Courses
Thiết kế quy trình Machine Learning bằng Python
4 giờ
12.6K
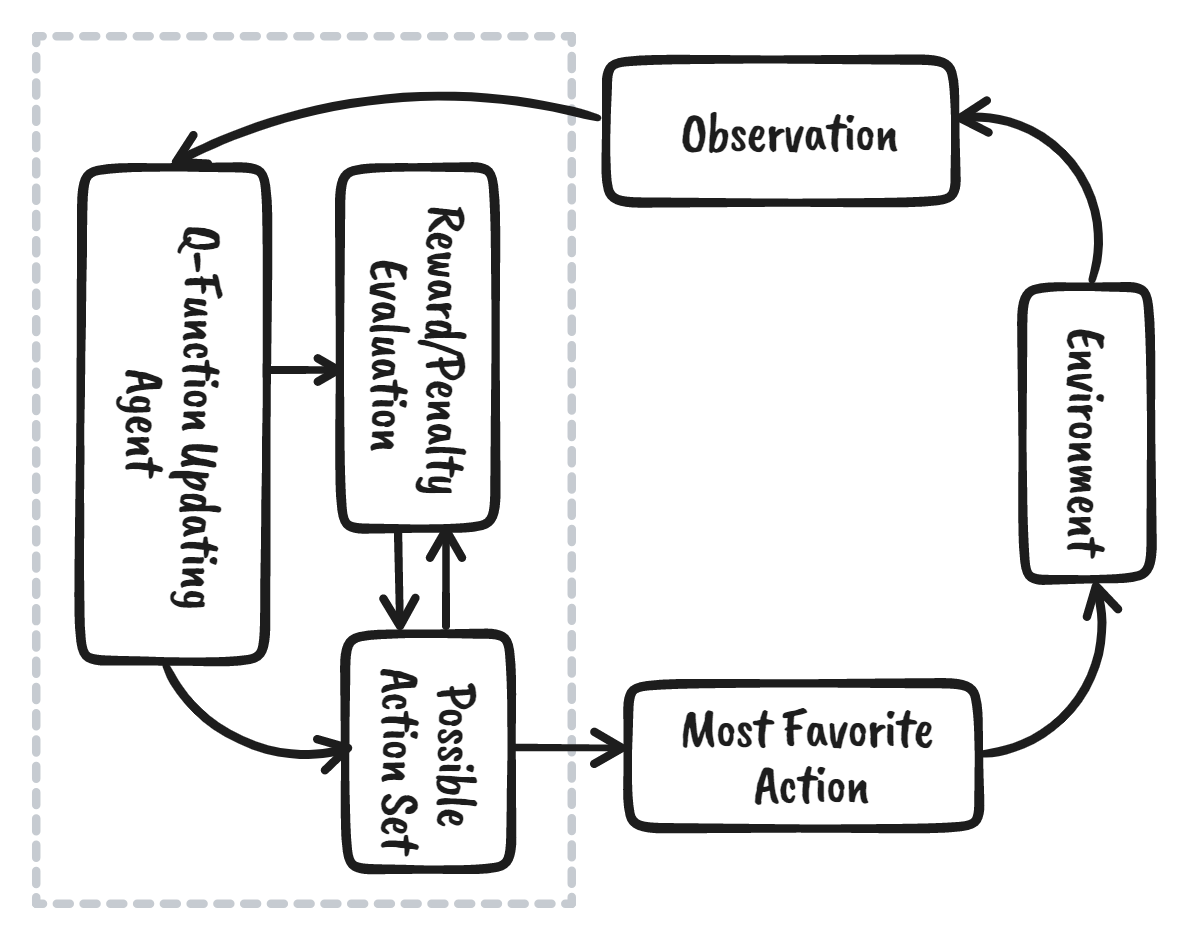
Học tăng cường (RL) là một phần của hệ sinh thái học máy, trong đó tác tử học bằng cách tương tác với môi trường để tìm ra chiến lược tối ưu nhằm đạt được mục tiêu. Nó khá khác với các thuật toán học có giám sát, nơi chúng ta cần nạp và xử lý dữ liệu. Học tăng cường không yêu cầu dữ liệu sẵn có. Thay vào đó, nó học từ môi trường và hệ thống phần thưởng để đưa ra quyết định tốt hơn.
