Kurs
Python'da Machine Learning İş Akışları Tasarlama
4 sa
12.6K
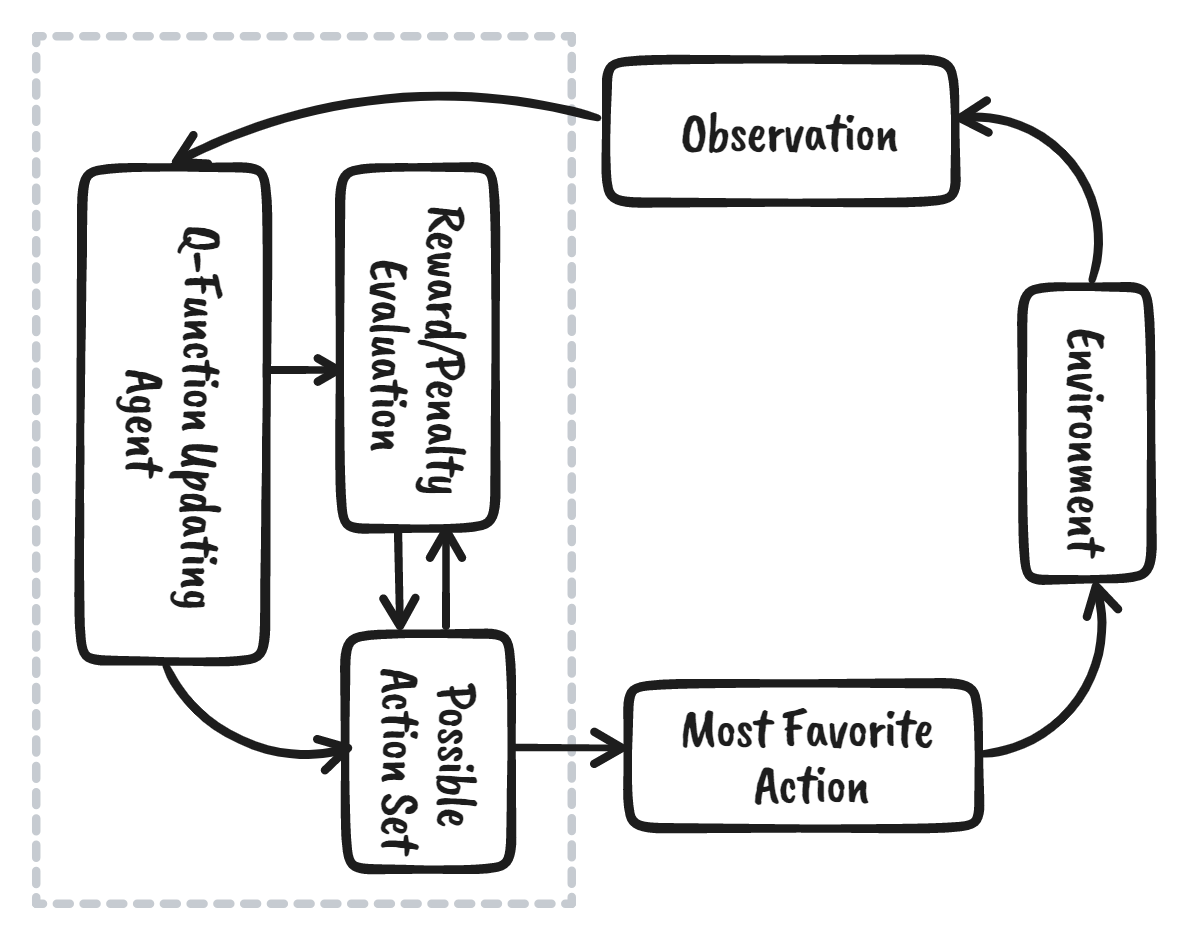
Pekiştirmeli öğrenme (RL), ajanın hedeflere ulaşmak için en iyi stratejiyi elde etmek amacıyla çevreyle etkileşime girerek öğrendiği makine öğrenmesi ekosisteminin bir parçasıdır. Verinin içe alınmasını ve işlenmesini gerektiren gözetimli makine öğrenmesi algoritmalarından oldukça farklıdır. Pekiştirmeli öğrenme veriye ihtiyaç duymaz. Bunun yerine, daha iyi kararlar vermek için çevreden ve ödül sisteminden öğrenir.
