
Kursus
Analisis Data Eksploratori dengan R
4 Hr
118.1K
Saat menafsirkan data, memilih ukuran pemusatan yang tepat dapat menentukan kualitas analisis Anda. Di antara metrik yang paling umum adalah mean dan median, dua konsep yang tampak sederhana namun membawa implikasi mendalam dalam penafsiran data. Sementara mean memberi kita rata-rata aritmetika, median adalah titik tengah dalam sekumpulan nilai yang diurutkan, sehingga separuh pengamatan berada di masing-masing sisi. Namun, mana yang lebih andal? Jawabannya sering bergantung pada distribusi data Anda, keberadaan pencilan (outlier), dan cerita yang ingin Anda sampaikan.
Dalam artikel ini, saya akan menguraikan perbedaan antara mean dan median, kelebihan dan kekurangannya, serta cara memilih yang tepat untuk berbagai skenario. Saya juga akan membahas bagaimana distribusi yang miring (skew) dan pencilan memengaruhi ukuran-ukuran ini, dengan contoh praktis dan visual untuk membantu Anda memahami konsep dasar ini. Kita juga akan menyinggung beberapa gagasan yang lebih lanjut.
Untuk benar-benar memahami perbedaan antara mean dan median, mari kita lihat masing-masing ukuran ini dan soroti sifat kuncinya.
Mean dapat dipandang sebagai "titik keseimbangan" (atau pusat massa) dari data. Mean mempertimbangkan semua titik data dalam suatu himpunan data dan memberikan satu nilai yang merepresentasikan rata-rata. Lebih tepatnya, mean dihitung dengan menjumlahkan semua nilai dalam suatu himpunan data lalu membaginya dengan jumlah nilai.
Median adalah nilai tengah ketika data diurutkan. Berbeda dengan mean, median lebih tangguh terhadap pencilan, sehingga memberikan ukuran pemusatan yang lebih baik untuk data yang miring.
Modus adalah ukuran pemusatan lainnya, yang merepresentasikan nilai yang paling sering muncul dalam suatu himpunan data. Mari kita lihat contoh:
3, 3, 6, 8, 9Di sini, modusnya adalah 3 karena muncul dua kali, sementara nilai lainnya hanya muncul sekali.
Membaca definisi itu satu hal, tetapi menghitungnya adalah hal lain. Pada bagian ini, saya akan menguraikan langkah-langkah menghitung masing-masing ukuran dan menyoroti perbedaannya secara komputasional.
Mean adalah rata-rata aritmetika dari suatu himpunan data dan dihitung sebagai berikut:
Berikut prosesnya direpresentasikan sebagai persamaan umum:
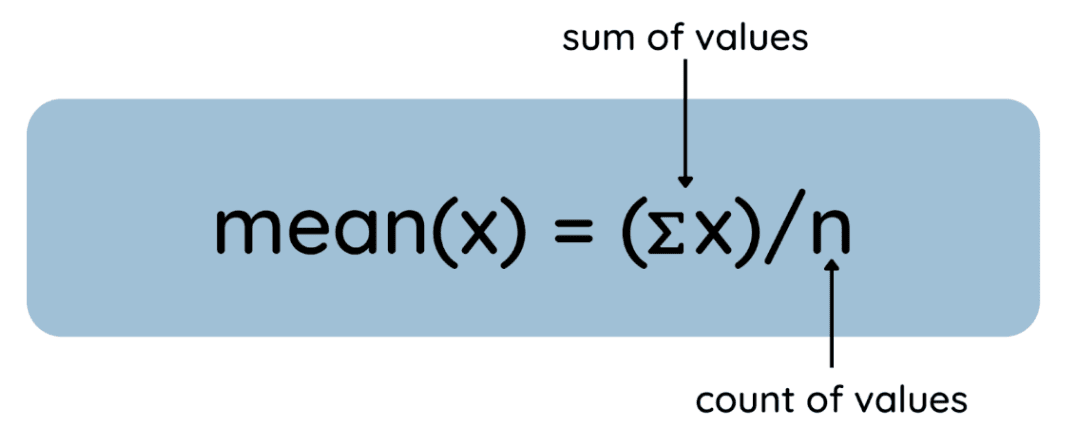
Cara mencari mean. Gambar oleh Penulis
Sebagai contoh, pertimbangkan himpunan data nilai ujian:
78, 85, 92, 88, 70Nilai mean adalah 82,6.
