Course
Introduction to Deep Learning in Python
4 hr
263.6K
There are several reasons why CNNs are important in the modern world, as highlighted below:
Convolutional neural networks were inspired by the layered architecture of the human visual cortex, and below are some key similarities and differences:
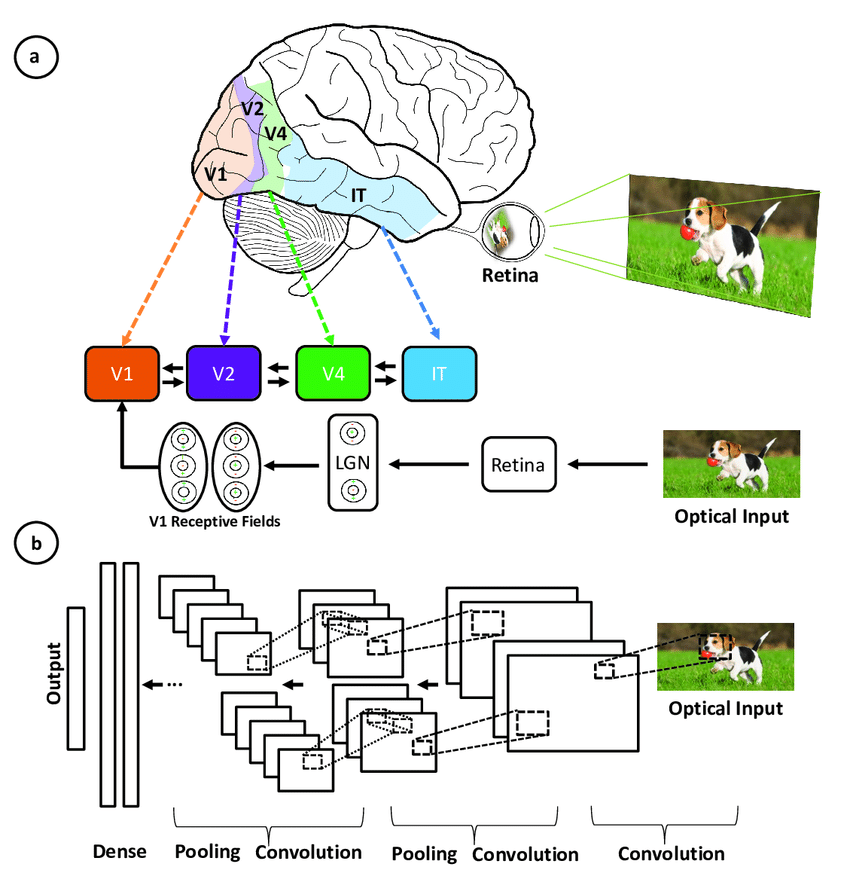
Illustration of the correspondence between the areas associated with the primary visual cortex and the layers in a convolutional neural network (source)
CNNs mimic the human visual system but are simpler, lacking its complex feedback mechanisms and relying on supervised learning rather than unsupervised, driving advances in computer vision despite these differences.
The convolutional neural network is made of four main parts.
But how do CNNs Learn with those parts?
They help the CNNs mimic how the human brain operates to recognize patterns and features in images:
This section dives into the definition of each one of these components through the following example of classifying a handwritten digit.
