
Cursus
Introductie tot Deep Learning in Python
4 Hr
264K
Er zijn meerdere redenen waarom CNN's belangrijk zijn in de moderne wereld, zoals hieronder uitgelicht:
Convolutionele neurale netwerken zijn geïnspireerd op de gelaagde architectuur van de menselijke visuele cortex. Hieronder staan enkele belangrijke overeenkomsten en verschillen:
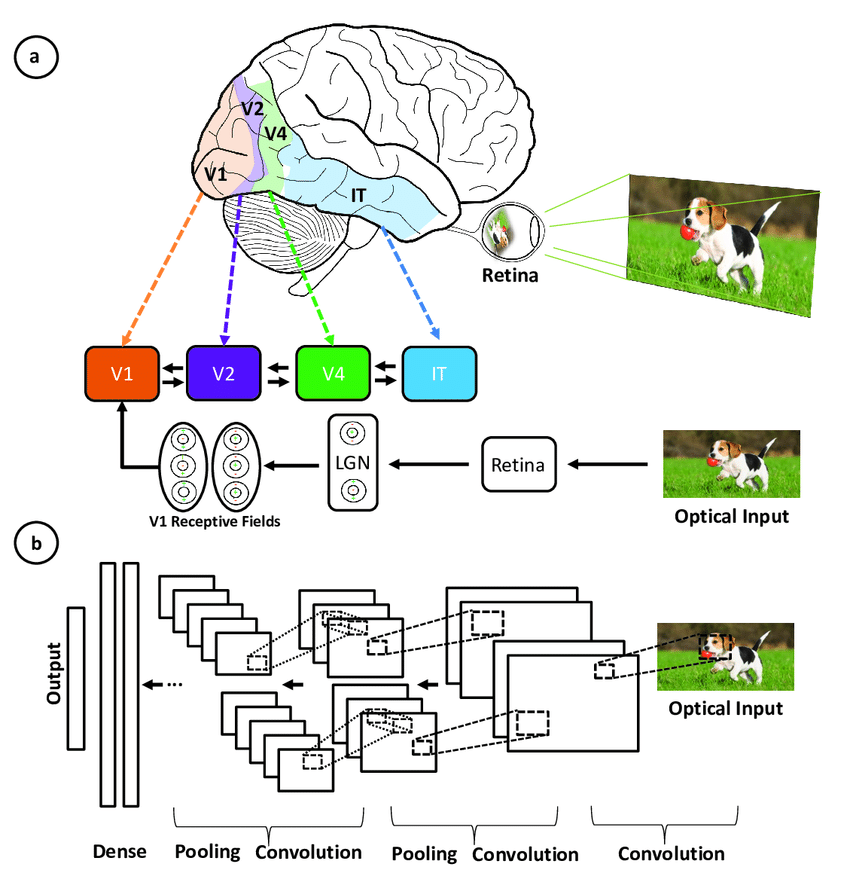
Illustratie van de overeenkomst tussen de gebieden die geassocieerd zijn met de primaire visuele cortex en de lagen in een convolutioneel neuraal netwerk (bron)
CNN's bootsen het menselijke visuele systeem na, maar zijn eenvoudiger: ze missen complexe feedbackmechanismen en steunen op supervised learning in plaats van unsupervised. Ondanks deze verschillen drijven ze de vooruitgang in computervisie.
Het convolutionele neurale netwerk bestaat uit vier hoofdonderdelen.
Maar hoe leren CNN's met die onderdelen?
Ze helpen CNN's na te bootsen hoe het menselijk brein patronen en features in afbeeldingen herkent:
In dit onderdeel gaan we in op de definitie van elk van deze componenten aan de hand van het volgende voorbeeld: het classificeren van een handgeschreven cijfer.
