
Corso
Introduzione al Deep Learning in Python
4 h
264K
Ci sono diversi motivi per cui le CNN sono importanti nel mondo moderno, come evidenziato di seguito:
Le reti neurali convoluzionali sono state ispirate dall'architettura a strati della corteccia visiva umana, e di seguito trovi alcune somiglianze e differenze chiave:
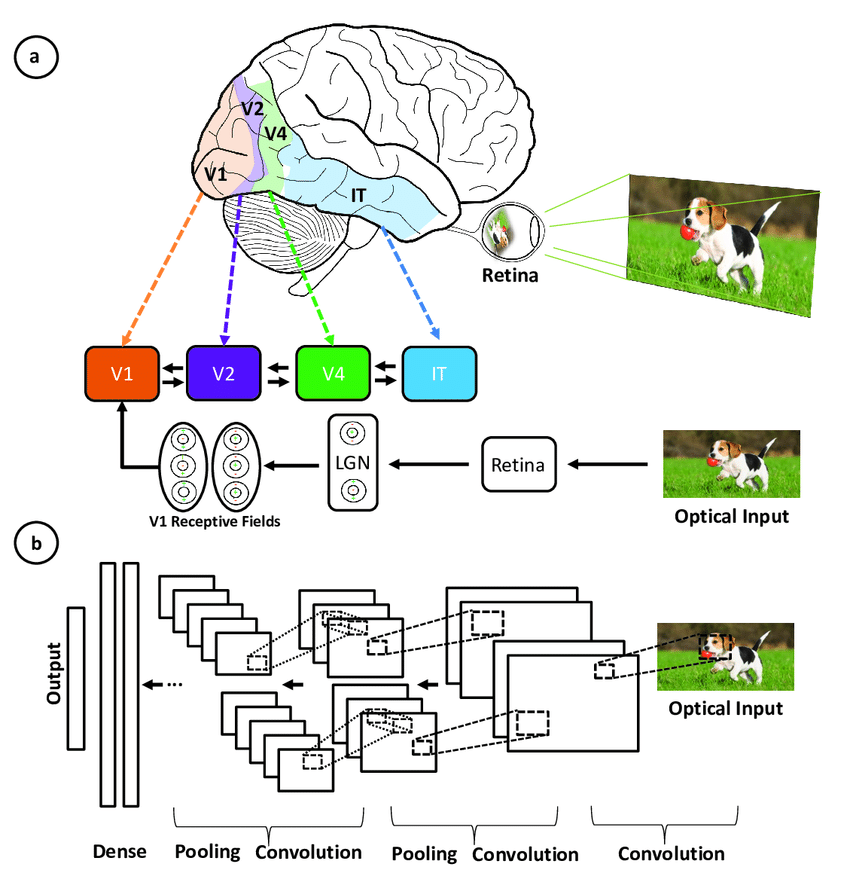
Illustrazione della corrispondenza tra le aree associate alla corteccia visiva primaria e i livelli in una rete neurale convoluzionale (fonte)
Le CNN imitano il sistema visivo umano ma sono più semplici, prive dei suoi complessi meccanismi di feedback e basate sull'apprendimento supervisionato piuttosto che non supervisionato; nonostante queste differenze, hanno guidato i progressi nella computer vision.
La rete neurale convoluzionale è composta da quattro parti principali.
Ma come imparano le CNN con queste parti?
Aiutano le CNN a imitare il funzionamento del cervello umano per riconoscere pattern e caratteristiche nelle immagini:
Questa sezione approfondisce la definizione di ciascuno di questi componenti attraverso il seguente esempio di classificazione di una cifra scritta a mano.
