Kurs
Machine-Learning-Workflows in Python entwerfen
4 Std.
12.6K
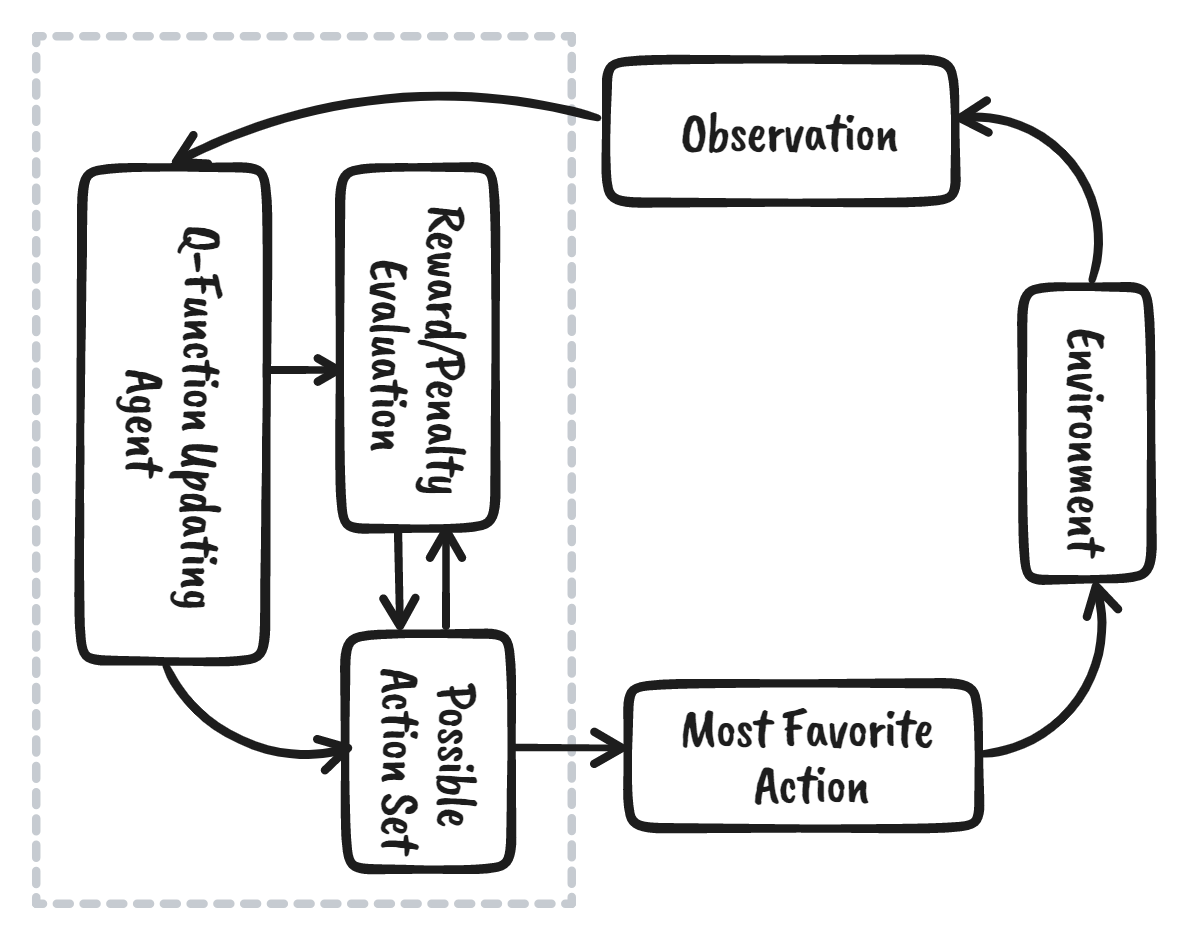
Verstärkungslernen (Reinforcement Learning, RL) ist der Teil des maschinellen Lernens, bei dem der Agent durch Interaktion mit der Umgebung lernt, um die optimale Strategie zum Erreichen der Ziele zu finden. Das ist etwas ganz anderes als überwachte maschinelle Lernalgorithmen, bei denen wir die Daten aufnehmen und verarbeiten müssen. Für das Reinforcement Learning werden keine Daten benötigt. Stattdessen lernt es aus der Umgebung und dem Belohnungssystem, um bessere Entscheidungen zu treffen.
