
Corso
Analisi esplorativa dei dati in R
4 h
118.1K
Quando interpreti i dati, scegliere la giusta misura di tendenza centrale può determinare il successo o il fallimento della tua analisi. Tra le metriche più comuni ci sono media e mediana, due concetti all’apparenza semplici che hanno implicazioni profonde nell’interpretazione dei dati. Mentre la media ci dà la media aritmetica, la mediana è il punto centrale in un insieme di valori ordinati, tale che metà delle osservazioni si trovi da ciascun lato. Ma quale delle due è più affidabile? La risposta dipende spesso dalla distribuzione dei dati, dalla presenza di outlier e dalla storia che vuoi raccontare.
In questo articolo analizzerò le differenze tra media e mediana, i loro punti di forza e di debolezza e come scegliere quella giusta in diversi scenari. Esplorerò anche come le distribuzioni asimmetriche e gli outlier influenzano queste misure, fornendo esempi pratici e visualizzazioni per aiutarti a comprendere questi concetti fondamentali. Toccheremo anche idee più avanzate.
Per comprendere appieno le differenze tra media e mediana, esaminiamo ciascuna di queste misure e mettiamone in evidenza le proprietà chiave.
La media può essere vista come il “punto di equilibrio” (o centro di massa) dei dati. Considera tutti i punti dati in un dataset e fornisce un unico valore che rappresenta la media. Più precisamente, la media si calcola sommando tutti i valori in un dataset e dividendo poi per il numero di valori.
La mediana è il valore centrale quando i dati sono ordinati. A differenza della media, è più robusta rispetto agli outlier e fornisce una misura di tendenza centrale migliore per dati asimmetrici.
La moda è un’altra misura di tendenza centrale e rappresenta il valore che si presenta più frequentemente in un dataset. Vediamo un esempio:
3, 3, 6, 8, 9Qui la moda è 3 perché compare due volte, mentre tutti gli altri valori compaiono una sola volta.
Leggere una definizione è una cosa, calcolare è un’altra. In questa sezione illustrerò i passaggi per calcolare ciascuna misura e metterò in evidenza le differenze computazionali.
La media è la media aritmetica di un dataset e si calcola così:
Ecco il processo rappresentato come equazione generale:
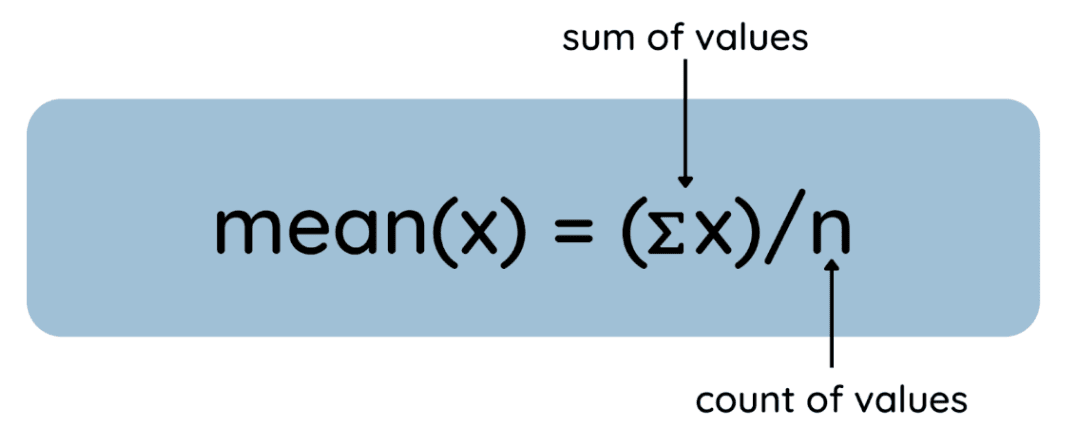
Come trovare la media. Immagine dell’autore
Per esempio, considera un dataset di voti d’esame:
78, 85, 92, 88, 70La media è 82,6.
