
Courses
Nhập môn Deep Learning với Python
4 giờ
264K
Có nhiều lý do khiến CNN quan trọng trong thế giới hiện đại, như nêu dưới đây:
Mạng nơ-ron tích chập lấy cảm hứng từ kiến trúc phân lớp của vỏ não thị giác người, và dưới đây là vài điểm tương đồng và khác biệt then chốt:
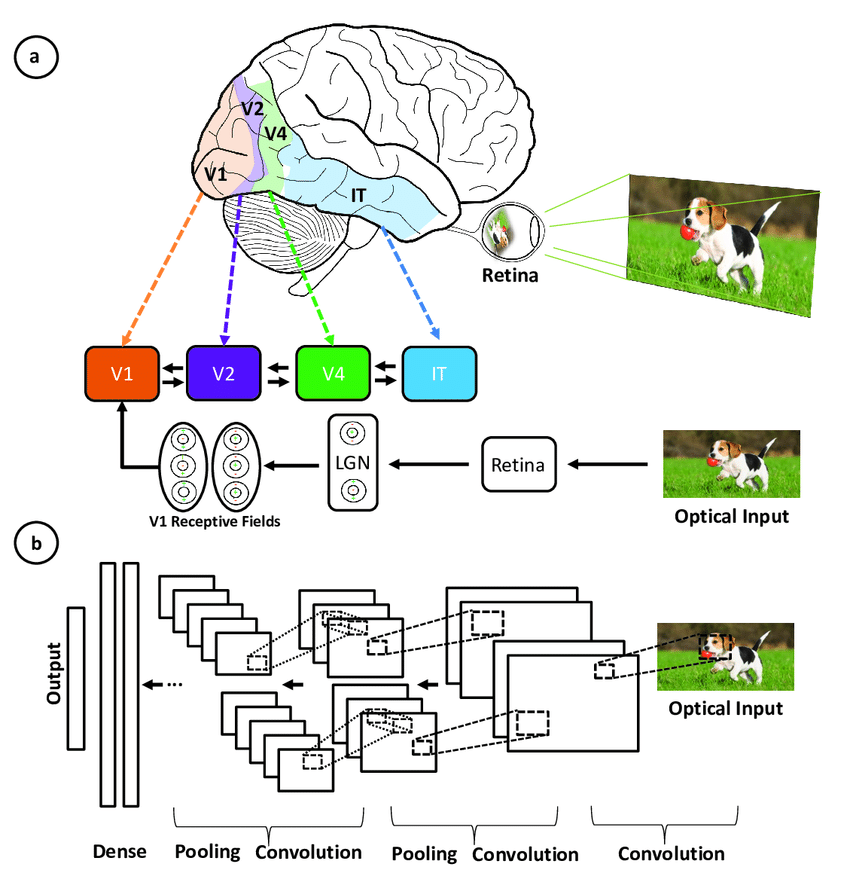
Minh hoạ sự tương ứng giữa các vùng liên quan đến vỏ não thị giác sơ cấp và các tầng trong mạng nơ-ron tích chập (nguồn)
CNN mô phỏng hệ thị giác người nhưng đơn giản hơn, thiếu các cơ chế phản hồi phức tạp và dựa vào học có giám sát thay vì không giám sát, song vẫn thúc đẩy tiến bộ trong thị giác máy tính bất chấp những khác biệt này.
Mạng nơ-ron tích chập gồm bốn phần chính.
Vậy CNN học với những phần đó như thế nào?
Chúng giúp CNN mô phỏng cách não người hoạt động để nhận diện mẫu và đặc trưng trong ảnh:
Phần này đi sâu vào định nghĩa từng thành phần thông qua ví dụ phân loại một chữ số viết tay.