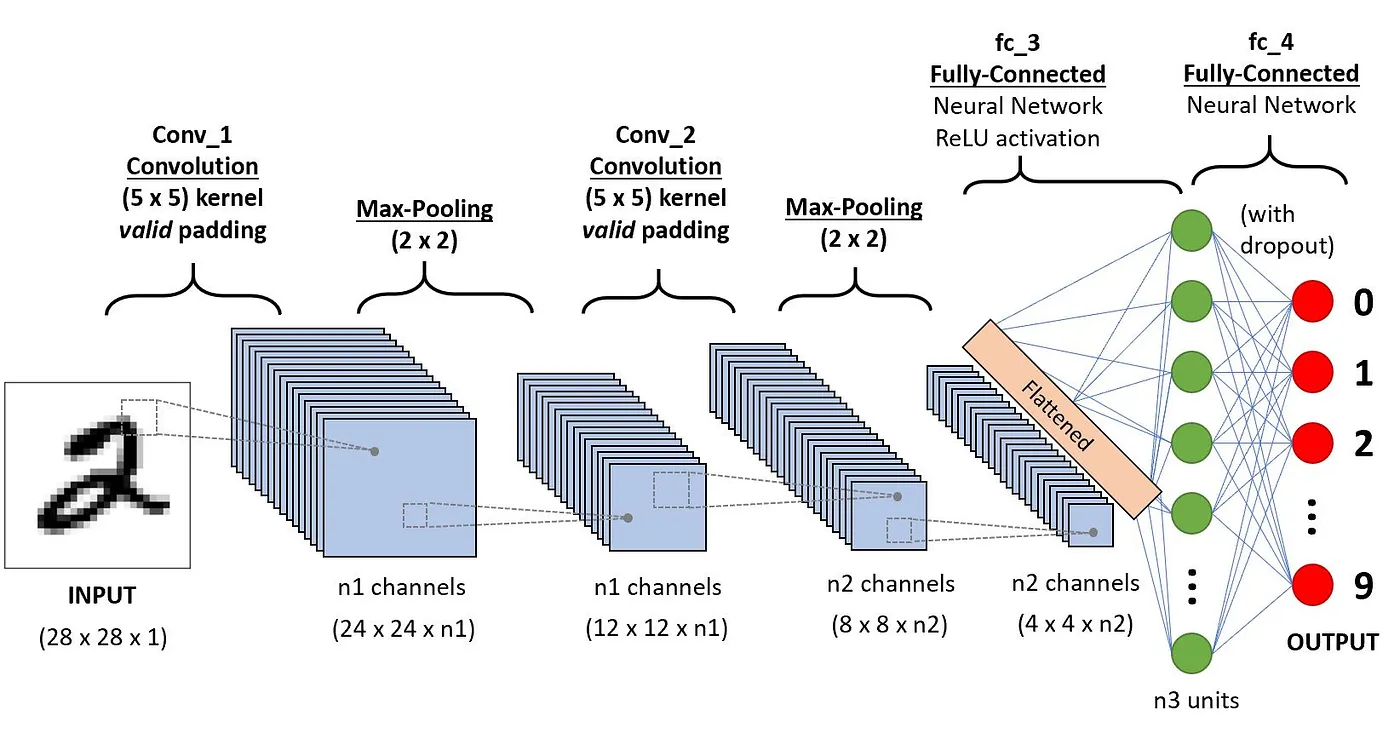
Architettura delle CNN applicata al riconoscimento delle cifre (fonte)
Questo è il primo mattone di una CNN. Come suggerisce il nome, l'operazione matematica principale è la convoluzione, ossia l'applicazione di una funzione a finestra scorrevole a una matrice di pixel che rappresenta un'immagine. La funzione scorrevole applicata alla matrice è chiamata kernel o filtro, e i due termini sono intercambiabili.
Nel livello di convoluzione si applicano diversi filtri di uguale dimensione, e ciascun filtro viene usato per riconoscere uno specifico pattern dall'immagine, come la curvatura delle cifre, i bordi, l'intera forma delle cifre e altro.
In parole semplici, nel livello di convoluzione usiamo piccole griglie (chiamate filtri o kernel) che scorrono sull'immagine. Ogni piccola griglia è come una mini lente d'ingrandimento che cerca pattern specifici nella foto, come linee, curve o forme. Mentre si muove sulla foto, crea una nuova griglia che evidenzia dove ha trovato questi pattern.
Per esempio, un filtro potrebbe essere bravo a trovare linee rette, un altro a trovare curve e così via. Usando più filtri diversi, la CNN può farsi un'idea completa di tutti i diversi pattern che compongono l'immagine.
Consideriamo questa immagine in scala di grigi 32x32 di una cifra scritta a mano. I valori nella matrice sono forniti a scopo illustrativo.
