcement learning (RL) adalah bagian dari ekosistem machine learning di mana agen belajar dengan berinteraksi dengan lingkungan untuk mendapatkan strategi optimal guna mencapai tujuan. Ini cukup berbeda dari algoritma machine learning terawasi, yang mengharuskan kita memuat dan memproses data tersebut. Reinforcement learning tidak memerlukan data. Sebaliknya, ia belajar dari lingkungan dan sistem hadiah untuk membuat keputusan yang lebih baik.
Misalnya, dalam gim video Mario, jika sebuah karakter mengambil tindakan acak (misalnya bergerak ke kiri), berdasarkan tindakan itu, ia dapat menerima hadiah. Setelah mengambil tindakan tersebut, agen (Mario) berada pada keadaan baru, dan proses ini berulang hingga karakter gim mencapai akhir stage atau mati.
Episode ini akan berulang berkali-kali sampai Mario belajar menavigasi lingkungan dengan memaksimalkan hadiah.

Gambar oleh Penulis
Kita dapat menguraikan reinforcement learning menjadi lima langkah sederhana:
Pelajari lebih lanjut dengan membaca tutorial kami, Pengantar Reinforcement Learning. Anda akan mengeksplorasi lebih jauh cara kerja reinforcement learning dengan contoh kode.
Dalam tutorial ini, kita akan mempelajari Q-learning dan memahami mengapa kita memerlukan Deep Q-learning. Selain itu, kita akan belajar membuat dan melatih algoritma Q-learning dari nol menggunakan Numpy dan Gymnasium.
Catatan: Jika Anda baru dalam machine learning, kami merekomendasikan Anda mengikuti career track Machine Learning Scientist with Python untuk lebih memahami Reinforcement Learning dan Q-Learning.
Q-learning adalah algoritma model-free, berbasis nilai, dan off-policy yang akan menemukan rangkaian tindakan terbaik berdasarkan keadaan saat ini dari agen. Huruf “Q” adalah singkatan dari quality. Quality merepresentasikan seberapa bernilai suatu tindakan dalam memaksimalkan hadiah di masa depan.
Algoritma model-based menggunakan fungsi transisi dan fungsi hadiah untuk memperkirakan kebijakan optimal dan membuat model. Sebaliknya, algoritma model-free mempelajari konsekuensi dari tindakannya melalui pengalaman tanpa fungsi transisi dan hadiah.
Metode berbasis nilai melatih fungsi nilai untuk mempelajari keadaan mana yang lebih bernilai dan mengambil tindakan. Di sisi lain, metode berbasis kebijakan melatih kebijakan secara langsung untuk mempelajari tindakan mana yang harus diambil pada suatu keadaan tertentu.
Pada off-policy, algoritma mengevaluasi dan memperbarui kebijakan yang berbeda dari kebijakan yang digunakan untuk mengambil tindakan. Sebaliknya, algoritma on-policy mengevaluasi dan menyempurnakan kebijakan yang sama yang digunakan untuk mengambil tindakan.
Sebelum kita membahas cara kerja Q-learning, kita perlu mempelajari beberapa istilah yang berguna untuk memahami dasar-dasar Q-learning.
Kita akan mempelajari secara rinci cara kerja Q-learning dengan menggunakan contoh danau beku. Dalam lingkungan ini, agen harus melintasi danau beku dari awal hingga tujuan, tanpa jatuh ke lubang. Strategi terbaik adalah mencapai tujuan dengan menempuh jalur terpendek.

Gif oleh Penulis
Agen akan menggunakan Q-table untuk mengambil tindakan terbaik berdasarkan hadiah yang diharapkan untuk setiap keadaan di lingkungan. Sederhananya, Q-table adalah struktur data berupa himpunan tindakan dan keadaan, dan kita menggunakan algoritma Q-learning untuk memperbarui nilai-nilai di tabel.
