
Kurs
Einführung in Deep Learning mit Python
4 Std.
263.6K
Es gibt mehrere Gründe, warum CNNs in der modernen Welt wichtig sind, die im Folgenden erläutert werden:
Faltungsneuronale Netze wurden von der schichtweisen Architektur des menschlichen visuellen Kortex inspiriert, und im Folgenden werden einige wichtige Ähnlichkeiten und Unterschiede beschrieben:
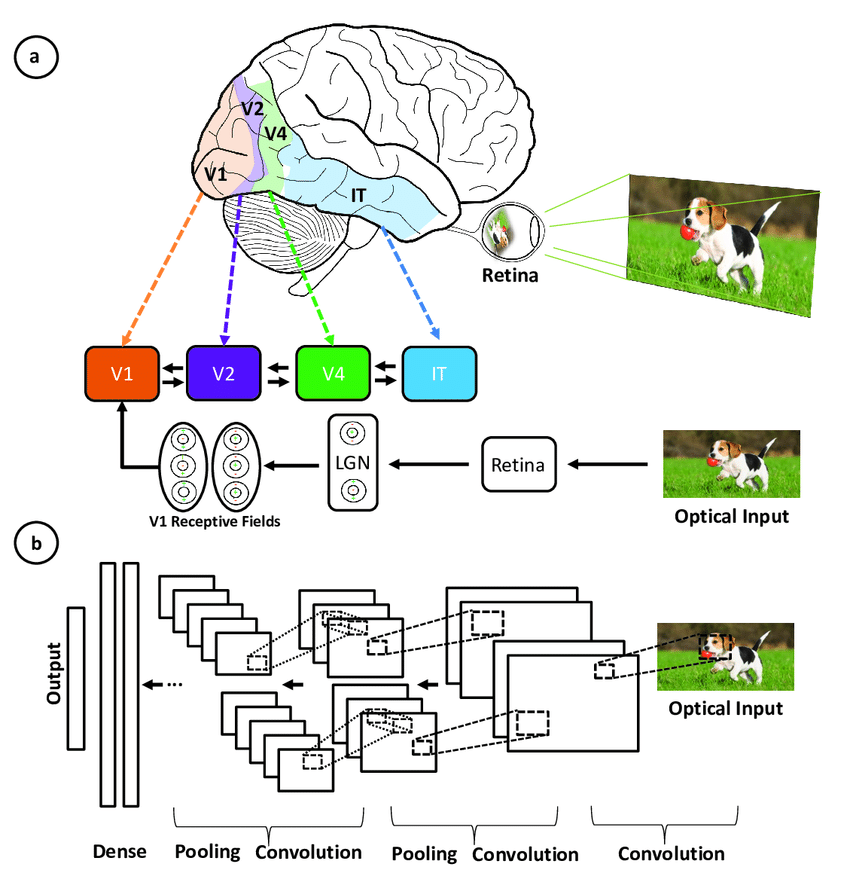
Veranschaulichung der Übereinstimmung zwischen den Bereichen, die mit dem primären visuellen Kortex verbunden sind, und den Schichten in einem neuronalen Faltungsnetzwerk(Quelle)
CNNs ahmen das menschliche Sehsystem nach, sind aber einfacher, da ihnen die komplexen Rückkopplungsmechanismen fehlen und sie eher auf überwachtes als auf unbeaufsichtigtes Lernen setzen, was trotz dieser Unterschiede zu Fortschritten in der Computer Vision führt.
Das neuronale Faltungsnetzwerk besteht aus vier Hauptteilen.
Aber wie lernen CNNs mit diesen Teilen?
Sie helfen den CNNs zu imitieren, wie das menschliche Gehirn arbeitet, um Muster und Merkmale in Bildern zu erkennen:
In diesem Abschnitt wird die Definition jeder dieser Komponenten anhand des folgenden Beispiels der Klassifizierung einer handschriftlichen Ziffer erläutert.
