Cours
Concevoir des workflows de Machine Learning en Python
4 h
12.6K
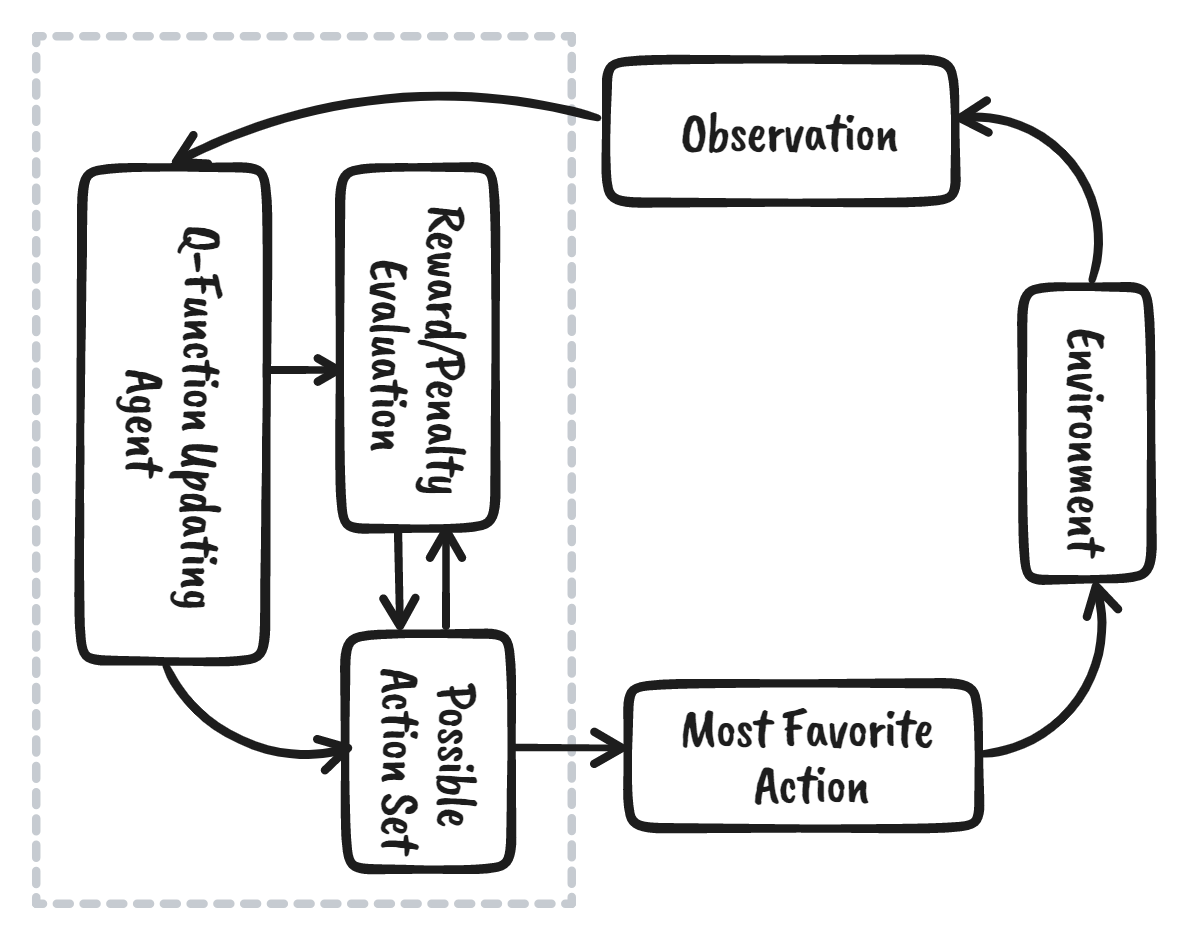
L'apprentissage par renforcement (RL) est la partie de l'écosystème de l'apprentissage automatique où l'agent apprend en interagissant avec l'environnement afin d'obtenir la stratégie optimale pour atteindre les objectifs. C'est très différent des algorithmes d'apprentissage automatique supervisé, pour lesquels nous devons ingérer et traiter ces données. L'apprentissage par renforcement ne nécessite pas de données. Au lieu de cela, il apprend de l'environnement et du système de récompense pour prendre de meilleures décisions.