Q-function menggunakan persamaan Bellman dan menerima state(s) dan action(a) sebagai masukan. Persamaan ini menyederhanakan perhitungan nilai keadaan dan nilai keadaan-tindakan. 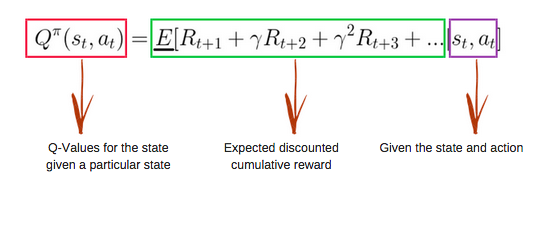
Gambar dari freecodecamp.org
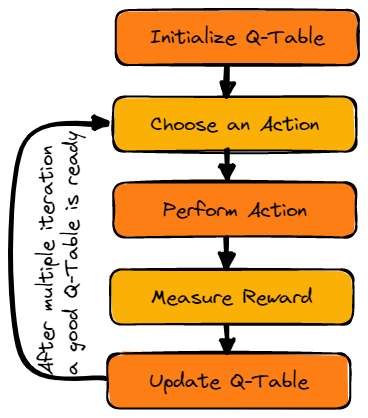
Gambar oleh Penulis
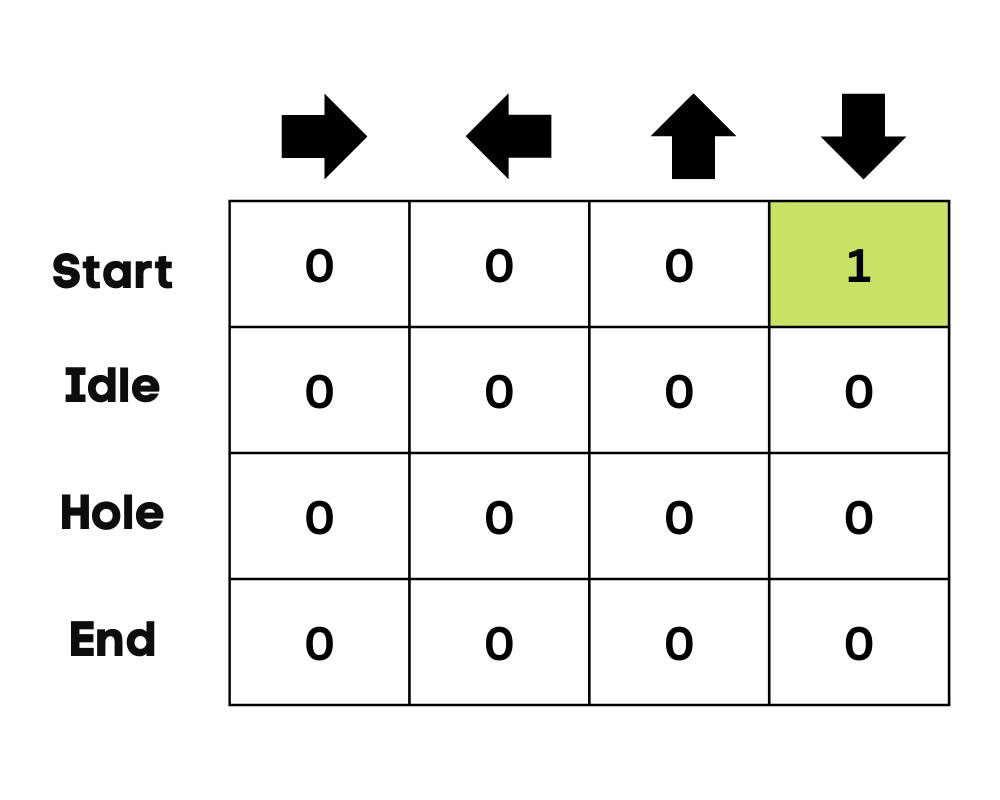
Kita akan terlebih dahulu menginisialisasi Q-table. Kita akan membangun tabel dengan kolom berdasarkan jumlah tindakan dan baris berdasarkan jumlah keadaan.