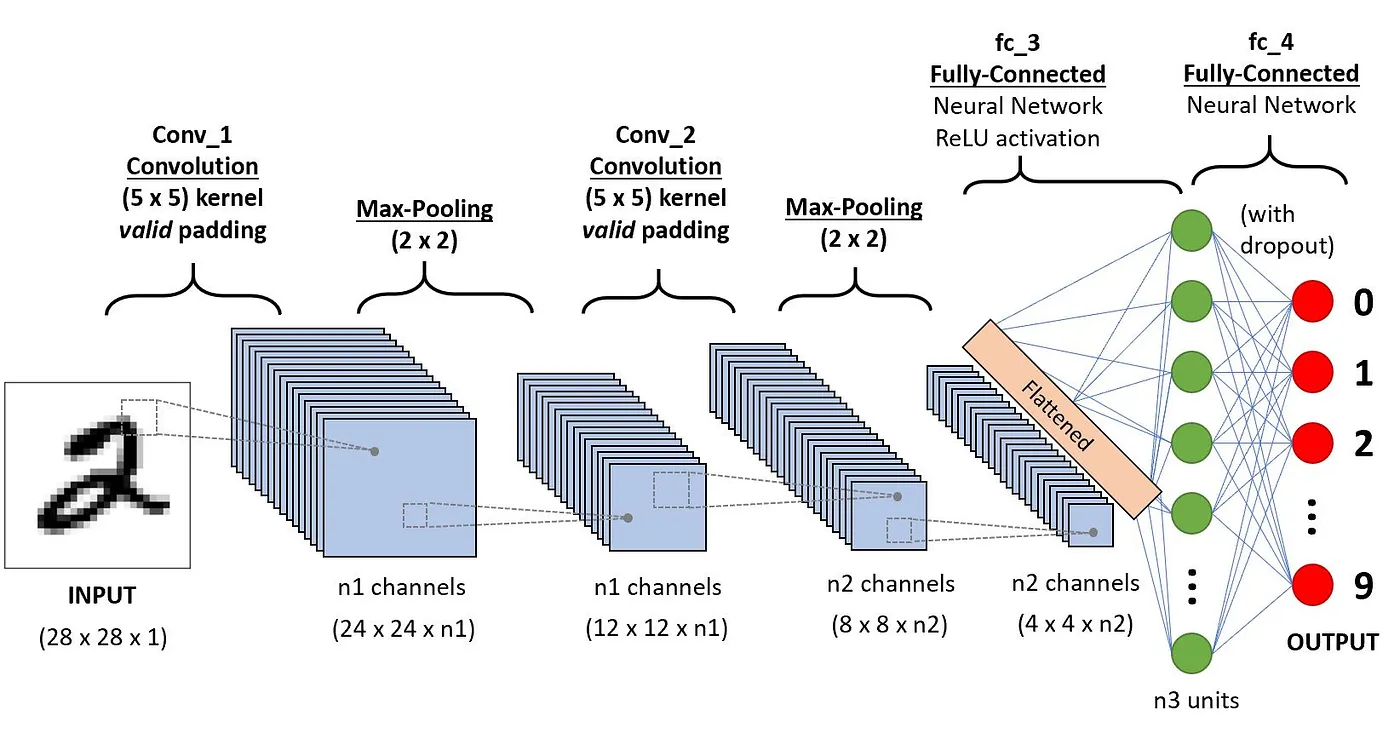
Architektur der CNNs für die Ziffernerkennung(Quelle)
Dies ist der erste Baustein eines CNN. Wie der Name schon sagt, ist die wichtigste mathematische Aufgabe die Faltung, d.h. die Anwendung einer Schiebefensterfunktion auf eine Matrix von Pixeln, die ein Bild darstellen. Die gleitende Funktion, die auf die Matrix angewendet wird, wird als Kernel oder Filter bezeichnet, und beide können austauschbar verwendet werden.