Wenn eine Figur im Mario-Videospiel zum Beispiel eine zufällige Aktion ausführt (z. B. nach links gehen), kann sie dafür eine Belohnung erhalten. Nachdem er die Aktion ausgeführt hat, befindet sich der Agent (Mario) in einem neuen Zustand und der Vorgang wiederholt sich, bis die Spielfigur das Ende der Etappe erreicht oder stirbt.
Diese Episode wird sich mehrmals wiederholen, bis Mario lernt, sich in der Umgebung zurechtzufinden und die Belohnungen zu maximieren.

Bild vom Autor
Wir können das Verstärkungslernen in fünf einfache Schritte unterteilen:
Mehr dazu erfährst du in unserem Tutorial, einer Einführung in das Reinforcement Learning. Anhand von Codebeispielen erfährst du mehr darüber, wie Reinforcement Learning funktioniert.
In diesem Lernprogramm lernen wir Q-Learning kennen und verstehen, warum wir Deep Q-Learning brauchen. Außerdem werden wir lernen, Q-Learning-Algorithmen mit Numpy und OpenAI Gym von Grund auf zu erstellen und zu trainieren.
Hinweis: Wenn du neu im Bereich des maschinellen Lernens bist, empfehlen wir dir unseren Lernpfad "Machine Learning Scientist with Python ", um Reinforcement Learning und Q-Learning besser zu verstehen.
Q-Learning ist ein modellfreier, wertbasierter Algorithmus, der die beste Reihe von Aktionen auf der Grundlage des aktuellen Zustands des Agenten findet. Das "Q" steht für Qualität. Die Qualität gibt an, wie wertvoll die Aktion für die Maximierung zukünftiger Belohnungen ist.
Die modellbasierten Algorithmen verwenden Übergangs- und Belohnungsfunktionen, um die optimale Politik zu schätzen und das Modell zu erstellen. Im Gegensatz dazu lernen modellfreie Algorithmen die Konsequenzen ihrer Handlungen durch die Erfahrung ohne Übergangs- und Belohnungsfunktion.
Die wertbasierte Methode trainiert die Wertfunktion, um zu lernen, welcher Zustand wertvoller ist und Maßnahmen zu ergreifen. Bei richtlinienbasierten Methoden hingegen wird die Richtlinie direkt trainiert, um zu lernen, welche Maßnahme in einem bestimmten Zustand zu ergreifen ist.
In der Off-Policy bewertet und aktualisiert der Algorithmus eine Policy, die sich von der Policy unterscheidet, die für die Durchführung einer Aktion verwendet wurde. Umgekehrt bewertet und verbessert der On-Policy-Algorithmus dieselbe Richtlinie, die zur Durchführung einer Aktion verwendet wurde.
Bevor wir uns mit der Funktionsweise von Q-Learning beschäftigen, müssen wir ein paar nützliche Begriffe lernen, um die Grundlagen des Q-Learnings zu verstehen.
Wir werden am Beispiel eines zugefrorenen Sees im Detail lernen, wie Q-Learning funktioniert. In dieser Umgebung muss der Agent den zugefrorenen See vom Start zum Ziel überqueren, ohne in die Löcher zu fallen. Die beste Strategie ist, die Ziele auf dem kürzesten Weg zu erreichen.

Gif nach Autor
Der Agent verwendet eine Q-Tabelle, um die bestmögliche Aktion auf der Grundlage der erwarteten Belohnung für jeden Zustand in der Umgebung zu wählen. Einfach ausgedrückt, ist eine Q-Tabelle eine Datenstruktur mit Mengen von Aktionen und Zuständen, und wir verwenden den Q-Lernalgorithmus, um die Werte in der Tabelle zu aktualisieren.