La mediana è il valore centrale di un dataset quando è ordinato in senso crescente. Ecco come trovarla:
Ecco questi passaggi rappresentati come formule:
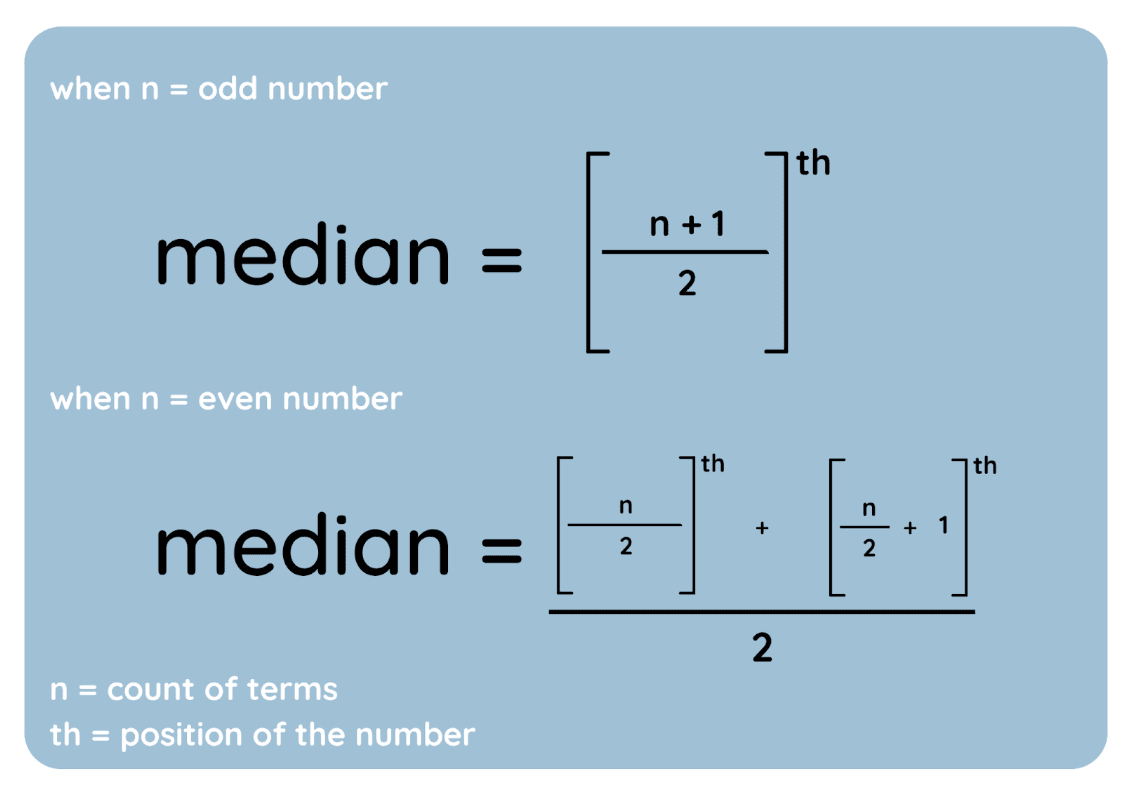
Formula della mediana. Immagine dell’autore
Ho anche creato una visualizzazione per evidenziare il processo.