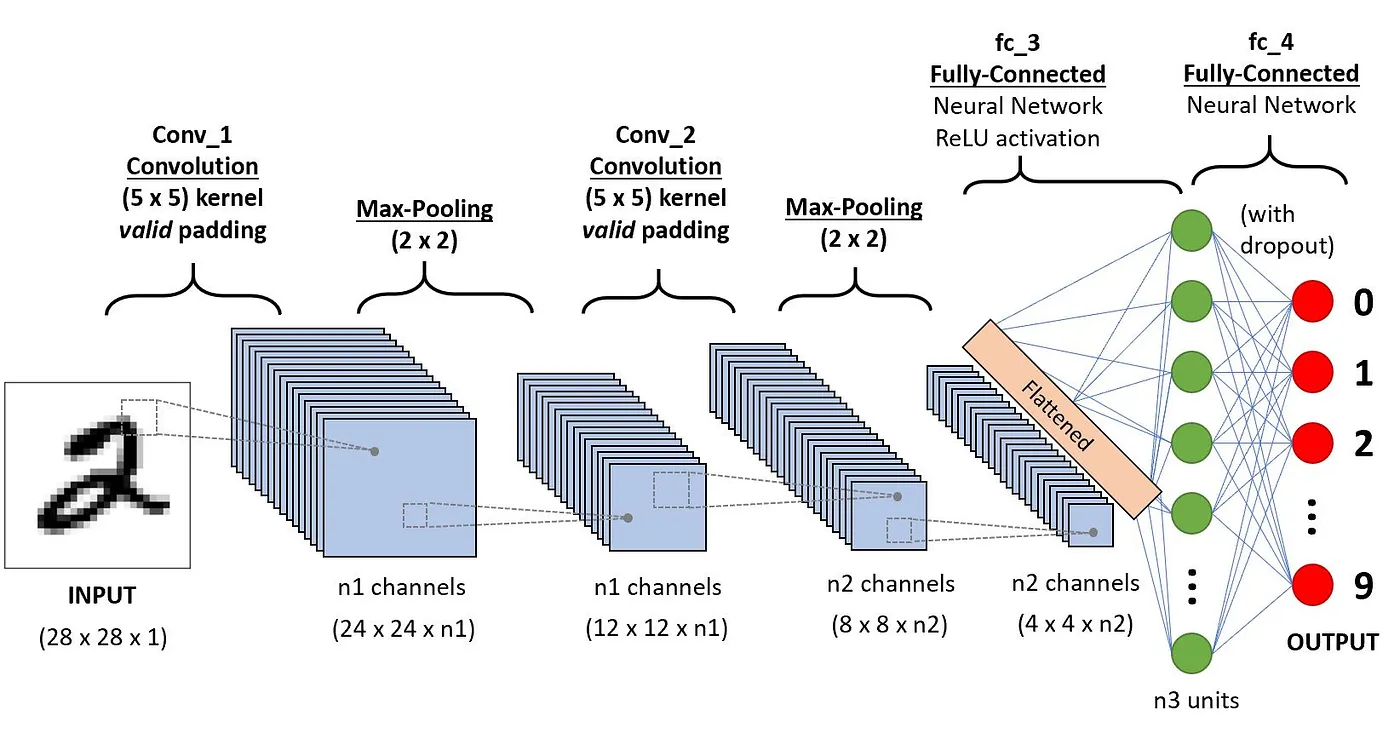
Kiến trúc CNN áp dụng cho nhận dạng chữ số (nguồn)
Đây là khối xây dựng đầu tiên của CNN. Như tên gọi, tác vụ toán học chính là tích chập, tức áp dụng một cửa sổ trượt lên ma trận điểm ảnh biểu diễn một bức ảnh. Hàm trượt áp dụng lên ma trận gọi là kernel hay filter, và hai thuật ngữ này dùng thay thế cho nhau.
Trong tầng tích chập, nhiều bộ lọc cùng kích thước được áp dụng, và mỗi bộ lọc được dùng để nhận diện một mẫu cụ thể từ ảnh, như độ cong của chữ số, các cạnh, hình dạng tổng thể của chữ số, v.v.
Nói đơn giản, ở tầng tích chập, chúng ta dùng các lưới nhỏ (gọi là filter hay kernel) di chuyển trên ảnh. Mỗi lưới nhỏ như một kính lúp mini tìm các mẫu cụ thể trong ảnh, như đường thẳng, đường cong hay hình dạng. Khi di chuyển trên ảnh, nó tạo ra một lưới mới làm nổi bật nơi tìm thấy các mẫu đó.
Ví dụ, một bộ lọc có thể giỏi tìm đường thẳng, bộ khác tìm đường cong, v.v. Bằng cách dùng nhiều bộ lọc khác nhau, CNN có thể nắm bắt tốt các mẫu đa dạng cấu thành bức ảnh.
Hãy xét ảnh thang xám 32x32 của một chữ số viết tay. Các giá trị trong ma trận được cho nhằm minh hoạ.