Örneğin, Mario video oyununda, bir karakter rastgele bir eylem yaparsa (ör. sola hareket etme), bu eyleme bağlı olarak bir ödül alabilir. Eylemi yaptıktan sonra, ajan (Mario) yeni bir durumda olur ve süreç, oyun karakteri bölümü bitirene kadar veya ölünceye kadar tekrar eder.
Bu bölüm, Mario ödülleri en üst düzeye çıkararak çevrede gezinmeyi öğrenene kadar birçok kez tekrarlanır.

Görsel: Yazar
Pekiştirmeli öğrenmeyi beş basit adımda özetleyebiliriz:
Daha fazlasını öğrenmek için Pekiştirmeli Öğrenmeye Giriş eğitimimizi okuyun. Kod örnekleriyle pekiştirmeli öğrenmenin nasıl çalıştığını keşfedeceksiniz.
Bu eğitimde Q-learning’i öğrenecek ve neden Derin Q-learning’e ihtiyaç duyduğumuzu anlayacağız. Ayrıca, Numpy ve Gymnasium kullanarak sıfırdan Q-learning algoritmaları oluşturmayı ve eğitmeyi öğreneceğiz.
Not: Makine öğrenmesinde yeniyseniz, Pekiştirmeli öğrenme ve Q-Learning’i daha iyi anlamak için Python ile Makine Öğrenimi Bilimcisi kariyer yolumuzu takip etmenizi öneririz.
Q-learning, ajanın mevcut durumuna göre en iyi eylem dizisini bulan modelden bağımsız, değer tabanlı, off-policy bir algoritmadır. “Q”, kaliteyi ifade eder. Kalite, gelecekteki ödülleri en üst düzeye çıkarmada bir eylemin ne kadar değerli olduğunu temsil eder.
Modele dayalı algoritmalar, en iyi politikayı tahmin etmek ve modeli oluşturmak için geçiş ve ödül fonksiyonlarını kullanır. Buna karşılık, modelden bağımsız algoritmalar, geçiş ve ödül fonksiyonları olmadan, deneyim yoluyla eylemlerinin sonuçlarını öğrenir.
Değer tabanlı yöntem, hangi durumun daha değerli olduğunu öğrenmek ve eylem almak için değer fonksiyonunu eğitir. Öte yandan, politika tabanlı yöntemler, belirli bir durumda hangi eylemi alacağını öğrenmek için politikayı doğrudan eğitir.
Off-policy yaklaşımda, algoritma, eylemi almak için kullanılan politikadan farklı bir politikayı değerlendirir ve günceller. Buna karşılık, on-policy algoritma, eylemi almak için kullanılan aynı politikayı değerlendirip iyileştirir.
Q-learning’in nasıl çalıştığına geçmeden önce, Q-learning’in temellerini anlamak için birkaç yararlı terim öğrenmemiz gerekir.
Q-learning’in nasıl çalıştığını ayrıntılı olarak donmuş göl örneği üzerinden öğreneceğiz. Bu ortamda, ajanın başlangıçtan hedefe kadar donmuş gölü deliklere düşmeden geçmesi gerekir. En iyi strateji, en kısa yolu izleyerek hedefe ulaşmaktır.

Gif: Yazar
Ajan, çevredeki her durum için beklenen ödüle göre en iyi eylemi seçmek için bir Q-tablosu kullanır. Basitçe söylemek gerekirse, Q-tablosu eylem ve durum kümelerinden oluşan bir veri yapısıdır ve tablodaki değerleri güncellemek için Q-learning algoritmasını kullanırız.