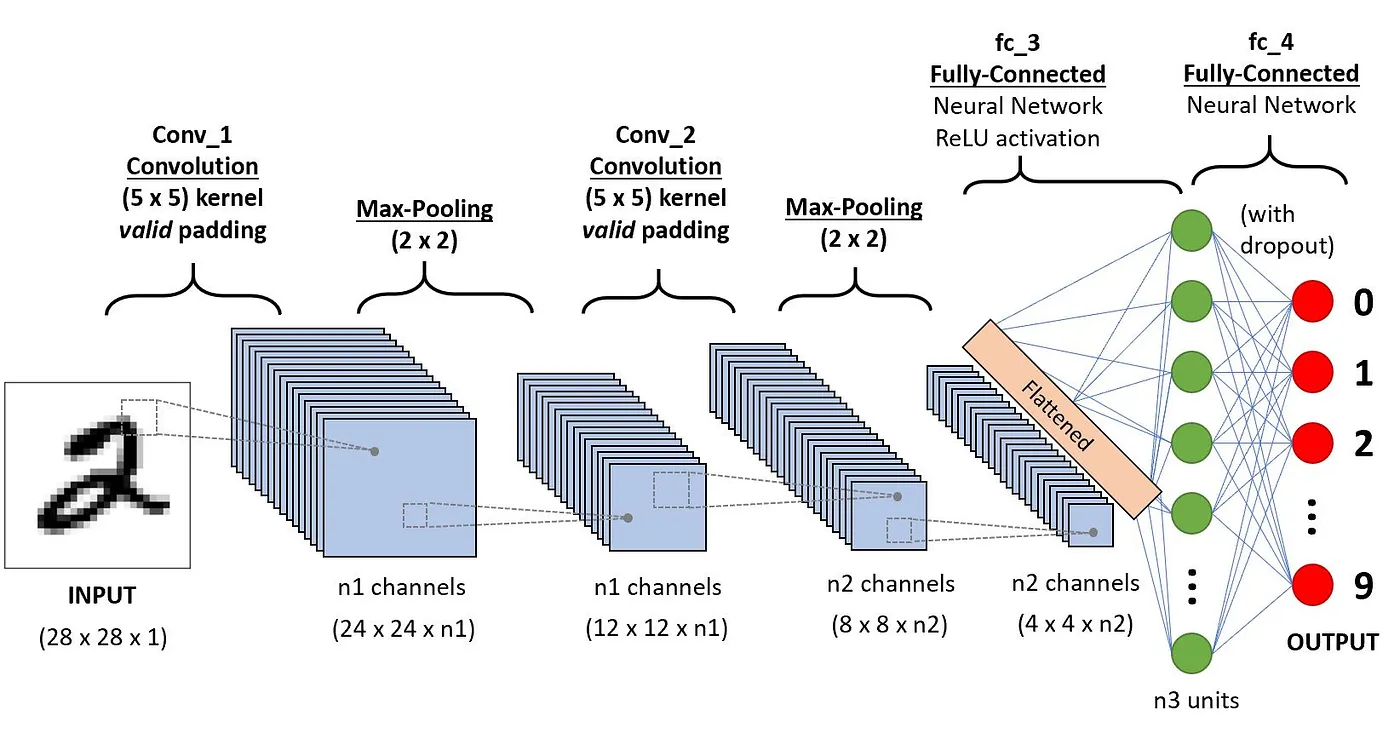
Architectuur van CNN's toegepast op cijferherkenning (bron)
Dit is de eerste bouwsteen van een CNN. Zoals de naam aangeeft, is de belangrijkste wiskundige bewerking convolutie: het toepassen van een schuivend venster op een matrix van pixels die een afbeelding voorstellen. De schuivende functie die op de matrix wordt toegepast heet kernel of filter; beide termen worden door elkaar gebruikt.
In de convolutionele laag worden meerdere filters van gelijke grootte toegepast, en elk filter wordt gebruikt om een specifiek patroon in de afbeelding te herkennen, zoals de kromming van cijfers, de randen, de algehele vorm van de cijfers, enzovoort.