Pada contoh kita, karakter dapat bergerak ke atas, bawah, kiri, dan kanan. Kita memiliki empat kemungkinan tindakan dan empat keadaan (mulai, Diam, jalur salah, dan akhir). Anda juga dapat menganggap jalur salah sebagai jatuh ke lubang. Kita akan menginisialisasi Q-Table dengan nilai 0.
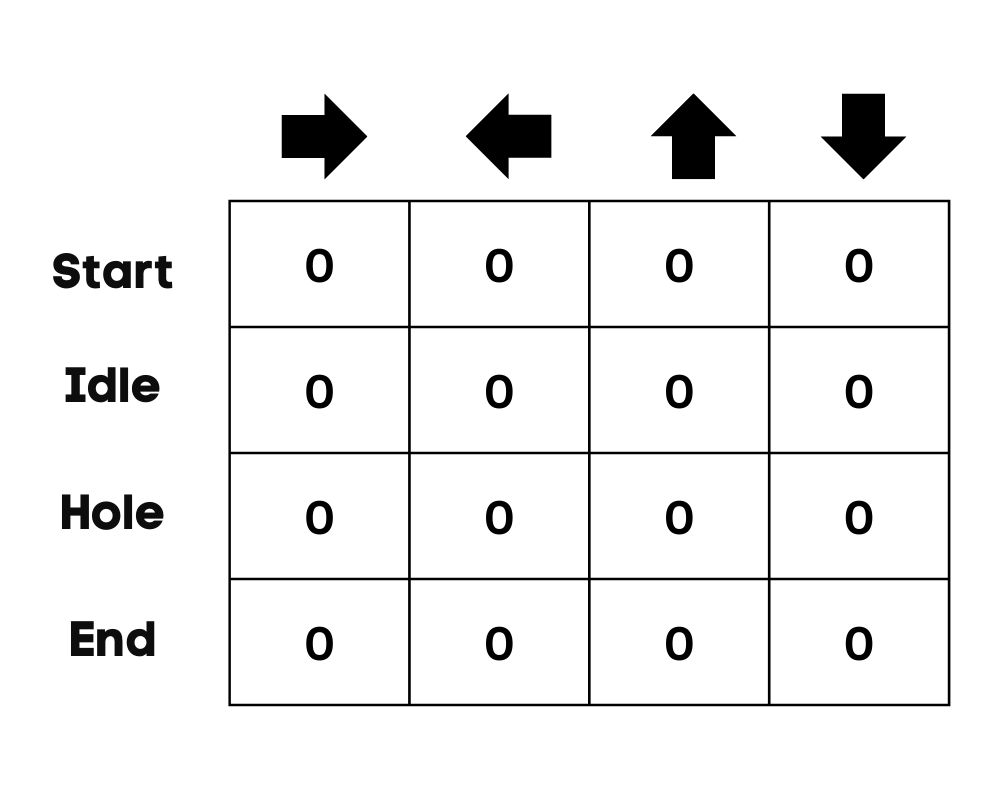
Gambar oleh Penulis
Langkah kedua cukup sederhana. Pada awalnya, agen akan memilih untuk mengambil tindakan acak (turun atau kanan), dan pada putaran kedua, ia akan menggunakan Q-Table yang telah diperbarui untuk memilih tindakan.
Memilih tindakan dan melakukan tindakan akan berulang berkali-kali hingga loop pelatihan berhenti. Tindakan dan keadaan pertama dipilih menggunakan Q-Table. Dalam kasus kita, semua nilai pada Q-Table adalah nol.
Kemudian, agen akan bergerak turun dan memperbarui Q-Table menggunakan persamaan Bellman. Dengan setiap langkah, kita akan memperbarui nilai pada Q-Table dan juga menggunakannya untuk menentukan tindakan terbaik.
Awalnya, agen berada dalam mode eksplorasi dan memilih tindakan acak untuk menjelajahi lingkungan. Epsilon Greedy Strategy adalah metode sederhana untuk menyeimbangkan eksplorasi dan eksploitasi. Epsilon merepresentasikan probabilitas memilih untuk mengeksplorasi dan mengekspolitasi ketika peluang eksplorasi lebih kecil.
