
Cours
Introduction au Deep Learning en Python
4 h
263.5K
Plusieurs raisons expliquent l'importance des CNN dans le monde moderne, comme indiqué ci-dessous :
Les réseaux neuronaux convolutifs ont été inspirés par l'architecture en couches du cortex visuel humain, et vous trouverez ci-dessous quelques similitudes et différences essentielles :
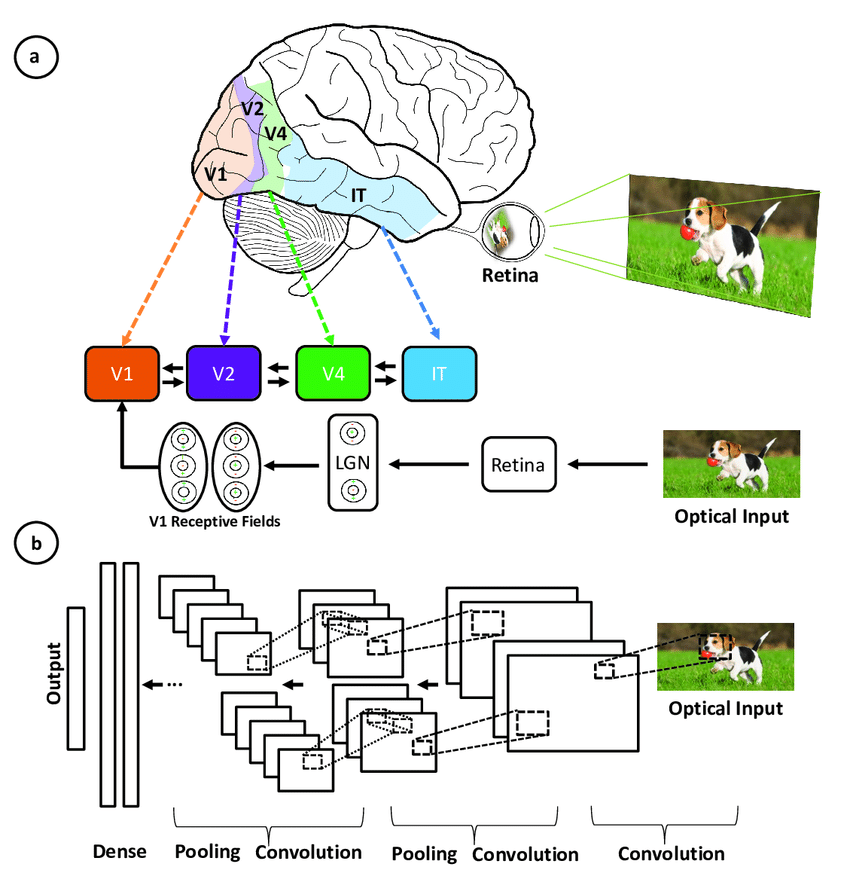
Illustration de la correspondance entre les zones associées au cortex visuel primaire et les couches d'un réseau neuronal convolutif(source)
Les CNN imitent le système visuel humain mais sont plus simples, ne disposant pas de ses mécanismes de rétroaction complexes et s'appuyant sur l'apprentissage supervisé plutôt que sur l'apprentissage non supervisé, ce qui a permis de réaliser des progrès dans le domaine de la vision par ordinateur en dépit de ces différences.
Le réseau neuronal convolutif se compose de quatre parties principales.
Mais comment les CNN apprennent-ils avec ces pièces ?
Ils aident les CNN à imiter la façon dont le cerveau humain fonctionne pour reconnaître des modèles et des caractéristiques dans les images :
Cette section aborde la définition de chacun de ces éléments à travers l'exemple suivant de classification d'un chiffre manuscrit.
