
Cursus
Exploratory Data Analysis in R
4 Hr
118.1K
Bij het interpreteren van data kan de juiste maat voor centrale tendentie je analyse maken of breken. De meest gebruikte maten zijn het gemiddelde en de mediaan: twee schijnbaar eenvoudige begrippen met grote gevolgen voor datainterpretatie. Terwijl het gemiddelde ons het rekenkundig gemiddelde geeft, is de mediaan het middelste punt in een gesorteerde reeks waarden, zodat de helft van de observaties aan weerszijden ligt. Maar welke is betrouwbaarder? Het antwoord hangt vaak af van de verdeling van je data, de aanwezigheid van uitschieters en het verhaal dat je wilt vertellen.
In dit artikel leg ik de verschillen uit tussen gemiddelde en mediaan, hun sterke en zwakke punten en hoe je in verschillende situaties de juiste kiest. Ik ga ook in op hoe scheve verdelingen en uitschieters deze maten beïnvloeden, met praktische voorbeelden en visuals om je te helpen deze basisbegrippen te begrijpen. We stippen ook kort wat meer geavanceerde ideeën aan.
Om de verschillen tussen het gemiddelde en de mediaan goed te begrijpen, bekijken we elk van deze maten en lichten we hun kerneigenschappen uit.
Het gemiddelde kun je zien als het “zwaartepunt” (of massamiddelpunt) van de data. Het neemt alle datapunten in een dataset mee en geeft één waarde die het gemiddelde vertegenwoordigt. Concreter gezegd: het gemiddelde wordt berekend door alle waarden in een dataset op te tellen en te delen door het aantal waarden.
De mediaan is de middelste waarde wanneer de data is gesorteerd. In tegenstelling tot het gemiddelde is ze robuuster tegen uitschieters en geeft ze een betere maat voor centrale tendentie bij scheve data.
De modus is een andere maat voor centrale tendentie en staat voor de meest voorkomende waarde in een dataset. Laten we een voorbeeld bekijken:
3, 3, 6, 8, 9Hier is de modus 3, omdat die twee keer voorkomt, terwijl alle andere waarden slechts één keer voorkomen.
Een definitie lezen is één ding, maar berekenen is iets anders. In deze sectie bespreek ik stap voor stap hoe je elke maat berekent en licht ik de computationele verschillen toe.
Het gemiddelde is het rekenkundig gemiddelde van een dataset en wordt als volgt berekend:
Hier is het proces weergegeven als algemene formule:
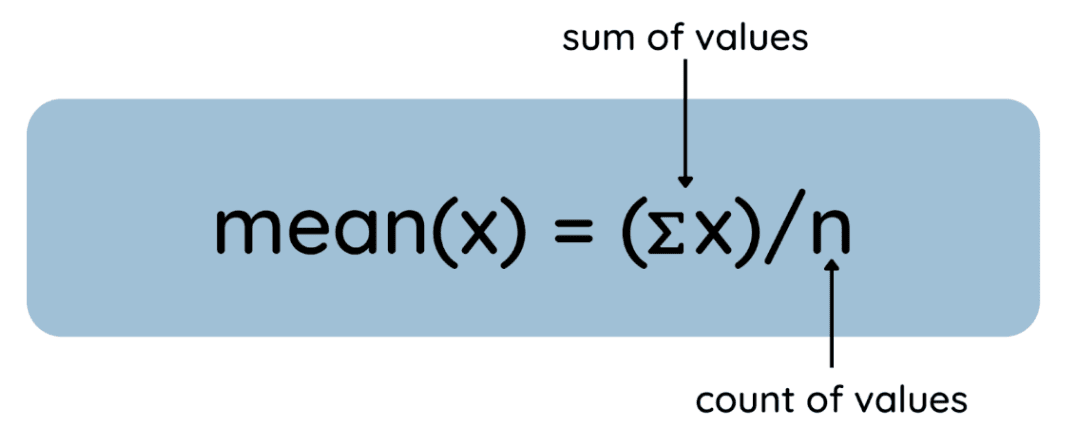
Zo vind je het gemiddelde. Afbeelding door auteur
Neem als voorbeeld een dataset met examencijfers:
78, 85, 92, 88, 70Het gemiddelde cijfer is 82,6.