Ví dụ, trong trò chơi Mario, nếu nhân vật thực hiện một hành động ngẫu nhiên (ví dụ: đi sang trái), dựa trên hành động đó, nhân vật có thể nhận được một phần thưởng. Sau khi thực hiện hành động, tác tử (Mario) ở một trạng thái mới và quy trình lặp lại cho đến khi nhân vật trò chơi đến cuối màn hoặc chết.
Tập này sẽ lặp lại nhiều lần cho đến khi Mario học cách điều hướng môi trường bằng cách tối đa hóa phần thưởng.

Hình ảnh của Tác giả
Chúng ta có thể chia học tăng cường thành năm bước đơn giản:
Tìm hiểu thêm bằng cách đọc hướng dẫn Giới thiệu về Học tăng cường. Bạn sẽ khám phá sâu hơn cách học tăng cường hoạt động với các ví dụ mã.
Trong hướng dẫn này, chúng ta sẽ tìm hiểu về Q-learning và lý do tại sao cần Deep Q-learning. Ngoài ra, chúng ta sẽ học cách tạo và huấn luyện thuật toán Q-learning từ đầu bằng Numpy và Gymnasium.
Lưu ý: Nếu bạn mới bắt đầu với học máy, chúng tôi khuyến nghị bạn theo học lộ trình nghề nghiệp Nhà khoa học Máy học với Python để hiểu rõ hơn về Học tăng cường và Q-Learning.
Q-learning là một thuật toán không mô hình, dựa trên giá trị, off-policy, giúp tìm chuỗi hành động tốt nhất dựa trên trạng thái hiện tại của tác tử. Chữ “Q” là viết tắt của quality (chất lượng). Quality biểu thị mức độ hữu ích của một hành động trong việc tối đa hóa phần thưởng tương lai.
Các thuật toán có mô hình sử dụng hàm chuyển trạng thái và hàm phần thưởng để ước tính chính sách tối ưu và tạo mô hình. Ngược lại, các thuật toán không mô hình học hậu quả của hành động thông qua trải nghiệm, không cần hàm chuyển trạng thái và hàm phần thưởng.
Phương pháp dựa trên giá trị huấn luyện hàm giá trị để học xem trạng thái nào giá trị hơn và đưa ra hành động. Ngược lại, phương pháp dựa trên chính sách huấn luyện trực tiếp chính sách để học xem nên thực hiện hành động nào tại một trạng thái nhất định.
Trong off-policy, thuật toán đánh giá và cập nhật một chính sách khác với chính sách được dùng để thực hiện hành động. Ngược lại, thuật toán on-policy đánh giá và cải thiện chính sách giống với chính sách dùng để hành động.
Trước khi đi vào cách Q-learning hoạt động, chúng ta cần học một vài thuật ngữ hữu ích để hiểu các nền tảng của Q-learning.
Chúng ta sẽ tìm hiểu chi tiết cách Q-learning hoạt động bằng ví dụ hồ băng. Trong môi trường này, tác tử phải băng qua hồ băng từ điểm bắt đầu đến mục tiêu mà không rơi vào hố. Chiến lược tốt nhất là đến mục tiêu bằng con đường ngắn nhất.

Gif của Tác giả
Tác tử sẽ dùng Q-table để chọn hành động tốt nhất có thể dựa trên phần thưởng kỳ vọng cho mỗi trạng thái trong môi trường. Nói đơn giản, Q-table là cấu trúc dữ liệu gồm các tập hành động và trạng thái, và chúng ta dùng thuật toán Q-learning để cập nhật các giá trị trong bảng.