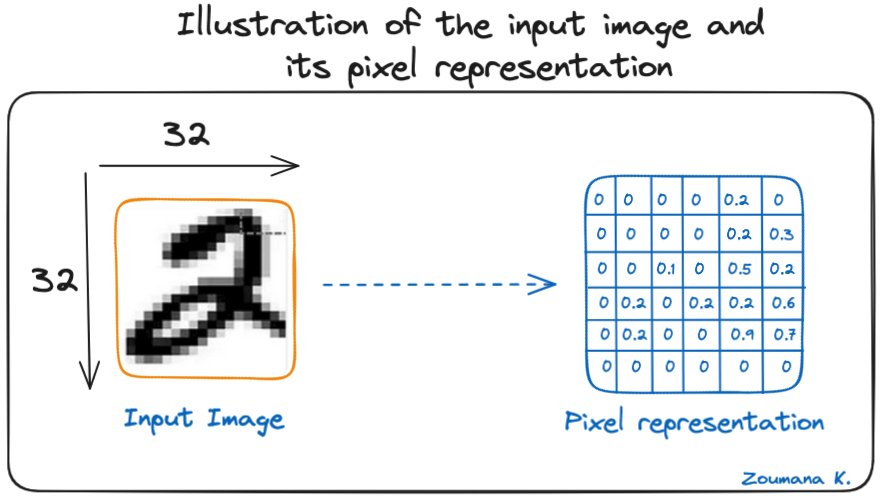
Illustrazione dell'immagine di input e della sua rappresentazione in pixel
Consideriamo anche il kernel usato per la convoluzione. È una matrice con dimensione 3x3. I pesi di ciascun elemento del kernel sono rappresentati nella griglia. I pesi zero sono rappresentati nelle celle nere e gli uno nella cella bianca.
Dobbiamo trovare manualmente questi pesi?
Nella pratica, i pesi dei kernel vengono determinati durante il processo di addestramento della rete neurale.
Usando queste due matrici, possiamo eseguire l'operazione di convoluzione applicando il prodotto scalare e procedendo come segue:
La dimensione della matrice convoluta dipende dalla dimensione della finestra scorrevole. Più grande è la finestra, più piccola è la dimensione risultante.
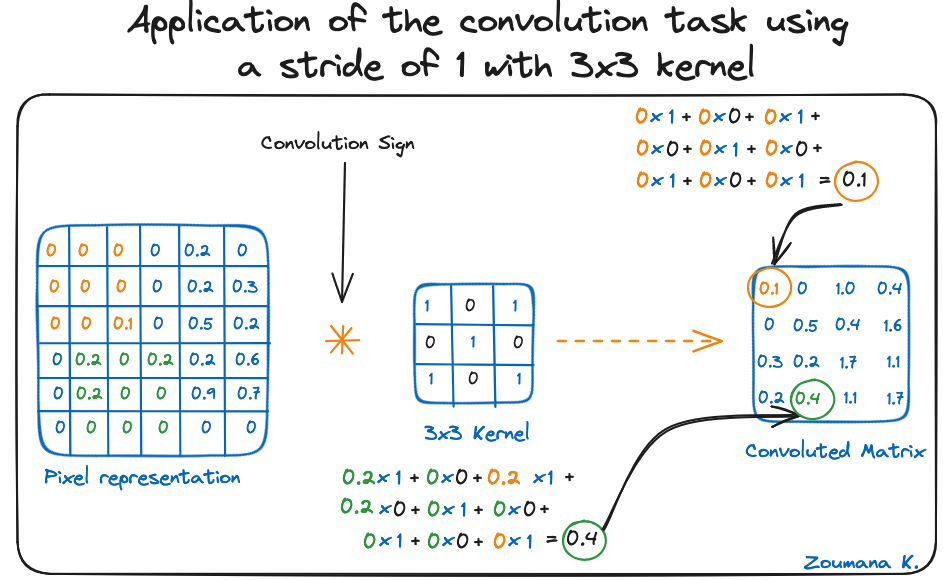
Applicazione della convoluzione con stride 1 e kernel 3x3
Un altro nome associato al kernel in letteratura è feature detector, perché i pesi possono essere ottimizzati per rilevare caratteristiche specifiche nell'immagine di input.
