Curso
Projetando Workflows de Machine Learning em Python
4 h
12.6K
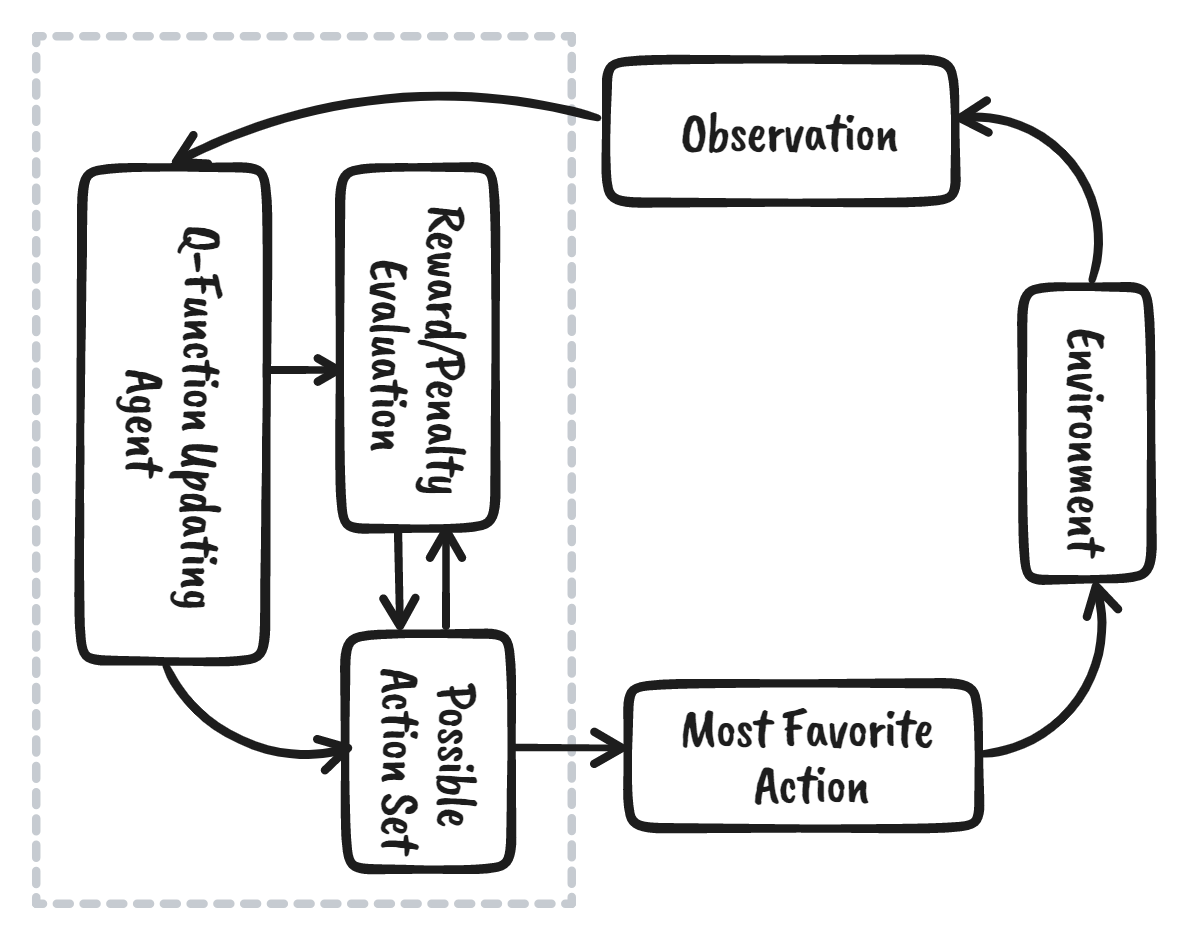
O aprendizado por reforço (RL) é a parte do ecossistema de aprendizado de máquina em que o agente aprende interagindo com o ambiente para obter a estratégia ideal para atingir as metas. Isso é bem diferente dos algoritmos de aprendizado de máquina supervisionados, em que precisamos ingerir e processar esses dados. O aprendizado por reforço não requer dados. Em vez disso, ele aprende com o ambiente e o sistema de recompensas para tomar decisões melhores.