Simpel gezegd gebruiken we in de convolutionele laag kleine roosters (filters of kernels) die over de afbeelding bewegen. Elk klein rooster is als een mini-vergrootglas dat zoekt naar specifieke patronen in de foto, zoals lijnen, bochten of vormen. Terwijl het over de foto schuift, ontstaat een nieuw rooster dat markeert waar deze patronen zijn gevonden.
Zo kan één filter goed zijn in het vinden van rechte lijnen, een ander in het vinden van bochten, enzovoort. Door verschillende filters te gebruiken krijgt de CNN een goed beeld van alle patronen waaruit de afbeelding is opgebouwd.
Laten we deze 32x32-grijswaardenafbeelding van een handgeschreven cijfer bekijken. De waarden in de matrix zijn ter illustratie gegeven.
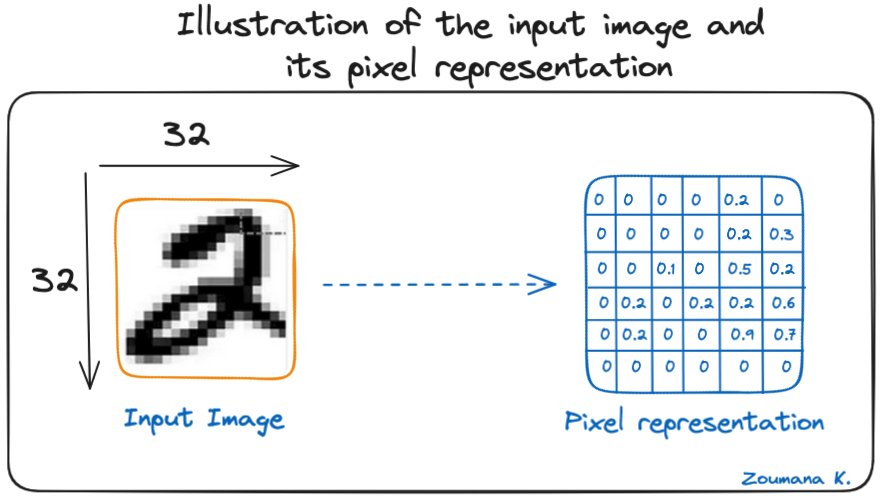
Illustratie van de invoerafbeelding en de pixelrepresentatie
Neem ook de kernel die voor de convolutie wordt gebruikt. Dat is een matrix van 3x3. De gewichten van elk element van de kernel zijn in het rooster weergegeven. Nulgewichten zijn zwart en enen zijn wit weergegeven.
Moeten we deze gewichten handmatig bepalen?
In de praktijk worden de gewichten van de kernels bepaald tijdens het trainingsproces van het neurale netwerk.
Met deze twee matrices kunnen we de convolutie uitvoeren door het inproduct toe te passen. Dat gaat als volgt:
De afmeting van de geconvolueerde matrix hangt af van de grootte van het schuivende venster. Hoe groter het schuivende venster (stride), hoe kleiner de afmeting.