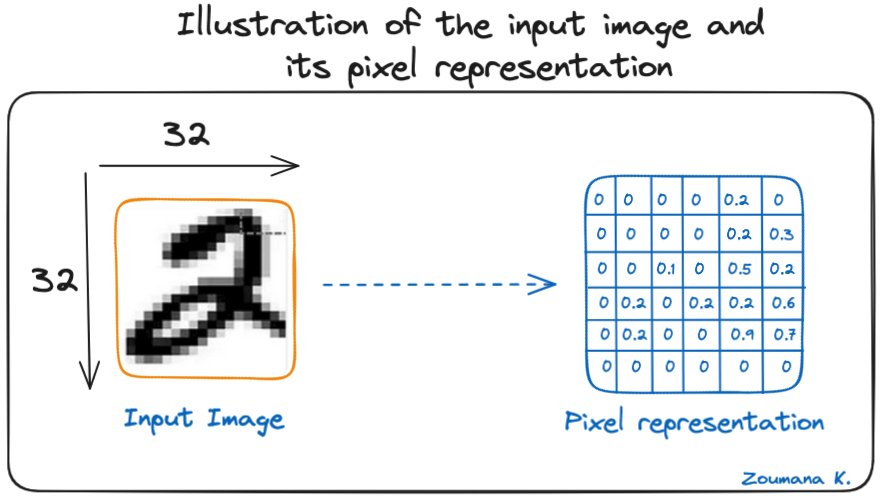
Minh hoạ ảnh đầu vào và biểu diễn điểm ảnh
Cũng xét kernel dùng cho tích chập. Đó là ma trận kích thước 3x3. Trọng số của từng phần tử kernel được hiển thị trong lưới. Trọng số 0 thể hiện bằng ô đen và 1 bằng ô trắng.
Chúng ta có phải tự tìm các trọng số này không?
Trong thực tế, trọng số của các kernel được xác định trong quá trình huấn luyện mạng nơ-ron.
Dùng hai ma trận này, ta có thể thực hiện phép tích chập bằng cách áp dụng tích vô hướng, và tiến hành như sau:
Kích thước ma trận sau tích chập phụ thuộc vào kích thước bước trượt. Bước trượt càng lớn, kích thước càng nhỏ.
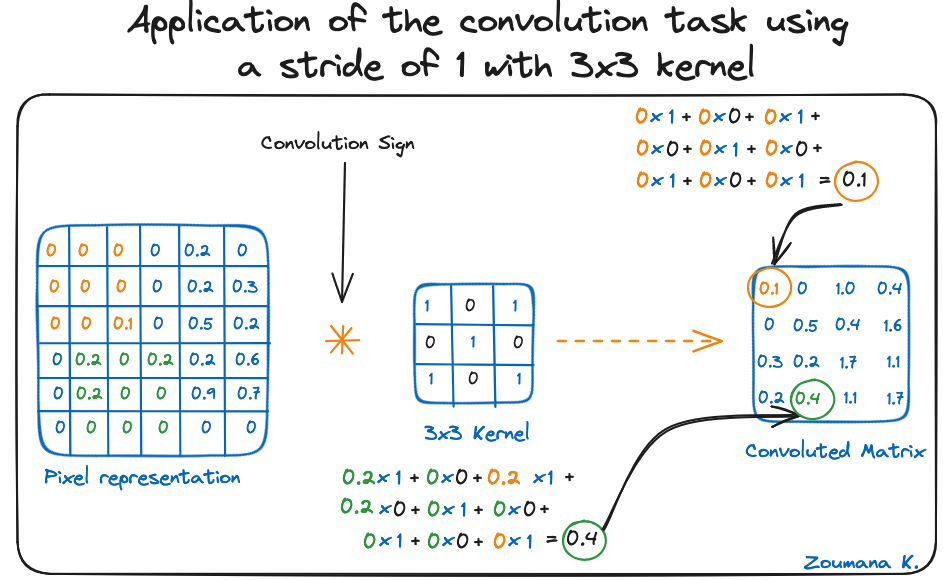
Áp dụng phép tích chập với bước trượt 1 và kernel 3x3
Một tên gọi khác liên quan đến kernel trong tài liệu là bộ dò đặc trưng vì các trọng số có thể được tinh chỉnh để phát hiện các đặc trưng cụ thể trong ảnh đầu vào.
Chẳng hạn:
Số tầng tích chập càng nhiều, khả năng phát hiện các đặc trưng trừu tượng càng tốt.
Một hàm kích hoạt ReLU được áp dụng sau mỗi phép tích chập. Hàm này giúp mạng học các quan hệ phi tuyến giữa các đặc trưng trong ảnh, nhờ đó mạng vững vàng hơn khi nhận diện các mẫu khác nhau. Nó cũng giúp giảm vấn đề tiêu biến gradient.