Hàm Q sử dụng phương trình Bellman và nhận đầu vào là trạng thái (s) và hành động (a). Phương trình giúp đơn giản hóa việc tính giá trị trạng thái và giá trị trạng thái–hành động. 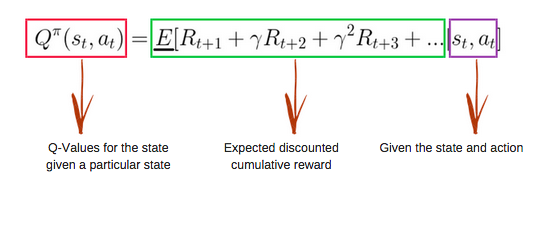
Hình ảnh từ freecodecamp.org
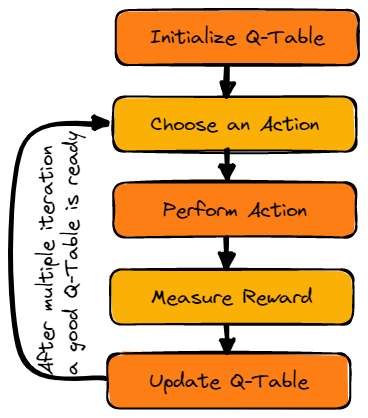
Hình ảnh của Tác giả
Đầu tiên, chúng ta sẽ khởi tạo Q-table. Bảng sẽ có số cột bằng số hành động và số hàng bằng số trạng thái.
Trong ví dụ của chúng ta, nhân vật có thể di chuyển lên, xuống, trái và phải. Chúng ta có bốn hành động có thể và bốn trạng thái (bắt đầu, chờ, sai đường và kết thúc). Bạn cũng có thể coi sai đường là rơi vào hố. Chúng ta sẽ khởi tạo Q-Table với các giá trị bằng 0.
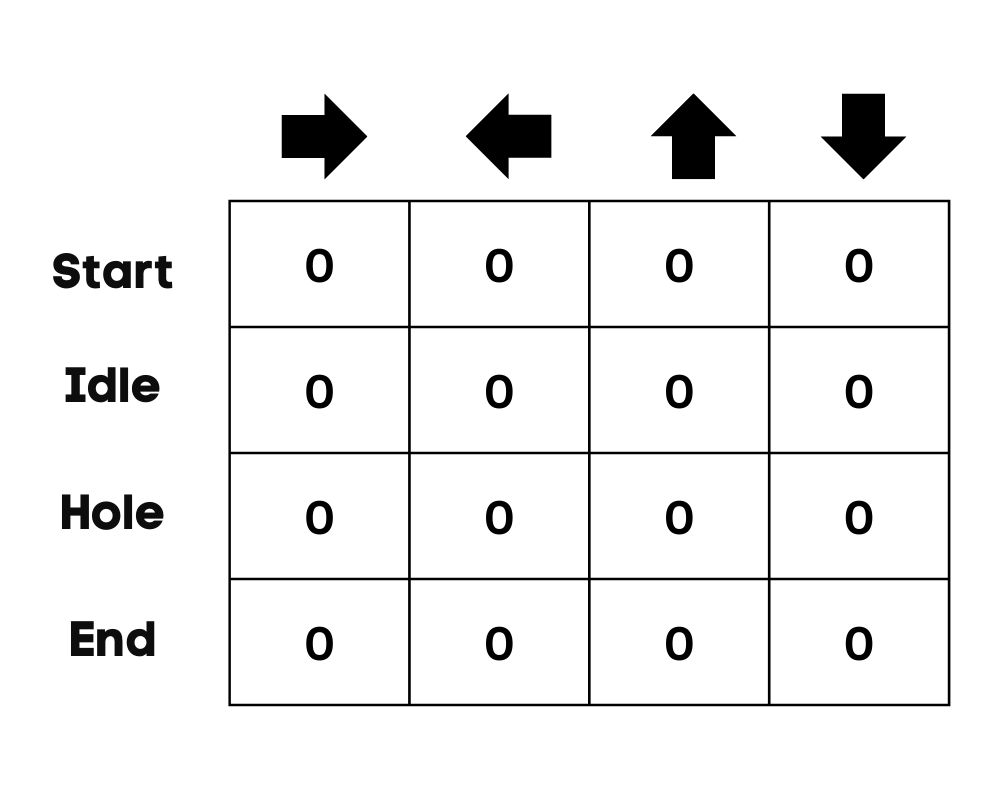
Hình ảnh của Tác giả
Bước thứ hai khá đơn giản. Lúc bắt đầu, tác tử sẽ chọn hành động ngẫu nhiên (xuống hoặc phải), và ở lần chạy thứ hai, nó sẽ dùng Q-Table đã cập nhật để chọn hành động.