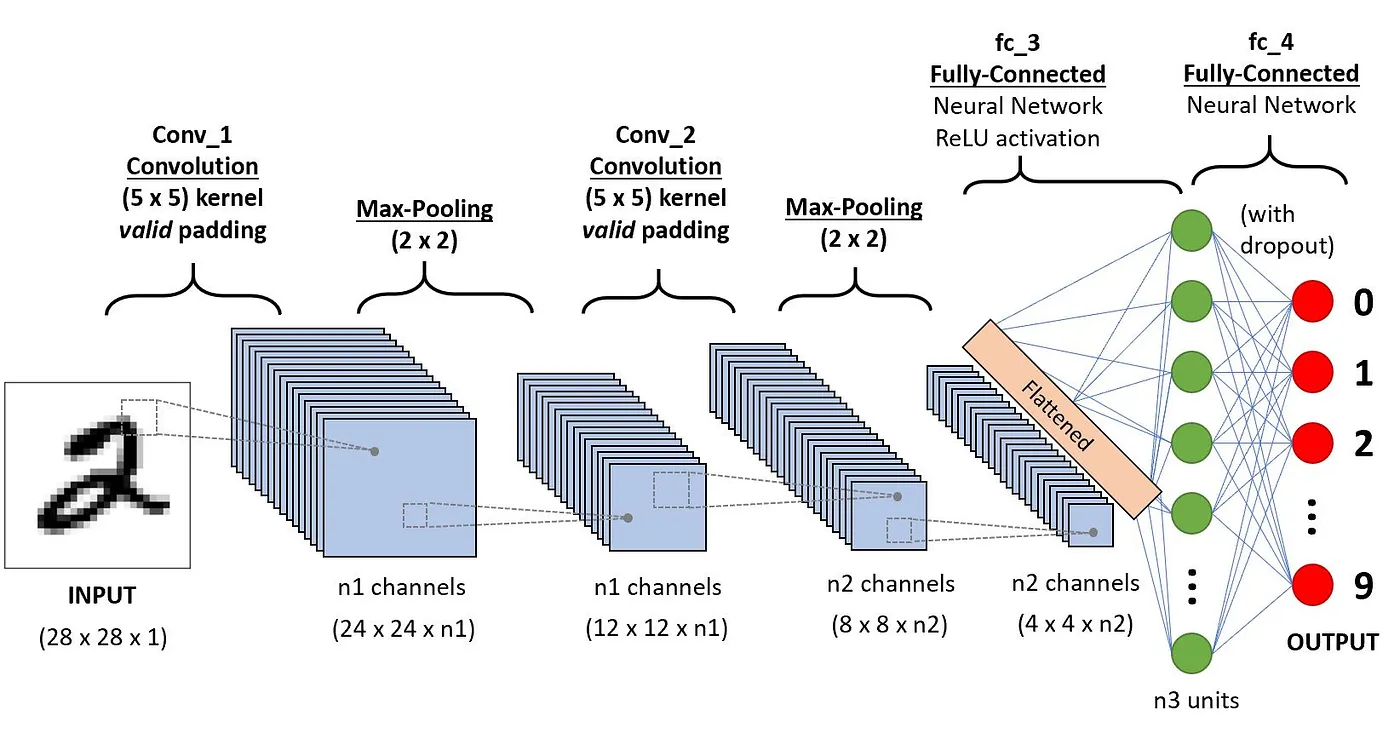
Architecture des CNN appliqués à la reconnaissance de chiffres(source)
C'est le premier élément constitutif d'un CNN. Comme son nom l'indique, la principale tâche mathématique effectuée s'appelle la convolution, qui consiste à appliquer une fonction de fenêtre coulissante à une matrice de pixels représentant une image. La fonction de glissement appliquée à la matrice est appelée noyau ou filtre, les deux pouvant être utilisés de manière interchangeable.
Dans la couche de convolution, plusieurs filtres de taille égale sont appliqués, et chaque filtre est utilisé pour reconnaître un motif spécifique de l'image, tel que la courbure des chiffres, les bords, la forme entière des chiffres, etc.