Mục tiêu của tầng pooling là rút ra các đặc trưng quan trọng nhất từ ma trận sau tích chập. Điều này được thực hiện bằng cách áp dụng các phép tổng hợp, giúp giảm kích thước bản đồ đặc trưng (ma trận sau tích chập), từ đó giảm bộ nhớ dùng khi huấn luyện mạng. Pooling cũng hữu ích để giảm overfitting.
Những hàm tổng hợp phổ biến có thể áp dụng gồm:
Dưới đây là minh hoạ cho từng ví dụ trước đó:
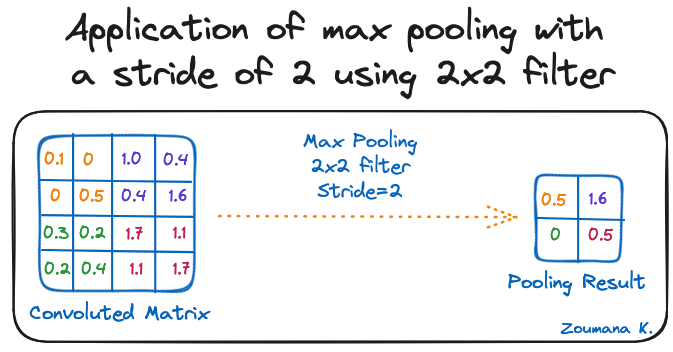
Áp dụng max pooling với bước trượt 2 và bộ lọc 2x2
Ngoài ra, kích thước bản đồ đặc trưng sẽ nhỏ dần khi áp dụng hàm pooling.
Tầng pooling cuối cùng sẽ làm phẳng bản đồ đặc trưng để có thể được xử lý bởi tầng kết nối đầy đủ.
Những tầng này nằm ở phần cuối của mạng nơ-ron tích chập, và đầu vào của chúng là ma trận một chiều đã được làm phẳng do tầng pooling cuối tạo ra. Hàm kích hoạt ReLU được áp dụng để tạo phi tuyến.
Cuối cùng, một tầng dự đoán softmax được dùng để tạo ra giá trị xác suất cho từng nhãn đầu ra có thể, và nhãn cuối cùng được dự đoán là nhãn có điểm xác suất cao nhất.
Overfitting là một thách thức phổ biến trong các mô hình học máy và các dự án học sâu với CNN. Nó xảy ra khi mô hình học quá kỹ dữ liệu huấn luyện (“học thuộc lòng”), bao gồm cả nhiễu và ngoại lai. Việc học như vậy dẫn đến mô hình hoạt động tốt trên dữ liệu huấn luyện nhưng kém trên dữ liệu mới, chưa thấy.