Median adalah nilai tengah dari suatu himpunan data ketika diurutkan secara naik. Begini cara menemukannya:
Dan berikut langkah-langkah tersebut direpresentasikan sebagai persamaan:
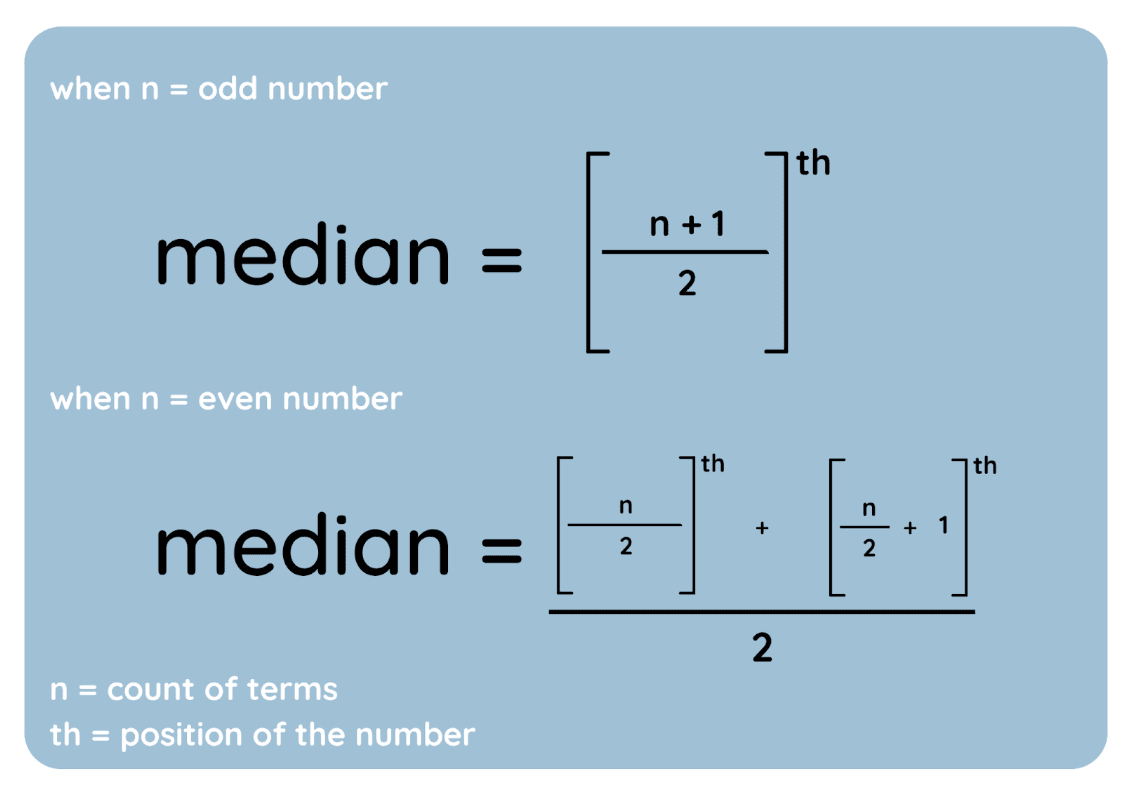
Rumus median. Gambar oleh Penulis
Saya juga membuat visual untuk menyoroti prosesnya.