Plus simplement, dans la couche de convolution, nous utilisons de petites grilles (appelées filtres ou noyaux) qui se déplacent sur l'image. Chaque petite grille est comme une mini-loupe qui recherche des motifs spécifiques dans la photo, comme des lignes, des courbes ou des formes. En se déplaçant sur la photo, il crée une nouvelle grille qui met en évidence les endroits où il a trouvé ces motifs.
Par exemple, un filtre peut être efficace pour trouver des lignes droites, un autre peut trouver des courbes, et ainsi de suite. En utilisant plusieurs filtres différents, le CNN peut se faire une bonne idée des différents motifs qui composent l'image.
Considérons cette image 32x32 en niveaux de gris d'un chiffre écrit à la main. Les valeurs de la matrice sont données à titre d'illustration.
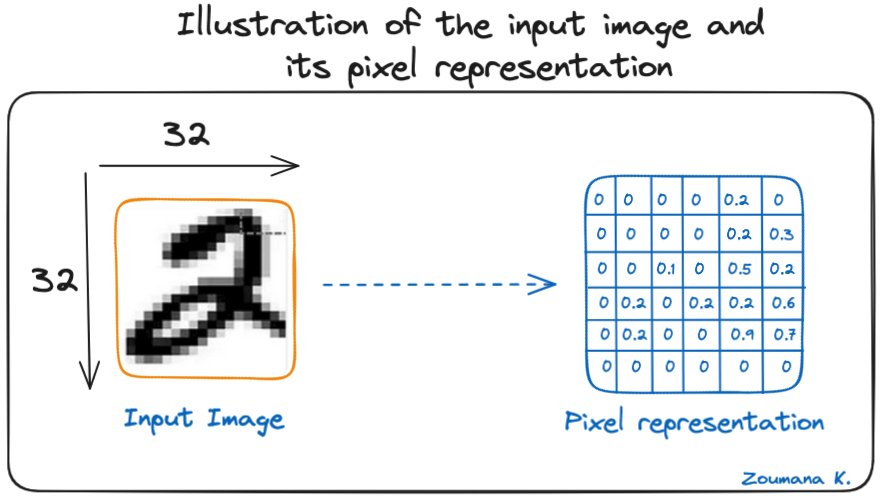
Illustration de l'image d'entrée et de sa représentation en pixels
Considérons également le noyau utilisé pour la convolution. Il s'agit d'une matrice de dimension 3x3. Les poids de chaque élément du noyau sont représentés dans la grille. Les poids nuls sont représentés dans les grilles noires et les poids un dans les grilles blanches.
Devons-nous trouver manuellement ces poids ?
Dans la réalité, les poids des noyaux sont déterminés au cours du processus d'apprentissage du réseau neuronal.
En utilisant ces deux matrices, nous pouvons effectuer l'opération de convolution en appliquant le produit de points, et travailler comme suit :
La dimension de la matrice convoluée dépend de la taille de la fenêtre coulissante. Plus la fenêtre coulissante est grande, plus la dimension est petite.