In der Faltungsschicht werden mehrere gleich große Filter angewendet, und jeder Filter wird verwendet, um ein bestimmtes Muster aus dem Bild zu erkennen, z. B. die Krümmung der Ziffern, die Kanten, die gesamte Form der Ziffern und mehr.
Vereinfacht gesagt, verwenden wir in der Faltungsschicht kleine Gitter (Filter oder Kernel genannt), die sich über das Bild bewegen. Jedes kleine Raster ist wie eine Mini-Lupe, die nach bestimmten Mustern im Foto sucht, wie Linien, Kurven oder Formen. Wenn er sich über das Foto bewegt, erstellt er ein neues Raster, das hervorhebt, wo er diese Muster gefunden hat.
Ein Filter kann zum Beispiel gut gerade Linien finden, ein anderer Kurven und so weiter. Durch die Verwendung verschiedener Filter kann sich das CNN einen guten Überblick über die verschiedenen Muster verschaffen, die das Bild ausmachen.
Betrachten wir dieses 32x32-Graustufenbild einer handgeschriebenen Ziffer. Die Werte in der Matrix werden zur Veranschaulichung angegeben.
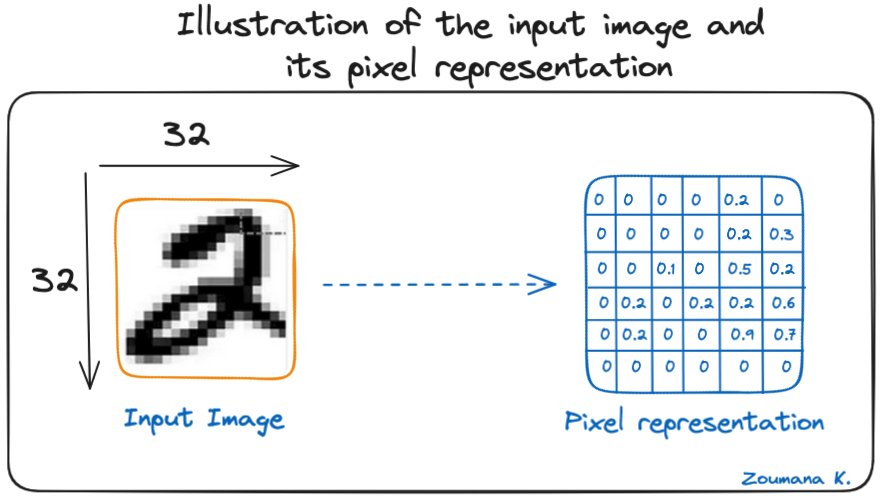
Illustration des Eingangsbildes und seiner Pixeldarstellung
Betrachten wir auch den Kernel, der für die Faltung verwendet wird. Es ist eine Matrix mit einer Dimension von 3x3. Die Gewichte der einzelnen Elemente des Kerns werden in dem Raster dargestellt. Nullgewichte werden in den schwarzen Gittern und Einsen in den weißen Gittern dargestellt.
Müssen wir diese Gewichte manuell finden?
In der Praxis werden die Gewichte der Kernel während des Trainingsprozesses des neuronalen Netzes festgelegt.
Mit diesen beiden Matrizen können wir die Faltungsoperation durchführen, indem wir das Punktprodukt anwenden und wie folgt vorgehen:
Die Dimension der gefalteten Matrix hängt von der Größe des Schiebefensters ab. Je höher das Schiebefenster, desto kleiner die Dimension.
