Cursus
Machine Learning-workflows ontwerpen in Python
4 Hr
12.6K
Reinforcement learning (RL) is het deel van het machinelearning-ecosysteem waarin de agent leert door met de omgeving te interageren om zo de optimale strategie te vinden om doelen te bereiken. Het verschilt sterk van gesuperviseerde machinelearning-algoritmen, waarbij we data moeten inladen en verwerken. Reinforcement learning heeft geen data nodig. In plaats daarvan leert het via de omgeving en het beloningssysteem om betere beslissingen te nemen.
In de Mario-videogame bijvoorbeeld: als een personage een willekeurige actie uitvoert (bijv. naar links bewegen), kan het op basis van die actie een beloning krijgen. Na het uitvoeren van de actie bevindt de agent (Mario) zich in een nieuwe toestand, en het proces herhaalt zich totdat het gamepersonage het einde van het level bereikt of sterft.
Deze episode zal meerdere keren herhalen totdat Mario leert door de omgeving te navigeren door de beloningen te maximaliseren.

Afbeelding door de auteur
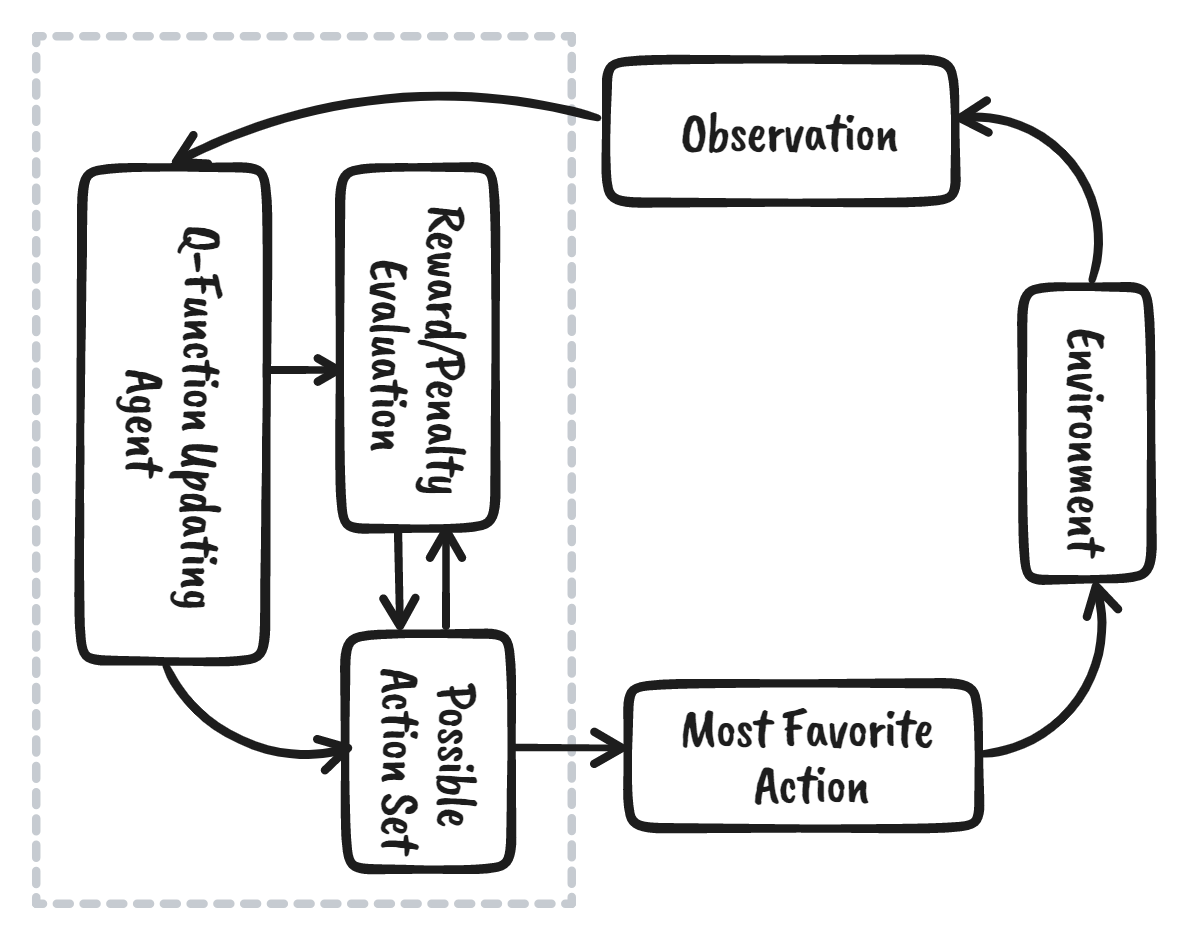
We kunnen reinforcement learning opdelen in vijf eenvoudige stappen:
Leer meer in onze tutorial, een Introductie tot Reinforcement Learning. Je ontdekt meer over hoe reinforcement learning werkt met codevoorbeelden.