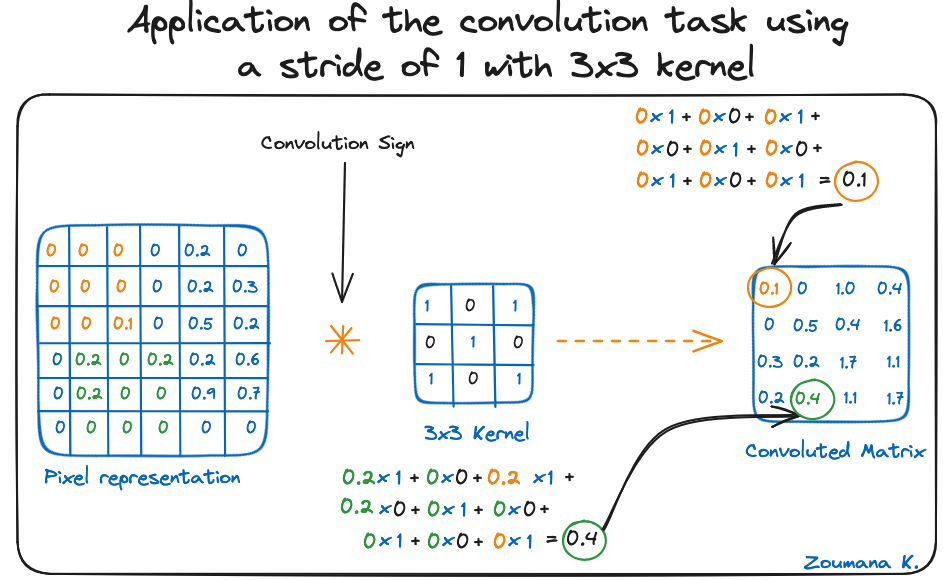
Application de la tâche de convolution en utilisant un pas de 1 avec un noyau 3x3
Un autre nom associé au noyau dans la littérature est celui de détecteur de caractéristiques, car les poids peuvent être ajustés avec précision pour détecter des caractéristiques spécifiques dans l'image d'entrée.
Par exemple :
Plus le réseau comporte de couches de convolution, meilleure est la capacité de la couche à détecter des caractéristiques plus abstraites.
Une fonction d'activation ReLU est appliquée après chaque opération de convolution. Cette fonction aide le réseau à apprendre les relations non linéaires entre les caractéristiques de l'image, ce qui rend le réseau plus robuste pour l'identification de différents modèles. Elle permet également d'atténuer les problèmes de gradient de fuite.
L'objectif de la couche de mise en commun est d'extraire les caractéristiques les plus significatives de la matrice convoluée. Pour ce faire, on applique certaines opérations d'agrégation qui réduisent la dimension de la carte des caractéristiques (matrice convoluée), ce qui permet de réduire la mémoire utilisée lors de l'apprentissage du réseau. La mise en commun permet également d'atténuer l'ajustement excessif.
Les fonctions d'agrégation les plus courantes qui peuvent être appliquées sont les suivantes :
Vous trouverez ci-dessous une illustration de chacun des exemples précédents :
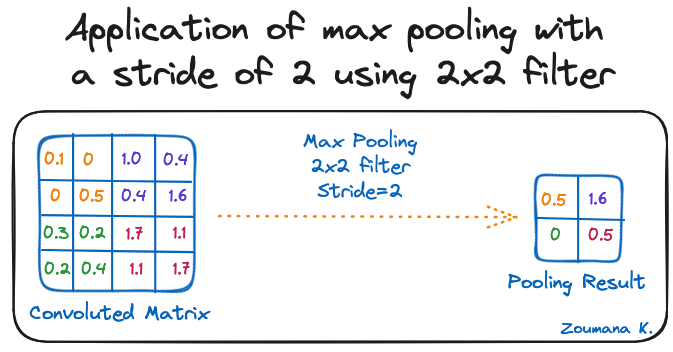
Application du pooling max avec un pas de 2 en utilisant le filtre 2x2
En outre, la dimension de la carte des caractéristiques diminue au fur et à mesure que la fonction de regroupement est appliquée.
La dernière couche de mise en commun aplatit sa carte de caractéristiques afin qu'elle puisse être traitée par la couche entièrement connectée.
Ces couches se trouvent dans la dernière couche du réseau neuronal convolutif et leurs entrées correspondent à la matrice unidimensionnelle aplatie générée par la dernière couche de mise en commun. Les fonctions d'activation ReLU leur sont appliquées pour assurer la non-linéarité.
Enfin, une couche de prédiction softmax est utilisée pour générer des valeurs de probabilité pour chacune des étiquettes de sortie possibles, et l'étiquette finale prédite est celle qui présente le score de probabilité le plus élevé.
