
Corso
Progettare workflow di Machine Learning in Python
4 h
12.6K
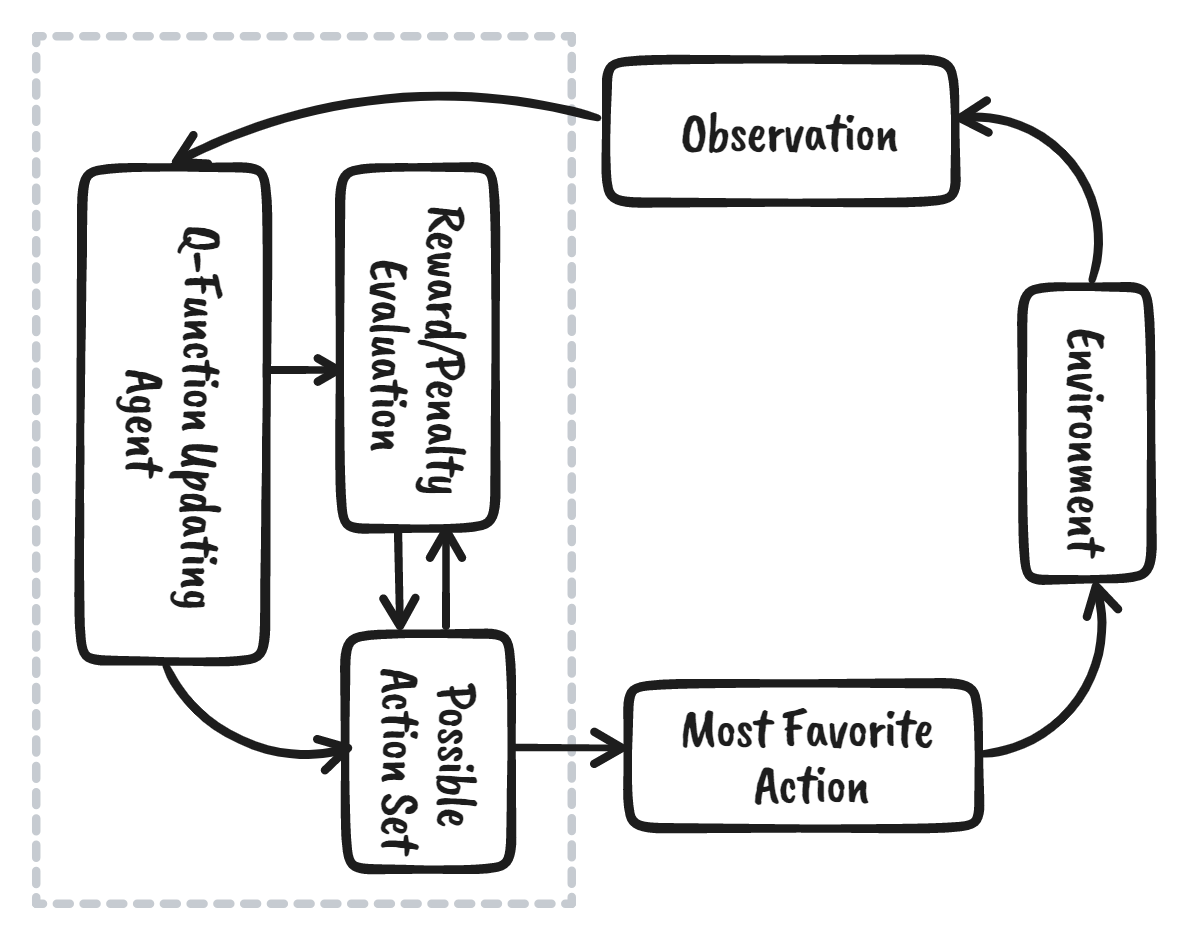
Il reinforcement learning (RL) è l’area del machine learning in cui un agente impara interagendo con l’ambiente per ottenere la strategia ottimale per raggiungere gli obiettivi. È piuttosto diverso dagli algoritmi di machine learning supervisionato, dove dobbiamo ingerire ed elaborare i dati. Il reinforcement learning non richiede dati preesistenti: impara dall’ambiente e dal sistema di ricompense per prendere decisioni migliori.