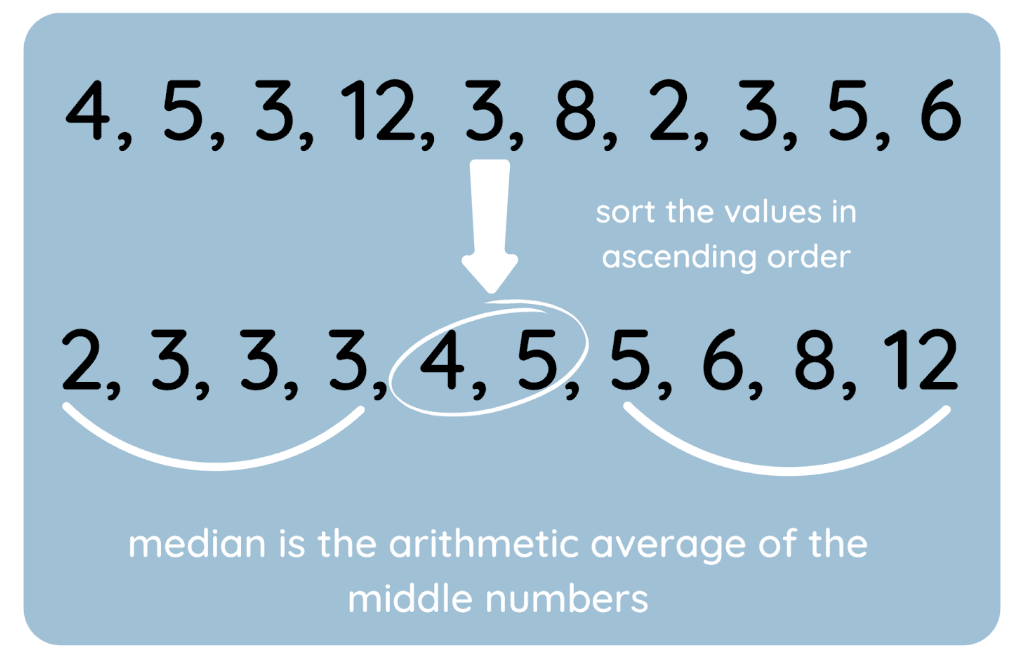
Cara mencari median. Gambar oleh Penulis
Berikut contoh himpunan data dengan jumlah nilai ganjil:
70, 78, 85, 88, 92Median adalah 85.
Berikut contoh lain, tetapi dengan jumlah nilai genap:
70, 78, 85, 88Median adalah 81,5.
Walaupun mean dan median sama-sama menggambarkan pusat suatu himpunan data, perilakunya berbeda secara signifikan ketika terdapat pencilan dan distribusi yang miring. Memahami perbedaan ini sangat penting untuk menafsirkan data secara akurat dan menghindari kesimpulan yang menyesatkan.
Pencilan adalah nilai yang jauh lebih tinggi atau lebih rendah dibandingkan data lainnya. Pencilan dapat sangat memengaruhi mean tetapi hampir tidak memengaruhi median.
Mari kita pertimbangkan himpunan data pendapatan bulanan (dalam ribuan):
3, 3.5, 4, 4.5, 5, 6, 50Mean pendapatan di sini adalah 10,85k, yang sangat terdistorsi oleh nilai ekstrem 50k.
Di sisi lain, nilai median adalah 4,5k, yang, menurut saya, jauh lebih mewakili pendapatan khas untuk kelompok ini.
Mean dan median juga berbeda dalam merepresentasikan data pada distribusi yang miring (himpunan data yang tidak simetris).
Sebagai contoh, pada distribusi kemencengan ke kanan (misalnya, pendapatan atau harga rumah), sebagian besar nilai berkelompok di ujung bawah, dengan beberapa nilai ekstrem menarik ekor ke kanan.
Pertimbangkan pendapatan:
30k, 35k, 40k, 45k, 50k, 100k, 200kSatu hal yang perlu Anda ingat adalah penting untuk selalu memeriksa distribusi data sebelum memutuskan apakah akan menggunakan mean atau median. Alat seperti histogram dan box plot dapat membantu memvisualisasikan kemencengan dan mengidentifikasi pencilan. Kita akan membahas ini nanti. Juga, saya ingin mengatakan bahwa memeriksa perbedaan antara mean dan median adalah salah satu cara menilai kemencengan.