Le surajustement est un problème courant dans les modèles d'apprentissage automatique et les projets d'apprentissage profond du CNN. Cela se produit lorsque le modèle apprend trop bien les données d'apprentissage ("apprentissage par cœur"), y compris le bruit et les valeurs aberrantes. Ce type d'apprentissage conduit à un modèle qui donne de bons résultats sur les données d'apprentissage, mais de mauvais résultats sur de nouvelles données inédites.
Ce phénomène peut être observé lorsque la performance sur les données d'apprentissage est trop faible par rapport à la performance sur les données de validation ou de test ; une illustration graphique est donnée ci-dessous :
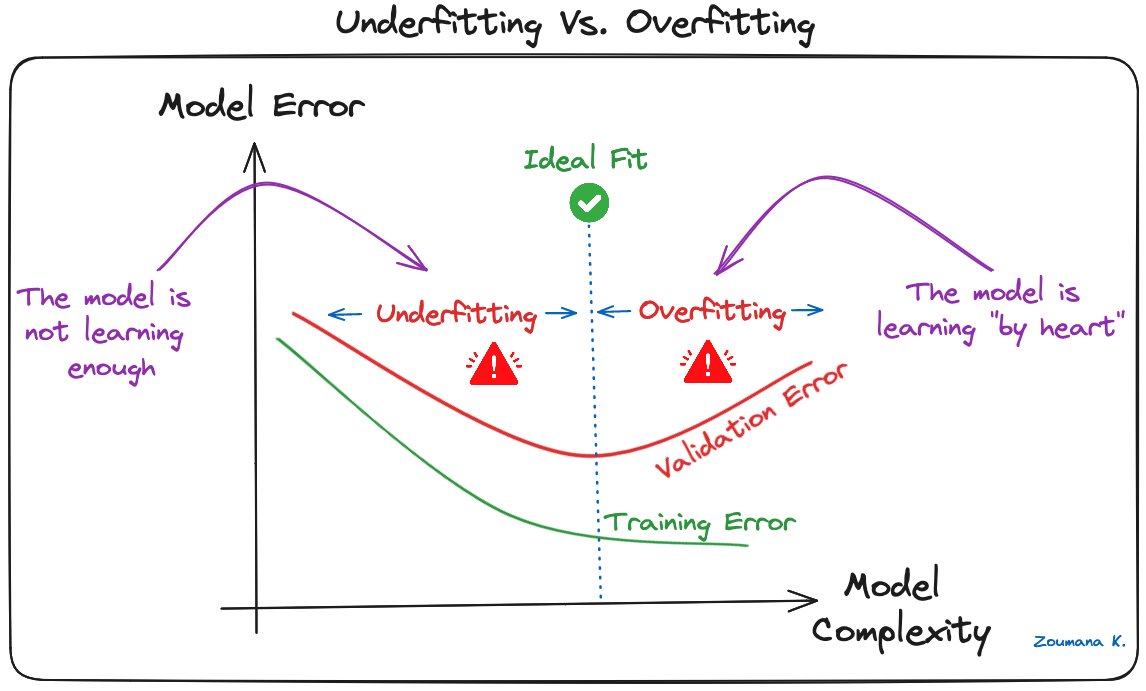
Sous-appareillage vs. Surajustement
Les modèles d'apprentissage profond, en particulier les réseaux neuronaux convolutifs (CNN), sont particulièrement sensibles à l'overfitting en raison de leur capacité de complexité élevée et de leur aptitude à apprendre des modèles détaillés dans des données à grande échelle.