Per esempio, nel videogioco di Mario, se un personaggio compie un’azione casuale (ad es. si muove a sinistra), in base a quell’azione può ricevere una ricompensa. Dopo aver agito, l’agente (Mario) si trova in un nuovo stato e il processo si ripete finché il personaggio non raggiunge la fine del livello o muore.
Questo episodio si ripeterà più volte finché Mario non impara a muoversi nell’ambiente massimizzando le ricompense.

Immagine dell’autore
Possiamo scomporre il reinforcement learning in cinque semplici passaggi:
Per saperne di più, leggi il nostro tutorial, un’Introduzione al Reinforcement Learning. Esplorerai meglio come funziona il reinforcement learning con esempi di codice.
In questo tutorial impareremo il Q-learning e capiremo perché serve il Deep Q-learning. Inoltre, creeremo e alleneremo algoritmi di Q-learning da zero usando Numpy e Gymnasium.
Nota: se sei alle prime armi con il machine learning, ti consigliamo di seguire il nostro percorso di carriera Machine Learning Scientist with Python per comprendere meglio Reinforcement learning e Q-Learning.
Il Q-learning è un algoritmo model-free, value-based e off-policy che trova la migliore sequenza di azioni in base allo stato attuale dell’agente. La “Q” sta per quality. La qualità rappresenta quanto sia utile un’azione nel massimizzare le ricompense future.
Gli algoritmi model-based usano funzioni di transizione e ricompensa per stimare la policy ottimale e creare il modello. Al contrario, gli algoritmi model-free apprendono le conseguenze delle loro azioni attraverso l’esperienza, senza funzioni di transizione e ricompensa.
Il metodo value-based allena la funzione di valore per imparare quali stati sono più preziosi e agire di conseguenza. I metodi policy-based, invece, allenano direttamente la policy per imparare quale azione intraprendere in un dato stato.
Nell’off-policy, l’algoritmo valuta e aggiorna una policy diversa da quella usata per agire. Al contrario, l’algoritmo on-policy valuta e migliora la stessa policy usata per agire.
Prima di vedere come funziona il Q-learning, dobbiamo chiarire alcune terminologie utili per comprenderne le basi.
Vedremo nel dettaglio come funziona il Q-learning usando l’esempio di un lago ghiacciato. In questo ambiente, l’agente deve attraversare il lago ghiacciato dalla partenza all’obiettivo, senza cadere nelle buche. La strategia migliore è raggiungere l’obiettivo seguendo il percorso più breve.

Gif dell’autore
L’agente userà una Q-table per scegliere l’azione migliore possibile in base alla ricompensa attesa per ogni stato nell’ambiente. In parole semplici, una Q-table è una struttura dati di insiemi di azioni e stati, e usiamo l’algoritmo di Q-learning per aggiornare i valori nella tabella.
La Q-function usa l’equazione di Bellman e prende stato (s) e azione (a) in input. L’equazione semplifica il calcolo dei valori di stato e dei valori stato-azione. 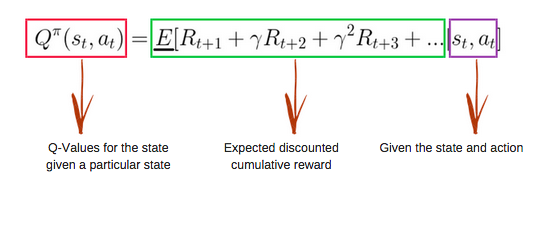
Immagine da freecodecamp.org
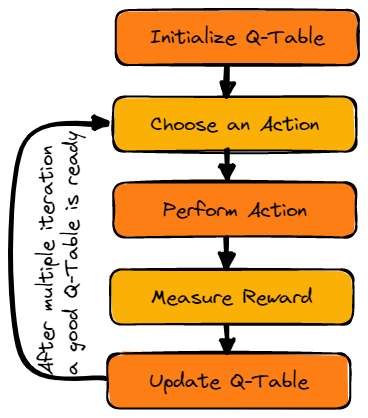
Immagine dell’autore
Per prima cosa inizializzeremo la Q-table. Costruiremo la tabella con colonne basate sul numero di azioni e righe sul numero di stati.
Nel nostro esempio, il personaggio può muoversi su, giù, sinistra e destra. Abbiamo quattro azioni possibili e quattro stati (inizio, inattivo, percorso sbagliato e fine). Puoi considerare il percorso sbagliato come la caduta in una buca. Inizializzeremo la Q-Table con valori pari a 0.
