
Kursus
Pengantar Deep Learning dengan Python
4 Hr
264K
Ada beberapa alasan mengapa CNN penting di dunia modern, seperti disorot di bawah ini:
Convolutional neural networks terinspirasi oleh arsitektur berlapis korteks visual manusia, dan berikut beberapa kesamaan serta perbedaannya:
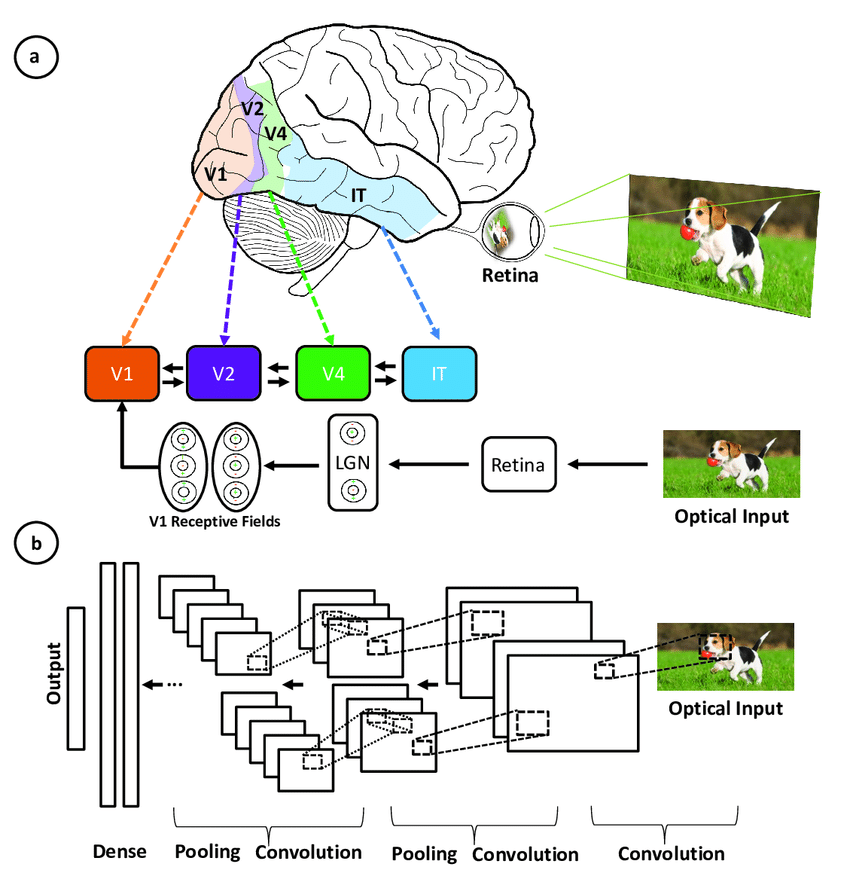
Ilustrasi kesesuaian antara area yang terkait dengan korteks visual primer dan layer dalam convolutional neural network (sumber)
CNN meniru sistem visual manusia namun lebih sederhana, tidak memiliki mekanisme umpan balik kompleks dan bergantung pada pembelajaran terawasi alih-alih tanpa pengawasan, tetap mendorong kemajuan visi komputer meski ada perbedaan ini.
Convolutional neural network terdiri dari empat bagian utama.
Lalu bagaimana CNN belajar dengan bagian-bagian tersebut?
Bagian-bagian ini membantu CNN meniru cara kerja otak manusia dalam mengenali pola dan fitur pada gambar:
Bagian ini membahas definisi masing-masing komponen melalui contoh klasifikasi digit tulisan tangan berikut.