Die Q-Funktion verwendet die Bellman-Gleichung und nimmt Zustand(e) und Aktion(a) als Eingabe. Die Gleichung vereinfacht die Berechnung der Zustandswerte und der Zustands-Aktionswerte. 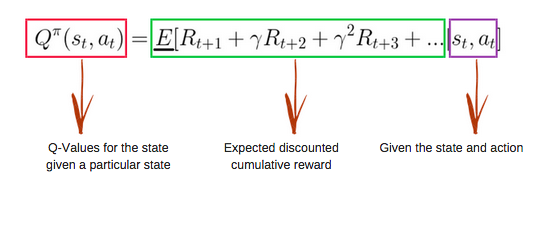
Bild von freecodecamp.org
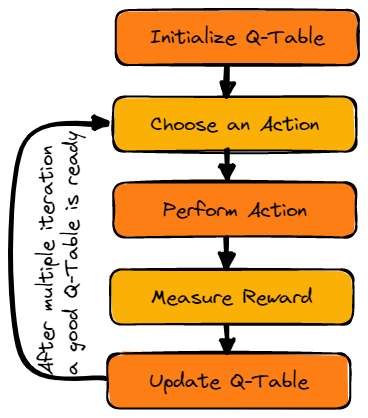
Bild vom Autor
Wir werden zunächst die Q-Tabelle initialisieren. Wir werden die Tabelle mit Spalten nach der Anzahl der Aktionen und Zeilen nach der Anzahl der Zustände aufbauen.
In unserem Beispiel kann sich die Figur nach oben, unten, links und rechts bewegen. Wir haben vier mögliche Aktionen und vier Zustände (Start, Leerlauf, falscher Weg und Ende). Du kannst auch den falschen Weg in Betracht ziehen, um in das Loch zu fallen. Wir initialisieren die Q-Tabelle mit Werten bei 0.
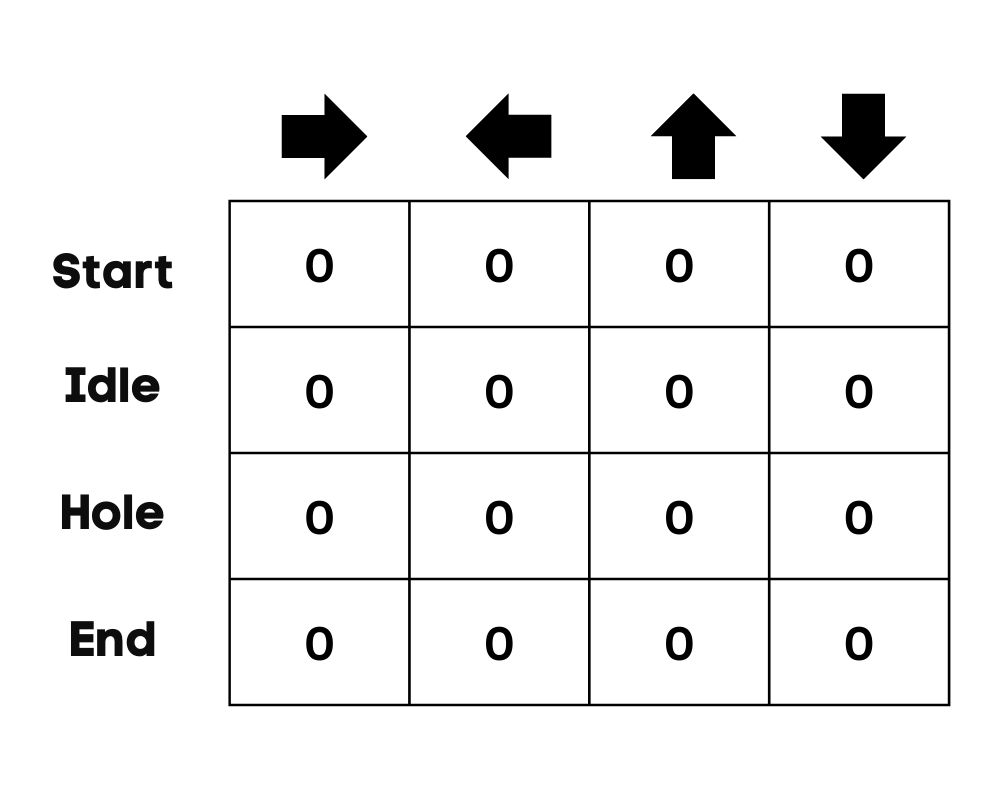
Bild vom Autor
Der zweite Schritt ist ganz einfach. Zu Beginn entscheidet sich der Agent für eine zufällige Aktion (nach unten oder rechts), und beim zweiten Durchlauf verwendet er eine aktualisierte Q-Tabelle, um die Aktion auszuwählen.