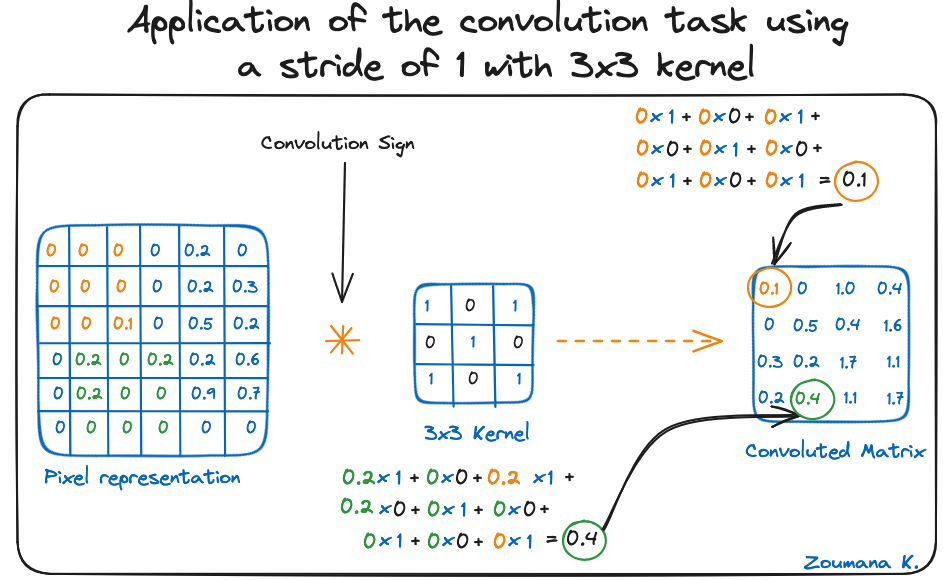
Anwendung der Faltungsaufgabe mit einer Schrittweite von 1 und einem 3x3-Kernel
In der Literatur wird der Kernel auch als Merkmalsdetektor bezeichnet, weil die Gewichte fein abgestimmt werden können, um bestimmte Merkmale im Eingangsbild zu erkennen.
Zum Beispiel:
Je mehr Faltungsschichten das Netz hat, desto besser kann es abstraktere Merkmale erkennen.
Nach jeder Faltungsoperation wird eine ReLU-Aktivierungsfunktion angewendet. Diese Funktion hilft dem Netz, nicht-lineare Beziehungen zwischen den Merkmalen im Bild zu erlernen, und macht das Netz dadurch robuster für die Erkennung verschiedener Muster. Es hilft auch, die Probleme mit dem verschwindenden Gradienten zu entschärfen.
Das Ziel der Pooling-Schicht ist es, die wichtigsten Merkmale aus der gefalteten Matrix herauszufiltern. Dies geschieht durch die Anwendung einiger Aggregationsoperationen, die die Dimension der Merkmalskarte (gefaltete Matrix) reduzieren und damit den Speicherbedarf beim Training des Netzes verringern. Das Pooling ist auch wichtig, um die Überanpassung abzuschwächen.
Die häufigsten Aggregationsfunktionen, die angewendet werden können, sind:
Im Folgenden findest du eine Illustration zu jedem der vorherigen Beispiele:
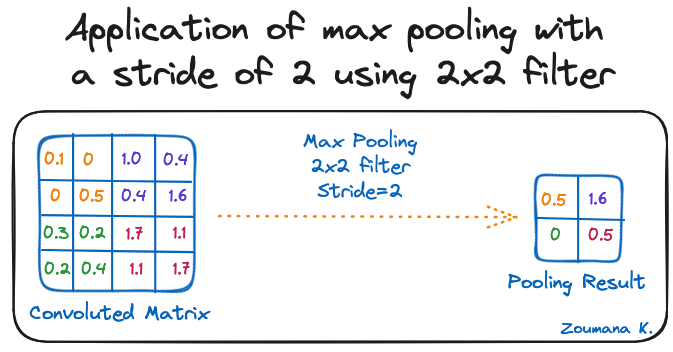
Anwendung von Max-Pooling mit einer Schrittweite von 2 unter Verwendung eines 2x2-Filters
Außerdem wird die Dimension der Merkmalskarte kleiner, wenn die Pooling-Funktion angewendet wird.