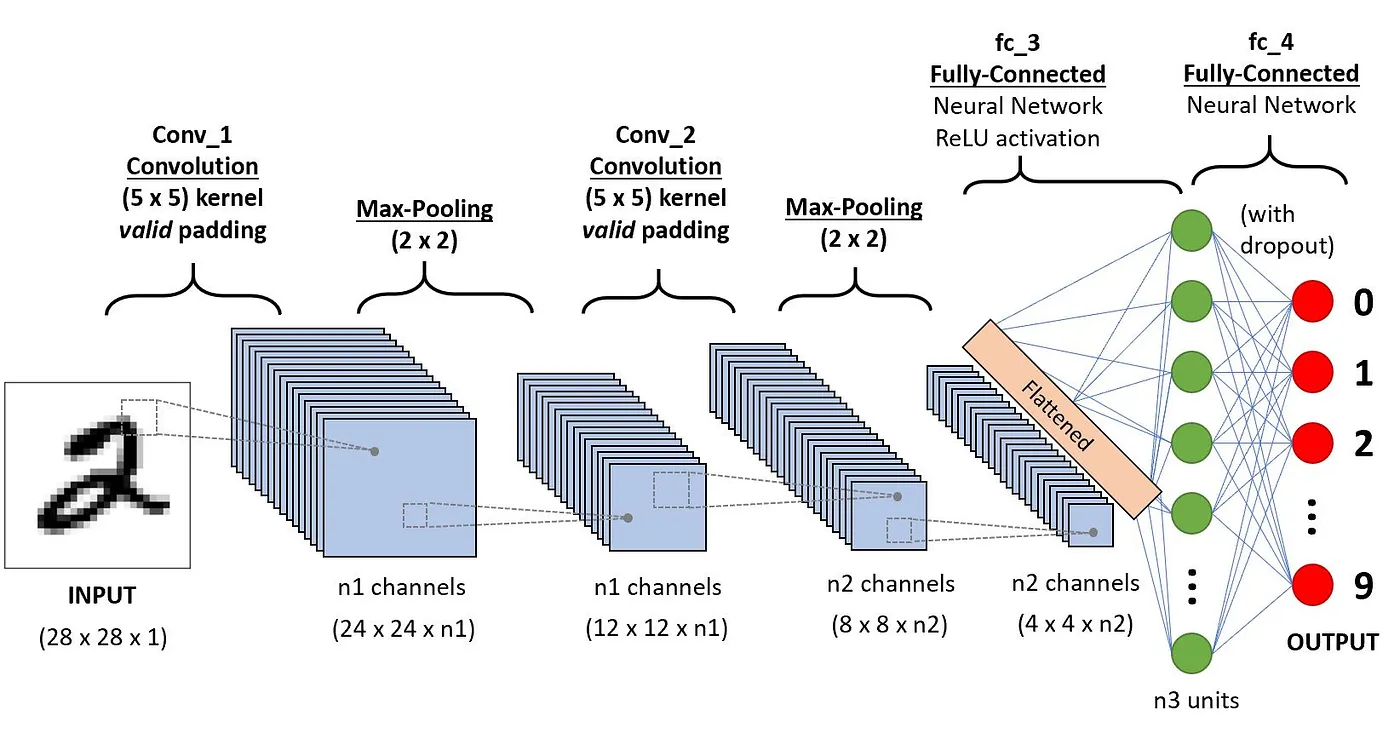
Arsitektur CNN yang diterapkan pada pengenalan digit (sumber)
Ini adalah blok bangunan pertama dari CNN. Sesuai namanya, tugas matematis utama yang dilakukan disebut konvolusi, yaitu penerapan fungsi jendela geser pada matriks piksel yang merepresentasikan sebuah gambar. Fungsi geser yang diterapkan pada matriks disebut kernel atau filter, dan keduanya dapat digunakan secara bergantian.
Dalam convolution layer, beberapa filter berukuran sama diterapkan, dan setiap filter digunakan untuk mengenali pola tertentu dari gambar, seperti lengkungan digit, tepi, bentuk keseluruhan digit, dan lainnya.
Sederhananya, di convolution layer, kita menggunakan kisi-kisi kecil (disebut filter atau kernel) yang bergerak di atas gambar. Setiap kisi kecil seperti kaca pembesar mini yang mencari pola tertentu pada foto, seperti garis, kurva, atau bentuk. Saat bergerak melintasi foto, ia membuat kisi baru yang menyoroti tempat ditemukannya pola-pola tersebut.