Por exemplo, no videogame Mario, se um personagem realizar uma ação aleatória (por exemplo, mover-se para a esquerda), com base nessa ação, ele poderá receber uma recompensa. Depois de realizar a ação, o agente (Mario) fica em um novo estado, e o processo se repete até que o personagem do jogo chegue ao final da fase ou morra.
Esse episódio se repetirá várias vezes até que Mario aprenda a navegar pelo ambiente maximizando as recompensas.

Imagem do autor
Podemos dividir o aprendizado por reforço em cinco etapas simples:
Saiba mais lendo nosso tutorial, Introdução ao aprendizado por reforço. Você saberá mais sobre como funciona o aprendizado por reforço com exemplos de código.
Neste tutorial, aprenderemos sobre Q-learning e entenderemos por que precisamos do Deep Q-learning. Além disso, aprenderemos a criar e treinar algoritmos de aprendizado Q do zero usando o Numpy e o OpenAI Gym.
Observação: Se você é novo no aprendizado de máquina, recomendamos que faça o curso de carreira Cientista de aprendizado de máquina com Python para entender melhor o aprendizado por reforço e o Q-Learning.
O Q-learning é um algoritmo sem modelo, baseado em valores e fora da política que encontrará a melhor série de ações com base no estado atual do agente. O "Q" significa qualidade. A qualidade representa o valor da ação para maximizar as recompensas futuras.
Os algoritmos baseados em modelos usam funções de transição e recompensa para estimar a política ideal e criar o modelo. Por outro lado, os algoritmos sem modelo aprendem as consequências de suas ações por meio da experiência sem transição e função de recompensa.
O método baseado em valor treina a função de valor para saber qual estado é mais valioso e tomar medidas. Por outro lado, os métodos baseados em políticas treinam a política diretamente para aprender qual ação deve ser tomada em um determinado estado.
Na política de desativação, o algoritmo avalia e atualiza uma política que difere da política usada para realizar uma ação. Por outro lado, o algoritmo na política avalia e aprimora a mesma política usada para realizar uma ação.
Antes de falarmos sobre como o Q-learning funciona, precisamos aprender algumas terminologias úteis para entender os fundamentos do Q-learning.
Aprenderemos em detalhes como funciona o Q-learning usando o exemplo de um lago congelado. Nesse ambiente, o agente deve atravessar o lago congelado desde o início até o objetivo, sem cair nos buracos. A melhor estratégia é atingir as metas pelo caminho mais curto.

Gif por autor
O agente usará uma tabela Q para tomar a melhor ação possível com base na recompensa esperada para cada estado do ambiente. Em palavras simples, um Q-table é uma estrutura de dados de conjuntos de ações e estados, e usamos o algoritmo de Q-learning para atualizar os valores na tabela.
A função Q usa a equação de Bellman e usa estado(s) e ação(a) como entrada. A equação simplifica os valores de estado e o cálculo do valor da ação de estado. 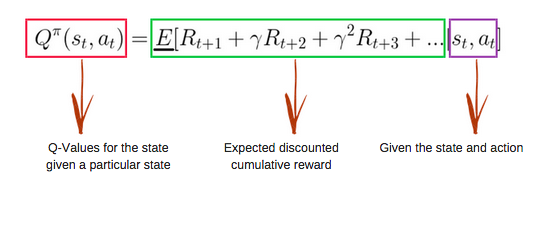
Imagem de freecodecamp.org
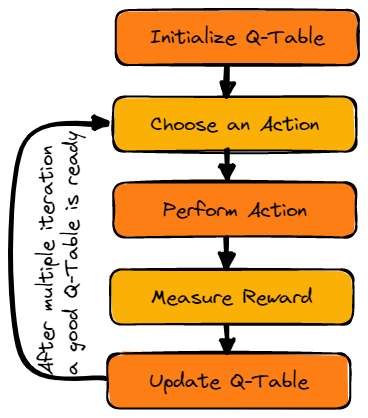
Imagem do autor
Primeiro, inicializaremos o Q-table. Criaremos a tabela com colunas baseadas no número de ações e linhas baseadas no número de estados.