Plusieurs techniques de régularisation peuvent être appliquées pour atténuer l'ajustement excessif dans les CNN, et certaines d'entre elles sont illustrées ci-dessous :
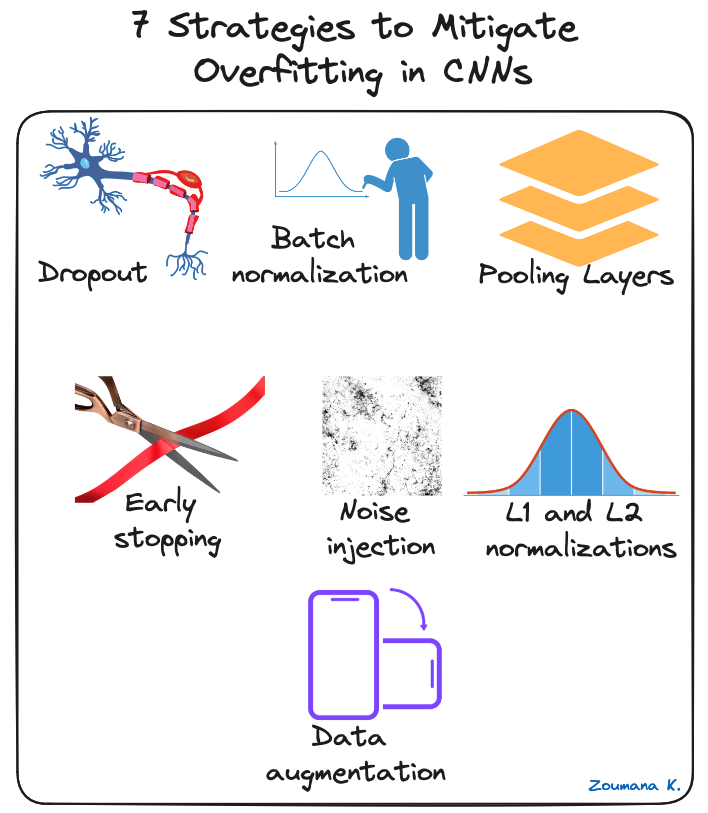
7 stratégies pour limiter l'overfitting dans les CNNs
Les réseaux neuronaux convolutifs ont révolutionné le domaine de la vision par ordinateur, conduisant à des avancées significatives dans de nombreuses applications du monde réel. Vous trouverez ci-dessous quelques exemples de leur application.
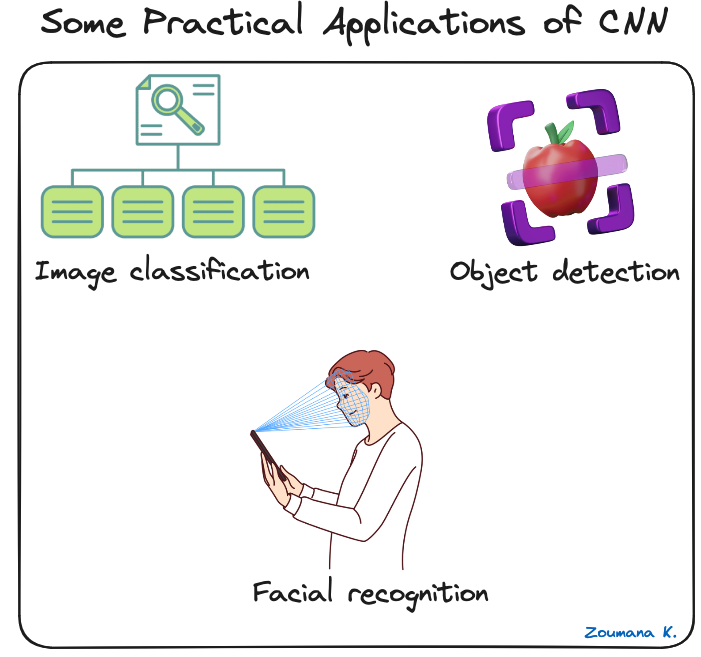
Quelques applications pratiques des CNN
Pour une mise en œuvre plus pratique, notre tutoriel sur les réseaux neuronaux convolutifs (CNN) avec TensorFlow vous apprend à construire et à mettre en œuvre des CNN en Python avec le framework Tensorflow 2.
La croissance rapide de l'apprentissage profond est principalement due à des cadres puissants tels que Tensorflow, Pytorch et Keras, qui facilitent la formation des réseaux neuronaux convolutionnels et d'autres modèles d'apprentissage profond.