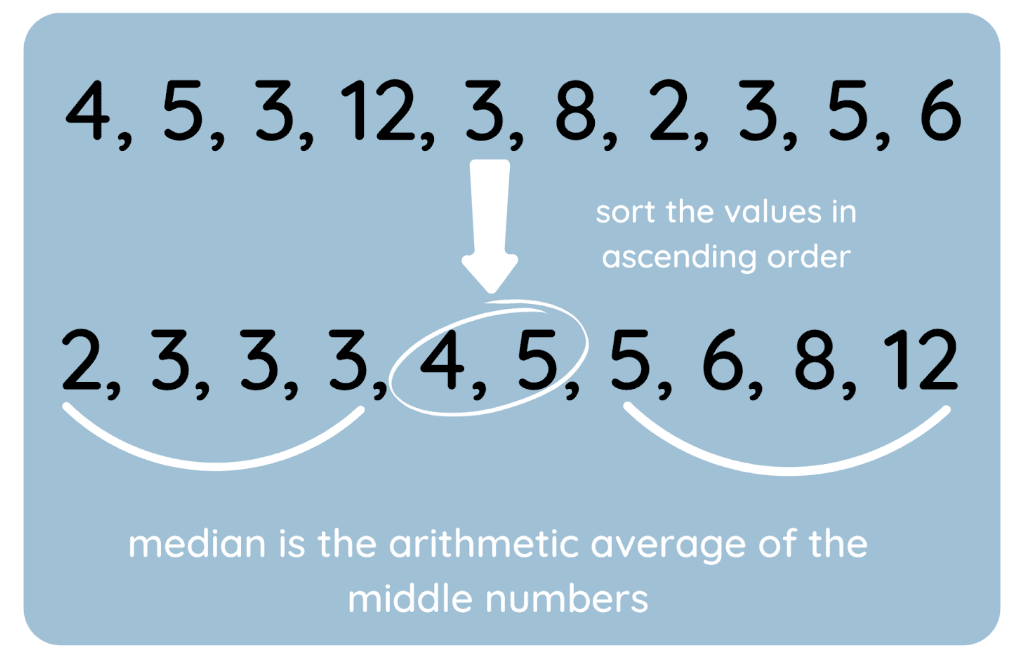
Come trovare la mediana. Immagine dell’autore
Ecco un dataset di esempio con un numero dispari di valori:
70, 78, 85, 88, 92La mediana è 85.
Ecco un altro esempio, ma con un numero pari di valori:
70, 78, 85, 88La mediana è 81,5.
Sebbene sia la media sia la mediana descrivano il centro di un dataset, il loro comportamento diverge significativamente in presenza di outlier e distribuzioni asimmetriche. Comprendere questa differenza è molto importante per interpretare correttamente i dati ed evitare conclusioni fuorvianti.
Gli outlier sono valori significativamente più alti o più bassi rispetto al resto dei dati. Possono influenzare fortemente la media, ma hanno un effetto minimo o nullo sulla mediana.
Consideriamo un dataset di redditi mensili (in migliaia):
3, 3.5, 4, 4.5, 5, 6, 50La media del reddito qui è 10,85k, fortemente influenzata dal valore estremo di 50k.
D’altra parte, il valore di mediana è 4,5k che, direi, rappresenta molto più tipicamente il reddito di questo gruppo.
Media e mediana differiscono anche nel modo in cui rappresentano i dati in distribuzioni asimmetriche (dataset non simmetrici).
Per esempio, nelle distribuzioni asimmetriche a destra (es. reddito o prezzi delle case), la maggior parte dei valori è concentrata nella parte bassa, con pochi valori estremi che allungano la coda verso destra.
Considera i redditi:
30k, 35k, 40k, 45k, 50k, 100k, 200kUna cosa da ricordare è che è importante esaminare sempre la distribuzione dei dati prima di decidere se usare media o mediana. Strumenti come istogrammi e box plot possono aiutare a visualizzare l’asimmetria e a identificare gli outlier. Ne parleremo più avanti. Inoltre, vale la pena dire che esaminare la differenza tra media e mediana è un modo per valutare l’asimmetria.