Em nosso exemplo, o personagem pode se mover para cima, para baixo, para a esquerda e para a direita. Temos quatro ações possíveis e quatro estados (início, ocioso, caminho errado e fim). Você também pode considerar o caminho errado para cair no buraco. Inicializaremos o Q-Table com valores em 0.
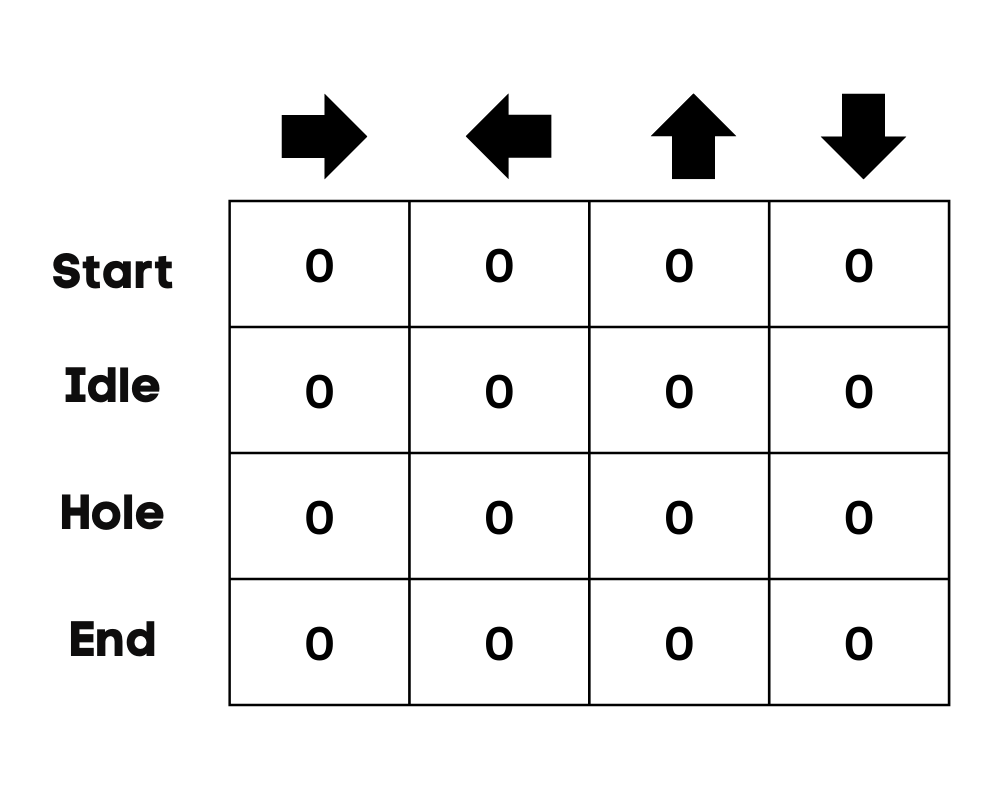
Imagem do autor
A segunda etapa é bastante simples. No início, o agente escolherá tomar a ação aleatória (para baixo ou para a direita) e, na segunda execução, usará um Q-Table atualizado para selecionar a ação.
A escolha de uma ação e a execução da ação serão repetidas várias vezes até que o loop de treinamento seja interrompido. A primeira ação e o primeiro estado são selecionados usando o Q-Table. Em nosso caso, todos os valores do Q-Table são zero.
Em seguida, o agente se moverá para baixo e atualizará o Q-Table usando a equação de Bellman. A cada jogada, atualizaremos os valores no Q-Table e também o usaremos para determinar o melhor curso de ação.
Inicialmente, o agente está no modo de exploração e escolhe uma ação aleatória para explorar o ambiente. A estratégia Epsilon Greedy é um método simples para equilibrar a exploração e o aproveitamento. O epsilon representa a probabilidade de escolher explorar e explora quando há menos chances de explorar.