Saat menganalisis data, keputusan untuk menggunakan mean atau median bergantung pada karakteristik himpunan data Anda dan wawasan yang ingin Anda peroleh. Berikut tabel referensi cepat untuk memandu pilihan Anda:
| Gunakan Mean Ketika | Gunakan Median Ketika |
|---|---|
| Distribusi data kira-kira normal (simetris). | Data sangat miring (misalnya, pendapatan, nilai properti). |
| Pencilan minimal atau tidak relevan bagi analisis. | Ada pencilan yang dapat mendistorsi hasil jika disertakan. |
| Anda memerlukan ukuran yang sensitif terhadap setiap titik data, seperti dalam pemodelan prediktif atau saat menghitung total. | Anda ingin mencerminkan nilai "tipikal" alih-alih "pusat matematis" dari himpunan data. |
Berikut kiat praktis yang sangat membantu: Selalu mulai dengan analisis visual data Anda (misalnya, histogram atau box plot) untuk memeriksa simetri, kemencengan, dan keberadaan pencilan. Ini akan membantu Anda memutuskan apakah mean atau median lebih sesuai untuk skenario Anda.
Visualisasi adalah alat yang kuat untuk memahami perilaku mean dan median pada berbagai himpunan data. Visualisasi dapat dengan jelas menunjukkan bagaimana ukuran-ukuran ini merespons pencilan dan distribusi yang miring, sehingga membantu pengambilan keputusan berbasis data yang lebih baik.
Bayangkan himpunan data kecil tentang pendapatan dalam ribuan:
30, 35, 40, 45, 50, 55, 1000Diagram batang berikut menunjukkan bagaimana satu nilai ekstrem dapat sangat memengaruhi mean, sementara median relatif stabil. Dalam kasus ini, sebagian besar titik data berkelompok antara 30 dan 55, tetapi keberadaan pencilan (1000) menarik mean ke atas.
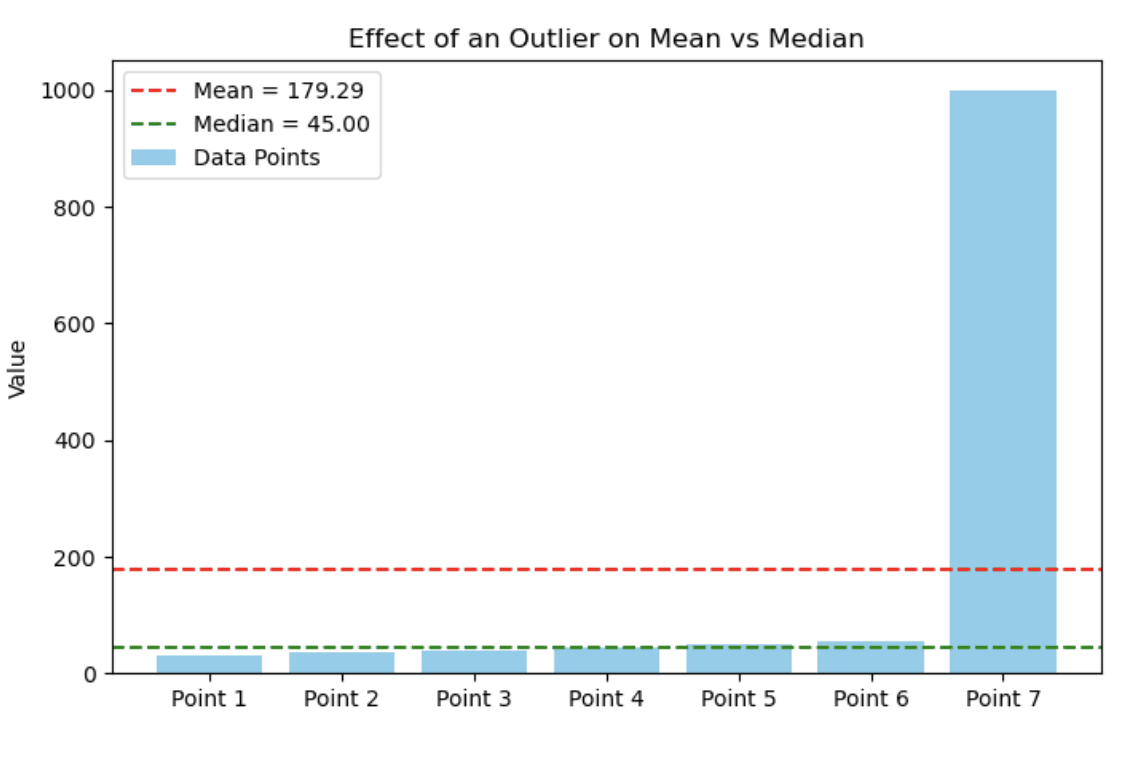
Diagram batang yang menunjukkan efek pencilan pada mean vs. median. Gambar oleh Penulis
Pada distribusi miring ke kanan (seperti pendapatan atau harga rumah), mean sering tertarik ke ekor panjang dari nilai-nilai tinggi, sementara median tetap lebih dekat ke titik data "tipikal". Hal ini membuat median menjadi ukuran pemusatan yang lebih baik dalam kasus seperti ini.