Việc chọn và thực hiện hành động sẽ lặp lại nhiều lần cho đến khi vòng huấn luyện dừng. Hành động và trạng thái đầu tiên được chọn bằng Q-Table. Trong trường hợp của chúng ta, tất cả giá trị trong Q-Table đều bằng không.
Sau đó, tác tử sẽ đi xuống và cập nhật Q-Table bằng phương trình Bellman. Với mỗi bước đi, chúng ta sẽ cập nhật các giá trị trong Q-Table và cũng dùng chúng để xác định hướng hành động tốt nhất.
Ban đầu, tác tử ở chế độ khám phá và chọn hành động ngẫu nhiên để khám phá môi trường. Chiến lược Epsilon Greedy là một phương pháp đơn giản để cân bằng giữa khám phá và khai thác. Epsilon là xác suất chọn khám phá và sẽ chuyển sang khai thác khi cơ hội khám phá giảm dần.
Lúc bắt đầu, tỷ lệ epsilon cao, nghĩa là tác tử đang ở chế độ khám phá. Khi khám phá môi trường, epsilon giảm dần và tác tử bắt đầu khai thác môi trường. Trong quá trình khám phá, qua mỗi vòng lặp, tác tử trở nên tự tin hơn trong việc ước lượng các giá trị Q