No início, a taxa de epsilon é mais alta, o que significa que o agente está no modo de exploração. Ao explorar o ambiente, o epsilon diminui e os agentes começam a explorar o ambiente. Durante a exploração, a cada iteração, o agente se torna mais confiante na estimativa dos valores Q
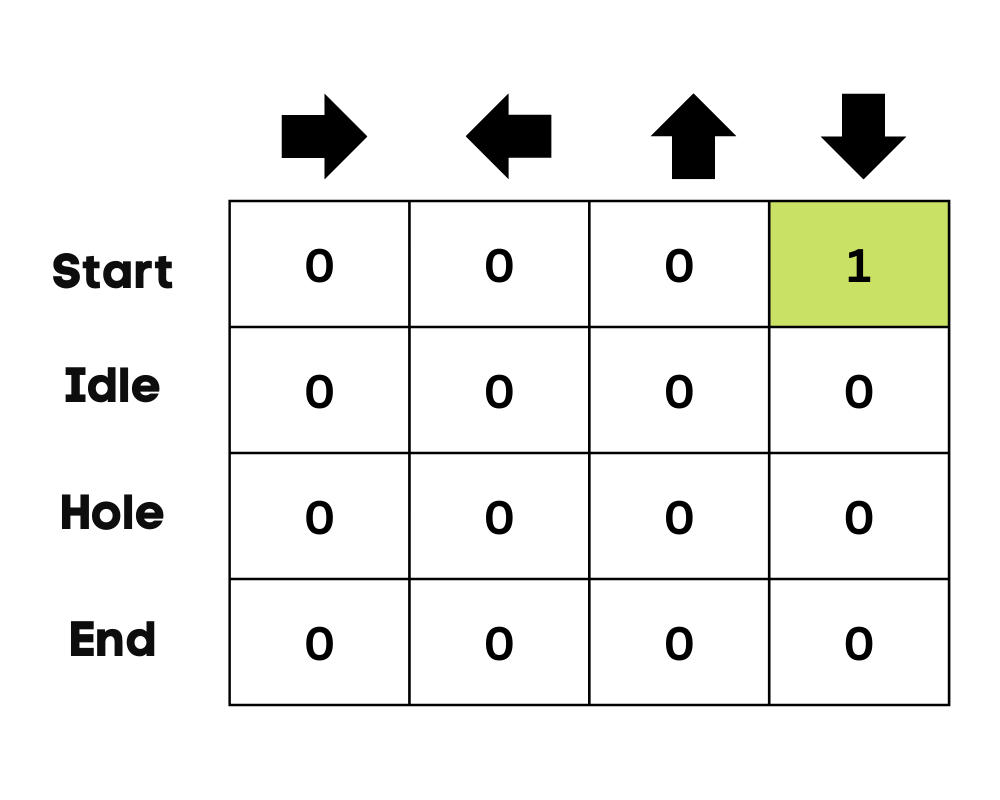
Imagem do autor
No exemplo do lago congelado, o agente não tem conhecimento do ambiente e, portanto, toma uma ação aleatória (mover-se para baixo) para começar. Como podemos ver na imagem acima, o Q-Table é atualizado usando a equação de Bellman.
Depois de realizar a ação, mediremos o resultado e a recompensa.
Atualizaremos a função Q(St,At) usando a equação. Ele usa os valores Q estimados do episódio anterior, a taxa de aprendizado e o erro de diferenças temporais. O erro de diferenças temporais é calculado usando a recompensa imediata, a recompensa futura máxima esperada descontada e o valor Q da estimativa anterior.
O processo é repetido várias vezes até que o Q-Table seja atualizado e a função de valor Q seja maximizada.