De mediaan is de middelste waarde van een dataset wanneer die in oplopende volgorde staat. Zo vind je haar:
En hier zijn die stappen als formules weergegeven:
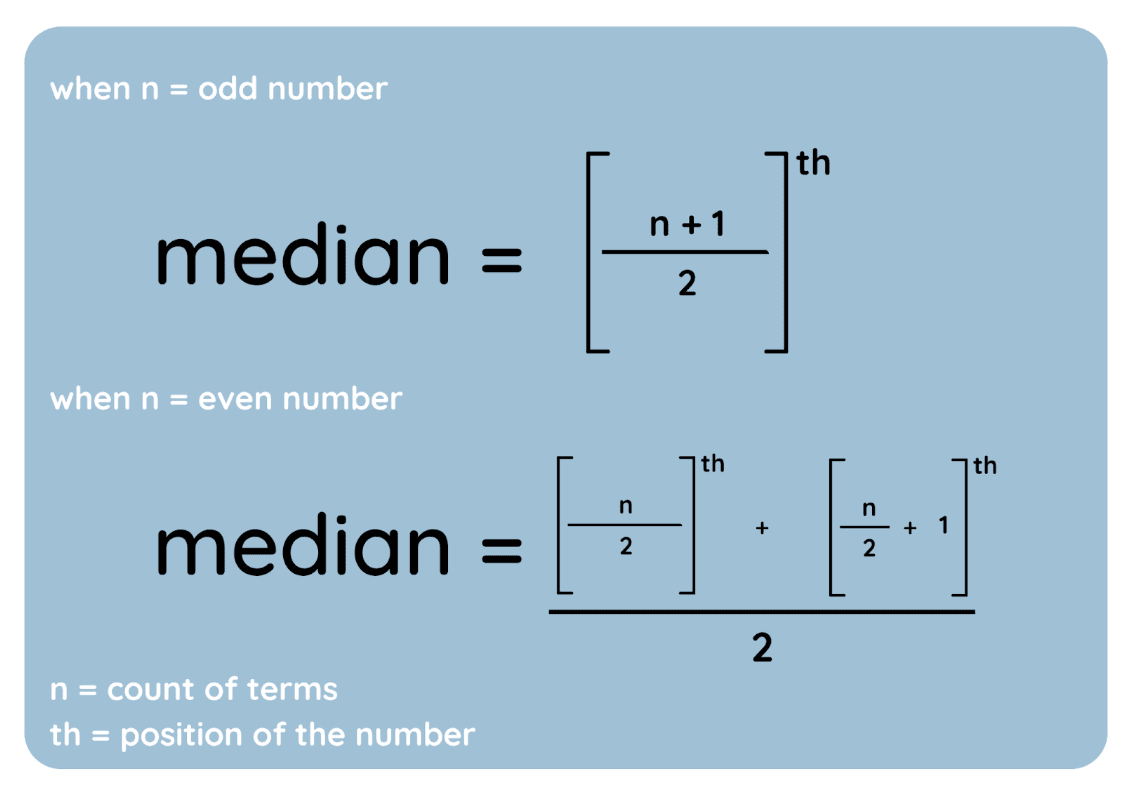
Formule voor de mediaan. Afbeelding door auteur
Ik heb ook een visual gemaakt om het proces te laten zien.