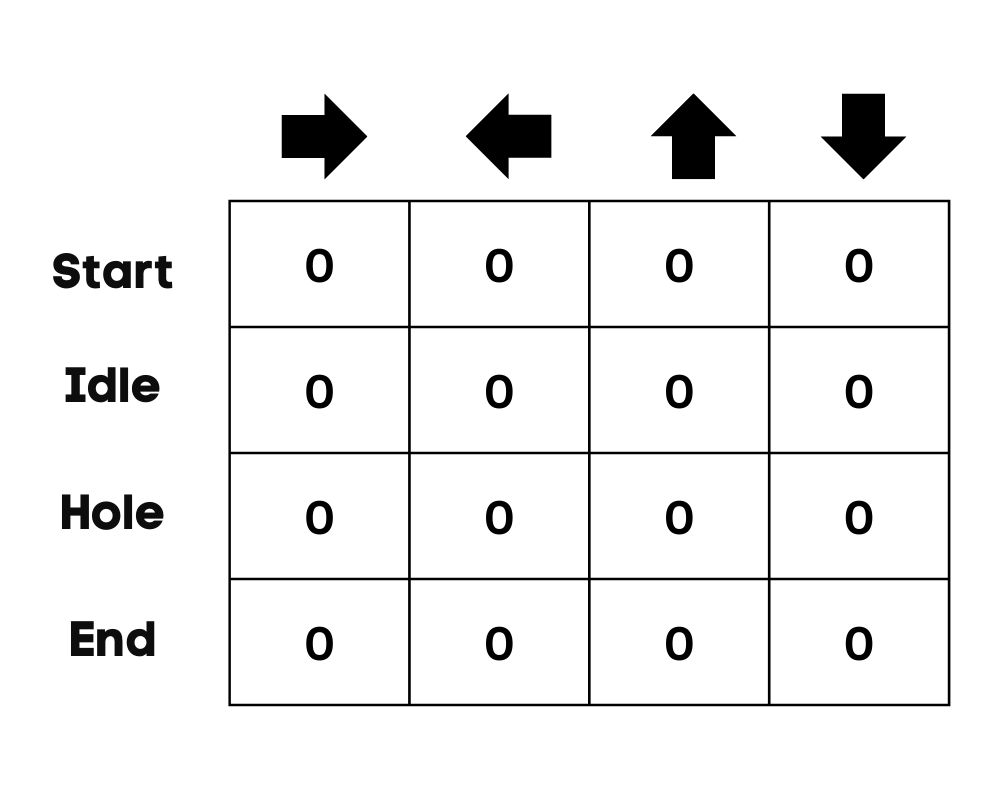
Immagine dell’autore
Il secondo passaggio è abbastanza semplice. All’inizio, l’agente sceglierà un’azione casuale (giù o destra) e, alla seconda esecuzione, userà la Q-Table aggiornata per selezionare l’azione.
Scegliere ed eseguire l’azione si ripeterà più volte finché il ciclo di training non si interrompe. La prima azione e il primo stato sono selezionati usando la Q-Table. Nel nostro caso, tutti i valori della Q-Table sono zero.
Poi l’agente si muoverà verso il basso e aggiornerà la Q-Table usando l’equazione di Bellman. A ogni mossa, aggiorneremo i valori nella Q-Table e li useremo anche per determinare la migliore linea d’azione.
Inizialmente, l’agente è in modalità esplorazione e sceglie un’azione casuale per esplorare l’ambiente. La strategia Epsilon Greedy è un metodo semplice per bilanciare esplorazione ed exploitation. Epsilon rappresenta la probabilità di scegliere di esplorare e l’exploitation quando le possibilità di esplorare sono più piccole.
All’inizio, il tasso di epsilon è più alto, quindi l’agente è in modalità esplorazione. Mentre esplora l’ambiente, l’epsilon diminuisce e l’agente inizia a sfruttare l’ambiente. Durante l’esplorazione, a ogni iterazione, l’agente diventa più sicuro nella stima dei valori Q.