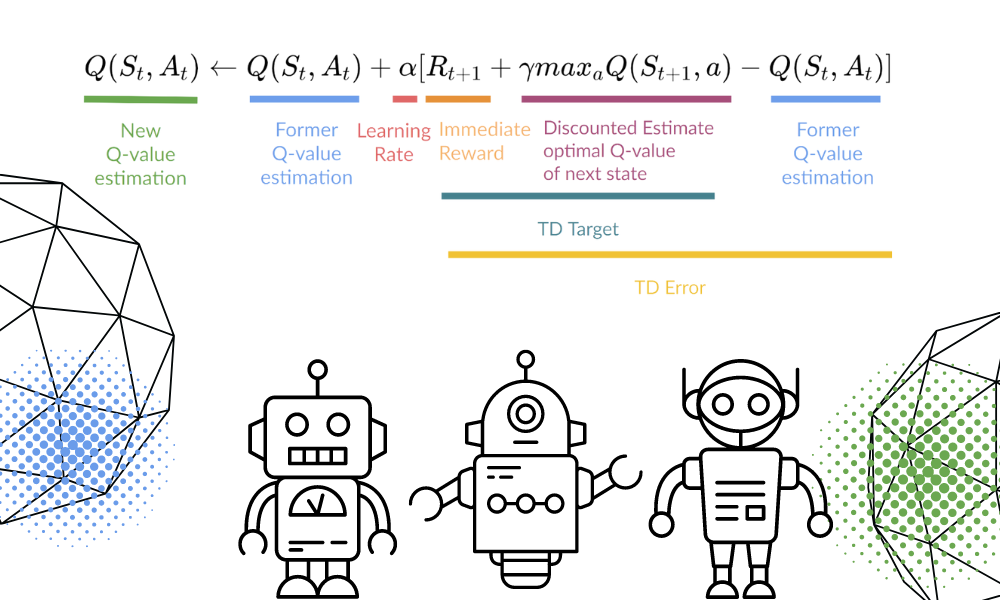
Imagem do autor | Equation Visuals de Thomas Simonini
No início, o agente está explorando o ambiente para atualizar o Q-table. E quando o Q-Table estiver pronto, o agente começará a explorar e a tomar decisões melhores. 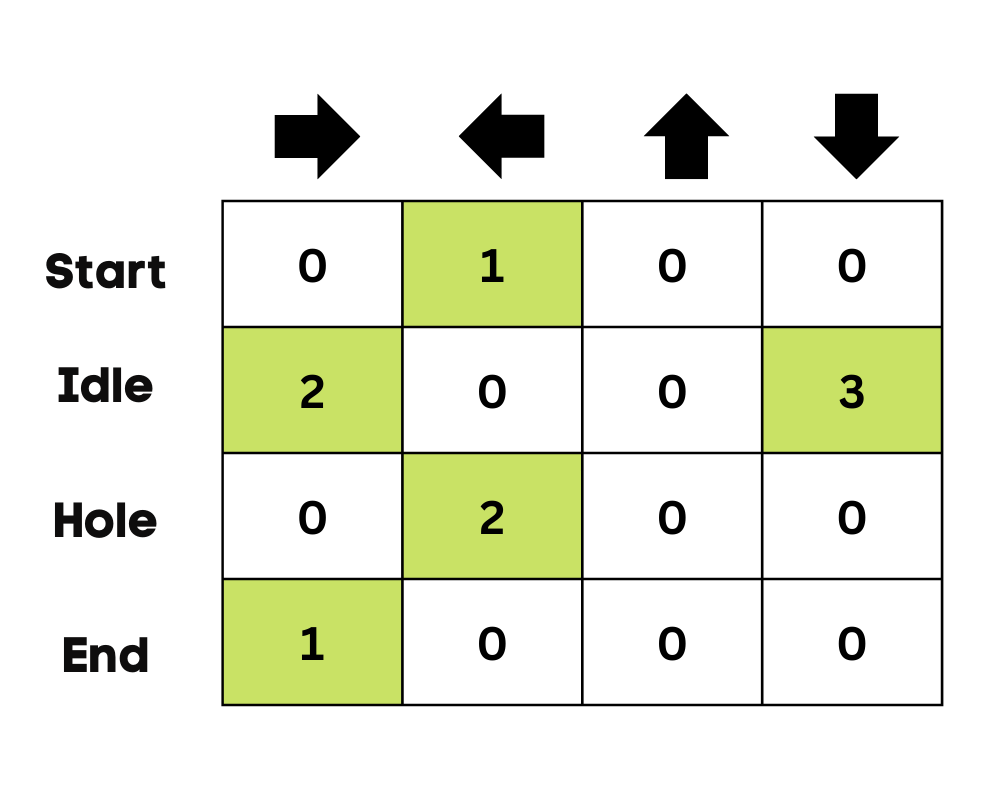
Imagem do autor
No caso de um lago congelado, o agente aprenderá a seguir o caminho mais curto para atingir a meta e evitar pular nos buracos.