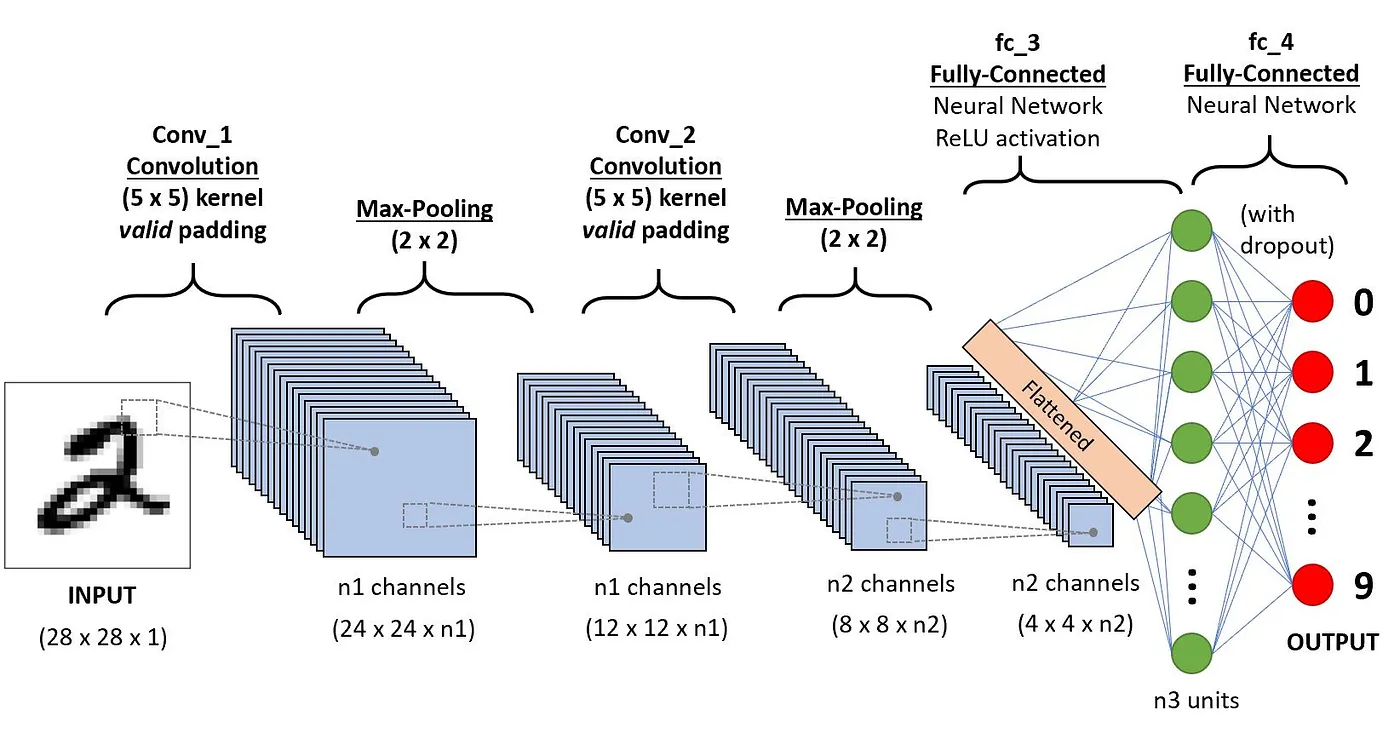
Architecture of the CNNs applied to digit recognition (source)
This is the first building block of a CNN. As the name suggests, the main mathematical task performed is called convolution, which is the application of a sliding window function to a matrix of pixels representing an image. The sliding function applied to the matrix is called kernel or filter, and both can be used interchangeably.
In the convolution layer, several filters of equal size are applied, and each filter is used to recognize a specific pattern from the image, such as the curving of the digits, the edges, the whole shape of the digits, and more.
Put simply, in the convolution layer, we use small grids (called filters or kernels) that move over the image. Each small grid is like a mini magnifying glass that looks for specific patterns in the photo, like lines, curves, or shapes. As it moves across the photo, it creates a new grid that highlights where it found these patterns.
For example, one filter might be good at finding straight lines, another might find curves, and so on. By using several different filters, the CNN can get a good idea of all the different patterns that make up the image.
Let’s consider this 32x32 grayscale image of a handwritten digit. The values in the matrix are given for illustration purposes.
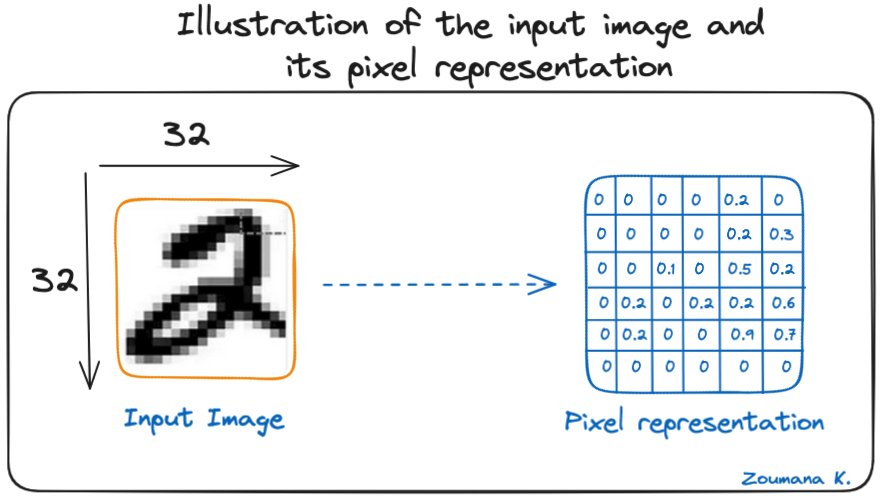
Illustration of the input image and its pixel representation
Also, let’s consider the kernel used for the convolution. It is a matrix with a dimension of 3x3. The weights of each element of the kernel is represented in the grid. Zero weights are represented in the black grids and ones in the white grid.