Par exemple, dans le jeu vidéo Mario, si un personnage effectue une action aléatoire (par exemple, se déplacer vers la gauche), il peut recevoir une récompense en fonction de cette action. Après avoir effectué l'action, l'agent (Mario) se trouve dans un nouvel état, et le processus se répète jusqu'à ce que le personnage du jeu atteigne la fin de l'étape ou meure.
Cet épisode se répète plusieurs fois jusqu'à ce que Mario apprenne à naviguer dans l'environnement en maximisant les récompenses.

Image par l'auteur
Nous pouvons décomposer l'apprentissage par renforcement en cinq étapes simples :
Pour en savoir plus, lisez notre tutoriel, Introduction à l'apprentissage par renforcement. Vous découvrirez le fonctionnement de l'apprentissage par renforcement à l'aide d'exemples de code.
Dans ce tutoriel, nous allons apprendre ce qu'est l'apprentissage Q et comprendre pourquoi nous avons besoin de l'apprentissage Q profond. De plus, nous apprendrons à créer et à entraîner des algorithmes d'apprentissage Q à partir de zéro en utilisant Numpy et OpenAI Gym.
Note: Si vous êtes novice en matière d'apprentissage automatique, nous vous recommandons de suivre notre parcours Machine Learning Scientist with Python pour mieux comprendre l'apprentissage par renforcement et le Q-Learning.
L'apprentissage Q est un algorithme sans modèle, basé sur la valeur et hors politique, qui trouvera la meilleure série d'actions en fonction de l'état actuel de l'agent. Le "Q" signifie qualité. La qualité représente la valeur de l'action pour maximiser les récompenses futures.
Les algorithmes basés sur un modèle utilisent des fonctions de transition et de récompense pour estimer la politique optimale et créer le modèle. En revanche, les algorithmes sans modèle apprennent les conséquences de leurs actions par l'expérience, sans transition ni fonction de récompense.
La méthode basée sur la valeur entraîne la fonction de valeur à apprendre quel état a le plus de valeur et à prendre des mesures. D'autre part, les méthodes basées sur la politique entraînent directement la politique pour apprendre quelle action entreprendre dans un état donné.
Dans le cas d'une politique hors norme, l'algorithme évalue et met à jour une politique qui diffère de celle utilisée pour prendre une mesure. Inversement, l'algorithme "on-policy" évalue et améliore la même politique que celle utilisée pour prendre une mesure.
Avant d'aborder le fonctionnement du Q-learning, nous devons apprendre quelques termes utiles pour comprendre les principes fondamentaux du Q-learning.
Nous verrons en détail comment fonctionne l'apprentissage par la méthode des quotas en prenant l'exemple d'un lac gelé. Dans cet environnement, l'agent doit traverser le lac gelé du point de départ au point d'arrivée, sans tomber dans les trous. La meilleure stratégie consiste à atteindre les objectifs en empruntant le chemin le plus court.

Gif par auteur
L'agent utilisera un tableau Q pour prendre la meilleure action possible en fonction de la récompense attendue pour chaque état de l'environnement. En d'autres termes, un tableau Q est une structure de données composée d'ensembles d'actions et d'états, et nous utilisons l'algorithme d'apprentissage Q pour mettre à jour les valeurs du tableau.
La fonction Q utilise l'équation de Bellman et prend l'état(s) et l'action(a) en entrée. L'équation simplifie le calcul des valeurs d'état et des valeurs d'état-action. 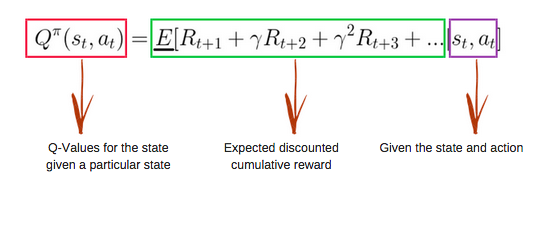
Image de freecodecamp.org
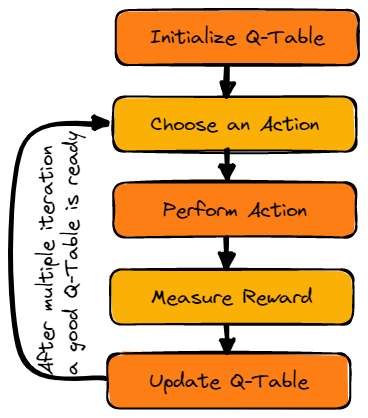
Image par l'auteur
Nous allons d'abord initialiser le tableau Q. Nous construirons le tableau avec des colonnes basées sur le nombre d'actions et des lignes basées sur le nombre d'états.