Q-fonksiyonu Bellman denklemini kullanır ve girdi olarak durum (s) ve eylem (a) alır. Denklem, durum değerlerini ve durum-eylem değeri hesaplamasını basitleştirir. 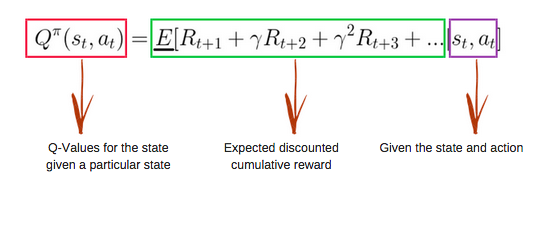
Görsel: freecodecamp.org
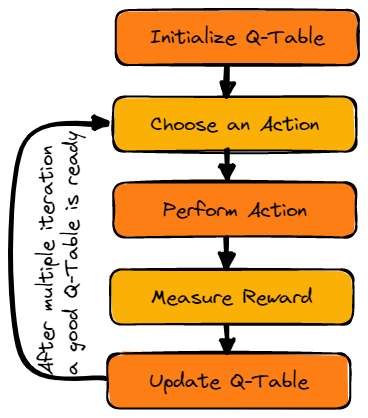
Görsel: Yazar
Önce Q-tablosunu başlatacağız. Tabloda sütunları eylem sayısına, satırları da durum sayısına göre oluşturacağız.
Örneğimizde karakter yukarı, aşağı, sola ve sağa hareket edebilir. Dört olası eylem ve dört durumumuz var (başlangıç, boşta, yanlış yol ve bitiş). Yanlış yolu, deliğe düşmek olarak da düşünebilirsiniz. Q-Tablosunu 0 değerleriyle başlatacağız.
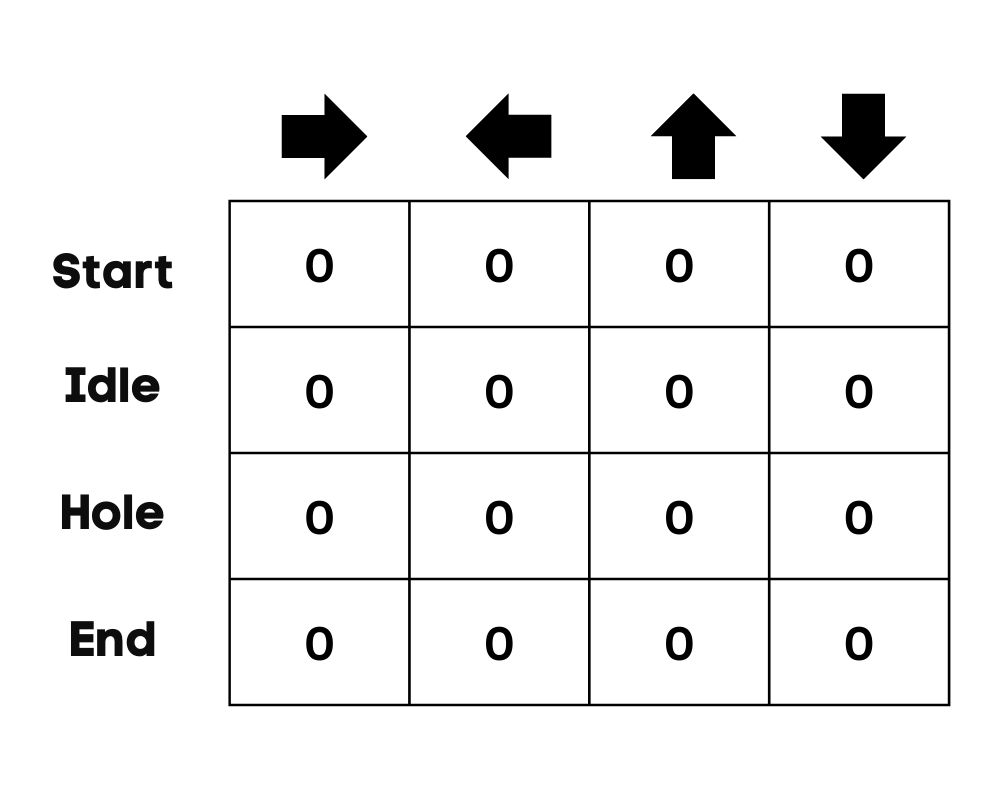
Görsel: Yazar
İkinci adım oldukça basittir. Başlangıçta, ajan rastgele bir eylem (aşağı ya da sağ) seçecek, ikinci çalıştırmada ise eylemi seçmek için güncellenmiş Q-Tablosunu kullanacaktır.