Histogram di bawah ini menunjukkan distribusi pendapatan simulasi di mana mean (garis putus-putus merah) secara signifikan lebih besar daripada median (garis putus-putus hijau) karena kemencengan.
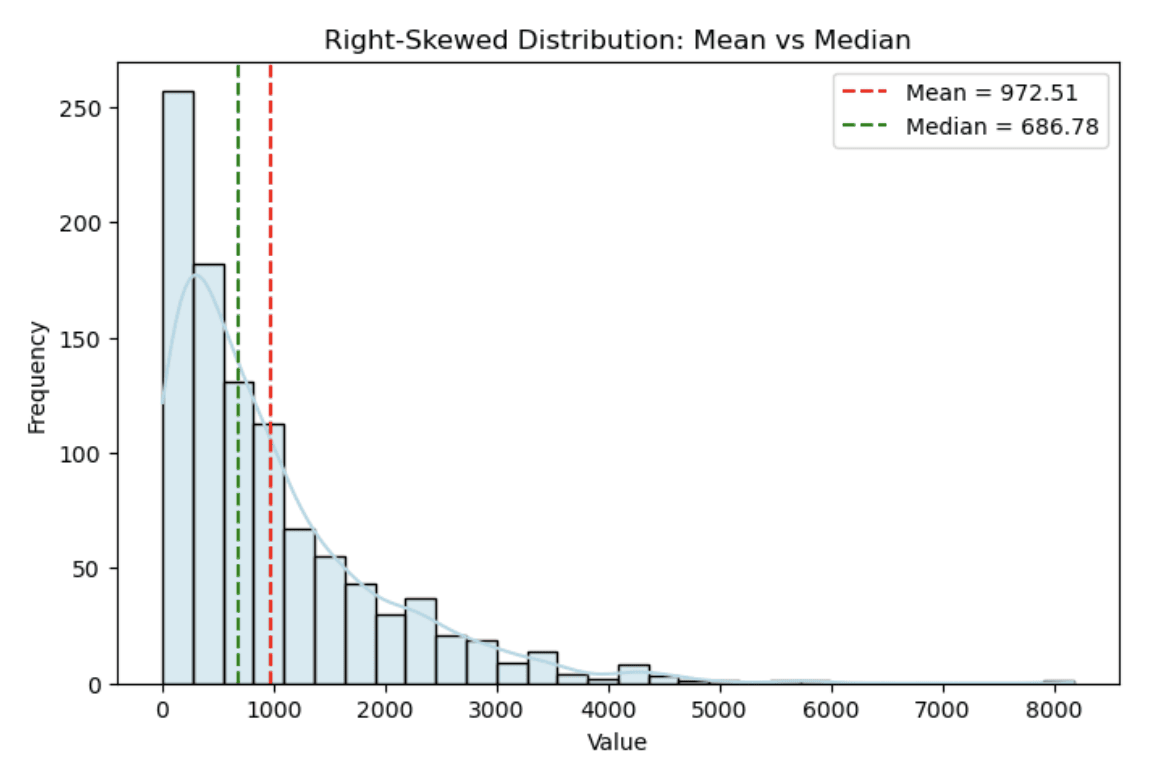
Histogram yang menunjukkan distribusi miring ke kanan. Gambar oleh Penulis
Anda dapat melihat bagaimana kemencengan ke kanan memperpanjang ekor, menciptakan perbedaan yang jelas antara mean dan median.
Box plot adalah cara yang sangat baik untuk memvisualisasikan dampak pencilan pada median. Di bawah ini, kita membandingkan dua kelompok: satu dengan pencilan dan satu tanpa. Median (garis vertikal di dalam kotak) tetap stabil meskipun terdapat nilai ekstrem, tetapi rentang keseluruhan data sangat dipengaruhi oleh pencilan.