In deze tutorial leren we over Q-learning en begrijpen we waarom we Deep Q-learning nodig hebben. Bovendien leren we Q-learning-algoritmen vanaf nul te maken en te trainen met Numpy en Gymnasium.
Let op: Als je nieuw bent met machine learning, raden we je aan om ons Machine Learning Scientist met Python-carrièretraject te volgen om Reinforcement learning en Q-learning beter te begrijpen.
Q-learning is een modelvrij, waardegestuurd, off-policy algoritme dat de beste reeks acties vindt op basis van de huidige toestand van de agent. De “Q” staat voor quality (kwaliteit). Kwaliteit geeft aan hoe waardevol de actie is voor het maximaliseren van toekomstige beloningen.
De modelgebaseerde algoritmen gebruiken transitie- en beloningsfuncties om het optimale beleid te schatten en het model te creëren. Daarentegen leren modelloze algoritmen de consequenties van hun acties via ervaring, zonder transitie- en beloningsfunctie.
De waardegestuurde methode traint de waardefunctie om te leren welke toestand waardevoller is en onderneemt actie. Aan de andere kant trainen beleidsgestuurde methoden het beleid direct om te leren welke actie in een gegeven toestand moet worden genomen.
Bij off-policy evalueert en werkt het algoritme een beleid bij dat verschilt van het beleid dat gebruikt wordt om een actie te nemen. Omgekeerd evalueert en verbetert het on-policy algoritme hetzelfde beleid dat gebruikt wordt om een actie te nemen.
Voordat we ingaan op hoe Q-learning werkt, moeten we een paar nuttige termen leren om de basisprincipes van Q-learning te begrijpen.
We leren in detail hoe Q-learning werkt aan de hand van het voorbeeld van een bevroren meer. In deze omgeving moet de agent het bevroren meer oversteken van start naar doel, zonder in de gaten te vallen. De beste strategie is om het doel te bereiken via het kortste pad.

Gif door de auteur
De agent gebruikt een Q-tabel om de best mogelijke actie te ondernemen op basis van de verwachte beloning voor elke toestand in de omgeving. Simpel gezegd: een Q-tabel is een datastructuur met verzamelingen acties en toestanden, en we gebruiken het Q-learning-algoritme om de waarden in de tabel bij te werken.
De Q-functie gebruikt de vergelijking van Bellman en neemt toestand (s) en actie (a) als invoer. De vergelijking vereenvoudigt de berekening van toestandswaarden en toestand-actie-waarden. 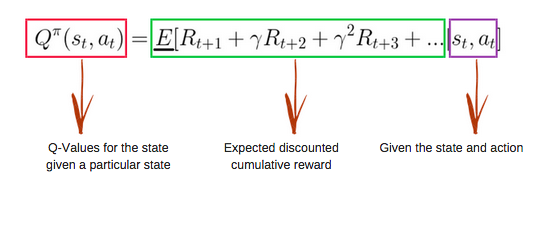
Afbeelding van freecodecamp.org
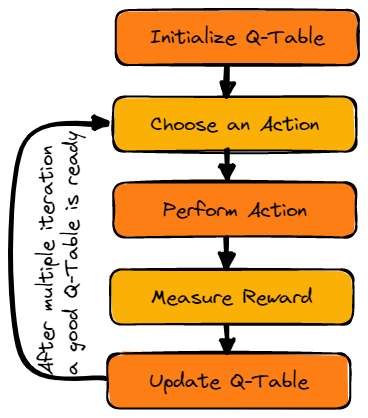
Afbeelding door de auteur
We initialiseren eerst de Q-tabel. We bouwen de tabel met kolommen op basis van het aantal acties en rijen op basis van het aantal toestanden.