Per esempio:
Più livelli di convoluzione ha la rete, meglio gli strati più profondi riescono a rilevare caratteristiche più astratte.
Dopo ogni operazione di convoluzione si applica una funzione di attivazione ReLU. Questa funzione aiuta la rete a imparare relazioni non lineari tra le caratteristiche nell'immagine, rendendo quindi la rete più robusta nel riconoscere pattern diversi. Inoltre, aiuta a mitigare il problema del vanishing gradient.
L'obiettivo del livello di pooling è estrarre le caratteristiche più significative dalla matrice convoluta. Questo avviene applicando operazioni di aggregazione che riducono la dimensione della feature map (matrice convoluta), riducendo così la memoria utilizzata durante l'addestramento della rete. Il pooling è rilevante anche per mitigare l'overfitting.
Le funzioni di aggregazione più comuni sono:
Di seguito un'illustrazione di ciascuno dei precedenti esempi:
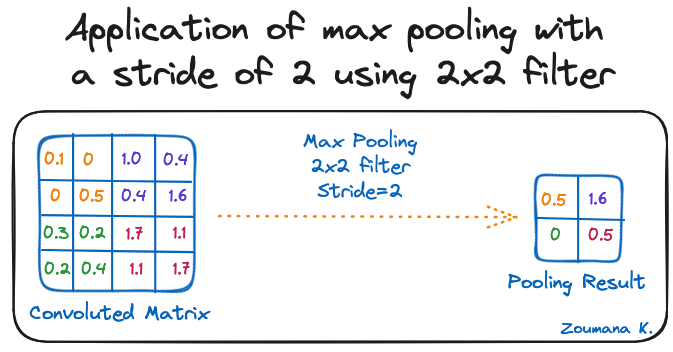
Applicazione del max pooling con stride 2 usando un filtro 2x2
Anche la dimensione della feature map diventa più piccola man mano che si applica la funzione di pooling.
L'ultimo livello di pooling appiattisce la sua feature map in modo che possa essere elaborata dal livello completamente connesso.
Questi livelli si trovano nella parte finale della rete neurale convoluzionale, e i loro input corrispondono alla matrice monodimensionale appiattita generata dall'ultimo livello di pooling. Su di essi si applicano funzioni di attivazione ReLU per introdurre non linearità.