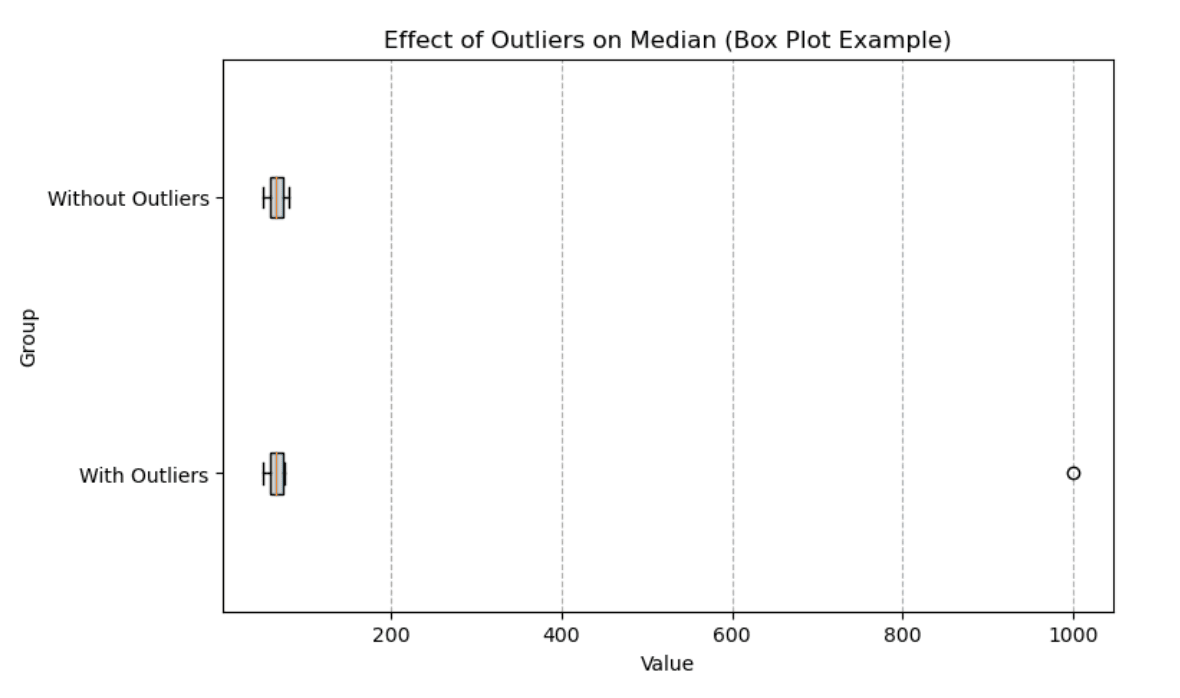
Box plot yang menunjukkan efek pencilan pada median. Gambar oleh Penulis
Visualisasi ini menyoroti bagaimana mean dan median merespons karakteristik data yang berbeda, memberikan kejelasan tentang kapan menggunakan masing-masing ukuran. Baik saat menganalisis data yang miring, himpunan data yang rawan pencilan, atau membandingkan kelompok, alat bantu visual seperti ini dapat memudahkan pemahaman hubungan yang kompleks.
Mari sekarang melihat beberapa gagasan yang lebih lanjut jika Anda ingin belajar lebih jauh.
Sekarang, jika Anda seorang data scientist dan perlu mengisi celah dalam data, Anda mungkin harus memilih metode imputasi. Anda mungkin bertanya-tanya, apa perbedaan praktis antara imputasi mean vs. median?
Seperti yang dapat Anda duga, imputasi mean menggantikan nilai yang hilang dengan rata-rata dari data yang tersedia, yang, seperti telah kita katakan, dapat terdistorsi oleh nilai ekstrem. Imputasi median, sebaliknya, menggantikan nilai yang hilang dengan nilai tengah dari himpunan data.
Aturan praktis yang berguna adalah melihat distribusi data Anda. Jika distribusi data Anda miring dengan banyak nilai yang hilang, dan Anda menggunakan imputasi mean, maka Anda mungkin telah mengubah distribusi data Anda!