Quando analizzi i dati, decidere se usare la media o la mediana dipende dalle caratteristiche del dataset e dagli insight che stai cercando di ottenere. Di seguito trovi una tabella di riferimento rapido per guidare la tua scelta:
| Usa la media quando | Usa la mediana quando |
|---|---|
| La distribuzione dei dati è approssimativamente normale (simmetrica). | I dati sono molto asimmetrici (es. reddito, valore degli immobili). |
| Gli outlier sono minimi o irrilevanti per l’analisi. | Sono presenti outlier che potrebbero distorcere i risultati se inclusi. |
| Hai bisogno di una misura sensibile a ogni punto dati, ad esempio nel modeling predittivo o quando calcoli totali. | Vuoi riflettere il valore “tipico” piuttosto che il “centro matematico” del dataset. |
Ecco un consiglio pratico davvero utile: inizia sempre con un’analisi visiva dei tuoi dati (es. istogramma o box plot) per verificare simmetria, asimmetria e presenza di outlier. Questo ti aiuterà a decidere se la media o la mediana è più adatta al tuo scenario.
Le visualizzazioni sono strumenti potenti per comprendere il comportamento di media e mediana in diversi dataset. Possono mostrare chiaramente come queste misure rispondono a outlier e distribuzioni asimmetriche, aiutando a prendere decisioni migliori basate sui dati.
Immagina un piccolo dataset di redditi in migliaia:
30, 35, 40, 45, 50, 55, 1000Il seguente bar chart mostra come un singolo valore estremo possa influenzare drasticamente la media, lasciando la mediana relativamente stabile. In questo caso, la maggior parte dei punti dati è compresa tra 30 e 55, ma la presenza di un outlier (1000) trascina verso l’alto la media.
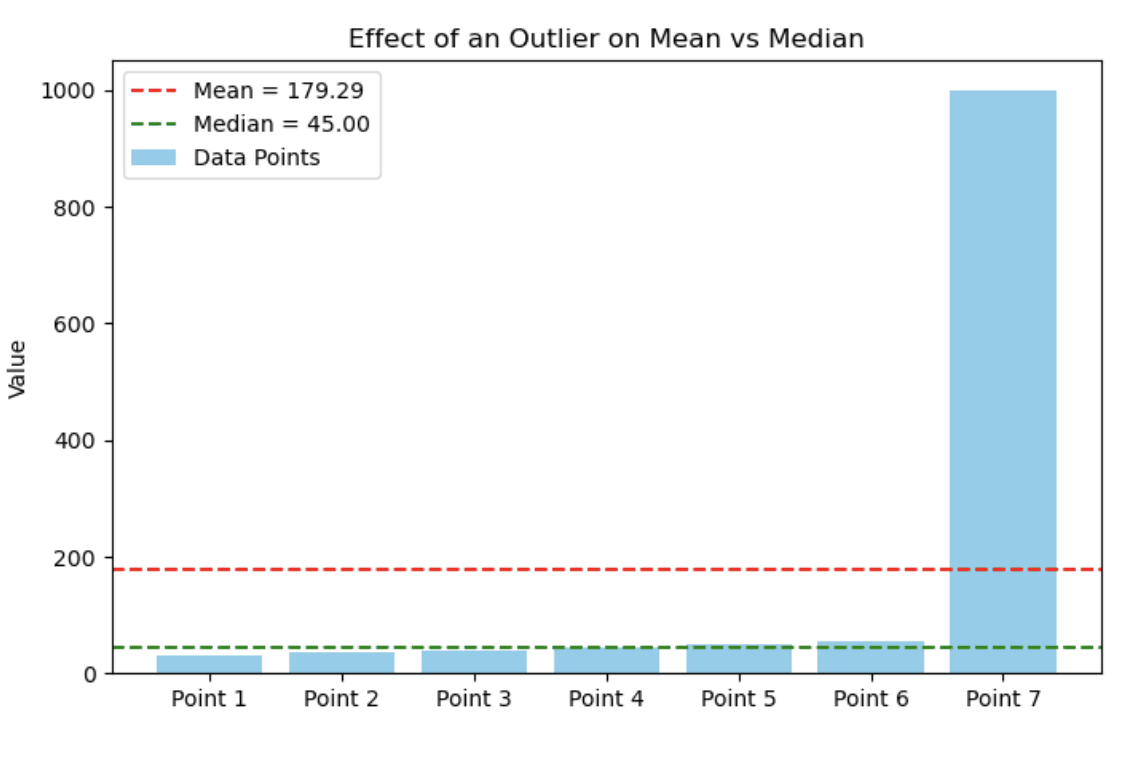
Bar chart che mostra l’effetto di un outlier su media vs mediana. Immagine dell’autore
In una distribuzione asimmetrica a destra (come redditi o prezzi delle case), la media viene spesso trascinata verso la coda lunga dei valori elevati, mentre la mediana rimane più vicina al punto dati “tipico”. In questi casi, la mediana è una misura di tendenza centrale migliore.