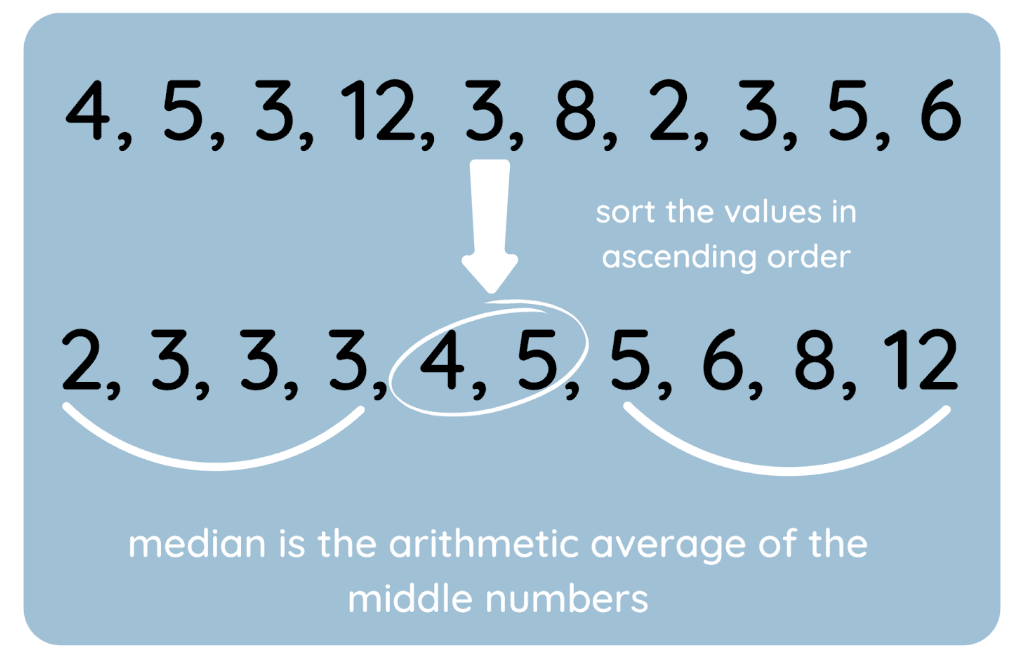
Zo vind je de mediaan. Afbeelding door auteur
Hier is een voorbeeld-dataset met een oneven aantal waarden:
70, 78, 85, 88, 92De mediaan is 85.
Hier is nog een voorbeeld, maar dan met een even aantal waarden:
70, 78, 85, 88De mediaan is 81,5.
Hoewel zowel het gemiddelde als de mediaan het midden van een dataset beschrijven, gedragen ze zich heel anders bij uitschieters en scheve verdelingen. Dit verschil begrijpen is cruciaal om data correct te interpreteren en misleidende conclusies te vermijden.
Uitschieters zijn waarden die aanzienlijk hoger of lager zijn dan de rest. Ze kunnen het gemiddelde sterk beïnvloeden, maar hebben weinig tot geen effect op de mediaan.
Bekijk een dataset met maandinkomens (in duizenden):
3, 3.5, 4, 4.5, 5, 6, 50Het gemiddelde inkomen is hier 10,85k, wat sterk wordt scheefgetrokken door de extreme waarde van 50k.
De mediaan daarentegen is 4,5k, wat, zou ik zeggen, een veel typischer weergave van het inkomen voor deze groep is.
Het gemiddelde en de mediaan verschillen ook in hoe ze data weergeven bij scheve verdelingen (datasets die niet symmetrisch zijn).
Neem bijvoorbeeld rechts-scheve verdelingen (zoals inkomen of huizenprijzen), waar de meeste waarden aan de onderkant clusteren en enkele extreme waarden de staart naar rechts trekken.
Neem inkomens:
30k, 35k, 40k, 45k, 50k, 100k, 200kWat je hiervan moet onthouden: bekijk altijd eerst de verdeling van je data voordat je beslist of je het gemiddelde of de mediaan gebruikt. Hulpmiddelen zoals histogrammen en boxplots helpen om scheefheid te visualiseren en uitschieters te herkennen. Daar komen we later op terug. Ook wil ik zeggen dat het bekijken van het verschil tussen gemiddelde en mediaan één manier is om scheefheid te beoordelen.