Pada awalnya, laju epsilon lebih tinggi, artinya agen berada dalam mode eksplorasi. Saat menjelajahi lingkungan, epsilon menurun, dan agen mulai mengeksploitasi lingkungan. Selama eksplorasi, pada setiap iterasi, agen menjadi lebih percaya diri dalam memperkirakan nilai Q
Gambar oleh Penulis
Pada contoh danau beku, agen tidak mengetahui lingkungan, sehingga ia mengambil tindakan acak (bergerak turun) untuk memulai. Seperti terlihat pada gambar di atas, Q-Table diperbarui menggunakan persamaan Bellman.
Setelah mengambil tindakan, kita akan mengukur hasil dan hadiahnya.
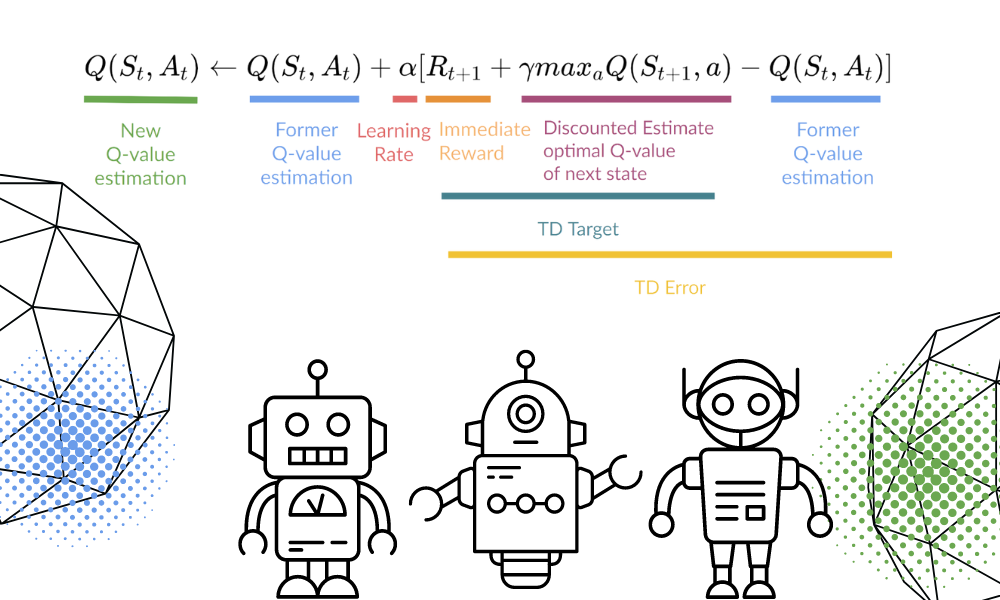
Kita akan memperbarui fungsi Q(St, At) menggunakan persamaan. Fungsi ini menggunakan estimasi nilai Q episode sebelumnya, laju pembelajaran, dan galat Temporal Differences. Galat Temporal Differences dihitung menggunakan hadiah langsung, diskonto maksimum hadiah masa depan yang diharapkan, dan estimasi nilai Q sebelumnya.
Proses ini diulang berkali-kali hingga Q-Table diperbarui dan fungsi nilai Q dimaksimalkan.