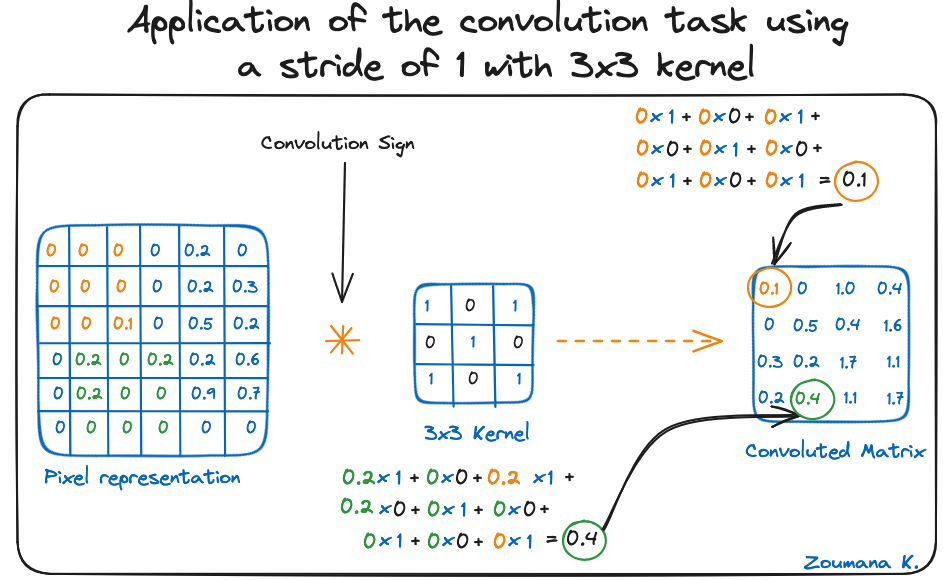
Toepassing van de convolutietaak met een stride van 1 en een 3x3-kernel
Een andere benaming voor de kernel in de literatuur is featuredetector, omdat de gewichten kunnen worden verfijnd om specifieke features in de invoerafbeelding te detecteren.
Bijvoorbeeld:
Hoe meer convolutionele lagen het netwerk heeft, hoe beter de lagen in staat zijn om abstractere features te detecteren.
Na elke convolutie wordt een ReLU-activatiefunctie toegepast. Deze functie helpt het netwerk niet-lineaire relaties tussen de features in de afbeelding te leren, waardoor het robuuster wordt in het herkennen van verschillende patronen. Het helpt ook om problemen met verdwijnende gradiënten te beperken.
Het doel van de pooling-laag is om de belangrijkste features uit de geconvolueerde matrix te halen. Dit gebeurt door aggregatiebewerkingen toe te passen die de afmeting van de feature map (geconvolueerde matrix) verkleinen, waardoor het geheugenverbruik tijdens het trainen afneemt. Pooling helpt ook om overfitting te beperken.
De meest gebruikte aggregatiefuncties zijn:
Hieronder staat een illustratie van elk van de voorgaande voorbeelden:
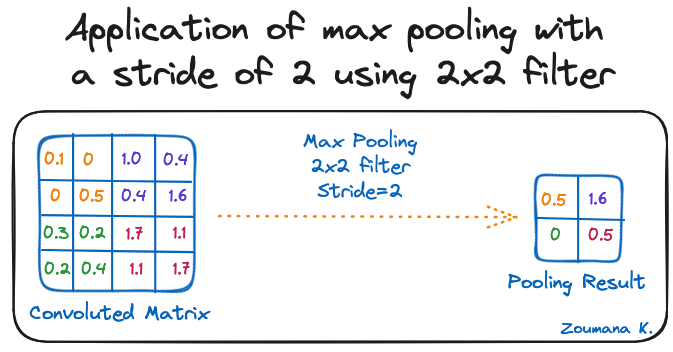
Toepassing van max pooling met een stride van 2 en een 2x2-filter
Ook hier geldt: de afmeting van de feature map wordt kleiner naarmate de pooling-functie wordt toegepast.
De laatste pooling-laag maakt zijn feature map plat (flatten) zodat die door de volledig verbonden laag kan worden verwerkt.
Deze lagen bevinden zich aan het eind van het convolutionele neurale netwerk en hun input komt overeen met de afgevlakte eendimensionale matrix die door de laatste pooling-laag is gegenereerd. ReLU-activatiefuncties worden toegepast voor non-lineariteit.
Tot slot wordt een softmax-voorspellingslaag gebruikt om waarschijnlijkheidswaarden te genereren voor elk van de mogelijke uitvoerlabels. Het uiteindelijke voorspelde label is dat met de hoogste waarschijnlijkheid.