Die letzte Pooling-Schicht flacht ihre Merkmalskarte ab, damit sie von der voll vernetzten Schicht verarbeitet werden kann.
Diese Schichten befinden sich in der letzten Schicht des neuronalen Faltungsnetzwerks, und ihre Eingänge entsprechen der abgeflachten eindimensionalen Matrix, die von der letzten Pooling-Schicht erzeugt wurde. Für die Nichtlinearität werden ReLU-Aktivierungsfunktionen auf sie angewendet.
Schließlich wird eine Softmax-Vorhersageschicht verwendet, um Wahrscheinlichkeitswerte für jedes der möglichen Output-Labels zu generieren, und das endgültige Label, das vorhergesagt wird, ist das mit dem höchsten Wahrscheinlichkeitswert.
Überanpassung ist eine häufige Herausforderung bei Machine-Learning-Modellen und CNN Deep-Learning-Projekten. Das passiert, wenn das Modell die Trainingsdaten zu gut lernt ("auswendig lernen"), einschließlich der Störungen und Ausreißer. Ein solches Lernen führt zu einem Modell, das bei den Trainingsdaten gut abschneidet, aber bei neuen, ungesehenen Daten schlecht.
Dies kann beobachtet werden, wenn die Leistung bei den Trainingsdaten im Vergleich zur Leistung bei den Validierungs- oder Testdaten zu niedrig ist:
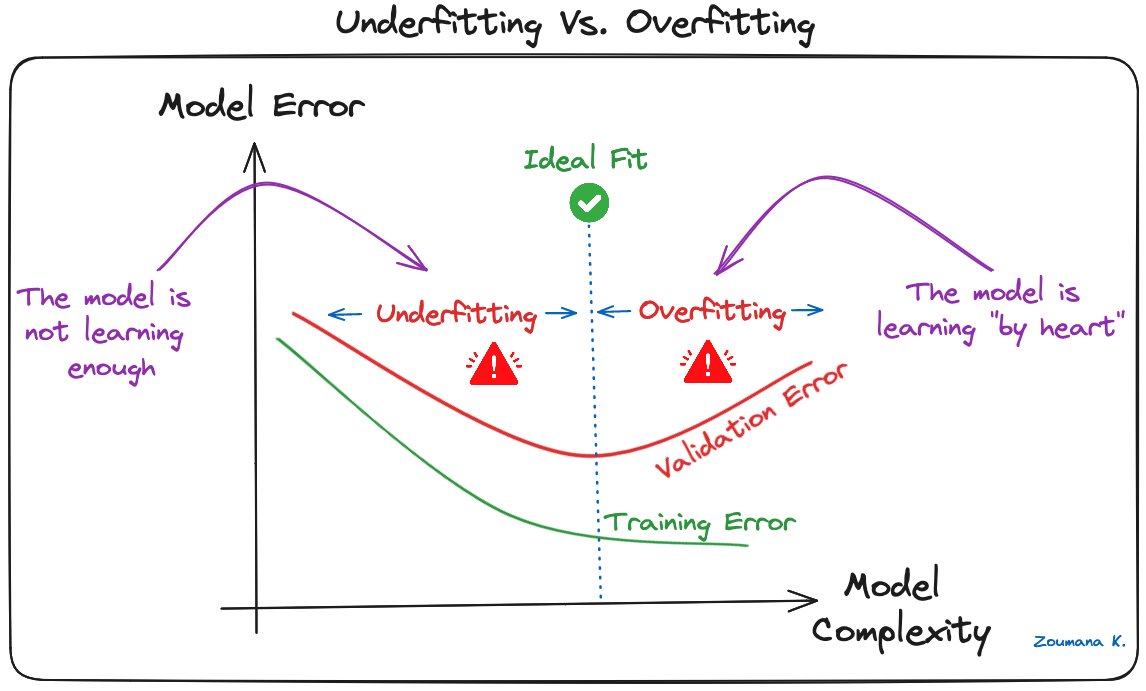
Underfitting Vs. Überanpassung
Deep Learning-Modelle, insbesondere Convolutional Neural Networks (CNNs), sind aufgrund ihrer hohen Komplexität und ihrer Fähigkeit, detaillierte Muster in großen Datenmengen zu lernen, besonders anfällig für Overfitting.