L’istogramma qui sotto mostra una distribuzione simulata dei redditi in cui la media (linea tratteggiata rossa) è significativamente maggiore della mediana (linea tratteggiata verde) a causa dell’asimmetria.
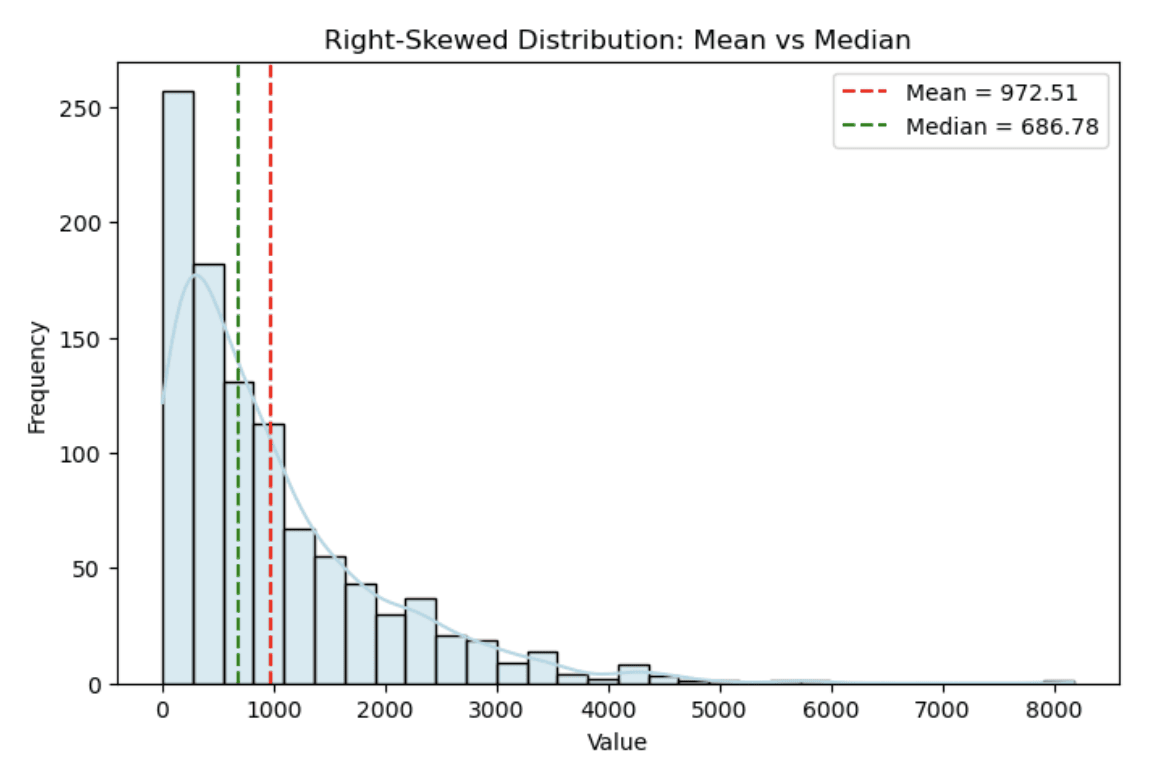
Istogramma che mostra una distribuzione asimmetrica a destra. Immagine dell’autore
Si nota come l’asimmetria a destra allunghi la coda, creando una chiara differenza tra media e mediana.