Wenn du eine Aktion auswählst und durchführst, wird diese mehrmals wiederholt, bis die Trainingsschleife endet. Die erste Aktion und der erste Zustand werden über die Q-Tabelle ausgewählt. In unserem Fall sind alle Werte der Q-Tabelle Null.
Dann geht der Agent nach unten und aktualisiert die Q-Tabelle mithilfe der Bellman-Gleichung. Mit jedem Zug aktualisieren wir die Werte in der Q-Tabelle und nutzen sie auch, um die beste Vorgehensweise zu bestimmen.
Zu Beginn befindet sich der Agent im Erkundungsmodus und wählt eine zufällige Aktion, um die Umgebung zu erkunden. Die Epsilon Greedy Strategy ist eine einfache Methode, um ein Gleichgewicht zwischen Erkundung und Ausbeutung herzustellen. Das Epsilon steht für die Wahrscheinlichkeit, sich für eine Erkundung zu entscheiden, wenn die Chancen auf eine Erkundung geringer sind.
Zu Beginn ist die Epsilon-Rate höher, was bedeutet, dass sich der Agent im Erkundungsmodus befindet. Während der Erkundung der Umgebung sinkt das Epsilon und die Agenten beginnen, die Umgebung zu nutzen. Während der Erkundung wird der Agent mit jeder Iteration sicherer in der Einschätzung der Q-Werte
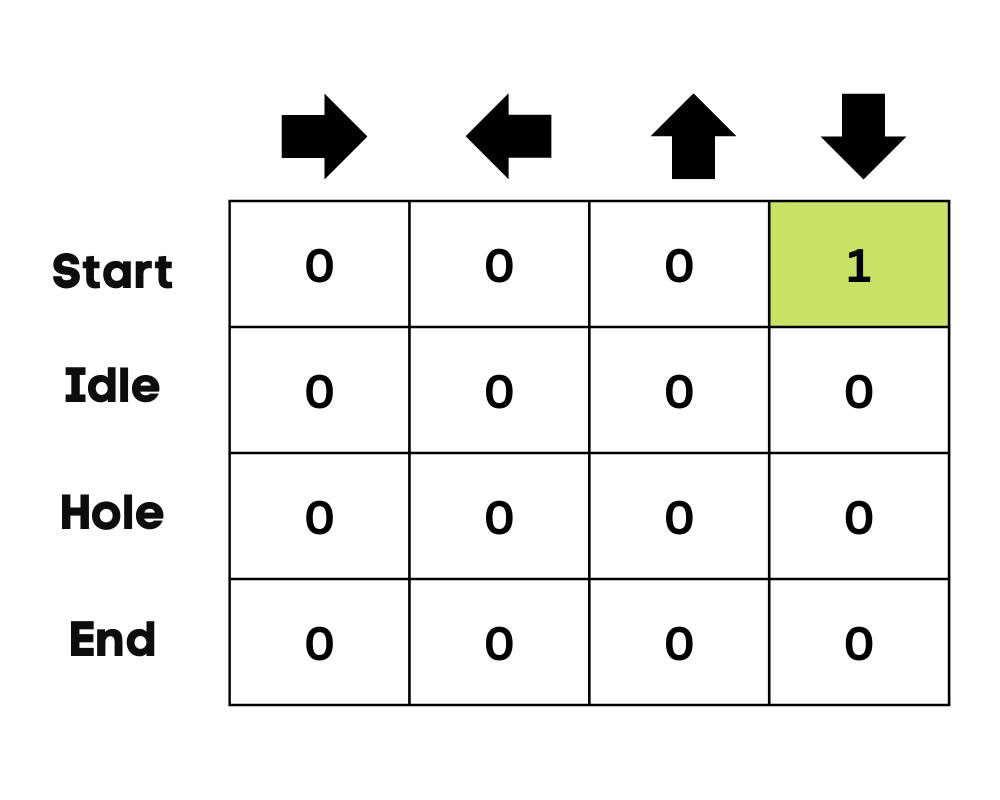
Bild vom Autor
Im Beispiel des zugefrorenen Sees kennt der Agent die Umgebung nicht, also führt er eine zufällige Aktion aus (nach unten gehen), um zu starten. Wie wir in der obigen Abbildung sehen können, wird die Q-Tabelle mithilfe der Bellman-Gleichung aktualisiert.