Bij data-analyse hangt de keuze tussen gemiddelde of mediaan af van de eigenschappen van je dataset en de inzichten die je zoekt. Onderstaand een snelle referentietabel om je keuze te helpen:
| Gebruik het gemiddelde wanneer | Gebruik de mediaan wanneer |
|---|---|
| De dataverdeling ongeveer normaal (symmetrisch) is. | De data sterk scheef is (bijv. inkomen, vastgoedwaarden). |
| Uitschieters minimaal zijn of niet relevant voor de analyse. | Er uitschieters zijn die de resultaten zouden kunnen vertekenen als je ze meeneemt. |
| Je een maat nodig hebt die gevoelig is voor elk datapunt, zoals bij voorspellende modellen of bij het berekenen van totalen. | Je de “typische” waarde wilt weergeven in plaats van het “wiskundige midden” van de dataset. |
Hier is een praktische tip die je echt helpt: begin altijd met een visuele analyse van je data (bijv. een histogram of boxplot) om te kijken naar symmetrie, scheefheid en de aanwezigheid van uitschieters. Dat helpt je te beslissen of het gemiddelde of de mediaan beter past bij jouw situatie.
Visualisaties zijn krachtige hulpmiddelen om het gedrag van gemiddelde en mediaan in verschillende datasets te begrijpen. Ze laten duidelijk zien hoe deze maten reageren op uitschieters en scheve verdelingen, wat helpt om betere datagedreven beslissingen te nemen.
Stel je een kleine dataset met inkomens in duizenden voor:
30, 35, 40, 45, 50, 55, 1000Het volgende staafdiagram laat zien hoe een enkele extreme waarde het gemiddelde drastisch kan beïnvloeden, terwijl de mediaan relatief stabiel blijft. In dit geval clusteren de meeste datapunten tussen 30 en 55, maar de aanwezigheid van een uitschieter (1000) trekt het gemiddelde omhoog.
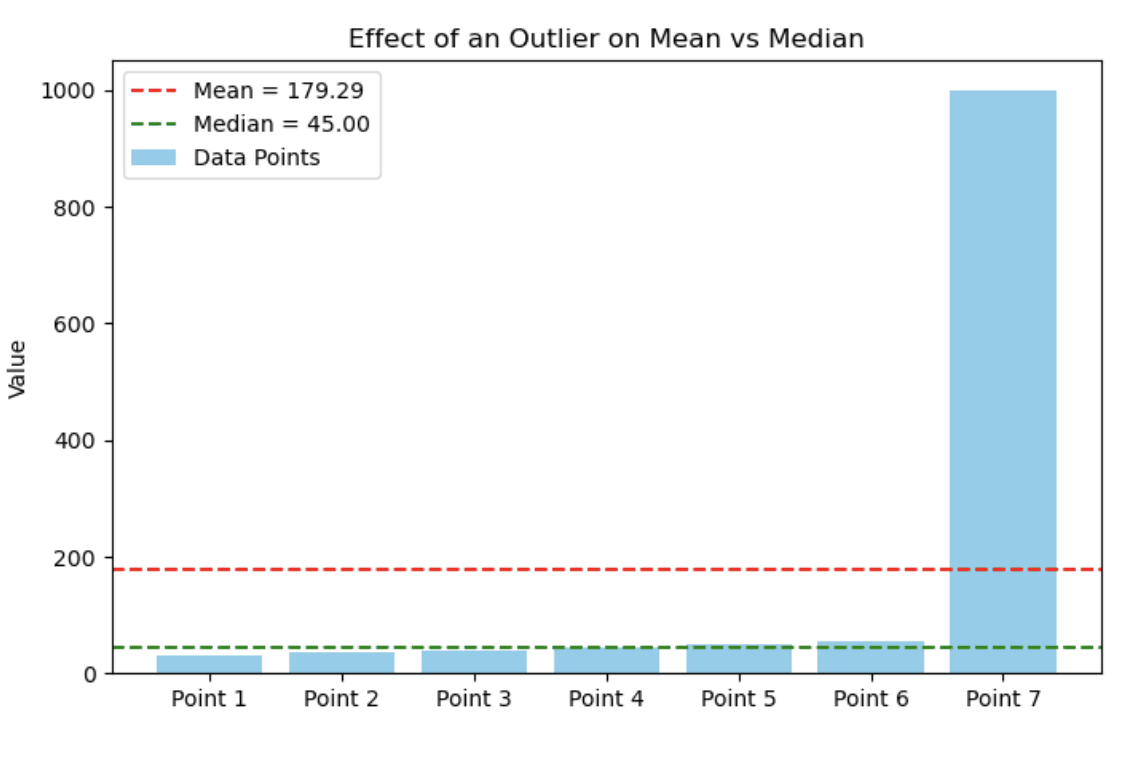
Staafdiagram dat het effect van een uitschieter op gemiddelde vs. mediaan laat zien. Afbeelding door auteur
In een rechts-scheve verdeling (zoals inkomens of huizenprijzen) wordt het gemiddelde vaak naar de lange staart van hoge waarden getrokken, terwijl de mediaan dichter bij het “typische” datapunt blijft. In zulke gevallen is de mediaan een betere maat voor centrale tendentie.