In ons voorbeeld kan het personage omhoog, omlaag, links en rechts bewegen. We hebben vier mogelijke acties en vier toestanden (start, idle, verkeerd pad en einde). Je kunt het verkeerde pad ook zien als in een gat vallen. We initialiseren de Q-tabel met waarden op 0.
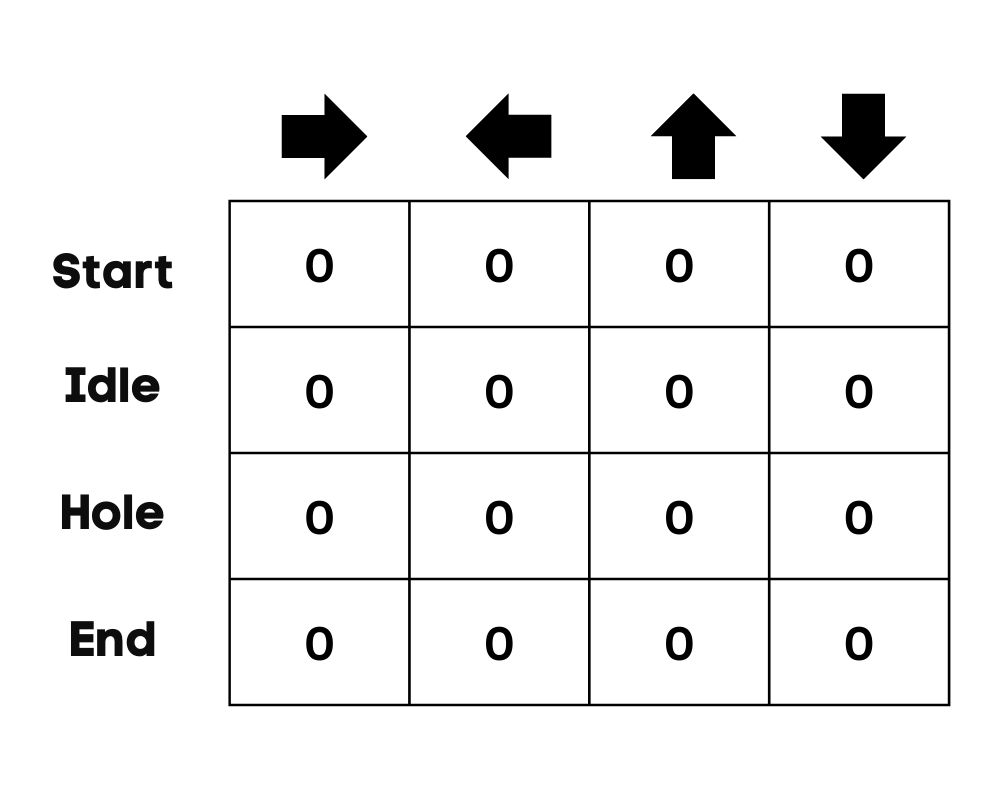
Afbeelding door de auteur
De tweede stap is vrij eenvoudig. In het begin kiest de agent willekeurig een actie (omlaag of rechts), en bij de tweede run gebruikt hij een bijgewerkte Q-tabel om de actie te selecteren.
Een actie kiezen en uitvoeren zal meerdere keren herhalen totdat de trainingslus stopt. De eerste actie en toestand worden geselecteerd met behulp van de Q-tabel. In ons geval zijn alle waarden in de Q-tabel nul.
Daarna beweegt de agent omlaag en werkt de Q-tabel bij met behulp van de vergelijking van Bellman. Bij elke zet werken we waarden in de Q-tabel bij en gebruiken we die ook om de beste handelswijze te bepalen.
In het begin staat de agent in exploratiemodus en kiest hij een willekeurige actie om de omgeving te verkennen. De Epsilon-greedy-strategie is een eenvoudige methode om exploratie en exploitatie in balans te brengen. Epsilon staat voor de kans om te kiezen voor exploratie en voor exploitatie wanneer de kans op exploratie kleiner wordt.