Do we have to manually find these weights?
In real life, the weights of the kernels are determined during the training process of the neural network.
Using these two matrices, we can perform the convolution operation by applying the dot product, and work as follows:
The dimension of the convoluted matrix depends on the size of the sliding window. The higher the sliding window, the smaller the dimension.
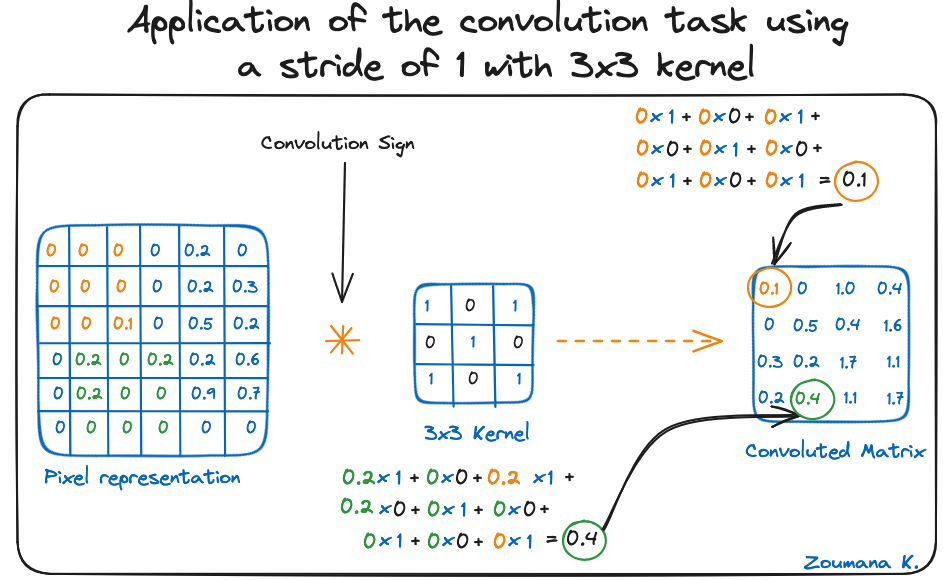
Application of the convolution task using a stride of 1 with 3x3 kernel
Another name associated with the kernel in the literature is feature detector because the weights can be fine-tuned to detect specific features in the input image.
For instance:
The more convolution layers the network has, the better the layer is at detecting more abstract features.
A ReLU activation function is applied after each convolution operation. This function helps the network learn non-linear relationships between the features in the image, hence making the network more robust for identifying different patterns. It also helps to mitigate the vanishing gradient problems.
The goal of the pooling layer is to pull the most significant features from the convoluted matrix. This is done by applying some aggregation operations, which reduce the dimension of the feature map (convoluted matrix), hence reducing the memory used while training the network. Pooling is also relevant for mitigating overfitting.
The most common aggregation functions that can be applied are:
Below is an illustration of each of the previous example:
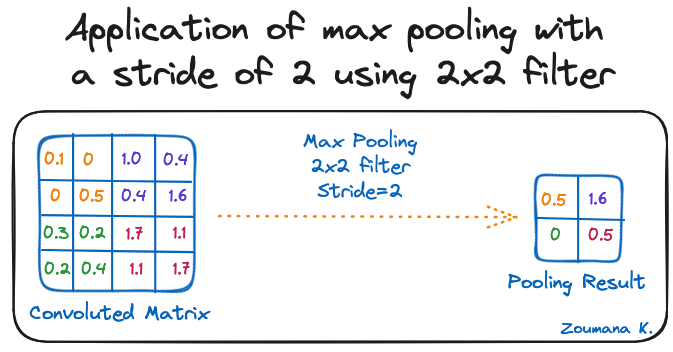
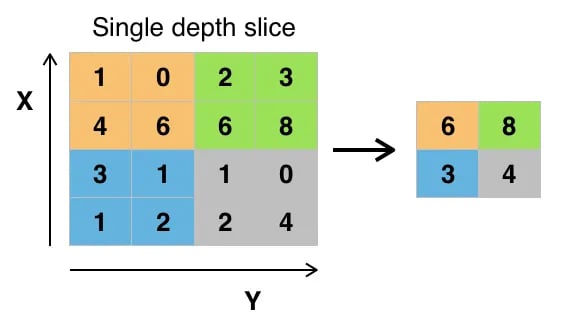
Application of max pooling with a stride of 2 using 2x2 filter
Also, the dimension of the feature map becomes smaller as the pooling function is applied.
The last pooling layer flattens its feature map so that it can be processed by the fully connected layer.