Het onderstaande histogram toont een gesimuleerde inkomensverdeling waarbij het gemiddelde (rode stippellijn) door de scheefheid aanzienlijk groter is dan de mediaan (groene stippellijn).
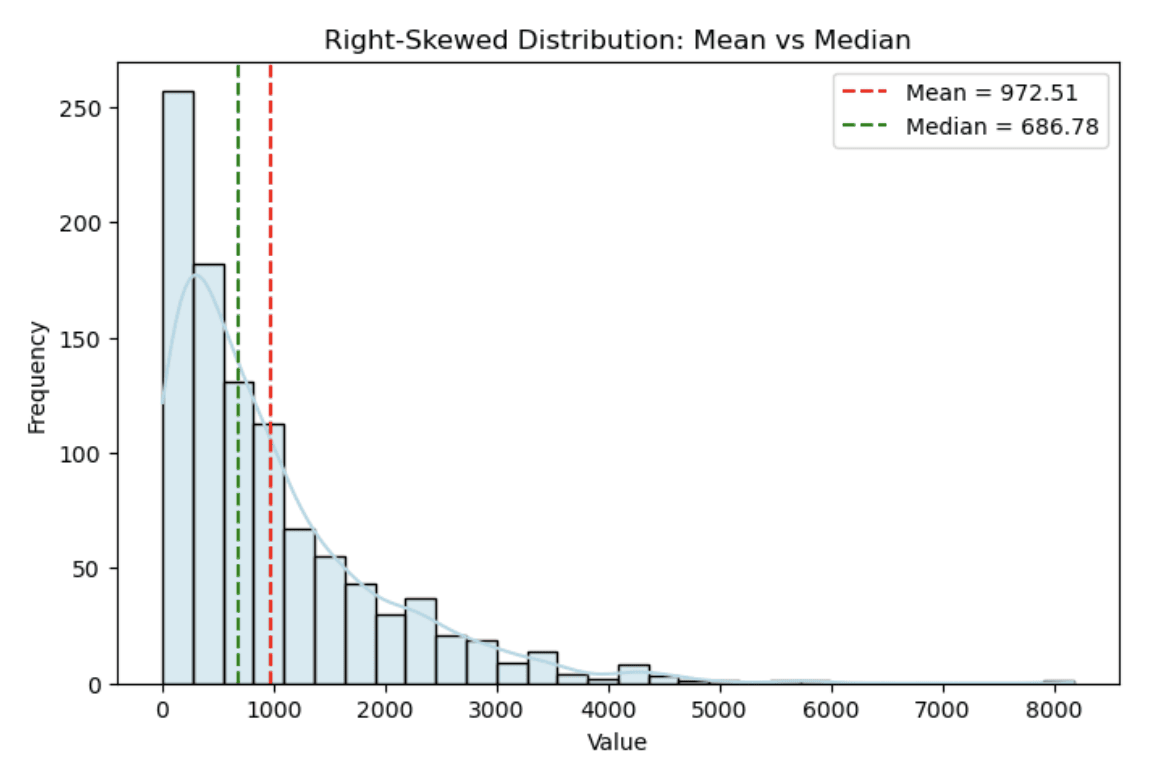
Histogram van een rechts-scheve verdeling. Afbeelding door auteur
Je ziet hoe de rechtsscheefheid de staart uitrekt en zo een duidelijk verschil tussen gemiddelde en mediaan creëert.