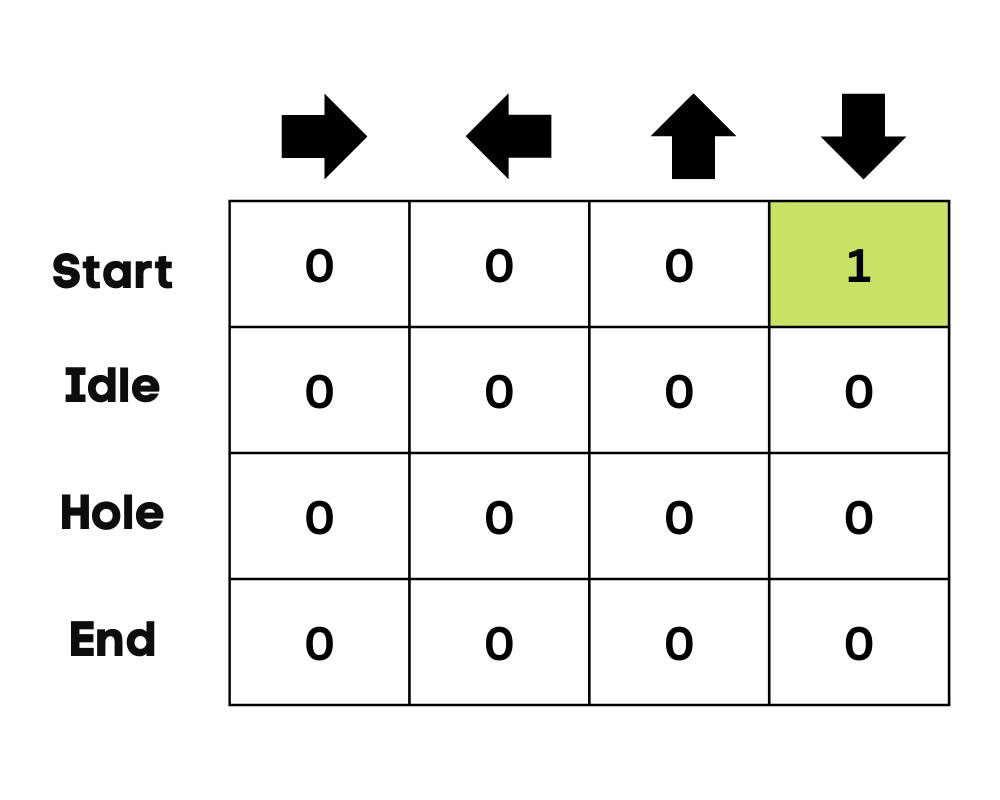
Immagine dell’autore
Nell’esempio del lago ghiacciato, l’agente non conosce l’ambiente, quindi all’inizio compie un’azione casuale (muoversi in giù). Come si vede nell’immagine sopra, la Q-Table viene aggiornata usando l’equazione di Bellman.
Dopo aver compiuto l’azione, misureremo l’esito e la ricompensa.
Aggiorneremo la funzione Q(St, At) usando l’equazione. Usa i valori Q stimati nell’episodio precedente, il learning rate e l’errore di Temporal Differences. L’errore di Temporal Differences è calcolato usando la ricompensa immediata, la ricompensa futura attesa massima scontata e la precedente stima del valore Q.
Il processo si ripete più volte finché la Q-Table non è aggiornata e la funzione di valore Q è massimizzata.