Voici un bref aperçu de chaque cadre.

Logos Tensorflow, Keras et Pytorch
TensorFlow est un framework d'apprentissage profond open-source développé par Google et publié en 2015. Il offre une gamme d'outils pour le développement et le déploiement de l'apprentissage automatique. Notre introduction aux réseaux neuronaux profonds fournit un guide complet pour comprendre les réseaux neuronaux profonds et leur importance dans le monde moderne de l'apprentissage profond de l'intelligence artificielle, ainsi que des implémentations du monde réel dans Tensorflow.
Keras est un framework de réseau neuronal de haut niveau en Python qui permet une expérimentation et un développement rapides. Il est open-source et peut être utilisé dans d'autres frameworks comme TensorFlow, CNTK et Theano. Notre cours, Image Processing with Keras in Python, vous apprend à mener des analyses d'images à l'aide de Keras avec Python en construisant, en entraînant et en évaluant des réseaux de neurones convolutifs.
Lancé par la division de recherche en IA de Facebook en 2017, il est conçu pour des applications de traitement du langage naturel et se distingue par son graphique de calcul dynamique et son efficacité en termes de mémoire. Si vous souhaitez vous plonger dans le traitement du langage naturel, consultez notre site NLP with PyTorch : Un guide complet est un excellent point de départ.
Chaque projet étant différent, la décision dépend réellement des caractéristiques les plus importantes pour un cas d'utilisation donné. Pour vous aider à prendre de meilleures décisions, le tableau suivant propose une brève comparaison de ces tableaux, en mettant en évidence leurs caractéristiques uniques.
|
Tensorflow |
Pytorch |
Keras |
|
|
Niveau API |
Both (haut et bas) |
Faible |
Haut |
|
Architecture |
Pas facile à utiliser |
Complexe, moins lisible |
Simple, concis, lisible |
|
Ensembles de données |
Grands ensembles de données, hautes performances |
Grands ensembles de données, hautes performances |
Petits ensembles de données |
|
Débogage |
Difficile de procéder à un débogage |
Bonnes capacités de débogage |
Réseau simple, ce qui fait que le débogage n'est pas souvent nécessaire |
|
Modèles pré-entraînés ? |
Oui |
Oui |
Oui |
|
Popularité |
Le deuxième plus populaire des trois |
Troisième plus populaire des trois |
Le plus populaire des trois |
|
Vitesse |
Rapide et performant |
Rapide et performant |
Lenteur et faible performance |
|
Rédigé en |
C++, CUDA, Python |
Lua |
Python |
Tableau comparatif entre Tensorflow, Pytorch et Keras(source)
Cet article donne un aperçu complet de ce qu'est un CNN dans l'apprentissage profond, ainsi que de son rôle crucial dans les tâches de reconnaissance et de classification d'images.
Elle a commencé par mettre en évidence l'inspiration tirée du système visuel humain pour la conception des CNN et a ensuite exploré les composants clés qui permettent à ces réseaux d'apprendre et de faire des prédictions.
La question du surajustement a été reconnue comme un défi important pour la capacité de généralisation des CNN. Pour y remédier, diverses stratégies pertinentes ont été définies pour atténuer le surajustement et améliorer les performances globales des CNN.
Enfin, les principaux frameworks CNN d'apprentissage profond ont été mentionnés, ainsi que les caractéristiques uniques de chacun d'entre eux et la manière dont ils se comparent les uns aux autres.
Vous avez envie de vous plonger dans le monde de l'IA et de l'apprentissage automatique ? Faites passer votre expertise au niveau supérieur en vous inscrivant dès aujourd'hui au cours Deep Learning with PyTorch.
Commencez dès aujourd'hui votre voyage dans l'apprentissage profond !
Cours
Cours
Cours
blog
Kurtis Pykes
9 min
blog
blog
Zoumana Keita
15 min
Tutoriel
Samuel Shaibu
Tutoriel
Tutoriel
Matt Crabtree