In het begin is de epsilonwaarde hoger, wat betekent dat de agent in exploratiemodus is. Terwijl hij de omgeving verkent, daalt epsilon en beginnen agents de omgeving te exploiteren. Tijdens exploratie wordt de agent met elke iteratie zekerder in het schatten van Q-waarden
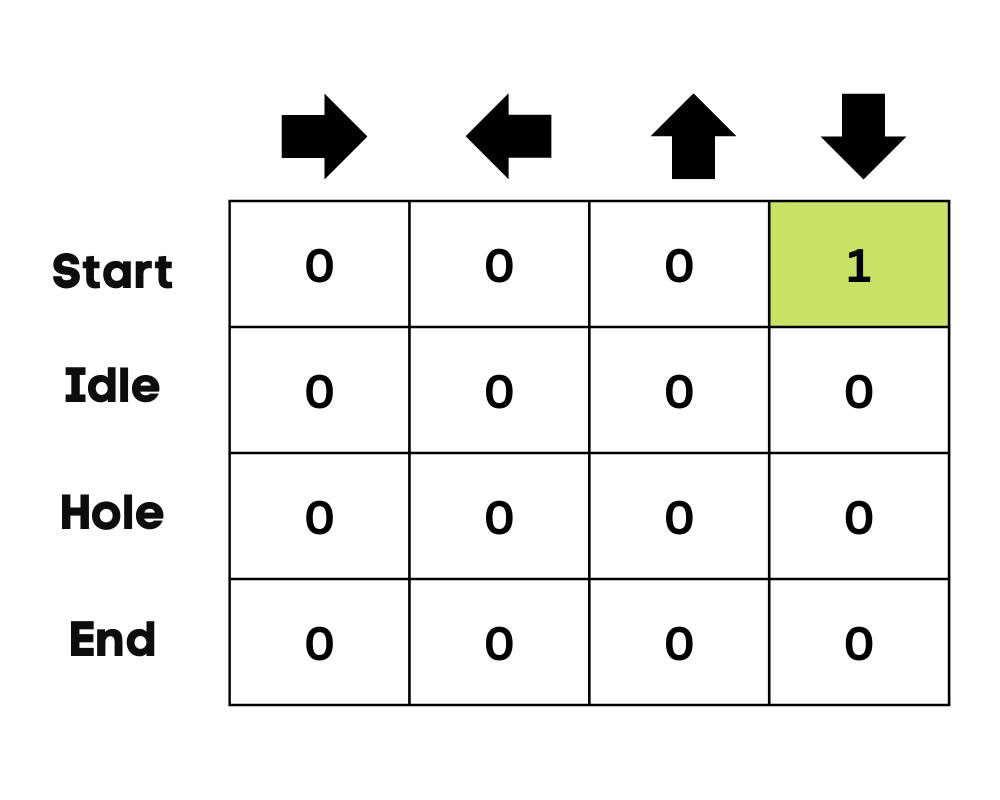
Afbeelding door de auteur
In het voorbeeld van het bevroren meer kent de agent de omgeving niet, dus neemt hij om te beginnen een willekeurige actie (omlaag bewegen). Zoals we in de bovenstaande afbeelding zien, wordt de Q-tabel bijgewerkt met de vergelijking van Bellman.
Nadat we de actie hebben genomen, meten we de uitkomst en de beloning.
We werken de functie Q(St, At) bij met de vergelijking. Deze gebruikt de geschatte Q-waarden van de vorige episode, het leerpercentage en de Temporal Differences-fout. De Temporal Differences-fout wordt berekend met de onmiddellijke beloning, de verdisconteerde maximaal verwachte toekomstige beloning en de eerdere geschatte Q-waarde.
Het proces wordt meerdere keren herhaald totdat de Q-tabel is bijgewerkt en de Q-waardefunctie is gemaximaliseerd.