Eylem seçme ve eylemi gerçekleştirme, eğitim döngüsü durana kadar defalarca tekrarlanır. İlk eylem ve durum Q-Tablosu kullanılarak seçilir. Bizim durumda, Q-Tablosundaki tüm değerler sıfırdır.
Ardından, ajan aşağı hareket edecek ve Q-Tablosunu Bellman denklemini kullanarak güncelleyecektir. Her hamlede, Q-Tablosundaki değerleri güncellerken aynı zamanda en iyi hareket tarzını belirlemek için de kullanacağız.
Başlangıçta, ajan keşif modundadır ve çevreyi keşfetmek için rastgele eylemler seçer. Epsilon Açgözlü Strateji, keşif ve sömürü arasında denge kurmak için basit bir yöntemdir. Epsilon, keşfetmeyi seçme olasılığını ifade eder; keşfetme olasılığı azaldığında sömürü artar.
Başlangıçta epsilon oranı yüksektir; bu da ajanın keşif modunda olduğu anlamına gelir. Çevre keşfedildikçe epsilon azalır ve ajan çevreyi sömürmeye başlar. Keşif sırasında, her yinelemede ajan Q-değerlerini tahmin etmede daha da kendinden emin hale gelir
Görsel: Yazar
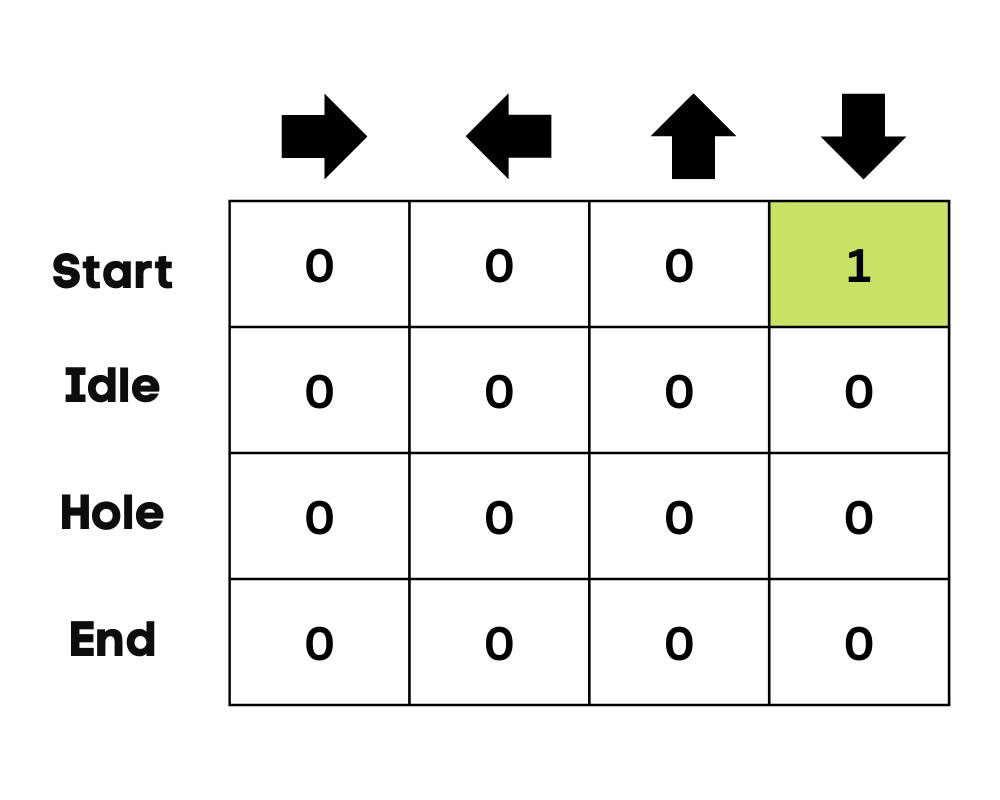
Donmuş göl örneğinde, ajan çevreyi bilmediği için başlangıçta rastgele bir eylem (aşağı hareket) yapar. Yukarıdaki görselde gördüğümüz gibi Q-Tablosu Bellman denklemi kullanılarak güncellenir.