Tetapi ingat juga bahwa imputasi satu nilai (mean atau median) dapat mengecilkan varians dan melemahkan hubungan antarkomponen variabel. Jika nilai yang hilang cukup banyak, pertimbangkan multiple imputation atau imputasi berbasis model untuk lebih mempertahankan ketidakpastian dan struktur.
Dalam banyak metode parametrik, mean (dan varians) adalah parameter utama. Misalnya, sebuah model regresi linear sederhana mengasumsikan galat terdistribusi normal di sekitar mean. Ketika data Anda memenuhi asumsi kenormalan, mean sampel adalah penaksir yang alami dan sesuai dalam kerangka parametrik.
Sekarang, median sering digunakan dalam pengaturan yang robust dan non-parametrik, dan merupakan pilihan umum ketika data miring atau mengandung pencilan. Banyak uji, seperti uji Mann–Whitney, berbasis peringkat dan membandingkan distribusi (sering diinterpretasikan sebagai pergeseran lokasi di bawah asumsi) alih-alih mean, dan tidak selalu menguji perbedaan median.
Semua ini untuk mengatakan bahwa memahami perbedaan antara mean vs. median bukan hanya soal mendeskripsikan data dengan benar, tetapi juga penting dalam pengujian hipotesis.
Saat memutuskan apakah akan menggunakan mean atau median, salah satu pertanyaan kunci adalah seberapa stabil statistik kita untuk suatu himpunan data. Bootstrapping adalah salah satu opsi yang memungkinkan kita memperkirakan secara empiris distribusi penarikan sampel dari mean dan median dengan berulang kali melakukan resampling (dengan pengembalian) dari data asli.
Anda dapat menyoroti perbedaan stabilitas mean dan median secara empiris. Anda bisa memasukkan beberapa pencilan ke dalam himpunan data lalu menjalankan ulang prosedur bootstrap, sehingga memungkinkan Anda menunjukkan secara visual bagaimana distribusi mean bergeser lebih dramatis dibanding median. Selain itu, bootstrapping dapat memperjelas dengan menunjukkan seberapa besar atau kecil interval kepercayaan Anda dalam skenario realistis. Baca tutorial kami tentang penerapan metode bootstrap untuk mempelajari lebih lanjut.
Izinkan saya memberikan definisi alternatif namun sama benarnya: Mean adalah nilai yang meminimalkan jumlah deviasi kuadrat dari data, sedangkan median adalah nilai yang meminimalkan jumlah deviasi absolut.
Perhatikan persamaan ini:
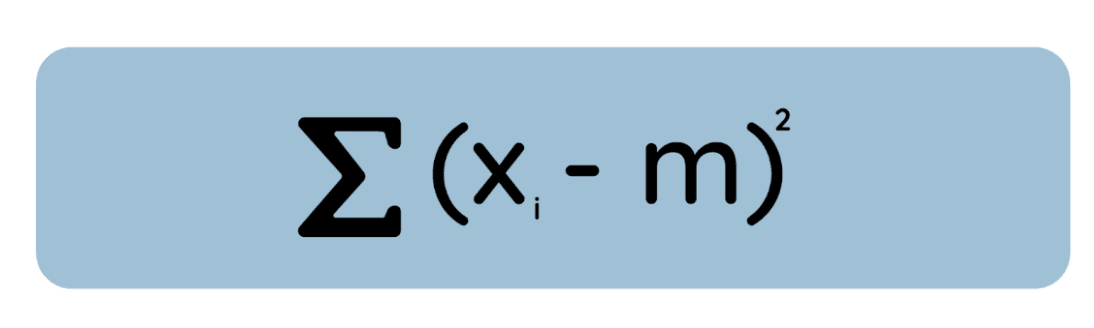
Jika Anda mengambil turunan dari persamaan ini terhadap , mensetelnya ke nol, dan menyelesaikannya, Anda akan menemukan bahwa nilai yang meminimalkan hanyalah mean aritmetika. Ini penting karena dalam banyak metode statistik, seperti regresi OLS, kita meminimalkan galat kuadrat demi kemudahan matematis dan untuk menyesuaikan dengan asumsi galat yang berdistribusi normal.