Un box plot è un ottimo modo per visualizzare l’impatto degli outlier sulla mediana. Sotto, confrontiamo due gruppi: uno con outlier e uno senza. La mediana (linea verticale all’interno della scatola) rimane stabile anche in presenza di valori estremi, ma l’intervallo complessivo dei dati è fortemente influenzato dall’outlier.
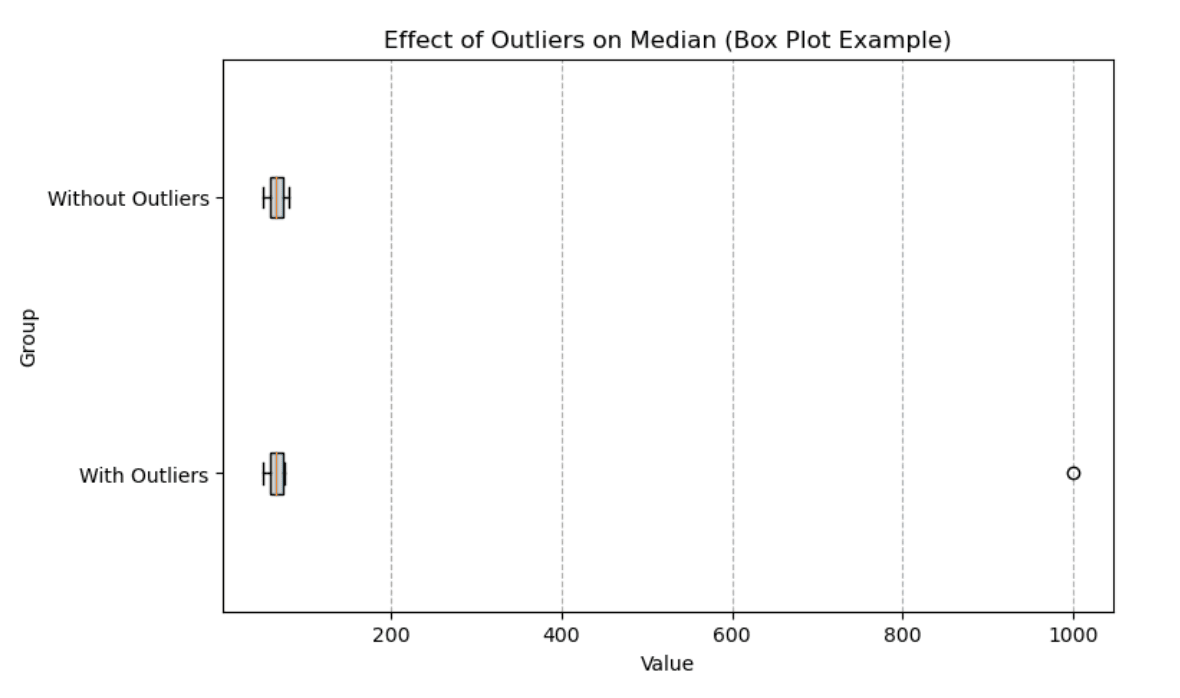
Box plot che mostra l’effetto degli outlier sulla mediana. Immagine dell’autore
Queste visualizzazioni evidenziano come media e mediana rispondano a diverse caratteristiche dei dati, chiarendo quando usare ciascuna misura. Che tu stia analizzando dati asimmetrici, dataset soggetti a outlier o confrontando gruppi, ausili visivi come questi possono rendere molto più comprensibili relazioni complesse.
Vediamo ora alcune idee più avanzate, se sei curioso di saperne di più.
Se sei un data scientist e devi colmare i vuoti nei dati, potresti dover scegliere un metodo di imputazione. Ora potresti chiederti: qual è la differenza pratica tra imputazione con media vs mediana?
Come puoi immaginare, l’imputazione con la media sostituisce i valori mancanti con la media dei dati disponibili, che, come abbiamo detto, può essere influenzata da valori estremi. L’imputazione con la mediana, invece, sostituisce i valori mancanti con il valore centrale del dataset.