Điều này có thể quan sát khi mô hình đạt độ chính xác cao hơn đáng kể trên dữ liệu huấn luyện so với dữ liệu xác thực hoặc kiểm thử, và hình minh hoạ dưới đây cho thấy điều đó:
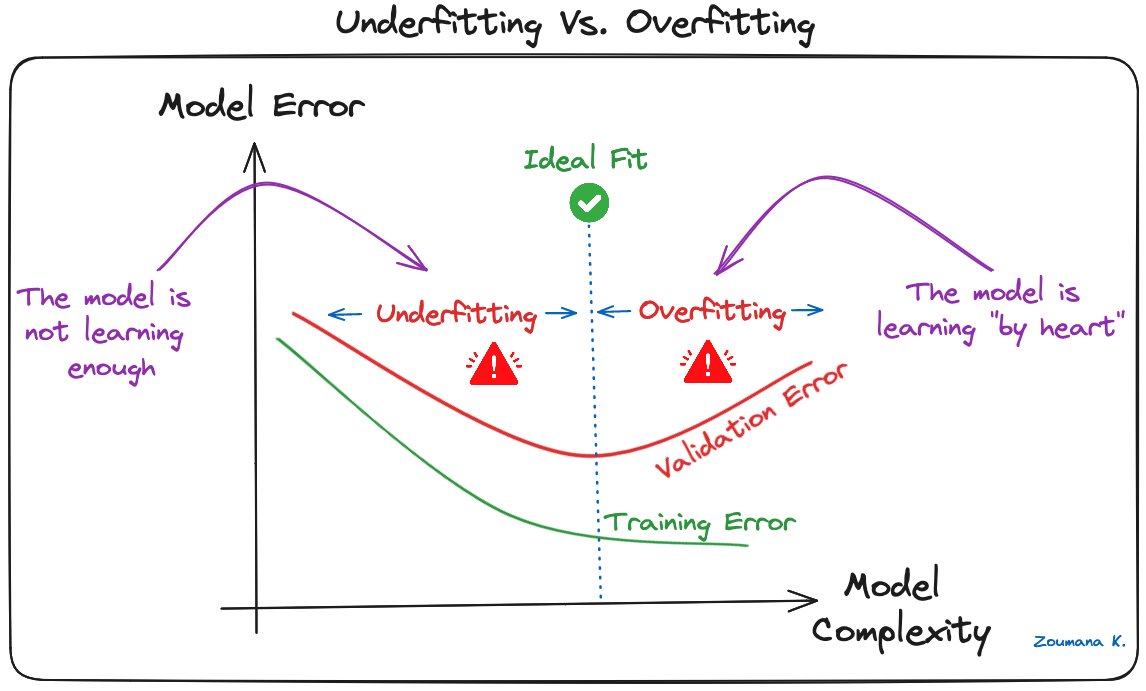
Underfitting so với Overfitting
Các mô hình học sâu, đặc biệt là CNN, đặc biệt dễ bị overfitting do khả năng biểu diễn phức tạp cao và khả năng học các mẫu chi tiết trong dữ liệu quy mô lớn.
Nhiều kỹ thuật regularization có thể áp dụng để giảm overfitting trong CNN, một số được minh hoạ dưới đây:
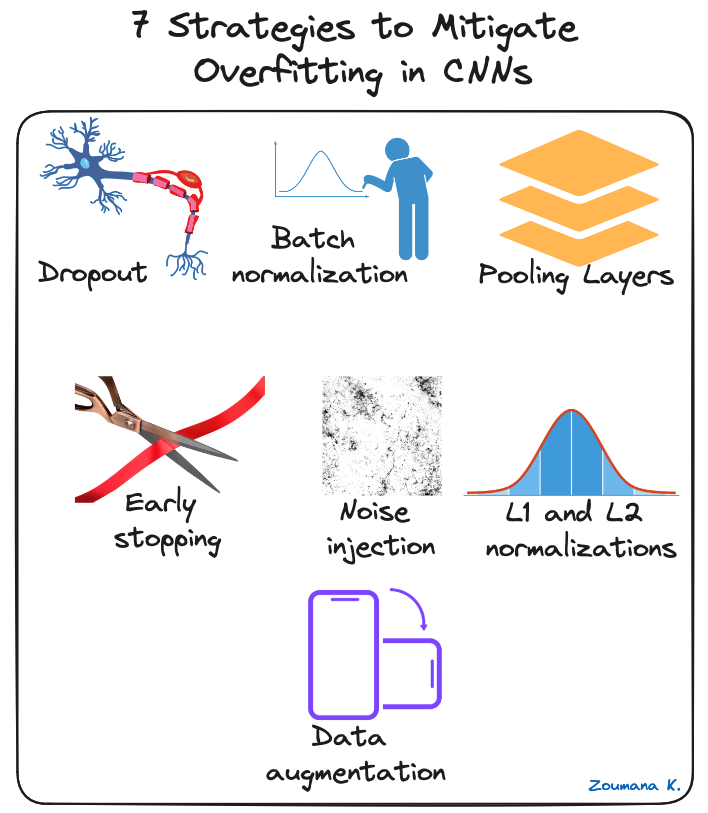
7 chiến lược giảm overfitting trong CNN
Mạng nơ-ron tích chập đã cách mạng hóa lĩnh vực thị giác máy tính, dẫn đến những tiến bộ đáng kể trong nhiều ứng dụng đời thực. Dưới đây là một vài ví dụ về cách chúng được áp dụng.
Một số ứng dụng thực tiễn của CNN
Để triển khai thực hành, Hướng dẫn CNN với TensorFlow của chúng tôi dạy cách xây dựng và triển khai CNN trong Python với TensorFlow 2.
Qua nhiều năm, các nhà nghiên cứu đã phát triển những kiến trúc CNN ngày càng mạnh. Dưới đây là một số kiến trúc có ảnh hưởng nhất:
Dù Vision Transformer (ViT) đã nổi lên như lựa chọn mạnh kể từ 2020, CNN vẫn được dùng rộng rãi nhờ hiệu quả, yêu cầu dữ liệu thấp hơn và độ chín trong môi trường sản xuất.