Sekarang pertimbangkan gagasan berbeda: Alih-alih menguadratkan setiap deviasi, kita mengukur absolut error antara m dan setiap titik data:
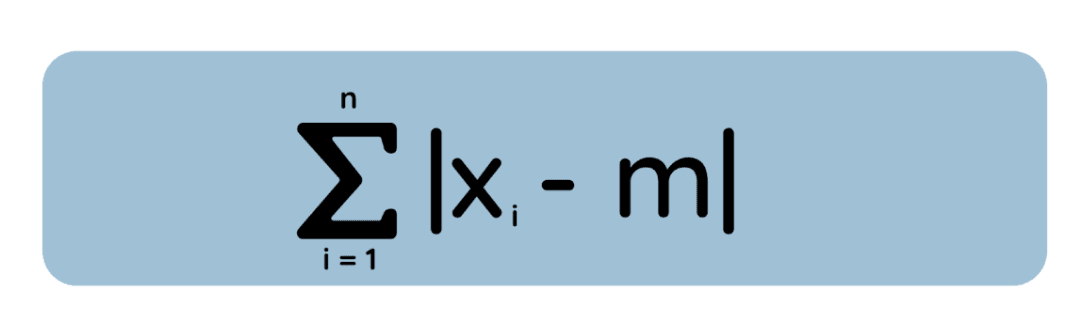
Di sini kita ingin menemukan m yang meminimalkan total deviasi absolut ini. Ternyata (dengan menganalisis turunan dari kerugian absolut, atau dengan argumen geometris) solusinya adalah median dari himpunan data. (Dan ketika Anda memiliki jumlah observasi genap, nilai apa pun di antara dua titik tengah meminimalkan total deviasi absolut—jadi peminimumnya mungkin tidak unik.)
Secara intuitif, jika berada di kiri median, ada lebih banyak titik data di kanan yang menariknya untuk bergeser. Hanya median yang membuat tarikan dari kiri dan kanan seimbang, sehingga meminimalkan total jarak absolut.
Terakhir, saya akan katakan mean secara komputasional lebih sederhana pada skala besar. Artinya, Anda dapat menghitungnya secara inkremental saat data mengalir masuk, tanpa perlu mengurutkan.
Median sering dihitung dengan pengurutan dalam praktik, yang bisa mahal pada skala besar. Namun median tidak secara inheren memerlukan pengurutan penuh (ada algoritma seleksi), dan untuk himpunan data yang sangat besar atau streaming, algoritma sketsa kuantil aproksimasi umum digunakan untuk memperkirakan median secara efisien. Kursus Concepts in Computer Science kami adalah sumber yang bagus untuk mempelajari hal-hal ini.
Seperti yang telah Anda lihat, mean adalah rata-rata aritmetika dari suatu himpunan data, yang membuatnya sensitif terhadap nilai ekstrem, sementara median merepresentasikan nilai tengah dalam himpunan data yang diurutkan. Pilihan yang tepat dapat membuat perbedaan besar tetapi, demikian dikatakan, dalam analisis dunia nyata, sering kali terbaik untuk melaporkan baik mean maupun median bersamaan dengan statistik tambahan seperti modus, simpangan baku, dan persentil. Ini adalah cara terbaik karena memberikan gambaran yang menyeluruh.
Jika Anda ingin menggali lebih dalam konsep statistik, ada beberapa area yang layak difokuskan. Mulailah dengan membaca variasi mean yang lebih lanjut, seperti trimmed mean, geometric mean, dan mean berbobot, yang masing-masing memiliki kegunaannya. Saya juga merekomendasikan kursus Introduction to Statistics kami yang bebas teknologi tertentu.
Lalu, untuk benar-benar menjadi lebih ahli, Anda akan ingin memilih dan menguasai sebuah alat. Kursus Introduction to Statistics in R dan jalur karier Statistician in R kami sama-sama merupakan titik awal yang sangat informatif jika Anda ingin menggunakan R, yang merupakan bahasa populer untuk data science dan statistik. Jika Anda lebih suka bekerja dengan spreadsheet dan bahasa pemrograman seperti Python, kursus Introduction to Statistics in Google Sheets dan Introduction to Statistics in Python kami memberikan pendekatan praktis untuk analisis statistik menggunakan rumus dan pustaka yang kuat.
Belajar bersama DataCamp
Kursus
Kursus
Kursus