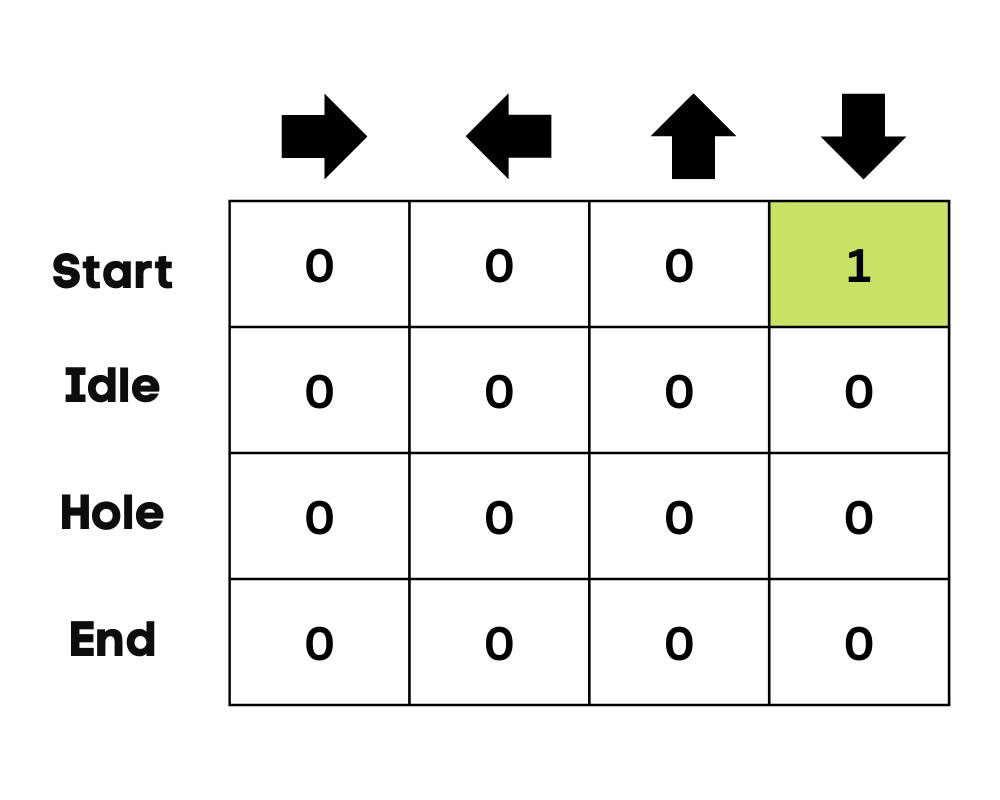
Hình ảnh của Tác giả
Trong ví dụ hồ băng, tác tử chưa biết gì về môi trường nên nó thực hiện hành động ngẫu nhiên (đi xuống) để bắt đầu. Như ta thấy ở hình trên, Q-Table được cập nhật bằng phương trình Bellman.
Sau khi thực hiện hành động, chúng ta sẽ đo lường kết quả và phần thưởng.
Chúng ta sẽ cập nhật hàm Q(St, At) bằng công thức. Công thức sử dụng các giá trị Q ước lượng từ tập trước, tốc độ học và sai số Temporal Differences. Sai số Temporal Differences được tính từ phần thưởng tức thời, phần thưởng tương lai kỳ vọng tối đa đã chiết khấu và giá trị Q ước lượng trước đó.
Quy trình được lặp lại nhiều lần cho đến khi Q-Table được cập nhật và hàm giá trị Q được tối đa hóa.
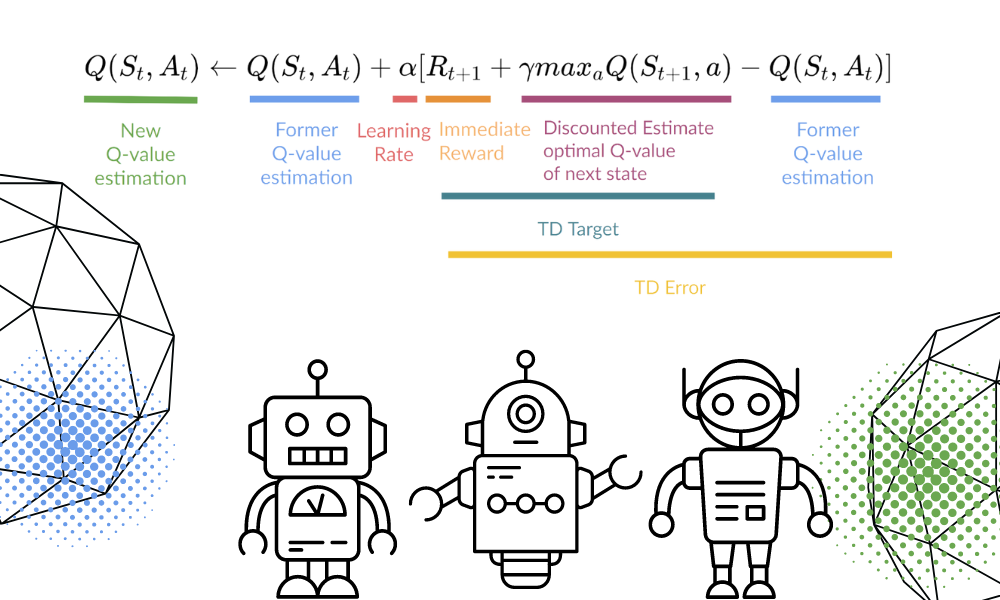
Hình ảnh của Tác giả | Minh họa phương trình từ Thomas Simonini