These layers are in the last layer of the convolutional neural network, and their inputs correspond to the flattened one-dimensional matrix generated by the last pooling layer. ReLU activations functions are applied to them for non-linearity.
Finally, a softmax prediction layer is used to generate probability values for each of the possible output labels, and the final label predicted is the one with the highest probability score.
Overfitting is a common challenge in machine learning models and CNN deep learning projects. It happens when the model learns the training data too well (“learning by heart”), including its noise and outliers. Such a learning leads to a model that performs well on the training data but badly on new, unseen data.
This can be observed when the model achieves significantly higher accuracy on training data compared to validation or testing data, and a graphical illustration is given below:
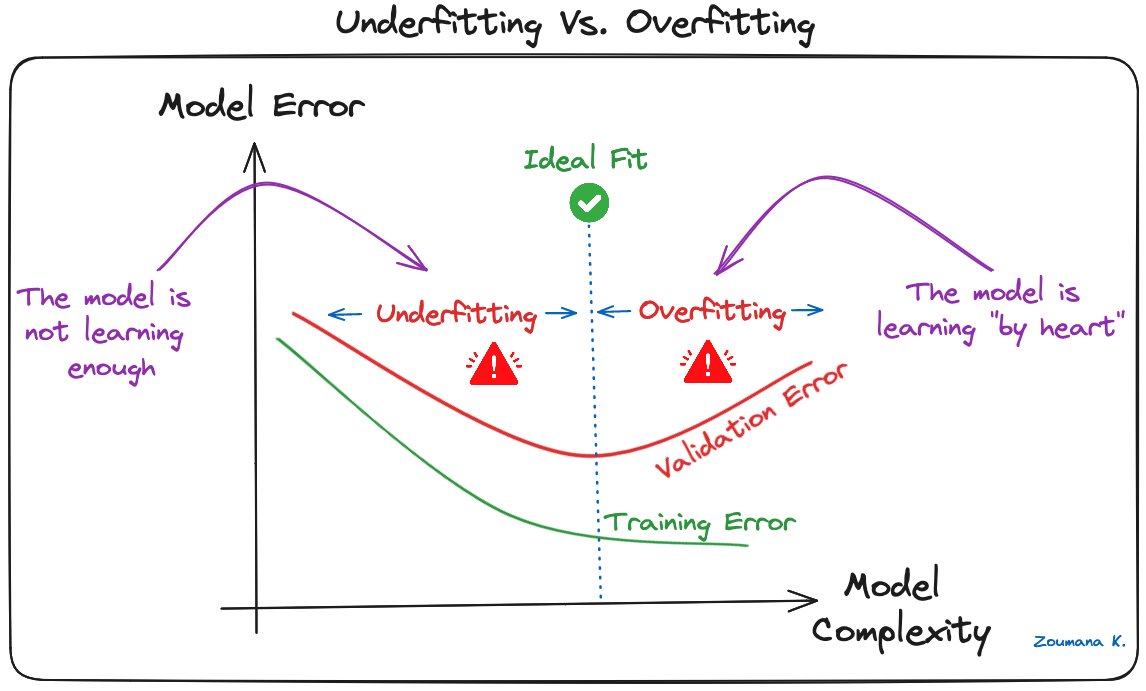
Underfitting Vs. Overfitting
Deep learning models, especially Convolutional Neural Networks (CNNs), are particularly susceptible to overfitting due to their capacity for high complexity and their ability to learn detailed patterns in large-scale data.
Several regularization techniques can be applied to mitigate overfitting in CNNs, and some are illustrated below:
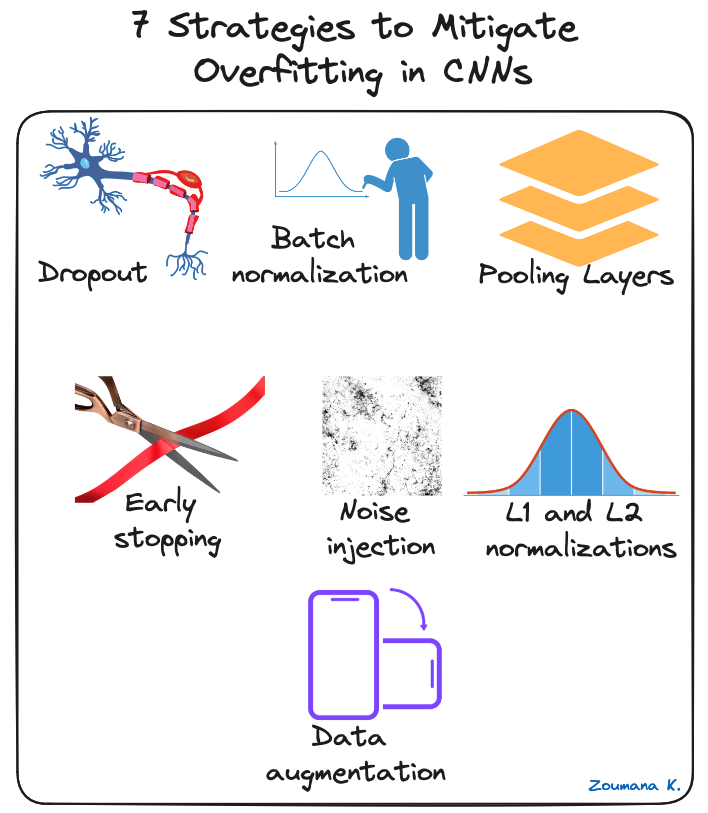
7 strategies to mitigate overfitting in CNNs
Convolutional Neural Networks have revolutionized the field of computer vision, leading to significant advancements in many real-world applications. Below are a few examples of how they are applied.