Um die Überanpassung von CNNs zu verringern, können verschiedene Regularisierungstechniken angewendet werden, von denen einige im Folgenden vorgestellt werden:
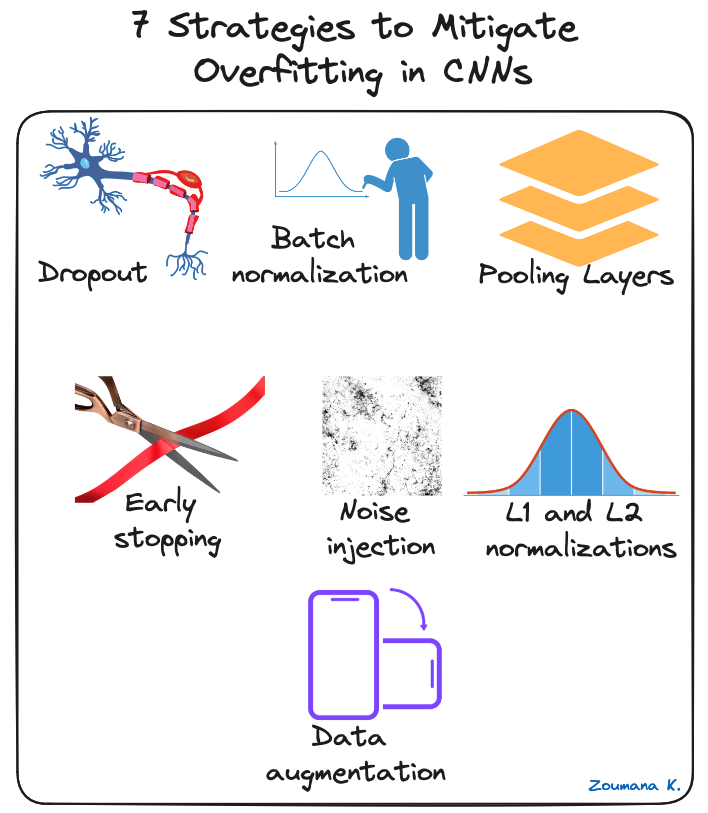
7 Strategien zur Verringerung der Überanpassung in CNNs
Convolutional Neural Networks haben das Feld der Computer Vision revolutioniert und zu erheblichen Fortschritten in vielen realen Anwendungen geführt. Im Folgenden findest du einige Beispiele, wie sie angewendet werden.
Einige praktische Anwendungen von CNNs
In unserem Convolutional Neural Networks (CNN) with TensorFlow Tutorial lernst du, wie man CNNs in Python mit dem Tensorflow Framework 2 konstruiert und implementiert.
Das rasante Wachstum von Deep Learning ist vor allem auf leistungsstarke Frameworks wie Tensorflow, Pytorch und Keras zurückzuführen, die das Training von faltigen neuronalen Netzen und anderen Deep-Learning-Modellen erleichtern.
Lass uns einen kurzen Überblick über jedes Framework geben.

Tensorflow, Keras und Pytorch-Logos
TensorFlow ist ein Open-Source Deep Learning Framework, das von Google entwickelt und 2015 veröffentlicht wurde. Es bietet eine Reihe von Tools für die Entwicklung und den Einsatz von maschinellem Lernen. Unsere Einführung in tiefe neuronale Netze bietet einen vollständigen Leitfaden zum Verständnis tiefer neuronaler Netze und ihrer Bedeutung in der modernen Deep Learning-Welt der künstlichen Intelligenz, zusammen mit realen Implementierungen in Tensorflow.