Ban đầu, tác tử đang khám phá môi trường để cập nhật Q-Table. Và khi Q-Table đã sẵn sàng, tác tử sẽ bắt đầu khai thác và đưa ra quyết định tốt hơn. 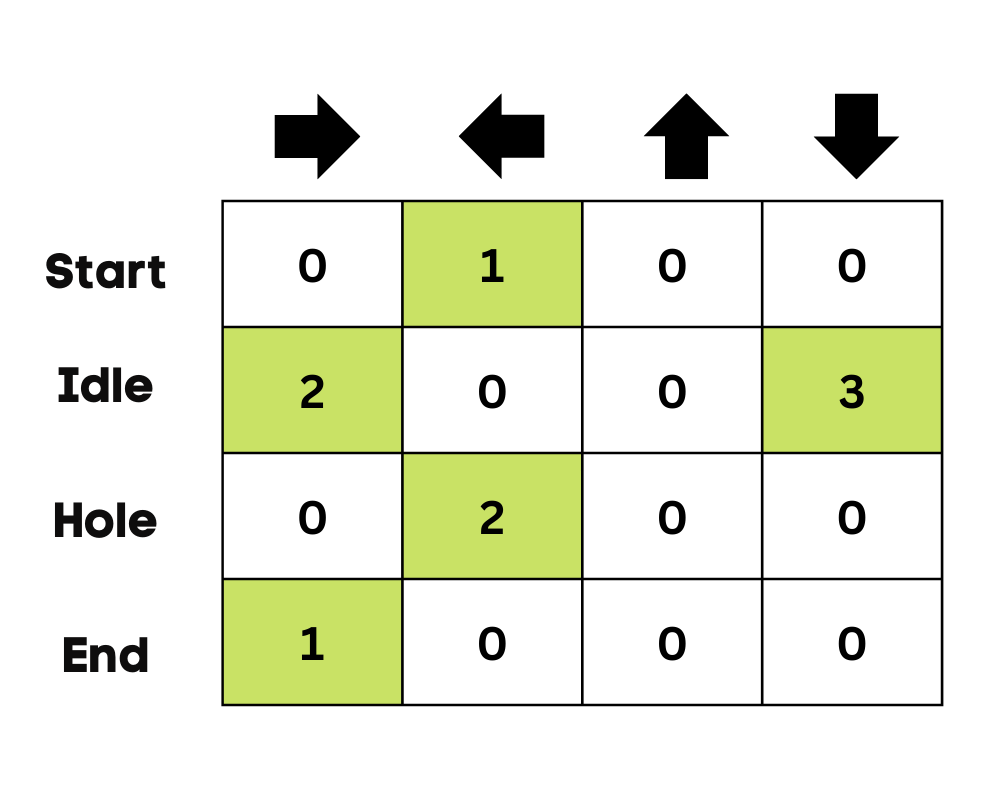
Hình ảnh của Tác giả
Trong trường hợp hồ băng, tác tử sẽ học cách đi đường ngắn nhất để đến mục tiêu và tránh nhảy vào hố.
Trong phần này, chúng ta sẽ xây dựng mô hình Q-learning từ đầu bằng môi trường Gymnasium, Pygame và Numpy. Hướng dẫn Python này là phiên bản điều chỉnh từ Notebook của Thomas Simonini. Nội dung bao gồm khởi tạo môi trường và Q-Table, định nghĩa chính sách greedy, thiết lập siêu tham số, tạo và chạy vòng huấn luyện và đánh giá, cũng như trực quan hóa kết quả.
Nếu bạn gặp vấn đề khi tạo và chạy vòng huấn luyện, bạn có thể xem mã nguồn kèm đầu ra.
Trước tiên, chúng ta sẽ cài đặt tất cả phụ thuộc để tạo video phát lại (Gif). Chúng ta sẽ cần một màn hình ảo (pyvirtualdisplay) để render môi trường và ghi khung hình.