Een boxplot is een uitstekend middel om de impact van uitschieters op de mediaan te visualiseren. Hieronder vergelijken we twee groepen: één met uitschieters en één zonder. De mediaan (verticale lijn in de box) blijft stabiel, zelfs bij extreme waarden, maar het totale bereik van de data wordt sterk beïnvloed door de uitschieter.
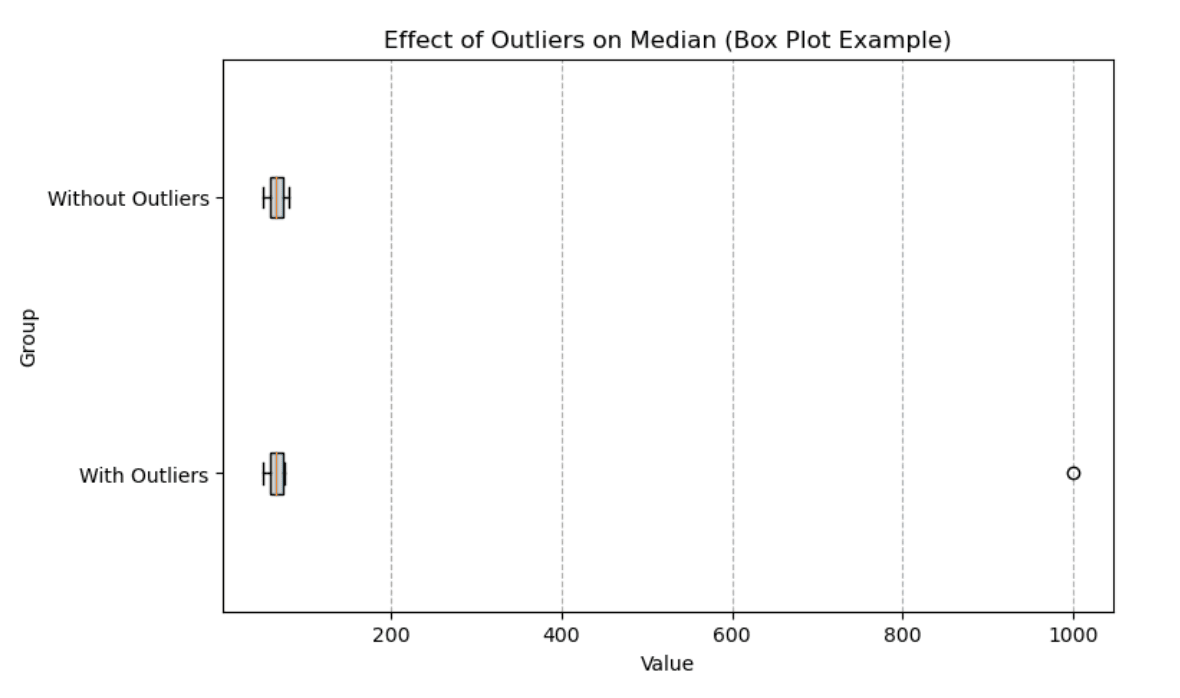
Boxplot die het effect van uitschieters op de mediaan laat zien. Afbeelding door auteur
Deze visualisaties laten zien hoe gemiddelde en mediaan reageren op verschillende data-eigenschappen en maken duidelijk wanneer je welke maat gebruikt. Of je nu scheve data analyseert, datasets met veel uitschieters bekijkt of groepen vergelijkt: dit soort visuals maakt complexe relaties veel begrijpelijker.
Laten we nu enkele meer geavanceerde ideeën bekijken als je nieuwsgierig bent naar meer.
Als je data scientist bent en hiaten in je data moet opvullen, moet je misschien een imputatiemethode kiezen. Je vraagt je nu misschien af: wat is het praktische verschil tussen imputatie met gemiddelde vs. mediaan?
Zoals je kunt raden vervangt imputatie met het gemiddelde ontbrekende waarden door het gemiddelde van de beschikbare data, wat, zoals we zeiden, kan worden scheefgetrokken door extreme waarden. Imputatie met de mediaan vervangt daarentegen ontbrekende waarden door de middelste waarde van de dataset.