Gambar oleh Penulis | Visual Persamaan dari Thomas Simonini
Pada awalnya, agen sedang mengeksplorasi lingkungan untuk memperbarui Q-table. Dan ketika Q-Table sudah siap, agen akan mulai mengeksploitasi dan mulai mengambil keputusan yang lebih baik. 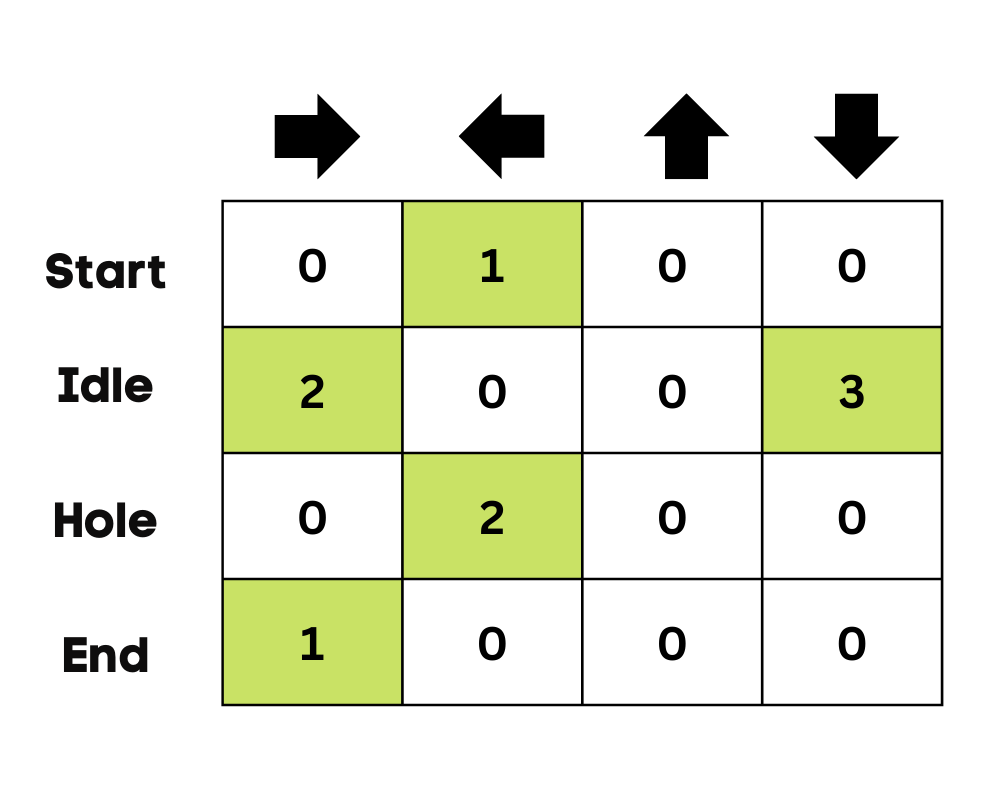
Gambar oleh Penulis
Pada kasus danau beku, agen akan belajar mengambil jalur terpendek untuk mencapai tujuan dan menghindari melompat ke lubang.
Pada bagian ini, kita akan membangun model Q-learning dari nol menggunakan lingkungan Gymnasium, Pygame, dan Numpy. Tutorial Python ini adalah versi modifikasi dari Notebook oleh Thomas Simonini. Ini mencakup inisialisasi lingkungan dan Q-Table, mendefinisikan kebijakan greedy, menyetel hiperparameter, membuat dan menjalankan loop pelatihan serta evaluasi, dan memvisualisasikan hasilnya.
Jika Anda mengalami masalah saat membuat dan menjalankan loop pelatihan, Anda dapat memeriksa sumber kode beserta keluarannya.
Kita terlebih dahulu akan memasang semua dependensi untuk menghasilkan video replay (Gif). Kita memerlukan layar virtual (pyvirtualdisplay) untuk merender lingkungan dan merekam frame.
Catatan: dengan menggunakan %%capture kita menekan keluaran sel Jupyter.
%%capture
!pip install pyglet==1.5.1
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip3 install pyvirtualdisplay
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()Selanjutnya kita akan memasang dependensi yang akan membantu kita membuat, menjalankan, dan mengevaluasi loop pelatihan.
%%capture
!pip install gymnasium
!pip install pygame
!pip install numpy
!pip install imageio imageio_ffmpegSekarang kita akan mengimpor pustaka yang diperlukan.
import numpy as np
import gymnasium as gym
import random
import imageio
from tqdm.notebook import trangeKita akan membuat lingkungan 4x4 non-slippery menggunakan pustaka Gymnasium Frozen Lake.
is_slippery=True, agen mungkin tidak bergerak ke arah yang diinginkan karena sifat licin dari danau beku. Setelah menginisialisasi lingkungan, kita akan melakukan analisis lingkungan.
env = gym.make("FrozenLake-v1",map_name="4x4",is_slippery=False)
print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # display a random observationAda 16 ruang unik di lingkungan yang ditampilkan pada posisi acak.