Sự phát triển nhanh của học sâu chủ yếu nhờ các framework mạnh như TensorFlow, PyTorch và Keras, giúp việc huấn luyện CNN và các mô hình học sâu khác trở nên dễ dàng hơn.
Hãy điểm qua ngắn gọn từng framework.
TensorFlow là framework học sâu mã nguồn mở do Google phát triển và phát hành năm 2015. Nó cung cấp một loạt công cụ cho phát triển và triển khai học máy. Giới thiệu về Mạng nơ-ron Sâu của chúng tôi cung cấp hướng dẫn đầy đủ để hiểu mạng nơ-ron sâu và tầm quan trọng của chúng trong thế giới AI học sâu hiện đại, cùng các triển khai thực tế trong TensorFlow.
Keras là framework mạng nơ-ron cấp cao trong Python, cho phép thử nghiệm và phát triển nhanh. Nó là mã nguồn mở và là API cấp cao chính thức của TensorFlow (từ phiên bản 2.0), giúp tinh gọn phát triển mô hình trong hệ sinh thái TensorFlow. Khóa học Xử lý ảnh với Keras trong Python của chúng tôi dạy cách phân tích ảnh bằng Keras với Python bằng cách xây dựng, huấn luyện và đánh giá CNN.
Phát hành bởi Meta (trước đây là Facebook) AI Research năm 2017, PyTorch là framework học sâu đa dụng, nổi tiếng với đồ thị tính toán động, cú pháp đậm chất Python và cộng đồng nghiên cứu mạnh. Nếu bạn muốn tìm hiểu xử lý ngôn ngữ tự nhiên, NLP với PyTorch: Hướng dẫn Toàn diện của chúng tôi là điểm khởi đầu tuyệt vời.
Mỗi dự án đều khác nhau, nên quyết định phụ thuộc vào những đặc điểm quan trọng nhất cho trường hợp sử dụng cụ thể. Để hỗ trợ ra quyết định tốt hơn, bảng sau cung cấp so sánh ngắn giữa các framework này, làm nổi bật các tính năng độc đáo.
Tensorflow | Pytorch | Keras | |
Cấp độ API | Cả hai (Cao và Thấp) | Thấp | Cao |
Kiến trúc | Không dễ dùng | Cú pháp đậm chất Python, trực quan | Đơn giản, súc tích, dễ đọc |
Tập dữ liệu | Tập lớn, hiệu năng cao | Tập lớn, hiệu năng cao | Tập nhỏ hơn |
Gỡ lỗi | Khó gỡ lỗi | Khả năng gỡ lỗi tốt | Mạng đơn giản nên thường ít cần gỡ lỗi |
Mô hình tiền huấn luyện? | Có | Có | Có |
Độ phổ biến | Phổ biến thứ hai trong ba cái | Được dùng rộng rãi nhất cho nghiên cứu và ngày càng nhiều trong sản xuất | Tích hợp vào TensorFlow như API cấp cao chính thức |
Tốc độ | Nhanh, hiệu năng cao | Nhanh, hiệu năng cao | Tương tự TensorFlow (chạy trên backend TF) |
Viết bằng | C++, CUDA, Python | C++, Python | Python |
Bảng so sánh giữa Tensorflow, Pytorch và Keras (nguồn)
Bài viết này đã cung cấp cái nhìn tổng quan đầy đủ về CNN trong học sâu, cùng vai trò quan trọng của chúng trong các tác vụ nhận dạng và phân loại ảnh.
Bài viết bắt đầu bằng việc nêu bật cảm hứng từ hệ thị giác người cho thiết kế của CNN rồi khám phá các thành phần chính cho phép các mạng này học và đưa ra dự đoán.
Vấn đề overfitting được thừa nhận là một thách thức đáng kể đối với khả năng khái quát của CNN. Để giảm thiểu, bài viết đã liệt kê nhiều chiến lược phù hợp nhằm giảm overfitting và cải thiện hiệu năng tổng thể của CNN.
Cuối cùng, một số framework CNN học sâu quan trọng đã được nhắc tới, cùng các tính năng độc đáo của từng cái và cách chúng so sánh với nhau.
Háo hức khám phá sâu hơn thế giới AI và học máy? Nâng tầm chuyên môn của bạn bằng cách ghi danh khóa học Học sâu với PyTorch ngay hôm nay.
Bắt đầu hành trình Học sâu của bạn ngay hôm nay!
Courses
Courses
Courses