Een handige vuistregel is om naar de verdeling van je data te kijken. Als je verdeling scheef is met veel ontbrekende waarden, en je zou imputatie met het gemiddelde gebruiken, dan zou je de verdeling van je data wel eens kunnen veranderen!
Maar onthoud ook dat enkelwaardige imputatie (gemiddelde of mediaan) de variantie kan verkleinen en relaties tussen variabelen kan verzwakken. Als er veel ontbreekt, overweeg dan multiple imputatie of modelgebaseerde imputatie om onzekerheid en structuur beter te behouden.
In veel parametrische methoden staan het gemiddelde (en de variantie) centraal. Zo gaat een eenvoudig lineair regressiemodel ervan uit dat fouten normaal verdeeld zijn rond een gemiddelde. Als je data aan de normaliteitsaanname voldoet, is het steekproefgemiddelde een logische schatter en past het goed binnen parametrische kaders.
De mediaan wordt vaak gebruikt in robuuste en niet-parametrische settings en is een veelgemaakte keuze wanneer data scheef is of uitschieters bevat. Veel toetsen, zoals de Mann–Whitney-toets, zijn ranggebaseerd en vergelijken verdelingen (vaak geïnterpreteerd als een locatieshift onder aannames) in plaats van gemiddelden, en ze toetsen niet altijd een verschil in medianen.
Dit alles wil zeggen dat het onderscheid tussen gemiddelde en mediaan niet alleen belangrijk is om data correct te beschrijven, maar ook in hypothesetoetsing.
Als je beslist tussen gemiddelde of mediaan, is een sleutelvraag hoe stabiel onze statistieken zijn voor een gegeven dataset. Bootstrapping is een optie waarmee je de steekproefverdeling van zowel het gemiddelde als de mediaan empirisch kunt schatten door herhaaldelijk (met teruglegging) te hertrekken uit de oorspronkelijke data.
Je kunt de verschillen in stabiliteit tussen gemiddelde en mediaan empirisch laten zien. Voeg een paar uitschieters toe aan een dataset en voer vervolgens een bootstrap-procedure opnieuw uit; zo kun je visueel laten zien dat de verdeling van het gemiddelde sterker verschuift dan die van de mediaan. Ook kan bootstrapping het concreet maken door te laten zien hoe groot of klein je betrouwbaarheidsintervallen kunnen zijn in realistische scenario’s. Lees onze tutorial over het toepassen van bootstrapmethoden voor meer info.
Laat me nu een alternatieve, maar even ware definitie geven: het gemiddelde is de waarde die de som van de gekwadrateerde afwijkingen van de data minimaliseert, terwijl de mediaan de waarde is die de som van de absolute afwijkingen minimaliseert.
Bekijk deze vergelijking:
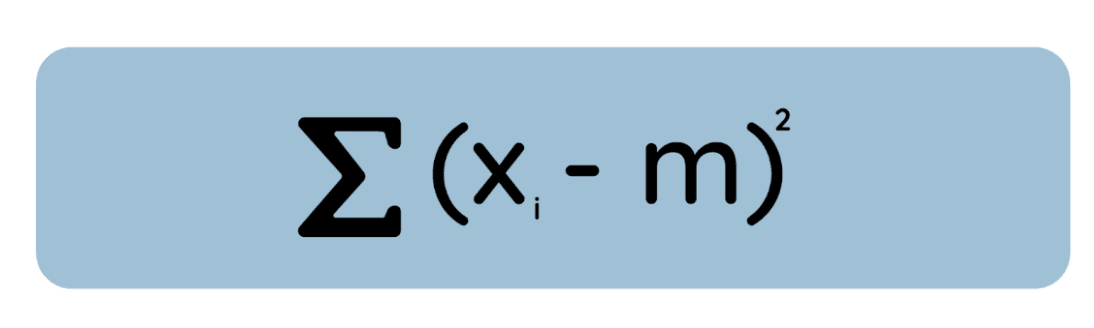
Als je hiervan de afgeleide neemt met betrekking tot , die gelijk aan nul zet en oplost, vind je dat de minimaliserende waarde simpelweg het rekenkundig gemiddelde is. Dit is relevant omdat we in veel statistische methoden, zoals OLS-regressie, de kwadratische fouten minimaliseren om wiskundige redenen en om te voldoen aan aannames van normaal verdeelde fouten.