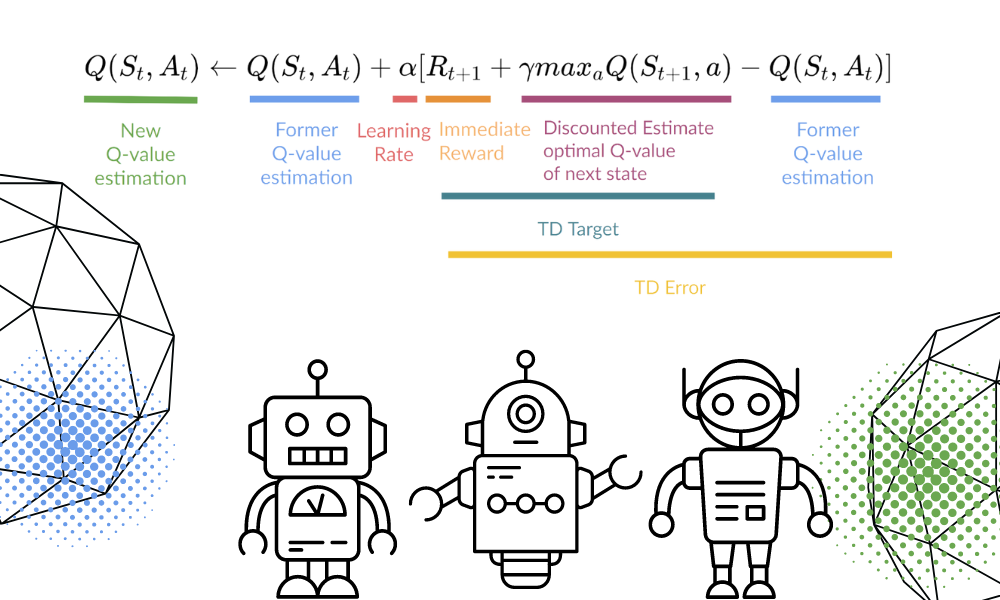
Afbeelding door de auteur | Vergelijkingsvisuals van Thomas Simonini
In het begin verkent de agent de omgeving om de Q-tabel bij te werken. En wanneer de Q-tabel klaar is, begint de agent te exploiteren en betere beslissingen te nemen. 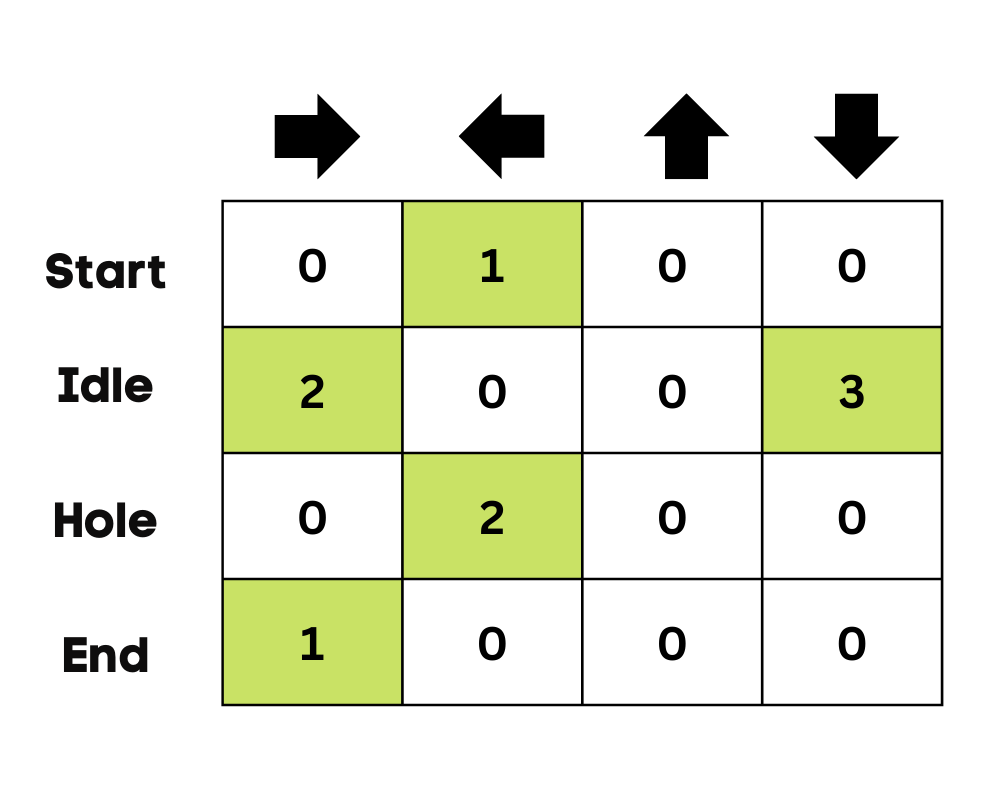
Afbeelding door de auteur
In het geval van een bevroren meer leert de agent het kortste pad te nemen om het doel te bereiken en te vermijden om in de gaten te springen.