Eylemi yaptıktan sonra sonucu ve ödülü ölçeceğiz.
Q(St, At) fonksiyonunu denklem kullanarak güncelleyeceğiz. Bu, önceki bölümün tahmini Q-değerlerini, öğrenme oranını ve Geçici Farklar hatasını kullanır. Geçici Farklar hatası, Anlık ödül, indirgenmiş beklenen maksimum gelecekteki ödül ve önceki tahmin Q-değeri kullanılarak hesaplanır.
Q-Tablosu güncellenip Q-değeri fonksiyonu en üst düzeye çıkarılana kadar süreç birçok kez tekrarlanır.
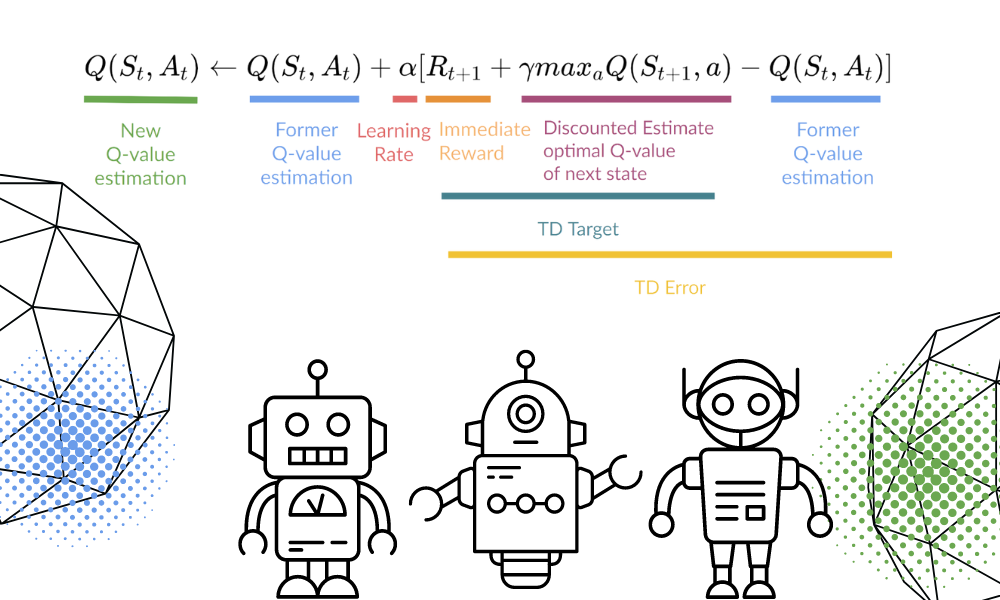
Görsel: Yazar | Denklem görselleri: Thomas Simonini
Başlangıçta ajan, Q-tablosunu güncellemek için çevreyi keşfeder. Q-Tablosu hazır olduğunda ise ajan sömürüye geçer ve daha iyi kararlar almaya başlar. 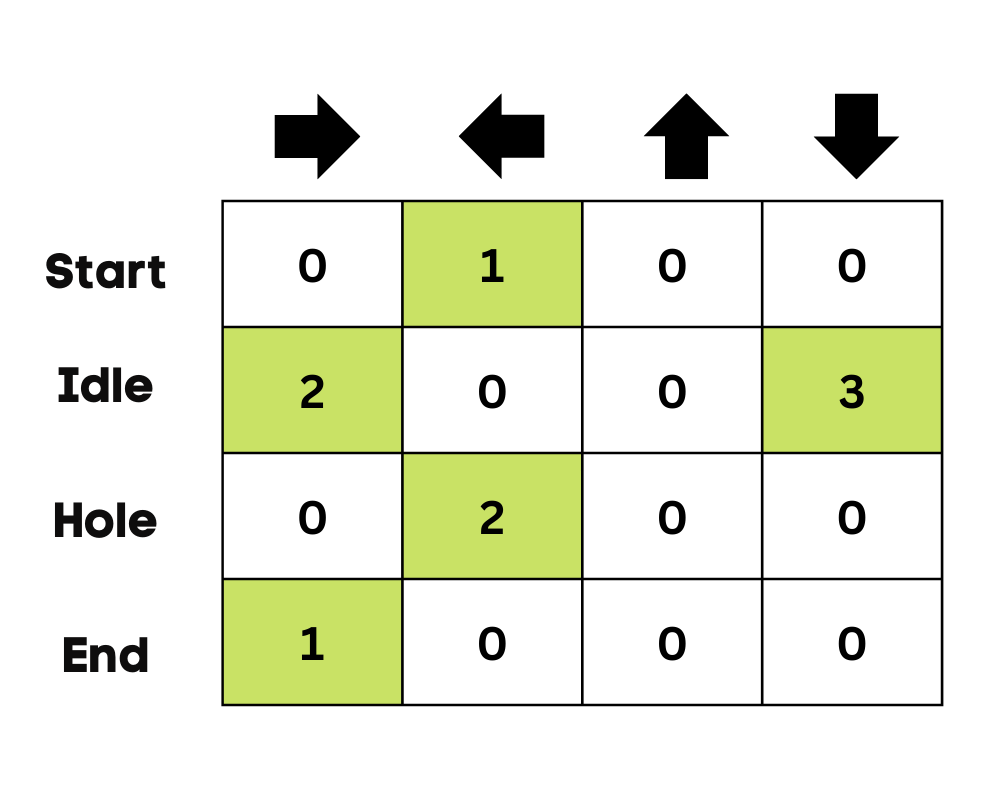
Görsel: Yazar
Donmuş göl durumunda ajan, hedefe ulaşmak için en kısa yolu öğrenir ve deliklere atlamaktan kaçınır.
Bu bölümde, Gymnasium ortamı, Pygame ve Numpy kullanarak Q-learning modelimizi sıfırdan oluşturacağız. Python eğitimi, Thomas Simonini’nin Defterinin değiştirilmiş bir sürümüdür. Ortamın ve Q-Tablosunun başlatılmasını, açgözlü politikanın tanımlanmasını, hiperparametrelerin ayarlanmasını, eğitim döngüsünün ve değerlendirmesinin oluşturulup çalıştırılmasını ve sonuçların görselleştirilmesini içerir.
Eğitim döngünüzü oluşturma ve çalıştırmada sorun yaşıyorsanız, çıktısıyla birlikte kod kaynağını kontrol edebilirsiniz.
Önce bir tekrar oynatma videosu (Gif) oluşturmak için tüm bağımlılıkları kuracağız. Çevreyi oluşturmak ve kareleri kaydetmek için sanal bir ekrana (pyvirtualdisplay) ihtiyacımız olacak.