Beschouw nu iets anders: in plaats van elke afwijking te kwadrateren, meten we de absolute fout tussen m en elk datapunt:
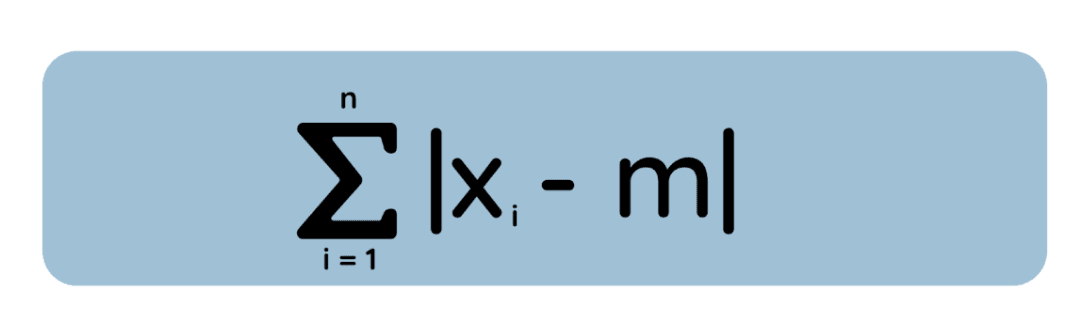
Hier willen we m vinden die deze totale absolute afwijking minimaliseert. Het blijkt (door de afgeleide van het absolute verlies te analyseren of via een geometrisch argument) dat de oplossing de mediaan van de dataset is. (En bij een even aantal observaties minimaliseert elke waarde tussen de twee middelste punten de totale absolute afwijking—de minimizer is dan mogelijk niet uniek.)
Intuïtief: als links van de mediaan ligt, zijn er meer datapunten rechts die “trekken” om op te schuiven. Alleen bij de mediaan is de trek van links en rechts in balans en is de totale absolute afstand minimaal.
Tot slot: het gemiddelde is computationeel eenvoudiger op schaal. Dat wil zeggen dat je het incrementeel kunt berekenen terwijl data binnenstroomt, zonder te hoeven sorteren.
De mediaan wordt in de praktijk vaak door sorteren berekend, wat op grote schaal duur kan zijn. Maar de mediaan vereist niet per se een volledige sortering (er zijn selectie-algoritmen) en voor zeer grote of streamende datasets worden veelgebruikte benaderende quantile sketch-algoritmen ingezet om de mediaan efficiënt te schatten. Onze cursus Concepts in Computer Science is een geweldige bron om hierover te leren.
Zoals je hebt gezien, is het gemiddelde het rekenkundig gemiddelde van een dataset, waardoor het gevoelig is voor extreme waarden, terwijl de mediaan de middelste waarde in een geordende dataset vertegenwoordigt. De juiste keuze kan een wereld van verschil maken, maar dat gezegd, in analyses uit de echte wereld is het vaak het beste om zowel het gemiddelde als de mediaan te rapporteren, samen met aanvullende statistieken zoals modus, standaarddeviatie en percentielen. Dat is het beste, omdat het een volledig beeld geeft.
Als je dieper in statistische concepten wilt duiken, zijn er verschillende interessante gebieden. Begin met het lezen over meer geavanceerde varianten van het gemiddelde, zoals het getrimde gemiddelde, het meetkundig gemiddelde en het gewogen gemiddelde, die elk hun doel hebben. Volg ook onze technologie-onafhankelijke cursus Introduction to Statistics.
Wil je echt meer expert worden, kies dan een tool en beheers die. Onze cursus Introduction to Statistics in R en het carrièrepad Statistician in R zijn allebei zeer informatieve startpunten als je met R wilt werken, een populaire taal voor data science en statistiek. Werk je liever met spreadsheets en een programmeertaal zoals Python, dan bieden onze cursussen Introduction to Statistics in Google Sheets en Introduction to Statistics in Python een hands-on aanpak van statistische analyse met formules en krachtige libraries.
Leren met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