Observation Space Discrete(16)
Sample observation 15Mari cari tahu jumlah tindakan dan tampilkan tindakan acak.
Ruang tindakan:
Fungsi hadiah:
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample())Action Space Shape 4
Action Space Sample 1Q-Table memiliki kolom sebagai tindakan, dan baris sebagai keadaan. Kita dapat menggunakan Gymnasium untuk menemukan ruang tindakan dan ruang keadaan. Lalu, kita akan menggunakan informasi ini untuk membuat Q-Table.
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
action_space = env.action_space.n
print("There are ", action_space, " possible actions")There are 16 possible states
There are 4 possible actionsUntuk menginisialisasi Q-Table, kita akan membuat array Numpy dari state_space dan action space. Kita akan membuat array 16 X 4.
def initialize_q_table(state_space, action_space):
Qtable = np.zeros((state_space, action_space))
return Qtable
Qtable_frozenlake = initialize_q_table(state_space, action_space)Pada bagian sebelumnya, kita telah mempelajari strategi epsilon greedy yang menangani trade-off eksplorasi dan eksploitasi. Dengan probabilitas 1 - ɛ, kita melakukan eksploitasi, dan dengan probabilitas ɛ, kita melakukan eksplorasi.
Dalam epsilon_greedy_policy kita akan:
def epsilon_greedy_policy(Qtable, state, epsilon):
random_int = random.uniform(0,1)
if random_int > epsilon:
action = np.argmax(Qtable[state])
else:
action = env.action_space.sample()
return actionSeperti yang kini kita ketahui, Q-learning adalah algoritma off-policy yang berarti kebijakan untuk mengambil tindakan dan kebijakan untuk memperbarui fungsi berbeda.
Pada contoh ini, kebijakan Epsilon Greedy adalah kebijakan bertindak, dan kebijakan Greedy adalah kebijakan pembaruan.
Kebijakan Greedy juga akan menjadi kebijakan final saat agen telah dilatih. Kebijakan ini digunakan untuk memilih nilai keadaan dan tindakan tertinggi dari Q-Table.
def greedy_policy(Qtable, state):
action = np.argmax(Qtable[state])
return actionHiperparameter ini digunakan dalam loop pelatihan, dan penyetelannya akan memberikan hasil yang lebih baik.
Agen perlu mengeksplorasi ruang keadaan yang cukup untuk mempelajari pendekatan nilai yang baik; kita perlu memiliki penurunan epsilon yang progresif. Jika laju penurunan tinggi, agen mungkin terjebak karena belum mengeksplorasi ruang keadaan yang cukup.
# Training parameters
n_training_episodes = 10000
learning_rate = 0.7
# Evaluation parameters
n_eval_episodes = 100
# Environment parameters
env_id = "FrozenLake-v1"
max_steps = 99
gamma = 0.95
eval_seed = []
# Exploration parameters
max_epsilon = 1.0
min_epsilon = 0.05
decay_rate = 0.0005 Di dalam loop pelatihan, kita akan:
done= True, akhiri episode dan hentikan loop.def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in trange(n_training_episodes):
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
state = env.reset()
step = 0
done = False
# repeat
for step in range(max_steps):
action = epsilon_greedy_policy(Qtable, state, epsilon)
new_state, reward, done, info = env.step(action)
Qtable[state][action] = Qtable[state][action] + learning_rate * (reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action])
# If done, finish the episode
if done:
break
# Our state is the new state
state = new_state
return QtableDibutuhkan 3 detik untuk menyelesaikan 10.000 episode pelatihan.
Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
Seperti yang terlihat, Q-Table yang dilatih memiliki nilai, dan agen sekarang akan menggunakan nilai-nilai ini untuk menavigasi lingkungan dan mencapai tujuan.