Dans notre exemple, le personnage peut se déplacer vers le haut, le bas, la gauche et la droite. Nous avons quatre actions possibles et quatre états (début, inactif, mauvais chemin et fin). Vous pouvez également considérer que le mauvais chemin est à l'origine de la chute dans le trou. Nous allons initialiser le tableau Q avec des valeurs à 0.
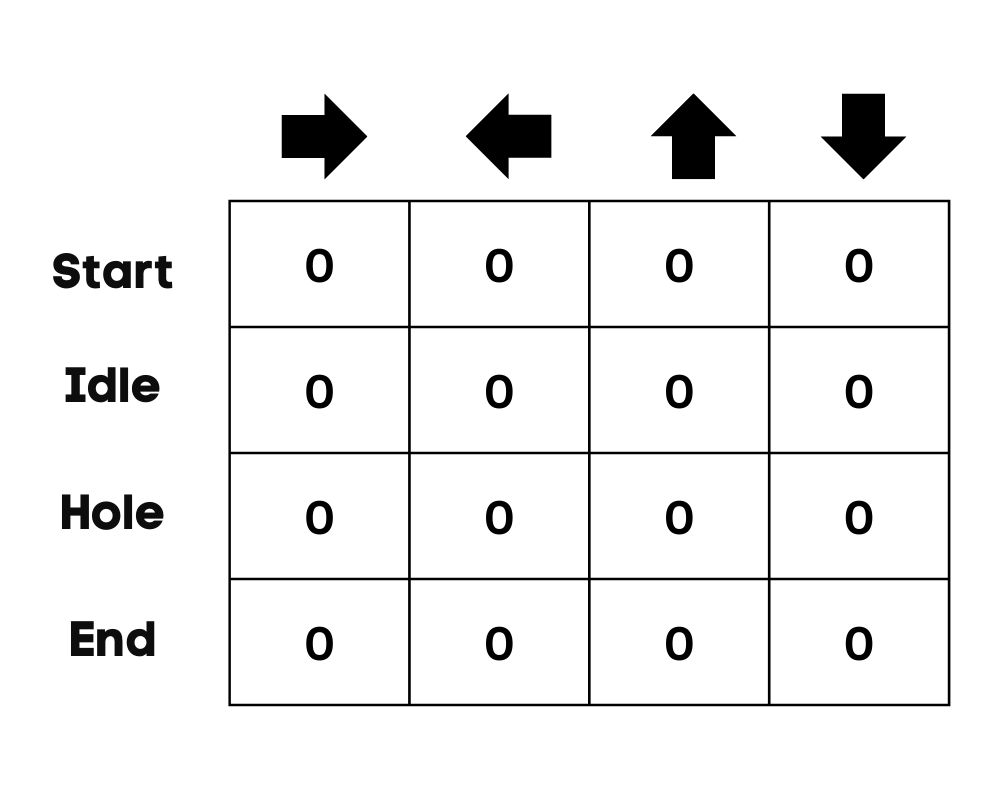
Image par l'auteur
La deuxième étape est très simple. Au départ, l'agent choisira une action aléatoire (vers le bas ou vers la droite), et lors de la deuxième exécution, il utilisera un tableau Q mis à jour pour sélectionner l'action.
Le choix d'une action et son exécution se répètent plusieurs fois jusqu'à ce que la boucle d'entraînement s'arrête. La première action et le premier état sont sélectionnés à l'aide du tableau Q. Dans notre cas, toutes les valeurs du tableau Q sont nulles.
Ensuite, l'agent se déplace vers le bas et met à jour le tableau Q à l'aide de l'équation de Bellman. À chaque coup, nous mettrons à jour les valeurs du tableau Q et nous l'utiliserons également pour déterminer le meilleur plan d'action.
Au départ, l'agent est en mode exploration et choisit une action aléatoire pour explorer l'environnement. La stratégie Epsilon Greedy est une méthode simple pour équilibrer l'exploration et l'exploitation. L'epsilon représente la probabilité de choisir d'explorer et d'exploiter lorsque les chances d'explorer sont moindres.