Nesta seção, criaremos nosso modelo de Q-learning do zero usando o ambiente Gym, Pygame e Numpy. O tutorial de Python é uma versão modificada do Notebook de Thomas Simonini. Inclui a inicialização do ambiente e do Q-Table, a definição da política de ganância, a configuração dos hiperparâmetros, a criação e a execução do loop de treinamento e da avaliação e a visualização dos resultados.
Se estiver enfrentando problemas para criar e executar o loop de treinamento, verifique o código-fonte com o resultado.
Primeiro, instalaremos todas as dependências para gerar um vídeo de reprodução (Gif). Precisaremos de uma tela virtual (pyvirtualdisplay) para renderizar o ambiente e gravar os quadros.
Observação: ao usar `%%capture`, estamos suprimindo a saída da célula do Jupyter.
%%capture
!pip install pyglet==1.5.1
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip3 install pyvirtualdisplay
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()Agora, instalaremos as dependências que nos ajudarão a criar, executar e avaliar o loop de treinamento.
%%capture
!pip install gym==0.24
!pip install pygame
!pip install numpy
!pip install imageio imageio_ffmpegAgora vamos importar as bibliotecas necessárias.
import numpy as np
import gym
import random
import imageio
from tqdm.notebook import trangeVamos criar um ambiente 4x4 não escorregadio usando a biblioteca de ginástica Frozen Lake.
Depois de inicializar o ambiente, faremos uma análise ambiental.
env = gym.make("FrozenLake-v1",map_name="4x4",is_slippery=False)
print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # display a random observationHá 16 espaços exclusivos no ambiente exibidos em posições aleatórias.
Observation Space Discrete(16)
Sample observation 15Vamos descobrir o número de ações e exibir a ação aleatória.
O espaço de ação:
Função de recompensa:
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample())Action Space Shape 4
Action Space Sample 1O Q-Table tem colunas como ações e linhas como estados. Podemos usar o OpenAI Gym para encontrar o espaço de ação e o espaço de estado. Em seguida, usaremos essas informações para criar o Q-Table.
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
action_space = env.action_space.n
print("There are ", action_space, " possible actions")There are 16 possible states
There are 4 possible actionsPara inicializar o Q-Table, criaremos uma matriz Numpy de state_space e actions space. Criaremos uma matriz de 16 x 4.
def initialize_q_table(state_space, action_space):
Qtable = np.zeros((state_space, action_space))
return Qtable
Qtable_frozenlake = initialize_q_table(state_space, action_space)Na seção anterior, aprendemos sobre a estratégia epsilon greedy que lida com as compensações de exploração e aproveitamento. Com uma probabilidade de 1 - ɛ, fazemos exploitation, e com a probabilidade ɛ, fazemos exploration.
Na política epsilon_greedy_policy, faremos o seguinte:
def epsilon_greedy_policy(Qtable, state, epsilon):
random_int = random.uniform(0,1)
if random_int > epsilon:
action = np.argmax(Qtable[state])
else:
action = env.action_space.sample()
return actionComo já sabemos, o Q-learning é um algoritmo fora da política, o que significa que a política de tomada de ação e a função de atualização são diferentes.
Neste exemplo, a política Epsilon Greedy é a política de atuação, e a política Greedy é a política de atualização.
A política Greedy também será a política final quando o agente for treinado. É usado para selecionar o valor mais alto de estado e ação do Q-Table.
def greedy_policy(Qtable, state):
action = np.argmax(Qtable[state])
return actionEsses hiperparâmetros são usados no loop de treinamento, e o ajuste fino deles lhe proporcionará melhores resultados.