Overfitting is een veelvoorkomende uitdaging in machinelearning-modellen en CNN-deeplearningprojecten. Het treedt op wanneer het model de trainingsdata te goed leert ("uit het hoofd leren"), inclusief de ruis en uitschieters. Zo'n leergedrag leidt tot een model dat goed presteert op de trainingsdata maar slecht op nieuwe, ongeziene data.
Dit zie je wanneer het model significant hogere nauwkeurigheid behaalt op trainingsdata vergeleken met validatie- of testdata. Hieronder staat een grafische illustratie:
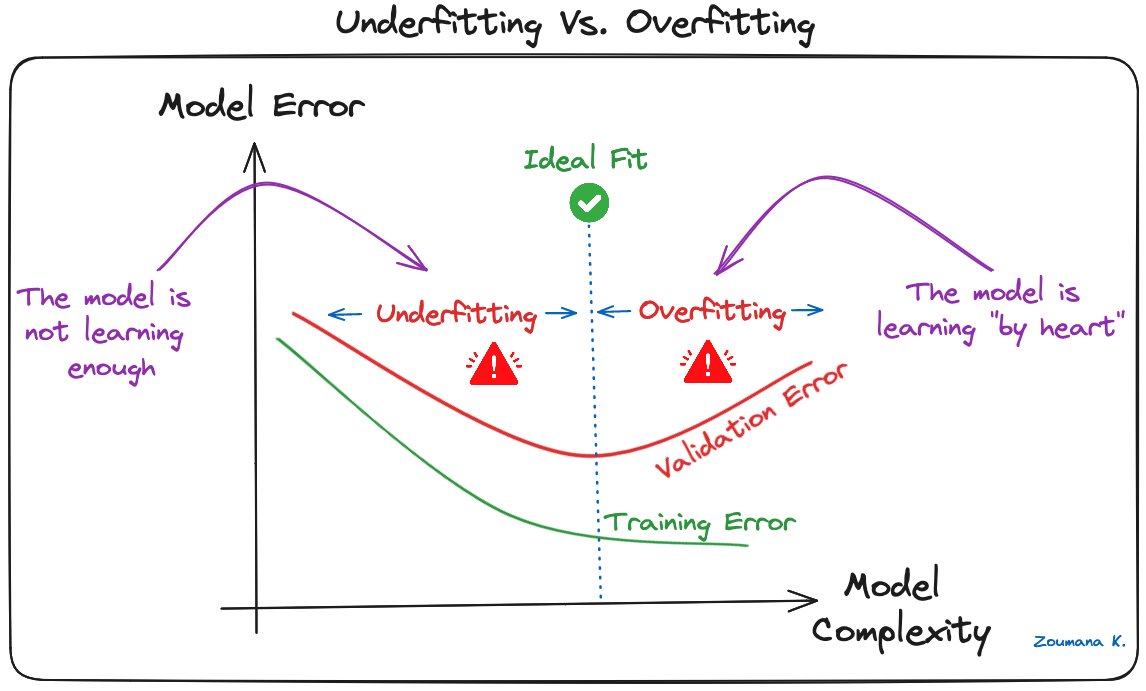
Underfitting versus overfitting
Deep-learningmodellen, vooral convolutionele neurale netwerken (CNN's), zijn bijzonder vatbaar voor overfitting vanwege hun hoge complexiteit en hun vermogen om gedetailleerde patronen in grootschalige data te leren.