Some practical applications of CNNs
For a more hands-on implementation, our Convolutional Neural Networks (CNN) with TensorFlow Tutorial teaches how to construct and implement CNNs in Python with TensorFlow 2.
Over the years, researchers have developed increasingly powerful CNN architectures. Here are some of the most influential ones:
While Vision Transformers (ViTs) have emerged as strong alternatives since 2020, CNNs remain widely used due to their efficiency, lower data requirements, and maturity in production environments.
The rapid growth of deep learning is mainly due to powerful frameworks like Tensorflow, Pytorch, and Keras, which make it easier to train convolutional neural networks and other deep learning models.
Let’s have a brief overview of each framework.
TensorFlow is an open-source deep learning framework developed by Google and released in 2015. It offers a range of tools for machine learning development and deployment. Our Introduction to Deep Neural Networks provides a complete guide to understanding deep neural networks and their significance in the modern deep learning world of artificial intelligence, along with real-world implementations in TensorFlow.
Keras is a high-level neural network framework in Python that enables rapid experimentation and development. It's open-source and serves as TensorFlow's official high-level API (since version 2.0), streamlining model development in the TensorFlow ecosystem. Our course, Image Processing with Keras in Python, teaches how to conduct image analysis using Keras with Python by constructing, training, and evaluating convolutional neural networks.
Released by Meta (formerly Facebook) AI Research in 2017, PyTorch is a general-purpose deep learning framework known for its dynamic computational graph, Pythonic syntax, and strong research community. If you are interested in diving into natural language processing, our NLP with PyTorch: A Comprehensive Guide is a great starting point.
Each project is different, so the decision really depends on what characteristics are most important for a given use case. To help make better decisions, the following table provides a brief comparison of these frameworks, highlighting their unique features.
Tensorflow | Pytorch | Keras | |
API Level | Both (High and Low) | Low | High |
Architecture | Not easy to use | Pythonic, intuitive syntax | Simple, concise, readable |
Datasets | Large datasets, high performance | Large datasets, high performance | Smaller datasets |
Debugging | Difficult to conduct debugging | Good debugging capabilities | Simple network, so debugging is not often needed |
Pretrained models? | Yes | Yes | Yes |
Popularity | Second most popular of the three | Most widely used for research and increasingly for production | Integrated into TensorFlow as its official high-level API |
Speed | Fast, high-performance | Fast, high-performance | Same as TensorFlow (runs on TF backend) |
Written in | C++, CUDA, Python | C++, Python | Python |
Comparative table between Tensorflow, Pytorch and Keras (source)
This article has provided a complete overview of what a CNN in deep learning is, along with their crucial role in image recognition and classification tasks.
It started by highlighting the inspiration drawn from the human visual system for the design of CNNs and then explored the key components that allow these networks to learn and make predictions.
The issue of overfitting was acknowledged as a significant challenge to CNNs' generalization capability. To mitigate this, a variety of relevant strategies to mitigate overfitting and improve CNNs overall performance were outlined.
Finally, some major deep learning CNN frameworks have been mentioned, along with the unique features of each one and how they compare to each other.
Eager to dive further into the world of AI, and machine learning? Take your expertise to the next level by enrolling in the Deep Learning with PyTorch course today.
Start Your Deep Learning Journey Today!
Course
Course
Course
blog
Abid Ali Awan
7 min
Tutorial
Aditya Sharma
Tutorial
Zoumana Keita
Tutorial
Bharath K
Tutorial
Javier Canales Luna
Tutorial
Sejal Jaiswal