Lưu ý: bằng cách dùng %%capture chúng ta ẩn đầu ra của ô Jupyter.
%%capture
!pip install pyglet==1.5.1
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip3 install pyvirtualdisplay
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()Bây giờ chúng ta sẽ cài đặt các phụ thuộc hỗ trợ tạo, chạy và đánh giá vòng huấn luyện.
%%capture
!pip install gymnasium
!pip install pygame
!pip install numpy
!pip install imageio imageio_ffmpegBây giờ chúng ta sẽ import các thư viện cần thiết.
import numpy as np
import gymnasium as gym
import random
import imageio
from tqdm.notebook import trangeChúng ta sẽ tạo một môi trường 4x4 không trơn trượt bằng thư viện Frozen Lake của gymnasium.
is_slippery=True, tác tử có thể không di chuyển đúng hướng dự định do bề mặt hồ băng trơn. Sau khi khởi tạo môi trường, chúng ta sẽ phân tích môi trường.
env = gym.make("FrozenLake-v1",map_name="4x4",is_slippery=False)
print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # display a random observationCó 16 không gian trạng thái duy nhất trong môi trường được hiển thị tại các vị trí ngẫu nhiên.
Observation Space Discrete(16)
Sample observation 15Hãy khám phá số lượng hành động và hiển thị một hành động ngẫu nhiên.
Không gian hành động:
Hàm phần thưởng:
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample())Action Space Shape 4
Action Space Sample 1Q-Table có các cột là hành động và các hàng là trạng thái. Chúng ta có thể dùng Gymnasium để tìm không gian hành động và không gian trạng thái. Sau đó dùng thông tin này để tạo Q-Table.
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
action_space = env.action_space.n
print("There are ", action_space, " possible actions")There are 16 possible states
There are 4 possible actionsĐể khởi tạo Q-Table, chúng ta sẽ tạo một mảng Numpy có kích thước state_space và action_space. Chúng ta sẽ tạo mảng 16 x 4.
def initialize_q_table(state_space, action_space):
Qtable = np.zeros((state_space, action_space))
return Qtable
Qtable_frozenlake = initialize_q_table(state_space, action_space)Ở phần trước, chúng ta đã tìm hiểu về chiến lược epsilon greedy để xử lý đánh đổi giữa khám phá và khai thác. Với xác suất 1 - ɛ, chúng ta khai thác; với xác suất ɛ, chúng ta khám phá.
Trong hàm epsilon_greedy_policy, chúng ta sẽ:
def epsilon_greedy_policy(Qtable, state, epsilon):
random_int = random.uniform(0,1)
if random_int > epsilon:
action = np.argmax(Qtable[state])
else:
action = env.action_space.sample()
return actionNhư chúng ta đã biết, Q-learning là thuật toán off-policy, nghĩa là chính sách dùng để hành động và chính sách dùng để cập nhật là khác nhau.
Trong ví dụ này, chính sách Epsilon Greedy là chính sách hành động, còn chính sách Greedy là chính sách cập nhật.
Chính sách Greedy cũng sẽ là chính sách cuối cùng khi tác tử đã được huấn luyện. Nó được dùng để chọn giá trị trạng thái và hành động cao nhất từ Q-Table.
def greedy_policy(Qtable, state):
action = np.argmax(Qtable[state])
return actionCác siêu tham số này được dùng trong vòng huấn luyện, và tinh chỉnh chúng sẽ cho kết quả tốt hơn.
Tác tử cần khám phá đủ không gian trạng thái để học xấp xỉ giá trị tốt; chúng ta cần giảm epsilon dần dần. Nếu tốc độ suy giảm quá cao, tác tử có thể bị kẹt do chưa khám phá đủ không gian trạng thái.