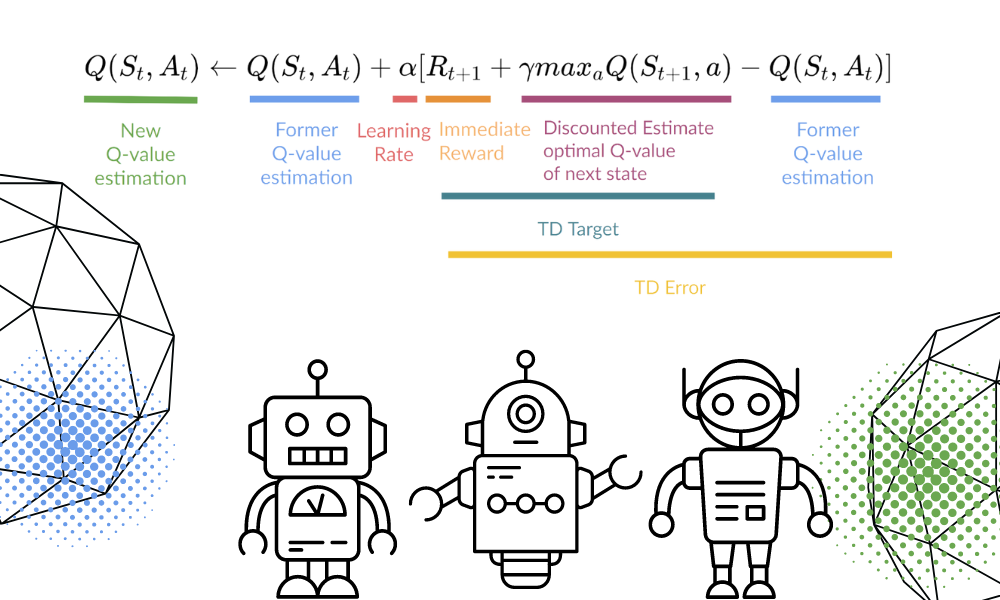
Immagine dell’autore | Visual della formula di Thomas Simonini
All’inizio, l’agente esplora l’ambiente per aggiornare la Q-table. E quando la Q-Table è pronta, l’agente inizia a sfruttarla e a prendere decisioni migliori. 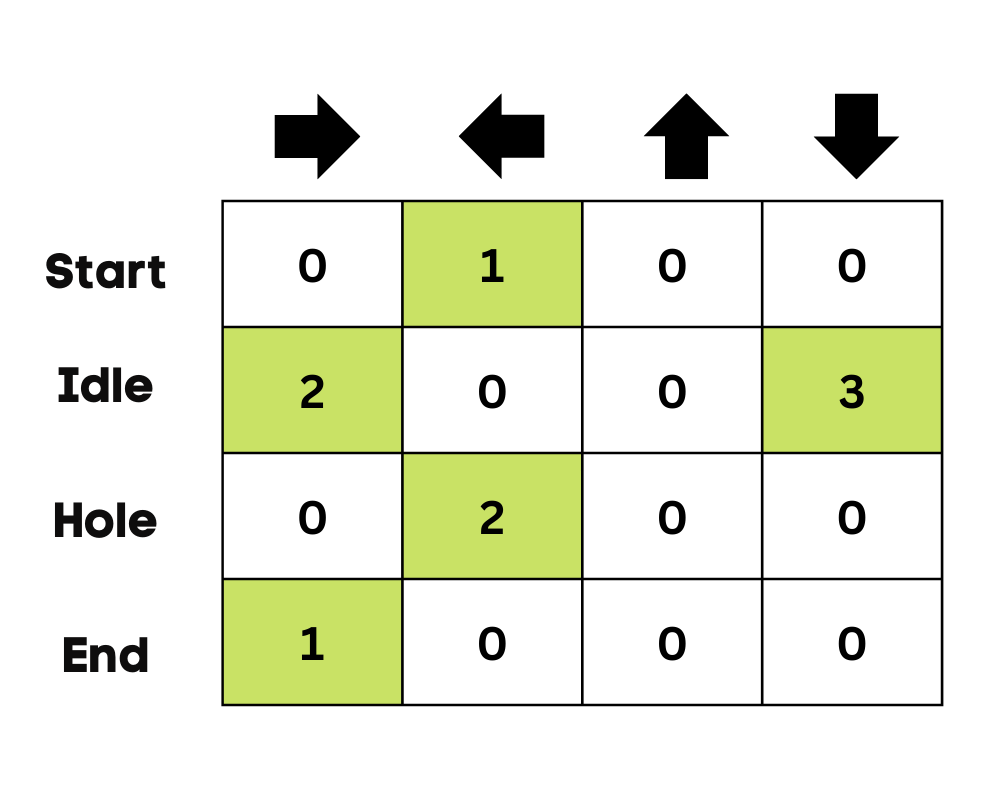
Immagine dell’autore
Nel caso del lago ghiacciato, l’agente imparerà a prendere il percorso più breve per raggiungere l’obiettivo ed evitare di saltare nelle buche.
In questa sezione costruiremo il nostro modello di Q-learning da zero usando l’ambiente Gymnasium, Pygame e Numpy. Il tutorial in Python è una versione modificata del Notebook di Thomas Simonini. Include l’inizializzazione dell’ambiente e della Q-Table, la definizione della policy greedy, l’impostazione degli iperparametri, la creazione ed esecuzione del ciclo di training e della valutazione, e la visualizzazione dei risultati.