Qtable_frozenlakearray([[0.73509189, 0.77378094, 0.77378094, 0.73509189], [0.73509189, 0. , 0.81450625, 0.77378094], [0.77378094, 0.857375 , 0.77378094, 0.81450625], [0.81450625, 0. , 0.77378094, 0.77378094], [0.77378094, 0.81450625, 0. , 0.73509189], [0. , 0. , 0. , 0. ], [0. , 0.9025 , 0. , 0.81450625], [0. , 0. , 0. , 0. ], [0.81450625, 0. , 0.857375 , 0.77378094], [0.81450625, 0.9025 , 0.9025 , 0. ], [0.857375 , 0.95 , 0. , 0.857375 ], [0. , 0. , 0. , 0. ], [0. , 0. , 0. , 0. ], [0. , 0.9025 , 0.95 , 0.857375 ], [0.9025 , 0.95 , 1. , 0.9025 ], [0. , 0. , 0. , 0. ]])Evaluasi
Fungsi evaluate_agent berjalan selama
n_eval_episodesepisode dan mengembalikan mean dan standar deviasi dari hadiah.
- Di dalam loop, pertama-tama kita akan memeriksa apakah ada evaluation seed. Jika tidak ada, maka kita akan me-reset lingkungan tanpa seed.
- Loop bersarang akan berjalan hingga max_steps.
- Agen akan mengambil tindakan yang memiliki hadiah masa depan yang diharapkan maksimum pada keadaan tertentu menggunakan Q-Table.
- Hitung hadiah.
- Ubah keadaan.
- Jika selesai (agen jatuh ke lubang atau tujuan tercapai), hentikan loop.
- Tambahkan hasilnya.
- Pada akhirnya, kita akan menggunakan hasil ini untuk menghitung mean dan standar deviasi.
def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed): episode_rewards = [] for episode in range(n_eval_episodes): if seed: state = env.reset(seed=seed[episode]) else: state = env.reset() step = 0 done = False total_rewards_ep = 0 for step in range(max_steps): # Take the action (index) that have the maximum reward action = np.argmax(Q[state][:]) new_state, reward, done, info = env.step(action) total_rewards_ep += reward if done: break state = new_state episode_rewards.append(total_rewards_ep) mean_reward = np.mean(episode_rewards) std_reward = np.std(episode_rewards) return mean_reward, std_rewardSeperti yang Anda lihat, kita mendapatkan skor sempurna dengan standar deviasi nol. Ini berarti agen kita telah mencapai tujuan di semua 100 episode.
# Evaluate our Agent mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed) print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")Mean_reward=1.00 +/- 0.00Memvisualisasikan hasil
Sejauh ini, kita bermain dengan angka, dan untuk memberi demo, kita perlu membuat Gif animasi dari agen sejak awal hingga mencapai tujuan.
- Kita akan terlebih dahulu membuat state dengan me-reset lingkungan menggunakan bilangan bulat acak 0–500.
- Render lingkungan menggunakan rdb_array untuk membuat array gambar.
- Lalu tambahkan
imgke arrayimages.- Di dalam loop, kita akan mengambil langkah menggunakan Q-Table dan merender gambar untuk setiap langkah.
- Pada akhirnya, kita akan menggunakan array ini dan imageio untuk membuat Gif satu frame per detik.
def record_video(env, Qtable, out_directory, fps=1): images = [] done = False state = env.reset(seed=random.randint(0,500)) img = env.render(mode='rgb_array') images.append(img) while not done: # Take the action (index) that have the maximum expected future reward given that state action = np.argmax(Qtable[state][:]) state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic img = env.render(mode='rgb_array') images.append(img) imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)Jika Anda berada di Jupyter notebook, Anda dapat menampilkan Gif menggunakan fungsi Image dari
IPython.display.video_path="/content/replay.gif" video_fps=1 record_video(env, Qtable_frozenlake, video_path, video_fps) from IPython.display import Image Image('./replay.gif')Sekarang Anda dapat membagikan hasil ini dengan rekan kerja dan teman sekelas atau mempostingnya di media sosial.
Kursus Machine Learning
Kursus
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