Misalnya, satu filter mungkin bagus dalam menemukan garis lurus, lainnya menemukan kurva, dan seterusnya. Dengan menggunakan beberapa filter berbeda, CNN dapat memperoleh gambaran yang baik tentang berbagai pola yang membentuk gambar.
Mari kita pertimbangkan gambar skala abu-abu 32x32 dari sebuah digit tulisan tangan. Nilai dalam matriks diberikan untuk tujuan ilustrasi.
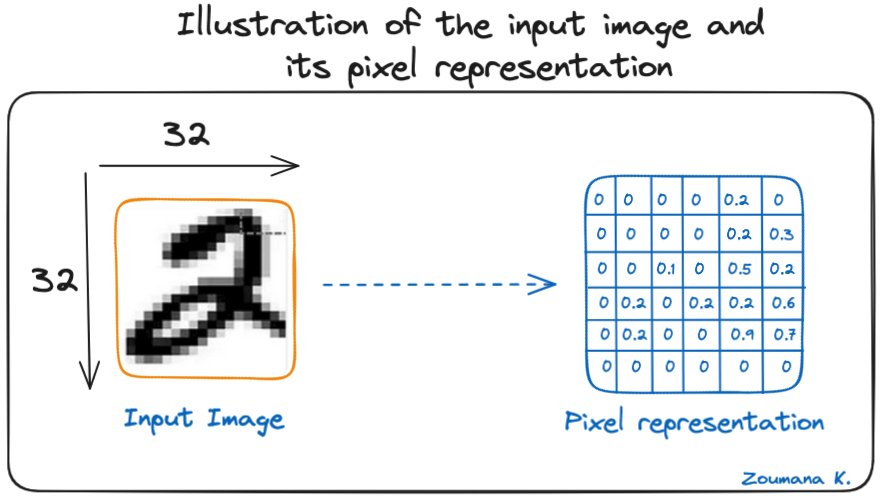
Ilustrasi gambar input dan representasi pikselnya
Selain itu, mari kita pertimbangkan kernel yang digunakan untuk konvolusi. Ini adalah matriks berdimensi 3x3. Bobot setiap elemen kernel direpresentasikan dalam kisi. Bobot nol direpresentasikan pada kisi berwarna hitam dan bobot satu pada kisi berwarna putih.
Apakah kita harus menemukan bobot ini secara manual?
Dalam praktik, bobot kernel ditentukan selama proses pelatihan jaringan saraf.
Dengan menggunakan dua matriks ini, kita dapat melakukan operasi konvolusi dengan menerapkan dot product, dan bekerja sebagai berikut:
Dimensi matriks hasil konvolusi bergantung pada ukuran jendela geser. Semakin besar jendela geser, semakin kecil dimensinya.