Nachdem wir die Aktion durchgeführt haben, messen wir das Ergebnis und die Belohnung.
Wir aktualisieren die Funktion Q(St,At) mithilfe der Gleichung. Er verwendet die geschätzten Q-Werte, die Lernrate und den Fehler der zeitlichen Differenzen der vorherigen Episode. Der Fehler bei den zeitlichen Unterschieden wird anhand der sofortigen Belohnung, der abgezinsten maximalen erwarteten zukünftigen Belohnung und dem Q-Wert der früheren Schätzung berechnet.
Der Vorgang wird so oft wiederholt, bis die Q-Tabelle aktualisiert und die Q-Wert-Funktion maximiert ist.
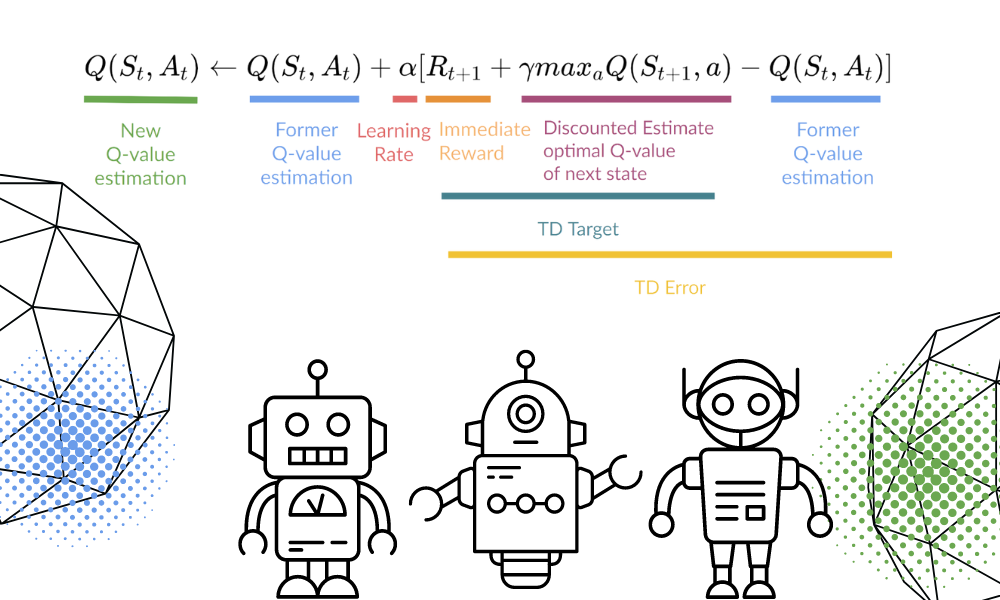
Bild von Autor | Equation Visuals von Thomas Simonini
Zu Beginn erkundet der Agent die Umgebung, um die Q-Tabelle zu aktualisieren. Und wenn die Q-Tabelle fertig ist, wird der Agent anfangen, sie zu nutzen und bessere Entscheidungen zu treffen. 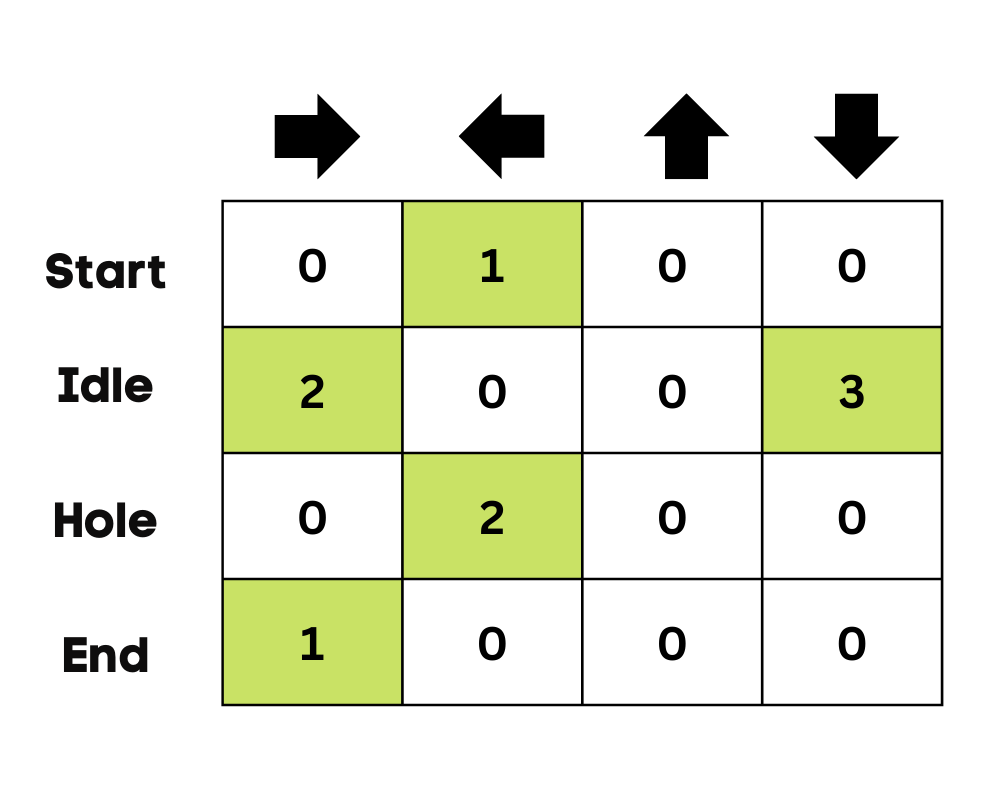
Bild vom Autor
Bei einem zugefrorenen See wird der Agent lernen, den kürzesten Weg zum Ziel zu nehmen und nicht in die Löcher zu springen.
In diesem Abschnitt werden wir unser Q-Learning-Modell mit der Gym-Umgebung, Pygame und Numpy von Grund auf neu aufbauen. Das Python-Tutorial ist eine modifizierte Version des Notebook von Thomas Simonini. Es umfasst die Initialisierung der Umgebung und der Q-Tabelle, die Definition der Gierpolitik, die Festlegung der Hyperparameter, die Erstellung und Ausführung der Trainingsschleife und der Auswertung sowie die Visualisierung der Ergebnisse.
Wenn du Probleme beim Erstellen und Ausführen deiner Trainingsschleife hast, kannst du den Quellcode mit der Ausgabe überprüfen.
Zuerst werden wir alle Abhängigkeiten installieren, um ein Replay-Video (Gif) zu erstellen. Wir brauchen einen virtuellen Bildschirm (pyvirtualdisplay), um die Umgebung zu rendern und die Bilder aufzuzeichnen.
Hinweis: Durch die Verwendung von %%capture unterdrücken wir die Ausgabe der Jupyter-Zelle.