Not: %%capture kullanarak Jupyter hücresinin çıktısını bastırıyoruz.
%%capture
!pip install pyglet==1.5.1
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip3 install pyvirtualdisplay
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()Şimdi eğitim döngüsünü oluşturmamıza, çalıştırmamıza ve değerlendirmemize yardımcı olacak bağımlılıkları kuracağız.
%%capture
!pip install gymnasium
!pip install pygame
!pip install numpy
!pip install imageio imageio_ffmpegŞimdi gerekli kütüphaneleri içe aktaracağız.
import numpy as np
import gymnasium as gym
import random
import imageio
from tqdm.notebook import trangeFrozen Lake gymnasium kütüphanesini kullanarak kaygan olmayan 4x4 bir ortam oluşturacağız.
is_slippery=True ise, donmuş gölün kaygan doğası nedeniyle ajan planlanan yönde hareket etmeyebilir. Ortamı başlattıktan sonra çevresel bir analiz yapacağız.
env = gym.make("FrozenLake-v1",map_name="4x4",is_slippery=False)
print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # display a random observationÇevrede rastgele konumlarda görüntülenen 16 benzersiz alan vardır.
Observation Space Discrete(16)
Sample observation 15Şimdi eylem sayısını keşfedelim ve rastgele bir eylemi görüntüleyelim.
Eylem uzayı:
Ödül fonksiyonu:
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample())Action Space Shape 4
Action Space Sample 1Q-Tablosunda sütunlar eylemler, satırlar ise durumlardır. Eylem uzayını ve durum uzayını bulmak için Gymnasium’u kullanabiliriz. Ardından bu bilgiyi Q-Tablosunu oluşturmak için kullanacağız.
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
action_space = env.action_space.n
print("There are ", action_space, " possible actions")There are 16 possible states
There are 4 possible actionsQ-Tablosunu başlatmak için, durum uzayı ve eylem uzayı boyutlarında bir Numpy dizisi oluşturacağız. 16 X 4’lük bir dizi oluşturacağız.
def initialize_q_table(state_space, action_space):
Qtable = np.zeros((state_space, action_space))
return Qtable
Qtable_frozenlake = initialize_q_table(state_space, action_space)Önceki bölümde, keşif ve sömürü arasındaki ödünleşimi yöneten epsilon açgözlü stratejiyi öğrendik. 1 - ɛ olasılıkla sömürü, ɛ olasılıkla keşif yaparız.
epsilon_greedy_policy içinde şunları yapacağız:
def epsilon_greedy_policy(Qtable, state, epsilon):
random_int = random.uniform(0,1)
if random_int > epsilon:
action = np.argmax(Qtable[state])
else:
action = env.action_space.sample()
return actionArtık Q-learning’in bir off-policy algoritma olduğunu, yani eylem alma ve fonksiyonu güncelleme politikasının farklı olduğunu biliyoruz.
Bu örnekte, Epsilon Açgözlü politika eylem politikası, Açgözlü politika ise güncelleme politikasıdır.
Açgözlü politika, ajan eğitildiğinde nihai politika olacaktır. Q-Tablosundan en yüksek durum ve eylem değerini seçmek için kullanılır.
def greedy_policy(Qtable, state):
action = np.argmax(Qtable[state])
return actionBu hiperparametreler eğitim döngüsünde kullanılır; ince ayar yapmak daha iyi sonuçlar verir.
Ajanın iyi bir değer yaklaşımı öğrenmesi için yeterli durum uzayını keşfetmesi gerekir; bu nedenle epsilon’un kademeli olarak azalması gerekir. Azalma oranı yüksekse, ajan yeterince durum uzayını keşfetmediği için takılabilir.