Au début, le taux epsilon est plus élevé, ce qui signifie que l'agent est en mode exploration. Lors de l'exploration de l'environnement, l'epsilon diminue et les agents commencent à exploiter l'environnement. Au cours de l'exploration, à chaque itération, l'agent devient plus confiant dans l'estimation des valeurs Q
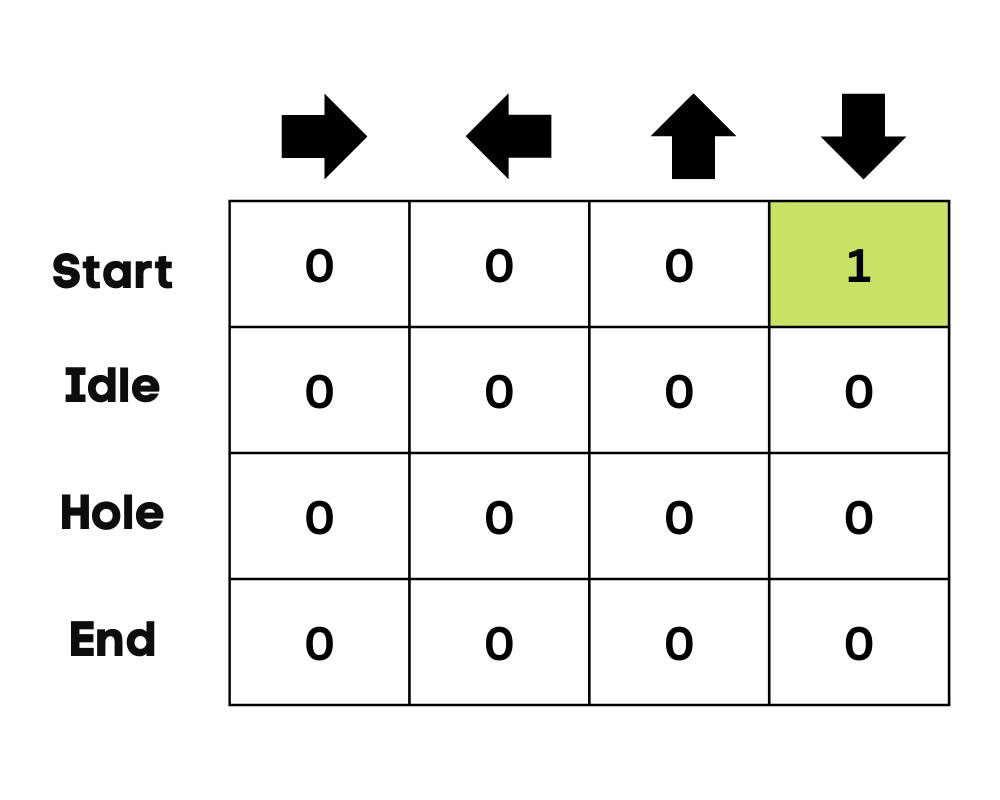
Image par l'auteur
Dans l'exemple du lac gelé, l'agent n'est pas conscient de l'environnement, il entreprend donc une action aléatoire (se déplacer vers le bas) pour commencer. Comme le montre l'image ci-dessus, la table Q est mise à jour à l'aide de l'équation de Bellman.
Après avoir agi, nous mesurerons le résultat et la récompense.
Nous mettrons à jour la fonction Q(St,At) à l'aide de l'équation. Il utilise les valeurs Q estimées, le taux d'apprentissage et l'erreur de différence temporelle de l'épisode précédent. L'erreur de différence temporelle est calculée à partir de la récompense immédiate, de la récompense future maximale escomptée actualisée et de la valeur Q de l'ancienne estimation.
Le processus est répété plusieurs fois jusqu'à ce que le tableau Q soit mis à jour et que la fonction de valeur Q soit maximisée.