%%capture
!pip install pyglet==1.5.1
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip3 install pyvirtualdisplay
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()Jetzt werden wir die Abhängigkeiten installieren, die uns helfen, die Trainingsschleife zu erstellen, auszuführen und auszuwerten.
%%capture
!pip install gym==0.24
!pip install pygame
!pip install numpy
!pip install imageio imageio_ffmpegJetzt importieren wir die benötigten Bibliotheken.
import numpy as np
import gym
import random
import imageio
from tqdm.notebook import trangeWir werden eine rutschfeste 4x4-Umgebung mit Hilfe der Frozen Lake Gym-Bibliothek erstellen.
is_slippery=True, kann es sein, dass sich der Agent aufgrund der Glätte des zugefrorenen Sees nicht in die gewünschte Richtung bewegt. Nachdem wir die Umgebung initialisiert haben, führen wir eine Umweltanalyse durch.
env = gym.make("FrozenLake-v1",map_name="4x4",is_slippery=False)
print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # display a random observationIn der Umgebung gibt es 16 einzigartige Räume, die an zufälligen Positionen angezeigt werden.
Observation Space Discrete(16)
Sample observation 15Lass uns die Anzahl der Aktionen herausfinden und die zufällige Aktion anzeigen.
Der Aktionsraum:
Belohnungsfunktion:
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample())Action Space Shape 4
Action Space Sample 1Die Q-Tabelle hat Spalten als Aktionen und Zeilen als Zustände. Wir können OpenAI Gym verwenden, um den Aktionsraum und den Zustandsraum zu finden. Mit diesen Informationen erstellen wir dann die Q-Tabelle.
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
action_space = env.action_space.n
print("There are ", action_space, " possible actions")There are 16 possible states
There are 4 possible actionsUm die Q-Tabelle zu initialisieren, erstellen wir ein Numpy-Array von state_space und actions space. Wir werden ein 16 x 4 Array erstellen.
def initialize_q_table(state_space, action_space):
Qtable = np.zeros((state_space, action_space))
return Qtable
Qtable_frozenlake = initialize_q_table(state_space, action_space)Im vorigen Abschnitt haben wir die Epsilon-Greedy-Strategie kennengelernt, die einen Kompromiss zwischen Erkundung und Ausbeutung ermöglicht. Mit einer Wahrscheinlichkeit von 1 - ɛ betreiben wir Ausbeutung, und mit der Wahrscheinlichkeit ɛ betreiben wir Erkundung.
In der epsilon_greedy_policy werden wir:
def epsilon_greedy_policy(Qtable, state, epsilon):
random_int = random.uniform(0,1)
if random_int > epsilon:
action = np.argmax(Qtable[state])
else:
action = env.action_space.sample()
return actionWie wir jetzt wissen, ist das Q-Lernen ein Off-Policy-Algorithmus, was bedeutet, dass die Handlungspolitik und die Aktualisierungsfunktion unterschiedlich sind.
In diesem Beispiel ist die Epsilon-Greedy-Politik die Handlungspolitik und die Greedy-Politik die Aktualisierungspolitik.
Die Gier-Politik wird auch die endgültige Politik sein, wenn der Agent ausgebildet ist. Er wird verwendet, um den höchsten Status- und Aktionswert aus der Q-Tabelle auszuwählen.
def greedy_policy(Qtable, state):
action = np.argmax(Qtable[state])
return actionDiese Hyperparameter werden in der Trainingsschleife verwendet, und durch eine Feinabstimmung kannst du bessere Ergebnisse erzielen.
Der Agent muss genügend Zustandsraum erkunden, um eine gute Wertannäherung zu erlernen; wir brauchen einen progressiven Verfall von Epsilon. Wenn die Abklingrate hoch ist, könnte der Agent stecken bleiben, weil er nicht genug Zustandsraum erkundet hat.