Er zijn verschillende regularisatietechnieken om overfitting in CNN's te beperken, waarvan er hieronder enkele zijn geïllustreerd:
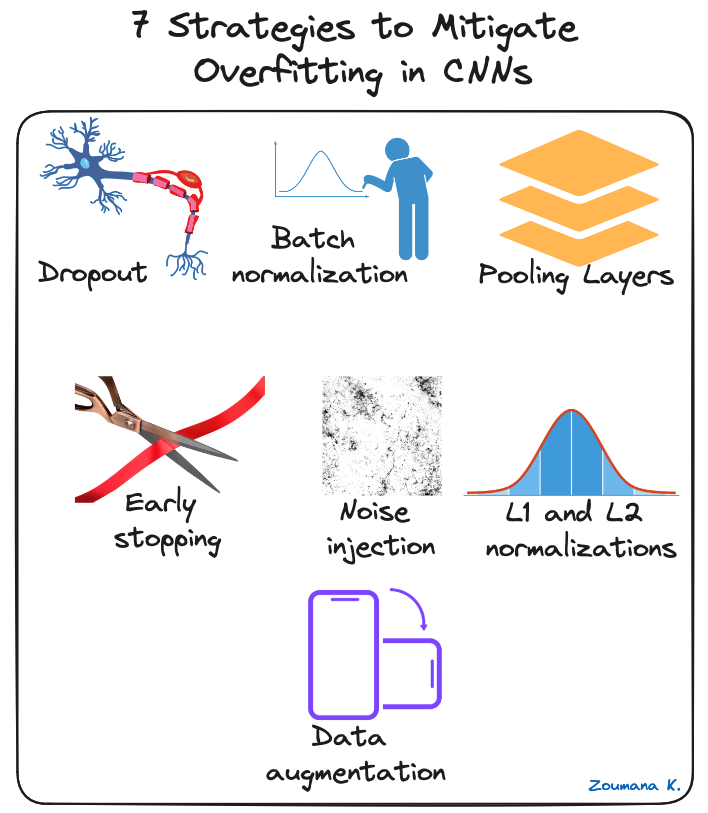
7 strategieën om overfitting in CNN's te beperken
Convolutionele neurale netwerken hebben het vakgebied van computervisie getransformeerd en geleid tot grote vooruitgang in veel echte toepassingen. Hieronder staan enkele voorbeelden van hoe ze worden toegepast.
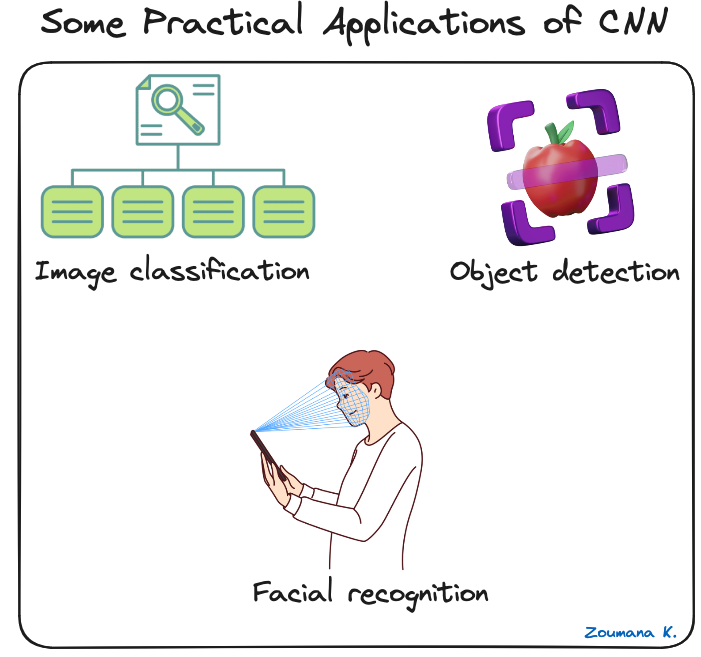
Enkele praktische toepassingen van CNN's
Voor een meer hands-on implementatie leert onze Convolutional Neural Networks (CNN) with TensorFlow Tutorial hoe je CNN's in Python met TensorFlow 2 bouwt en implementeert.
In de loop der jaren hebben onderzoekers steeds krachtigere CNN-architecturen ontwikkeld. Dit zijn enkele van de meest invloedrijke:
Hoewel Vision Transformers (ViT's) sinds 2020 als sterke alternatieven zijn opgekomen, blijven CNN's veel gebruikt vanwege hun efficiëntie, lagere data-eisen en volwassenheid in productieomgevingen.