Keras ist ein High-Level-Framework für neuronale Netze in Python, das schnelles Experimentieren und Entwickeln ermöglicht. Es ist Open-Source und kann in anderen Frameworks wie TensorFlow, CNTK und Theano verwendet werden. In unserem Kurs Bildverarbeitung mit Keras in Python lernst du, wie du mit Keras und Python Bildanalysen durchführst, indem du Faltungsneuronale Netze konstruierst, trainierst und auswertest.
Sie wurde 2017 von der KI-Forschungsabteilung von Facebook entwickelt und ist für Anwendungen im Bereich der natürlichen Sprachverarbeitung konzipiert und zeichnet sich durch ihren dynamischen Berechnungsgraphen und ihre Speichereffizienz aus. Wenn du in die natürliche Sprachverarbeitung einsteigen möchtest, findest du auf NLP mit PyTorch: Ein umfassender Leitfaden ist ein guter Ausgangspunkt.
Jedes Projekt ist anders, daher hängt die Entscheidung davon ab, welche Eigenschaften für den jeweiligen Anwendungsfall am wichtigsten sind. Um eine bessere Entscheidung treffen zu können, bietet die folgende Tabelle einen kurzen Vergleich dieser Frameworks und hebt ihre einzigartigen Merkmale hervor.
|
Tensorflow |
Pytorch |
Keras |
|
|
API Level |
Beide (Hoch und Niedrig) |
Niedrig |
Hoch |
|
Architektur |
Nicht einfach zu bedienen |
Komplex, weniger lesbar |
Einfach, prägnant, lesbar |
|
Datensätze |
Große Datensätze, hohe Leistung |
Große Datensätze, hohe Leistung |
Kleinere Datensätze |
|
Fehlersuche |
Schwierige Fehlersuche |
Gute Debugging-Fähigkeiten |
Einfaches Netzwerk, so dass eine Fehlersuche nicht oft erforderlich ist |
|
Vorgefertigte Modelle? |
Ja |
Ja |
Ja |
|
Beliebtheit |
Die zweitbeliebteste der drei |
Drittbeliebteste der drei |
Der beliebteste der drei |
|
Geschwindigkeit |
Schnell, leistungsstark |
Schnell, leistungsstark |
Langsam, geringe Leistung |
|
Geschrieben in |
C++, CUDA, Python |
Lua |
Python |
Vergleichende Tabelle zwischen Tensorflow, Pytorch und Keras(Quelle)
Dieser Artikel gibt einen vollständigen Überblick darüber, was ein CNN im Deep Learning ist und welche wichtige Rolle er bei der Bilderkennung und Klassifizierung spielt.
Zunächst wurden die Inspirationen des menschlichen Sehsystems für die Entwicklung von CNNs hervorgehoben und dann die Schlüsselkomponenten untersucht, die es diesen Netzen ermöglichen, zu lernen und Vorhersagen zu treffen.
Das Problem der Überanpassung wurde als eine große Herausforderung für die Generalisierungsfähigkeit von CNNs erkannt. Um dies abzumildern, wurden verschiedene Strategien entwickelt, um die Überanpassung abzuschwächen und die Gesamtleistung von CNN zu verbessern.
Abschließend wurden einige wichtige CNN-Frameworks für das Deep Learning erwähnt, sowie die einzigartigen Merkmale jedes einzelnen und wie sie im Vergleich zueinander stehen.
Willst du tiefer in die Welt der KI und des maschinellen Lernens eintauchen? Bringe dein Wissen auf die nächste Stufe und melde dich noch heute für den Kurs Deep Learning mit PyTorch an.
Beginne deine Deep Learning-Reise noch heute!
Kurs
Kurs
Kurs
Blog
Tutorial
Matt Crabtree
Tutorial
Javier Canales Luna
Tutorial
Satyabrata Pal
Tutorial
Mark Pedigo
Tutorial
Derrick Mwiti