# Training parameters
n_training_episodes = 10000
learning_rate = 0.7
# Evaluation parameters
n_eval_episodes = 100
# Environment parameters
env_id = "FrozenLake-v1"
max_steps = 99
gamma = 0.95
eval_seed = []
# Exploration parameters
max_epsilon = 1.0
min_epsilon = 0.05
decay_rate = 0.0005 Eğitim döngüsünde şunları yapacağız:
done= True ise bölümü bitirin ve döngüyü kırın.def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in trange(n_training_episodes):
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
state = env.reset()
step = 0
done = False
# repeat
for step in range(max_steps):
action = epsilon_greedy_policy(Qtable, state, epsilon)
new_state, reward, done, info = env.step(action)
Qtable[state][action] = Qtable[state][action] + learning_rate * (reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action])
# If done, finish the episode
if done:
break
# Our state is the new state
state = new_state
return Qtable10.000 eğitim bölümünü tamamlamamız 3 saniye sürdü.
Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
Gördüğümüz gibi, eğitilmiş Q-Tablosunda değerler var ve ajan artık bu değerleri kullanarak ortamda gezinip hedefe ulaşacak.
Qtable_frozenlakearray([[0.73509189, 0.77378094, 0.77378094, 0.73509189],
[0.73509189, 0. , 0.81450625, 0.77378094],
[0.77378094, 0.857375 , 0.77378094, 0.81450625],
[0.81450625, 0. , 0.77378094, 0.77378094],
[0.77378094, 0.81450625, 0. , 0.73509189],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0. , 0.81450625],
[0. , 0. , 0. , 0. ],
[0.81450625, 0. , 0.857375 , 0.77378094],
[0.81450625, 0.9025 , 0.9025 , 0. ],
[0.857375 , 0.95 , 0. , 0.857375 ],
[0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0.95 , 0.857375 ],
[0.9025 , 0.95 , 1. , 0.9025 ],
[0. , 0. , 0. , 0. ]])evaluate_agent, n_eval_episodes bölüm boyunca çalışır ve ödülün ortalamasını ve standart sapmasını döndürür.
def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
episode_rewards = []
for episode in range(n_eval_episodes):
if seed:
state = env.reset(seed=seed[episode])
else:
state = env.reset()
step = 0
done = False
total_rewards_ep = 0
for step in range(max_steps):
# Take the action (index) that have the maximum reward
action = np.argmax(Q[state][:])
new_state, reward, done, info = env.step(action)
total_rewards_ep += reward
if done:
break
state = new_state
episode_rewards.append(total_rewards_ep)
mean_reward = np.mean(episode_rewards)
std_reward = np.std(episode_rewards)
return mean_reward, std_rewardGördüğünüz gibi, sıfır standart sapma ile mükemmel bir puan aldık. Bu, ajanın 100 bölümün tamamında hedefe ulaştığı anlamına gelir.
# Evaluate our Agent
mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")Mean_reward=1.00 +/- 0.00Şimdiye kadar sayılarla oynadık; bir demo sunmak için ajanın başlangıçtan hedefe ulaşana kadar olan sürecinin animasyonlu bir Gif’ini oluşturmamız gerekiyor.
img öğesini images dizisine ekleyin. def record_video(env, Qtable, out_directory, fps=1):
images = []
done = False
state = env.reset(seed=random.randint(0,500))
img = env.render(mode='rgb_array')
images.append(img)
while not done:
# Take the action (index) that have the maximum expected future reward given that state
action = np.argmax(Qtable[state][:])
state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
img = env.render(mode='rgb_array')
images.append(img)
imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)Bir Jupyter defterindeyseniz, Gif’i IPython.display Image işlevini kullanarak görüntüleyebilirsiniz.
video_path="/content/replay.gif"
video_fps=1
record_video(env, Qtable_frozenlake, video_path, video_fps)
from IPython.display import Image
Image('./replay.gif')Artık bu sonuçları meslektaşlarınız ve sınıf arkadaşlarınızla paylaşabilir veya sosyal medyada yayınlayabilirsiniz.
Makine Öğrenimi Kursları
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