De snelle groei van deep learning is vooral te danken aan krachtige frameworks zoals TensorFlow, PyTorch en Keras, die het trainen van convolutionele neurale netwerken en andere deep-learningmodellen eenvoudiger maken.
Laten we elk framework kort bekijken.
TensorFlow is een open-source deep-learningframework, ontwikkeld door Google en uitgebracht in 2015. Het biedt een reeks tools voor machinelearning-ontwikkeling en -deployment. Onze Introduction to Deep Neural Networks geeft een complete gids om diepe neurale netwerken te begrijpen en hun betekenis in de moderne deep-learningwereld van kunstmatige intelligentie, inclusief implementaties in TensorFlow.
Keras is een high-level neurale-netwerkframework in Python waarmee je snel kunt experimenteren en ontwikkelen. Het is open-source en fungeert (sinds versie 2.0) als de officiële high-level API van TensorFlow, wat de modelontwikkeling binnen het TensorFlow-ecosysteem stroomlijnt. Onze cursus Image Processing with Keras in Python leert je hoe je beeldanalyse uitvoert met Keras in Python door convolutionele neurale netwerken te bouwen, trainen en evalueren.
PyTorch, uitgebracht door Meta (voorheen Facebook) AI Research in 2017, is een algemeen deep-learningframework dat bekendstaat om zijn dynamische computationele grafiek, Pythonic syntax en sterke onderzoeksgemeenschap. Als je wilt duiken in natural language processing, is onze NLP with PyTorch: A Comprehensive Guide een uitstekend startpunt.
Elk project is anders, dus de keuze hangt af van welke eigenschappen voor een bepaalde usecase het belangrijkst zijn. Om betere beslissingen te nemen, geeft de volgende tabel een korte vergelijking van deze frameworks, met hun unieke kenmerken.
Tensorflow | Pytorch | Keras | |
API Level | Beide (High en Low) | Low | High |
Architectuur | Niet makkelijk te gebruiken | Pythonic, intuïtieve syntax | Eenvoudig, beknopt, leesbaar |
Datasets | Grote datasets, hoge prestaties | Grote datasets, hoge prestaties | Kleinere datasets |
Debugging | Moeilijk te debuggen | Goede debugging-mogelijkheden | Eenvoudig netwerk, dus debugging is vaak niet nodig |
Pretrained models? | Ja | Ja | Ja |
Populariteit | Op één na populairst van de drie | Meest gebruikt voor onderzoek en steeds vaker voor productie | Geïntegreerd in TensorFlow als de officiële high-level API |
Snelheid | Snel, hoge prestaties | Snel, hoge prestaties | Zelfde als TensorFlow (draait op TF-backend) |
Geschreven in | C++, CUDA, Python | C++, Python | Python |
Vergelijkende tabel tussen Tensorflow, Pytorch en Keras (bron)
Dit artikel gaf een volledig overzicht van wat een CNN in deep learning is, samen met hun cruciale rol bij beeldherkenning en classificatietaken.
Het begon met de inspiratie uit het menselijke visuele systeem voor het ontwerp van CNN's en verkende vervolgens de belangrijkste componenten die deze netwerken in staat stellen te leren en voorspellingen te doen.
Het probleem van overfitting werd erkend als een aanzienlijke uitdaging voor de generalisatiecapaciteit van CNN's. Ter beperking hiervan zijn diverse relevante strategieën uiteengezet om overfitting tegen te gaan en de algehele prestaties van CNN's te verbeteren.
Tot slot zijn enkele belangrijke deep-learningframeworks voor CNN's genoemd, met de unieke kenmerken van elk en hoe ze zich tot elkaar verhouden.
Sta je te popelen om verder te duiken in de wereld van AI en machine learning? Til je expertise naar een hoger niveau met de cursus Deep Learning with PyTorch.
Begin vandaag nog aan je deep-learningreis!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