# Training parameters
n_training_episodes = 10000
learning_rate = 0.7
# Evaluation parameters
n_eval_episodes = 100
# Environment parameters
env_id = "FrozenLake-v1"
max_steps = 99
gamma = 0.95
eval_seed = []
# Exploration parameters
max_epsilon = 1.0
min_epsilon = 0.05
decay_rate = 0.0005 Trong vòng huấn luyện, chúng ta sẽ:
done= True, kết thúc tập và thoát vòng lặp.def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in trange(n_training_episodes):
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
state = env.reset()
step = 0
done = False
# repeat
for step in range(max_steps):
action = epsilon_greedy_policy(Qtable, state, epsilon)
new_state, reward, done, info = env.step(action)
Qtable[state][action] = Qtable[state][action] + learning_rate * (reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action])
# If done, finish the episode
if done:
break
# Our state is the new state
state = new_state
return QtableChúng ta mất 3 giây để hoàn thành 10.000 tập huấn luyện.
Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
Như có thể thấy, Q-Table đã được huấn luyện có các giá trị, và tác tử giờ sẽ dùng các giá trị này để điều hướng môi trường và đạt mục tiêu.
Qtable_frozenlakearray([[0.73509189, 0.77378094, 0.77378094, 0.73509189],
[0.73509189, 0. , 0.81450625, 0.77378094],
[0.77378094, 0.857375 , 0.77378094, 0.81450625],
[0.81450625, 0. , 0.77378094, 0.77378094],
[0.77378094, 0.81450625, 0. , 0.73509189],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0. , 0.81450625],
[0. , 0. , 0. , 0. ],
[0.81450625, 0. , 0.857375 , 0.77378094],
[0.81450625, 0.9025 , 0.9025 , 0. ],
[0.857375 , 0.95 , 0. , 0.857375 ],
[0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0.95 , 0.857375 ],
[0.9025 , 0.95 , 1. , 0.9025 ],
[0. , 0. , 0. , 0. ]])Hàm evaluate_agent chạy trong n_eval_episodes tập và trả về giá trị trung bình cùng độ lệch chuẩn của phần thưởng.
def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
episode_rewards = []
for episode in range(n_eval_episodes):
if seed:
state = env.reset(seed=seed[episode])
else:
state = env.reset()
step = 0
done = False
total_rewards_ep = 0
for step in range(max_steps):
# Take the action (index) that have the maximum reward
action = np.argmax(Q[state][:])
new_state, reward, done, info = env.step(action)
total_rewards_ep += reward
if done:
break
state = new_state
episode_rewards.append(total_rewards_ep)
mean_reward = np.mean(episode_rewards)
std_reward = np.std(episode_rewards)
return mean_reward, std_rewardNhư bạn thấy, chúng ta đạt điểm hoàn hảo với độ lệch chuẩn bằng không. Điều đó có nghĩa tác tử của chúng ta đã đạt mục tiêu trong cả 100 tập.
# Evaluate our Agent
mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")Mean_reward=1.00 +/- 0.00Đến giờ, chúng ta mới làm việc với các con số; để minh họa, chúng ta cần tạo một ảnh Gif động của tác tử từ lúc bắt đầu đến khi nó đạt mục tiêu.
img vào mảng images. def record_video(env, Qtable, out_directory, fps=1):
images = []
done = False
state = env.reset(seed=random.randint(0,500))
img = env.render(mode='rgb_array')
images.append(img)
while not done:
# Take the action (index) that have the maximum expected future reward given that state
action = np.argmax(Qtable[state][:])
state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
img = env.render(mode='rgb_array')
images.append(img)
imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)Nếu bạn ở trong Jupyter notebook, bạn có thể hiển thị Gif bằng hàm Image của IPython.display.
video_path="/content/replay.gif"
video_fps=1
record_video(env, Qtable_frozenlake, video_path, video_fps)
from IPython.display import Image
Image('./replay.gif')Bây giờ bạn có thể chia sẻ các kết quả này với đồng nghiệp, bạn học hoặc đăng lên mạng xã hội.
Khóa học Máy học
blogs
Matt Crabtree
10 phút