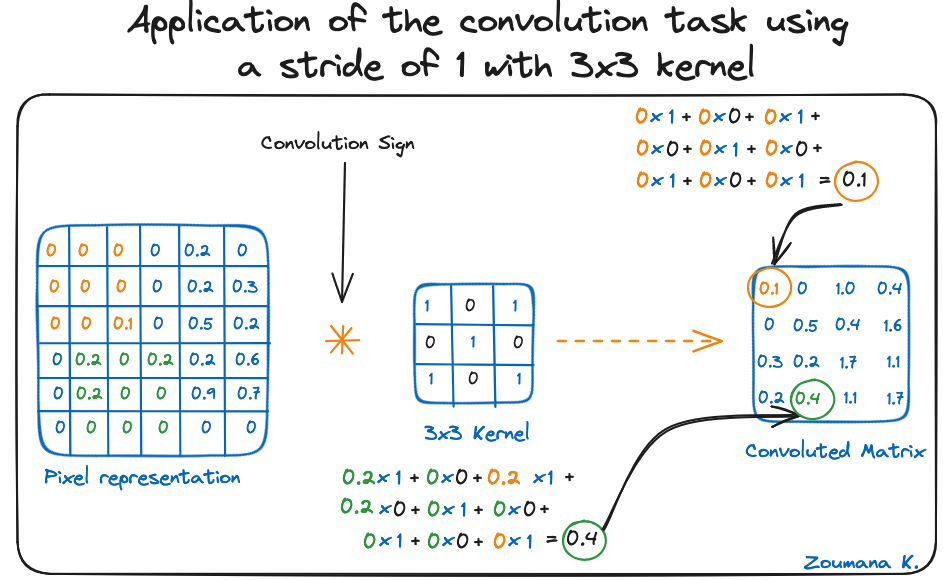
Penerapan tugas konvolusi dengan stride 1 menggunakan kernel 3x3
Nama lain yang terkait dengan kernel dalam literatur adalah feature detector karena bobotnya dapat di-fine-tune untuk mendeteksi fitur tertentu pada gambar input.
Sebagai contoh:
Semakin banyak convolution layer yang dimiliki jaringan, semakin baik layer tersebut dalam mendeteksi fitur yang lebih abstrak.
Sebuah fungsi aktivasi ReLU diterapkan setelah setiap operasi konvolusi. Fungsi ini membantu jaringan mempelajari hubungan non-linear antar fitur pada gambar, sehingga membuat jaringan lebih andal dalam mengenali berbagai pola. Fungsi ini juga membantu mengurangi masalah vanishing gradient.
Tujuan pooling layer adalah mengambil fitur paling signifikan dari matriks hasil konvolusi. Ini dilakukan dengan menerapkan beberapa operasi agregasi, yang mengurangi dimensi peta fitur (matriks hasil konvolusi), sehingga mengurangi memori yang digunakan saat melatih jaringan. Pooling juga relevan untuk mengurangi overfitting.
Fungsi agregasi yang paling umum diterapkan adalah:
Di bawah ini ilustrasi dari masing-masing contoh sebelumnya:
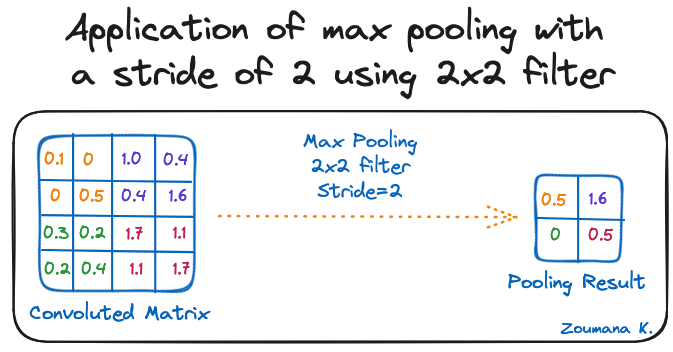
Penerapan max pooling dengan stride 2 menggunakan filter 2x2
Selain itu, dimensi peta fitur menjadi lebih kecil saat fungsi pooling diterapkan.
Pooling layer terakhir meratakan peta fiturnya agar dapat diproses oleh fully connected layer.
Layer-layer ini berada pada bagian akhir convolutional neural network, dan inputnya berupa matriks satu dimensi yang telah diratakan yang dihasilkan oleh pooling layer terakhir. Fungsi aktivasi ReLU diterapkan untuk memberi sifat non-linear.
Terakhir, softmax prediction layer digunakan untuk menghasilkan nilai probabilitas bagi setiap label keluaran yang mungkin, dan label akhir yang diprediksi adalah yang memiliki skor probabilitas tertinggi.
Overfitting adalah tantangan umum dalam model machine learning dan proyek deep learning berbasis CNN. Ini terjadi ketika model mempelajari data pelatihan terlalu baik (“menghafal”), termasuk noise dan outlier-nya. Pembelajaran seperti ini menghasilkan model yang berkinerja baik pada data pelatihan namun buruk pada data baru yang belum pernah dilihat.