# Training parameters
n_training_episodes = 10000
learning_rate = 0.7
# Evaluation parameters
n_eval_episodes = 100
# Environment parameters
env_id = "FrozenLake-v1"
max_steps = 99
gamma = 0.95
eval_seed = []
# Exploration parameters
max_epsilon = 1.0
min_epsilon = 0.05
decay_rate = 0.0005 In der Trainingsschleife werden wir:
done= True, beende die Episode und unterbreche die Schleife.def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in trange(n_training_episodes):
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
state = env.reset()
step = 0
done = False
# repeat
for step in range(max_steps):
action = epsilon_greedy_policy(Qtable, state, epsilon)
new_state, reward, done, info = env.step(action)
Qtable[state][action] = Qtable[state][action] + learning_rate * (reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action])
# If done, finish the episode
if done:
break
# Our state is the new state
state = new_state
return QtableWir haben 3 Sekunden gebraucht, um 10.000 Trainingsepisoden zu beenden.
Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
Wie wir sehen können, hat die trainierte Q-Tabelle Werte, und der Agent wird diese Werte nun nutzen, um in der Umgebung zu navigieren und das Ziel zu erreichen.
Qtable_frozenlakearray([[0.73509189, 0.77378094, 0.77378094, 0.73509189],
[0.73509189, 0. , 0.81450625, 0.77378094],
[0.77378094, 0.857375 , 0.77378094, 0.81450625],
[0.81450625, 0. , 0.77378094, 0.77378094],
[0.77378094, 0.81450625, 0. , 0.73509189],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0. , 0.81450625],
[0. , 0. , 0. , 0. ],
[0.81450625, 0. , 0.857375 , 0.77378094],
[0.81450625, 0.9025 , 0.9025 , 0. ],
[0.857375 , 0.95 , 0. , 0.857375 ],
[0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0.95 , 0.857375 ],
[0.9025 , 0.95 , 1. , 0.9025 ],
[0. , 0. , 0. , 0. ]])Der evaluate_agent läuft für n_eval_episodes Episoden und gibt den Mittelwert und die Standardabweichung der Belohnung zurück.
def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
episode_rewards = []
for episode in range(n_eval_episodes):
if seed:
state = env.reset(seed=seed[episode])
else:
state = env.reset()
step = 0
done = False
total_rewards_ep = 0
for step in range(max_steps):
# Take the action (index) that have the maximum reward
action = np.argmax(Q[state][:])
new_state, reward, done, info = env.step(action)
total_rewards_ep += reward
if done:
break
state = new_state
episode_rewards.append(total_rewards_ep)
mean_reward = np.mean(episode_rewards)
std_reward = np.std(episode_rewards)
return mean_reward, std_rewardWie du siehst, haben wir das perfekte Ergebnis mit einer Standardabweichung von null. Das bedeutet, dass unser Agent das Ziel in allen 100 Episoden erreicht hat.
# Evaluate our Agent
mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")Mean_reward=1.00 +/- 0.00Bis jetzt haben wir mit Zahlen gespielt, und für die Demo müssen wir ein animiertes Gif des Agenten vom Start bis zum Erreichen des Ziels erstellen.
img an das Array images an. def record_video(env, Qtable, out_directory, fps=1):
images = []
done = False
state = env.reset(seed=random.randint(0,500))
img = env.render(mode='rgb_array')
images.append(img)
while not done:
# Take the action (index) that have the maximum expected future reward given that state
action = np.argmax(Qtable[state][:])
state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
img = env.render(mode='rgb_array')
images.append(img)
imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)Wenn du dich in einem Jupyter-Notebook befindest, kannst du das Gif mit der Funktion IPython.display Bild anzeigen.
video_path="/content/replay.gif"
video_fps=1
record_video(env, Qtable_frozenlake, video_path, video_fps)
from IPython.display import Image
Image('./replay.gif')Du kannst diese Ergebnisse nun mit deinen Kollegen und Klassenkameraden teilen oder sie in den sozialen Medien posten.
Kurse zum maschinellen Lernen
Kurs
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Satyabrata Pal
Tutorial
DataCamp Team
Tutorial
Mark Pedigo
Tutorial
Sejal Jaiswal