In deze sectie bouwen we ons Q-learningmodel vanaf nul met de Gymnasium-omgeving, Pygame en Numpy. De Python-tutorial is een aangepaste versie van het Notebook van Thomas Simonini. Het omvat het initialiseren van de omgeving en Q-tabel, het definiëren van het greedy-beleid, het instellen van hyperparameters, het maken en draaien van de trainingslus en evaluatie, en het visualiseren van de resultaten.
Als je problemen ondervindt met het maken en draaien van je trainingslus, kun je de codebron met de output bekijken.
We installeren eerst alle afhankelijkheden om een replayvideo (gif) te genereren. We hebben een virtueel scherm (pyvirtualdisplay) nodig om de omgeving te renderen en de frames op te nemen.
Let op: met %%capture onderdrukken we de output van de Jupyter-cel.
%%capture
!pip install pyglet==1.5.1
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip3 install pyvirtualdisplay
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()We installeren nu afhankelijkheden die ons helpen om de trainingslus te maken, te draaien en te evalueren.
%%capture
!pip install gymnasium
!pip install pygame
!pip install numpy
!pip install imageio imageio_ffmpegWe importeren nu de vereiste libraries.
import numpy as np
import gymnasium as gym
import random
import imageio
from tqdm.notebook import trangeWe gaan een niet-gladde 4x4-omgeving maken met behulp van de Frozen Lake gymnasium-bibliotheek.
is_slippery=True, beweegt de agent mogelijk niet in de bedoelde richting vanwege het gladde karakter van het bevroren meer. Na het initialiseren van de omgeving doen we een omgevingsanalyse.
env = gym.make("FrozenLake-v1",map_name="4x4",is_slippery=False)
print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # display a random observationEr zijn 16 unieke ruimtes in de omgeving die op willekeurige posities worden weergegeven.
Observation Space Discrete(16)
Sample observation 15Laten we het aantal acties ontdekken en de willekeurige actie weergeven.
De actieruimte:
Beloningsfunctie:
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample())Action Space Shape 4
Action Space Sample 1De Q-tabel heeft kolommen als acties en rijen als toestanden. We kunnen Gymnasium gebruiken om de actieruimte en toestandsruimte te vinden. We gebruiken deze informatie vervolgens om de Q-tabel te maken.
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
action_space = env.action_space.n
print("There are ", action_space, " possible actions")There are 16 possible states
There are 4 possible actionsVoor het initialiseren van de Q-tabel maken we een Numpy-array van toestandsruimte en actieruimte. We maken een array van 16 x 4.
def initialize_q_table(state_space, action_space):
Qtable = np.zeros((state_space, action_space))
return Qtable
Qtable_frozenlake = initialize_q_table(state_space, action_space)In de vorige sectie hebben we geleerd over de epsilon-greedy-strategie die de afweging tussen exploratie en exploitatie afhandelt. Met een kans van 1 - ɛ doen we exploitatie, en met kans ɛ doen we exploratie.
In de epsilon_greedy_policy doen we het volgende:
def epsilon_greedy_policy(Qtable, state, epsilon):
random_int = random.uniform(0,1)
if random_int > epsilon:
action = np.argmax(Qtable[state])
else:
action = env.action_space.sample()
return actionWe weten nu dat Q-learning een off-policy algoritme is, wat betekent dat het beleid voor het nemen van acties en het bijwerken van de functie verschillend is.
In dit voorbeeld is het Epsilon-greedy-beleid het handelende beleid, en het greedy-beleid is het bijwerkbeleid.
Het greedy-beleid zal ook het uiteindelijke beleid zijn wanneer de agent is getraind. Het wordt gebruikt om de hoogste toestand- en actiewaarde uit de Q-tabel te selecteren.
def greedy_policy(Qtable, state):
action = np.argmax(Qtable[state])
return actionDeze hyperparameters worden in de trainingslus gebruikt, en het fijn afstellen ervan levert je betere resultaten op.