Una regola pratica utile è guardare alla distribuzione dei dati. Se la distribuzione fosse asimmetrica con molti valori mancanti e avessi usato l’imputazione con la media, potresti aver alterato la distribuzione dei tuoi dati!
Ma ricorda anche che l’imputazione a valore singolo (media o mediana) può ridurre la varianza e indebolire le relazioni tra variabili. Se la quantità di dati mancanti è sostanziale, considera l’imputazione multipla o basata su modello per preservare meglio incertezza e struttura.
In molti metodi parametrici, la media (e la varianza) sono parametri centrali. Ad esempio, un modello di regressione lineare semplice assume che gli errori siano distribuiti normalmente attorno a una media. Quando i tuoi dati soddisfano l’assunzione di normalità, la media campionaria è uno stimatore naturale e si inserisce bene nei framework parametrici.
La mediana, invece, è spesso usata in contesti robusti e non parametrici, ed è una scelta comune quando i dati sono asimmetrici o contengono outlier. Molti test, come il test di Mann–Whitney, sono basati sui ranghi e confrontano distribuzioni (spesso interpretate come uno spostamento di posizione sotto certe assunzioni) piuttosto che le medie, e non testano sempre una differenza nelle mediane.
Tutto questo per dire che comprendere la distinzione tra media e mediana non serve solo a descrivere correttamente i dati, ma è importante anche nel test d’ipotesi.
Quando decidi se usare una media o una mediana, una domanda chiave è quanto siano stabili le nostre statistiche per un dato dataset. Il bootstrapping è un’opzione che consente di stimare empiricamente la distribuzione campionaria sia della media sia della mediana rieseguendo ripetutamente campionamenti (con reinserimento) dai dati originali.
Potresti mettere in evidenza empiricamente le differenze di stabilità tra media e mediana. Potresti introdurre alcuni outlier in un dataset e poi rieseguire una procedura bootstrap, mostrando così visivamente come la distribuzione della media si sposti più drasticamente rispetto a quella della mediana. Inoltre, il bootstrapping può rendere concreto quanto possano essere ampi o stretti i tuoi intervalli di confidenza in scenari realistici. Leggi il nostro tutorial sull’applicazione dei metodi bootstrap per saperne di più.
Ora ti propongo una definizione alternativa ma ugualmente vera: la media è il valore che minimizza la somma degli scarti al quadrato dai dati, mentre la mediana è il valore che minimizza la somma degli scarti assoluti.
Guarda questa equazione:
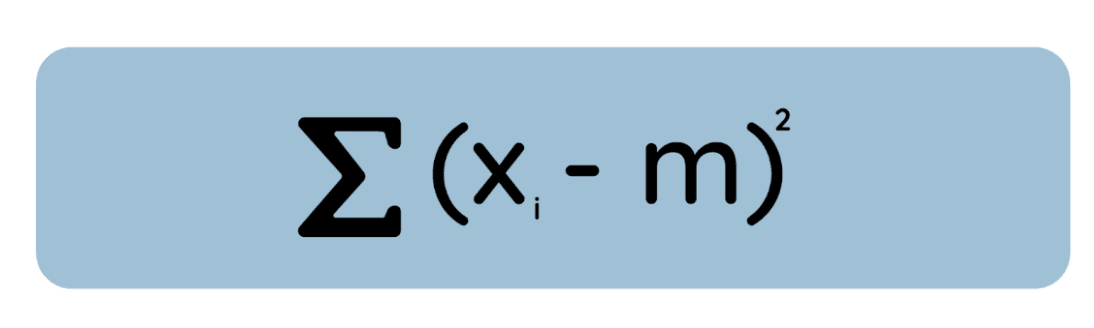
Se prendi la derivata di questa equazione rispetto a , la poni uguale a zero e risolvi, vedrai che il valore che minimizza è semplicemente la media aritmetica. Questo è importante perché in molti metodi statistici, come la regressione OLS, minimizziamo gli errori quadratici per comodità matematica e per rispettare l’assunzione di errori distribuiti normalmente.