Hal ini dapat diamati ketika model mencapai akurasi yang jauh lebih tinggi pada data pelatihan dibandingkan data validasi atau pengujian, dan ilustrasi grafisnya diberikan di bawah:
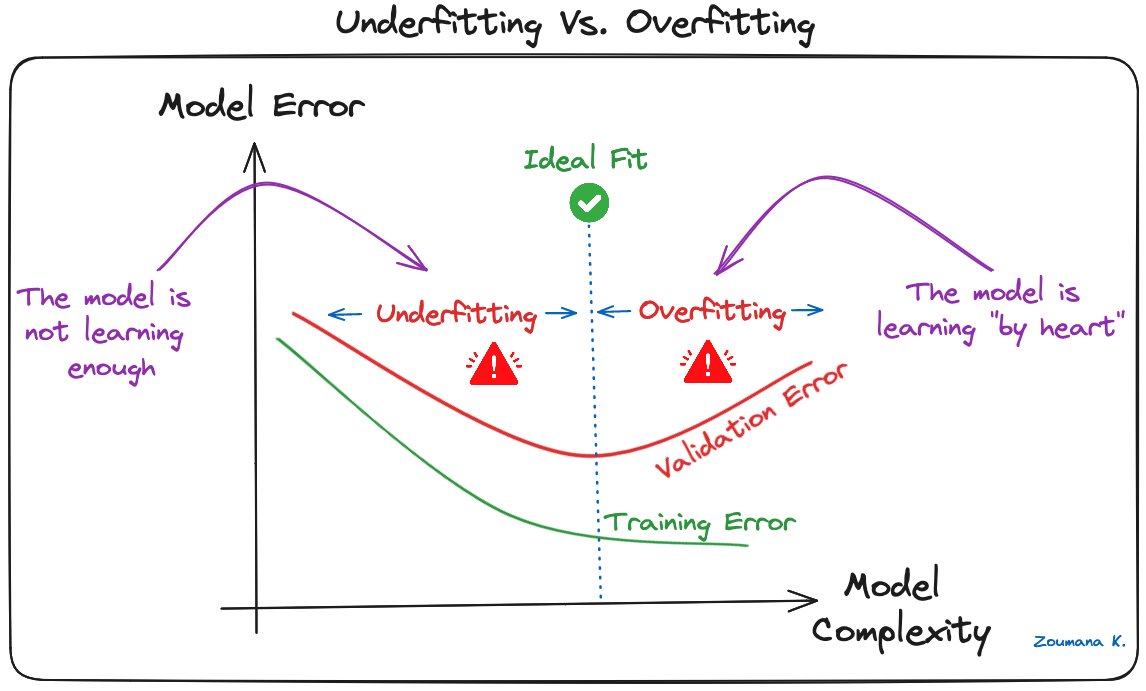
Underfitting vs. Overfitting
Model deep learning, terutama Convolutional Neural Networks (CNN), sangat rentan terhadap overfitting karena kapasitasnya yang tinggi untuk kompleksitas dan kemampuannya mempelajari pola terperinci pada data berskala besar.