O agente precisa explorar um espaço de estado suficiente para aprender uma boa aproximação de valores; precisamos ter um decaimento progressivo do épsilon. Se a taxa de decaimento for alta, o agente poderá ficar preso, pois não explorou espaço de estado suficiente.
# Training parameters
n_training_episodes = 10000
learning_rate = 0.7
# Evaluation parameters
n_eval_episodes = 100
# Environment parameters
env_id = "FrozenLake-v1"
max_steps = 99
gamma = 0.95
eval_seed = []
# Exploration parameters
max_epsilon = 1.0
min_epsilon = 0.05
decay_rate = 0.0005 No loop de treinamento, nós o faremos:
def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in trange(n_training_episodes):
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
state = env.reset()
step = 0
done = False
# repeat
for step in range(max_steps):
action = epsilon_greedy_policy(Qtable, state, epsilon)
new_state, reward, done, info = env.step(action)
Qtable[state][action] = Qtable[state][action] + learning_rate * (reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action])
# If done, finish the episode
if done:
break
# Our state is the new state
state = new_state
return QtableLevamos 3 segundos para concluir 10.000 episódios de treinamento.
Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
Como podemos ver, o Q-Table treinado tem valores, e o agente agora usará esses valores para navegar pelo ambiente e atingir a meta.
Qtable_frozenlakearray([[0.73509189, 0.77378094, 0.77378094, 0.73509189],
[0.73509189, 0. , 0.81450625, 0.77378094],
[0.77378094, 0.857375 , 0.77378094, 0.81450625],
[0.81450625, 0. , 0.77378094, 0.77378094],
[0.77378094, 0.81450625, 0. , 0.73509189],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0. , 0.81450625],
[0. , 0. , 0. , 0. ],
[0.81450625, 0. , 0.857375 , 0.77378094],
[0.81450625, 0.9025 , 0.9025 , 0. ],
[0.857375 , 0.95 , 0. , 0.857375 ],
[0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0.95 , 0.857375 ],
[0.9025 , 0.95 , 1. , 0.9025 ],
[0. , 0. , 0. , 0. ]])O evaluate_agent é executado por `n_eval_episodes` episódios e retorna a média e o desvio padrão da recompensa.
def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
episode_rewards = []
for episode in range(n_eval_episodes):
if seed:
state = env.reset(seed=seed[episode])
else:
state = env.reset()
step = 0
done = False
total_rewards_ep = 0
for step in range(max_steps):
# Take the action (index) that have the maximum reward
action = np.argmax(Q[state][:])
new_state, reward, done, info = env.step(action)
total_rewards_ep += reward
if done:
break
state = new_state
episode_rewards.append(total_rewards_ep)
mean_reward = np.mean(episode_rewards)
std_reward = np.std(episode_rewards)
return mean_reward, std_rewardComo você pode ver, obtivemos a pontuação perfeita com desvio padrão zero. Isso significa que nosso agente atingiu a meta em todos os 100 episódios.
# Evaluate our Agent
mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")Mean_reward=1.00 +/- 0.00Até agora, estivemos brincando com números e, para fazer a demonstração, precisamos criar um gif animado do agente desde o início até ele atingir a meta.
def record_video(env, Qtable, out_directory, fps=1):
images = []
done = False
state = env.reset(seed=random.randint(0,500))
img = env.render(mode='rgb_array')
images.append(img)
while not done:
# Take the action (index) that have the maximum expected future reward given that state
action = np.argmax(Qtable[state][:])
state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
img = env.render(mode='rgb_array')
images.append(img)
imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)Se você estiver em um notebook Jupyter, poderá exibir o Gif usando a função Image do `IPython.display`.
video_path="/content/replay.gif"
video_fps=1
record_video(env, Qtable_frozenlake, video_path, video_fps)
from IPython.display import Image
Image('./replay.gif')Agora você pode compartilhar esses resultados com seus colegas e companheiros de classe ou publicá-los nas mídias sociais.
Cursos de aprendizado de máquina
Curso
Tutorial
Avinash Navlani
Tutorial
Kevin Babitz
Tutorial
Moez Ali
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
Satyabrata Pal