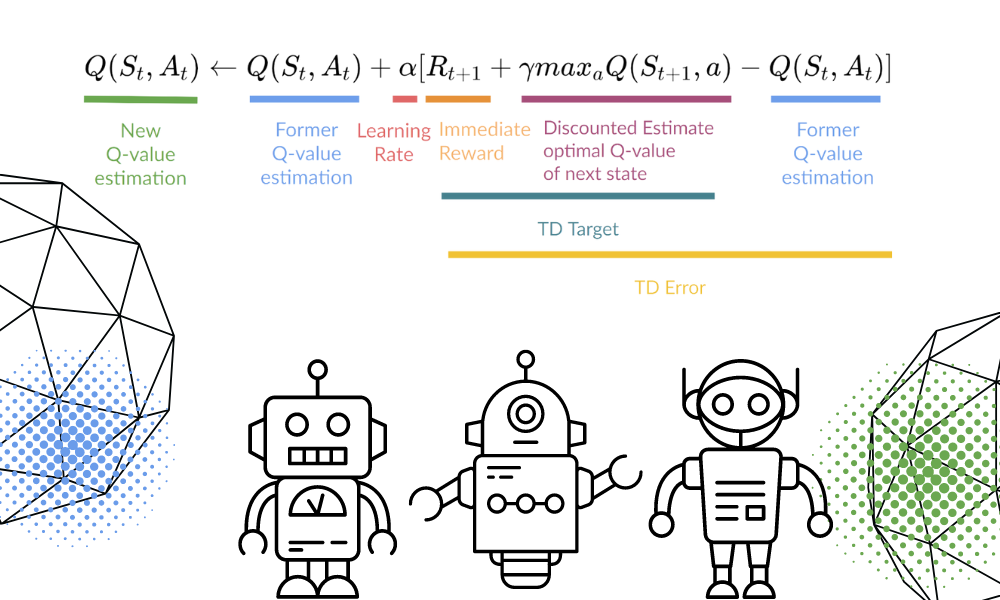
Image par l'auteur | Equation Visuals de Thomas Simonini
Au départ, l'agent explore l'environnement pour mettre à jour le tableau Q. Et lorsque le tableau Q est prêt, l'agent commence à exploiter et à prendre de meilleures décisions. 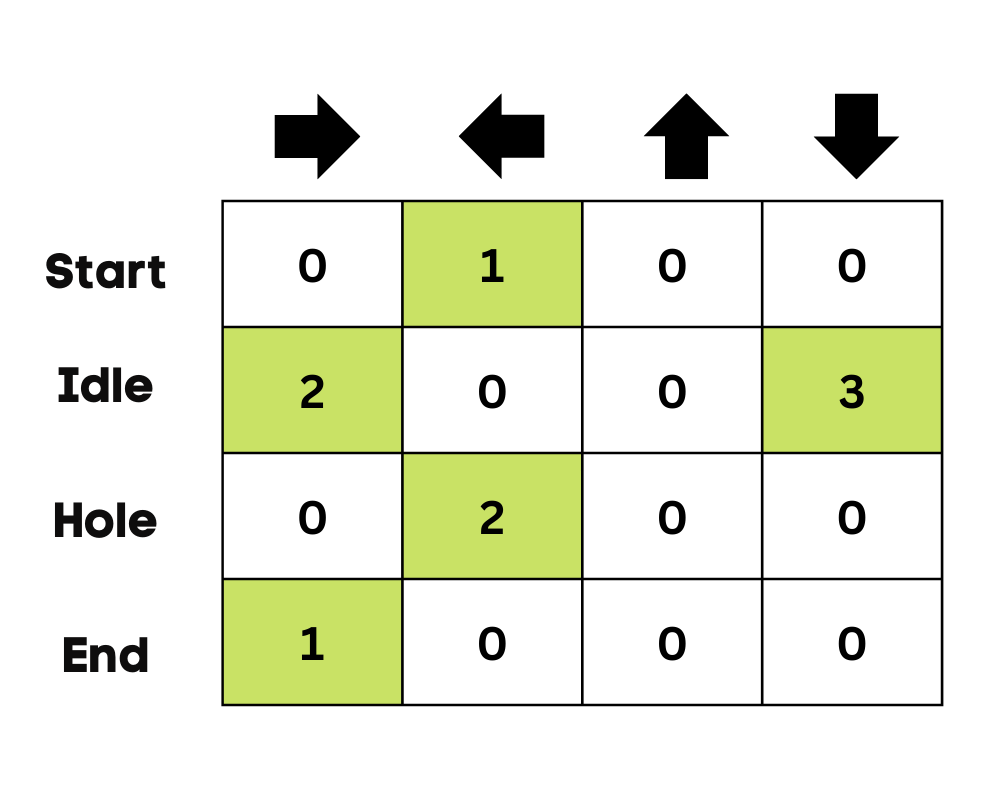
Image par l'auteur
Dans le cas d'un lac gelé, l'agent apprendra à prendre le chemin le plus court pour atteindre l'objectif et éviter de sauter dans les trous.