De agent moet genoeg toestandsruimte verkennen om goede waarde-approximaties te leren; we hebben een geleidelijke afname van epsilon nodig. Als de afnamesnelheid hoog is, kan de agent vastlopen omdat hij niet genoeg toestandsruimte heeft verkend.
# Training parameters
n_training_episodes = 10000
learning_rate = 0.7
# Evaluation parameters
n_eval_episodes = 100
# Environment parameters
env_id = "FrozenLake-v1"
max_steps = 99
gamma = 0.95
eval_seed = []
# Exploration parameters
max_epsilon = 1.0
min_epsilon = 0.05
decay_rate = 0.0005 In de trainingslus doen we het volgende:
done= True, beëindig de episode en breek de lus af.def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in trange(n_training_episodes):
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
state = env.reset()
step = 0
done = False
# repeat
for step in range(max_steps):
action = epsilon_greedy_policy(Qtable, state, epsilon)
new_state, reward, done, info = env.step(action)
Qtable[state][action] = Qtable[state][action] + learning_rate * (reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action])
# If done, finish the episode
if done:
break
# Our state is the new state
state = new_state
return QtableHet kostte ons 3 seconden om 10.000 trainingsepisodes te voltooien.
Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
Zoals we zien, heeft de getrainde Q-tabel waarden, en de agent gebruikt deze waarden nu om door de omgeving te navigeren en het doel te bereiken.
Qtable_frozenlakearray([[0.73509189, 0.77378094, 0.77378094, 0.73509189],
[0.73509189, 0. , 0.81450625, 0.77378094],
[0.77378094, 0.857375 , 0.77378094, 0.81450625],
[0.81450625, 0. , 0.77378094, 0.77378094],
[0.77378094, 0.81450625, 0. , 0.73509189],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0. , 0.81450625],
[0. , 0. , 0. , 0. ],
[0.81450625, 0. , 0.857375 , 0.77378094],
[0.81450625, 0.9025 , 0.9025 , 0. ],
[0.857375 , 0.95 , 0. , 0.857375 ],
[0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0.95 , 0.857375 ],
[0.9025 , 0.95 , 1. , 0.9025 ],
[0. , 0. , 0. , 0. ]])De evaluate_agent draait voor n_eval_episodes episodes en retourneert het gemiddelde en de standaarddeviatie van de beloning.
def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
episode_rewards = []
for episode in range(n_eval_episodes):
if seed:
state = env.reset(seed=seed[episode])
else:
state = env.reset()
step = 0
done = False
total_rewards_ep = 0
for step in range(max_steps):
# Take the action (index) that have the maximum reward
action = np.argmax(Q[state][:])
new_state, reward, done, info = env.step(action)
total_rewards_ep += reward
if done:
break
state = new_state
episode_rewards.append(total_rewards_ep)
mean_reward = np.mean(episode_rewards)
std_reward = np.std(episode_rewards)
return mean_reward, std_rewardZoals je ziet, kregen we de perfecte score met nul standaarddeviatie. Dat betekent dat onze agent in alle 100 episodes het doel heeft bereikt.
# Evaluate our Agent
mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")Mean_reward=1.00 +/- 0.00Tot nu toe hebben we met getallen gewerkt, en om de demo te geven moeten we een geanimeerde gif maken van de agent vanaf de start tot hij het doel bereikt.
img toe aan de images-array. def record_video(env, Qtable, out_directory, fps=1):
images = []
done = False
state = env.reset(seed=random.randint(0,500))
img = env.render(mode='rgb_array')
images.append(img)
while not done:
# Take the action (index) that have the maximum expected future reward given that state
action = np.argmax(Qtable[state][:])
state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
img = env.render(mode='rgb_array')
images.append(img)
imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)Als je in een Jupyter-notebook werkt, kun je de gif weergeven met de functie Image van IPython.display.
video_path="/content/replay.gif"
video_fps=1
record_video(env, Qtable_frozenlake, video_path, video_fps)
from IPython.display import Image
Image('./replay.gif')Je kunt deze resultaten nu delen met je collega’s en studiegenoten of posten op social media.
Cursussen Machine Learning
Cursus
blog
Adel Nehme
15 min