Ora considera un’idea diversa: invece di elevare al quadrato ogni scarto, misuriamo l’errore assoluto tra m e ciascun punto dati:
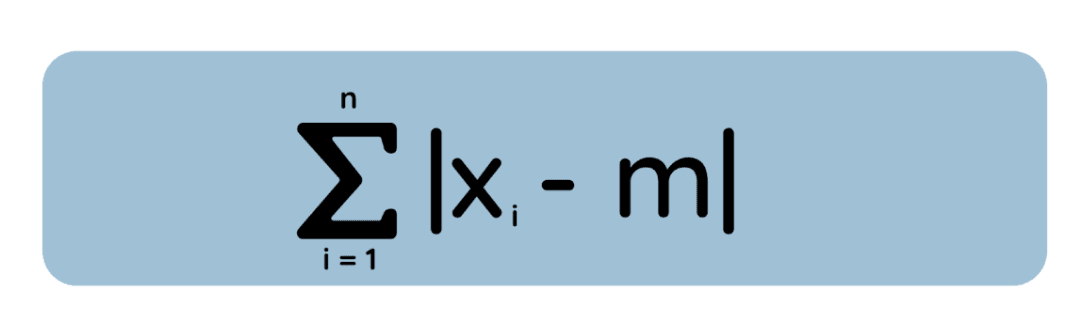
Qui vogliamo trovare m che minimizza questa deviazione assoluta totale. Si scopre (analizzando la derivata della perdita assoluta o con un argomento geometrico) che la soluzione è la mediana del dataset. (E quando hai un numero pari di osservazioni, qualsiasi valore tra i due punti centrali minimizza la deviazione assoluta totale—quindi il minimizzatore potrebbe non essere unico.)
Intuitivamente, se è a sinistra della mediana, ci sono più punti dati a destra che lo “tirano” a spostarsi. Solo la mediana è il punto in cui la spinta da sinistra e destra si bilancia, minimizzando la distanza assoluta totale.
Infine, direi che la media è computazionalmente più semplice su larga scala. Significa che puoi calcolarla in modo incrementale man mano che i dati arrivano in streaming, senza dover ordinare.
La mediana in pratica viene spesso calcolata ordinando, il che può essere costoso su larga scala. Ma la mediana non richiede intrinsecamente un ordinamento completo (esistono algoritmi di selezione) e, per dataset molto grandi o in streaming, sono comunemente usati algoritmi di quantile sketch approssimati per stimare la mediana in modo efficiente. Il nostro corso Concepts in Computer Science è un’ottima risorsa per imparare queste cose.
Come hai visto, la media è la media aritmetica di un dataset, il che la rende sensibile ai valori estremi, mentre la mediana rappresenta il valore centrale in un dataset ordinato. La scelta giusta può fare la differenza ma, detto questo, nelle analisi reali è spesso meglio riportare sia la media sia la mediana insieme a statistiche aggiuntive come moda, deviazione standard e percentili. Questo è il modo migliore perché offre un quadro completo.
Se vuoi approfondire i concetti statistici, ci sono diverse aree su cui vale la pena concentrarsi. Inizia leggendo varianti più avanzate della media, come la media troncata, la media geometrica e la media ponderata, che hanno ciascuna il proprio scopo. Ti consiglierei anche il nostro corso tecnologicamente neutro Introduction to Statistics.
Poi, per diventare davvero più esperto, vorrai scegliere e padroneggiare uno strumento. Il nostro corso Introduction to Statistics in R e il percorso di carriera Statistician in R sono entrambi ottimi punti di partenza se vuoi usare R, un linguaggio popolare per data science e statistica. Se preferisci lavorare con fogli di calcolo e un linguaggio di programmazione come Python, i nostri corsi Introduction to Statistics in Google Sheets e Introduction to Statistics in Python offrono un approccio pratico all’analisi statistica usando formule e librerie potenti.
Impara con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