Dans cette section, nous allons construire notre modèle d'apprentissage Q à partir de zéro en utilisant l'environnement Gym, Pygame et Numpy. Le tutoriel Python est une version modifiée du Cahier de Thomas Simonini. Il comprend l'initialisation de l'environnement et du tableau Q, la définition de la politique gourmande, le réglage des hyperparamètres, la création et l'exécution de la boucle d'entraînement et de l'évaluation, ainsi que la visualisation des résultats.
Si vous rencontrez des problèmes lors de la création et de l'exécution de votre boucle d'entraînement, vous pouvez consulter le code source avec le résultat.
Nous allons d'abord installer toutes les dépendances nécessaires à la génération d'un replay vidéo (Gif). Nous aurons besoin d'un écran virtuel (pyvirtualdisplay) pour rendre l'environnement et enregistrer les images.
Remarque: en utilisant %%capture, nous supprimons la sortie de la cellule Jupyter.
%%capture
!pip install pyglet==1.5.1
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip3 install pyvirtualdisplay
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()Nous allons maintenant installer les dépendances qui nous aideront à créer, exécuter et évaluer la boucle de formation.
%%capture
!pip install gym==0.24
!pip install pygame
!pip install numpy
!pip install imageio imageio_ffmpegNous allons maintenant importer les bibliothèques nécessaires.
import numpy as np
import gym
import random
import imageio
from tqdm.notebook import trangeNous allons créer un environnement 4x4 non glissant en utilisant la bibliothèque de gymnastique Frozen Lake.
is_slippery=True, l'agent peut ne pas se déplacer dans la direction voulue en raison de la nature glissante du lac gelé. Après avoir initialisé l'environnement, nous procéderons à une analyse environnementale.
env = gym.make("FrozenLake-v1",map_name="4x4",is_slippery=False)
print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # display a random observationIl y a 16 espaces uniques dans l'environnement, affichés à des positions aléatoires.
Observation Space Discrete(16)
Sample observation 15Découvrons le nombre d'actions et affichons l'action aléatoire.
L'espace d'action:
Fonction de récompense:
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample())Action Space Shape 4
Action Space Sample 1Le tableau Q comporte des colonnes représentant des actions et des lignes représentant des états. Nous pouvons utiliser OpenAI Gym pour trouver l'espace d'action et l'espace d'état. Nous utiliserons ensuite ces informations pour créer le tableau Q.
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
action_space = env.action_space.n
print("There are ", action_space, " possible actions")There are 16 possible states
There are 4 possible actionsPour initialiser le tableau Q, nous allons créer un tableau Numpy de l'espace des états et de l'espace des actions. Nous allons créer un réseau de 16 x 4.
def initialize_q_table(state_space, action_space):
Qtable = np.zeros((state_space, action_space))
return Qtable
Qtable_frozenlake = initialize_q_table(state_space, action_space)Dans la section précédente, nous avons découvert la stratégie cupide epsilon qui gère les compromis entre l'exploration et l'exploitation. Avec une probabilité de 1 - ɛ, nous faisons de l'exploitation, et avec la probabilité ɛ, nous faisons de l'exploration.
Dans la politique epsilon_greedy_policy, nous allons :
def epsilon_greedy_policy(Qtable, state, epsilon):
random_int = random.uniform(0,1)
if random_int > epsilon:
action = np.argmax(Qtable[state])
else:
action = env.action_space.sample()
return actionComme nous le savons maintenant, l'apprentissage Q est un algorithme hors politique, ce qui signifie que la politique d'action et la fonction de mise à jour sont différentes.
Dans cet exemple, la politique Epsilon Greedy est la politique d'action et la politique Greedy est la politique de mise à jour.
La politique gourmande sera également la politique finale lorsque l'agent sera formé. Il est utilisé pour sélectionner la valeur d'état et d'action la plus élevée dans le tableau Q.
def greedy_policy(Qtable, state):
action = np.argmax(Qtable[state])
return actionCes hyperparamètres sont utilisés dans la boucle d'apprentissage, et leur réglage fin vous permettra d'obtenir de meilleurs résultats.
L'agent doit explorer suffisamment d'espace d'état pour apprendre une bonne approximation de la valeur ; nous avons besoin d'une décroissance progressive d'epsilon. Si le taux de décroissance est élevé, l'agent risque d'être bloqué car il n'a pas exploré suffisamment d'espace d'état.