Infine, si usa un livello di predizione softmax per generare valori di probabilità per ciascuna delle possibili etichette di output, e l'etichetta finale prevista è quella con il punteggio di probabilità più alto.
L'overfitting è una sfida comune nei modelli di machine learning e nei progetti di deep learning con CNN. Accade quando il modello impara troppo bene i dati di addestramento ("imparare a memoria"), inclusi rumore e outlier. Un apprendimento del genere porta a un modello che va bene sui dati di training ma male su nuovi dati non visti.
Questo si osserva quando il modello raggiunge un'accuratezza significativamente più alta sui dati di addestramento rispetto ai dati di validazione o test, come illustrato graficamente di seguito:
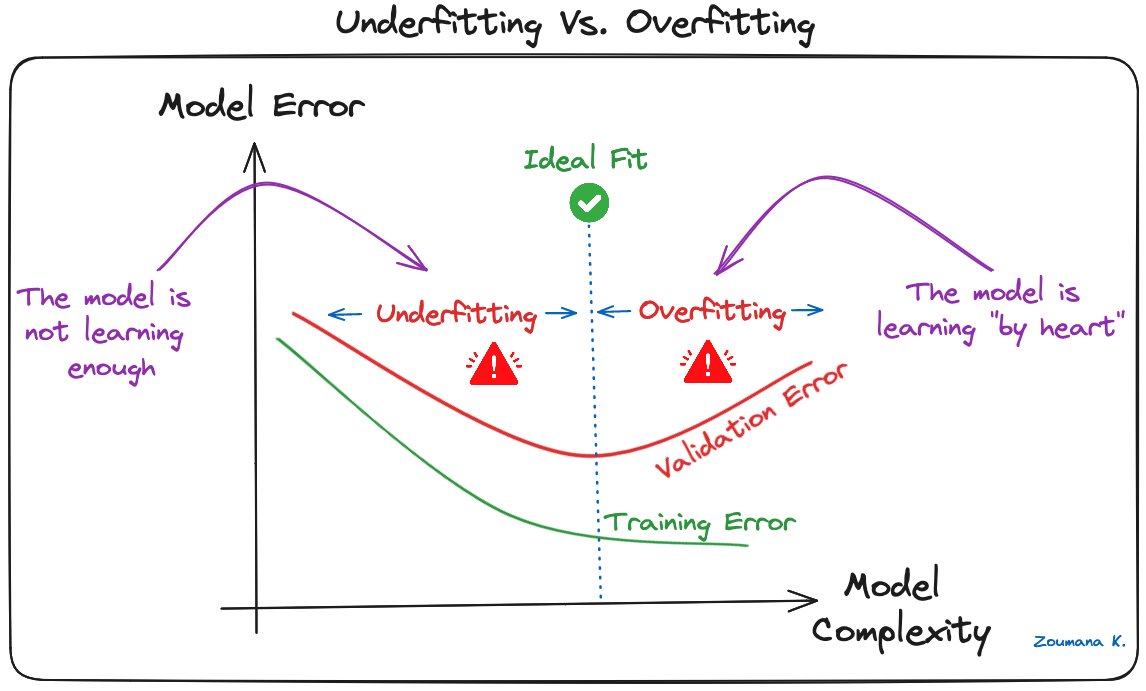
Underfitting vs. Overfitting
I modelli di deep learning, in particolare le Convolutional Neural Networks (CNN), sono particolarmente suscettibili all'overfitting a causa della loro elevata complessità e della capacità di apprendere pattern dettagliati in dati su larga scala.
Si possono applicare diverse tecniche di regolarizzazione per mitigare l'overfitting nelle CNN, alcune delle quali sono illustrate di seguito:
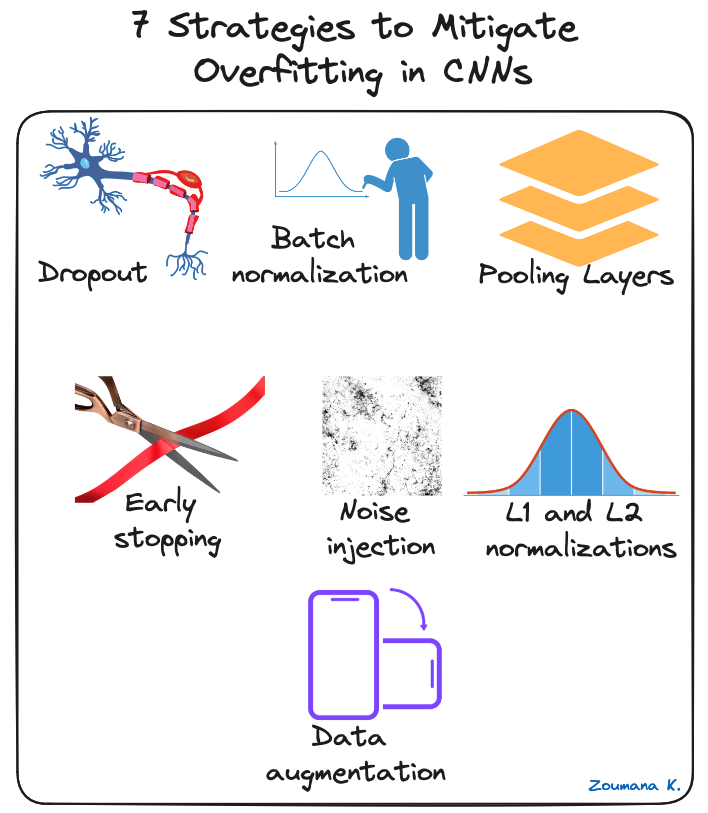
7 strategie per mitigare l'overfitting nelle CNN
Le reti neurali convoluzionali hanno rivoluzionato il campo della computer vision, portando a notevoli progressi in molte applicazioni reali. Ecco alcuni esempi di come vengono applicate.
Alcune applicazioni pratiche delle CNN
Per un'implementazione più pratica, il nostro tutorial Convolutional Neural Networks (CNN) with TensorFlow insegna come costruire e implementare CNN in Python con TensorFlow 2.