Se riscontri problemi nel creare ed eseguire il tuo ciclo di training, puoi consultare il codice sorgente con l’output.
Per prima cosa installeremo tutte le dipendenze per generare un video di replay (Gif). Ci serve uno schermo virtuale (pyvirtualdisplay) per renderizzare l’ambiente e registrare i frame.
Nota: usando %%capture sopprimiamo l’output della cella Jupyter.
%%capture
!pip install pyglet==1.5.1
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip3 install pyvirtualdisplay
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()Ora installeremo le dipendenze che ci aiuteranno a creare, eseguire e valutare il ciclo di training.
%%capture
!pip install gymnasium
!pip install pygame
!pip install numpy
!pip install imageio imageio_ffmpegOra importeremo le librerie necessarie.
import numpy as np
import gymnasium as gym
import random
import imageio
from tqdm.notebook import trangeCreeremo un ambiente 4x4 non scivoloso usando la libreria Frozen Lake di Gymnasium.
is_slippery=True, l’agente potrebbe non muoversi nella direzione prevista a causa della natura scivolosa del lago ghiacciato. Dopo aver inizializzato l’ambiente, faremo un’analisi dell’ambiente.
env = gym.make("FrozenLake-v1",map_name="4x4",is_slippery=False)
print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # display a random observationCi sono 16 spazi unici nell’ambiente mostrati in posizioni casuali.
Observation Space Discrete(16)
Sample observation 15Scopriamo il numero di azioni e mostriamo un’azione casuale.
Action space:
Funzione di ricompensa:
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample())Action Space Shape 4
Action Space Sample 1La Q-Table ha come colonne le azioni e come righe gli stati. Possiamo usare Gymnasium per trovare action space e state space. Useremo poi queste informazioni per creare la Q-Table.
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
action_space = env.action_space.n
print("There are ", action_space, " possible actions")There are 16 possible states
There are 4 possible actionsPer inizializzare la Q-Table, creeremo un array Numpy di state_space e action space. Creeremo un array 16 X 4.
def initialize_q_table(state_space, action_space):
Qtable = np.zeros((state_space, action_space))
return Qtable
Qtable_frozenlake = initialize_q_table(state_space, action_space)Nella sezione precedente abbiamo visto la strategia epsilon greedy che gestisce il compromesso tra esplorazione ed exploitation. Con probabilità 1 - ɛ, facciamo exploitation, e con probabilità ɛ, facciamo esplorazione.
Nella epsilon_greedy_policy faremo:
def epsilon_greedy_policy(Qtable, state, epsilon):
random_int = random.uniform(0,1)
if random_int > epsilon:
action = np.argmax(Qtable[state])
else:
action = env.action_space.sample()
return actionOra sappiamo che il Q-learning è un algoritmo off-policy, il che significa che la policy usata per agire e quella usata per aggiornare la funzione sono diverse.
In questo esempio, la policy Epsilon Greedy è la policy di azione e la policy Greedy è quella di aggiornamento.
La policy Greedy sarà anche la policy finale quando l’agente è addestrato. Si usa per selezionare dallo stato il valore di azione più alto nella Q-Table.
def greedy_policy(Qtable, state):
action = np.argmax(Qtable[state])
return actionQuesti iperparametri sono usati nel ciclo di training e ottimizzarli ti darà risultati migliori.
L’agente deve esplorare a sufficienza lo spazio degli stati per imparare una buona approssimazione dei valori; serve quindi un decadimento progressivo di epsilon. Se il tasso di decadimento è alto, l’agente potrebbe bloccarsi perché non ha esplorato abbastanza lo spazio degli stati.
# Training parameters
n_training_episodes = 10000
learning_rate = 0.7
# Evaluation parameters
n_eval_episodes = 100
# Environment parameters
env_id = "FrozenLake-v1"
max_steps = 99
gamma = 0.95
eval_seed = []
# Exploration parameters
max_epsilon = 1.0
min_epsilon = 0.05
decay_rate = 0.0005 Nel ciclo di training, faremo:
done= True, terminare l’episodio e uscire dal ciclo.def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in trange(n_training_episodes):
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
state = env.reset()
step = 0
done = False
# repeat
for step in range(max_steps):
action = epsilon_greedy_policy(Qtable, state, epsilon)
new_state, reward, done, info = env.step(action)
Qtable[state][action] = Qtable[state][action] + learning_rate * (reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action])
# If done, finish the episode
if done:
break
# Our state is the new state
state = new_state
return QtableCi sono voluti 3 secondi per completare 10.000 episodi di training.
Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
Come possiamo vedere, la Q-Table addestrata ha dei valori e l’agente ora userà questi valori per muoversi nell’ambiente e raggiungere l’obiettivo.
Qtable_frozenlakearray([[0.73509189, 0.77378094, 0.77378094, 0.73509189], [0.73509189, 0. , 0.81450625, 0.77378094], [0.77378094, 0.857375 , 0.77378094, 0.81450625], [0.81450625, 0. , 0.77378094, 0.77378094], [0.77378094, 0.81450625, 0. , 0.73509189], [0. , 0. , 0. , 0. ], [0. , 0.9025 , 0. , 0.81450625], [0. , 0. , 0. , 0. ], [0.81450625, 0. , 0.857375 , 0.77378094], [0.81450625, 0.9025 , 0.9025 , 0. ], [0.857375 , 0.95 , 0. , 0.857375 ], [0. , 0. , 0. , 0. ], [0. , 0. , 0. , 0. ], [0. , 0.9025 , 0.95 , 0.857375 ], [0.9025 , 0.95 , 1. , 0.9025 ], [0. , 0. , 0. , 0. ]])Valutazione
La funzione evaluate_agent esegue per
n_eval_episodesepisodi e restituisce media e deviazione standard della ricompensa.
- Nel ciclo, per prima cosa verificheremo se c’è un seed di valutazione. In caso contrario, resetteremo l’ambiente senza seed.
- Il ciclo annidato verrà eseguito fino a max_steps.
- L’agente eseguirà l’azione che ha la massima ricompensa futura attesa in un dato stato usando la Q-Table.
- Calcolare la ricompensa.
- Cambiare lo stato.
- Se done (l’agente cade nella buca o l’obiettivo è stato raggiunto), interrompere il ciclo.
- Accodare i risultati.
- Alla fine useremo questi risultati per calcolare media e deviazione standard.
def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed): episode_rewards = [] for episode in range(n_eval_episodes): if seed: state = env.reset(seed=seed[episode]) else: state = env.reset() step = 0 done = False total_rewards_ep = 0 for step in range(max_steps): # Take the action (index) that have the maximum reward action = np.argmax(Q[state][:]) new_state, reward, done, info = env.step(action) total_rewards_ep += reward if done: break state = new_state episode_rewards.append(total_rewards_ep) mean_reward = np.mean(episode_rewards) std_reward = np.std(episode_rewards) return mean_reward, std_rewardCome puoi vedere, abbiamo ottenuto il punteggio perfetto con deviazione standard zero. Significa che il nostro agente ha raggiunto l’obiettivo in tutti i 100 episodi.
# Evaluate our Agent mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed) print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")Mean_reward=1.00 +/- 0.00Visualizzare il risultato
Finora abbiamo lavorato con numeri; per una demo dobbiamo creare una Gif animata dell’agente dall’inizio fino al raggiungimento dell’obiettivo.
- Per prima cosa creeremo lo stato resettando l’ambiente con un intero casuale 0-500.
- Renderizzeremo l’ambiente usando rdb_array per creare un array di immagini.
- Poi aggiungeremo
imgall’arrayimages.- Nel ciclo, faremo lo step usando la Q-Table e renderizzeremo l’immagine a ogni passo.
- Alla fine useremo questo array e imageio per creare una Gif a un fotogramma al secondo.
def record_video(env, Qtable, out_directory, fps=1): images = [] done = False state = env.reset(seed=random.randint(0,500)) img = env.render(mode='rgb_array') images.append(img) while not done: # Take the action (index) that have the maximum expected future reward given that state action = np.argmax(Qtable[state][:]) state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic img = env.render(mode='rgb_array') images.append(img) imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)Se sei in un Jupyter notebook, puoi visualizzare la Gif usando la funzione Image di
IPython.display.video_path="/content/replay.gif" video_fps=1 record_video(env, Qtable_frozenlake, video_path, video_fps) from IPython.display import Image Image('./replay.gif')Ora puoi condividere questi risultati con colleghi e compagni di corso o pubblicarli sui social.
Corsi di Machine Learning
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