Beberapa teknik regularisasi dapat diterapkan untuk mengurangi overfitting pada CNN, dan beberapa diilustrasikan di bawah:
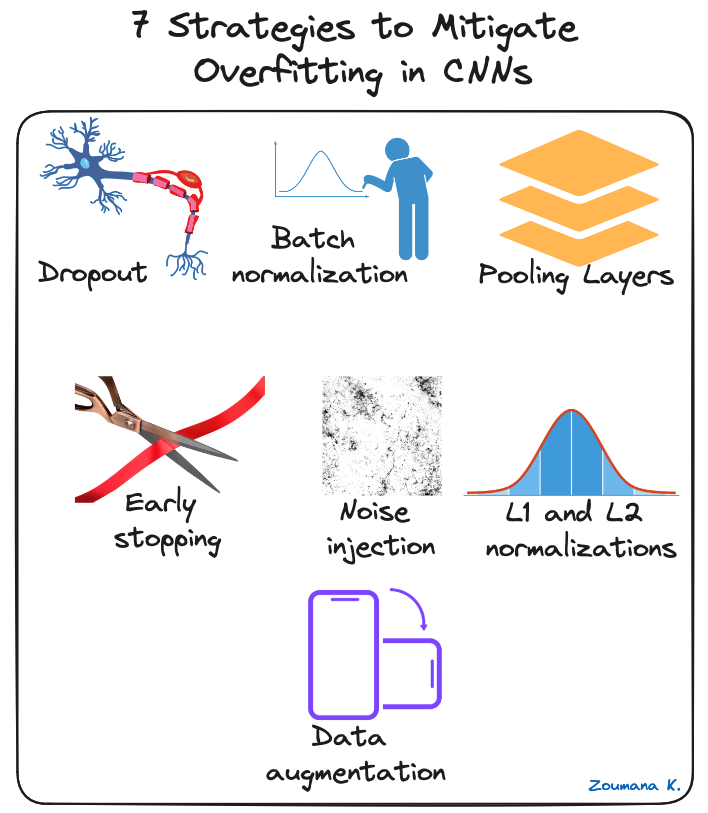
7 strategi untuk mengurangi overfitting pada CNN
Convolutional Neural Networks merevolusi bidang visi komputer, memicu kemajuan signifikan pada banyak aplikasi dunia nyata. Berikut beberapa contohnya.
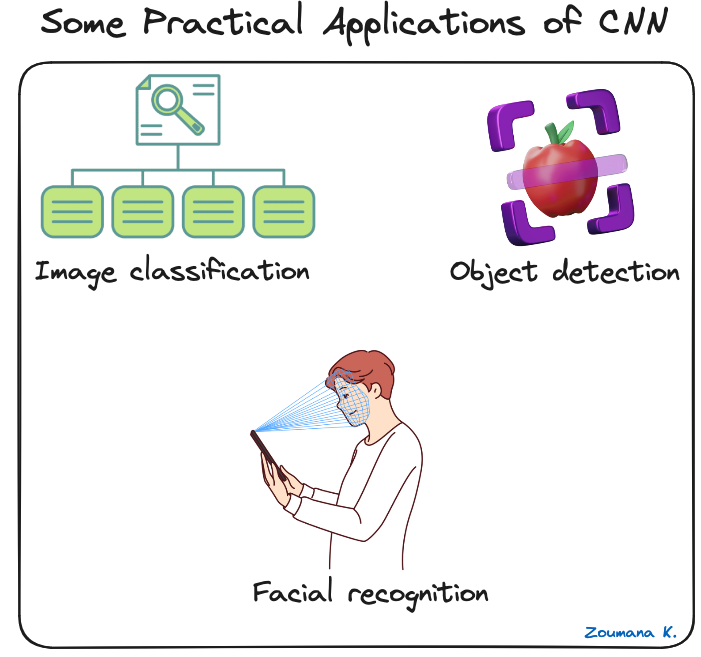
Beberapa aplikasi praktis CNN
Untuk implementasi yang lebih praktis, tutorial kami Convolutional Neural Networks (CNN) with TensorFlow mengajarkan cara membangun dan mengimplementasikan CNN di Python dengan TensorFlow 2.
Selama bertahun-tahun, peneliti telah mengembangkan arsitektur CNN yang semakin kuat. Berikut beberapa yang paling berpengaruh:
Walaupun Vision Transformer (ViT) muncul sebagai alternatif kuat sejak 2020, CNN tetap banyak digunakan karena efisien, membutuhkan data lebih sedikit, dan matang di lingkungan produksi.
Pertumbuhan pesat deep learning terutama disebabkan oleh kerangka kerja andal seperti TensorFlow, PyTorch, dan Keras, yang memudahkan pelatihan convolutional neural networks dan model deep learning lainnya.