# Training parameters
n_training_episodes = 10000
learning_rate = 0.7
# Evaluation parameters
n_eval_episodes = 100
# Environment parameters
env_id = "FrozenLake-v1"
max_steps = 99
gamma = 0.95
eval_seed = []
# Exploration parameters
max_epsilon = 1.0
min_epsilon = 0.05
decay_rate = 0.0005 Dans la boucle de formation, nous allons :
done= True, terminez l'épisode et interrompez la boucle.def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in trange(n_training_episodes):
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
state = env.reset()
step = 0
done = False
# repeat
for step in range(max_steps):
action = epsilon_greedy_policy(Qtable, state, epsilon)
new_state, reward, done, info = env.step(action)
Qtable[state][action] = Qtable[state][action] + learning_rate * (reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action])
# If done, finish the episode
if done:
break
# Our state is the new state
state = new_state
return QtableIl nous a fallu 3 secondes pour terminer 10 000 épisodes de formation.
Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
Comme nous pouvons le voir, le tableau Q formé a des valeurs, et l'agent va maintenant utiliser ces valeurs pour naviguer dans l'environnement et atteindre l'objectif.
Qtable_frozenlakearray([[0.73509189, 0.77378094, 0.77378094, 0.73509189],
[0.73509189, 0. , 0.81450625, 0.77378094],
[0.77378094, 0.857375 , 0.77378094, 0.81450625],
[0.81450625, 0. , 0.77378094, 0.77378094],
[0.77378094, 0.81450625, 0. , 0.73509189],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0. , 0.81450625],
[0. , 0. , 0. , 0. ],
[0.81450625, 0. , 0.857375 , 0.77378094],
[0.81450625, 0.9025 , 0.9025 , 0. ],
[0.857375 , 0.95 , 0. , 0.857375 ],
[0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0.95 , 0.857375 ],
[0.9025 , 0.95 , 1. , 0.9025 ],
[0. , 0. , 0. , 0. ]])L'agent d'évaluation s'exécute pendant n_eval_episodes épisodes et renvoie la moyenne et l'écart type de la récompense.
def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
episode_rewards = []
for episode in range(n_eval_episodes):
if seed:
state = env.reset(seed=seed[episode])
else:
state = env.reset()
step = 0
done = False
total_rewards_ep = 0
for step in range(max_steps):
# Take the action (index) that have the maximum reward
action = np.argmax(Q[state][:])
new_state, reward, done, info = env.step(action)
total_rewards_ep += reward
if done:
break
state = new_state
episode_rewards.append(total_rewards_ep)
mean_reward = np.mean(episode_rewards)
std_reward = np.std(episode_rewards)
return mean_reward, std_rewardComme vous pouvez le constater, nous avons obtenu le score parfait avec un écart-type nul. Cela signifie que notre agent a atteint l'objectif dans les 100 épisodes.
# Evaluate our Agent
mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")Mean_reward=1.00 +/- 0.00Jusqu'à présent, nous avons joué avec des chiffres, et pour faire la démonstration, nous devons créer un Gif animé de l'agent du début jusqu'à ce qu'il atteigne l'objectif.
img au tableau images. def record_video(env, Qtable, out_directory, fps=1):
images = []
done = False
state = env.reset(seed=random.randint(0,500))
img = env.render(mode='rgb_array')
images.append(img)
while not done:
# Take the action (index) that have the maximum expected future reward given that state
action = np.argmax(Qtable[state][:])
state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
img = env.render(mode='rgb_array')
images.append(img)
imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)Si vous êtes dans un carnet Jupyter, vous pouvez afficher le Gif à l'aide de la fonction IPython.display Image.
video_path="/content/replay.gif"
video_fps=1
record_video(env, Qtable_frozenlake, video_path, video_fps)
from IPython.display import Image
Image('./replay.gif')Vous pouvez maintenant partager ces résultats avec vos collègues et camarades de classe ou les publier sur les médias sociaux.
Cours sur l'apprentissage automatique
Cours
Tutoriel
Satyabrata Pal
Tutoriel
Sejal Jaiswal
Tutoriel
DataCamp Team
Tutoriel
Mark Pedigo
Tutoriel
Aditya Sharma
Tutoriel
Sejal Jaiswal