Negli anni, i ricercatori hanno sviluppato architetture CNN sempre più potenti. Ecco alcune tra le più influenti:
Sebbene i Vision Transformer (ViT) siano emersi come valide alternative dal 2020, le CNN restano ampiamente utilizzate grazie all'efficienza, al minor fabbisogno di dati e alla maturità negli ambienti di produzione.
La rapida crescita del deep learning è dovuta principalmente a potenti framework come TensorFlow, PyTorch e Keras, che semplificano l'addestramento di reti neurali convoluzionali e altri modelli di deep learning.
Diamo una breve panoramica di ciascun framework.
TensorFlow è un framework open-source per il deep learning sviluppato da Google e rilasciato nel 2015. Offre una gamma di strumenti per lo sviluppo e la distribuzione di soluzioni di machine learning. La nostra Introduction to Deep Neural Networks fornisce una guida completa per comprendere le reti neurali profonde e la loro importanza nel moderno mondo del deep learning nell'intelligenza artificiale, con implementazioni reali in TensorFlow.
Keras è un framework di alto livello per reti neurali in Python che consente sperimentazione e sviluppo rapidi. È open-source e funge da API ufficiale di alto livello di TensorFlow (dalla versione 2.0), semplificando lo sviluppo di modelli nell'ecosistema TensorFlow. Il nostro corso Image Processing with Keras in Python insegna come svolgere analisi di immagini con Keras in Python costruendo, addestrando e valutando reti neurali convoluzionali.
Rilasciato dal team Meta (ex Facebook) AI Research nel 2017, PyTorch è un framework di deep learning general-purpose noto per il grafo computazionale dinamico, la sintassi Pythonic e la forte comunità di ricerca. Se vuoi approfondire l'elaborazione del linguaggio naturale, la nostra guida NLP with PyTorch: A Comprehensive Guide è un ottimo punto di partenza.
Ogni progetto è diverso, quindi la scelta dipende davvero da quali caratteristiche sono più importanti per il caso d'uso. Per aiutarti a decidere meglio, la seguente tabella offre un breve confronto tra questi framework, evidenziandone le caratteristiche uniche.
Tensorflow | Pytorch | Keras | |
Livello API | Entrambi (Alto e Basso) | Basso | Alto |
Architettura | Non facile da usare | Sintassi Pythonic, intuitiva | Semplice, concisa, leggibile |
Dataset | Dataset grandi, alte prestazioni | Dataset grandi, alte prestazioni | Dataset più piccoli |
Debug | Debug difficile | Buone capacità di debug | Rete semplice, quindi spesso non serve il debug |
Modelli pre-addestrati? | Sì | Sì | Sì |
Popolarità | Secondo più popolare dei tre | Il più usato nella ricerca e sempre più in produzione | Integrato in TensorFlow come API ufficiale di alto livello |
Velocità | Veloce, alte prestazioni | Veloce, alte prestazioni | Come TensorFlow (gira sul backend TF) |
Scritto in | C++, CUDA, Python | C++, Python | Python |
Tabella comparativa tra Tensorflow, Pytorch e Keras (fonte)
Questo articolo ha fornito una panoramica completa su cosa sia una CNN nel deep learning e il loro ruolo cruciale nei compiti di riconoscimento e classificazione delle immagini.
È iniziato mettendo in evidenza l'ispirazione tratta dal sistema visivo umano per il design delle CNN e poi ha esplorato i componenti chiave che permettono a queste reti di apprendere e fare previsioni.
Il problema dell'overfitting è stato riconosciuto come una sfida significativa alla capacità di generalizzazione delle CNN. Per mitigarla, sono state descritte diverse strategie rilevanti per ridurre l'overfitting e migliorare le prestazioni complessive delle CNN.
Infine, sono stati menzionati alcuni tra i principali framework di deep learning per CNN, insieme alle caratteristiche uniche di ciascuno e a come si confrontano tra loro.
Desideri approfondire ancora il mondo dell'IA e del machine learning? Porta la tua competenza al livello successivo iscrivendoti oggi al corso Deep Learning with PyTorch.
Inizia oggi il tuo percorso nel deep learning!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