Mari kita tinjau singkat masing-masing kerangka kerja.
TensorFlow adalah kerangka kerja deep learning open-source yang dikembangkan oleh Google dan dirilis pada 2015. Kerangka ini menawarkan beragam alat untuk pengembangan dan penerapan machine learning. Introduction to Deep Neural Networks kami menyediakan panduan lengkap untuk memahami jaringan saraf dalam dan signifikansinya di dunia kecerdasan buatan berbasis deep learning modern, beserta implementasi nyata di TensorFlow.
Keras adalah kerangka jaringan saraf tingkat tinggi di Python yang memungkinkan eksperimen dan pengembangan cepat. Keras bersifat open-source dan menjadi API tingkat tinggi resmi TensorFlow (sejak versi 2.0), yang merampingkan pengembangan model dalam ekosistem TensorFlow. Kursus kami, Image Processing with Keras in Python, mengajarkan cara melakukan analisis gambar menggunakan Keras dengan Python melalui pembuatan, pelatihan, dan evaluasi convolutional neural networks.
Dirilis oleh Meta (sebelumnya Facebook) AI Research pada 2017, PyTorch adalah kerangka deep learning serbaguna yang dikenal dengan computational graph dinamis, sintaks Pythonic, dan komunitas riset yang kuat. Jika Anda tertarik memulai pemrosesan bahasa alami, NLP with PyTorch: A Comprehensive Guide kami adalah titik awal yang bagus.
Setiap proyek berbeda, jadi keputusan sangat bergantung pada karakteristik apa yang paling penting untuk kasus penggunaan tertentu. Untuk membantu pengambilan keputusan, tabel berikut memberikan perbandingan singkat ketiga kerangka kerja ini, menyoroti fitur uniknya.
Tensorflow | Pytorch | Keras | |
Tingkat API | Keduanya (Tinggi dan Rendah) | Rendah | Tinggi |
Arsitektur | Tidak mudah digunakan | Sintaks Pythonic, intuitif | Sederhana, ringkas, mudah dibaca |
Dataset | Dataset besar, performa tinggi | Dataset besar, performa tinggi | Dataset lebih kecil |
Debugging | Sulit melakukan debugging | Kemampuan debugging yang baik | Jaringan sederhana, sehingga debugging jarang diperlukan |
Model pra-latih? | Ya | Ya | Ya |
Popularitas | Paling populer kedua dari ketiganya | Paling banyak digunakan untuk riset dan semakin untuk produksi | Terintegrasi ke TensorFlow sebagai API tingkat tinggi resminya |
Kecepatan | Cepat, performa tinggi | Cepat, performa tinggi | Sama seperti TensorFlow (berjalan di backend TF) |
Ditulis dalam | C++, CUDA, Python | C++, Python | Python |
Tabel perbandingan antara Tensorflow, Pytorch, dan Keras (sumber)
Artikel ini memberikan gambaran lengkap tentang apa itu CNN dalam deep learning, beserta peran krusialnya dalam tugas pengenalan dan klasifikasi gambar.
Artikel dimulai dengan menyoroti inspirasi dari sistem visual manusia untuk desain CNN lalu mengeksplorasi komponen kunci yang memungkinkan jaringan ini belajar dan membuat prediksi.
Masalah overfitting diakui sebagai tantangan signifikan bagi kemampuan generalisasi CNN. Untuk mengatasinya, diuraikan berbagai strategi relevan untuk mengurangi overfitting dan meningkatkan kinerja CNN secara keseluruhan.
Terakhir, beberapa kerangka kerja CNN deep learning utama disebutkan, beserta fitur unik masing-masing dan bagaimana perbandingannya satu sama lain.
Ingin menyelami lebih jauh dunia AI dan machine learning? Tingkatkan keahlian Anda dengan mendaftar kursus Deep Learning with PyTorch hari ini.
Mulai Perjalanan Deep Learning Anda Hari Ini!
Kursus
Kursus
Kursus
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
